ФПЧАЮЊжЙЃЌвбОЬжТлСЫЛњЦїбЇЯАКЭХњДІРэФЃЪНЕФЪ§ОнЭкОђЁЃЯждкЩѓЪгГжајДІРэСїЪ§ОнЃЌЪЕЪБМьВтЦфжаЕФЪТЪЕКЭФЃЪНЃЌКУЯёДгКўВДРДЕНСЫКгСїЁЃ
ЯШбаОПвЛЯТВЛЖЯИФБфЕФЖЏЬЌЛЗОГДјРДЕФЬєеНЃЌдкСаГіСїДІРэгІгУЕФЯШОіЬѕМўЃЈШчЃЌгыTwitterЕФTCP SocketsЃЉжЎКѓЃЌ НсКЯSpark, Kafka and Flume АбЪ§ОнЗХШывЛИіЕЭбгГйЃЌИпЭЬЭТСПЃЌПЩЫѕЗХЕФДІРэСїЫЎЯпЁЃ
вЊЕуШчЯТ:
- ЗжЮіСїЪНгІгУМмЙЙЕФЬєеНЃЌдМЪјКЭашЧѓ
- РћгУSpark Streaming Дг TCP socket жаДІРэЪЕЪБЪ§Он
- СЌНг Twitter ЗўЮёЃЌзМЪЕЪБНтЮі tweets
- ЪЙгУ Spark, Kafka КЭ Flume НЈСЂвЛИіПЩППЃЌШнДэЃЌПЩЫѕЗХЃЌИпЭЬЭТСПЃЌЕЭбгГйЕФМЏГЩгІгУ
- вд Lambda КЭ Kappa ЕФМмЙЙЗЖЪННсЮВ
Spark StreamingдкЪ§ОнУмМЏаЭгІгУжаЕФЮЛжУ
АДееЙпР§, ЯШПДвЛЯТзюГѕЕФЪ§ОнУмМЏаЭгІгУМмЙЙЃЌжИУїЮвУЧЫљИааЫШЄЕФ Spark Streaming ФЃПщЕФЫљДІЮЛжУ.
ЯТЭМзХжижИУїСЫећЬхМмЙЙжаЕФSpark StreamingФЃПщЃЌSpark SQLКЭ Spark MLlibЃК
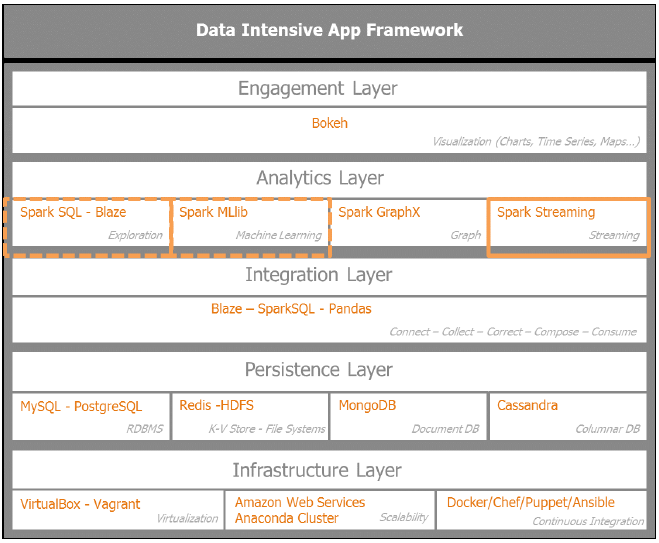
5-1 Streaming дкЪ§ОнУмМЏаЭгІгУМмЙЙЕФЮЛжУ
Ъ§ОнСїПЩвдРДздЙЩЦБЪаГЁЕФЪБађЗжЮіЃЌЦѓвЕНЛвзЃЌИїжжНЛЛЅЃЌЪТМўЃЌwebСїСПЃЌЕуЛїСїЃЌКЭДЋИаЦїЪ§ОнЕШЃЌЖМЪЧМАЪБЧвДјгаЪБМфДСЕФЪ§ОнЁЃгУР§гаЦлеЉМьВтКЭЗРЮБЃЌвЦЖЏЕФНЛВцЯњЪлКЭЯњЪлЬсЩ§ЃЌЛђепНЛЭЈдЄОЏЁЃетаЉЪ§ОнСїашвЊМАЪБДІРэвдБугкМрВтЃЌР§Шч вьГЃМьВтЃЌвьГЃЦцЕуЃЌРЌЛјгЪМўЃЌЦлеЉКЭШыЧж; вВПЩЬсЙЉЛљДЁЕФЭГМЦЃЌМћНтЃЌЧїЪЦЃЌКЭЭЦМіЁЃ ФГаЉЧщаЮЃЌзмНсадЕФЛузмаХЯЂашвЊДцДЂвдБИНЋРДЪЙгУЁЃДгМмЙЙЗЖЪНЕФНЧЖШПДЃЌЮвУЧДгУцЯђЗўЮёЕФМмЙЙзЊЮЊЪТМўЧ§ЖЏЕФМмЙЙЁЃ
Ъ§ОнЕФСїДІРэгаСНИіФЃаЭ:
- дкЪ§ОнЕНДяЪБМАЪБДІРэУПЬѕМЧТМЃЌдкДІРэЧАВЛашвЊдкШнЦїжаЛКДцМЧТМЃЌБШШч Twitter's Storm, Yahoo's S4, КЭ Google's MillWheel.
