|
вЛЁЂListener
ListenerЯпГЬЃЌЕБServerДІгкдЫаазДЬЌЪБЃЌЦфИКд№МрЬ§РДздПЭЛЇЖЫЕФСЌНгЃЌВЂЪЙгУSelectФЃЪНДІРэAcceptЪТМўЁЃ
ЭЌЪБЃЌЫќПЊЦєСЫвЛИіПеЯаСЌНгЃЈIdle ConnectionЃЉДІРэР§ГЬЃЌШчЙћгаЙ§ЦкЕФПеЯаСЌНгЃЌОЭЙиБеЁЃетИіР§ГЬЭЈЙ§вЛИіМЦЪБЦїРДЪЕЯжЁЃ
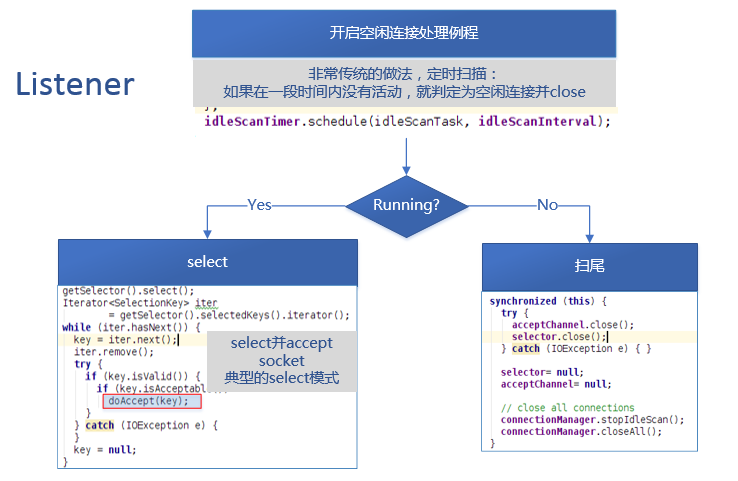
ЕБselectВйзїЕїгУЪБЃЌЫќПЩФмЛсзшШћЃЌетИјСЫЦфЫќЯпГЬжДааЕФЛњЛсЁЃЕБгаacceptЪТМўЗЂЩњЃЌЫќОЭЛсБЛЛНабвдДІРэШЋВПЕФЪТМўЃЌДІРэЪТМўЪЧНјаавЛИіdoAcceptЕФЕїгУЁЃ
doAcceptЃК
| void
doAccept(SelectionKey key) throws InterruptedException,
IOException, OutOfMemoryError {
ServerSocketChannel server = (ServerSocketChannel)
key.channel();
SocketChannel channel;
while ((channel = server.accept()) != null)
{
channel.configureBlocking(false);
channel.socket().setTcpNoDelay(tcpNoDelay);
channel.socket().setKeepAlive(true);
Reader reader = getReader();
Connection c = connectionManager.register(channel);
key.attach(c); // so closeCurrentConnection
can get the object
reader.addConnection(c);
}
} |
гЩгкЖрИіСЌНгПЩФмЭЌЪБЗЂЦ№ЩъЧыЃЌЫљвдетРяВЩгУСЫwhileбЛЗДІРэЁЃ
етРязюЙиМќЕФЪЧЩшжУСЫаТНЈСЂЕФsocketЮЊЗЧзшШћЃЌетвЛЕуЪЧЛљгкадФмЕФПМТЧЃЌЗЧзшШћЕФЗНЪНОЁПЩФмЕФЖСШЁsocketНгЪеЛКГхЧјжаЕФЪ§ОнЃЌетвЛЕуБЃжЄСЫНЋРДЛсЕїгУетИіsocketНјааНгЪеЕФReaderКЭНјааЗЂЫЭЕФResponderЯпГЬВЛЛсвђЮЊЗЂЫЭКЭНгЪеЖјзшШћЃЌШчЙћећИіЭЈбЖЙ§ГЬЖМБШНЯЗБУІЃЌФЧУДReaderКЭResponderЯпГЬЕФОЭПЩвдОЁСПВЛзшШћдкI/OЩЯЃЌетбљПЩвдЯджјМѕЩйЯпГЬЩЯЯТЮФЧаЛЛЕФДЮЪ§ЃЌЬсИпcpuЕФРћгУТЪЁЃ
зюКѓЃЌЛёШЁСЫвЛИіReaderЃЌНЋДЫСЌНгМгШыReaderЕФЛКГхЖгСаЃЌЭЌЪБШУСЌНгЙмРэЦїМрЪгВЂЙмРэетИіСЌНгЕФЩњДцЦкЁЃ
ЛёШЁReaderЕФЗНЪНШчЯТЃК
| //зюМђЕЅЕФИКдиОљКт
Reader getReader() {
currentReader = (currentReader + 1) % readers.length;
