| Spark
Streaming”¶”√”Ž Ķ’ĹŌĶŃ–įŁņ®“‘Ō¬Ńý≤Ņ∑÷ńŕ»›£ļ
1.Ī≥ĺį”Žľ‹ĻĻłń‘ž
2.Õ®Ļżīķ¬Ž ĶŌ÷ĺŖŐŚŌłĹŕ£¨≤Ę‘ň––ŌÓńŅ
3.∂‘StreamingľŗŅōĶńĹť…‹“‘ľįĹ‚ĺŲ Ķľ ő Ő‚
4.∂‘ŌÓńŅ◊Ų—Ļ≤‚”ŽŌŗĻōĶń”ŇĽĮ
5.Streaming≥÷–ݔҼĮ÷ģHBase
6.Ļ‹ņŪStreaming»őőŮ
Īĺ∆™ő™Ķŕ“Ľ≤Ņ∑÷£¨įŁņ®Ī≥ĺį”Žľ‹ĻĻłń‘ž°ĘÕ®Ļżīķ¬Ž ĶŌ÷ĺŖŐŚŌłĹŕ≤Ę‘ň––ŌÓńŅ°Ę∂‘StreamingľŗŅōĶńĹť…‹“‘ľįĹ‚ĺŲ Ķľ ő Ő‚°Ę∂‘ŌÓńŅ◊Ų—Ļ≤‚”ŽŌŗĻōĶń”ŇĽĮ°£
“Ľ°ĘĪ≥ĺį”Žľ‹ĻĻłń‘ž
1.1 ő Ő‚√Ť Ų
”–“ĽŅť“ĶőŮ÷ų“™ «◊ŲŇņ≥ś◊•»°”Ž żĺ› š≥Ų£¨Õ®Ļżīů żĺ›’‚ĪŖŐŠĻ©ĶńSOA∑ĢőŮ»ŽŅ‚ĶĹHBase,ľ‹ĻĻīů÷¬»ÁŌ¬£ļ

ľ‹ĻĻłń‘ž÷ģ«į
“‘∂‘”ŕ“‘…ŌĶńľ‹ĻĻīś‘ŕ“Ľ–©ő Ő‚£¨ő“√«Ņ…“‘ŅīľŻ żĺ›‘ŕDubbox∑ĢőŮĹ◊∂őī¶ņŪļů÷ĪĹ”Õ®ĻżHBase API»ŽŅ‚ŃňHBase£¨÷–ľš≤Ę√Ľ◊Ų»őļőĽļ≥Ś£¨“™ «HBase≥ŲŌ÷Ńňő Ő‚’ŻłŲľĮ»ļ∂ľÕÍĶį£¨√Ľ∑®–ī»Ž żĺ›£¨ żĺ›ĽĻ∂™ ߣ¨HBase’‚ĪŖ—ĻѶ“≤ŌŗĶĪīů£¨’Ž∂‘’‚“ĽĶ„£¨∂‘»ŽŅ‚HBase’‚łŲĹ◊∂ő◊ŲŃň“Ľ–©łń‘ž°£
1.2 ľ‹ĻĻłń‘ž
łń‘žļůĶńľ‹ĻĻ£¨Ňņ≥śÕ®ĻżĹ”Ņŕ∑ĢőŮ£¨»ŽŅ‚ĶĹKafka£¨Spark streaming»•ŌŻ∑—kafkaĶń żĺ›£¨»ŽŅ‚ĶĹHBase.ļň–ń◊ťľĢ»ÁŌ¬Õľňý ĺ£ļ
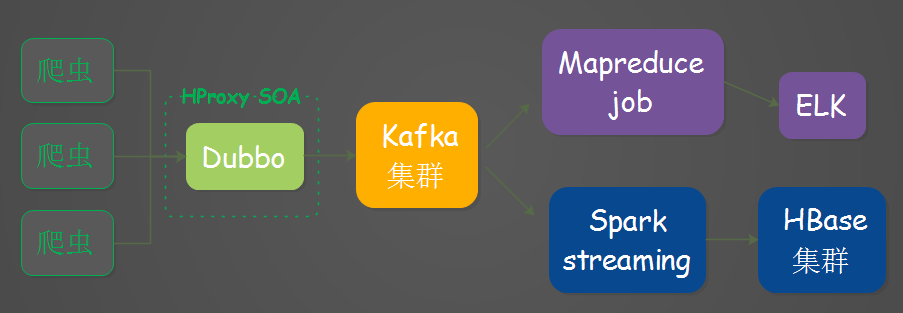
ľ‹ĻĻłń‘žÕľ
ő™ ≤√ī≤Ľ÷ĪĹ”»ŽŅ‚ĶĹHBase£¨’‚—ý◊Ų”– ≤√īļ√ī¶£Ņ
1.ĽļĹ‚ŃňHBase’‚ĪŖ∑Ś÷ĶĶń—ĻѶ£¨≤Ę«“ŃųŃŅŅ…Ņō£Ľ
2.HBaseľĮ»ļ≥ŲŌ÷ő Ő‚ĽÚ’ŖĻ“ĶŰ£¨∂ľ≤ĽĽŠ’’≥… żĺ›∂™ ßĶńő Ő‚£Ľ
3.‘Ųľ”ŃňÕŐÕ¬ŃŅ°£
1.3 ő™ ≤√ī—°‘ŮKafkaļÕSpark streaming
1.”…”ŕKafkaňŁľÚĶ•Ķńľ‹ĻĻ“‘ľį≥Ų…ęĶńÕŐÕ¬ŃŅ£Ľ
2.Kafka”ŽSpark streaming“≤”–◊®√ŇĶńľĮ≥…ń£Ņť£Ľ
3.SparkĶń»›īŪ,“‘ľįŌ÷‘ŕľľ űŌŗĶĪĶń≥… ž°£
∂Ģ°ĘÕ®Ļżīķ¬Ž ĶŌ÷ĺŖŐŚŌłĹŕ£¨≤Ę‘ň––ŌÓńŅ
»ĽļůĺÕŅ™ ľ–īīķ¬ŽŃň£¨◊‹ŐŚňľ¬∑ĺÕ «£ļ
1.put żĺ›ĻĻ‘žjson żĺ›£¨–ī»ŽKafka£Ľ
2.Spark Streaming»őőŮ∆Ű∂Įļů ◊Ō»»•Zookeeper÷–»•∂Ń»°offset,◊ť◊į≥…fromOffsets£Ľ
3.Spark Streaming ĽŮ»°ĶĹfromOffsetsļůÕ®ĻżKafkaUtils.createDirectStream»•ŌŻ∑—KafkaĶń żĺ›£Ľ
4.∂Ń»°Kafka żĺ›∑ĶĽō“ĽłŲInputDStreamĶń–ŇŌĘ£¨foreachRDDĪťņķ£¨Õ¨ Īľ«¬ľ∂Ń»°ĶĹĶńoffsetĶĹzk÷–£Ľ
5.–ī»Ž żĺ›ĶĹHBase°£
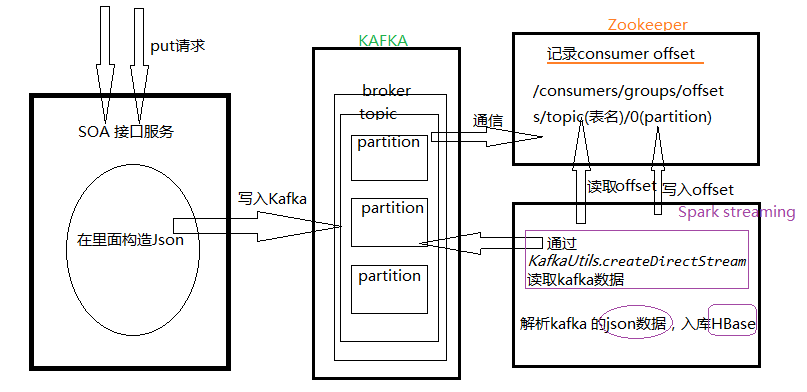
ŌÍŌł“ĽĶ„Ķńľ‹ĻĻÕľ
2.1 ≥ű ľĽĮ”ŽŇš÷√ľ”‘ō
Ō¬√ś «“Ľ–©Ĺ” ’≤ő ż£¨ľ”‘ōŇš÷√£¨ĽŮ»°Ňš÷√÷–Ķńtopic£¨ĽĻ”–≥ű ľĽĮŇš÷√£¨īķ¬Ž»ÁŌ¬£ļ
| //Ĺ” ’≤ő ż
val Array(kafka_topic, timeWindow, maxRatePerPartition)
= args
//ľ”‘ōŇš÷√
val prop: Properties = new Properties()
prop.load(this.getClass().getResourceAsStream
("/kafka.properties"))
val groupName = prop.getProperty("group.id")
//ĽŮ»°Ňš÷√őńľĢ÷–Ķńtopic
val kafkaTopics: String = prop.getProperty("kafka.topic."