- ЮЂаЭХњДІРэ ЛђепаЁМфИєжДааХњДІРэМЦЫуЃЌР§Шч Spark Streaming and Storm Trident. ИљОнЮЂаЭХњДІРэЩшжУЕФЪБМфДАПкЃЌНЋСїШыЕФЪ§ОнМЧТМЛКГхЕНвЛИіШнЦїжаЁЃ Spark Streaming ОГЃгУРДгы Storm БШНЯЃЌетЪЧСНжжВЛЭЌЕФСїЪ§ОнФЃаЭЁЃ Spark Streaming ЛљгкЮЂаЭХњДІРэЃЌЖј Storm ЛљгкМАЪБДІРэСїШыЕФЪ§ОнЁЃ Storm вВЬсЙЉСЫЮЂаЭХњДІРэбЁЯю МД Storm TridenЁЃ
СїДІРэгІгУЕФжївЊЧ§ЖЏвђЫиЕФЪБМфбгГйЁЃЪБбгДг RPC (short for Remote Procedure Call) ЕФКСУы ЕНМИУы ЕНЮЂаХХњДІРэЗНАИЕФМИЗжжгВЛЕШЁЃ RPC дЪаэЧыЧѓГЬађгыдЖГЬЗўЮёЦїжЎМфЕФЭЌВНВйзїЁЃЯпГЬдЪаэЖрИі RPC ЕїгУЕФВЂЗЂЁЃ
ЗжВМЪНRPC ФЃаЭЪЕЯжЕФвЛИіЪЕР§ОЭЪЧ Apache Storm. Storm ЪЕЯжСЫЮоБпНчдЊзщЕФЮозДЬЌКСУыМЖбгГйДІРэЃЌНсКЯЪ§ОнСїзїЮЊХчЗЂдДЪЙгУСЫЭиЦЫЛђЖЈЯђЛЗЭМЕФМАЪБЃЌЬсЙЉСЫЙ§ТЫЃЌ join, ОлКЯКЭзЊЛЛ. Storm вВЪЕЯжСЫвЛИіИпВуГщЯѓНазі Trident , гыSparkРрЫЦ, вдЮЂаЭХњДІРэНјааСїЪНЪ§ОнДІРэЁЃ
ПМТЧЪБбгЕФЯожЦ, ДгКСУыЕНУыМЖ, Storm ЪЧИіКмКУЕФКђбЁ. ЖдгкУыЕНЗжжгМЖ, Spark Streaming and Storm Trident ЪЧзюМббЁдёЁЃ ЖдгкШєИЩЗжжгвдЩЯЃЌ Spark КЭ NoSQL Ъ§ОнПтШч Cassandra КЭHBase ЪЧКЯЪЪЕФЗНАИ. ЖдгкЖраЁЪБдЫЫуКЃСПЪ§ОнЃЌHadoop ЪЧРэЯыЕФОКељепЁЃ ОЁЙмЭЬЭТСПгтЪБбгЯрЙиЃЌЕЋВЛЪЧвЛИіМђЕЅЕФЗДЯпадЙиЯЕЁЃ ШчЙћДІРэвЛЬѕЯћЯЂашвЊ2 ms, жЛШЁОігкбгГйЕФЧщПі, ПЩвдМйЩшЭЬЭТСПЯожЦдк500ЬѕЯћЯЂУПУыЁЃШчЙћЛКДцСЫ8msЕФЪ§ОнЃЌФЧУДХњДІРэдЪаэИќИпЕФЭЬЭТСПЁЃ 