return readers[currentReader];
} |
ЖўЁЂReader
ЕБвЛИіаТНЈСЂЕФСЌНгБЛМгШыReaderЕФЛКГхЖгСаpendingConnectionsжЎКѓЃЌReaderвВБЛЛНабЃЌвдДІРэДЫСЌНгЩЯЕФЪ§ОнНгЪеЁЃ
| public
void addConnection(Connection conn) throws InterruptedException
{
pendingConnections.put(conn);
readSelector.wakeup();
} |
ServerжаХфжУСЫЖрИіReaderЯпГЬЃЌЯдШЛЪЧЮЊСЫЬсИпВЂЗЂЗўЮёСЌНгЕФФмСІЁЃ
ЯТУцЪЧReaderЕФжївЊТпМЃК
| while(true)
{
...
//ШЁГівЛИіСЌНгЃЌПЩФмзшШћ
Connection conn = pendingConnections.take();
//ЯђselectзЂВсвЛИіЖСЪТМў
conn.channel.register(readSelector, SelectionKey.OP_READ,
conn);
...
//НјааselectЃЌПЩФмзшШћ
readSelector.select();
...
//вРДЮЖСШЁЪ§Он
for(keys){
doRead(key);
}
...
} |
ЕБServerЛЙдкдЫааЪБЃЌReaderЯпГЬОЁПЩФмЖрЕиДІРэЛКГхЖгСажаЕФСЌНгЃЌзЂВсУПвЛИіСЌНгЕФREADЪТМўЃЌВЩгУselectФЃЪНРДЛёШЁСЌНгЩЯгаЪ§ОнНгЪеЕФЭЈжЊЁЃЕБгаЪ§ОнашвЊНгЪеЪБЃЌЫќОЁзюДѓПЩФмЖСШЁselectЗЕЛиЕФСЌНгЩЯЕФЪ§ОнЃЌвдЗРжЙListenerЯпГЬвђЮЊУЛгадЫааЪБМфЖјЗЂЩњМЂЖіЃЈstarvingЃЉЁЃ
ШчЙћListenerЯпГЬМЂЖіЃЌдьГЩЕФНсЙћЪЧВЂЗЂФмСІМБОчЯТНЕЃЌРДздПЭЛЇЖЫЕФаТСЌНгЧыЧѓГЌЪБЛђЮоЗЈНЈСЂЁЃ
зЂвтдкДгЛКГхЖгСажаЛёШЁСЌНгЪБЃЌReaderПЩФмЛсЗЂЩњзшШћЃЌвђЮЊЫќВЩгУСЫLinkedBlockingQueueРржаЕФtakeЗНЗЈЃЌетИіЗНЗЈдкЖгСаЮЊПеЪБЛсзшШћЃЌетбљReaderЯпГЬЕУвдзшШћЃЌвдИјЦфЫќЯпГЬжДааЕФЪБМфЁЃ
ReaderЯпГЬЕФЛНабЪБЛњгаСНИіЃК
ListenerНЈСЂСЫаТСЌНгЃЌВЂНЋДЫСЌНгМгШы1ИіReaderЕФЛКГхЖгСа;
selectЕїгУЗЕЛиЁЃ
дкReaderЕФdoReadЕїгУжа,ЦфжївЊЕїгУСЫreadAndProcessЗНЗЈЃЌДЫЗНЗЈбЛЗДІРэЪ§ОнЃЌНгЪеЪ§ОнАќЕФЭЗВПЁЂЩЯЯТЮФЭЗВПКЭеце§ЕФЪ§ОнЁЃ
етИіЙ§ГЬжажЕЕУвЛЬсЕФЪЧЯТУцЕФетИіchannelReadЗНЗЈЃК
| private
int channelRead(ReadableByteChannel channel,
ByteBuffer buffer) throws IOException {
int count = (buffer.remaining() <= NIO_BUFFER_LIMIT)
?