+ kafka_topic)
if (kafkaTopics == null || kafkaTopics.length
<= 0) {
System.err.println("Usage: KafkaDataStream
<kafka_topic>
is number from kafka.properties")
System.exit(1)
}
val topics: Set[String] = kafkaTopics.split(",").toSet
val kafkaParams = scala.collection.immutable.Map[String,
String](
"metadata.broker.list" -> prop.getProperty("bootstrap.servers"),
"group.id" -> groupName,
"auto.offset.reset" -> "largest")
val kc = new KafkaCluster(kafkaParams)
//≥ű ľĽĮŇš÷√
val sparkConf = new SparkConf()
.setAppName(KafkaDataStream.getClass.getSimpleName
+ topics.
toString())
.set("spark.yarn.am.memory", prop.getProperty("am.memory"))
.set("spark.yarn.am.memoryOverhead",
prop.getProperty
("am.memoryOverhead"))
.set("spark.yarn.executor.memoryOverhead",
prop.getProperty
("executor.memoryOverhead"))
.set("spark.streaming.kafka.maxRatePerPartition",
maxRatePerPartition) //īňī¶ő™√Ņ√Ž√ŅłŲpartitionĶńŐű ż
.set("spark.serializer", "org.apache.spark.serializer
.KryoSerializer")
.set("spark.reducer.maxSizeInFlight",
"1m")
val sc = new SparkContext(sparkConf)
val ssc = new StreamingContext(sc, Seconds(timeWindow.toInt))
//∂ŗ…Ŕ√Žī¶ņŪ“Ľīő«Ž«ů |
÷Ľ «–Ť“™◊Ę“‚“ĽŌ¬£¨’‚ņÔĶńKafkaCluster£¨–Ť“™į—‘ī¬ŽŅĹĪīĻżņī£¨–řłń“ĽŌ¬£¨“Úő™ņÔ√ś”––©∑Ĺ∑® «ňĹ”–Ķń°£copyĻżņīļůłńő™publicľīŅ…°£
2.2 ŃīĹ”ZK
◊Ę“‚£ļ’‚ņÔĶńZKStringSerializer£¨–Ť“™į—‘ī¬ŽŅĹĪīĻżņī£¨–řłń“ĽŌ¬°£
| //zk
val zkClient = new ZkClient(prop.getProperty("zk.connect")
, Integer.MAX_VALUE,
100000, ZKStringSerializer)
val messageHandler = (mmd: MessageAndMetadata[String,
String]) =>
(mmd.topic, mmd.message()) |
2.3 ◊ť◊įfromOffsets
◊ť◊įfromOffsets£¨createDirectStreamĹ” ’Ķń «“ĽłŲmapĶńĹŠĻĻ£¨ňý“‘Ņ…“‘÷ß≥÷∂ŗłŲtopicĶńŌŻ∑—°£
| var
fromOffsets: Map[TopicAndPartition, Long] =
Map()
//∂ŗłŲpartitionĶńoffset
//÷ß≥÷∂ŗłŲtopic : Set[String]
topics.foreach(topicName => {
//»•brokers÷–ĽŮ»°partition żŃŅ£¨◊Ę“‚£ļ–¬‘Ųpartitionļů–Ť“™÷ō∆Ű
val children = zkClient.countChildren(ZkUtils.getTopicPar
titionsPath(topicName))
for (i <- 0 until children) {
//kafka consumer ÷– «∑Ů”–ł√partitionĶńŌŻ∑—ľ«¬ľ£¨»ÁĻŻ√Ľ”–…Ť÷√ő™0
val tp = TopicAndPartition(topicName, i)
val path: String = s"${new ZKGroupTopicDirs(groupName,
topicName).consumerOffsetDir}/$i"
if (zkClient.exists(path)) {
fromOffsets += (tp -> zkClient.readData[String](path).toLong)
} else {
fromOffsets += (tp -> 0)
}
}
}) |
2.4 Õ®ĻżcreateDirectStreamĹ” ‹ żĺ›
Ļ”√KafkaUtilsņÔ√śĶńcreateDirectStream∑Ĺ∑®»•ŌŻ∑—kafka żĺ›£¨createDirectStream Ļ”√Ķń «kafkaľÚĶ•ĶńConsumer
API£¨ňý“‘–Ť“™◊‘ľļ»•Ļ‹ņŪoffset,ő“√«į—offset–ī»ŽĶĹzk÷–£¨’‚—ý“≤∑ĹĪ„Ńň“Ľ–©ľŗŅō»ŪľĢ∂Ń»°ľ«¬ľ°£
| //īīĹ®Kafka≥÷–Ý∂Ń»°Ńų£¨Õ®Ļżzk÷–ľ«¬ľĶńoffset
val messages: InputDStream[(String, String)]
=
KafkaUtils.createDirectStream[String, String,
StringDecoder,
StringDecoder, (String,
String)](ssc, kafkaParams, fromOffsets,
messageHandler) |
2.5 »ŽŅ‚
»ŽŅ‚HBase£ļ
| // żĺ›≤Ŕ◊ų
messages.foreachRDD(rdd => {
val offsetsList: Array[OffsetRange] = rdd.asInstance
Of[HasOffsetRanges].offsetRanges
//data ī¶ņŪ
rdd.foreachPartition(partitionRecords =>
{
//TaskContext …ŌŌ¬őń
val offsetRange: OffsetRange = offsetsList(TaskContext
.get.partitionId)
logger.info(s"${offsetRange.topic} ${offsetRange.partit
ion} ${offsetRange.fromOffset} ${offsetRange.untilOffset}")
//TopicAndPartition ÷ųĻĻ‘ž≤ő żĶŕ“ĽłŲ «topic£¨Ķŕ∂ĢłŲ «Kafka
partition id
val topicAndPartition = TopicAndPartition(offsetRange.topic,
offsetRange.partition)
val either = kc.setConsumerOffsets(groupName,
Map((topicAnd
Partition, offsetRange.untilOffset))) // «
if (either.isLeft) {
logger.info(s"Error updating the offset
to Kafka cluster:
${either.left.get}")
}
partitionRecords.foreach(data => {
HBaseDao.insert(data)
})
})
}) |
≤Ś»Ž żĺ›ĶĹĺŖŐŚHBase żĺ›Ņ‚£ļ
| /**
*
* ≤Ś»Ž żĺ›ĶĹ HBase
*
* ≤ő ż( tableName , json ) )£ļ
*
* JsonłŮ Ĺ£ļ
* {
* "rowKey": "00000-0",
* "family:qualifier": "value",
* "family:qualifier": "value",
* ......