10 ms ЪБбг, ЯЕЭГПЩвдЛКГх10,000 ЬѕЯћЯЂ. ЮЊСЫвЛИіПЩШЬЪмЕФЪБбгдіГЄЃЌЮвУЧвЊЯджјЕФдіМгЭЬЭТСПЁЃетЪЧSpark Streaming ЮЂаЭХњДІРэЕФвЛИіФЇЗЈЁЃ
Spark Streaming ФкВПЙЄзїЗНЪН
Spark Streaming ГфЗжРћгУСЫ Spark ЕФКЫаФМмЙЙЃЌзїЮЊСїДІРэЙІФмЕФШыПкЕуЃЌЫќЙЙНЈдк SparkContext ЕФ StreamingContext жЎЩЯ. МЏШКЙмРэЦїНЋжСЩйЕЅЖРЗжЦЌвЛИіЙЄзїНкЕузїЮЊНгЪеЦїЃЌетЪЧвЛИіГЄЪБМфдЫааЕФШЮЮёжДааЦїРДДІРэНјШыЕФСїЪ§ОнЁЃ жДааЦїДДНЈ Discretized Streams ЛђепДгЪфШыЪ§ОнСїжаЕУРДЕФ DStreamsЃЌ DStream ФЌШЯЮЊСэвЛИіworker ЕФЛКДцЁЃ НгЪеЦїЗўЮёгкЪфШыЪ§ОнСїЃЌЖрИіНгЪеЦїЬсЩ§СЫВЂааадЃЌВњЩњЖрИіDStreams ЃЌ Spark гУЫќunite Лђ join RDD.
ЯТЭМИјГіСЫ Spark Streaming ЕФФЧБпЙЄзїИХвЊЁЃПЭЛЇЖЫЭЈЙ§МЏШКЙмРэЦїгы Spark МЏШКНЛЛЅ ЃЌSpark Streaming гавЛИізЈЪєЕФworker дЫаазХГЄШЮЮёРДНгД§ЪфШыЕФЪ§ОнСїЃЌзЊЛЏЮЊ discretized streams ЛђDStreams. НгЪеЦїВЩМЏЃЌЛКДцЃЌИДжЦЪ§ОнЃЌШЛКѓЗХШывЛИі RDDsЕФСї.
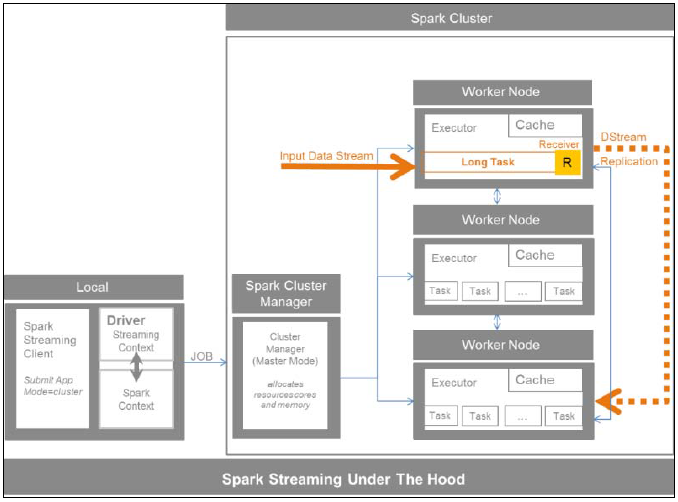
5-2 Spark Streaming ФкВПЙЄзїЗНЪН
Spark НгЪеЦїФмЙЛДгЖржжЪ§ОндДНгЪеЪ§ОнЁЃКЫаФЕФЪфШыдДАќРЈДгTCP socket КЭ HDFS/Amazon S3 ЕН Akka Actors. ЦфЫќЕФЪ§ОндДАќРЈ Apache Kafka, Apache Flume, Amazon Kinesis, ZeroMQ, Twitter, вдМАЦфЫќгУЛЇЖЈвхЕФНгЪеЦїЁЃ
