НќМИФъЃЌApache
KylinзїЮЊвЛИіИпЫйЕФПЊдДЗжВМЪНДѓЪ§ОнВщбЏв§Чце§дкбИЫйсШЦ№ЁЃЫќГфЗжЗЂЛгHadoopЁЂSparkЁЂHBaseЕШММЪѕЕФгХЪЦЃЌЭЈЙ§ЖдГЌДѓЙцФЃЪ§ОнМЏНјаадЄМЦЫуЃЌЪЕЯжУыМЖЩѕжСбЧУыМЖЕФВщбЏЯьгІЪБМфЃЌЭЌЪБЬсЙЉБъзМSQLНгПкЁЃФПЧАЃЌApache
KylinвбдкШЋЧђЗЖЮЇЕУЕНСЫЙуЗКгІгУЃЌШчАйЖШЁЂУРЭХЁЂНёШеЭЗЬѕЁЂeBayЕШЃЌжЇГХзХЕЅИівЕЮёЩЯЭђвкЙцФЃЕФЪ§ОнВщбЏвЕЮёЁЃдкГЌИпадФмЕФБГКѓЃЌCubeЪЧжСЙиживЊЕФКЫаФЁЃвЛИігХЛЏЕУЕБЕФCubeМШФмТњзуИпЫйВщбЏЕФашвЊЃЌгжФмНкЪЁМЏШКзЪдДЁЃБОЮФНЋДгЖрИіЗНУцШыЪжЃЌНщЩмШчКЮЭЈЙ§гХЛЏCubeЬсЩ§ЯЕЭГадФмЁЃ
CubeЛљБОдРэ
дкДЋЭГЖрЮЌЗжЮіОЭгаЖрЮЌСЂЗНЬхЃЈOLAP CubeЃЉЕФИХФюЁЃApache KylinдкДѓЪ§ОнСьгђЖдCubeНјааСЫРЉеЙЃЌЭЈЙ§жДаа
MapReduce/SparkШЮЮёЙЙНЈCubeЃЌЖдвЕЮёЫљашЕФЮЌЖШзщКЯКЭЖШСПНјаадЄОлКЯЃЌЕБВщбЏЕНДяЪБжБНгЗУЮЪдЄМЦЫуОлКЯНсЙћЃЌЪЁШЅЖдДѓЪ§ОнЕФЩЈУшКЭдЫЫуЃЌетОЭЪЧApache
KylinИпадФмВщбЏЕФЛљБОЪЕЯждРэЁЃ
ШчЭМ1ЫљЪОЃЌApache KylinЛсЖдSQLЕФВщбЏМЦЛЎНјааИФаДЃЌАбдДБэЩЈУшЁЂЖрБэСЌНгЁЂжИБъОлКЯЕШдкЯпМЦЫузЊЛЛГЩЖддЄМЦЫуНсЙћЕФЖСШЁЃЌМЋДѓМѕЩйСЫдкЯпМЦЫуКЭI/OЖСаДЕФДњМлЁЃ
ЖјВщбЏЫљЗУЮЪЕФдЄМЦЫуНсЙћБЃДцдкCuboidЕБжаЃЈМћЭМ1КьЩЋЗНПђЃЉЃЌCuboidДѓаЁжЛКЭЮЌЖШСаЕФЛљЪ§гаЙиЃЌКЭдДЪ§ОнааЪ§ЮоЙиЃЌетЪЙЕУВщбЏЕФЪБМфИДдгЖШПЩвдШЁЕУвЛИіСПМЖЕФЬсЩ§ЁЃ
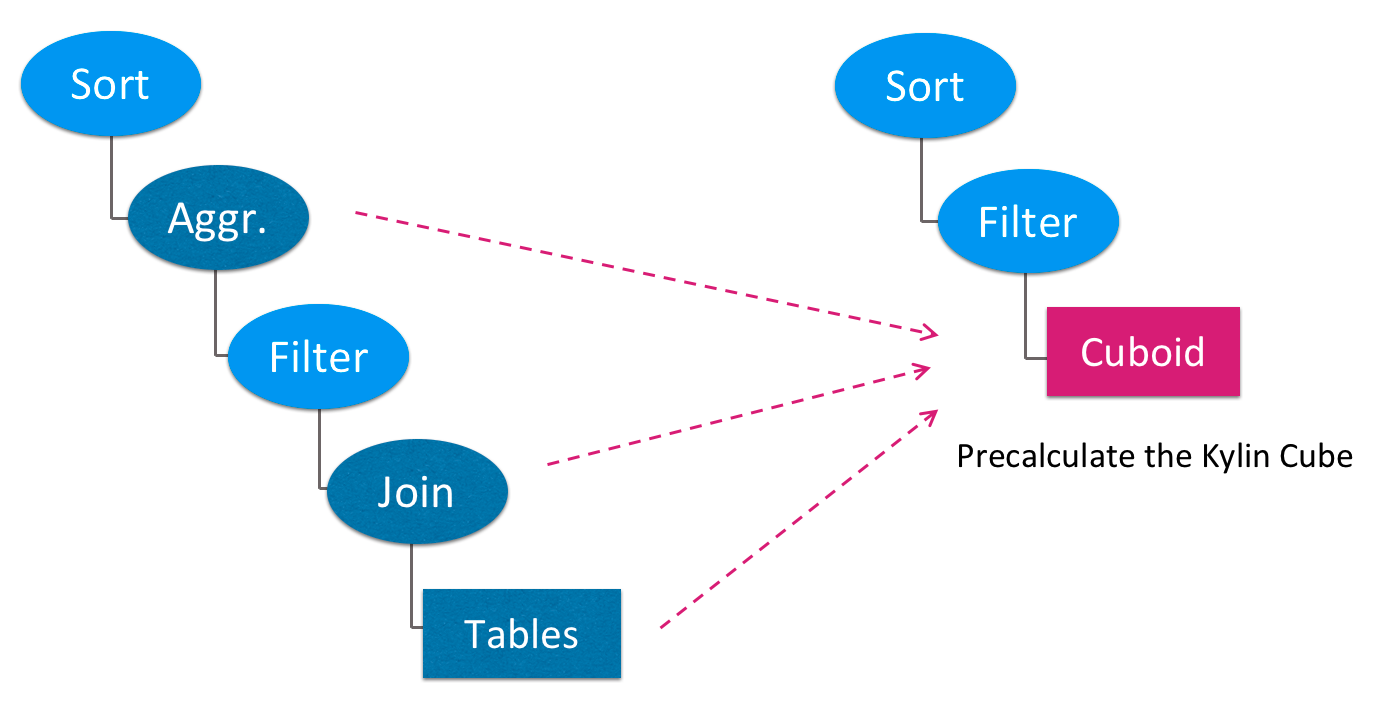
ЭМ - 1дЄМЦЫуВщбЏМЦЛЎ
вЛИіCuboidЖдгІзХвЛзщЗжЮіЕФЮЌЖШЃЌВЂБЃДцСЫЖШСПЕФОлКЯНсЙћЁЃCubeОЭЪЧЫљгаCuboidЕФМЏКЯЃЌШчЭМ2ЫљЪОЃЌУПИіНкЕуДњБэвЛИіCuboidЁЃЕБВщбЏЕНДяЃЌApache
KylinЛсИљОнSQLЫљЪЙгУЕФЮЌЖШСадкCubeжабЁдёзюКЯЪЪЕФCuboidЃЌзюДѓГЬЖШЕиНкЪЁВщбЏЪБМфЁЃ
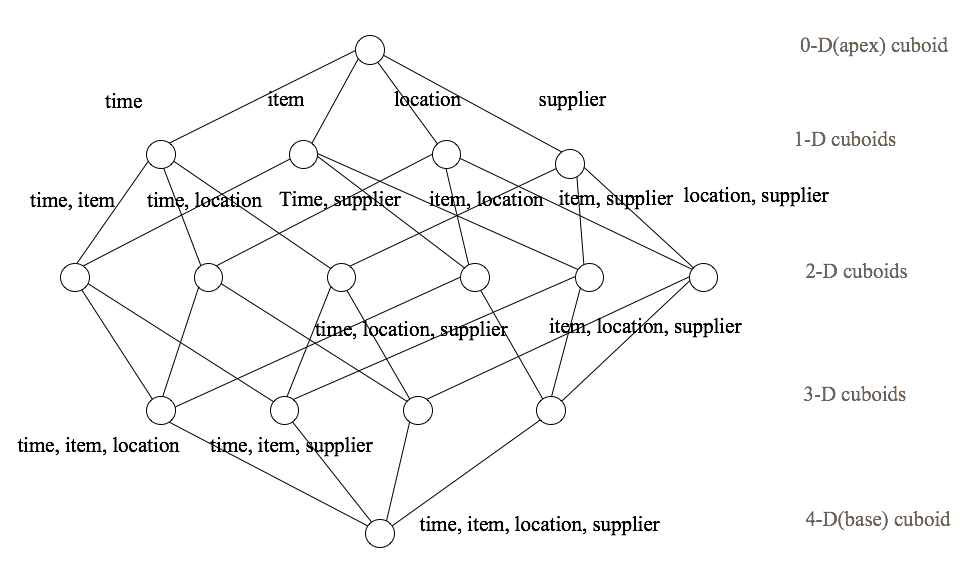
ЭМ - 2 CubeЪОвтЭМ
CubeгХЛЏАИР§
ЩчЧјВЛЗІвЛаЉЪЙгУApache KylinЕФГЩЙІАИР§ЗжЯэЃЌЕЋОГЃЛЙЛсПДЕНКмЖрХѓгбгіЕНадФмЮЪЬтЃЌР§ШчSQLВщбЏЙ§Т§ЁЂCubeЙЙНЈЪБМфЙ§ГЄЩѕжСЪЇАмЁЂCubeХђеЭТЪЙ§ИпЕШЕШЁЃОПЦфдвђЃЌДѓЖрЪ§ЮЪЬтЖМЪЧгЩгкCubeЩшМЦВЛЕБдьГЩЕФЁЃвђДЫЃЌКЯРэЕиНјааCubeгХЛЏОЭЯдЕУгШЮЊживЊЁЃ
етРяЯШЗжЯэСНИіЩчЧјгУЛЇНјаагХЛЏЕФАИР§ЃК
АИР§1 ЈC ЬсЩ§CubeВщбЏаЇТЪ
БГОАЃКФГжЧФмгВМўЦѓвЕЪЙгУApache KylinзїЮЊДѓЪ§ОнЦНЬЈВщбЏв§ЧцЃЌЖдВщбЏадФмгаНЯИпвЊЧѓЃЌЯЃЭћЬсИпВщбЏаЇТЪЁЃ
Ъ§ОнЃК
9ИіЮЌЖШЃЌЦфжа1ИіЮЌЖШЛљЪ§ЪЧЧЇЭђМЖЃЌ1ИіЮЌЖШЛљЪ§ЪЧАйЭђМЖЃЌЦфЫћЮЌЖШЛљЪ§ЪЧ10wвдФк
ЕЅдТдЪМЪ§Он6вкЬѕ
гХЛЏЗНАИЃК
Ъ§ОнЧхРэЃКНЋЪБМфДСзжЖЮзЊЛЛГЩШеЦкЃЌНЕЕЭЮЌЖШЕФЛљЪ§
ЕїећОлКЯзщЃКВЛЛсЭЌЪБдкВщбЏжаГіЯжЕФЮЌЖШЗжБ№АќКЌдкВЛЭЌОлКЯзщЃЈШчБРРЃЪБМфЁЂЩЯДЋЪБМфЕШЃЉ
ЩшжУБиаыЮЌЖШЃКАбФГаЉГЌЕЭЛљЪ§ЮЌЖШЩшЮЊБиаыЮЌЖШ
гХЛЏГЩЙћЃК
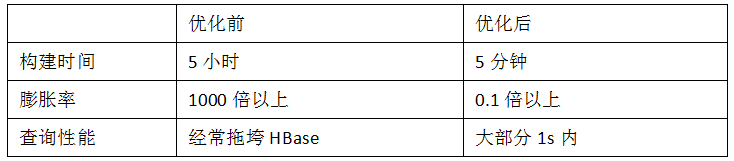
ВщбЏадФмЃКЬсЩ§5БЖ
ЙЙНЈЪБМфЃКЫѕЖЬ30%
CubeДѓаЁЃКМѕаЁ74%
АИР§Жў ЈC ЬсЩ§CubeЙЙНЈаЇТЪ
БГОАЃКФГН№ШкЦѓвЕЪЙгУApache KylinзїЮЊБЈБэЗжЮів§ЧцЃЌЗЂЯжCubeХђеЭТЪЖрДѓЁЂЙЙНЈЪБМфЙ§ГЄЃЌЯЃЭћЖдетвЛЧщПіНјааИФЩЦЁЃ
гВМўЃК20ЬЈИпХфжУPCЗўЮёЦї
Ъ§ОнЃКЪТЪЕБэга100ЖрЭђЬѕМЧТМЃЌЖШСПЪЧФГаЉСаЕФЦНОљжЕ
гХЛЏЗНАИЃК
ЮЌЖШОЋМђЃКШЅГ§ВщбЏжаВЛЛсГіЯжЕФЮЌЖШ
ЕїећОлКЯзщЃКЩшжУЖрИіОлКЯзщЃЌУПИіОлКЯзщФкЩшжУЖрзщСЊКЯЮЌЖШ
гХЛЏГЩЙћЃК
CubeгХЛЏдРэ
ДгвдЩЯАИР§ПЩвдПДГіЃЌЭЈЙ§CubeЕїгХПЩвдЯджјИФЩЦApache KylinЕФЙЙНЈадФмЁЂВщбЏадФмМАCubeХђеЭТЪЁЃФЧУДетаЉИФНјЕФБГКѓОПОЙЪЧЪВУДдРэФиЃП