channel.read(buffer) : channelIO(channel, null,
buffer);
if (count > 0) {
rpcMetrics.incrReceivedBytes(count);
}
return count;
} |
channelReadЛсХаЖЯЪ§ОнНгЪеЪ§зщbufferжаЕФЪЃгрЮДЖСЪ§ОнЃЌШчЙћДѓгквЛИіСйНчжЕNIO_BUFFER_LIMITЃЌОЭВЩШЁЗжЦЌЕФММЧЩРДЖрДЮЕиЖСЃЌвдЗРжЙjdkЖдlarge
bufferВЩШЁБфЮЊdirect bufferЕФгХЛЏЁЃ
етвЛЕуЃЌвВаэЪЧПМТЧЕНdirect bufferдкНЈСЂЪБЛсгавЛаЉПЊЯњЃЌЭЌЪБдкjdk1.6жЎЧАdirect
bufferВЛЛсБЛGCЛиЪеЃЌвђЮЊЫќУЧЗжХфдкJVMЕФЖбЭтЕФФкДцПеМфжаЁЃ
ЕНЕзетбљгХЛЏЕФаЇЙћШчКЮЃЌУЛгаВтЪдЃЌвВОЭТдЙ§ЁЃвВаэЪЧЮЊСЫМѕЩйGCЕФИКЕЃЁЃ
дкReaderЖСШЁЕНвЛИіЭъећЕФRpcRequestАќжЎКѓЃЌЛсЕїгУprocessOneRpcЗНЗЈЃЌДЫЕїгУНЋНјШывЕЮёТпМЛЗНкЁЃетИіЗНЗЈЃЌЛсДгНгЪмЕНЕФЪ§ОнАќжаЃЌЗДађСаЛЏГіRpcRequestЕФЭЗВПКЭЪ§ОнЃЌвРДЫЙЙдьвЛИіRpcRequestЖдЯѓЃЌЩшжУПЭЛЇЖЫашвЊЕФИњзйаХЯЂЃЈtrace
infoЃЉЃЌШЛКѓЙЙдьвЛИіCallЖдЯѓЃЌШчЯТЭМЫљЪОЃК
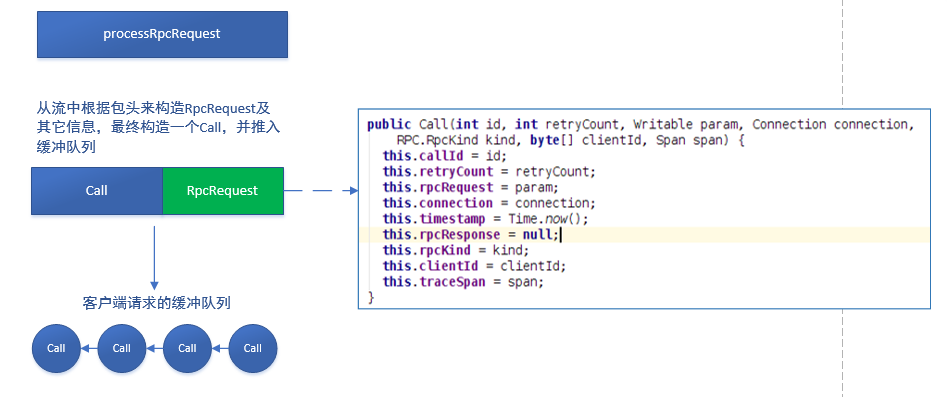
ДЫКѓЃЌдкHandlerДІРэЪБЃЌОЭвдCallЮЊЕЅЮЛЃЌетЪЧвЛИіАќКЌСЫгыСЌНгЯрЙиаХЯЂЕФЗтзАЖдЯѓЁЃ
гаСЫCallЖдЯѓКѓЃЌНЋЦфМгШыServerЕФcallQueueЖгСаЃЌвдЙЉHandlerДІРэЁЃвђЮЊВЩгУСЫputЗНЗЈЃЌЫљвдЕБcallQueueТњЪБЃЈHandlerУІЃЉЃЌReaderЛсЗЂЩњзшШћЃЌШчЯТЫљЪОЃК
| callQueue.put(call);
// queue the call; maybe blocked here |
Ш§ЁЂHandler
HandlerОЭЪЧИљОнrpcЧыЧѓжаЕФЗНЗЈЃЈCallЃЉМАВЮЪ§ЃЌРДЕїгУЯргІЕФвЕЮёТпМНгПкРДДІРэЧыЧѓЁЃ
вЛИіServerжагаЖрИіHandler,ЖдгІЖрИівЕЮёНгПкЃЌБОЦЊВЛЬжТлОпЬхвЕЮёТпМЁЃ
