|
KafkaМђНщ
KafkaЪЧвЛжжЗжВМЪНЕФЃЌЛљгкЗЂВМ/ЖЉдФЕФЯћЯЂЯЕЭГЁЃжївЊЩшМЦФПБъШчЯТЃК
вдЪБМфИДдгЖШЮЊO(1)ЕФЗНЪНЬсЙЉЯћЯЂГжОУЛЏФмСІЃЌВЂБЃжЄМДЪЙЖдTBМЖвдЩЯЪ§ОнвВФмБЃжЄГЃЪ§ЪБМфЕФЗУЮЪадФм
ИпЭЬЭТТЪЁЃМДЪЙдкЗЧГЃСЎМлЕФЩЬгУЛњЦїЩЯвВФмзіЕНЕЅЛњжЇГжУПУы100KЬѕЯћЯЂЕФДЋЪф
жЇГжKafka ServerМфЕФЯћЯЂЗжЧјЃЌМАЗжВМЪНЯћЯЂЯћЗбЃЌЭЌЪББЃжЄУПИіpartitionФкЕФЯћЯЂЫГађДЋЪф
ЭЌЪБжЇГжРыЯпЪ§ОнДІРэКЭЪЕЪБЪ§ОнДІРэ
ЮЊЪВУДвЊгУMessage Queue
Нтёю
дкЯюФПЦєЖЏжЎГѕРДдЄВтНЋРДЯюФПЛсХіЕНЪВУДашЧѓЃЌЪЧМЋЦфРЇФбЕФЁЃЯћЯЂЖгСадкДІРэЙ§ГЬжаМфВхШыСЫвЛИівўКЌЕФЁЂЛљгкЪ§ОнЕФНгПкВуЃЌСНБпЕФДІРэЙ§ГЬЖМвЊЪЕЯжетвЛНгПкЁЃетдЪаэФуЖРСЂЕФРЉеЙЛђаоИФСНБпЕФДІРэЙ§ГЬЃЌжЛвЊШЗБЃЫќУЧзёЪиЭЌбљЕФНгПкдМЪј
Шпгр
гаЪБдкДІРэЪ§ОнЕФЪБКђДІРэЙ§ГЬЛсЪЇАмЁЃГ§ЗЧЪ§ОнБЛГжОУЛЏЃЌЗёдђНЋгРдЖЖЊЪЇЁЃЯћЯЂЖгСаАбЪ§ОнНјааГжОУЛЏжБЕНЫќУЧвбОБЛЭъШЋДІРэЃЌЭЈЙ§етвЛЗНЪНЙцБмСЫЪ§ОнЖЊЪЇЗчЯеЁЃдкБЛаэЖрЯћЯЂЖгСаЫљВЩгУЕФЁБВхШы-ЛёШЁ-ЩОГ§ЁБЗЖЪНжаЃЌдкАбвЛИіЯћЯЂДгЖгСажаЩОГ§жЎЧАЃЌашвЊФуЕФДІРэЙ§ГЬУїШЗЕФжИГіИУЯћЯЂвбОБЛДІРэЭъБЯЃЌШЗБЃФуЕФЪ§ОнБЛАВШЋЕФБЃДцжБЕНФуЪЙгУЭъБЯЁЃ
РЉеЙад
вђЮЊЯћЯЂЖгСаНтёюСЫФуЕФДІРэЙ§ГЬЃЌЫљвддіДѓЯћЯЂШыЖгКЭДІРэЕФЦЕТЪЪЧКмШнвзЕФЃЛжЛвЊСэЭтдіМгДІРэЙ§ГЬМДПЩЁЃВЛашвЊИФБфДњТыЁЂВЛашвЊЕїНкВЮЪ§ЁЃРЉеЙОЭЯёЕїДѓЕчСІАДХЅвЛбљМђЕЅЁЃ
СщЛюад
& ЗхжЕДІРэФмСІ дкЗУЮЪСПОчдіЕФЧщПіЯТЃЌгІгУШдШЛашвЊМЬајЗЂЛгзїгУЃЌЕЋЪЧетбљЕФЭЛЗЂСїСПВЂВЛГЃМћЃЛШчЙћЮЊвдФмДІРэетРрЗхжЕЗУЮЪЮЊБъзМРДЭЖШызЪдДЫцЪБД§УќЮовЩЪЧОоДѓЕФРЫЗбЁЃЪЙгУЯћЯЂЖгСаФмЙЛЪЙЙиМќзщМўЖЅзЁдіГЄЕФЗУЮЪбЙСІЃЌЖјВЛЪЧвђЮЊГЌГіИККЩЕФЧыЧѓЖјЭъШЋБРРЃЁЃ
ПЩЛжИДад
ЕБЬхЯЕЕФвЛВПЗжзщМўЪЇаЇЃЌВЛЛсгАЯьЕНећИіЯЕЭГЁЃЯћЯЂЖгСаНЕЕЭСЫНјГЬМфЕФёюКЯЖШЃЌЫљвдМДЪЙвЛИіДІРэЯћЯЂЕФНјГЬЙвЕєЃЌМгШыЖгСажаЕФЯћЯЂШдШЛПЩвддкЯЕЭГЛжИДКѓБЛДІРэЁЃЖјетжждЪаэжиЪдЛђепбгКѓДІРэЧыЧѓЕФФмСІЭЈГЃЪЧдьОЭвЛИіТдИаВЛБуЕФгУЛЇКЭвЛИіОкЩЅЭИЖЅЕФгУЛЇжЎМфЕФЧјБ№ЁЃ
ЫЭДяБЃжЄ
ЯћЯЂЖгСаЬсЙЉЕФШпгрЛњжЦБЃжЄСЫЯћЯЂФмБЛЪЕМЪЕФДІРэЃЌжЛвЊвЛИіНјГЬЖСШЁСЫИУЖгСаМДПЩЁЃдкДЫЛљДЁЩЯЃЌIronMQЬсЙЉСЫвЛИіЁБжЛЫЭДявЛДЮЁББЃжЄЁЃЮоТлгаЖрЩйНјГЬдкДгЖгСажаСьШЁЪ§ОнЃЌУПвЛИіЯћЯЂжЛФмБЛДІРэвЛДЮЁЃетжЎЫљвдГЩЮЊПЩФмЃЌЪЧвђЮЊЛёШЁвЛИіЯћЯЂжЛЪЧЁБдЄЖЈЁБСЫетИіЯћЯЂЃЌднЪБАбЫќвЦГіСЫЖгСаЁЃГ§ЗЧПЭЛЇЖЫУїШЗЕФБэЪОвбОДІРэЭъСЫетИіЯћЯЂЃЌЗёдђетИіЯћЯЂЛсБЛЗХЛиЖгСажаШЅЃЌдквЛЖЮПЩХфжУЕФЪБМфжЎКѓПЩдйДЮБЛДІРэЁЃ
ЫГађБЃжЄ
дкаэЖрЧщПіЯТЃЌЪ§ОнДІРэЕФЫГађЖМКмживЊЁЃЯћЯЂЖгСаБОРДОЭЪЧХХађЕФЃЌВЂЧвФмБЃжЄЪ§ОнЛсАДееЬиЖЈЕФЫГађРДДІРэЁЃIronMOБЃжЄЯћЯЂНЌК§ЭЈЙ§FIFOЃЈЯШНјЯШГіЃЉЕФЫГађРДДІРэЃЌвђДЫЯћЯЂдкЖгСажаЕФЮЛжУОЭЪЧДгЖгСажаМьЫїЫћУЧЕФЮЛжУЁЃ
ЛКГх
дкШЮКЮживЊЕФЯЕЭГжаЃЌЖМЛсгаашвЊВЛЭЌЕФДІРэЪБМфЕФдЊЫиЁЃР§Шч,МгдивЛеХЭМЦЌБШгІгУЙ§ТЫЦїЛЈЗбИќЩйЕФЪБМфЁЃЯћЯЂЖгСаЭЈЙ§вЛИіЛКГхВуРДАяжњШЮЮёзюИпаЇТЪЕФжДааЁЊаДШыЖгСаЕФДІРэЛсОЁПЩФмЕФПьЫйЃЌЖјВЛЪмДгЖгСаЖСЕФдЄБИДІРэЕФдМЪјЁЃИУЛКГхгажњгкПижЦКЭгХЛЏЪ§ОнСїОЙ§ЯЕЭГЕФЫйЖШЁЃ
РэНтЪ§ОнСї
дквЛИіЗжВМЪНЯЕЭГРяЃЌвЊЕУЕНвЛИіЙигкгУЛЇВйзїЛсгУЖрГЄЪБМфМАЦфдвђЕФзмЬхгЁЯѓЃЌЪЧИіОоДѓЕФЬєеНЁЃЯћЯЂЯЕСаЭЈЙ§ЯћЯЂБЛДІРэЕФЦЕТЪЃЌРДЗНБуЕФИЈжњШЗЖЈФЧаЉБэЯжВЛМбЕФДІРэЙ§ГЬЛђСьгђЃЌетаЉЕиЗНЕФЪ§ОнСїЖМВЛЙЛгХЛЏЁЃ
вьВНЭЈаХ
КмЖрЪБКђЃЌФуВЛЯывВВЛашвЊСЂМДДІРэЯћЯЂЁЃЯћЯЂЖгСаЬсЙЉСЫвьВНДІРэЛњжЦЃЌдЪаэФуАбвЛИіЯћЯЂЗХШыЖгСаЃЌЕЋВЂВЛСЂМДДІРэЫќЁЃФуЯыЯђЖгСажаЗХШыЖрЩйЯћЯЂОЭЗХЖрЩйЃЌШЛКѓдкФуРжвтЕФЪБКђдйШЅДІРэЫќУЧЁЃ
ГЃгУMessage QueueЖдБШ
RabbitMQ
RabbitMQЪЧЪЙгУErlangБраДЕФвЛИіПЊдДЕФЯћЯЂЖгСаЃЌБОЩэжЇГжКмЖрЕФавщЃКAMQPЃЌXMPP,
SMTP, STOMPЃЌвВе§вђШчДЫЃЌЫќЗЧГЃжиСПМЖЃЌИќЪЪКЯгкЦѓвЕМЖЕФПЊЗЂЁЃЭЌЪБЪЕЯжСЫBrokerЙЙМмЃЌетвтЮЖзХЯћЯЂдкЗЂЫЭИјПЭЛЇЖЫЪБЯШдкжааФЖгСаХХЖгЁЃЖдТЗгЩЃЌИКдиОљКтЛђепЪ§ОнГжОУЛЏЖМгаКмКУЕФжЇГжЁЃ
Redis
RedisЪЧвЛИіЛљгкKey-ValueЖдЕФNoSQLЪ§ОнПтЃЌПЊЗЂЮЌЛЄКмЛюдОЁЃЫфШЛЫќЪЧвЛИіKey-ValueЪ§ОнПтДцДЂЯЕЭГЃЌЕЋЫќБОЩэжЇГжMQЙІФмЃЌЫљвдЭъШЋПЩвдЕБзівЛИіЧсСПМЖЕФЖгСаЗўЮёРДЪЙгУЁЃЖдгкRabbitMQКЭRedisЕФШыЖгКЭГіЖгВйзїЃЌИїжДаа100ЭђДЮЃЌУП10ЭђДЮМЧТМвЛДЮжДааЪБМфЁЃВтЪдЪ§ОнЗжЮЊ128BytesЁЂ512BytesЁЂ1KКЭ10KЫФИіВЛЭЌДѓаЁЕФЪ§ОнЁЃЪЕбщБэУїЃКШыЖгЪБЃЌЕБЪ§ОнБШНЯаЁЪБRedisЕФадФмвЊИпгкRabbitMQЃЌЖјШчЙћЪ§ОнДѓаЁГЌЙ§СЫ10KЃЌRedisдђТ§ЕФЮоЗЈШЬЪмЃЛГіЖгЪБЃЌЮоТлЪ§ОнДѓаЁЃЌRedisЖМБэЯжГіЗЧГЃКУЕФадФмЃЌЖјRabbitMQЕФГіЖгадФмдђдЖЕЭгкRedisЁЃ
ZeroMQ
ZeroMQКХГЦзюПьЕФЯћЯЂЖгСаЯЕЭГЃЌгШЦфеыЖдДѓЭЬЭТСПЕФашЧѓГЁОАЁЃZMQФмЙЛЪЕЯжRabbitMQВЛЩУГЄЕФИпМЖ/ИДдгЕФЖгСаЃЌЕЋЪЧПЊЗЂШЫдБашвЊздМКзщКЯЖржжММЪѕПђМмЃЌММЪѕЩЯЕФИДдгЖШЪЧЖдетMQФмЙЛгІгУГЩЙІЕФЬєеНЁЃZeroMQОпгавЛИіЖРЬиЕФЗЧжаМфМўЕФФЃЪНЃЌФуВЛашвЊАВзАКЭдЫаавЛИіЯћЯЂЗўЮёЦїЛђжаМфМўЃЌвђЮЊФуЕФгІгУГЬађНЋАчбнСЫетИіЗўЮёНЧЩЋЁЃФужЛашвЊМђЕЅЕФв§гУZeroMQГЬађПтЃЌПЩвдЪЙгУNuGetАВзАЃЌШЛКѓФуОЭПЩвдгфПьЕФдкгІгУГЬађжЎМфЗЂЫЭЯћЯЂСЫЁЃЕЋЪЧZeroMQНіЬсЙЉЗЧГжОУадЕФЖгСаЃЌвВОЭЪЧЫЕШчЙћdownЛњЃЌЪ§ОнНЋЛсЖЊЪЇЁЃЦфжаЃЌTwitterЕФStormжаФЌШЯЪЙгУZeroMQзїЮЊЪ§ОнСїЕФДЋЪфЁЃ
ActiveMQ
ActiveMQЪЧApacheЯТЕФвЛИізгЯюФПЁЃ РрЫЦгкZeroMQЃЌЫќФмЙЛвдДњРэШЫКЭЕуЖдЕуЕФММЪѕЪЕЯжЖгСаЁЃЭЌЪБРрЫЦгкRabbitMQЃЌЫќЩйСПДњТыОЭПЩвдИпаЇЕиЪЕЯжИпМЖгІгУГЁОАЁЃ
Kafka/Jafka
KafkaЪЧApacheЯТЕФвЛИізгЯюФПЃЌЪЧвЛИіИпадФмПчгябдЗжВМЪНPublish/SubscribeЯћЯЂЖгСаЯЕЭГЃЌЖјJafkaЪЧдкKafkaжЎЩЯЗѕЛЏЖјРДЕФЃЌМДKafkaЕФвЛИіЩ§МЖАцЁЃОпгавдЯТЬиадЃКПьЫйГжОУЛЏЃЌПЩвддкO(1)ЕФЯЕЭГПЊЯњЯТНјааЯћЯЂГжОУЛЏЃЛИпЭЬЭТЃЌдквЛЬЈЦеЭЈЕФЗўЮёЦїЩЯМШПЩвдДяЕН10W/sЕФЭЬЭТЫйТЪЃЛЭъШЋЕФЗжВМЪНЯЕЭГЃЌBrokerЁЂProducerЁЂConsumerЖМдЩњздЖЏжЇГжЗжВМЪНЃЌздЖЏЪЕЯжИДдгОљКтЃЛжЇГжHadoopЪ§ОнВЂааМгдиЃЌЖдгкЯёHadoopЕФвЛбљЕФШежОЪ§ОнКЭРыЯпЗжЮіЯЕЭГЃЌЕЋгжвЊЧѓЪЕЪБДІРэЕФЯожЦЃЌетЪЧвЛИіПЩааЕФНтОіЗНАИЁЃKafkaЭЈЙ§HadoopЕФВЂааМгдиЛњжЦРДЭГвЛСЫдкЯпКЭРыЯпЕФЯћЯЂДІРэЃЌетвЛЕувВЪЧБОПЮЬтЫљбаОПЯЕЭГЫљПДжиЕФЁЃApache
KafkaЯрЖдгкActiveMQЪЧвЛИіЗЧГЃЧсСПМЖЕФЯћЯЂЯЕЭГЃЌГ§СЫадФмЗЧГЃКУжЎЭтЃЌЛЙЪЧвЛИіЙЄзїСМКУЕФЗжВМЪНЯЕЭГЁЃ
KafkaНтЮі
Terminology
Broker
KafkaМЏШКАќКЌвЛИіЛђЖрИіЗўЮёЦїЃЌетжжЗўЮёЦїБЛГЦЮЊbroker
Topic
УПЬѕЗЂВМЕНKafkaМЏШКЕФЯћЯЂЖМгавЛИіРрБ№ЃЌетИіРрБ№БЛГЦЮЊtopicЁЃЃЈЮяРэЩЯВЛЭЌtopicЕФЯћЯЂЗжПЊДцДЂЃЌТпМЩЯвЛИіtopicЕФЯћЯЂЫфШЛБЃДцгквЛИіЛђЖрИіbrokerЩЯЕЋгУЛЇжЛашжИЖЈЯћЯЂЕФtopicМДПЩЩњВњЛђЯћЗбЪ§ОнЖјВЛБиЙиаФЪ§ОнДцгкКЮДІЃЉ
Partition
paritionЪЧЮяРэЩЯЕФИХФюЃЌУПИіtopicАќКЌвЛИіЛђЖрИіpartitionЃЌДДНЈtopicЪБПЩжИЖЈparitionЪ§СПЁЃУПИіpartitionЖдгІгквЛИіЮФМўМаЃЌИУЮФМўМаЯТДцДЂИУpartitionЕФЪ§ОнКЭЫїв§ЮФМў
Producer
ИКд№ЗЂВМЯћЯЂЕНKafka broker
Consumer
ЯћЗбЯћЯЂЁЃУПИіconsumerЪєгквЛИіЬиЖЈЕФconsuer groupЃЈПЩЮЊУПИіconsumerжИЖЈgroup
nameЃЌШєВЛжИЖЈgroup nameдђЪєгкФЌШЯЕФgroupЃЉЁЃЪЙгУconsumer high level
APIЪБЃЌЭЌвЛtopicЕФвЛЬѕЯћЯЂжЛФмБЛЭЌвЛИіconsumer groupФкЕФвЛИіconsumerЯћЗбЃЌЕЋЖрИіconsumer
groupПЩЭЌЪБЯћЗбетвЛЯћЯЂЁЃ
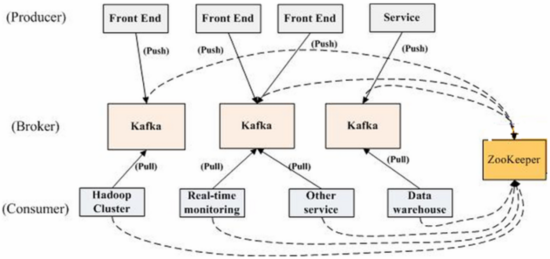
KafkaМмЙЙШчЩЯЭМЫљЪОЃЌвЛИіЕфаЭЕФkafkaМЏШКжаАќКЌШєИЩproducerЃЈПЩвдЪЧwebЧАЖЫВњЩњЕФpage
viewЃЌЛђепЪЧЗўЮёЦїШежОЃЌЯЕЭГCPUЁЂmemoryЕШЃЉЃЌШєИЩbrokerЃЈKafkaжЇГжЫЎЦНРЉеЙЃЌвЛАуbrokerЪ§СПдНЖрЃЌМЏШКЭЬЭТТЪдНИпЃЉЃЌШєИЩconsumer
groupЃЌвдМАвЛИі Zookeeper МЏШКЁЃKafkaЭЈЙ§ZookeeperЙмРэМЏШКХфжУЃЌбЁОйleaderЃЌвдМАдкconsumer
groupЗЂЩњБфЛЏЪБНјааrebalanceЁЃproducerЪЙгУpushФЃЪННЋЯћЯЂЗЂВМЕНbrokerЃЌconsumerЪЙгУpullФЃЪНДгbrokerЖЉдФВЂЯћЗбЯћЯЂЁЃ
Push vs. Pull
зїЮЊвЛИіmessaging systemЃЌKafkaзёбСЫДЋЭГЕФЗНЪНЃЌбЁдёгЩproducerЯђbroker
pushЯћЯЂВЂгЩconsumerДгbroker pullЯћЯЂЁЃвЛаЉlogging-centric systemЃЌБШШчFacebookЕФ
Scribe КЭClouderaЕФFlume ,ВЩгУЗЧГЃВЛЭЌЕФpushФЃЪНЁЃЪТЪЕЩЯЃЌpushФЃЪНКЭpullФЃЪНИїгагХСгЁЃ
pushФЃЪНКмФбЪЪгІЯћЗбЫйТЪВЛЭЌЕФЯћЗбепЃЌвђЮЊЯћЯЂЗЂЫЭЫйТЪЪЧгЩbrokerОіЖЈЕФЁЃpushФЃЪНЕФФПБъЪЧОЁПЩФмвдзюПьЫйЖШДЋЕнЯћЯЂЃЌЕЋЪЧетбљКмШнвздьГЩconsumerРДВЛМАДІРэЯћЯЂЃЌЕфаЭЕФБэЯжОЭЪЧОмОјЗўЮёвдМАЭјТчгЕШћЁЃЖјpullФЃЪНдђПЩвдИљОнconsumerЕФЯћЗбФмСІвдЪЪЕБЕФЫйТЪЯћЗбЯћЯЂЁЃ
Topic & Partition
TopicдкТпМЩЯПЩвдБЛШЯЮЊЪЧвЛИідкЕФqueueЃЌУПЬѕЯћЗбЖМБиаыжИЖЈЫќЕФtopicЃЌПЩвдМђЕЅРэНтЮЊБиаыжИУїАбетЬѕЯћЯЂЗХНјФФИіqueueРяЁЃЮЊСЫЪЙЕУKafkaЕФЭЬЭТТЪПЩвдЫЎЦНРЉеЙЃЌЮяРэЩЯАбtopicЗжГЩвЛИіЛђЖрИіpartitionЃЌУПИіpartitionдкЮяРэЩЯЖдгІвЛИіЮФМўМаЃЌИУЮФМўМаЯТДцДЂетИіpartitionЕФЫљгаЯћЯЂКЭЫїв§ЮФМўЁЃ
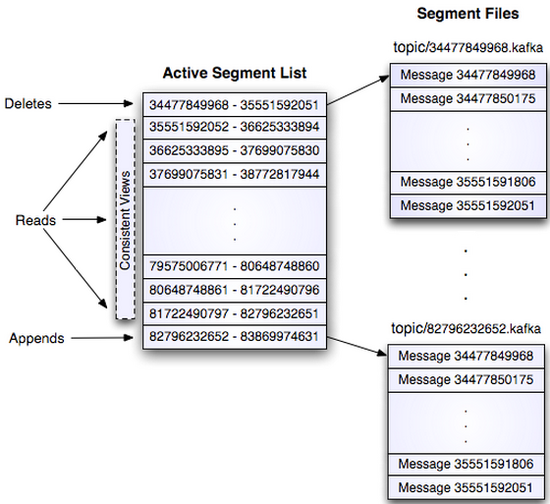
УПИіШежОЮФМўЖМЪЧЁАlog entriesЁБађСаЃЌУПвЛИі log entry
АќКЌвЛИі4зжНкећаЭЪ§ЃЈжЕЮЊNЃЉЃЌЦфКѓИњNИізжНкЕФЯћЯЂЬхЁЃУПЬѕЯћЯЂЖМгавЛИіЕБЧАpartitionЯТЮЈвЛЕФ64зжНкЕФoffsetЃЌЫќжИУїСЫетЬѕЯћЯЂЕФЦ№ЪМЮЛжУЁЃДХХЬЩЯДцДЂЕФЯћЗбИёЪНШчЯТЃК
message length ЃК 4 bytes (value: 1+4+n)
ЁАmagicЁБ value ЃК 1 byte
crc ЃК 4 bytes
payload ЃК n bytes
етИіЁАlog entriesЁБВЂЗЧгЩвЛИіЮФМўЙЙГЩЃЌЖјЪЧЗжГЩЖрИіsegmentЃЌУПИіsegmentУћЮЊИУsegmentЕквЛЬѕЯћЯЂЕФoffsetКЭЁА.kafkaЁБзщГЩЁЃСэЭтЛсгавЛИіЫїв§ЮФМўЃЌЫќБъУїСЫУПИіsegmentЯТАќКЌЕФ
log entry ЕФoffsetЗЖЮЇЃЌШчЯТЭМЫљЪОЁЃ
вђЮЊУПЬѕЯћЯЂЖМБЛappendЕНИУpartitionжаЃЌЪЧЫГађаДДХХЬЃЌвђДЫаЇТЪЗЧГЃИпЃЈОбщжЄЃЌЫГађаДДХХЬаЇТЪБШЫцЛњаДФкДцЛЙвЊИпЃЌетЪЧKafkaИпЭЬЭТТЪЕФвЛИіКмживЊЕФБЃжЄЃЉЁЃ
УПвЛЬѕЯћЯЂБЛЗЂЫЭЕНbrokerЪБЃЌЛсИљОнparititionЙцдђбЁдёБЛДцДЂЕНФФвЛИіpartitionЁЃШчЙћpartitionЙцдђЩшжУЕФКЯРэЃЌЫљгаЯћЯЂПЩвдОљдШЗжВМЕНВЛЭЌЕФpartitionРяЃЌетбљОЭЪЕЯжСЫЫЎЦНРЉеЙЁЃЃЈШчЙћвЛИіtopicЖдгІвЛИіЮФМўЃЌФЧетИіЮФМўЫљдкЕФЛњЦїI/OНЋЛсГЩЮЊетИіtopicЕФадФмЦПОБЃЌЖјpartitionНтОіСЫетИіЮЪЬтЃЉЁЃдкДДНЈtopicЪБПЩвддк
$KAFKA_HOME/config/server.propertiesжажИЖЈетИіpartitionЕФЪ§СП(ШчЯТЫљЪО)ЃЌЕБШЛвВПЩвддкtopicДДНЈжЎКѓШЅаоИФparitionЪ§СПЁЃ

дкЗЂЫЭвЛЬѕЯћЯЂЪБЃЌПЩвджИЖЈетЬѕЯћЯЂЕФkeyЃЌproducerИљОнетИіkeyКЭpartitionЛњжЦРДХаЖЯНЋетЬѕЯћЯЂЗЂЫЭЕНФФИіparitionЁЃparititionЛњжЦПЩвдЭЈЙ§жИЖЈ
producer ЕФ paritition . class етвЛВЮЪ§РДжИЖЈЃЌИУclassБиаыЪЕЯж kafka
. producer . Partitioner НгПкЁЃБОР§жаШчЙћkeyПЩвдБЛНтЮіЮЊећЪ§дђНЋЖдгІЕФећЪ§гыpartitionзмЪ§ШЁгрЃЌИУЯћЯЂЛсБЛЗЂЫЭЕНИУЪ§ЖдгІЕФpartitionЁЃЃЈУПИіparitionЖМЛсгаИіађКХЃЉ
| import
kafka.producer.Partitioner;import kafka.utils.
VerifiableProperties;public
class JasonPartitioner<T>
implements Partitioner
{ public JasonPartitioner(Ver
ifiableProperties
verifiableProperties) {} @Override
public int partition(Object
key, int numPartitions)
{ try { int partitionNum
= Integer.parseInt((String)
key); return Math.abs(Integer.parseInt((String)
key)
% numPartitions);
} catch (Exception e) { return Math.
abs(key.hashCode()
% numPartitions); } }}
|
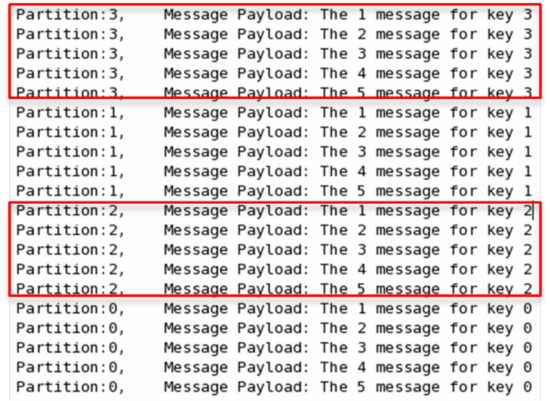
ШчЙћНЋЩЯР§жаЕФclassзїЮЊpartition.classЃЌВЂЭЈЙ§ШчЯТДњТыЗЂЫЭ20ЬѕЯћЯЂЃЈkeyЗжБ№ЮЊ0ЃЌ1ЃЌ2ЃЌ3ЃЉжСtopic2ЃЈАќКЌ4ИіpartitionЃЉЁЃ
| public
void sendMessage() throws InterruptedException{ЁЁ
ЁЁfor(int i = 1;
i <= 5; i++){ЁЁЁЁ List messageList = new
ArrayList<KeyedMessage<String,
String>>();ЁЁЁЁ for(int j = 0; j < 4;
j++ЃЉ{ЁЁЁЁ messageList.add(new KeyedMessage<String,
String>("topic2",
j+"",
"The " + i + " message for key
" + j));ЁЁЁЁ }ЁЁЁЁ producer.send(messageList);
}ЁЁЁЁproducer.close();}
|
дђkeyЯрЭЌЕФЯћЯЂЛсБЛЗЂЫЭВЂДцДЂЕНЭЌвЛИіpartitionРяЃЌЖјЧвkeyЕФађКХе§КУКЭpartitionађКХЯрЭЌЁЃЃЈpartitionађКХДг0ПЊЪМЃЌБОР§жаЕФkeyвВе§КУДг0ПЊЪМЃЉЁЃШчЯТЭМЫљЪОЁЃ
ЖдгкДЋЭГЕФmessage queueЖјбдЃЌвЛАуЛсЩОГ§вбОБЛЯћЗбЕФЯћЯЂЃЌЖјKafkaМЏШКЛсБЃСєЫљгаЕФЯћЯЂЃЌЮоТлЦфБЛЯћЗбгыЗёЁЃЕБШЛЃЌвђЮЊДХХЬЯожЦЃЌВЛПЩФмгРОУБЃСєЫљгаЪ§ОнЃЈЪЕМЪЩЯвВУЛБивЊЃЉЃЌвђДЫKafkaЬсЙЉСНжжВпТдШЅЩОГ§ОЩЪ§ОнЁЃвЛЪЧЛљгкЪБМфЃЌЖўЪЧЛљгкpartitionЮФМўДѓаЁЁЃР§ШчПЩвдЭЈЙ§ХфжУ
$KAFKA_HOME / config / server . properties ЃЌШУ Kafka
ЩОГ§вЛжмЧАЕФЪ§ОнЃЌвВПЩЭЈЙ§ХфжУШУ Kafka дк partition ЮФМўГЌЙ§1GBЪБЩОГ§ОЩЪ§ОнЃЌШчЯТЫљЪОЁЃ

етРявЊзЂвтЃЌвђЮЊKafkaЖСШЁЬиЖЈЯћЯЂЕФЪБМфИДдгЖШЮЊO(1)ЃЌМДгыЮФМўДѓаЁЮоЙиЃЌЫљвдетРяЩОГ§ЮФМўгыKafkaадФмЮоЙиЃЌбЁдёдѕбљЕФЩОГ§ВпТджЛгыДХХЬвдМАОпЬхЕФашЧѓгаЙиЁЃСэЭтЃЌKafkaЛсЮЊУПвЛИіconsumer
groupБЃСєвЛаЉmetadataаХЯЂЁЊЕБЧАЯћЗбЕФЯћЯЂЕФpositionЃЌвВМДoffsetЁЃетИіoffsetгЩconsumerПижЦЁЃе§ГЃЧщПіЯТconsumerЛсдкЯћЗбЭъвЛЬѕЯћЯЂКѓЯпаддіМгетИіoffsetЁЃЕБШЛЃЌconsumerвВПЩНЋoffsetЩшГЩвЛИіНЯаЁЕФжЕЃЌжиаТЯћЗбвЛаЉЯћЯЂЁЃвђЮЊoffetгЩconsumerПижЦЃЌЫљвдKafka
brokerЪЧЮозДЬЌЕФЃЌЫќВЛашвЊБъМЧФФаЉЯћЯЂБЛФФаЉconsumerЙ§ЃЌВЛашвЊЭЈЙ§brokerШЅБЃжЄЭЌвЛИіconsumer
groupжЛгавЛИіconsumerФмЯћЗбФГвЛЬѕЯћЯЂЃЌвђДЫвВОЭВЛашвЊЫјЛњжЦЃЌетвВЮЊKafkaЕФИпЭЬЭТТЪЬсЙЉСЫгаСІБЃеЯЁЃ
Replication & Leader election
KafkaДг0.8ПЊЪМЬсЙЉpartitionМЖБ№ЕФ replicationЃЌreplic$KAFKA_HOME
/ config / server . properties жаХфжУЁЃ
default.replication.factor = 1
ИУ Replicationгыleader electionХфКЯЬсЙЉСЫздЖЏЕФfailoverЛњжЦЁЃreplicationЖдKafkaЕФЭЬЭТТЪЪЧгавЛЖЈгАЯьЕФЃЌЕЋМЋДѓЕФдіЧПСЫПЩгУадЁЃФЌШЯЧщПіЯТЃЌKafkaЕФreplicationЪ§СПЮЊ1ЁЃ
УПИіpartitionЖМгавЛИіЮЈвЛЕФleaderЃЌЫљгаЕФЖСаДВйзїЖМдкleaderЩЯЭъГЩЃЌleaderХњСПДгleaderЩЯpullЪ§ОнЁЃвЛАуЧщПіЯТpartitionЕФЪ§СПДѓгкЕШгкbrokerЕФЪ§СПЃЌВЂЧвЫљгаpartitionЕФleaderОљдШЗжВМдкbrokerЩЯЁЃfollowerЩЯЕФШежОКЭЦфleaderЩЯЕФЭъШЋвЛбљЁЃ
КЭДѓВПЗжЗжВМЪНЯЕЭГвЛбљЃЌKakfaДІРэЪЇАмашвЊУїШЗЖЈвхвЛИіbrokerЪЧЗёaliveЁЃЖдгкKafkaЖјбдЃЌKafkaДцЛюАќКЌСНИіЬѕМўЃЌвЛЪЧЫќБиаыЮЌЛЄгыZookeeperЕФsession(етИіЭЈЙ§ZookeeperЕФheartbeatЛњжЦРДЪЕЯж)ЁЃЖўЪЧfollowerБиаыФмЙЛМАЪБНЋleaderЕФwritingИДжЦЙ§РДЃЌВЛФмЁАТфКѓЬЋЖрЁБЁЃ
leaderЛсtrackЁАin syncЁБЕФnode listЁЃШчЙћвЛИіfollowerхДЛњЃЌЛђепТфКѓЬЋЖрЃЌleaderНЋАбЫќДгЁБin
syncЁБ listжавЦГ§ЁЃетРяЫљУшЪіЕФЁАТфКѓЬЋЖрЁБжИfollowerИДжЦЕФЯћЯЂТфКѓгкleaderКѓЕФЬѕЪ§ГЌЙ§дЄЖЈжЕЃЌИУжЕПЩдк
$KAFKA_HOME/config/server.propertiesжаХфжУ

ашвЊЫЕУїЕФЪЧЃЌKafkaжЛНтОіЁБfail/recoverЁБЃЌВЛДІРэЁАByzantineЁБЃЈЁААнеМЭЅЁБЃЉЮЪЬтЁЃ
вЛЬѕЯћЯЂжЛгаБЛЁАin syncЁБ listРяЕФЫљгаfollowerЖМДгleaderИДжЦЙ§ШЅВХЛсБЛШЯЮЊвбЬсНЛЁЃетбљОЭБмУтСЫВПЗжЪ§ОнБЛаДНјСЫleaderЃЌЛЙУЛРДЕУМАБЛШЮКЮfollowerИДжЦОЭхДЛњСЫЃЌЖјдьГЩЪ§ОнЖЊЪЇЃЈconsumerЮоЗЈЯћЗбетаЉЪ§ОнЃЉЁЃЖјЖдгкproducerЖјбдЃЌЫќПЩвдбЁдёЪЧЗёЕШД§ЯћЯЂcommitЃЌетПЩвдЭЈЙ§
request . required . acks
РДЩшжУЁЃетжжЛњжЦШЗБЃСЫжЛвЊЁАin syncЁБ listгавЛИіЛђвдЩЯЕФflollowerЃЌвЛЬѕБЛcommitЕФЯћЯЂОЭВЛЛсЖЊЪЇЁЃ
етРяЕФИДжЦЛњжЦМДВЛЪЧЭЌВНИДжЦЃЌвВВЛЪЧЕЅДПЕФвьВНИДжЦЁЃЪТЪЕЩЯЃЌЭЌВНИДжЦвЊЧѓЁАЛюзХЕФЁБfollowerЖМИДжЦЭъЃЌетЬѕЯћЯЂВХЛсБЛШЯЮЊcommitЃЌетжжИДжЦЗНЪНМЋДѓЕФгАЯьСЫЭЬЭТТЪЃЈИпЭЬЭТТЪЪЧKafkaЗЧГЃживЊЕФвЛИіЬиадЃЉЁЃЖјвьВНИДжЦЗНЪНЯТЃЌfollowerвьВНЕФДгleaderИДжЦЪ§ОнЃЌЪ§ОнжЛвЊБЛleaderаДШыlogОЭБЛШЯЮЊвбОcommitЃЌетжжЧщПіЯТШчЙћfollwerЖМТфКѓгкleaderЃЌЖјleaderЭЛШЛхДЛњЃЌдђЛсЖЊЪЇЪ§ОнЁЃЖјKafkaЕФетжжЪЙгУЁАin
syncЁБ listЕФЗНЪНдђКмКУЕФОљКтСЫШЗБЃЪ§ОнВЛЖЊЪЇвдМАЭЬЭТТЪЁЃfollowerПЩвдХњСПЕФДгleaderИДжЦЪ§ОнЃЌетбљМЋДѓЕФЬсИпИДжЦадФмЃЈХњСПаДДХХЬЃЉЃЌМЋДѓМѕЩйСЫfollowerгыleaderЕФВюОрЃЈЧАЮФгаЫЕЕНЃЌжЛвЊfollowerТфКѓleaderВЛЬЋдЖЃЌдђБЛШЯЮЊдкЁАin
syncЁБ listРяЃЉЁЃ
ЩЯЮФЫЕУїСЫKafkaЪЧШчКЮзіreplicationЕФЃЌСэЭтвЛИіКмживЊЕФЮЪЬтЪЧЕБleaderхДЛњСЫЃЌдѕбљдкfollowerжабЁОйГіаТЕФleaderЁЃвђЮЊfollowerПЩФмТфКѓаэЖрЛђепcrashСЫЃЌЫљвдБиаыШЗБЃбЁдёЁАзюаТЁБЕФfollowerзїЮЊаТЕФleaderЁЃвЛИіЛљБОЕФддђОЭЪЧЃЌШчЙћleaderВЛдкСЫЃЌаТЕФleaderБиаыгЕгадРДЕФleader
commitЕФЫљгаЯћЯЂЁЃетОЭашвЊзївЛИіелждЃЌШчЙћleaderдкБъУївЛЬѕЯћЯЂБЛcommitЧАЕШД§ИќЖрЕФfollowerШЗШЯЃЌФЧдкЫќdieжЎКѓОЭгаИќЖрЕФfollowerПЩвдзїЮЊаТЕФleaderЃЌЕЋетвВЛсдьГЩЭЬЭТТЪЕФЯТНЕЁЃ
вЛжжЗЧГЃГЃгУЕФбЁОйleaderЕФЗНЪНЪЧЁАmajority СщауЁБЃЈЁАЩйЪ§ЗўДгЖрЪ§ЁБЃЉЃЌЕЋKafkaВЂЮДВЩгУетжжЗНЪНЁЃетжжФЃЪНЯТЃЌШчЙћЮвУЧга2f+1ИіreplicaЃЈАќКЌleaderКЭfollowerЃЉЃЌФЧдкcommitжЎЧАБиаыБЃжЄгаf+1ИіreplicaИДжЦЭъЯћЯЂЃЌЮЊСЫБЃжЄе§ШЗбЁГіаТЕФleaderЃЌfailЕФreplicaВЛФмГЌЙ§fИіЁЃвђЮЊдкЪЃЯТЕФШЮвтf+1ИіreplicaРяЃЌжСЩйгавЛИіreplicaАќКЌгазюаТЕФЫљгаЯћЯЂЁЃетжжЗНЪНгаИіКмДѓЕФгХЪЦЃЌЯЕЭГЕФlatencyжЛШЁОігкзюПьЕФМИЬЈserverЃЌвВОЭЪЧЫЕЃЌШчЙћreplication
factorЪЧ3ЃЌФЧlatencyОЭШЁОігкзюПьЕФФЧИіfollowerЖјЗЧзюТ§ФЧИіЁЃmajority
voteвВгавЛаЉСгЪЦЃЌЮЊСЫБЃжЄleader electionЕФе§ГЃНјааЃЌЫќЫљФмШнШЬЕФfailЕФfollowerИіЪ§БШНЯЩйЁЃШчЙћвЊШнШЬ1ИіfollowerЙвЕєЃЌБиаывЊга3ИівдЩЯЕФreplicaЃЌШчЙћвЊШнШЬ2ИіfollowerЙвЕєЃЌБиаывЊга5ИівдЩЯЕФreplicaЁЃвВОЭЪЧЫЕЃЌдкЩњВњЛЗОГЯТЮЊСЫБЃжЄНЯИпЕФШнДэГЬЖШЃЌБиаывЊгаДѓСПЕФreplicaЃЌЖјДѓСПЕФreplicaгжЛсдкДѓЪ§ОнСПЯТЕМжТадФмЕФМБОчЯТНЕЁЃетОЭЪЧетжжЫуЗЈИќЖргУдк
Zookeeper етжжЙВЯэМЏШКХфжУЕФЯЕЭГжаЖјКмЩйдкашвЊДцДЂДѓСПЪ§ОнЕФЯЕЭГжаЪЙгУЕФдвђЁЃР§ШчHDFSЕФHA
featureЪЧЛљгк majority-vote-based journal ЃЌЕЋЪЧЫќЕФЪ§ОнДцДЂВЂУЛгаЪЙгУетжжexpensiveЕФЗНЪНЁЃ
ЪЕМЪЩЯЃЌleader electionЫуЗЈЗЧГЃЖрЃЌБШШчZookeperЕФ Zab , Raft КЭ
Viewstamped ReplicationЁЃЖјKafkaЫљЪЙгУЕФleader electionЫуЗЈИќЯёЮЂШэЕФ
PacificA ЫуЗЈЁЃ
KafkaдкZookeeperжаЖЏЬЌЮЌЛЄСЫвЛИіISRЃЈin-sync replicasЃЉ setЃЌетИіsetРяЕФЫљгаreplicaЖМИњЩЯСЫleaderЃЌжЛгаISRРяЕФГЩдБВХгаБЛбЁЮЊleaderЕФПЩФмЁЃдкетжжФЃЪНЯТЃЌЖдгкf+1ИіreplicaЃЌвЛИіKafka
topicФмдкБЃжЄВЛЖЊЪЇвбОommitЕФЯћЯЂЕФЧАЬсЯТШнШЬfИіreplicaЕФЪЇАмЁЃдкДѓЖрЪ§ЪЙгУГЁОАжаЃЌетжжФЃЪНЪЧЗЧГЃгаРћЕФЁЃЪТЪЕЩЯЃЌЮЊСЫШнШЬfИіreplicaЕФЪЇАмЃЌmajority
voteКЭISRдкcommitЧАашвЊЕШД§ЕФreplicaЪ§СПЪЧвЛбљЕФЃЌЕЋЪЧISRашвЊЕФзмЕФreplicaЕФИіЪ§МИКѕЪЧmajority
voteЕФвЛАыЁЃ
ЫфШЛmajority voteгыISRЯрБШгаВЛашЕШД§зюТ§ЕФserverетвЛгХЪЦЃЌЕЋЪЧKafkaзїепШЯЮЊKafkaПЩвдЭЈЙ§producerбЁдёЪЧЗёБЛcommitзшШћРДИФЩЦетвЛЮЪЬтЃЌВЂЧвНкЪЁЯТРДЕФreplicaКЭДХХЬЪЙЕУISRФЃЪНШдШЛжЕЕУЁЃ
ЩЯЮФЬсЕНЃЌдкISRжажСЩйгавЛИіfollowerЪБЃЌKafkaПЩвдШЗБЃвбОcommitЕФЪ§ОнВЛЖЊЪЇЃЌЕЋШчЙћФГвЛИіpartitionЕФЫљгаreplicaЖМЙвСЫЃЌОЭЮоЗЈБЃжЄЪ§ОнВЛЖЊЪЇСЫЁЃетжжЧщПіЯТгаСНжжПЩааЕФЗНАИЃК
ЕШД§ISRжаЕФШЮвЛИіreplicaЁАЛюЁБЙ§РДЃЌВЂЧвбЁЫќзїЮЊleader
бЁдёЕквЛИіЁАЛюЁБЙ§РДЕФreplicaЃЈВЛвЛЖЈЪЧISRжаЕФЃЉзїЮЊleader
етОЭашвЊдкПЩгУадКЭвЛжТадЕБжазїГівЛИіМђЕЅЕФЦНКтЁЃШчЙћвЛЖЈвЊЕШД§ISRжаЕФreplicaЁАЛюЁБЙ§РДЃЌФЧВЛПЩгУЕФЪБМфОЭПЩФмЛсЯрЖдНЯГЄЁЃЖјЧвШчЙћISRжаЕФЫљгаreplicaЖМЮоЗЈЁАЛюЁБЙ§РДСЫЃЌЛђепЪ§ОнЖМЖЊЪЇСЫЃЌетИіpartitionНЋгРдЖВЛПЩгУЁЃбЁдёЕквЛИіЁАЛюЁБЙ§РДЕФreplicaзїЮЊleaderЃЌЖјетИіreplicaВЛЪЧISRжаЕФreplicaЃЌФЧМДЪЙЫќВЂВЛБЃжЄвбОАќКЌСЫЫљгавбcommitЕФЯћЯЂЃЌЫќвВЛсГЩЮЊleaderЖјзїЮЊconsumerЕФЪ§ОндДЃЈЧАЮФгаЫЕУїЃЌЫљгаЖСаДЖМгЩleaderЭъГЩЃЉЁЃKafka0.8.ЪЙгУСЫЕкЖўжжЗНЪНЁЃИљОнKafkaЕФЮФЕЕЃЌдквдКѓЕФАцБОжаЃЌKafkaжЇГжгУЛЇЭЈЙ§ХфжУбЁдёетСНжжЗНЪНжаЕФвЛжжЃЌДгЖјИљОнВЛЭЌЕФЪЙгУГЁОАбЁдёИпПЩгУадЛЙЪЧЧПвЛжТадЁЃ
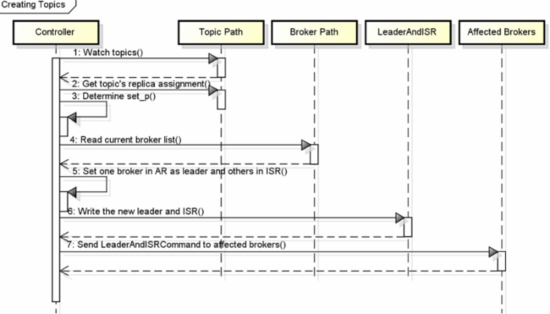
ЩЯЮФЫЕУїСЫвЛИіparitionЕФreplicationЙ§ГЬЃЌШЛЖћKafkaМЏШКашвЊЙмРэГЩАйЩЯЧЇИіpartitionЃЌKafkaЭЈЙ§round-robinЕФЗНЪНРДЦНКтpartitionДгЖјБмУтДѓСПpartitionМЏжадкСЫЩйЪ§МИИіНкЕуЩЯЁЃЭЌЪБKafkaвВашвЊЦНКтleaderЕФЗжВМЃЌОЁПЩФмЕФШУЫљгаpartitionЕФleaderОљдШЗжВМдкВЛЭЌbrokerЩЯЁЃСэвЛЗНУцЃЌгХЛЏleadership
electionЕФЙ§ГЬвВЪЧКмживЊЕФЃЌБЯОЙетЖЮЪБМфЯргІЕФpartitionДІгкВЛПЩгУзДЬЌЁЃвЛжжМђЕЅЕФЪЕЯжЪЧднЭЃхДЛњЕФbrokerЩЯЕФЫљгаpartitionЃЌВЂЮЊжЎбЁОйleaderЁЃЪЕМЪЩЯЃЌKafkaбЁОйвЛИіbrokerзїЮЊcontrollerЃЌетИіcontrollerЭЈЙ§watch
ZookeeperМьВтЫљгаЕФbroker failureЃЌВЂИКд№ЮЊЫљгаЪмгАЯьЕФparitionбЁОйleaderЃЌдйНЋЯргІЕФleaderЕїећУќСюЗЂЫЭжСЪмгАЯьЕФbrokerЃЌЙ§ГЬШчЯТЭМЫљЪОЁЃ

етбљзіЕФКУДІЪЧЃЌПЩвдХњСПЕФЭЈжЊleadershipЕФБфЛЏЃЌДгЖјЪЙЕУбЁОйЙ§ГЬГЩБОИќЕЭЃЌгШЦфЖдДѓСПЕФpartitionЖјбдЁЃШчЙћcontrollerЪЇАмСЫЃЌавДцЕФЫљгаbrokerЖМЛсГЂЪддкZookeeperжаДДНЈ/controller->{this
broker id}ЃЌШчЙћДДНЈГЩЙІЃЈжЛПЩФмгавЛИіДДНЈГЩЙІЃЉЃЌдђИУbrokerЛсГЩЮЊcontrollerЃЌШєДДНЈВЛГЩЙІЃЌдђИУbrokerЛсЕШД§аТcontrollerЕФУќСюЁЃ
ЃЈБОНкЫљгаУшЪіЖМЪЧЛљгкconsumer hight level APIЖјЗЧlow level APIЃЉЁЃ
УПвЛИіconsumerЪЕР§ЖМЪєгквЛИіconsumer groupЃЌУПвЛЬѕЯћЯЂжЛЛсБЛЭЌвЛИіconsumer
groupРяЕФвЛИіconsumerЪЕР§ЯћЗбЁЃЃЈВЛЭЌconsumer groupПЩвдЭЌЪБЯћЗбЭЌвЛЬѕЯћЯЂЃЉ
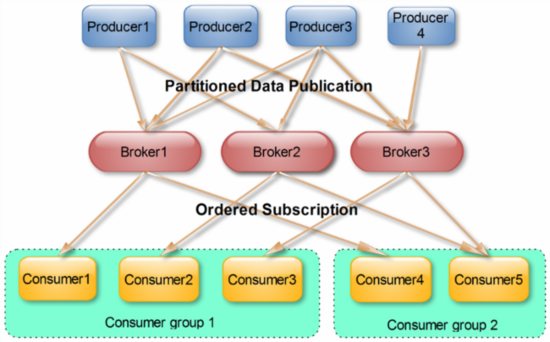
КмЖрДЋЭГЕФmessage queueЖМЛсдкЯћЯЂБЛЯћЗбЭъКѓНЋЯћЯЂЩОГ§ЃЌвЛЗНУцБмУтжиИДЯћЗбЃЌСэвЛЗНУцПЩвдБЃжЄqueueЕФГЄЖШБШНЯЩйЃЌЬсИпаЇТЪЁЃЖјШчЩЯЮФЫљНЋЃЌKafkaВЂВЛЩОГ§вбЯћЗбЕФЯћЯЂЃЌЮЊСЫЪЕЯжДЋЭГmessage
queueЯћЯЂжЛБЛЯћЗбвЛДЮЕФгявхЃЌKafkaБЃжЄБЃжЄЭЌвЛИіconsumer groupРяжЛгавЛИіconsumerЛсЯћЗбвЛЬѕЯћЯЂЁЃгыДЋЭГmessage
queueВЛЭЌЕФЪЧЃЌKafkaЛЙдЪаэВЛЭЌconsumer groupЭЌЪБЯћЗбЭЌвЛЬѕЯћЯЂЃЌетвЛЬиадПЩвдЮЊЯћЯЂЕФЖрдЊЛЏДІРэЬсЙЉСЫжЇГжЁЃЪЕМЪЩЯЃЌKafkaЕФЩшМЦРэФюжЎвЛОЭЪЧЭЌЪБЬсЙЉРыЯпДІРэКЭЪЕЪБДІРэЁЃИљОнетвЛЬиадЃЌПЩвдЪЙгУStormетжжЪЕЪБСїДІРэЯЕЭГЖдЯћЯЂНјааЪЕЪБдкЯпДІРэЃЌЭЌЪБЪЙгУHadoopетжжХњДІРэЯЕЭГНјааРыЯпДІРэЃЌЛЙПЩвдЭЌЪБНЋЪ§ОнЪЕЪББИЗнЕНСэвЛИіЪ§ОнжааФЃЌжЛашвЊБЃжЄетШ§ИіВйзїЫљЪЙгУЕФconsumerдкВЛЭЌЕФconsumer
groupМДПЩЁЃЯТЭМеЙЪОСЫKafkaдкLinkedinЕФвЛжжМђЛЏВПЪ№ЁЃ
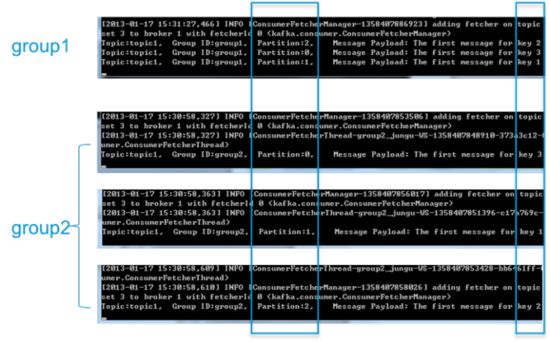
ЮЊСЫИќЧхЮњеЙЪОKafka consumer groupЕФЬиадЃЌБЪепзїСЫвЛЯюВтЪдЁЃДДНЈвЛИіtopic
(УћЮЊtopic1)ЃЌДДНЈвЛИіЪєгкgroup1ЕФconsumerЪЕР§ЃЌВЂДДНЈШ§ИіЪєгкgroup2ЕФconsumerЪЕР§ЃЌШЛКѓЭЈЙ§producerЯђtopic1ЗЂЫЭkeyЗжБ№ЮЊ1ЃЌ2ЃЌ3rЕФЯћЯЂЁЃНсЙћЗЂЯжЪєгкgroup1ЕФconsumerЪеЕНСЫЫљгаЕФетШ§ЬѕЯћЯЂЃЌЭЌЪБgroup2жаЕФ3ИіconsumerЗжБ№ЪеЕНСЫkeyЮЊ1ЃЌ2ЃЌ3ЕФЯћЯЂЁЃШчЯТЭМЫљЪОЁЃ
Consumer Rebalance
ЃЈБОНкЫљНВЪіФкШнОљЛљгкKafka consumer high level APIЃЉ
KafkaБЃжЄЭЌвЛconsumer groupжажЛгавЛИіconsumerЛсЯћЯЂФГЬѕЯћЯЂЃЌЪЕМЪЩЯЃЌKafkaБЃжЄЕФЪЧЮШЖЈзДЬЌЯТУПвЛИіconsumerЪЕР§жЛЛсЯћЗбФГвЛИіЛђЖрИіЬиЖЈpartitionЕФЪ§ОнЃЌЖјФГИіpartitionЕФЪ§ОнжЛЛсБЛФГвЛИіЬиЖЈЕФconsumerЪЕР§ЫљЯћЗбЁЃетбљЩшМЦЕФСгЪЦЪЧЮоЗЈШУЭЌвЛИіconsumer
groupРяЕФconsumerОљдШЯћЗбЪ§ОнЃЌгХЪЦЪЧУПИіconsumerВЛгУЖМИњДѓСПЕФbrokerЭЈаХЃЌМѕЩйЭЈаХПЊЯњЃЌЭЌЪБвВНЕЕЭСЫЗжХфФбЖШЃЌЪЕЯжвВИќМђЕЅЁЃСэЭтЃЌвђЮЊЭЌвЛИіpartitionРяЕФЪ§ОнЪЧгаађЕФЃЌетжжЩшМЦПЩвдБЃжЄУПИіpartitionРяЕФЪ§ОнвВЪЧгаађБЛЯћЗбЁЃ
ШчЙћФГconsumer groupжаconsumerЪ§СПЩйгкpartitionЪ§СПЃЌдђжСЩйгавЛИіconsumerЛсЯћЗбЖрИіpartitionЕФЪ§ОнЃЌШчЙћconsumerЕФЪ§СПгыpartitionЪ§СПЯрЭЌЃЌдђе§КУвЛИіconsumerЯћЗбвЛИіpartitionЕФЪ§ОнЃЌЖјШчЙћconsumerЕФЪ§СПЖргкpartitionЕФЪ§СПЪБЃЌЛсгаВПЗжconsumerЮоЗЈЯћЗбИУtopicЯТШЮКЮвЛЬѕЯћЯЂЁЃ
ШчЯТР§ЫљЪОЃЌШчЙћtopic1га0ЃЌ1ЃЌ2ЙВШ§ИіpartitionЃЌЕБgroup1жЛгавЛИіconsumer(УћЮЊconsumer1)ЪБЃЌИУ
consumerПЩЯћЗбет3ИіpartitionЕФЫљгаЪ§ОнЁЃ

діМгвЛИіconsumer(consumer2)КѓЃЌЦфжавЛИіconsumerЃЈconsumer1ЃЉПЩЯћЗб2ИіpartitionЕФЪ§ОнЃЌСэЭтвЛИіconsumer(consumer2)ПЩЯћЗбСэЭтвЛИіpartitionЕФЪ§ОнЁЃ
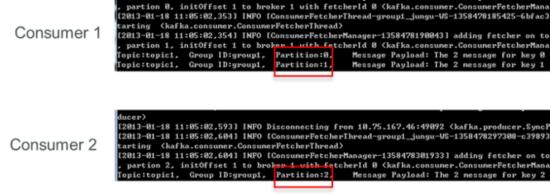
дйдіМгвЛИіconsumer(consumer3)КѓЃЌУПИіconsumerПЩЯћЗбвЛИіpartitionЕФЪ§ОнЁЃconsumer1ЯћЗбpartition0ЃЌconsumer2ЯћЗбpartition1ЃЌconsumer3ЯћЗбpartition2
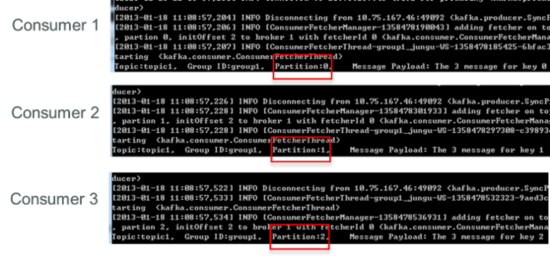
дйдіМгвЛИіconsumerЃЈconsumer4ЃЉКѓЃЌЦфжа3ИіconsumerПЩЗжБ№ЯћЗбвЛИіpartitionЕФЪ§ОнЃЌСэЭтвЛИіconsumerЃЈconsumer4ЃЉВЛФмЯћЗбtopic1ШЮКЮЪ§ОнЁЃ
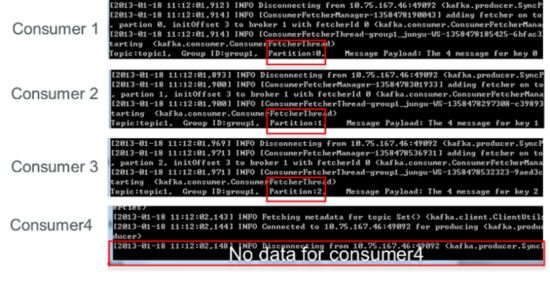
ДЫЪБЙиБеconsumer1ЃЌЪЃЯТЕФconsumerПЩЗжБ№ЯћЗбвЛИіpartitionЕФЪ§ОнЁЃ
[ЭМЦЌЩЯДЋжаЁЃЁЃЁЃЃЈ15ЃЉ]НгзХЙиБеconsumer2ЃЌЪЃЯТЕФconsumer3ПЩЯћЗб2ИіpartitionЃЌconsumer4ПЩЯћЗб1ИіpartitionЁЃ
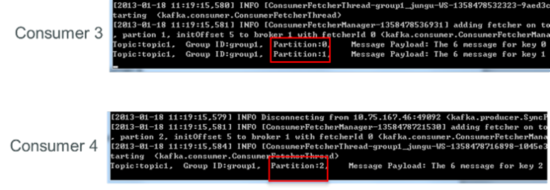
дйЙиБеconsumer3ЃЌЪЃЯТЕФconsumer4ПЩЭЌЪБЯћЗбtopic1ЕФ3ИіpartitionЁЃ
[ЭМЦЌЩЯДЋжаЁЃЁЃЁЃЃЈ17ЃЉ]
consumer rebalanceЫуЗЈШчЯТЃК
| Sort
PT (all partitions in topic T)
Sort CG(all consumers in consumer group G)
Let i be the index position of Ci in CG and
let N=size(PT)/size(CG)
Remove current entries owned by Ci from the
partition owner registry
Assign partitions from i N to (i+1)* N-1 to
consumer Ci
Add newly assigned partitions to the partition
owner registry
|
ФПЧАconsumer rebalanceЕФПижЦВпТдЪЧгЩУПвЛИіconsumerЭЈЙ§ZookeeperЭъГЩЕФЁЃОпЬхЕФПижЦЗНЪНШчЯТЃК
| Register
itself in the consumer id registry under its
group.
Register a watch on changes under the consumer
id registry.
Register a watch on changes under the broker
id registry.
If the consumer creates a message stream using
a topic filter, it also registers a watch on
changes under the broker topic registry.
Force itself to rebalance within in its consumer
group.
|
дкетжжВпТдЯТЃЌУПвЛИіconsumerЛђепbrokerЕФдіМгЛђепМѕЩйЖМЛсДЅЗЂconsumer rebalanceЁЃвђЮЊУПИіconsumerжЛИКд№ЕїећздМКЫљЯћЗбЕФpartitionЃЌЮЊСЫБЃжЄећИіconsumer
groupЕФвЛжТадЃЌЫљвдЕБвЛИіconsumerДЅЗЂСЫrebalanceЪБЃЌИУconsumer groupФкЕФЦфЫќЫљгаconsumerвВгІИУЭЌЪБДЅЗЂrebalanceЁЃ
ФПЧАЃЈ2015-01-19ЃЉзюаТАцЃЈ0.8.2ЃЉKafkaВЩгУЕФЪЧЩЯЪіЗНЪНЁЃЕЋИУЗНЪНгаВЛРћЕФЗНУцЃК
Herd effect ШЮКЮbrokerЛђепconsumerЕФдіМѕЖМЛсДЅЗЂЫљгаЕФconsumerЕФrebalance
Split Brain УПИіconsumerЗжБ№ЕЅЖРЭЈЙ§ZookeeperХаЖЯФФаЉ
partition downСЫЃЌФЧУДВЛЭЌconsumerДгZookeeperЁАПДЁБЕНЕФviewОЭПЩФмВЛвЛбљЃЌетОЭЛсдьГЩДэЮѓЕФreblanceГЂЪдЁЃЖјЧвгаПЩФмЫљгаЕФconsumerЖМШЯЮЊrebalanceвбОЭъГЩСЫЃЌЕЋЪЕМЪЩЯПЩФмВЂЗЧШчДЫЁЃ
ИљОнKafkaЙйЗНЮФЕЕЃЌKafkaзїепе§дкПМТЧдкЛЙЮДЗЂВМЕФ 0.9.xАцБОжаЪЙгУжааФаЕїЦї(coordinator)
ЁЃДѓЬхЫМЯыЪЧбЁОйГівЛИіbrokerзїЮЊcoordinatorЃЌгЩЫќwatch ZookeeperЃЌДгЖјХаЖЯЪЧЗёгаpartitionЛђепconsumerЕФдіМѕЃЌШЛКѓЩњГЩrebalanceУќСюЃЌВЂМьВщЪЧЗёетаЉrebalanceдкЫљгаЯрЙиЕФconsumerжаБЛжДааГЩЙІЃЌШчЙћВЛГЩЙІдђжиЪдЃЌШєГЩЙІдђШЯЮЊДЫДЮrebalanceГЩЙІЃЈетИіЙ§ГЬИњreplication
controllerЗЧГЃРрЫЦЃЌЫљвдЮвКмЦцЙжЮЊЪВУДЕБГѕЩшМЦreplication controllerЪБУЛгаЪЙгУРрЫЦЗНЪНРДНтОіconsumer
rebalanceЕФЮЪЬтЃЉЁЃСїГЬШчЯТЃК
[ЭМЦЌЩЯДЋжаЁЃЁЃЁЃЃЈ18ЃЉ]
ЯћЯЂDeliver guarantee
ЭЈЙ§ЩЯЮФНщЩмЃЌЯыБиЖСепвбОУїЬьСЫproducerКЭconsumerЪЧШчКЮЙЄзїЕФЃЌвдМАKafkaЪЧШчКЮзіreplicationЕФЃЌНгЯТРДвЊЬжТлЕФЪЧKafkaШчКЮШЗБЃЯћЯЂдкproducerКЭconsumerжЎМфДЋЪфЁЃгаетУДМИжжПЩФмЕФdelivery
guaranteeЃК
At most once
ЯћЯЂПЩФмЛсЖЊЃЌЕЋОјВЛЛсжиИДДЋЪф
At least one
ЯћЯЂОјВЛЛсЖЊЃЌЕЋПЩФмЛсжиИДДЋЪф
Exactly once
УПЬѕЯћЯЂПЯЖЈЛсБЛДЋЪфвЛДЮЧвНіДЋЪфвЛДЮЃЌКмЖрЪБКђетЪЧгУЛЇЫљЯывЊЕФЁЃKafkaЕФdelivery guarantee
semanticЗЧГЃжБНгЁЃЕБproducerЯђbrokerЗЂЫЭЯћЯЂЪБЃЌвЛЕЉетЬѕЯћЯЂБЛcommitЃЌвђЪ§replicationЕФДцдкЃЌЫќОЭВЛЛсЖЊЁЃЕЋЪЧШчЙћproducerЗЂЫЭЪ§ОнИјbrokerКѓЃЌгіЕНЕФЭјТчЮЪЬтЖјдьГЩЭЈаХжаЖЯЃЌФЧproducerОЭЮоЗЈХаЖЯИУЬѕЯћЯЂЪЧЗёвбОcommitЁЃетвЛЕугаЕуЯёЯђвЛИіздЖЏЩњГЩprimary
keyЕФЪ§ОнПтБэжаВхШыЪ§ОнЁЃЫфШЛKafkaЮоЗЈШЗЖЈЭјТчЙЪеЯЦкМфЗЂЩњСЫЪВУДЃЌЕЋЪЧproducerПЩвдЩњГЩвЛжжРрЫЦгкprimary
keyЕФЖЋЮїЃЌЗЂЩњЙЪеЯЪБУнЕШадЕФretryЖрДЮЃЌетбљОЭзіЕНСЫ Exactly one
ЁЃНижЙЕНФПЧА(Kafka 0.8.2АцБОЃЌ2015-01-25)ЃЌетвЛfeatureЛЙВЂЮДЪЕЯжЃЌгаЯЃЭћдкKafkaЮДРДЕФАцБОжаЪЕЯжЁЃЃЈЫљвдФПЧАФЌШЯЧщПіЯТвЛЬѕЯћЯЂДгproducerКЭbrokerЪЧШЗБЃСЫ
At least once
ЃЌЕЋПЩЭЈЙ§ЩшжУproducerвьВНЗЂЫЭЪЕЯж At most once
ЃЉЁЃ
НгЯТРДЬжТлЕФЪЧЯћЯЂДгbrokerЕНconsumerЕФdelivery guarantee semanticЁЃЃЈНіеыЖдKafka
consumer high level APIЃЉЁЃconsumerдкДгbrokerЖСШЁЯћЯЂКѓЃЌПЩвдбЁдёcommitЃЌИУВйзїЛсдкZookeeperжаДцЯТИУconsumerдкИУpartitionЯТЖСШЁЕФЯћЯЂЕФoffsetЁЃИУconsumerЯТвЛДЮдйЖСИУpartitionЪБЛсДгЯТвЛЬѕПЊЪМЖСШЁЁЃШчЮДcommitЃЌЯТвЛДЮЖСШЁЕФПЊЪМЮЛжУЛсИњЩЯвЛДЮcommitжЎКѓЕФПЊЪМЮЛжУЯрЭЌЁЃЕБШЛПЩвдНЋconsumerЩшжУЮЊautocommitЃЌМДconsumerвЛЕЉЖСЕНЪ§ОнСЂМДздЖЏcommitЁЃШчЙћжЛЬжТлетвЛЖСШЁЯћЯЂЕФЙ§ГЬЃЌФЧKafkaЪЧШЗБЃСЫ
Exactly once
ЁЃЕЋЪЕМЪЩЯЪЕМЪЪЙгУжаconsumerВЂЗЧЖСШЁЭъЪ§ОнОЭНсЪјСЫЃЌЖјЪЧвЊНјааНјвЛВНДІРэЃЌЖјЪ§ОнДІРэгыcommitЕФЫГађдкКмДѓГЬЖШЩЯОіЖЈСЫЯћЯЂДгbrokerКЭconsumerЕФdelivery
guarantee semanticЁЃ
ЖСЭъЯћЯЂЯШcommitдйДІРэЯћЯЂЁЃетжжФЃЪНЯТЃЌШчЙћconsumerдкcommitКѓЛЙУЛРДЕУМАДІРэЯћЯЂОЭcrashСЫЃЌЯТДЮжиаТПЊЪМЙЄзїКѓОЭЮоЗЈЖСЕНИеИевбЬсНЛЖјЮДДІРэЕФЯћЯЂЃЌетОЭЖдгІгк
At most once
ЖСЭъЯћЯЂЯШДІРэдйcommitЁЃетжжФЃЪНЯТЃЌШчЙћДІРэЭъСЫЯћЯЂдкcommitжЎЧАconsumer crashСЫЃЌЯТДЮжиаТПЊЪМЙЄзїЪБЛЙЛсДІРэИеИеЮДcommitЕФЯћЯЂЃЌЪЕМЪЩЯИУЯћЯЂвбОБЛДІРэЙ§СЫЁЃетОЭЖдгІгк
At least once
ЁЃдкКмЖрЧщПіЪЙгУГЁОАЯТЃЌЯћЯЂЖМгавЛИіprimary keyЃЌЫљвдЯћЯЂЕФДІРэЭљЭљОпгаУнЕШадЃЌМДЖрДЮДІРэетвЛЬѕЯћЯЂИњжЛДІРэвЛДЮЪЧЕШаЇЕФЃЌФЧОЭПЩвдШЯЮЊЪЧ
Exactly once
ЁЃЃЈШЫИіИаОѕетжжЫЕЗЈгааЉЧЃЧПЃЌБЯОЙЫќВЛЪЧKafkaБОЩэЬсЙЉЕФЛњжЦЃЌЖјЧвprimary keyБОЩэВЛБЃжЄВйзїЕФУнЕШадЁЃЖјЧвЪЕМЪЩЯЮвУЧЫЕdelivery
guarantee semanticЪЧЬжТлБЛДІРэЖрЩйДЮЃЌЖјЗЧДІРэНсЙћдѕбљЃЌвђЮЊДІРэЗНЪНЖржжЖрбљЃЌЮвУЧЕФЯЕЭГВЛгІИУАбДІРэЙ§ГЬЕФЬиадЁЊШчЪЧЗёУнЕШадЃЌЕБГЩKafkaБОЩэЕФfeatureЃЉ
ШчЙћвЛЖЈвЊзіЕН Exactly once
ЃЌОЭашвЊаЕїoffsetКЭЪЕМЪВйзїЕФЪфГіЁЃОЋЕфЕФзіЗЈЪЧв§ШыСННзЖЮЬсНЛЁЃШчЙћФмШУoffsetКЭВйзїЪфШыДцдкЭЌвЛИіЕиЗНЃЌЛсИќМђНрКЭЭЈгУЁЃетжжЗНЪНПЩФмИќКУЃЌвђЮЊаэЖрЪфГіЯЕЭГПЩФмВЛжЇГжСННзЖЮЬсНЛЁЃБШШчЃЌconsumerФУЕНЪ§ОнКѓПЩФмАбЪ§ОнЗХЕНHDFSЃЌШчЙћАбзюаТЕФoffsetКЭЪ§ОнБОЩэвЛЦ№аДЕНHDFSЃЌФЧОЭПЩвдБЃжЄЪ§ОнЕФЪфГіКЭoffsetЕФИќаТвЊУДЖМЭъГЩЃЌвЊУДЖМВЛЭъГЩЃЌМфНгЪЕЯж
Exactly once
ЁЃЃЈФПЧАОЭhigh level APIЖјбдЃЌoffsetЪЧДцгкZookeeperжаЕФЃЌЮоЗЈДцгкHDFSЃЌЖјlow
level APIЕФoffsetЪЧгЩздМКШЅЮЌЛЄЕФЃЌПЩвдНЋжЎДцгкHDFSжаЃЉ змжЎЃЌKafkaФЌШЯБЃжЄ
At least once
ЃЌВЂЧвдЪаэЭЈЙ§ЩшжУproducerвьВНЬсНЛРДЪЕЯж At most once
ЁЃЖј Exactly once
вЊЧѓгыФПБъДцДЂЯЕЭГазїЃЌавдЫЕФЪЧKafkaЬсЙЉЕФoffsetПЩвдЪЙгУетжжЗНЪНЗЧГЃжБНгЗЧГЃШнвзЁЃ
Benchmark
жНЩЯЕУРДжеОѕЧГЃЌОјжЊаЉЪТвЊЙЊааЁЃБЪепЯЃЭћФмЧзздВтвЛЯТKafkaЕФадФмЃЌЖјЗЧДгЭјЩЯеввЛаЉВтЪдЪ§ОнЁЃЫљвдБЪепдјдк0.8ЗЂВМЧАСНИідТзіЙ§ЯъЯИЕФKafka0.8адФмВтЪдЃЌВЛЙ§КмПЩЯЇВтЪдБЈИцВЛЩїЖЊЪЇЁЃЫљавдкЭјЩЯевЕНСЫKafkaЕФДДЪМШЫжЎвЛЕФ
Jay KrepsЕФbechmark ЁЃвдЯТУшЪіНдЛљгкИУbenchmarkЁЃЃЈИУbenchmarkЛљгкKafka0.8.1ЃЉ
ВтЪдЛЗОГ
ИУbenchmarkгУЕНСЫСљЬЈЛњЦїЃЌЛњЦїХфжУШчЯТ
Intel Xeon 2.5 GHz processor with six cores
Six 7200 RPM SATA drives
32GB of RAM
1Gb Ethernet
ет6ЬЈЛњЦїЦфжа3ЬЈгУРДДюНЈKafka brokerМЏШКЃЌСэЭт3ЬЈгУРДАВзАZookeeperМАЩњГЩВтЪдЪ§ОнЁЃ6ИіdriveЖМжБНгвдЗЧRAIDЗНЪНЙвдиЁЃЪЕМЪЩЯkafkaЖдЛњЦїЕФашЧѓгыHadoopЕФРрЫЦЁЃ
producerЭЬЭТТЪ
ИУЯюВтЪджЛВтproducerЕФЭЬЭТТЪЃЌвВОЭЪЧЪ§ОнжЛБЛГжОУЛЏЃЌУЛгаconsumerЖСЪ§ОнЁЃ
1ИіproducerЯпГЬЃЌЮоreplication
дкетвЛВтЪджаЃЌДДНЈСЫвЛИіАќКЌ6ИіpartitionЧвУЛгаreplicationЕФtopicЁЃШЛКѓЭЈЙ§вЛИіЯпГЬОЁПЩФмПьЕФЩњГЩ50
millionЬѕБШНЯЖЬЃЈpayload100зжНкГЄЃЉЕФЯћЯЂЁЃВтЪдНсЙћЪЧ 821,557 records/secondЃЈ
78.3MB/second ЃЉЁЃ
жЎЫљвдЪЙгУЖЬЯћЯЂЃЌЪЧвђЮЊЖдгкЯћЯЂЯЕЭГРДЫЕетжжЪЙгУГЁОАИќФбЁЃвђЮЊШчЙћЪЙгУMB/secondРДБэеїЭЬЭТТЪЃЌФЧЗЂЫЭГЄЯћЯЂЮовЩФмЪЙЕУВтЪдНсЙћИќКУЁЃ
ећИіВтЪджаЃЌЖМЪЧгУУПУыжгdeliveryЕФЯћЯЂЕФЪ§СПГЫвдpayloadЕФГЄЖШРДМЦЫуMB/secondЕФЃЌУЛгаАбЯћЯЂЕФдЊаХЯЂЫудкФкЃЌЫљвдЪЕМЪЕФЭјТчЪЙгУСПЛсБШетИіДѓЁЃЖдгкБОВтЪдРДЫЕЃЌУПДЮЛЙашДЋЪфЖюЭтЕФ22ИізжНкЃЌАќРЈвЛИіПЩбЁЕФkeyЃЌЯћЯЂГЄЖШУшЪіЃЌCRCЕШЁЃСэЭтЃЌЛЙАќКЌвЛаЉЧыЧѓЯрЙиЕФoverheadЃЌБШШч
topic ЃЌ partitionЃЌacknowledgementЕШЁЃетОЭЕМжТЮвУЧБШНЯФбХаЖЯЪЧЗёвбОДяЕНЭјПЈМЋЯоЃЌЕЋЪЧАбетаЉoverheadЖМЫудкЭЬЭТТЪРяУцгІИУИќКЯРэвЛаЉЁЃвђДЫЃЌЮвУЧвбОЛљБОДяЕНСЫЭјПЈЕФМЋЯоЁЃ
ГѕВНЙлВьДЫНсЙћЛсШЯЮЊЫќБШШЫУЧЫљдЄЦкЕФвЊИпКмЖрЃЌгШЦфЕБПМТЧЕНKafkaвЊАбЪ§ОнГжОУЛЏЕНДХХЬЕБжаЁЃЪЕМЪЩЯЃЌШчЙћЪЙгУЫцЛњЗУЮЪЪ§ОнЯЕЭГЃЌБШШчRDBMSЃЌЛђепkey-velue
storeЃЌПЩдЄЦкЕФзюИпЗУЮЪЦЕТЪДѓИХЪЧ5000ЕН50000ИіЧыЧѓУПУыЃЌетКЭвЛИіКУЕФRPCВуЫљФмНгЪмЕФдЖГЬЧыЧѓСПВюВЛЖрЁЃЖјИУВтЪджадЖГЌгкДЫЕФдвђгаСНИіЁЃ
KafkaШЗБЃаДДХХЬЕФЙ§ГЬЪЧЯпадДХХЬI/OЃЌВтЪджаЪЙгУЕФ6ПщСЎМлДХХЬЯпадI/OЕФзюДѓЭЬЭТСПЪЧ822MB/secondЃЌетвбОдЖДѓгк1GbЭјПЈЫљФмДјРДЕФЭЬЭТСПСЫЁЃаэЖрЯћЯЂЯЕЭГАбЪ§ОнГжОУЛЏЕНДХХЬЕБГЩЪЧвЛИіПЊЯњКмДѓЕФЪТЧщЃЌетЪЧвђЮЊЫћУЧЖдДХХЬЕФВйзїЖМВЛЪЧЯпадI/OЁЃ
дкУПвЛИіНзЖЮЃЌKafkaЖМОЁСПЪЙгУХњСПДІРэЁЃШчЙћЯыСЫНтХњДІРэдкI/OВйзїжаЕФживЊадЃЌПЩвдВЮПМDavid
PattersonЕФЁБ Latency Lags Bandwidth ЁА
1ИіproducerЯпГЬЃЌ3ИівьВНreplication
ИУЯюВтЪдгыЩЯвЛВтЪдЛљБОвЛбљЃЌЮЈвЛЕФЧјБ№ЪЧУПИіpartitionга3ИіreplicaЃЈЫљвдЭјТчДЋЪфЕФКЭаДШыДХХЬЕФзмЕФЪ§ОнСПдіМгСЫ3БЖЃЉЁЃУПвЛИіbrokerМДвЊаДзїЮЊleaderЕФ
partition ЃЌвВвЊЖСЃЈДгleaderЖСЪ§ОнЃЉаДЃЈНЋЪ§ОнаДЕНДХХЬЃЉзїЮЊfollowerЕФ partition
ЁЃВтЪдНсЙћЮЊ 786,980 records/second ЃЈ75.1MB/second ЃЉЁЃ
ИУЯюВтЪджаreplicationЪЧвьВНЕФЃЌвВОЭЪЧЫЕbrokerЪеЕНЪ§ОнВЂаДШыБОЕиДХХЬКѓОЭacknowledge
producerЃЌЖјВЛБиЕШЫљгаreplicaЖМЭъГЩreplicationЁЃвВОЭЪЧЫЕЃЌШчЙћleader
crashСЫЃЌПЩФмЛсЖЊЕєвЛаЉзюаТЕФЛЙЮДБИЗнЕФЪ§ОнЁЃЕЋетвВЛсШУmessage acknowledgementбгГйИќЩйЃЌЪЕЪБадИќКУЁЃ
етЯюВтЪдЫЕУїЃЌreplicationПЩвдКмПьЁЃећИіМЏШКЕФаДФмСІПЩФмЛсгЩгк3БЖЕФreplicationЖјжЛгадРДЕФШ§ЗжжЎвЛЃЌЕЋЪЧЖдгкУПвЛИіproducerРДЫЕЭЬЭТТЪвРШЛзуЙЛКУЁЃ
1ИіproducerЯпГЬЃЌ3ИіЭЌВНreplication
ИУЯюВтЪдгыЩЯвЛВтЪдЕФЮЈвЛЧјБ№ЪЧreplicationЪЧЭЌВНЕФЃЌУПЬѕЯћЯЂжЛгадкБЛ in sync
МЏКЯРяЕФЫљгаreplicaЖМИДжЦЙ§ШЅКѓВХЛсБЛжУЮЊcommittedЃЈДЫЪБbrokerЛсЯђproducerЗЂЫЭacknowledgementЃЉЁЃдкетжжФЃЪНЯТЃЌKafkaПЩвдБЃжЄМДЪЙleader
crashСЫЃЌвВВЛЛсгаЪ§ОнЖЊЪЇЁЃВтЪдНсЙћЮЊ 421,823 records/second ЃЈ 40.2MB/second
ЃЉЁЃ
KafkaЭЌВНИДжЦгывьВНИДжЦВЂУЛгаБОжЪЕФВЛЭЌЁЃleaderЛсЪМжеtrack follower replicaДгЖјМрПиЫќУЧЪЧЗёЛЙaliveЃЌжЛгаЫљга
in sync
МЏКЯРяЕФreplicaЖМacknowledgeЕФЯћЯЂВХПЩФмБЛconsumerЫљЯћЗбЁЃЖјЖдfollowerЕФЕШД§гАЯьСЫЭЬЭТТЪЁЃПЩвдЭЈЙ§діДѓbatch
sizeРДИФЩЦетжжЧщПіЃЌЕЋЮЊСЫБмУтЬиЖЈЕФгХЛЏЖјгАЯьВтЪдНсЙћЕФПЩБШадЃЌБОДЮВтЪдВЂУЛгазіетжжЕїећЁЃ
3Иіproducer,3ИівьВНreplication
ИУВтЪдЯрЕБгкАбЩЯЮФжаЕФ1Иіproducer,ИДжЦЕНСЫ3ЬЈВЛЭЌЕФЛњЦїЩЯЃЈдк1ЬЈЛњЦїЩЯХмЖрИіЪЕР§ЖдЭЬЭТТЪЕФдіМгВЛЛсгаЬЋДѓАяУІЃЌвђЮЊЭјПЈвбОЛљБОБЅКЭСЫЃЉЃЌет3ИіproducerЭЌЪБЗЂЫЭЪ§ОнЁЃећИіМЏШКЕФЭЬЭТТЪЮЊ
2,024,032 records/second ЃЈ 193,0MB/second ЃЉЁЃ
Producer Throughput Vs. Stored Data
ЯћЯЂЯЕЭГЕФвЛИіЧБдкЕФЮЃЯеЪЧЕБЪ§ОнФмЖМДцгкФкДцЪБадФмКмКУЃЌЕЋЕБЪ§ОнСПЬЋДѓЮоЗЈЭъШЋДцгкФкДцжаЪБЃЈШЛКѓКмЖрЯћЯЂЯЕЭГЖМЛсЩОГ§вбОБЛЯћЗбЕФЪ§ОнЃЌЕЋЕБЯћЗбЫйЖШБШЩњВњЫйЖШТ§ЪБЃЌШдЛсдьГЩЪ§ОнЕФЖбЛ§ЃЉЃЌЪ§ОнЛсБЛзЊвЦЕНДХХЬЃЌДгЖјЪЙЕУЭЬЭТТЪЯТНЕЃЌетгжЗДЙ§РДдьГЩЯЕЭГЮоЗЈМАЪБНгЪеЪ§ОнЁЃетбљОЭЗЧГЃдуИтЃЌЖјЪЕМЪЩЯКмЖрЧщОАЯТЪЙгУqueueЕФФПЕФОЭЪЧНтОіЪ§ОнЯћЗбЫйЖШКЭЩњВњЫйЖШВЛвЛжТЕФЮЪЬтЁЃ
ЕЋKafkaВЛДцдкетвЛЮЪЬтЃЌвђЮЊKafkaЪМжевдOЃЈ1ЃЉЕФЪБМфИДдгЖШНЋЪ§ОнГжОУЛЏЕНДХХЬЃЌЫљвдЦфЭЬЭТТЪВЛЪмДХХЬЩЯЫљДцДЂЕФЪ§ОнСПЕФгАЯьЁЃЮЊСЫбщжЄетвЛЬиадЃЌзіСЫвЛИіГЄЪБМфЕФДѓЪ§ОнСПЕФВтЪдЃЌЯТЭМЪЧЭЬЭТТЪгыЪ§ОнСПДѓаЁЕФЙиЯЕЭМЁЃ
[ЭМЦЌЩЯДЋжаЁЃЁЃЁЃЃЈ19ЃЉ]ЩЯЭМжагавЛаЉvarianceЕФДцдкЃЌВЂПЩвдУїЯдПДЕНЃЌЭЬЭТТЪВЂВЛЪмДХХЬЩЯЫљДцЪ§ОнСПДѓаЁЕФгАЯьЁЃЪЕМЪЩЯДгЩЯЭМПЩвдПДЕНЃЌЕБДХХЬЪ§ОнСПДяЕН1TBЪБЃЌЭЬЭТТЪКЭДХХЬЪ§ОнжЛгаМИАйMBЪБУЛгаУїЯдЧјБ№ЁЃ
етИіvarianceЪЧгЩLinux I/OЙмРэдьГЩЕФЃЌЫќЛсАбЪ§ОнЛКДцЦ№РДдйХњСПflushЁЃЩЯЭМЕФВтЪдНсЙћЪЧдкЩњВњЛЗОГжаЖдKafkaМЏШКзіСЫаЉtuningКѓЕУЕНЕФЃЌетаЉtuningЗНЗЈПЩВЮПМ
етРя ЁЃ
consumerЭЬЭТТЪ
ашвЊзЂвтЕФЪЧЃЌreplication factorВЂВЛЛсгАЯьconsumerЕФЭЬЭТТЪВтЪдЃЌвђЮЊconsumerжЛЛсДгУПИіpartition
ЕФleaderЖСЪ§ОнЃЌЖјгыreplicaiton factorЮоЙиЁЃЭЌбљЃЌconsumerЭЬЭТТЪвВгыЭЌВНИДжЦЛЙЪЧвьВНИДжЦЮоЙиЁЃ
1Иіconsumer
ИУВтЪдДгга6ИіpartitionЃЌ3ИіreplicationЕФtopicЯћЗб50 millionЕФЯћЯЂЁЃВтЪдНсЙћЮЊ
940,521 records/second ЃЈ 89.7MB/second ЃЉЁЃ
ПЩвдПДЕНЃЌKafkarЕФconsumerЪЧЗЧГЃИпаЇЕФЁЃЫќжБНгДгbrokerЕФЮФМўЯЕЭГРяЖСШЁЮФМўПщЁЃKafkaЪЙгУ
sendfile API РДжБНгЭЈЙ§ВйзїЯЕЭГжБНгДЋЪфЃЌЖјВЛгУАбЪ§ОнПНБДЕНгУЛЇПеМфЁЃИУЯюВтЪдЪЕМЪЩЯДгlogЕФЦ№ЪМДІПЊЪМЖСЪ§ОнЃЌЫљвдЫќзіСЫецЪЕЕФI/OЁЃдкЩњВњЛЗОГЯТЃЌconsumerПЩвджБНгЖСШЁproducerИеИеаДЯТЕФЪ§ОнЃЈЫќПЩФмЛЙдкЛКДцжаЃЉЁЃЪЕМЪЩЯЃЌШчЙћдкЩњВњЛЗОГЯТХм
I/O stat ЃЌФуПЩвдПДЕНЛљБОЩЯУЛгаЮяРэЁАЖСЁБЁЃвВОЭЪЧЫЕЩњВњЛЗОГЯТconsumerЕФЭЬЭТТЪЛсБШИУЯюВтЪджаЕФвЊИпЁЃ
3Иіconsumer
НЋЩЯУцЕФconsumerИДжЦЕН3ЬЈВЛЭЌЕФЛњЦїЩЯЃЌВЂЧвВЂаадЫааЫќУЧЃЈДгЭЌвЛИіtopicЩЯЯћЗбЪ§ОнЃЉЁЃВтЪдНсЙћЮЊ
2,615,968 records/second ЃЈ 249.5MB/second ЃЉЁЃ
е§ШчЫљдЄЦкЕФФЧбљЃЌconsumerЕФЭЬЭТТЪМИКѕЯпаддіеЧЁЃ
Producer and Consumer
ЩЯУцЕФВтЪджЛЪЧАбproducerКЭconsumerЗжПЊВтЪдЃЌЖјИУЯюВтЪдЭЌЪБдЫааproducerКЭconsumerЃЌетИќНгНќЪЙгУГЁОАЁЃЪЕМЪЩЯФПЧАЕФreplicationЯЕЭГжаfollowerОЭЯрЕБгкconsumerдкЙЄзїЁЃ
ИУЯюВтЪдЃЌдкОпга6Иі partition КЭ3ИіreplicaЕФtopicЩЯЭЌЪБЪЙгУ1ИіproducerКЭ1ИіconsumerЃЌВЂЧвЪЙгУвьВНИДжЦЁЃВтЪдНсЙћЮЊ
795,064 records/second ЃЈ 75.8MB/second ЃЉЁЃ
ПЩвдПДЕНЃЌИУЯюВтЪдНсЙћгыЕЅЖРВтЪд1ИіproducerЪБЕФНсЙћМИКѕвЛжТЁЃЫљвдЫЕconsumerЗЧГЃЧсСПМЖЁЃ
ЯћЯЂГЄЖШЖдЭЬЭТТЪЕФгАЯь
ЩЯУцЕФЫљгаВтЪдЖМЛљгкЖЬЯћЯЂЃЈpayload 100зжНкЃЉЃЌЖје§ШчЩЯЮФЫљЫЕЃЌЖЬЯћЯЂЖдKafkaРДЫЕЪЧИќФбДІРэЕФЪЙгУЗНЪНЃЌПЩвддЄЦкЃЌЫцзХЯћЯЂГЄЖШЕФдіДѓЃЌrecords/secondЛсМѕаЁЃЌЕЋMB/secondЛсгаЫљЬсИпЁЃЯТЭМЪЧrecords/secondгыЯћЯЂГЄЖШЕФЙиЯЕЭМЁЃ
[ЭМЦЌЩЯДЋжаЁЃЁЃЁЃЃЈ20ЃЉ]е§ШчЮвУЧЫљдЄЦкЕФФЧбљЃЌЫцзХЯћЯЂГЄЖШЕФдіМгЃЌУПУыжгЫљФмЗЂЫЭЕФЯћЯЂЕФЪ§СПж№НЅМѕаЁЁЃЕЋЪЧШчЙћПДУПУыжгЗЂЫЭЕФЯћЯЂЕФзмДѓаЁЃЌЫќЛсЫцзХЯћЯЂГЄЖШЕФдіМгЖјдіМгЃЌШчЯТЭМЫљЪОЁЃ
[ЭМЦЌЩЯДЋжаЁЃЁЃЁЃЃЈ21ЃЉ]ДгЩЯЭМПЩвдПДГіЃЌЕБЯћЯЂГЄЖШЮЊ10зжНкЪБЃЌвђЮЊвЊЦЕЗБШыЖгЃЌЛЈСЫЬЋЖрЪБМфЛёШЁЫјЃЌCPUГЩСЫЦПОБЃЌВЂВЛФмГфЗжРћгУДјПэЁЃЕЋДг100зжНкПЊЪМЃЌЮвУЧПЩвдПДЕНДјПэЕФЪЙгУж№НЅЧїгкБЅКЭЃЈЫфШЛMB/secondЛЙЪЧЛсЫцзХЯћЯЂГЄЖШЕФдіМгЖјдіМгЃЌЕЋдіМгЕФЗљЖШвВдНРДдНаЁЃЉЁЃ
ЖЫЕНЖЫЕФLatency
ЩЯЮФжаЬжТлСЫЭЬЭТТЪЃЌФЧЯћЯЂДЋЪфЕФlatencyШчКЮФиЃПвВОЭЪЧЫЕЯћЯЂДгproducerЕНconsumerашвЊЖрЩйЪБМфФиЃПИУЯюВтЪдДДНЈ1ИіproducerКЭ1ИіconsumerВЂЗДИДМЦЪБЁЃНсЙћЪЧЃЌ
2 ms (median), 3ms (99th percentile, 14ms (99.9th
percentile) ЁЃ
ЃЈетРяВЂУЛгаЫЕУїtopicгаЖрЩйИіpartitionЃЌвВУЛгаЫЕУїгаЖрЩйИіreplicaЃЌreplicationЪЧЭЌВНЛЙЪЧвьВНЁЃЪЕМЪЩЯетЛсМЋДѓгАЯьproducerЗЂЫЭЕФЯћЯЂБЛcommitЕФlatencyЃЌЖјжЛгаcommittedЕФЯћЯЂВХФмБЛconsumerЫљЯћЗбЃЌЫљвдЫќЛсзюжегАЯьЖЫЕНЖЫЕФlatencyЃЉ
жиЯжИУbenchmark
ШчЙћЖСепЯывЊдкздМКЕФЛњЦїЩЯжиЯжБОДЮbenchmarkВтЪдЃЌПЩвдВЮПМ БОДЮВтЪдЕФХфжУКЭЫљЪЙгУЕФУќСю ЁЃ
ЪЕМЪЩЯKafka DistributionЬсЙЉСЫproducerадФмВтЪдЙЄОпЃЌПЩЭЈЙ§ bin/kafka-producer-perf-test.sh
НХБОРДЦєЖЏЁЃЫљЪЙгУЕФУќСюШчЯТ
| ProducerSetupbin/kafka-topics.sh
--zookeeper esv4-hcl197
.grid.linkedin.com:2181
--create --topic test-rep-one --
partitions 6 --replication-factor
1bin/kafka-topics.sh
--zookeeper esv4-hcl197.grid.linkedin.com:2181
--create
--topic test --partitions
6 --replication-factor 3Single
thread, no replicationbin/kafka-run-class.sh
org.apache.kafka.clients.tools.ProducerPerformance
test7
50000000 100 -1
acks=1 bootstrap.servers=esv4-hcl198.grid.
linkedin.com:9092
buffer.memory=67108864 batch.size=8196S
ingle-thread, async
3x replicationbin/kafktopics.sh -
-zookeeper esv4-hcl197.grid.linkedin.com:2181
--create
--topic test --partitions
6 --replication-factor 3bin
/kafka-run-class.sh
org.apache.kafka.clients.tools.
ProducerPerformance
test6 50000000 100 -1 acks=1
bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092
buffer.memory=67108864
batch.size=8196Single-thread,
sync 3x replicationbin/kafka-run-class.sh
org.apache.kafka.clients.tools.ProducerPerformance
test 50000000 100
-1 acks=-1 bootstrap.servers=esv4-hcl198
.grid.linkedin.com:9092
buffer.memory=67108864 batch.s
ize=64000Three Producers,
3x async replicationbin/kafka
-run-class.sh org.apache.kafka.clients.tools.Producer
Performance test
50000000 100 -1 acks=1 bootstrap.servers
=esv4-hcl198.grid.linkedin.com:9092
buffer.memory=67108864
batch.size=8196Throughput
Versus Stored Databin/kafka-
run-class.sh org.apache.kafka.clients.tools.ProducerPer
formance test 50000000000
100 -1 acks=1 bootstrap.servers
=esv4-hcl198.grid.linkedin.com:9092
buffer.memory=67108864
batch.size=8196Effect
of message sizefor i in 10 100 1000
10000 100000;doecho
""echo $ibin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformance
test $(
(100010241024/$i))
$i -1 acks=1 bootstrap.servers=esv4-hcl198
.grid.linkedin.com:9092
buffer.memory=67108864 batch.
size=128000done;ConsumerConsumer
throughputbin/kafka-consume
r-perf-test.sh --zookeeper
esv4-hcl197.grid.linkedin.com:2181
--messages 50000000
--topic test --threads 13 ConsumersOn three
servers, run:bin/kafka-consumer-perf-test.sh
--zookeeper esv4-hcl197.grid.linkedin.com:2181
--messages 50000000 --topic test
--threads 1End-to-end
Latencybin/kafka-run-class.sh kafka.tools.
TestEndToEndLatency
esv4-hcl198.grid.linkedin.com:9092 esv4-hcl197.
grid.linkedin.com:2181
test 5000Producer and consumerbin/kafka-run
-class.sh org.apache.kafka.clients.tools.ProducerPerformance
test 50000000 100
-1 acks=1 bootstrap.servers=esv4-hcl198.grid
.linkedin.com:9092
buffer.memory=67108864 batch.size=8196bin
/kafka-consumer-perf-test.sh
--zookeeper esv4-hcl197.grid.
linkedin.com:2181
--messages 50000000 --topic test --threads 1
|
brokerХфжУШчЯТ
| #######################
Server Basics ##############################
The id of the broker.
This must be set to a unique integer for each
broker.broker.id=0#############################
Socket Server Settings
##############################
The port the socket server listens
onport=9092# Hostname
the broker will bind to and advertise to producers
and consumers.#
If not set, the server will bind to all
interfaces and advertise
the value returned from# from java.net.InetAddress.getCanoni
calHostName().#host.name=localhost#
The number of
threads handling
network
requestsnum.network.threads=4#
The number of threads
doing disk I/Onum.io
.threads=8# The
send buffer (SO_SNDBUF) used by the
socket serversocket.
send.buffer.bytes=1048576#
The receive buffer (SO_RCVBUF)
used by the socket
serversocket.receive.buffer.bytes=1048576#
The maximum
size of a request
that
the socket server
will accept (protection against OOM)
socket.request.max.
bytes=104857600#############################
Log Basics ##############################
The directory under
which to store log fileslog.dirs=
/grid/a/dfs-data/kafka-logs
,/grid/b/dfs-data/kafka-logs,/grid/c/dfs-data/kafka-logs
,/grid/d/dfs-data/kafka-logs,
/grid/e/dfs-data/kafka-logs,/grid/f/dfs-data/kafka-logs#
The number of logical
partitions per topic
per server. More partitions allow
greater parallelism#
for consumption,
but also mean more files.num
.partitions=8
#############################
Log Flush Policy ##############################
The following configurations
control the flush
of data to disk.
This is
the most# important
performance knob in kafka.#
There are a few
important
trade-offs here:#
1. Durability: Unflushed data
is at greater risk
of
loss in the event
of a crash.# 2. Latency: Data is
not made available
to consumers until
it is flushed (which adds latency).#
3. Throughput:
The flush is generally
the most expensive operation. #
The settings below
allow one to configure
the flush policy to flush data
after a period of
time or# every N
messages (or both). This can be done
globally and overridden
on a per-topic basis.#
Per-topic overrides for log.flush
.interval.ms#log.
flush.intervals.ms.per.topic=topic1:1000,
topic2:3000##
##############
############# Log
Retention Policy #######################
####### The
following configurations
control the disposal of log segments.
The policy can#
be set to delete segments after a period
of time, or after
a given size has accumulated.# A segment
will be deleted
whenever either of these criteria are met
. Deletion always
happens# from the end of the log.#
The minimum age
of a log file to be eligiblefor deletionlog.retention.hours=168#
A size-based retention
policy for logs.
Segments are pruned from the log as long as
the remaining# segments
ntion policieslog.cleanup.interval.mins=1###############
############## Zookeeper
##############################
Zookeeper connection
string (see zookeeper docs for details)
.# This is a comma
separated host:port pairs,
each corresponding
to a zk# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127
.0.0.1:3002".#
You can also append an optional chroot
string to the urls
to
specify the# root
directory for all kafka znodes.zookeeper.
connect=esv4-hcl197
.grid.linkedin.com:2181#
Timeout in ms for connecting to zookeeperzookeeper.
connection.timeout.ms=1000000#
metrics reporter propertieskafka.metrics.polling
.interval.secs=5kafka.metrics.reporters=kafka
.metrics.KafkaCSVMetricsReporterkafka.csv.metrics.dir=
/tmp/kafka_metrics#
Disable csv reporting
by default.kafka.csv.metrics.reporter.enabled=falsere
plica.lag.max.messages=10000000
|
|