ЮЊСЫЩюШыРэНтCubeЃЌЪзЯШвЊЯШСЫНтCuboidЩњГЩЪїЁЃШчЭМ3ЫљЪОЃЌдкCubeжаЃЌЫљгаЕФCuboidзщГЩвЛИіЪїаЮНсЙЙЃЌИљНкЕуЪЧШЋЮЌЖШЕФBase
CuboidЃЌдйвРДЮж№ВуОлКЯЕєУПИіЮЌЖШЩњГЩзгCuboidЃЌжБЕНГіЯж0ИіЮЌЖШЪБНсЪјЁЃЭМ3жаТЬЩЋВПЗжОЭЪЧвЛЬѕЭъећЕФCuboidЩњГЩТЗОЖЁЃдЄМЦЫуЕФЙ§ГЬЪЕМЪОЭЪЧАДееетИіСїГЬЙЙНЈЫљгаЕФCuboidЁЃ
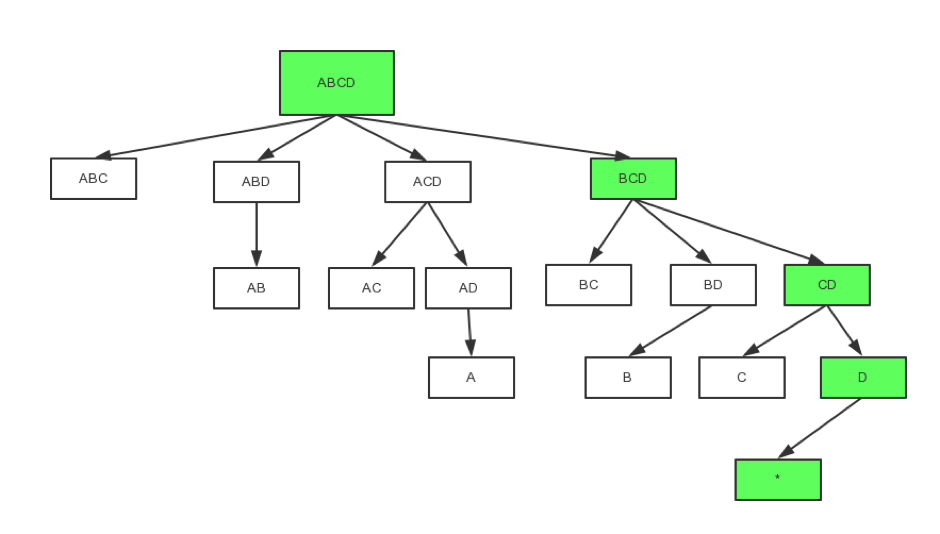
ЭМ - 3 CuboidЩњГЩЪї
ЭЈЙ§етПХCuboidЩњГЩЪїЃЌЮвУЧВЛФбЗЂЯжЃКЕБЮЌЖШЪ§СПЙ§ЖрЃЌОЭЛсЕМжТCuboidЪ§СПвджИЪ§МЖХђеЭЃЛШчЙћЮЌЖШЛљЪ§Й§ДѓЃЌЛЙЛсЪЙЫљдкЕФCuboidНсЙћМЏБфДѓЁЃетаЉЖМЪЧгАЯьCubeХђеЭТЪКЭЙЙНЈЪБМфЕФживЊвђЫиЁЃ
ЕЋЪЧЃЌЫљгаЕФCuboidЖМЪЧБивЊЕФТ№ЃПЪЕМЪЩЯЃЌдкЖрЪ§ЧщПіЯТЃЌЮвУЧВЂВЛашвЊетРяЕФУПвЛИіCuboidЃЌвђДЫашвЊЖдCuboidЩњГЩЪїзіМєжІЁЃМєжІПЩвдДгСНИіЗНУцШыЪжЃКЪ§ОнЬиадЁЂВщбЏашЧѓЁЃЪзЯШНщЩмЪ§ОнЬиадЃЌПМТЧЯТЭМЕФСНИіCuboidЃЌзѓВрCuboidАќКЌ4ИіЮЌЖШЃЈABCDЃЉЃЌгвВрCuboidАќКЌ3ИіЮЌЖШЃЈABCЃЉЃЌЖјСНИіCuboidЖМАќКЌЯрЭЌЃЈЛђМЋЖШЯрНќЃЉааЪ§ЕФМЧТМЃЌЫЕУїЖСШЁСНИіCuboidНсЙћЕФДњМлЪЧвЛбљЕФЃЌЭЌЪБзѓВрCuboidГ§СЫОпгагвВрCuboidЕФВщбЏжЇГжФмСІЭтЃЌЛЙФмжЇГжДјгаЮЌЖШDЕФВщбЏЃЌвђДЫгвВрCuboidОЭПЩвдБЛШЅГ§ЁЃ
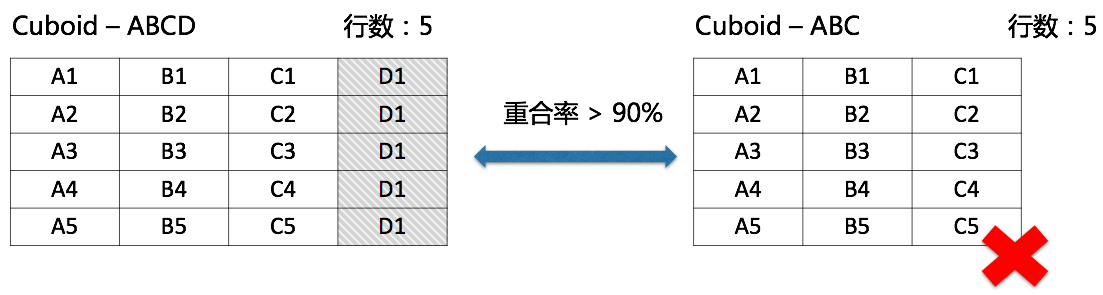
ЭМ - 4 ШЅГ§ШпгрCuboid
дйПМТЧВщбЏашЧѓЃЌдкБЈБэЛђЖрЮЌЗжЮіГЁОАжаЃЌгааЉЮЌЖШЪЧУПДЮВщбЏЖМЛсГіЯжЕФЃЌШчФъЗнЃЛгааЉЮЌЖШзмЪЧвЛЦ№ГіЯжЕФЃЌШчПЊЪМЪБМфЁЂНсЪјЪБМфЃЛгааЉЮЌЖШМфЪЧгаВуМЖЙиЯЕЕФЃЌШчЩЬЦЗЗжРрЛђЕиРэаХЯЂЁЃГфЗжРћгУВщбЏЕФетаЉЪЕМЪашЧѓвВФмШЅГ§ВЛашвЊЕФCuboidЃЌР§ШчЃКШчЙћФъЗнЪЧБивЊЕФЃЌФЧУДЫљгаВЛАќКЌФъЗнЮЌЖШЕФCuboidЖМПЩвдБЛШЅГ§ЃЛШчЙћСНИіЮЌЖШзмЪЧЭЌЪБГіЯжЃЌФЧУДететаЉЮЌЖШЕЅЖРГіЯжЕФCuboidОЭПЩвдБЛШЅГ§ЁЃ