handlerЕФТпМЛљБОШчЯТЃЈТдШЅвьГЃКЭЦфЫќДЮвЊаХЯЂЃЉЃК
| public
void run() {
SERVER.set(Server.this);
ByteArrayOutputStream buf =
new ByteArrayOutputStream(INITIAL_RESP_BUF_SIZE);
while (running) {
try {
final Call call = callQueue.take(); // pop the
queue; maybe blocked here
CurCall.set(call);
try {
if (call.connection.user == null) {
value = call(call.rpcKind, call.connection.protocolName,
call.rpcRequest,
call.timestamp);
} else {
value =
call.connection.user.doAs(...);
}
} catch (Throwable e) {
//Тд ...
}
CurCall.set(null);
synchronized (call.connection.responseQueue)
{
responder.doRespond(call);
}
} |
ПЩМћЃЌHandlerДгcallQueueжаШЁГівЛИіCallЃЌШЛКѓЕїгУетИіServer.callЗНЗЈЃЌзюКѓЕїгУResponderЕФdoRespondeЗНЗЈНЋНсЙћЗЂЫЭИјПЭЛЇЖЫЁЃ
Server.callЗНЗЈЃК
| public
Writable call(RPC.RpcKind rpcKind, String protocol,
Writable rpcRequest, long receiveTime) throws
Exception {
return getRpcInvoker(rpcKind).call(this, protocol,
rpcRequest,
receiveTime);
} |
ЫФЁЂResponder
вЛИіServerжЛга1ИіResponderЯпГЬЁЃ
ДЫЯпГЬВЛЖЯНјааШчЯТМИИіживЊЕїгУвдКЭHandlerаЕїВЂЗЂЫЭЪ§ОнЃК
| //етИіwaitЪЧЭЌВНзїгУЃЌОпЬхМћЯТУцЗжЮі
waitPending();
...
//ПЊЪМselectЃЌЛђаэЛсзшШћ
writeSelector.select(PURGE_INTERVAL);
...
//ШчЙћselectKeysгаЪ§ОнЃЌОЭвРДЮвьВНЗЂЫЭЪ§Он
for(selectorKeys){
doAsyncWrite(key);
}
...
