| HBase
дкАЂРяЫбЫїЕФРњЪЗЁЂЙцФЃКЭЗўЮёФмСІ
РњЪЗЃКАЂРяЫбЫїгк 2010 ФъПЊЪМЪЙгУ HBaseЃЌДгзюдчЕНФПЧАвбОгаЪЎгрИіАцБОЁЃФПЧАЪЙгУЕФАцБОЪЧдкЩчЧјАцБОЕФЛљДЁЩЯОЙ§ДѓСПгХЛЏЖјГЩЁЃЩчЧјАцБОНЈвщВЛвЊЪЙгУ
1.1.2АцБОЃЌгаНЯбЯжиЕФадФмЮЪЬтЃЌ1.1.3 вдКѓЕФАцБОЬхбщЛсКУКмЖрЁЃ
МЏШКЙцФЃЃКФПЧАЃЌНідкАЂРяЫбЫїНкЕуЪ§ОЭГЌЙ§ 3000 ИіЃЌзюДѓМЏШКГЌЙ§ 1500 ИіЁЃАЂРяМЏЭХНкЕуЪ§дЖдЖГЌЙ§етИіЪ§СПЁЃ
ЗўЮёФмСІЃКШЅФъЫЋ11ЃЌАЂРяЫбЫїРыЯпМЏШКЕФЭЬЭТЗхжЕвЛУыжгЗУЮЪГЌЙ§ 4000 ЭђДЮЃЌЕЅЛњвЛУыжгЭЬЭТЗхжЕДяЕН
10 ЭђДЮЁЃЛЙгадк CPU ЪЙгУСПГЌЙ§ 70% ЕФЧщПіЯТЃЌЕЅ cpu core ЛЙПЩжЇГХ 8000+
QPSЁЃ
HBase дкАЂРяЫбЫїЕФНЧЩЋКЭжївЊгІгУГЁОА
НЧЩЋЃКHBase ЪЧАЂРяЫбЫїЕФКЫаФДцДЂЯЕЭГЃЌЫќКЭМЦЫув§ЧцНєУмНсКЯЃЌжївЊЗўЮёЫбЫїКЭЭЦМіЕФвЕЮёЁЃ
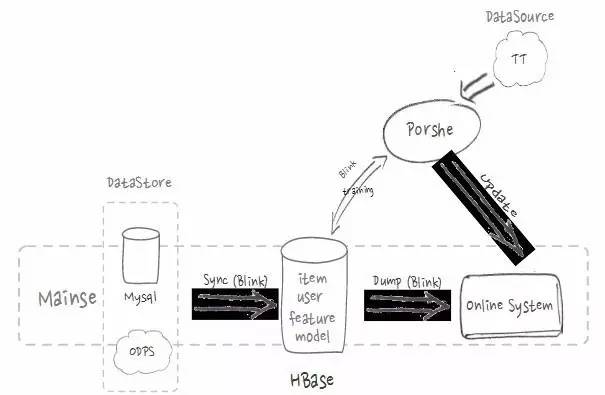
ЩЯЭМЪЧ HBase дкЫбЫїКЭЭЦМіЕФгІгУСїГЬЁЃдкЫїв§ЙЙНЈСїГЬжаЃЌЛсДгЯпЩЯ MySQL ЕШЪ§ОнПтжаДцДЂЕФЩЬЦЗКЭгУЛЇВњЩњЕФЫљгаЯпЩЯЪ§ОнЃЌЭЈЙ§СїЪНЕФЗНЪНЕМШыЕН
HBase жаЃЌВЂЬсЙЉИјЫбЫїв§ЧцЙЙНЈЫїв§ЁЃ
дкЭЦМіСїГЬжаЃЌЛњЦїбЇЯАЦНЬЈ Porshe ЛсНЋФЃаЭКЭЬиеїЪ§ОнДцДЂдк HBase РяЃЌВЂНЋгУЛЇЕуЛїЪ§ОнЪЕЪБЕФДцШы
HBaseЃЌЭЈЙ§дкЯп training ИќаТФЃаЭЃЌЬсИпЯпЩЯЭЦМіЕФзМШЗЖШКЭаЇЙћЁЃ
гІгУГЁОАвЛ
Ыїв§ЙЙНЈ
ЬдБІКЭЬьУЈгаИїжжИїбљЕФЕФЯпЩЯЪ§ОндДЃЌетШЁОігкЬдБІгаЗЧГЃЖрВЛЭЌЕФЯпЩЯЕъЦЬКЭИїжжгУЛЇЗУЮЪЁЃ
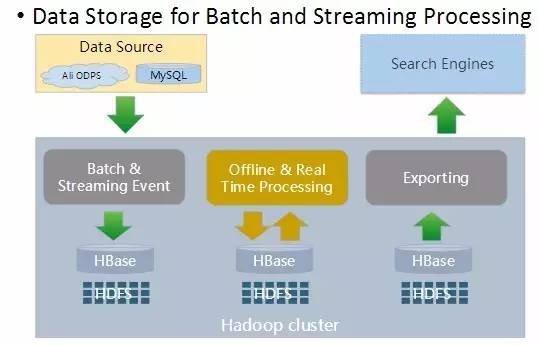
ШчЭМЫљЪОЁЃдквЙМфЃЌЮвУЧЛсНЋЪ§ОнДг HBase ХњСПЕМГіЃЌЙЉИјЫбЫїв§ЧцРДЙЙНЈШЋСПЫїв§ЁЃЖјдкАзЬьЃЌЯпЩЯЩЬЦЗЁЂгУЛЇаХЯЂЕШЖМдкВЛЭЃЕФБфЛЏЃЌетаЉЖЏЬЌЕФБфЛЏЪ§ОнвВЛсДгЯпЩЯДцДЂЪЕЪБЕФИќаТЕНHBaseВЂДЅЗЂдіСПЫїв§ЙЙНЈЃЌНјЖјБЃжЄЫбЫїНсЙћЕФЪЕЪБадЁЃ
ФПЧАЃЌПЩвдзіЕНЖЫЕНЖЫЕФбгЪБПижЦдкУыМЖЃЌМДПтДцБфЛЏЃЌВњЦЗЩЯМмЕШаХЯЂдкЗўЮёЖЫИќаТКѓЃЌбИЫйЕФПЩдкгУЛЇжеЖЫЫбЫїЕНЁЃ
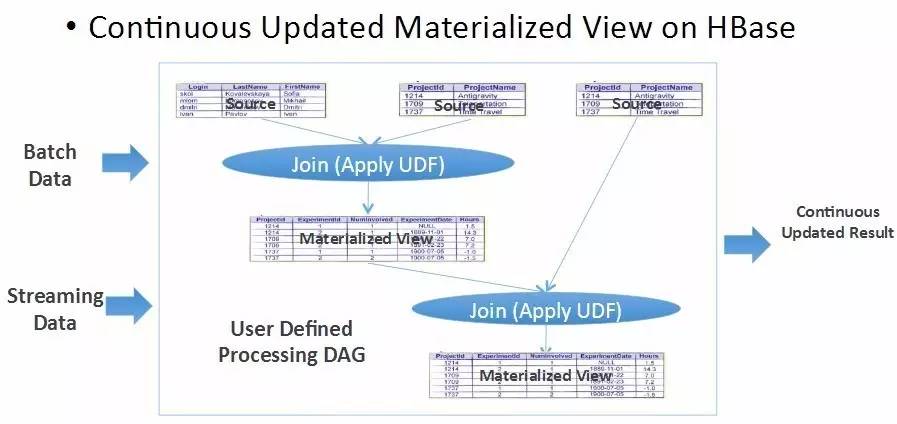
Ыїв§ЙЙНЈгІгУГЁОАГщЯѓЭМ
ећИіЫїв§ЙЙНЈЙ§ГЬПЩвдГщЯѓГЩвЛИіГжајИќаТЕФСїГЬЁЃШчАбШЋСПКЭдіСППДзіЪЧвЛИі JoinЃЌЯпЩЯгаВЛЭЌЕФЪ§ОндДЧвЪЕЪБДІгкИќаТзДЬЌЃЌећИіЙ§ГЬЪЧГЄЦкГжајЕФЙ§ГЬЁЃетРяЃЌОЭЭЙЯдГі
HBase КЭСїЪНМЦЫув§ЧцЯрНсКЯЕФЬиЕуЁЃ
гІгУГЁОАЖў
ЛњЦїбЇЯА
етРяОйвЛИіМђЕЅЕФЛњЦїбЇЯАЪОР§ЃКгУЛЇЯыТђвЛПюШ§ЧЇдЊЕФЪжЛњЃЌгкЪЧдкЬдБІАДееШ§ЧЇдЊЕФЬѕМўЩИбЁЯТРДЃЌЕЋЪЧУЛгажавтЕФЁЃжЎКѓ
ЃЌгУЛЇЛсДгЭЗЫбЫїЃЌетЪБОЭЛсРћгУЛњЦїбЇЯАФЃаЭАбШ§ЧЇПщЧЎзѓгвЕФЪжЛњХХдкЫбЫїНсЙћЕФППЧАЮЛжУЃЌвВОЭЪЧгУЧАвЛИіЫбЫїНсЙћРДгАЯьКѓвЛИіЫбЫїНсЙћЕФХХађЁЃ
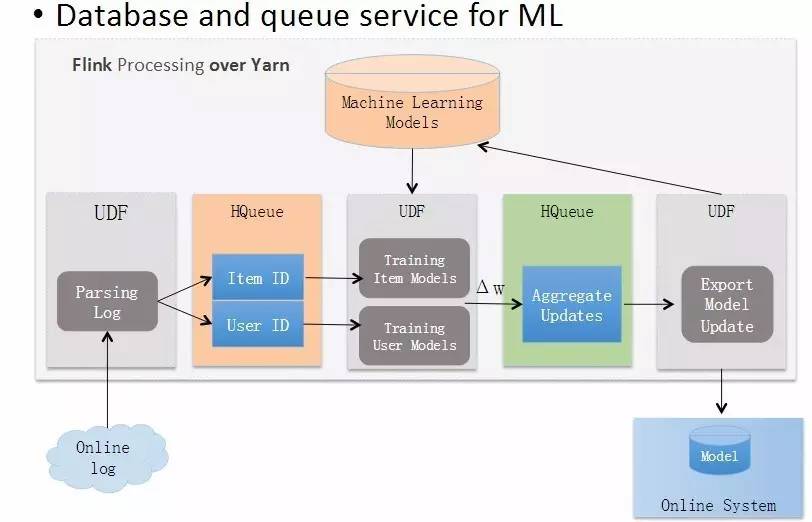
ЗжЮіЯпЩЯШежО
ШчЩЯЭМЃЌЗжЮіЯпЩЯШежОЁЃЙщНсЮЊЩЬЦЗКЭгУЛЇСНИіЮГЖШЃЌЕМШыЗжВМЪНЁЂГжОУЛЏЯћЯЂЖгСаЃЌДцЗХЕН HBase ЩЯЁЃЫцЯпЩЯгУЛЇЕФЕуЛїааЮЊШежОРДВњЩњЪ§ОнИќаТЃЌЖдгІФЃаЭЫцжЎИќаТЃЌНјааЛњЦїбЇЯАбЕСЗЃЌетЪЧвЛИіЗДИДЕќДњЕФЙ§ГЬЁЃ
HBase дкАЂРяЫбЫїгІгУжагіЕНЕФЮЪЬтКЭгХЛЏ
HBase МмЙЙЗжВу
дкЫЕЮЪЬтКЭгХЛЏжЎЧАЃЌЯШРДПД HBase ЕФМмЙЙЭМЃЌДѓжТЗжЮЊШчЯТМИИіВПЗжЃК
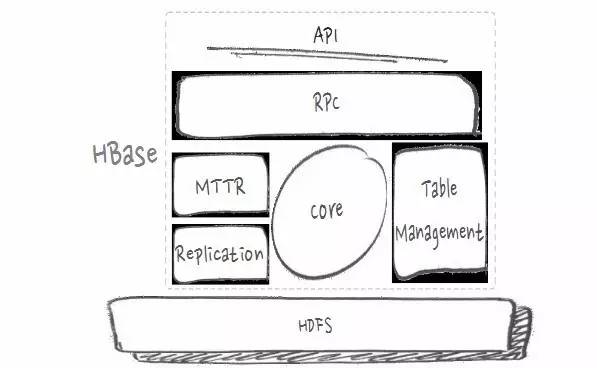
HBase ЕФМмЙЙЭМ
ЪзЯШЪЧ APIЃЌвЛаЉгІгУГЬађБрГЬНгПкЁЃRPCЃЌетРяАбдЖГЬЙ§ГЬЕїгУавщЗжЮЊПЭЛЇЖЫЛсЗЂЦ№ЗУЮЪгыЗўЮёЖЫРДДІРэЗУЮЪСНВПЗжЁЃMTTR
ЙЪеЯЛжИДЁЂReplication Ъ§ОнИДжЦЁЂБэДІРэЕШЃЌетаЉЖМЪЧЗжВМЪНЙмРэЕФЗЖГыЁЃжаМф Core ЪЧКЫаФЕФЪ§ОнДІРэСїГЬВПЗжЃЌЯёаДШыЁЂВщбЏЕШЃЌзюЕзВуЪЧ
HDFSЃЈЗжВМЪНЮФМўЯЕЭГЃЉЁЃ
HBase дкАЂРяЫбЫїгІгУжагіЕНЕФЮЪЬтКЭгХЛЏгаКмЖрЃЌЯТУцЬєбЁНќЦкБШНЯжиЕуЕФЮхЗНУцНјааеЙПЊЁЃ
RPC ЕФЦПОБКЭгХЛЏ
вьВНгыЭЬЭТ
GC гыУЋДЬ
IO ИєРыгыгХЛЏ
IO РћгУ
ЮЪЬтгыгХЛЏвЛ
RPC ЕФЦПОБКЭгХЛЏ
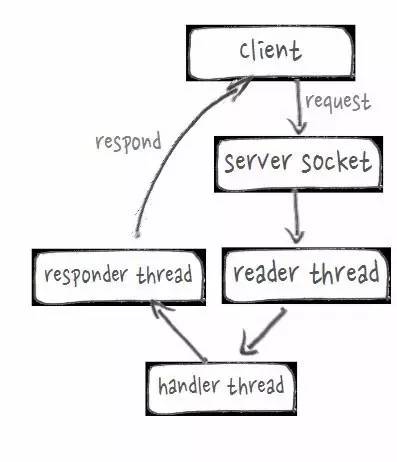
ЪЕМЪЮЪЬтЃК
дга RpcServer ЕФЯпГЬФЃаЭаЇТЪНЯЕЭ
гХЛЏЪжЖЮЃК
Netty ПЩвдИќИпаЇЕФИДгУЯпГЬ
Лљгк Netty ЪЕЯж HBase RpcServer
ЯпЩЯаЇЙћЃК
Rpc ЦНОљЯьгІЪБМфДг 0.92ms ЯТНЕЕН 0.25ms
Rpc ЭЬЭТФмСІЬсИпНгНќ 2 БЖ
ЮЪЬтгыгХЛЏЖў
вьВНгыЭЬЭТ
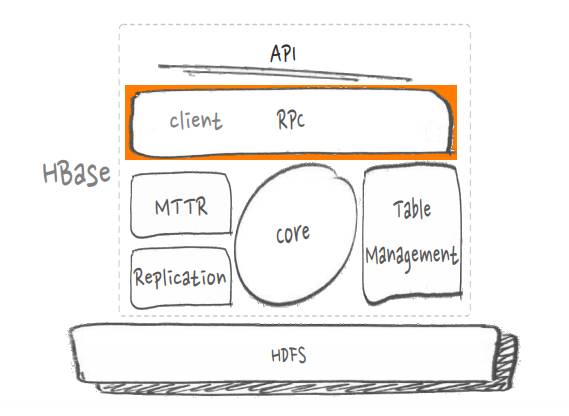
ЪЕМЪЮЪЬтЃК
СїЪНМЦЫуЖдгкЪЕЪБадЕФвЊЧѓКмИп
ЗжВМЪНЯЕЭГЮоЗЈБмУтУыМЖУЋДЬ
ЭЌВНФЃЪНЖдУЋДЬУєИаЃЌЭЬЭТДцдкЦПОБ
гХЛЏЪжЖЮЃК
Лљгк ne_y ЪЕЯж non-blocking client
Лљгк protobuf ЕФ non-blockingStub/RpcCallback ЪЕЯж callback
ЛиЕї
ЯпЩЯаЇЙћЃК
КЭ flink МЏГЩКѓЪЕВтЭЬЭТНЯЭЌВНФЃЪНЬсИп 2 БЖ
ЮЪЬтгыгХЛЏШ§
GCгыУЋДЬ
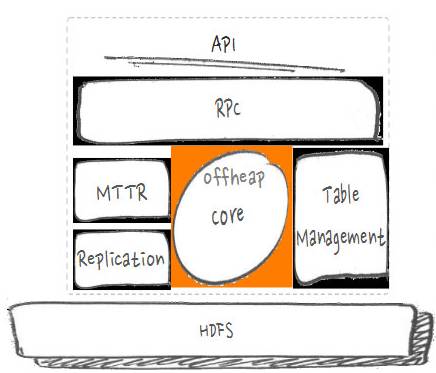
ЪЕМЪЮЪЬтЃК
PCIe-SSD ЕФИп IO ЭЬЭТФмСІЯТЃЌЖС cache ЕФЛЛШыЛЛГіЫйТЪДѓЗљЬсИп
ЖбЩЯЕФ cache ФкДцЛиЪеВЛМАЪБЃЌЕМжТЦЕЗБЕФ CMS gc ЩѕжС fullGC
гХЛЏЪжЖЮЃК
ЪЕЯжЖСТЗОЖ E2E ЕФ odeap
ЯпЩЯаЇЙћЃК
Full КЭ CMS gc ЦЕТЪНЕЕЭ 200% вдЩЯ
ЖСЭЬЭТЬсИп 20% вдЩЯ