дкApache KylinжаЃЌПЩвдЭЈЙ§ЩшжУCubeЕФЮЌЖШзщКЯЙцдђРДШЅГ§ЮогУЕФCuboidЁЃЪзЯШЃЌПЩвдЭЈЙ§ЖЈвхОлКЯзщЖдЮЌЖШЗжзщЃЌжЛдкУПИіОлКЯзщФкЩњГЩCuboidЁЃДЫЭтЃЌдкЕЅИіОлКЯзщФкВПЃЌЛЙПЩвдЩшжУЮЌЖШзщКЯЙцдђЃЌШчЃКБиаыЮЌЖШгУгкЖЈвхвЛЖЈГіЯжЕФЮЌЖШЁЂСЊКЯЮЌЖШгУгкЖЈвхвЛзщЭЌЪБГіЯжЕФЮЌЖШЁЂВуМЖЮЌЖШгУгкЖЈвхвЛзщгаВуМЖЙиЯЕЕФЮЌЖШЃЌЯъЯИЕФCuboidЩњГЩЙцдђШчЯТЭМЫљЪОЃК
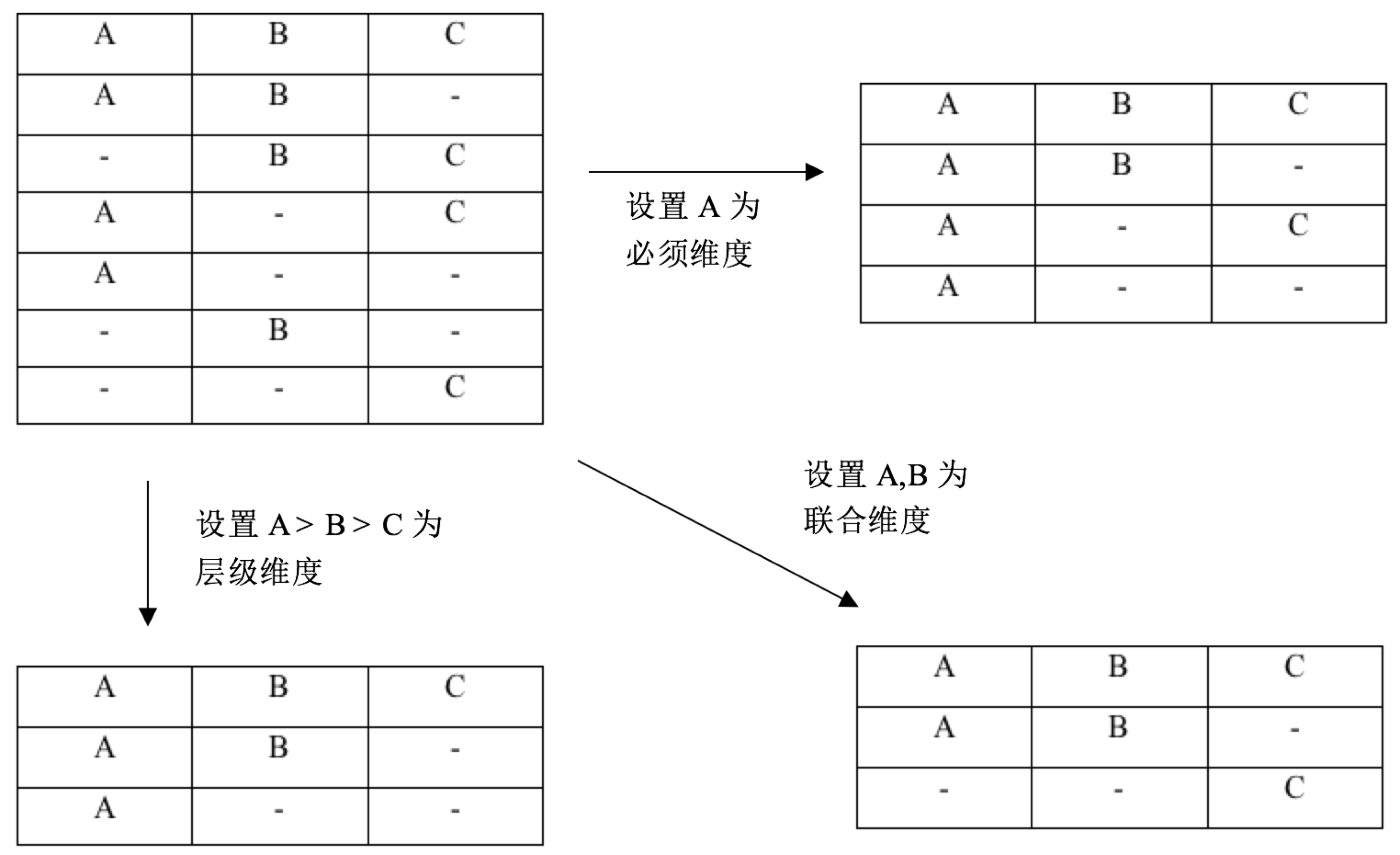
ЭМ - 5ОлКЯзщЙцдђ
CubeгХЛЏЙЄОп
ЩЯЮФНщЩмСЫCubeЩшМЦКЭгХЛЏЕФЛљБОдРэЃЌЕЋЪЧШчКЮЪЕМљЪЧвЛИіБШНЯгаЬєеНЕФЪТЧщЃЌашвЊВйзїепЖдетаЉдРэЕФЪЕЯжЯИНкЁЂЪ§ОнЬиадЁЂВщбЏашЧѓЖМгаНЯЩюРэНтЁЃЫљЮНЙЄгћЩЦЦфЪТЃЌБиЯШРћЦфЦїЁЃетРяНщЩмвЛИіCubeгХЛЏЕФЩёЦїKyBotЃЈhttps://kybot.ioЃЉЃЌПЩвдЭЈЙ§ПЩЪгЛЏЪжЖЮеЙЯжApache
KylinжаЕФИїЯюЭГМЦжИБъЃЌВЂНјаажЧФмЛЏЦРЗжМАЙцдђЃЌгажњгкПьЫйЖЈЮЛВщбЏЁЂЙЙНЈЦПОБКЭбАевНтОіЗНАИЁЃ
KyBotЕФЪЙгУвВЪЎЗжМђЕЅЃЌжЛашвЊМђЕЅЩЯДЋАќКЌШежОЕФеяЖЯАќЃЌКѓЬЈЛсздЖЏЖдеяЖЯАќжаЕФВщбЏЁЂЙЙНЈШежОЕШРњЪЗНјааЗжЮіЃЌЭкОђПЩФмЕФCubeЩшМЦШБЯнЃЌЭЈЙ§ПЩЪгЛЏвГУцжБЙлЕиеЙЯжГіРДЁЃШчЙћЯЃЭћЖдШежОжаЕФУєИааХЯЂЃЈШчIPЕижЗЕШЃЉНјааЭбУєБЃЛЄЃЌвВПЩвдМђЕЅНтОіЁЃ
ЭМ - 6 KyBotЭјеО
бАевCubeЩшМЦШБЯн
ЕБKyBotЗжЮіЭъГЩЃЌдкCubeвЧБэХЬЩЯОЭФмПДЕНCubeЕФеяЖЯНсЙћСЫЃЌАќРЈCubeЦРЗжЁЂCubeХХааЁЂCubeЯъЧщЕШЁЃЭМ7ЕФРзДяЭМеЙЪОЕФОЭЪЧЫљгаCubeЕФећЬхЦРЗжЃЌАќКЌВщбЏадФмЁЂЙЙНЈадФмЁЂХђеЭБЖЪ§ЁЂЪЙгУТЪЁЂФЃаЭЩшМЦЕШ5ИіЮЌЖШЁЃЭЈЙ§етИіЦРЗжЃЌОЭПЩвдвЛблЖдећИіApache