* }
*
* @param data
* @return
*/
def insert(data: (String, String)): Boolean
= {
val t: HTable = getTable(data._1) //HTable
try {
val map: mutable.HashMap[String, Object] =
JsonUtils.json2Map(data._2)
val rowKey: Array[Byte] = String.valueOf(map.
get("rowKey")).getBytes //rowKey
val put = new Put(rowKey)
for ((k, v) <- map) {
val keys: Array[String] = k.split(":")
if (keys.length == 2){
put.addColumn(keys(0).getBytes, keys(1).getBytes
, String.valueOf(v).getBytes)
}
}
Try(t.put(put)).getOrElse(t.close())
true
} catch {
case e: Exception =>
e.printStackTrace()
false
}
} |
2.6 ‘ň––≤Ę≤ťŅīĹŠĻŻ
‘ň––√ŁŃÓ£ļ
| /opt/cloudera/parcels/CDH/bin/spark-submit
--master
yarn-client --class
com.xiaoxiaomo.streaming.KafkaData
Stream hspark-1.0.jar
1 3 1000
|
‘ň––ļůŅ…“‘»•spark UI÷–»•≤ťŅīŌŗĻō‘ň––«ťŅŲ£¨UI÷–ĺŖŐŚŌłĹྯŌ¬őń°£
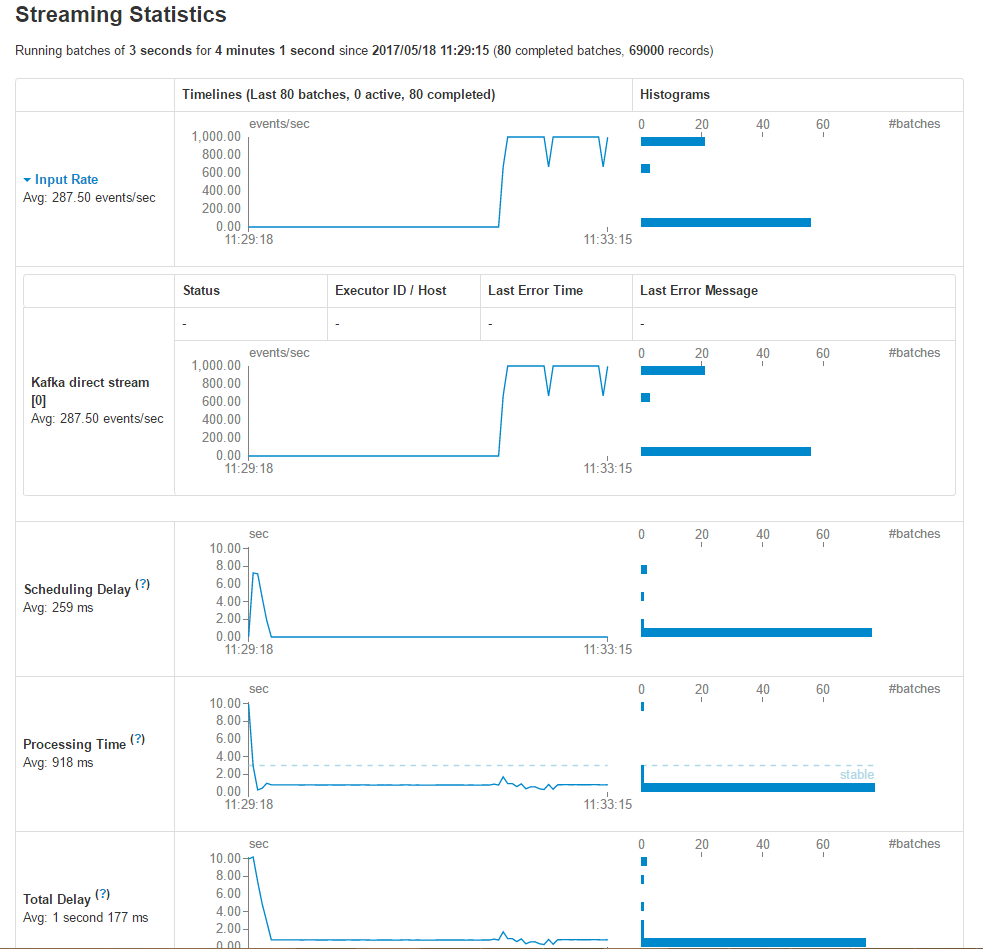
Streaming Statistics żĺ›Õ≥ľ∆Õľ
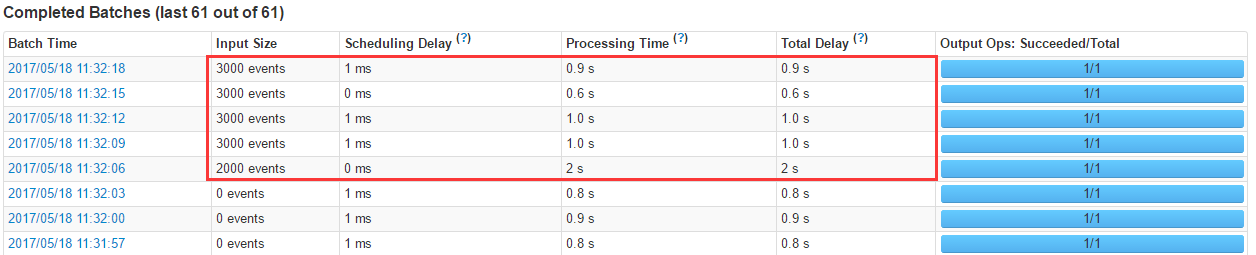
Completed Batches
»ż°Ę∂‘StreamingľŗŅōĶńĹť…‹“‘ľįĹ‚ĺŲ Ķľ ő Ő‚
’‚≤Ņ∑÷÷ų“™‘ŕīķ¬Ž‘ň––∆ūņīĶń«ťŅŲŌ¬ņīŅī“ĽŌ¬»őőŮĶń‘ň––«ťŅŲ÷ų“™ «streamingĶńľŗŅōĹÁ√ś£¨“‘ľįő“√«‘ű√ī»•Õ®ĻżľŗŅōĹÁ√ś∑ĘŌ÷ő Ő‚ļÕĹ‚ĺŲő Ő‚°£
3.1 ľŗŅō
ĻŔÕÝ÷–÷ł≥Ų£¨spark÷–◊®√Ňő™SparkStreaming≥Ő–ÚĶńľŗŅō…Ť÷√Ńň∂ÓÕ‚ĶńÕĺĺ∂£¨ĶĪ Ļ”√StreamingContext Ī£¨‘ŕWEB
UI÷–ĽŠ≥ŲŌ÷“ĽłŲ°ĪStreaming°ĪĶń—°ŌÓŅ®£ļ

WEB UI÷–Ķń°įStreaming°Ī—°ŌÓŅ®
‘ŕīň—°ŌÓŅ®ńŕ£¨Õ≥ľ∆Ķńńŕ»›’Ļ ĺ»ÁŌ¬£ļ

Streaming ◊īŐ¨Õľ
Spark streaming ī¶ņŪňŔ∂»ő™3s“Ľīő£¨√Ņīő1000Őű°£