//ЕБЕНДяЖЊЦњЪБМфЃЌЛсДгselectedKeysЙЙдьcallsЃЌВЂвРДЮЖЊЦњ
for(Call call : calls) {
doPurge(call, now);
} |
ЕБHandlerЕїгУdoRespondЗНЗЈКѓЃЌhandlerДІРэЕФНсЙћБЛМгШыresponseQueueЕФЖгЮВЃЌЖјВЛЪЧСЂМДЗЂЫЭЛиПЭЛЇЖЫЃК
| void
doRespond(Call call) throws IOException {
synchronized (call.connection.responseQueue)
{
call.connection.responseQueue.addLast(call);
if (call.connection.responseQueue.size() ==
1) {
//зЂвтетРяisHandler = true,БэЪОПЩФмЛсЯђselect
зЂВсаДЪТМўвддкResponderжїбЛЗжаЭЈЙ§selectДІРэЪ§ОнЗЂЫЭ
processResponse(call.connection.responseQueue,
true);
}
}
} |
ЩЯУцЕФsynchronized ПЩвдПДГіЃЌresponseQueueЪЧељгУзЪдДЃЌЯргІЕФЃК
HandlerЪЧЩњВњепЃЌНЋНсЙћМгШыЖгСаЃЛ
ResponderЪЧЯћЗбепЃЌДгЖгСажаШЁГіНсЙћВЂЗЂЫЭЁЃ
processResponseНЋЦєЖЏResponderНјааЗЂЫЭЃЌЪзЯШДгresponseQueueжавдЗЧзшШћЗНЪНШЁГівЛИіcallЃЌШЛКѓвдЗЧзшШћЗНЪНОЁСІЗЂЫЭcall.rpcResponseЃЌШчЙћЗЂЫЭЭъБЯЃЌдђЗЕЛиЁЃ
ЕБЛЙгаЪЃгрЪ§ОнЮДЗЂЫЭЃЌНЋcallВхШыЖгСаЕФЕквЛИіЮЛжУЃЌгЩгкisHandlerВЮЪ§ЃЌдкРДздHandlerЕФЕїгУжаДЋШыЮЊtrueЃЌЫљвдЛсЛНабwriteSelectorЃЌВЂзЂВсвЛИіаДЪТМўЃЌЦфжаincPending()ЗНЗЈЃЌЪЧЮЊСЫдкЯђselectorзЂВсаДЪТМўЪБЃЌзшШћResponderЯпГЬЃЌКѓУцгаЗжЮіЁЃ
| call.connection.responseQueue.addFirst(call);
if (inHandler) {
// set the serve time when the response has
to be sent later
call.timestamp = Time.now();
incPending();
try {
// Wakeup the thread blocked on select, only
then can the call
// to channel.register() complete.
writeSelector.wakeup();
channel.register(writeSelector, SelectionKey.OP_WRITE,
call);
} catch (ClosedChannelException e) {
//Its ok. channel might be closed else where.
done = true;
} finally {
decPending();
}
} |
дйЛиЕНResponderЕФжїбЛЗЃЌПДПДШчЙћЯђselectзЂВсСЫаДЪТМўЛсЗЂЩњЪВУДЃК