KylinЕФадФмЬхЯжгавЛИіжБЙлШЯЪЖЃЌвВПЩвджБЙлЕиПДГіCubeгХЛЏЕФживЊадКЭБивЊадЁЃР§ШчдкетИіР§згжаПЩвдПДГіЃЌЫфШЛећЬхЕФВщбЏЁЂЙЙНЈадФмНЯКУЃЌЕЋФЃаЭЩшМЦвРШЛгаКмДѓЬсЩ§ЕФПеМфЁЃ

ЭМ - 7 CubeзмЬхЦРЗжРзДяЭМ
СЫНтећЬхадФмжЎКѓЃЌЛЙашвЊНјвЛВНЫѕаЁЗЖЮЇбАевПЩгХЛЏЕФCubeЃЌЭЈЙ§ЭМ8ЕФCubeХХааОЭПЩвдЁЃЭМжаДгХђеЭБЖЪ§ЁЂВщбЏДЮЪ§ЁЂТ§ВщбЏДЮЪ§ЖдCubeНјааСЫХХУћЃЌХХдкЪзЮЛЕФОЭЪЧдкетвЛХХУћжазюашвЊгХЛЏЕФCubeЃЌР§ШчЃЌХђеЭБЖЪ§ХХУћЕквЛИіCubeЕФХђеЭБЖЪ§дЖдЖИпгкЦфЫћCubeЃЌЫЕУїгаОоДѓЕФгХЛЏПеМфЃЌШчЙћЖдЪ§ОнДцДЂЛђЙЙНЈЪБМфгавЊЧѓЃЌОЭПЩвдЯШДгетИіCubeШыЪжНјаагХЛЏЁЃЭЌбљЕФЃЌШчЙћЖдВщбЏаЇТЪгавЊЧѓЃЌОЭПЩвдДгТ§ВщбЏДЮЪ§ХХааШыЪжЁЃ
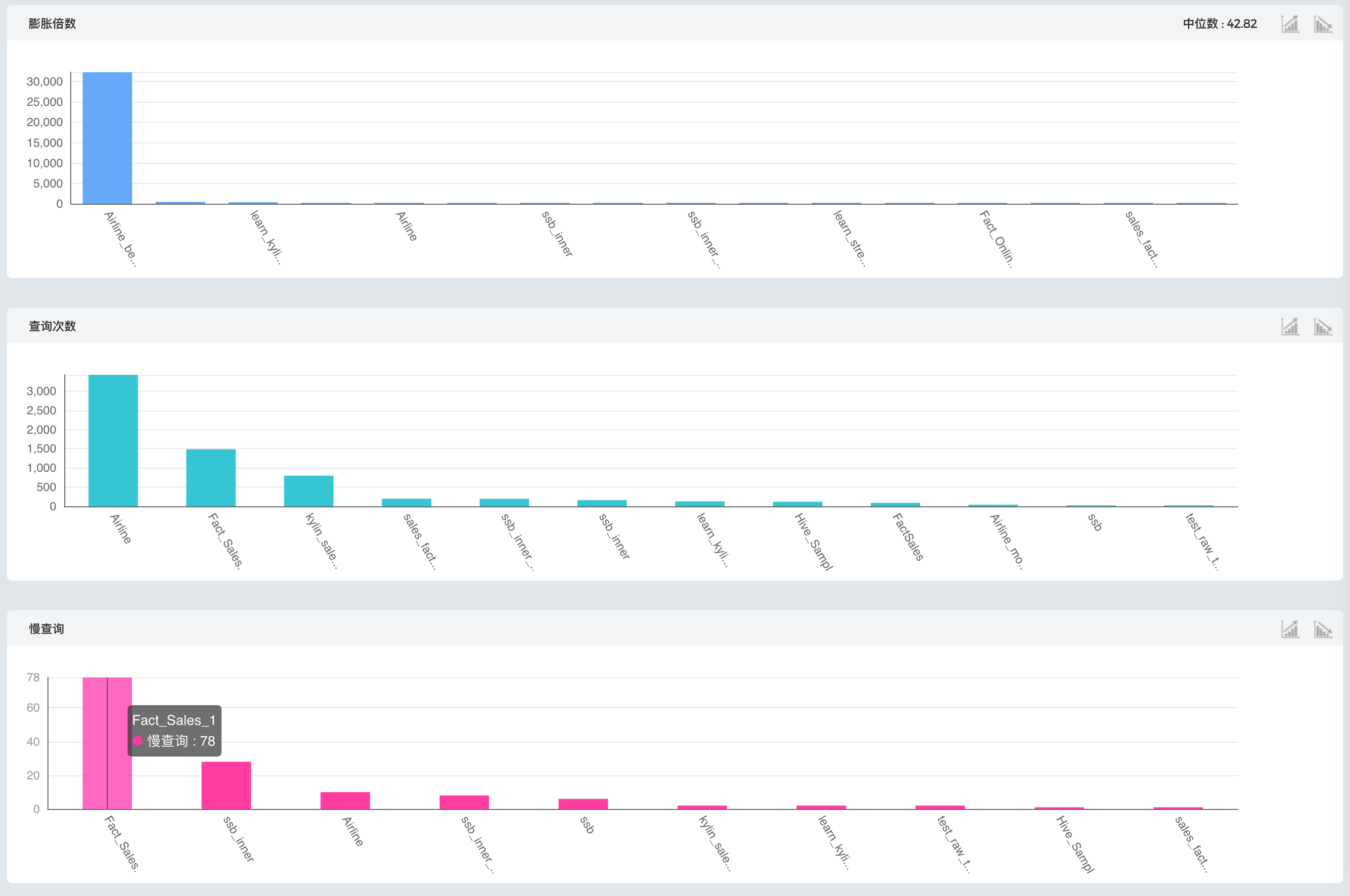
ЭМ - 8 CubeХХаа
ЫјЖЈСЫгХЛЏФПБъЃЌЕЅЛїетИіCubeЕФжљзДЭМВщПДCubeЯъЧщЃЌШчЭМ9ЫљЪОЁЃЭМжа1ЧјгђЪЧЕБЧАCubeЕФЦРЗжЃЌПЩвджБЙлПДГіCubeдкФЃаЭЩшМЦКЭВщбЏадФмЗНУцгаШБЯнЃЌЦфжаФЃаЭЩшМЦЕФгХСгРДздЖдCuboidжиКЯТЪКЭВщбЏЦЅХфЖШЕФЭГМЦЁЃЦРЗжЯТЗНЕФжљзДЭМЯдЪОCuboidжиКЯТЪХХУћЃЌCuboidжиКЯТЪДњБэвЛИіCuboidКЭЫћИИНкЕуCuboidааЪ§ЕФБШР§ЃЌШчЙћжиКЯТЪНгНќ100%ЃЌИљОнЩЯЮФЁАCuboidгХЛЏдРэЁБвЛНкЃЌетИіCuboidЪЧПЩвдБЛШЅГ§ЕФЁЃИљОнЭМжаЕФР§згЃЌга800ЖрИіCuboidжиКЯТЪИпгк90%ЃЌЖМЪЧПЩвдБЛШЅГ§ЕФЁЃ
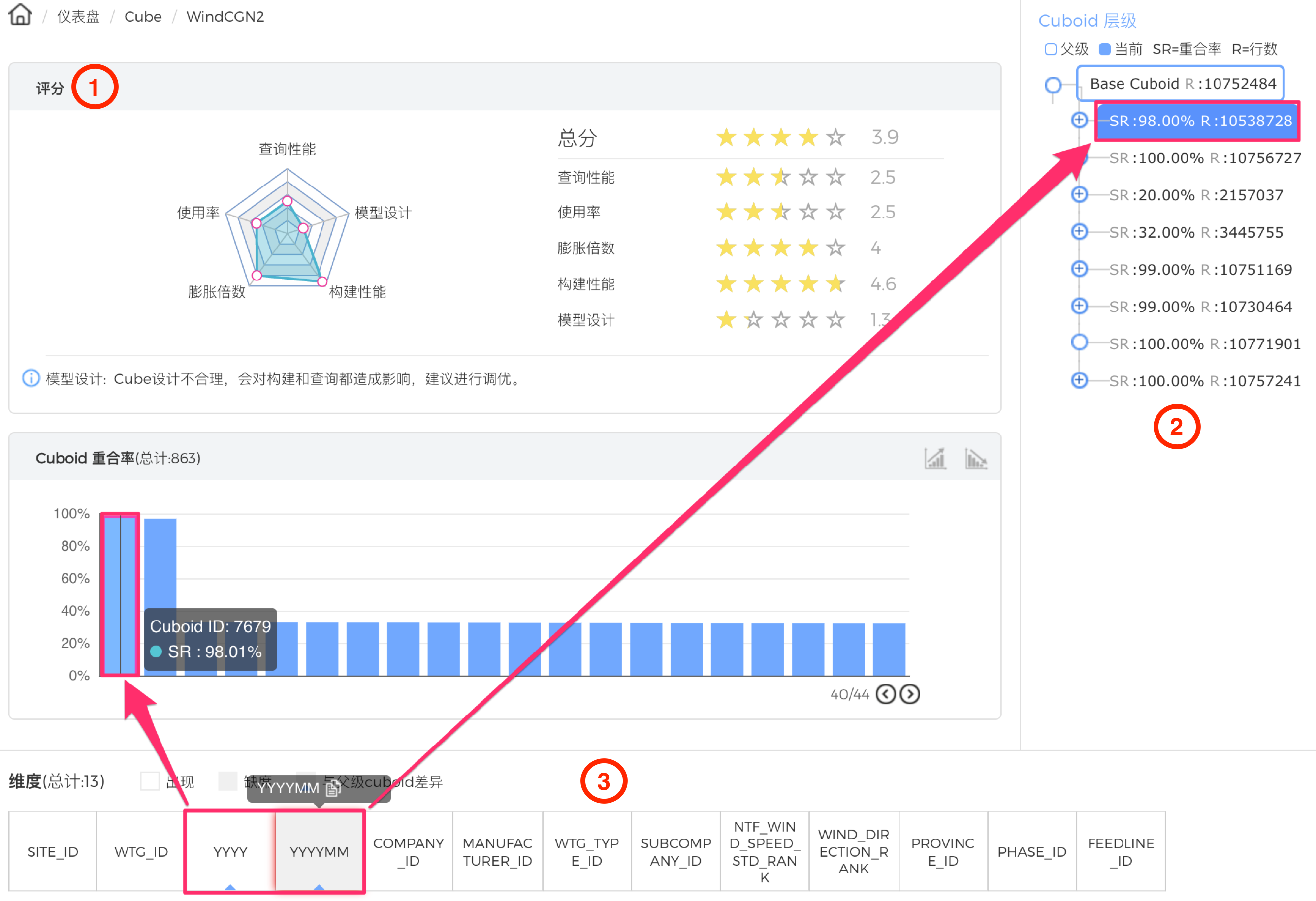
ЭМ - 9 CubeЕїгХ
НгЯТРДНјШыЪЕМЪВйЕЖЛЗНкЃЌЯШРДПДФЃаЭЩшМЦЕФЮЪЬтЁЃЭМжа2ЧјгђЪЧCuboidВуМЖЕФЪїзДЭМЃЌдкИљНкЕуЃЈBase
CuboidЃЉЕФ8ИізгНкЕуРяЃЌЗЂЯжга6ИіНкЕуЕФжиКЯТЪГЌЙ§СЫ98%ЃЌЧвааЪ§ГЌЙ§СЫ1ЧЇЭђЃЌЫЕУїетаЉCuboidМДЪЙБШИИCuboidЯрБШЩйСЫвЛИіЮЌЖШЃЌЕЋвРШЛУЛгаМѕЩйНсЙћМЏЪ§СПЃЌЛЛОфЛАЫЕЃЌЩйЕєЕФетИіЮЌЖШЪеЫѕСІНЯШѕЃЌдвђПЩФмЪЧвђЮЊетИіЮЌЖШЛљЪ§НЯЕЭЃЌЛђепCuboidжаАќКЌГЌИпЛљЪ§ЕФЮЌЖШЁЃЭЈЙ§ЕЅЛїЕквЛИізгCuboidЃЌдкЧјгђ3ВщПДИїИіЮЌЖШЕФЯъЯИаХЯЂЃЌВЛФбЗЂЯжЃЌИУCuboidВЂУЛгаГЌИпЛљЪ§ЮЌЖШЃЌЖјКЭИИМЖCuboidВювьЕФЮЌЖШYYYYMMЛљЪ§КмЕЭЁЃЫфШЛYYYYКЭYYYYMMСНСавбЪЧВуМЖЮЌЖШЃЌЕЋСНИіЮЌЖШЕФЛљЪ§ОљКмЕЭЁЃЭЌРэЃЌЗЂЯжCATA1_IDКЭCATA2_IDЕФзщКЯвВЪЧШчДЫЃЌШчЯТЭМЫљЪОЁЃМјгкYYYYЁЂYYYYMMЁЂCATA1_IDЁЂCATA2_IDет4ИіЮЌЖШЕФЪеЫѕСІНЯШѕЃЌПЩвдКЯВЂГЩвЛИіСЊКЯЮЌЖШЁЃ
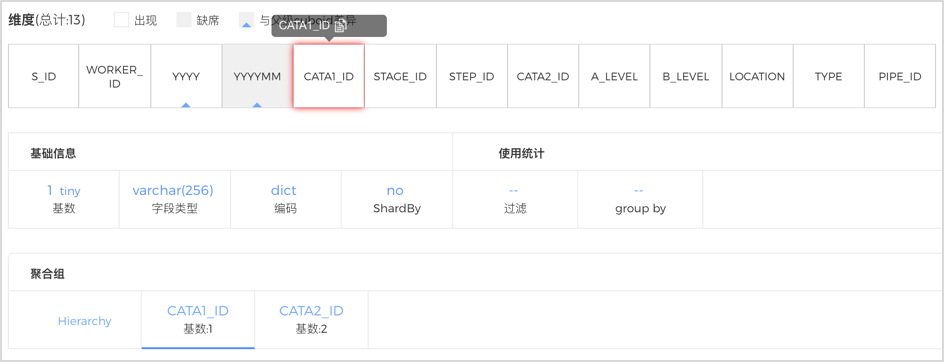
ЭМ - 10 CubeЮЌЖШаХЯЂ
ДЫЭтЃЌЛЙгаЖрИіЛљЪ§НЯЕЭЕФЮЌЖШЃЈLOCATIONЁЂTYPEЁЂPIPE_IDЃЉвВгаЪеЫѕСІНЯШѕЕФЮЪЬтЃЌвВгІКЯВЂГЩвЛзщСЊКЯЮЌЖШЁЃетбљЃЌШчЯТЭМЫљЪОЃЌгЩгкСЊКЯЮЌЖШЕФв§ШыЪЙCuboidЪ§Дг28МѕаЁЕН25ЃЌгааЇЕиНЕЕЭСЫCubeХђеЭТЪЁЂЬсЩ§ЙЙНЈадФмЃЌЭЌЪБгжВЛгАЯьВщбЏадФмЁЃ

ЭМ - 11 ЩшжУСЊКЯЮЌЖШ
зюКѓРДПДВщбЏаЇТЪЕФЮЪЬтЁЃШчЯТЭМЫљЪОЃЌЗЂЯжетИіCubeжагавЛИіЮЌЖШWORKER_IDЛљЪ§дк1300вдЩЯЃЌЧвБЛЩшЮЊБиаыЮЌЖШЁЃЕЋЪЧдкЪЙгУЭГМЦжаПДЕНЃЌетИіЮЌЖШВЂУЛгаБЛSQLгУЕНЙ§ЃЌетаЉSQLБОЩэПЩвдЗУЮЪвЛИіЬхСПНЯаЁЕФCuboidЃЌЕЋгЩгкWORKER_IDБЛЩшЮЊБиаыЮЌЖШЃЌЫљгаЕФCuboidЖМЛсАќКЌетИі1300+ЛљЪ§ЕФЮЌЖШЃЌЕМжТЫљгаCuboidМЧТМЪ§ХђеЭЃЌдьГЩВщбЏадФмЦеБщНЯВюЁЃвђДЫЃЌШЁЯћетвЛЮЌЖШЕФБиаыЮЌЖШЩшжУЃЌЪЦБиФмЙЛДѓДѓЬсЩ§CubeЕФВщбЏадФмЁЃ
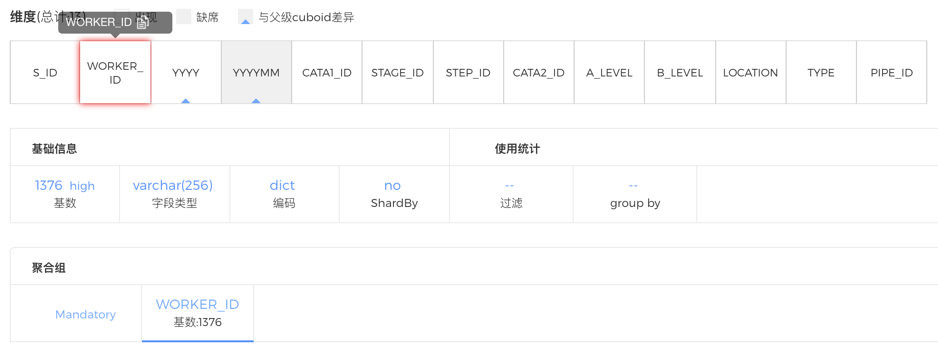
ЭМ - 12 ШЅГ§ВЛЧЁЕБЕФБиаыЮЌЖШ
бАевCubeЙЙНЈЦПОБ
дкApache KylinжаЃЌCubeЕФЙЙНЈЪЧЭЈЙ§вЛЯЕСаMapReduceКЭSparkШЮЮёЭъГЩЕФЃЌЦфжаMapReduceеМЖрЪ§ЁЃдкKyBotЩЯвВПЩвдПДЕНCubeЙЙНЈШЮЮёЕФПЩЪгЛЏЙ§ГЬЃЌШчЯТЭМЫљЪОЃЌОЭЪЧвЛИіCubeЙЙНЈЕФЩњУќжмЦкЃЌЦфжаУПвЛЬѕТЬЩЋгОЕРДњБэСЫЙЙНЈШЮЮёЕФвЛИіВНжшЃЌгОЕРзюГЄЕФвЛВНЫЕУїКФЪБзюДѓЃЌШчЙћвЊгХЛЏЃЌОЭПЩвдЪзЯШбаОПетвЛВНЁЃ
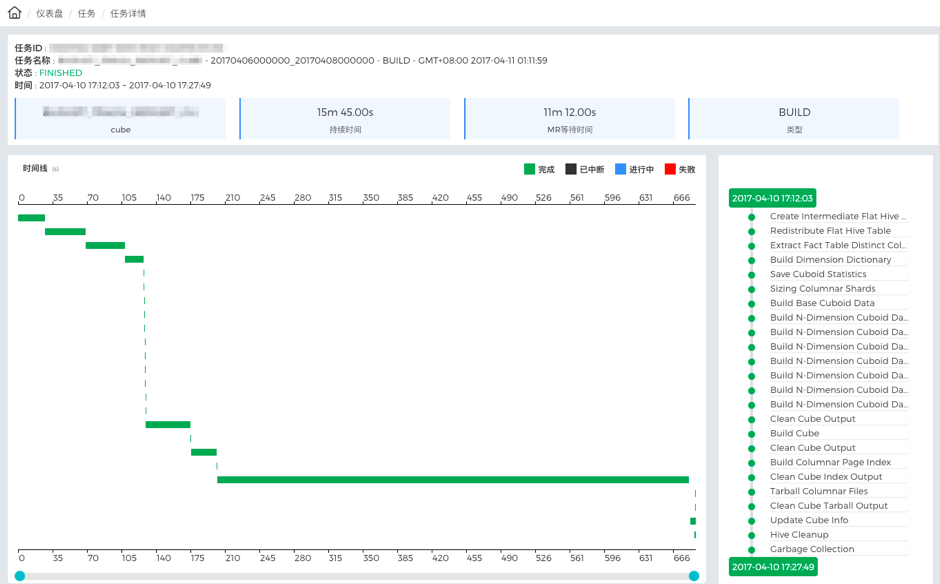
ЭМ - 13 CubeЙЙНЈЩњУќжмЦк
ШчЙћЩЯДЋСЫетИіШЮЮёЕФШЮЮёеяЖЯАќЃЌЛЙПЩвдМЬајВщПДУПвЛИіMapReduceВНжшЕФПЩЪгЛЏЙ§ГЬЁЃЕЅЛїетИіКФЪБзюОУЕФгОЕРЃЌОЭЛсДђПЊЯТЭМЫљЪОЕФMapReduceЩњУќжмЦкЃЌдкетИіР§згжаЃЌЮвУЧЗЂЯжЭЌвЛЪБМфжЛгавЛИіTaskдкдЫааЃЌЕквЛИіtaskПЊЪМЧАЛЙгаНЯГЄЕФЕШД§ЪБМфЃЌЫЕУїМЏШКзЪдДПЩФмНЯЮЊНєеХЁЃШчвЊгХЛЏЃЌНЈвщМьВщМЏШКзЪдДХфжУКЭЕїЖШЁЃ
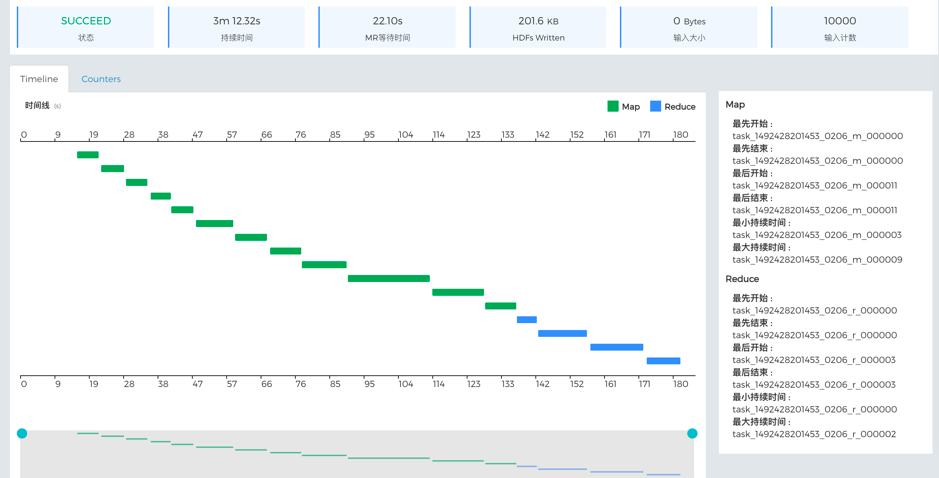
ЭМ - 14 MapReduceШЮЮёЩњУќжмЦк
бАевВщбЏЦПОБ
ВщбЏЪЧApache KylinЕФЧПЯюЃЌЕЋвВДцдкжжжжвђЫиЕМжТФГаЉВщбЏБфТ§ЁЃВщбЏадФмвЛАуЭЈЙ§ећЬхЕФадФмЁЂВЂЗЂЭГМЦЪ§ОнРДЬхЯжЃЌKyBotЕФВщбЏвЧБэХЬПЩвджБЙлеЙЯжВЛЭЌЮЌЖШЕФВщбЏЭГМЦаХЯЂЁЃШчЯТЭМЫљЪОЃЌетРяПЩвдПДЕНВщбЏЯьгІЪБМфЕФ90АйЗжЮЛКЭ95АйЗжЮЛЁЂВЛЭЌЯьгІЪБМфЗжВМЁЂУПШеадФмБфЛЏЕШЃЌгУгкжБЙлАбЮеВщбЏадФмЕФећЬхБэЯжЃЛЯТЗНЕФВщбЏДЮЪ§ЁЂШЫОљВщбЏДЮЪ§ЁЂУПШеВщбЏДЮЪ§ЕШжБЙлеЙЯжApache
KylinзїЮЊВщбЏЗўЮёЕФЪЙгУТЪКЭВЂЗЂЪ§ЁЃ
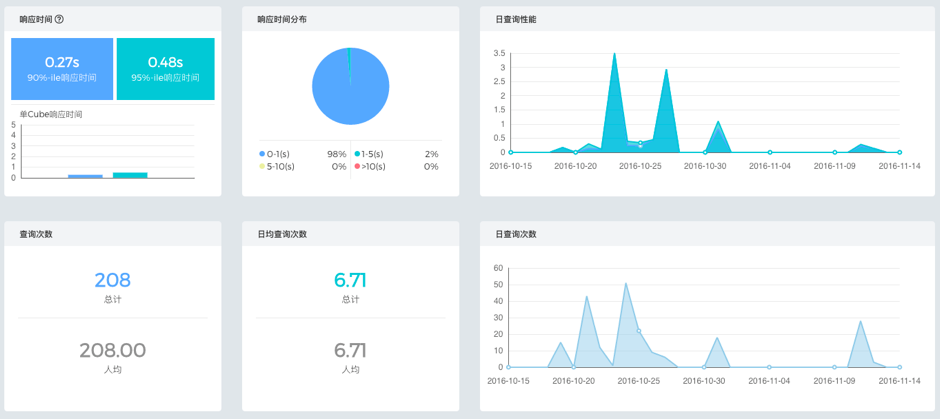
ЭМ - 15 ВщбЏЭГМЦЭМ
ЮЊСЫЬсЩ§Apache KylinЕФВщбЏадФмЃЌЪзЯШвЊЖЈЮЛТ§ВщбЏЁЃВщбЏвЧБэХЬЯТЗНЕФВщбЏУїЯИСаБэжаПЩвдПДЕНТ§ВщбЏСаБэЃЌВЂДгетРяНјШывЛИіВщбЏЕФЯъЧщвГУцЃЌШчЯТЭМЫљЪОЃК
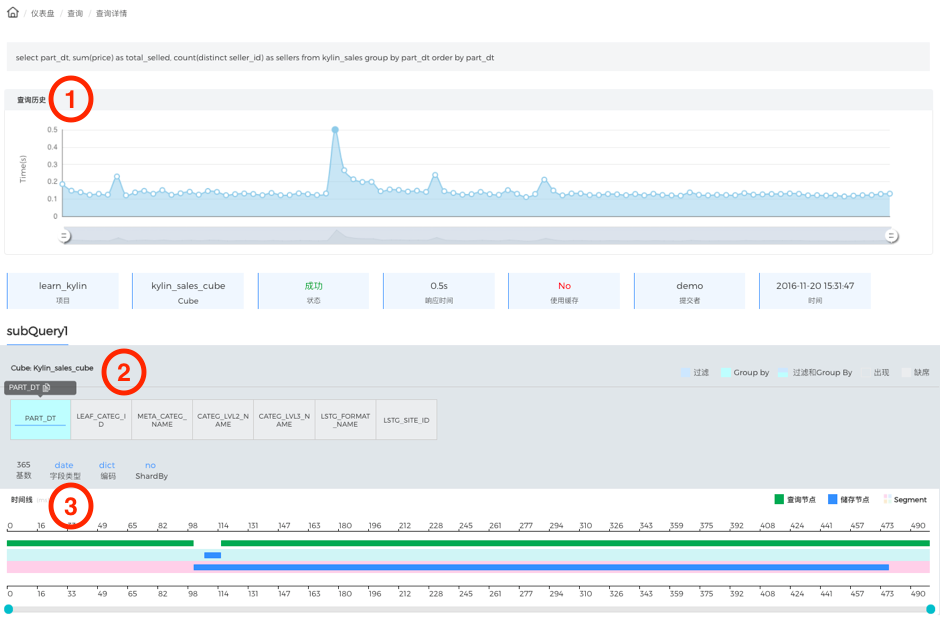
ЭМ - 16 ВщбЏЯъЧщвГ
дкВщбЏЕФЯъЧщвГЃЌЧјгђ1ЪЧИУВщбЏЕФРњЪЗжДааМЧТМЃЌЭЈЙ§ЕЅЛїЭМжаЕФПеаФдВШІПЩвдЖЈЮЛЕНФГДЮВщбЏМЧТМЁЃЧјгђ2ЪЧИУВщбЏЛїжаЕФCuboidМАRowkeyЕФЪЙгУЧщПіЃЌТЬЩЋДњБэетИіRowkeyзїЮЊВщбЏЕФЙ§ТЫЬѕМўЃЌРЖЩЋДњБэRowkeyзїЮЊВщбЏЕФGROUP
BYзжЖЮЃЌАзЩЋДњБэГіЯждкCuboidЩЯЕЋУЛБЛВщбЏгУЕНЕФRowkeyЁЃвђЮЊApache KylinЪЙгУHBaseзїДцДЂв§ЧцЃЌЫљвдВЮгыЙ§ТЫЕФRowkeyХХдкCuboidЧАУцЛсЖдВщбЏадФмгаАяжњЁЃвђДЫЃЌРЖТЬбеЩЋЕФЫГађОЭЯдЕУгШЮЊживЊСЫЁЃЭМ17ЪЧвЛИіашвЊгХЛЏЕФВщбЏР§згЃЌТЬЩЋRowkeyдкФЉЮВЃЌПЩФмгАЯьHBaseЙ§ТЫЕФаЇТЪЃЛжаМфга6ИіАзЩЋRowkeyЃЌЪЧвђЮЊетИі6ИіЮЌЖШБЛЩшЮЊСЫБиаыЮЌЖШЃЌЦфжаЛЙга4ИіЪЧИпЛљЪ§ЮЌЖШЃЌЛсДјРДНЯИпЕФДцДЂЩЈУшКЭдкЯпМЦЫуДњМлЃЌгАЯьВщбЏЕФаЇТЪЁЃгХЛЏЗНАИЪЧШЁЯћБиаыЮЌЖШЕФЩшжУЛђИФгУСЊКЯЮЌЖШЁЃ

ЭМ - 17 Д§гХЛЏВщбЏЃЈ1ЃЉ
ЭМ16ЕФЧјгђ3ЪЧИУВщбЏжДааЕФЩњУќжмЦкЃЌЦфжаТЬЩЋгОЕРДњБэApache KylinВщбЏНкЕуЕФЯпГЬЃЌРЖЩЋгОЕРДњБэHBaseНкЕуЕФжДааЯпГЬЁЃЭМ18ЪЧвЛИіашвЊгХЛЏЕФР§згЃЌЭМжаСНЬѕРЖЩЋгОЕРГЄЖШЧјБ№КмДѓЃЌЪЧгЩгкЪ§ОнЧаЗжRegionВЛЦНКтЕМжТВЛЭЌRegion
ServerИКдиВювьНЯДѓЁЃвђДЫПЩвдЭЈЙ§ЩшжУShard ByзжЖЮЛђЕїећRegionЧаЗжЯрЙиЕФВЮЪ§РДМгЫйВщбЏЁЃ

ЭМ - 18Д§гХЛЏВщбЏЃЈ2ЃЉ
змНс
БОЮФзХжиНщЩмСЫApache KylinжаЖдCubeКЭВщбЏНјаагХЛЏЕФдРэЁЂЙЄОпЁЂЗНАИКЭАИР§ЃЌЯЃЭћФмЙЛАяжњЪЙгУApache
KylinЕФХѓгбНтОіЙЄзїЩЯЕФМЌЪжЮЪЬтЁЃВщбЏашЧѓПЩФмЫцзХвЕЮёЗЂеЙЖјВЛЖЯБфЛЏЃЌЖјCubeгХЛЏОЭЪЧВЛЖЯБЃжЄCubeадФмЕФгааЇЪжЖЮЁЃЮЊСЫИќМгИпаЇЕиЭъГЩЕїгХЃЌЪЙгУKyBotЪЧвЛИізюМђЕЅЕФЗНЪНЃЌЮДРДЕФKyBotвВЛсИќМгздЖЏЛЏКЭжЧФмЛЏЁЃзюКѓЃЌЯЃЭћЁАїшїыЩёЪоЁБдкУПвЛЦЌДѓЪ§ОнВндЩЯЖМФмЪЉеЙзюДѓЕФЭўСІЃЁ
|