Kafka product √Ņ√Ž1000Őű żĺ›£¨”Ž…Ō√śspark consumerŌŻ∑—’Ŗ«°ļ√ŌŗĶ»°£ĹŠĻŻ£ļ żĺ›ŃŅīůĶľ÷¬Ľż—Ļ£¨’‚łŲĻż≥Ő÷–active
BatchesĽŠ‘ĹĪš‘Ĺīů°£
“Úő™ļŲ¬‘Ńň Ķľ ĶńProcessing time£ļ
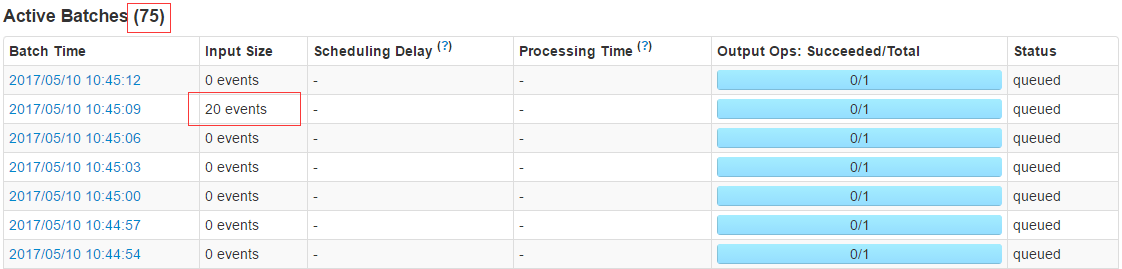
Active Batches
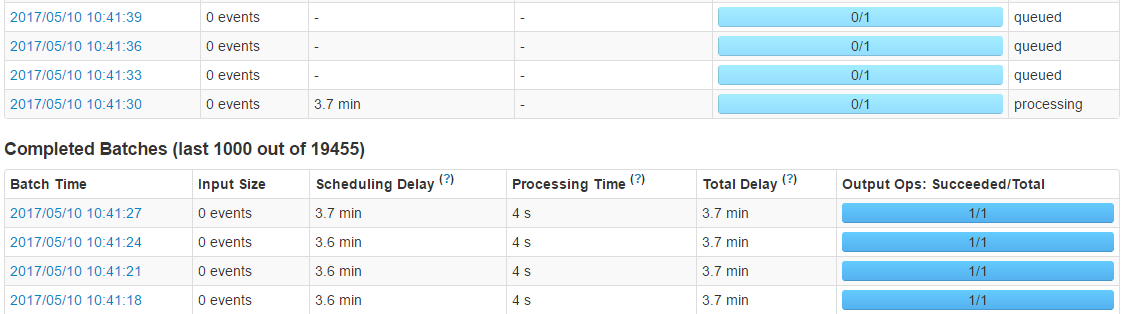
Completed Batches
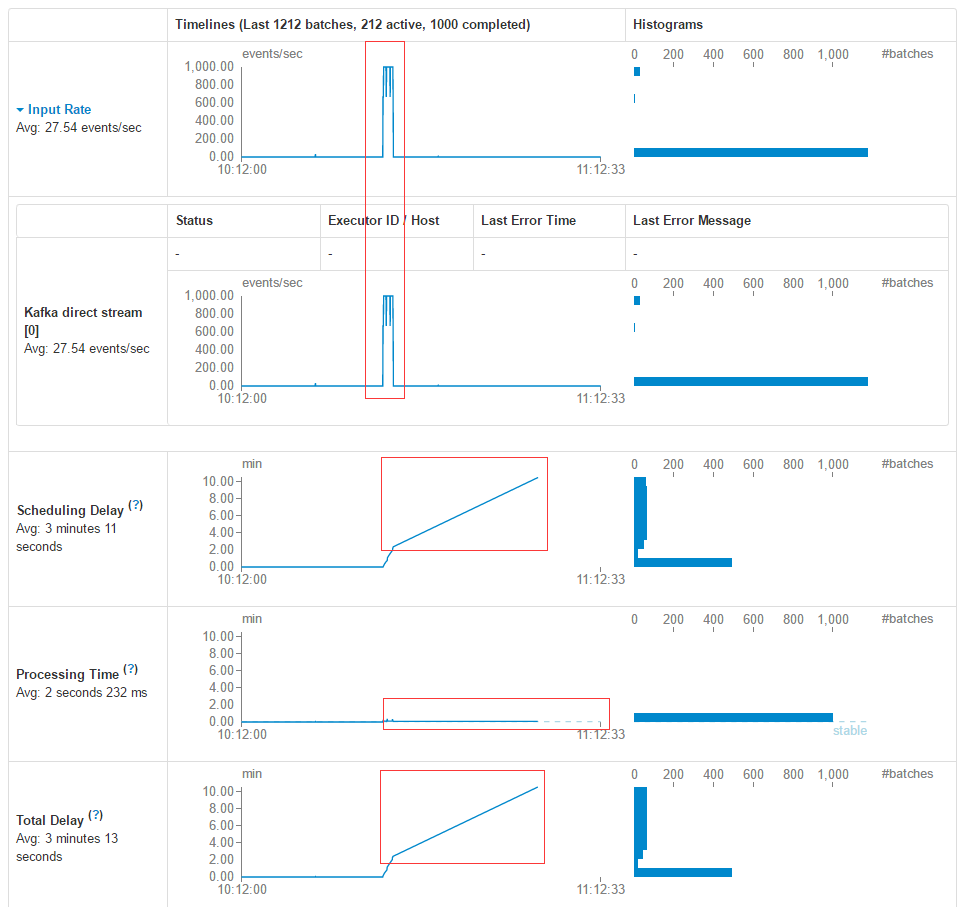
Streaming Batches∂‘”¶Ķń«ų ∆Õľ
’‚∆š÷–įŁņ®Ĺ” ‹Ķńľ«¬ľ żŃŅ£¨√Ņ“ĽłŲbatchńŕī¶ņŪĶńľ«¬ľ ż£¨ī¶ņŪ Īľš£¨“‘ľį◊‹Ļ≤ŌŻļńĶń Īľš°£‘ŕ…Ō Ų≤ő ż÷ģ÷–◊Ó÷ō“™ĶńŃĹłŲ≤ő ż∑÷Īū «Porcessing
Time “‘ľį Scheduling Delay£ļ
1.Porcessing Time”√ņīÕ≥ľ∆√ŅłŲbatchńŕī¶ņŪ żĺ›ňýŌŻ∑—Ķń Īľš
2.Scheduling Delay”√ņīÕ≥ľ∆‘ŕĶ»īżĪĽī¶ņŪňýŌŻ∑—Ķń Īľš
»ÁĻŻPTĪ»SDīů£¨ĽÚ’ŖSD≥÷–Ý…Ō…ż£¨’‚ĺÕĪŪ√ųīňŌĶÕ≥≤Ľń‹∂‘≤ķ…ķĶń żĺ› Ķ ĪŌž”¶£¨ĽĽĺšĽįņīňĶĺÕ «£¨≥ŲŌ÷Ńňī¶ņŪ Ī—”£¨√ŅłŲbatch
time ńŕĶńī¶ņŪňŔ∂»–°”ŕ żĺ›Ķń≤ķ…ķňŔ∂»°£
‘ŕ’‚÷÷«ťŅŲŌ¬£¨∂Ń’Ŗ–Ť“™ŌŽ∑®ľű…Ŕ żĺ›Ķńī¶ņŪňŔ∂»£¨ľī–Ť“™ŐŠ…żī¶ņŪ–߬ °£
3.2 ő Ő‚∑ĘŌ÷
‘ŕő“◊Ų—Ļ≤‚Ķń ĪļÚ£¨ Spark streaming ī¶ņŪňŔ∂»ő™3s“Ľīő£¨√Ņīő1000Őű°£
Kafka product√Ņ√Ž1000Őű żĺ›£¨ ”Ž…Ō√śspark consumerŌŻ∑—’Ŗ«°ļ√ŌŗĶ»°£”ŕ «ĺÕĽŠ żĺ›ŃŅīůĶľ÷¬Ľż—Ļ£¨’‚łŲĻż≥Ő÷–active
BatchesĽŠ‘ĹĪš‘Ĺīů°£◊Óļů∑ĘŌ÷Ńň“ĽłŲő Ő‚£ļ
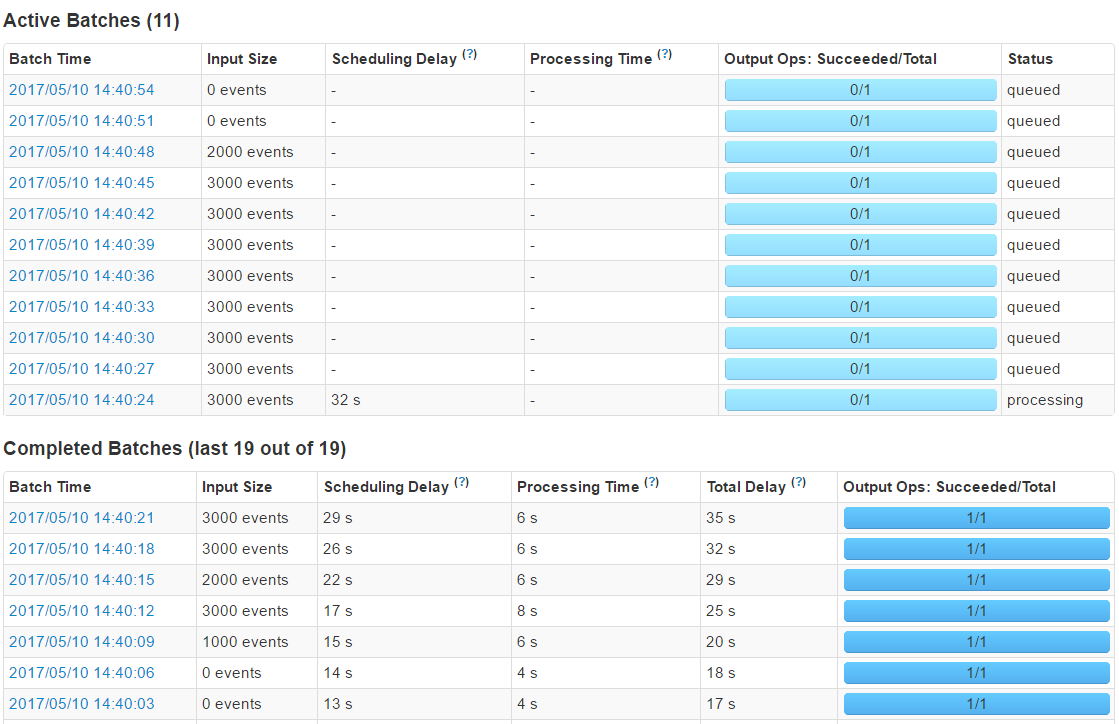
Streaming Batches∂‘”¶Ķń«ų ∆Õľ
ĶĪ—Ļ≤‚∑Ś÷ĶĻżļůInput Size=0 events£¨ Īľš»‘»Ľ≤Ľľű£¨∆śĻ÷£°

Streaming Batches“Ľ–©“ž≥£«ťŅŲÕľ
≤ťŅī√ĢłŲĺŖŐŚstage£ļ

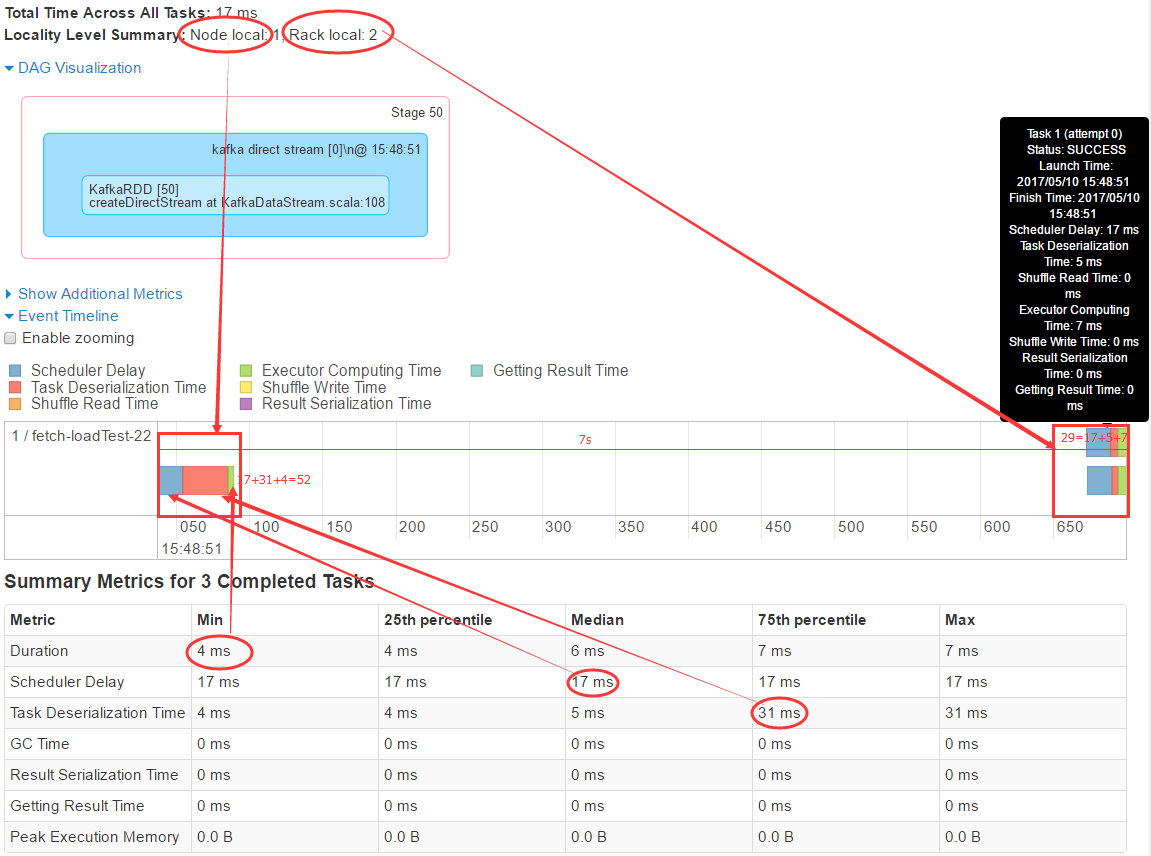
StreamingĺŖŐŚĶństage–ŇŌĘ
ī”Õľ÷–, ő“√«Ņ…“‘ŅīĶĹSpark◊‹Ļ≤Ķų∂»∑÷∑ĘŃňŃĹŇķīőtask set, √ŅłŲtask setĶńī¶ņŪ(ļ¨–ÚŃ–ĽĮļÕ—Ļňű÷ģņŗĶńĻ§◊ų)∂ľ≤Ľ≥¨Ļż100ļŃ√Ž£¨ń«√īł√StageļőņīŌŻļń4sńō£Ņ¬ż◊Ň£¨√≤ň∆’‚ŃĹŇķīőĶńtask