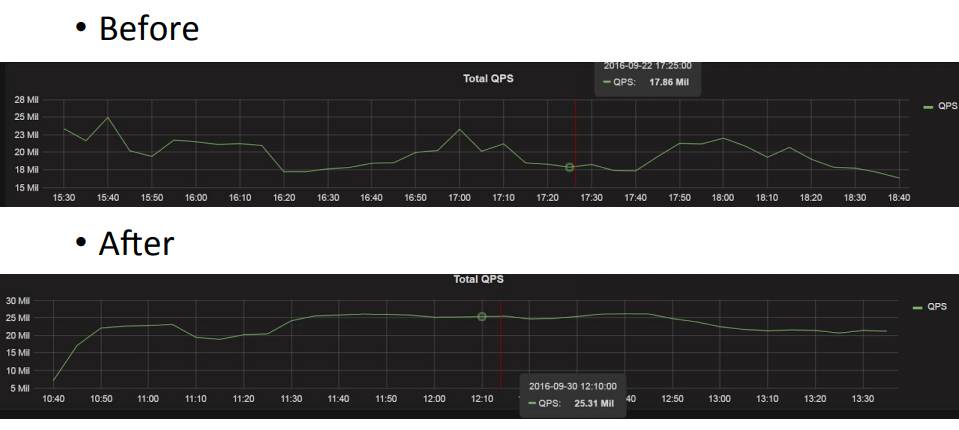
ШчЩЯЭМЃЌЪЧЯпЩЯЕФвЛИіНсЙћЃЌQPS жЎЧАЪЧ 17.86 MЃЌгХЛЏжЎКѓЪЧ 25.31 MЁЃ
ЮЪЬтгыгХЛЏЫФ
IOИєРыгыгХЛЏ
HBase БОЩэЖд IO ЗЧГЃУєИаЃЌДХХЬДђТњЛсдьГЩДѓСПУЋДЬЁЃдкМЦЫуДцДЂЛьКЯВПЪ№ЛЗОГЯТЃЌMapReduce
зївЕВњЩњЕФ shuffle Ъ§ОнКЭ HBase здЩэ Flush/Compaction етСНЗНУцЖМЪЧДѓ
IO РДдДЁЃ
ШчКЮЙцБметаЉгАЯьФиЃПРћгУ HDFS ЕФ Heterogeneous Storage ЙІФмЃЌЖд WAL(write-ahead-log)
КЭживЊвЕЮёБэЕФ HFile ЪЙгУ ALL_SSD ВпТдЁЂЦеЭЈвЕЮёБэЕФ HFile ЪЙгУ ONE_SSD
ВпТдЃЌБЃжЄ Bulkload жЇГжжИЖЈ storage policyЁЃЭЌЪБЃЌШЗБЃ MR СйЪБЪ§ОнФПТМ(mapreduce.cluster.local.dir)жЛЪЙгУ
SATA ХЬЁЃ
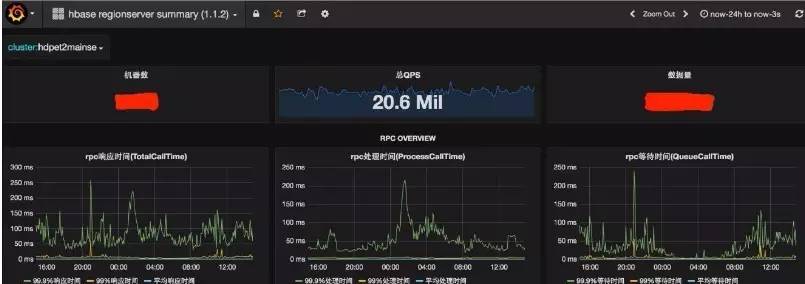
HBase МЏШК IO ИєРыКѓЕФУЋДЬгХЛЏаЇЙћ
Ждгк HBase здЩэЕФ IO ДјРДЕФгАЯьЃЌВЩгУ Compaction ЯоСїЁЂFlush ЯоСїКЭ Per-CF
flush Ш§ДѓЪжЖЮЁЃЩЯЭМЮЊЯпЩЯаЇЙћЃЌТЬЯпДгзѓЕНгвЗжБ№ЪЧЯьгІЪБМфЁЂДІРэЪБМфКЭЕШД§ЪБМфЕФ p999 Ъ§ОнЃЌвдЯьгІЪБМфЮЊР§ЃЌ99.9%
ЕФЧыЧѓВЛЛсГЌЙ§ 250msЁЃ
ЮЪЬтгыгХЛЏЮх
IO РћгУ
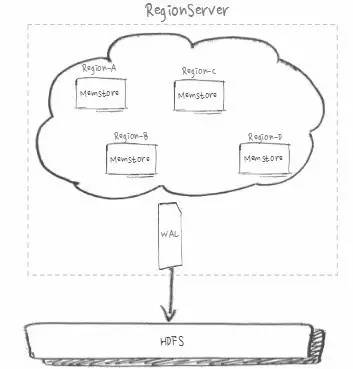
ЕЅ WAL ЮоЗЈГфЗжЪЙгУДХХЬ IO
HDFS аД 3 ЗнИББОЁЂЭЈгУЛњаЭга 12 Пщ HDD ХЬЁЂSSD ЕФ IO ФмСІдЖГЌ HDDЁЃШчЩЯЭМЃЌЪЕМЪЮЪЬтЪЧЕЅ
WAL ЮоЗЈГфЗжЪЙгУДХХЬ IOЁЃ
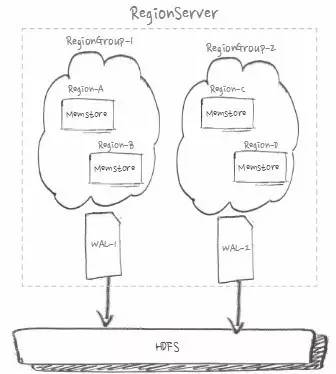
КЯРэгГЩфЖд region НјааЗжзщ
ШчЩЯЭМЃЌЮЊСЫГфЗжРћгУ IOЃЌЮвУЧПЩвдЭЈЙ§КЯРэгГЩфЖд region НјааЗжзщЃЌРДЪЕЯжЖр WALЁЃЛљгк
NamespaceЕФWAL ЗжзщЃЌжЇГж App Мф IO ИєРыЁЃДгЩЯЯпаЇЙћРДПДЃЌШЋ HDD ХЬЯТаДЭЬЭТЬсИп
20%ЃЌШЋ SSD ХЬЯТаДЭЬЭТЬсИп 40%ЁЃЯпЩЯаДШыЦНОљЯьгІбгЪБДг 0.5ms ЯТНЕЕН 0.3msЁЃ
ПЊдД&ЮДРД
ЮЊЪВУДвЊгЕБЇПЊдДЃПЦфвЛЃЌЪдЯыШчЙћДѓМвзіСЫгХЛЏЖМВЛФУГіРДЃЌШЯЮЊетЪЧздМКЧПгкБ№ШЫЕФгХЪЦЃЌНсЙћЛсдѕбљЃПШчЙћДѓМвАбздМКЕФгХЪЦЖМФУГіРДЗжЯэЃЌЕУЕНЕФЛсЪЧе§ЯђЕФЗДРЁЁЃЦфЖўЃЌ
HBase ЕФЭХЖгвЛАуЖМБШНЯаЁЃЌШЫдБСїЪЇЛсВњЩњКмДѓЕФЫ№ЪЇЁЃШчАбФкШнЙБЯзИјЩчЧјЃЌДњТыЕФЮЌЛЄГЩБОПЩвдДѓДѓНЕЕЭЁЃПЊдДвЛЦ№зіЃЌБШвЛИіЙЋЫОвЛИіШЫзівЊКУКмЖрЃЌЫљвдЮвУЧвЊгаЙБЯзОЋЩёЁЃ
ЮДРДЃЌвЛЗНУцЃЌАЂРяЫбЫїЛсНјвЛВНАб PPC ЗўЮёЖЫвВзівьВНЃЌАб HBase ФкКЫгУдкСїЪНМЦЫуЁЂЮЊ HBase
ЬсЙЉЧЖШыЪНЕФФЃЪНЁЃСэвЛЗНУцЃЌГЂЪдИќЛЛ HBase ФкКЫЃЌгУаТЕФ DB РДЬцДњЃЌДяЕНИќИпЕФадФмЁЃ |