ЮвУЧПЩвдЧјЗжзЪдДЪЧЗёПЩППЃЌПЩППЕФЪ§ОндДПЩвдШЗШЯЪ§ОнЕФНгЪеЦОжЄвдМАИББОФмЗёжиЗЂ,ЗЧПЩППЪ§ОндДжИНгЪеЦїВЛФмШЗШЯЯћЯЂЕФНгЪеЦОжЄЁЃ Spark ПЩвдЖдworkersЃЌЗжЧјКЭНгЪеЦїЕФЪ§СПНјааЫѕЗХЁЃ
ЯТЭМИјГіСЫSpark Streaming ПЩФмЕФЪ§ОндДКЭГжОУЛЏбЁЯю:
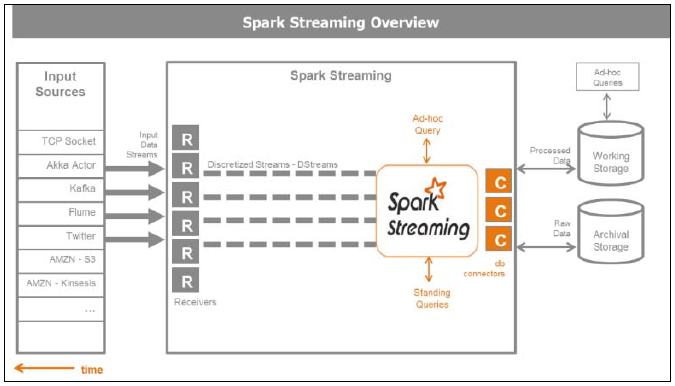
5-3 Spark Streaming ИХРР
Spark Streaming ЕФЕзВуЛљДЁ
Spark Streaming гЩНгЪеЦїЃЌ Discretized Streams КЭ гУгкГжОУЛЏЕФSpark Connectors зщГЩ. зїЮЊ Spark Core, ЛљБОЕФЪ§ОнНсЙЙЪЧ RDD, ЛљБОБрГЬГщЪЧ Discretized Stream Лђ DStream.
ЯТЭМНтЪЭСЫПДзі RDDsСЌајађСаЕФ Discretized Streams. DStream ЕФХњДІРэМфИєЪЧПЩХфжУЕФЁЃ

5-4 RDD-Descretized Stream
DStreams ЪЧдкХњДІРэМфИєЪЧЖдСїШыЪ§ОнЕФПьееЁЃЪБМфВНГЄПЩвдДг500ms ЕНМИУыЃЌDStream ЕФЕзВуНсЙЙЪЧвЛИі RDD. вЛИіDStream ЛљБОЩЯЪЧ RDDsЕФвЛИіСЌајађСаЁЃетЪЙЕУSpark Streaming ЗЧГЃЧПДѓЃЌПЩвдГфЗжРћгУSpark Core жавбгаЕФКЏЪ§ЃЌЪ§ОнзЊЛЛКЭЖЏзїЃЌ ПЩвдгыSpark SQL ЖдЛА, дкСїШыЕФЪ§ОнСїЩЯжДааSQL ВщбЏКЭ Spark MLlib. ЭЈгУЕФМАЛљгкМќжЕЖдRDDsЕФЪ§ОнзЊЛЛЭЌбљЪЪгУЁЃDStreams ЕУвцгк RDDs ФкВПЬхЯЕКЭШнДэЛњжЦЁЃ discretized stream гаЖюЭтЕФзЊЛЛКЭЪфГіВйзїЁЃDStream ЕФДѓЖрЪ§ЭЈгУВйзїЪЧ transform КЭ foreachRDD.
ЯТЭМИјГіСЫ DStreamsЕФЩњУќжмЦкЃЌНЋЯћЯЂЭЈЙ§ЮЂаЭХњДІРэЪЕЯжДДНЈГЩ RDDs ЃЌRDDsЩЯЕФЪ§ОнзЊЛЛКЏЪ§КЭЖЏзї ДЅЗЂСