| Spark
Streaming”¶”√”Ž Ķ’ĹŌĶŃ–įŁņ®“‘Ō¬Ńý≤Ņ∑÷ńŕ»›£ļ
1.Ī≥ĺį”Žľ‹ĻĻłń‘ž
2.Õ®Ļżīķ¬Ž ĶŌ÷ĺŖŐŚŌłĹŕ£¨≤Ę‘ň––ŌÓńŅ
3.∂‘StreamingľŗŅōĶńĹť…‹“‘ľįĹ‚ĺŲ Ķľ ő Ő‚
4.∂‘ŌÓńŅ◊Ų—Ļ≤‚”ŽŌŗĻōĶń”ŇĽĮ
5.Streaming≥÷–ݔҼĮ÷ģHBase
6.Ļ‹ņŪStreaming»őőŮ
Ķ„īň‘ń∂ŃĶŕ“Ľ≤Ņ∑÷ńŕ»›£¨Īĺ∆™ő™Ķŕ∂Ģ≤Ņ∑÷£¨įŁņ® Streaming ≥÷–ݔҼĮ÷ģ
HBase “‘ľįĻ‹ņŪ Streaming »őőŮ°£
őŚ°ĘStreaming≥÷–ݔҼĮ÷ģHBase
5.1 …Ť÷√WALog
ĻōĪ’WALogļů–ī»Žń‹ĶĹ20ÕÚ£¨Ķę «∑ĘŌ÷ĽĻ «≤Ľ «ŐōĪūő»∂®£¨”– Īļń ĪĽĻ «Ī»ĹŌ≥§Ķń£¨∑ĘŌ÷īňĹ◊∂ő’ż‘ŕ◊ŲCompaction!!!
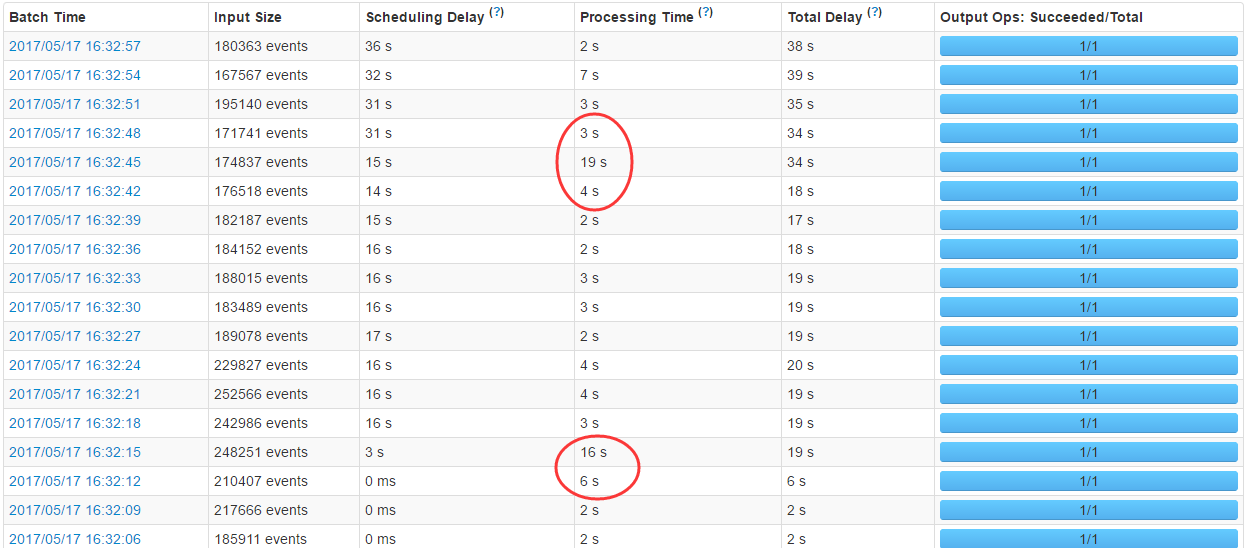
≤ťŅīstreamingÕ≥ľ∆,∑ĘŌ÷ļń Ī≤Ľő»∂®
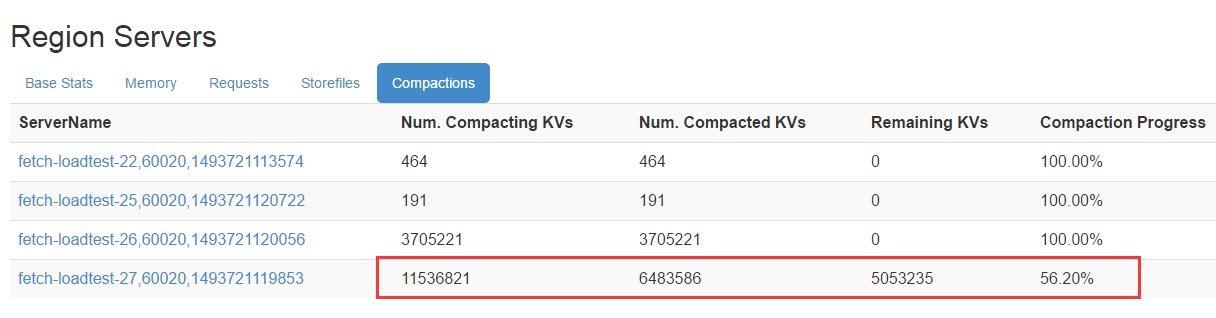
HBaseĹÁ√śÕ≥ľ∆–ŇŌĘ
HBase «“Ľ÷÷ Log-Structured Merge Tree
ľ‹ĻĻń£ Ĺ£¨”√Ľß żĺ›–ī»ŽŌ»–īWAL£¨‘Ŕ–īĽļīś£¨¬ķ◊„“Ľ∂®ŐűľĢļůĽļīś żĺ›ĽŠ÷ī––flush≤Ŕ◊ų’ś’ż¬šŇŐ£¨–ő≥…“ĽłŲ żĺ›őńľĢHFile°£ňś◊Ň żĺ›–ī»Ž≤Ľ∂Ō‘Ų∂ŗ£¨flushīő ż“≤ĽŠ≤Ľ∂Ō‘Ų∂ŗ£¨ĹÝ∂ÝHFile żĺ›őńľĢĺÕĽŠ‘Ĺņī‘Ĺ∂ŗ°£»Ľ∂Ý£¨Őę∂ŗ żĺ›őńľĢĽŠĶľ÷¬ żĺ›≤ť—ĮIOīő ż‘Ų∂ŗ£¨“ÚīňHBase≥Ę ‘◊Ň≤Ľ∂Ō∂‘’‚–©őńľĢĹÝ––ļŌ≤Ę£¨’‚łŲļŌ≤ĘĻż≥Ő≥∆ő™Compaction°£
CompactionĽŠī”“ĽłŲ region Ķń“ĽłŲ store ÷–—°‘Ů“Ľ–©
hfile őńľĢĹÝ––ļŌ≤Ę°£ļŌ≤ĘňĶņī‘≠ņŪļ‹ľÚĶ•£¨Ō»ī”’‚–©īżļŌ≤ĘĶń żĺ›őńľĢ÷–∂Ń≥ŲKeyValues£¨‘Ŕįī’’”…–°ĶĹīůŇŇŃ–ļů–ī»Ž“ĽłŲ–¬ĶńőńľĢ÷–°£÷ģļů£¨’‚łŲ–¬…ķ≥…ĶńőńľĢĺÕĽŠ»°īķ÷ģ«įīżļŌ≤ĘĶńňý”–őńľĢ∂‘Õ‚ŐŠĻ©∑ĢőŮ°£
HBasełýĺ›ļŌ≤ĘĻśń£Ĺę Compaction ∑÷ő™ŃňŃĹņŗ£ļ inorCompaction
ļÕ MajorCompaction °£
1. Minor Compaction «÷ł—°»°“Ľ–©–°Ķń°ĘŌŗŃŕĶń StoreFile
ĹęňŻ√«ļŌ≤Ę≥…“ĽłŲłŁīůĶń StoreFile £¨‘ŕ’‚łŲĻż≥Ő÷–≤ĽĽŠī¶ņŪ“—ĺ≠ Deleted ĽÚ Expired
Ķń Cell °£“Ľīő Minor Compaction ĶńĹŠĻŻ «łŁ…Ŕ≤Ę«“łŁīůĶń StoreFile
°£
2. Major Compaction «÷łĹęňý”–Ķń StoreFile
ļŌ≤Ę≥…“ĽłŲ StoreFile £¨’‚łŲĻż≥ŐĽĻĽŠ«ŚņŪ»żņŗőř“‚“Ś żĺ›£ļĪĽ…ĺ≥żĶń żĺ›°ĘTTLĻż∆ŕ żĺ›°ĘįśĪĺļŇ≥¨Ļż…Ť∂®įśĪĺļŇĶń żĺ›°£ŃŪÕ‚£¨“Ľį„«ťŅŲŌ¬£¨
Major Compaction ĪľšĽŠ≥÷–ÝĪ»ĹŌ≥§£¨’ŻłŲĻż≥ŐĽŠŌŻļńīůŃŅŌĶÕ≥◊ ‘ī£¨∂‘…Ō≤„“ĶőŮ”–Ī»ĹŌīůĶń”įŌž°£“ÚīňŌŖ…Ō“ĶőŮ∂ľĽŠĹęĻōĪ’◊‘∂Įī•∑ĘMajor
CompactionĻ¶ń‹£¨łńő™ ÷∂Į‘ŕ“ĶőŮĶÕ∑Ś∆ŕī•∑Ę°£
5.2 Ķų’Ż—Ļňű
Õ®≥£…ķ≤ķĽ∑ĺ≥ĽŠĻōĪ’◊‘∂Į major_compact (Ňš÷√őńľĢ÷– hbase
. hregion . majorcompaction …Ť ő™ 0 )£¨—°‘Ů“ĽłŲÕŪ…Ō”√Ľß…ŔĶń ĪľšīįŅŕ ÷Ļ§
major _ compact °£
÷∂Į £ļ major_compact °ģ testtable °Į
»ÁĻŻ hbase łŁ–¬≤Ľ «Őę∆Ķ∑Ī£¨Ņ…“‘“ĽłŲ–«∆ŕ∂‘ňý”–ĪŪ◊Ų“Ľīő major_compact£¨’‚łŲŅ…“‘‘ŕ◊ŲÕÍ“Ľīőmajor_compactļů£¨ĻŘŅīňý”–Ķń
storefil e żŃŅ£¨»ÁĻŻ storefile żŃŅ‘Ųľ”ĶĹ major_compact ļůĶń storefile
ĶńĹŁ∂ĢĪ∂ Ī£¨Ņ…“‘∂‘ňý”–ĪŪ◊Ų“Ľīő major_compact £¨ ĪľšĪ»ĹŌ≥§£¨≤Ŕ◊ųĺ°ŃŅĪ‹√‚łŖ∑ś∆ŕ°£

≤ťŅīÕ≥ľ∆–ŇŌĘ
Compactī•∑ĘŐűľĢ£ļ
1.memstore flush÷ģļůī•∑Ę
2.ŅÕĽß∂ňÕ®ĻżshellĽÚ’ŖAPIī•∑Ę
3.ļůŐ®ŌŖ≥ŐCompactionChecker∂®∆ŕī•∑Ę
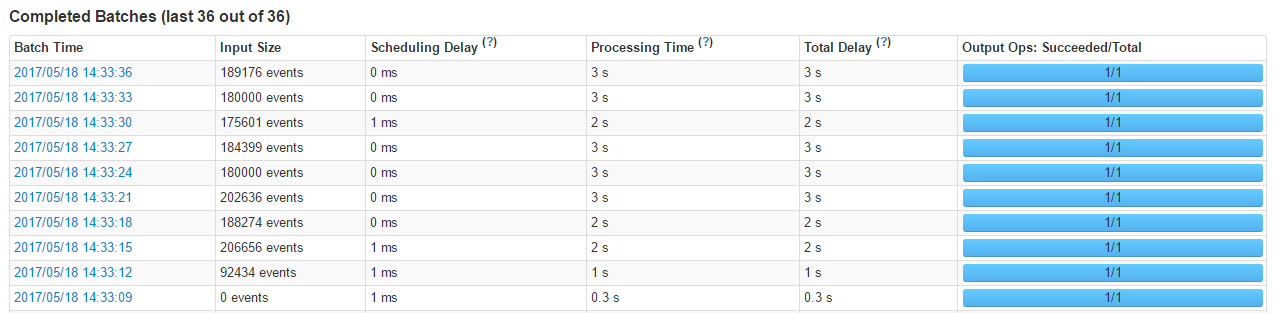
≤ťŅīÕ≥ľ∆–ŇŌĘ

≤ťŅīÕ≥ľ∆–ŇŌĘ
÷‹∆ŕő™£ļ Hbase . server . thread . wakefrequencyhbase
. server . compactchecker . interval . multiplier
ī•∑Ę compaction £¨ļů√śĽĻ”–“Ľ–©∆šňŻĶńŐűľĢ“≤Ņ…“‘‘ŕ‘ī¬ŽņÔ√śŅīŅī
ŐűľĢĶń—ť÷§¬Ŗľ≠ĺÕ «‘ŕ’‚łŲ Īľš∑∂őߣļmcTime = 7-70.5Őž,7+70.5Őž=3.5-10.5;
«∑Ů”–őńľĢ–řłńĺŖŐŚ¬Ŗľ≠Ņ…ľŻ RatioBasedCompactionPolicy
# isMajorCompaction ∑Ĺ∑®°£
5.3 Split
Õ®Ļż…Ō√śĶńĹōÕľő“√«Ņ…“‘ŅīĶĹ£¨ł√ĪŪ÷Ľ”–“ĽłŲ region £¨–ī»Ž żĺ›∂ľľĮ÷–ĶĹŃň“ĽŐ®∑ĢőŮ∆ų£¨’‚łŲ‘∂‘∂√Ľ”–∑ĘĽ”≥Ų
HBase ľĮ»ļĶńń‹Ń¶—Ĺ£¨ ÷∂Į≤ū∑÷į…£°
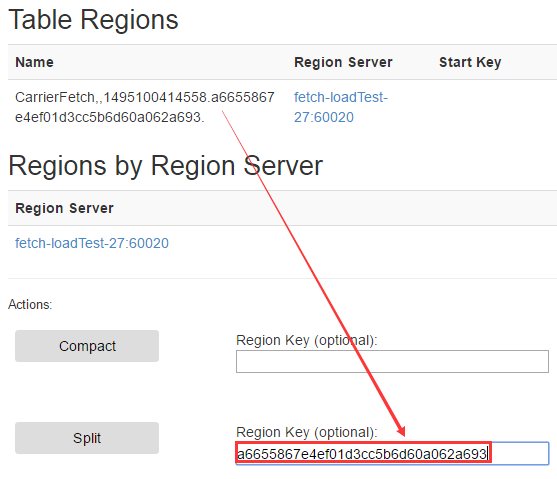
Õ®Ļżhbase uiĹÁ√ś≤ū∑÷Region
≤ū∑÷ļů£ļ
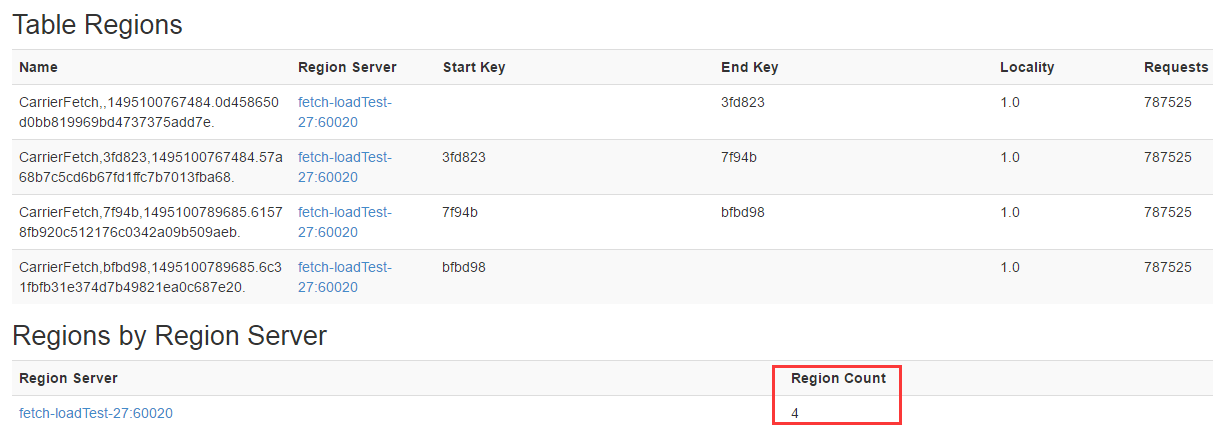
Region≤ū∑÷ļů
Ńý°ĘĻ‹ņŪStreaming»őőŮ
’‚ « Spark Streaming ŌĶŃ–≤©ŅÕĶń◊Óļů“Ľ≤Ņ∑÷£¨÷ų“™Ĺ≤“ĽŌ¬ő“◊‘ľļ∂‘
Spark Streaming »őőŮĶń“Ľ–©Ľģ∑÷£¨ĽĻ”–“ĽłŲSpark Streaming »őőŮĶń” ľĢľŗŅō°£
6.1 Streaming »őőŮĶńĽģ∑÷
ĶĪ Spark Streaming Ņ™∑ĘÕÍ≥…£¨≤‚ ‘ÕÍ≥…÷ģļů£¨ĺÕ∑Ę≤ľ…ŌŌŖŃň£¨
Spark Streaming »őőŮĶńĽģ∑÷£¨“‘ľį ĪľšīįŅŕĶų ‘∂ŗ…Ŕ’‚–©∂ľ «łŁĺŖ“ĶőŮĽģ∑÷Ķń°£
kafka “ĽłŲtopic∂‘”¶HBaseņÔ√śĶń“Ľ’ŇĪŪ
Kafka topic ņÔ√śĶńpartition£®3-5łŲ≤ĽĶ»£©
Strea Streaming ŌŻ∑—’ŖĶĹĶ◊»•∂‘”¶ńń–© topic
ńō£ŅĽĻ”–ő™ ≤√ī’‚√īĽģ∑÷£¨“‘ľį’‚—ýĽģ∑÷”– ≤√īļ√ī¶ńō£Ņ
“Úő™ kafka topic ∂‘”¶Ńň“ĶőŮ÷–ĶńĺŖŐŚ HBase ĪŪ£¨»ĽļůĺÕÕ®ĻżľŗŅō
HBase ĪŪ≤Ś»ŽŃųŃŅņīŇ–∂Ōł√ĪŪ≤Ś»Ž«ťŅŲ
∂‘”ŕ HBase ĪŪ żĺ›Ķń≤Ś»ŽŃŅĽģ∑÷Ńň5÷÷£¨≤Ś»ŽŃŅŐōĪūīů°Ę≤Ś»ŽŐű ż∂ŗ√ŅŐű żĺ›ŃŅ≤Ľīů°Ę√Ņīő≤Ś»Ž żĺ›ŃŅ…Ŕ żĺ›īů°ĘĪ»ĹŌĺý‘»°Ę≤Ś»Ž…Ŕ≤Ľ∆Ķ∑Ī
∂‘”ŕ≤Ś»ŽŃŅŐōĪūīů£¨Ī»»Áł√ĪŪ∂ľ’ľŃň≤Ś»Ž◊‹ŃŅĶń10%°Ę20%Ķń’‚÷÷ĺÕ∂ņŃĘ≥Ųņī“Ľ’ŇĪŪ∂‘”¶“ĽłŲstreamingŌŻ∑—’Ŗ
≤Ś»ŽŐű ż∂ŗ√ŅŐű żĺ›ŃŅ≤Ľīů£¨ĺÕ «į—≤Ś»ŽĪ»ĹŌ∆Ķ∑ĪĶńŅ…“‘∑Ň‘ŕ“Ľ∆ū£¨’‚ ĪļÚŅ…“‘Ķų–°
timeWindow
√Ņīő≤Ś»Ž żĺ›ŃŅ…Ŕ żĺ›īů£¨ĺÕ «Ņ…“‘ŅīľŻ≤Ś»Ž√Ņīő∂ľ «1000Őű£¨2000Őű£¨”––© ĪľšľšłŰ£¨ĺÕŅ…“‘Ķųīů
timeWindow ĪľšľšłŰ£¨ maxRatePerPartition …Ť÷√īů“ĽĶ„
Ī»ĹŌĺý‘»ĺÕļ√įžŃň£¨ļ‹ļ√…Ť÷√≤ő ż
≤Ś»Ž…Ŕ≤Ľ∆Ķ∑Ī£¨Ņ…“‘ĶųīůtimeWindowĶĹľł√Ž£¨…ű÷ŃŐę…Ŕ£¨Őę≤Ľ∆Ķ∑ĪŅ…“‘ľŐ–ÝĶųīů
ļ√ī¶īůľ“”¶ł√“≤Ņī≥ŲņīŃňį…£¨◊ ‘īĶńļŌņŪņŻ”√£¨∂‘ streaming
Ķń”ŇĽĮ£¨ timeWindow °Ę maxRatePerPartition ∂‘”¶≤ĽÕ¨ĪŪ£¨‘Ųľ”ļÕŅō÷∆Ńň≤Ę∑ĘŃŅ
6.2 Streaming»őőŮĶńľŗŅō
∂‘”ŕSpark Streaming jobĶńľŗŅō£¨◊‘īÝĶńStreaming UIń‹ŅīĶĹĺŖŐŚĶń“Ľ–©ŃųŃŅ£¨ ĪľšĶ»–ŇŌĘ£¨Ķę «»Ī…ŔŃň“ĽłŲÕ®÷™£¨”ŕ «ľÚĶ•ĶńŅ™∑ĘŃň“ĽłŲ°£‘ŕľŗŅō’‚“ĽŅť“≤ŌŽŃň≤Ľ…Ŕ∑Ĺįł£¨Ī»»ÁľŗŅōpid£¨Õ®Ļżshell»•ľŗŅō£¨ĽÚ’Ŗ÷ĪĹ”Ķų”√‘ī¬ŽņÔ√śĶń∑Ĺ∑®£¨∂ľ≥Ę ‘Ļż£¨”–Ķń“™√ī√ĽīÔĶĹ‘§∆ŕĶń–ßĻŻ£¨“™√ī”–Ķń≤Ľ «ļ‹ļ√ő¨Ľ§Ņ™∑Ę≥…ĪĺłŖ°£
◊Ó÷’—°Ńň“ĽłŲĪ»ĹŌľÚĶ•Ķń£¨Ķę «”÷ń‹īÔĶĹ“Ľ∂®–ßĻŻĶń£¨Õ®ĻżpyŇņ≥ś£¨ĶĹ‘≠ ľĶń
streaming UI ĹÁ√ś»•ĽŮ»°ĶĹĺŖŐŚĶń–ŇŌĘ£¨ņīľŗŅō£¨ĶĹīÔ„–÷ĶĺÕ∑ĘňÕ” ľĢ£¨◊‹ŐŚ≤Ĺ÷Ť»ÁŌ¬£ļ
Õ®Ļż job name ‘ŕ yarn 8088 ĹÁ√ś/cluster/apps/RUNNING’“
ApplicationMasterURL Ķō÷∑
»ĽļůÕ®Ļżł√Ķō÷∑ĶĹ streaming ĹÁ√śľŗŅōĺŖŐŚ Streaming
jobĶńScheduling Delay °Ę Processing Time ÷Ķ
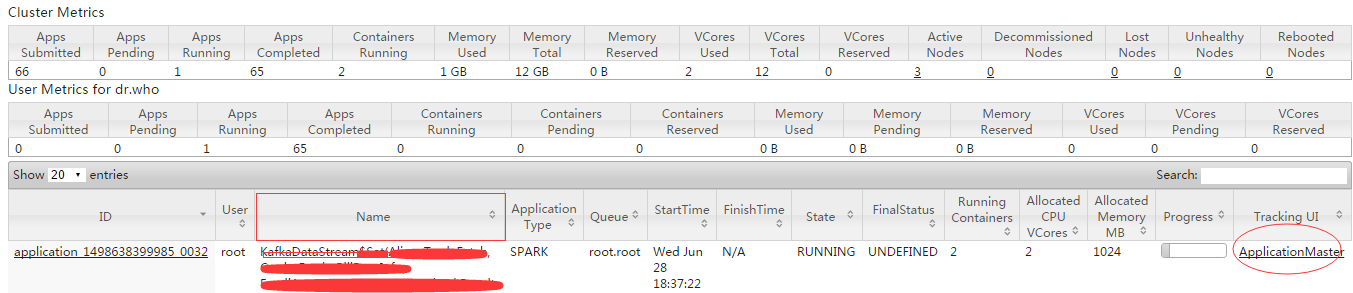
yarn 8088ĹÁ√ś/cluster/apps/RUNNING
ĺŖŐŚīķ¬Ž£ļ
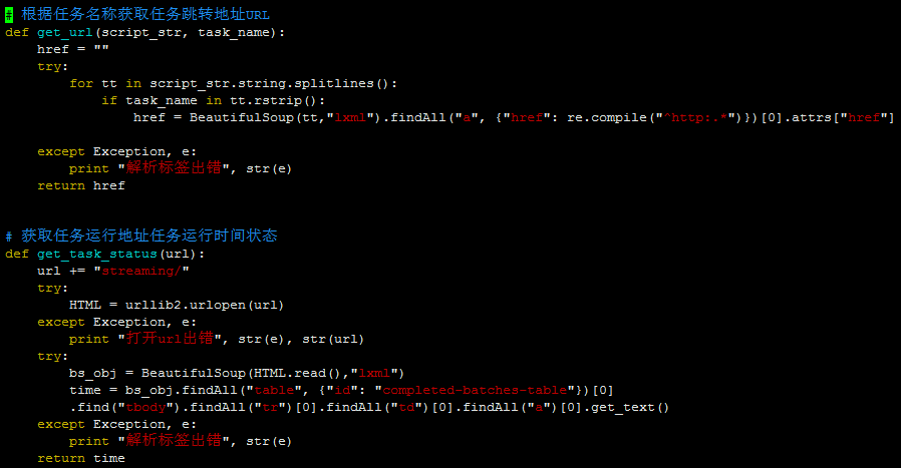
Python ľŗŅōŇņ≥ś ” ľĢÕ®÷™ |