set∑÷∑ĘĶń ĪľšŌŗłŰĶ√”–Ķ„≥§į°£¨łŰŃň4√Ž◊ů”“°£ő™ ≤√īĽŠłŰ’‚√īĺÕ≤ŇĶų∂»“Ľīőńō£Ņ
īňī¶“™“ż»Ž“ĽłŲŇš÷√ŌÓ°įspark.locality.wait°Ī(ń¨»ŌĶ»īż3s)£¨ňŁŇš÷√ŃňĪĺĶōĽĮĶų∂»ĹĶľ∂ňý–Ť“™Ķń Īľš°£’‚ņԳғ™≤Ļ≥šŌ¬SparkĪĺĶōĽĮĶų∂»Ķń÷™ ∂£¨SparkĶńtask“Ľį„∂ľĽŠ∑÷∑ĘĶĹňŁňý–Ť żĺ›Ķńń«łŲĹŕĶ„£¨’‚≥∆÷ģő™°ĪNODE_LOCAL°Ī£¨Ķę‘ŕ◊ ‘ī≤Ľ◊„Ķń«ťŅŲŌ¬£¨ żĺ›ňý‘ŕĹŕĶ„őīĪō”–◊ ‘īī¶ņŪtask£¨“ÚīňSpark‘ŕĶ»īżŃň°įspark.locality.wait°ĪňýŇš÷√Ķń Īľš≥§∂»ļů£¨ĽŠÕň∂Ý«ů∆šīő£¨∑÷∑ĘĶĹ żĺ›ňý‘ŕĹŕĶ„ĶńÕ¨“ĽłŲĽķľ‹Ķń∆šňŁĹŕĶ„…Ō£¨’‚ «°įRACK_LOCAL°Ī°£ĶĪ»Ľ£¨“≤”–łŁ≤“Ķń£¨ĺÕ «‘ŔĶ»Ńň“Ľ∂ő°įspark.locality.wait°ĪĶń Īľš≥§∂»ļů£¨ł…īŗňśĪ„’““ĽŐ®Ľķ∆ų»•Ň‹task£¨’‚ĺÕ «°įANY°Ī≤Ŗ¬‘Ńň°£

Streaming ‘ī¬Ž
∂Ýī”…ŌņżŅīĶĹ, ľī Ļ”√◊Ó≤ÓĶń°ĪANY°Ī≤Ŗ¬‘ĹÝ––Ķų∂»£¨task setĶńī¶ņŪ“≤÷Ľ «Ľ®Ńň100ļŃ√Ž£¨“Úīň£¨√ĽĪō“™∑«Ķ√ő™Ńň°ĪNODE_LOCAL°Ī≤Ŗ¬‘Ķń…ķ–ß∂Ý»•Ķ»īżń«√ī≥§Ķń Īľš£¨ŐōĪū «‘ŕŃųľ∆ň„’‚÷÷≥°ĺį…Ō°£ňý“‘į—°įspark.locality.wait°ĪĻŻ∂ŌĶų–°£¨ī”1√ŽĶĹ500ļŃ√Ž£¨◊Óļůł…īŗĶųĶĹ100ļŃ√Žň„Ńň°£
| spark-submit
®Cmaster yarn-client ®Cconf spark.driver.memory=256m
®Cclass com.KafkaDataStream
®Cnum-executors 1 ®Cexecutor-memory
256m ®Cexecutor-cores
2 ®Cconf spark.locality.wait=100ms hspark-1.0.jar |
ĶųŃň÷ģļůĶńī¶ņŪ Īľšő™0.7s£ļ
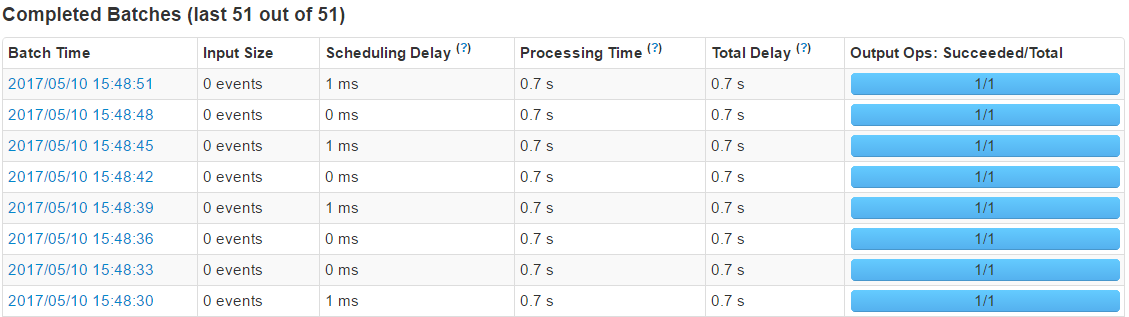
Streaming Completed
Batches’ż≥£
ĺŖŐŚļń Ī»ÁŌ¬£ļ
Streaming ĺŖŐŚļń Ī–ŇŌĘÕľ
ňń°Ę∂‘ŌÓńŅ◊Ų—Ļ≤‚”ŽŌŗĻōĶń”ŇĽĮ
∂‘ŌÓńŅ◊Ų—Ļ≤‚”ŽŌŗĻōĶń”ŇĽĮ£¨÷ų“™ī”ńŕīś(executor-memoryļÕdriver-memory)°Ęnum-executors°Ęexecutor-cores£¨“‘ľįīķ¬Ž≤„√ś◊Ų“Ľ–©≤‚ ‘ļÕłń‘ž°£
4.1 —Ļ≤‚
| spark-submit
®Cmaster yarn-client ®Cconf spark.
driver.memory=256m
®Cclass com.xiaoxiaomo.KafkaDataStream
®Cnum-executors 1
®Cexecutor-memory 256m ®Cexecutor-cores 2
®Cconf spark.locality.wait=100ms
hspark.jar 3 1000 |
Spark streaming ī¶ņŪňŔ∂»ő™3s“Ľīő£¨√Ņīő1000Őű°£
Kafka product √Ņ√Ž1000Őű żĺ›£¨ ”Ž…Ō√śspark consumerŌŻ∑—’Ŗ«°ļ√ŌŗĶ»°£ĹŠĻŻ£ļ żĺ›ŃŅīůĶľ÷¬Ľż—Ļ£¨’‚łŲĻż≥Ő÷–active
BatchesĽŠ‘ĹĪš‘Ĺīů°£
Ķų’ŻKafka product √Ņ√Ž600Őű żĺ›£¨īś‘༿—Ļ£¨Ķę“—ĺ≠≤Ľ—Ō÷ō£ļ
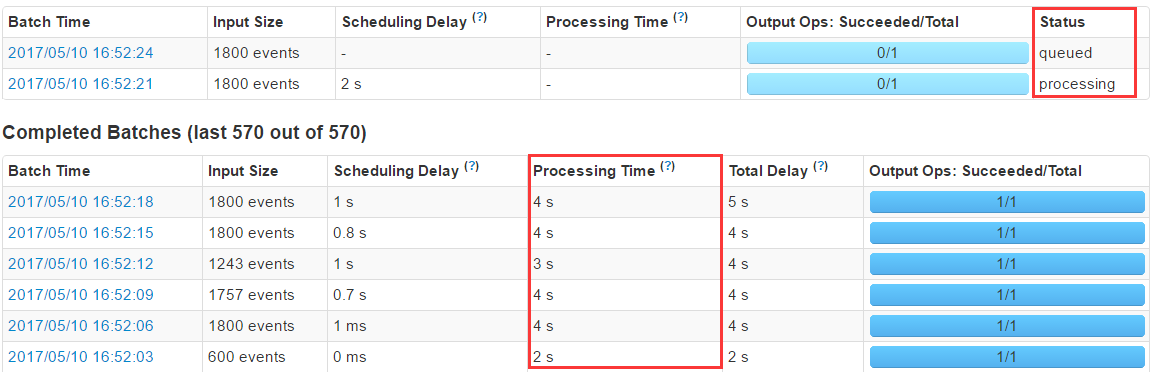
Kafka product √Ņ√Ž600Őű żĺ›£¨īś‘༿—Ļ
Ķų’ŻKafka product √Ņ√Ž500Őű żĺ›£¨ő™ŌŻ∑—’Ŗ50%£¨≤‚ ‘ĹŠĻŻŌ‘ ĺ’ż≥££¨Ķ»īż Īľšļ‹ő»∂®£ļ
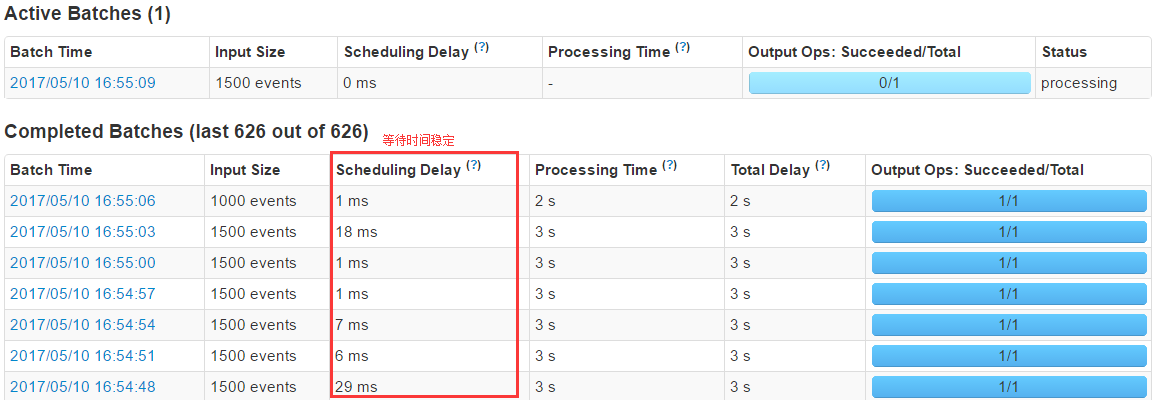
Kafka product √Ņ√Ž500Őű żĺ›£¨’ż≥£
Ķę «°£īň Ī√Ņ√ŽÕŐÕ¬ŃŅő™500Ō‘»Ľ≤ĽĻĽ£¨Õ®ĻżĶų’Żľš–™ Ķľ Ķ»£¨∑ĘŌ÷≤Ę√Ľ”–ĪšĽĮ£ļ
| spark-submit
®Cmaster yarn-client ®Cconf spark.driver.memory=256m
®Cclass com.xiaoxiaomo.KafkaDataStream ®Cnum-executors
1 ®Cexecutor-memory 256m ®Cexecutor-cores 2 ®Cconf
spark.locality.wait=100ms hspark.jar 2 2000
Spark streaming ī¶ņŪňŔ∂»ő™2s“Ľīő£¨√Ņīő2000Őű |
Kafka product √Ņ√Ž500Őű żĺ›£¨Ņ…“‘ŅīľŻ√Ľ”–‘ŕ÷ł∂® ĪľšńŕŌŻ∑—ÕÍ żĺ›£¨’’≥… żĺ›Ľż—Ļ£¨≤Ę∑ĘŌ¬ĹĶŃň°£
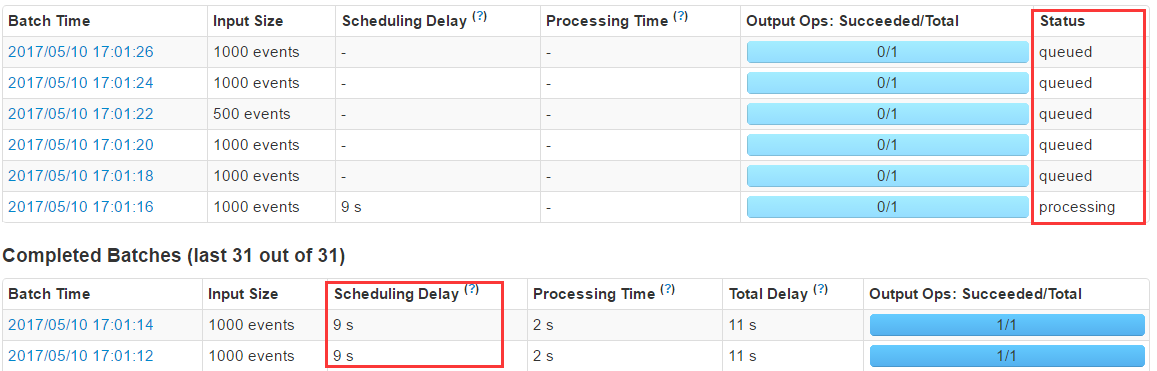
Kafka product √Ņ√Ž500Őű żĺ›£¨√Ľ”–‘ŕ÷ł∂® ĪľšńŕŌŻ∑—ÕÍ
4.2 ∑÷őŲ‘≠“Ú
∑÷őŲ‘≠“Ú£¨∑ĘŌ÷īů≤Ņ∑÷ļń Ī∂ľ‘ŕī¶ņŪ żĺ›’‚—ý“ĽĹ◊∂ő£¨»ÁŌ¬Õľňý ĺ£ļ
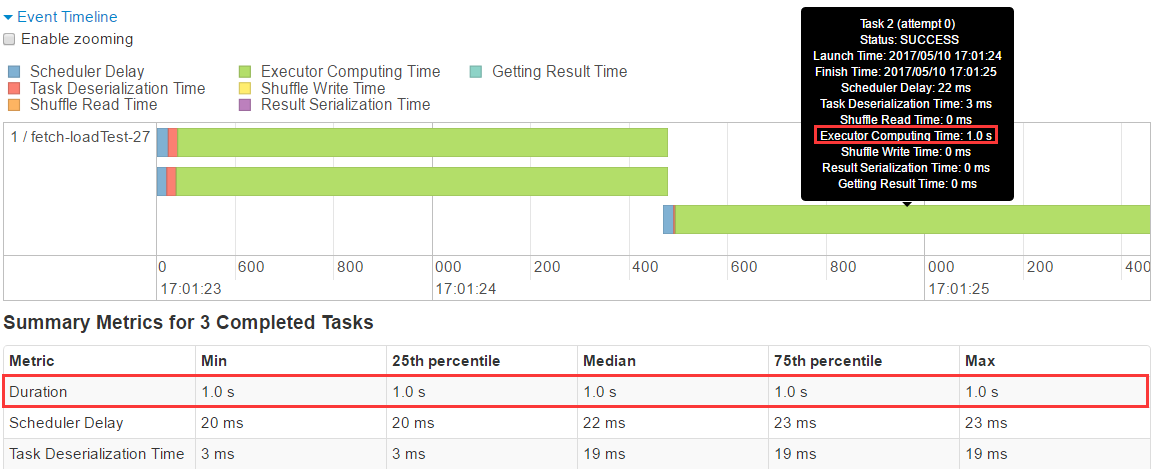
Streaming Īľš∑÷őŲÕľ
4.3 Ķų’Ż≤ő ż
Ķų’Ż executor-cores£ļ
1.executor-cores 2 ≤Ę∑Ę…Ō…ż÷Ń700/s
2.executor-cores 3 ≤Ę∑Ę…Ō…ż÷Ń750/s

Ķų’Żexecutor-coresļů
1.Ķų’Żexecutorńŕīś£¨≤Ę∑Ę√Ľ”–‘Ų≥§£¨őř–ߣļ
| executor-memory
512m
conf spark.yarn.executor.memoryOverhead=512 |
2.Ķų’Żamńŕīś£¨≤Ę∑Ę√Ľ”–‘Ų≥§£¨őř–ߣļ
| am-memory
512m
conf spark.yarn.am.memoryOverhead=512 |
4.4 īķ¬ŽĶų’Ż
∑ĘŌ÷Ō÷‘ŕ÷ų“™ĽĻ «‘ŕī¶ņŪ żĺ›Ķń ĪļÚŌŻļń Īľš“Ľ÷Ī√Ľ”–ľű…Ŕ£¨∂Ýī¶ņŪ żĺ›≤ťŅīļů∑ĘŌ÷ «“ĽŐű“ĽŐűĶńÕýHBaseņÔ√ś≤Ś»ŽĶń£¨–řłńő™ŇķŃŅ≤Ś»Ž£¨÷ō–¬ĻĻĹ®Ńňjson.–‘ń‹√Õ‘Ų£°£°–řłń«įĶńīķ¬Ž£ļ
| /**
*
* ≤Ś»Ž żĺ›ĶĹ HBase
*
* ≤ő ż( tableName , json ) )£ļ
*
* JsonłŮ Ĺ£ļ
* {
* "rowKey": "00000-0",
* "family:qualifier": "value",
* "family:qualifier": "value",
* ......
* }
*
* @param data
* @return
*/
def insert(data: (String, String)): Boolean
= {
val t: HTable = getTable(data._1) //HTable
try {
val map: mutable.HashMap[String, Object] =
JsonUtils.json2Map(data._2)
val rowKey: Array[Byte] = String.valueOf(map
.get("rowKey")).getBytes
//rowKey
val put = new Put(rowKey)
for ((k, v) <- map) {
val keys: Array[String] = k.split(":")
if (keys.length == 2){
put.addColumn(keys(0).getBytes, keys(1).getBytes,
String.valueOf(v).getBytes)
}
}
Try(t.put(put)).getOrElse(t.close())
true
} catch {
case e: Exception =>
e.printStackTrace()
false
}
} |
–řłńļůĶńīķ¬Ž£ļ
| // żĺ›≤Ŕ◊ų
messages.foreachRDD(rdd => {
val offsetsList: Array[OffsetRange] = rdd.asInstanceOf
[HasOffsetRanges].offsetRanges
//data ī¶ņŪ
rdd.foreachPartition(partitionRecords =>
{
//TaskContext …ŌŌ¬őń
val offsetRange: OffsetRange = offsetsList(TaskContext
.get.partitionId)
logger.debug(s"${offsetRange.topic} ${offsetRange.partition}
${offsetRange.fromOffset}
${offsetRange.untilOffset}")
//TopicAndPartition ÷ųĻĻ‘ž≤ő żĶŕ“ĽłŲ «topic£¨Ķŕ∂ĢłŲ «Kafka
partition id
val topicAndPartition = TopicAndPartition(offsetRange.topic,
offsetRange.partition)
val either = kc.setConsumerOffsets(groupName,
Map((topicAndPartition,
offsetRange.untilOffset))) // «
if (either.isLeft) {
logger.info(s"Error updating the offset
to Kafka cluster:
${either.left.get}")
}
/** Ĺ‚őŲPartitionRecords żĺ› */
if (offsetRange.topic != null) {
HBaseDao.insert(offsetRange.topic, partitionRecords)
}
})
}) |
≤Ś»Ž żĺ›ĶĹHBase£ļ
| /**
*
* ≤Ś»Ž żĺ›ĶĹ HBase
*
* ≤ő ż( tableName , [( tableName , json )] )£ļ
*
* JsonłŮ Ĺ£ļ
* {
* "r": "00000-0",
* "f": "family",
* "q": [
* "qualifier",
* "qualifier"
* ...
* ],
* "v": [
* "value",
* "value"
* ...
* ],
* }
*
* @return
*/
def insert(tableName: String, array: Iterator
[(String, String)]):
Boolean = {
try {
/** ≤Ŕ◊ų żĺ›ĪŪ && ≤Ŕ◊ųňų“żĪŪ */
val t: HTable = getTable(tableName) //HTable
val puts: util.ArrayList[Put] = new util.ArrayList[Put]()
/** ĪťņķJson ż◊ť */
array.foreach(json => {
val jsonObj: JSONObject = JSON.parseObject(json._2)
val rowKey: Array[Byte] = jsonObj.getString("r").getBytes
val family: Array[Byte] = jsonObj.getString("f").getBytes
val qualifiers: JSONArray = jsonObj.getJSONArray("q")
val values: JSONArray = jsonObj.getJSONArray("v")
val put = new Put(rowKey)
for (i <- 0 until qualifiers.size()) {
put.addColumn(family, qualifiers.getString(i).
getBytes, values.getString(i).getBytes)
}
puts.add(put)
})
Try(t.put(puts)).getOrElse(t.close())
true
} catch {
case e: Exception =>
e.printStackTrace()
logger.error(s"insert ${tableName} error
", e)
false
}
} |
4.5 ‘ň––
ł’≤‚ ‘ ĪłÝňŁŌŗ∂‘ļ‹–°ĶńńŕīśŇ‹“ĽŇ‹£ļ
|
[root@xiaoxiaomo.com ~]# /opt/cloudera/parcels
/CDH/bin/spark-submit
\
--master yarn-client --num-executors 1 \
--driver-memory 256m --conf spark.yarn.driver.
memoryOverhead=256
\
--conf spark.yarn.am.memory=256m --conf spark.yarn
.am.memoryOverhead=256
\
--executor-memory 256m --conf spark.yarn.executor
memoryOverhead=256
\
--executor-cores 1 \
--class com.creditease.streaming.KafkaDataStream
hspark-1.0.jar 1
3 30000 |
őŚŃýÕÚĶń≤Ś»Ž√Ľ ≤√ī—ĻѶ£¨Ķę «ĶĹ10ÕÚĶń ĪļÚ£¨ĺÕ”––©Ņ®∂ŔŃň£°£°

yarn »›∆ų°Ęcpu°Ęńŕīśīů–°
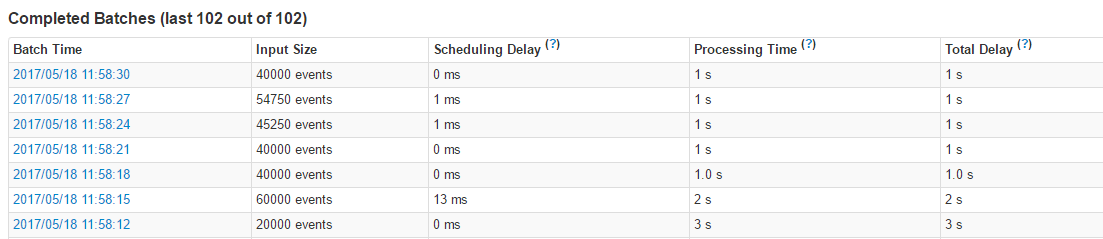
őŚŃýÕÚĶń≤Ś»Ž√Ľ ≤√ī—ĻѶ
ĶĪ»Ľ «–Ť“™‘ŲīůńŕīśĶń£¨–řłńŇš÷√£¨∂ľ‘Ųľ”“ĽĪ∂£ļ
|
[root@xiaoxiaomo.com ~]# /opt/cloudera/parcels/
CDH/bin/spark-submit
\
--master yarn-client --num-executors 2 \
--driver-memory 512m --conf spark.yarn.driver
.memoryOverhead=512
\
--conf spark.yarn.am.memory=512m --conf spark.
yarn.am.memoryOverhead=512
\
--executor-memory 512m --conf spark.yarn.executor
.memoryOverhead=512
\
--executor-cores 1 \
--class com.creditease.streaming.KafkaDataStream
hspark-1.0.jar 1
3 30000 |
yarn »›∆ų°Ęcpu°Ęńŕīśīů–°

90000Ķń≤Ś»Ž√Ľ ≤√ī—ĻѶ
≤ťŅī≤Ś»Ž żĺ›ŃŅ£¨ń‹ŅīĶĹ–řłńļů≤Ś»Ž żĺ›10ÕÚ «√Ľ”– ≤√ī—ĻѶĶń£ļ
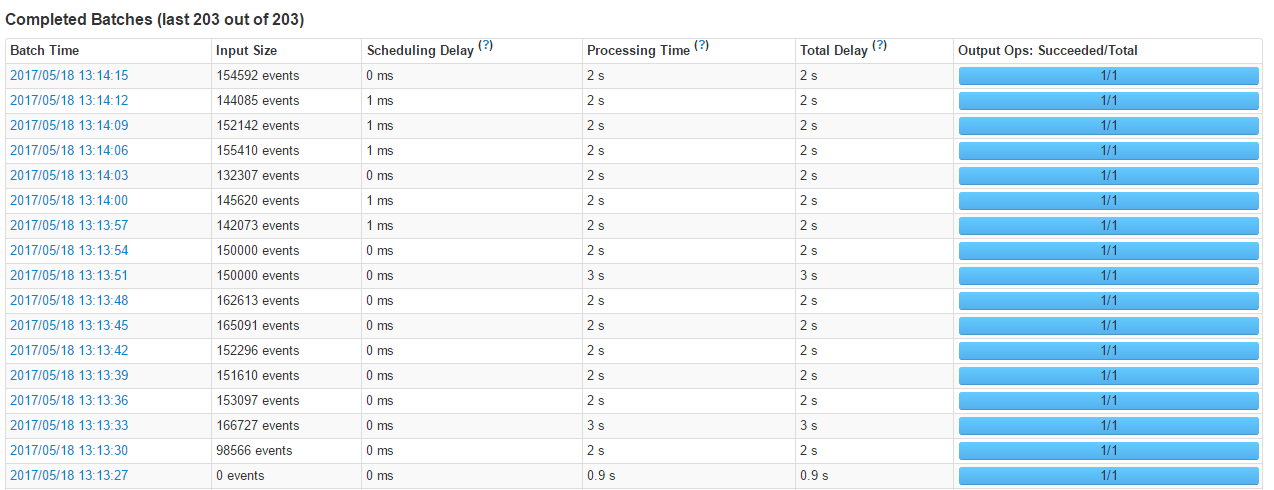
≤ťŅī≤Ś»Ž żĺ›ŃŅ£¨ń‹ŅīĶĹ–řłńļů≤Ś»Ž żĺ›10ÕÚ «√Ľ”– ≤√ī—ĻѶĶń
ĶĪő“√«‘ŔľŐ–Ýľ”īů—ĻѶ≤‚ ‘Ķń ĪļÚ£¨–‘ń‹Ō¬ĹĶ£ļ
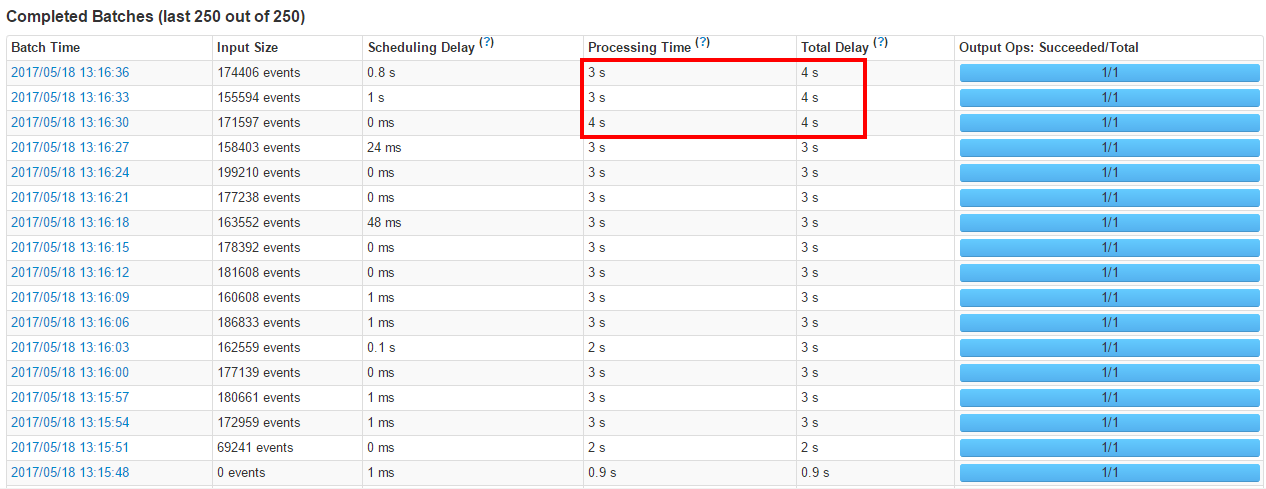
ĶĪő“√«‘ŔľŐ–Ýľ”īů—ĻѶ≤‚ ‘Ķń ĪļÚ£¨–‘ń‹Ō¬ĹĶ
≤ťŅīÕ≥ľ∆–ŇŌĘ£ļ

≤ťŅīÕ≥ľ∆–ŇŌĘ |