| //жДааетОфЪБЃЌШчЙћHandlerЕїгУЕФresponder.doResonde()
е§дкЯђselectзЂВсаДЪТМўЃЌетРяОЭЛсзшШћ
//ФПЕФКмЯдШЛЃЌЪЧЮЊСЫЯТОфЕФselectФмЛёШЁЪ§ОнВЂСЂМДЗЕЛиЃЌ
етОЭМѕЩйСЫзшШћЗЂЩњЕФДЮЪ§
waitPending(); // If a channel is being registered,
wait.
//етРягУГЌЪБзшШћРДselect,ЪЧЮЊСЫФмЙЛдкУЛгаЪ§ОнЗЂЫЭЪБЃЌ
ЖЈЦкЛНабЃЌвдДІРэГЄЦкЮДЕУЕНДІРэЕФCall
writeSelector.select(PURGE_INTERVAL);
Iterator<SelectionKey> iter = writeSelector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
try {
if (key.isValid() && key.isWritable())
{
//вьВНЗЂЫЭ
doAsyncWrite(key);
}
} catch (IOException e) {
LOG.info(Thread.currentThread().getName() +
":
doAsyncWrite threw exception " + e);
}
} |
жиЕуФкШнЖМзіСЫзЂЪЭЃЌВЛдйзИЪіЁЃПЩвдПДГіЃЌМШПМТЧЭЌВНЃЌгжПМТЧадФмЃЌетЪЧжЕЕУбЇЯАЕФЕиЗНЁЃ
ЮхЁЂзмНс
БОЦЊзХжиЗжЮіСЫhadoopЕФrpcЕїгУжаserverВПЗжЃЌПЩвдПДГіЃЌетЪЧвЛИіОЋСМЕФЩшМЦЃЌПМТЧЕФКмЯИЁЃ
1.ЙигкЭЌВНЃК
ListenerЩњВњЃЌReaderЯћЗбЃЛReaderЩњВњЃЌHandlerЯћЗбЃЌHandlerЩњВњЃЌResponderЯћЗбЁЃ
ЫљвдЫќУЧжЎМфБиаыЭЌВН.дкОпЬхЕФhadoopЪЕЯжжаЃЌМШгаРћгУBlockingQueueЕФput&takeВйзїЪЕЯжзшШћЃЌвдДяЕНЭЌВНФПЕФЃЌвВЖдељгУзЪдДЪЙгУsynchronizedРДЪЕЯжЭЌВНЁЃ
2.ЙигкЛКГхЃК
ЦфжаМИИіЛКГхЖгСавВжЕЕУЙизЂ.ServerЕФВЂЗЂЧыЧѓЛсЬиБ№ЖрЃЌЖјHandlerдкжДааcallНјаавЕЮёТпМЪБЃЌПЯЖЈЛсТ§ЯТРДЃЌЫљвдБиаыНЈСЂЧыЧѓКЭДІРэжЎМфЕФЛКГхЁЃ
СэЭтЃЌДІРэКЭЗЂЫЭжЎМфвВЭЌбљЛсГіЯжЫйТЪВЛЦЅХфЕФЯжЯѓЃЌЭЌбљашвЊЛКГхЁЃ
3.ЙигкЯпГЬФЃаЭЃК
ListenerЕЅЯпГЬЃЌReaderЖрЯпГЬЃЌHandlerЖрЯпГЬЃЌResponderЕЅЯпГЬЃЌЮЊЪВУДЛсетбљЩшМЦЃПListenerВЩгУselectФЃЪНДІРэacceptЪТМўЃЌвЛИіПЭЛЇЖЫдквЛЖЮЪБМфФквЛАужЛНЈСЂгаЯоДЮЕФСЌНгЃЌЖјЧвСЌНгЕФНЈСЂЪЧБШНЯПьЕФЃЌЫљвдЕЅЯпГЬзуЙЛгІИЖЃЌНЈСЂКѓжБНгЖЊИјReaderЃЌДгЖјздМККмДгШнЕигІИЖаТСЌНгЁЃHandlerЖрЯпГЬЃЌвЕЮёТпМЪЧДѓЭЗЃЌгжКмДѓПЩФмЛсЧЃЩцI/OУмМЏ(HDFS)ЃЌШчЙћЯпГЬЩйЃЌКФЪБЙ§ГЄЕФвЕЮёТпМПЩФмОЭЛсШУДѓВПЗжЕФHandlerЯпГЬДІгкзшШћЃЌетбљЧсПьЕФвЕЮёТпМвВБиаыХХЖгЃЌПЩФмЛсЗЂЩњМЂЖіЁЃШчЙћReaderЪеМЏЕФЧыЧѓЖгСаГЄЪБМфДІгкТњЕФзДЬЌЃЌећИіЭЈбЖБиШЛЖёЛЏЃЌЫљвдетЪЧЕфаЭЕФашвЊНЕЕЭЯьгІЪБМфЁЂЬсЩ§ЭЬЭТСПЕФИпВЂЗЂЪБПЬЃЌетИіЪБПЬЕФЩЯЯТЮФЧаЛЛЪЧБиаыЕФЃЌВЛОРНсЃЌВЂЗЂЮЊжиЁЃResponderЪЧЕЅЯпГЬЃЌЯдШЛЃЌResponderЛсБШНЯЧсЫЩЃЌвђЮЊЫфШЛЧыЧѓКмЖрЃЌЕЋОЙ§Reader->HandlerЕФЛКГхКЭHandlerЕФДІРэЃЌЩЯвЛХњФмЗЂЫЭЭъЕФНсЙћвбОЗЂЫЭСЫЁЃResponderИќЖрЕФЪЧЫбМЏВЂДІРэФЧаЉГЄНсЙћЃЌВЂЭЈЙ§ИпаЇselectФЃЪНРДЛёШЁНсЙћВЂЗЂЫЭЁЃ
етРяЃЌHandlerдквЕЮёТпМЕїгУЭъБЯжБНгЕїгУСЫresponder.doRespondЗЂЫЭЃЌЪЧвђЮЊетЪЧИіСЂМДЗЕЛиЕФЕїгУЃЌетИіЕїгУЕФКФЪБЪЧКмЩйЕФЃЌЫљвдВЛБиШУHandlerвђЮЊЗЂЫЭЖјзшШћЃЌНјвЛВНГфЗжЗЂЛгСЫHandlerЖрЯпГЬЕФФмСІЃЌМѕЩйСЫЯпГЬЧаЛЛЕФЛњЛсЃЌЧПЕїСЫЦфЖрЯпГЬВЂЗЂЕФгХЪЦЃЌЭЌЪБгжЮЊresponderМѕИКЃЌвддіЧПResponderЕЅЯпГЬзїеНЕФаХаФЁЃ
4.ЙигкЫј
ЖдHadoopРДНВЃЌвђЮЊЭЌВНашЧѓЃЌЫљвдМгЫјЪЧБиВЛПЩЩйЕФЁЃадФмЪЧашвЊПМТЧЃЌЕЋЪЧДгЙЄГЬЕФНЧЖШЩЯРДПДЃЌЭЈбЖВуЕФЮШЖЈадЁЂДњТыПЩЮЌЛЄадЁЂБЃГжДњТыНсЙЙЕФЯрЖдМђЕЅадЃЈЦфДњТывђРњЪЗдвђвбЗЧГЃИДдгЃЉЃЌДѓВПЗжВЩгУСЫsynchronizedетжжБЏЙлЕУЁЂжиаЭЕФМгЫјЗНЪНЃЌетбљЃЌПЩвдЯджјМѕЩйЖдЯѓжЎМфЭЌВНЕФИДдгадЃЌМѕЩйДэЮѓЕФЗЂЩњЁЃ
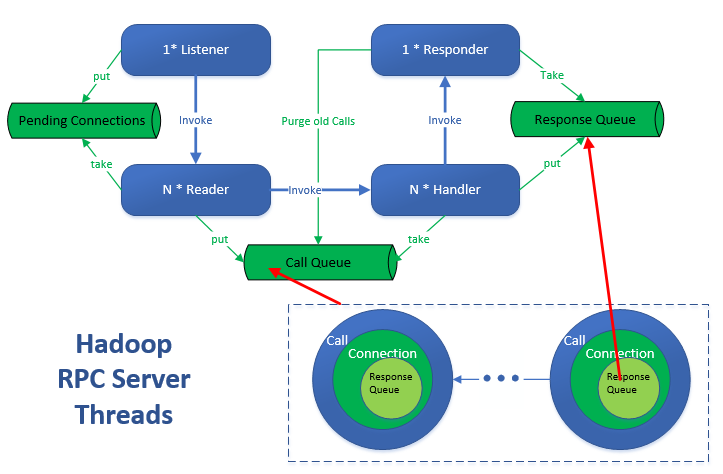
СљЁЂЃЈВЙГфЃЉRpcServer ЯпГЬФЃаЭ
NameNodeЦєЖЏЙ§ГЬЃК
ЯпГЬФЃаЭ
Listener 1ИіЃК
1.МрЬ§ВЂНгЪмРДздПЭЛЇЖЫЕФСЌНг.НЋаТНЈСЌНгЗХШыpendingConnections.
2.ЧхРэПеЯаСЌНг.
3.ЛНабReader.
Reader NИі : ДгpendingConnectionsжаЛёШЁСЌНгЃЌЖСШЁЪ§ОнЃЌДгRpcRequestЙЙдьCallЃЌВЂЗХШыcallQueue.
Handler N ИіЃК
1.ДгcallQueueЛёШЁПЭЛЇЖЫЕїгУcallЃЌВЂжДаа.
2.ЕїгУResponderЃЌНЋНсЙћМгШыresponseQueueЕФЮВВП.етРяЛсЕїгУвЛДЮЗЂЫЭ.ШчЙћЪ§ОнЮДЗЂЫЭЭъЃЌзЂВсWRITEЪТМўЕНselector.ВЂЛНабResponder.
Responder 1ИіЃК
1.ДгresponseQueueжаАДееFIFOЫГађЗЂЫЭЪ§Он.
2.ДІРэselector selectГіЕФЪ§Он.
3.ЩЈУшcallQueue,ВЂЖЊЦњЙ§ЦкЕФCall.
|









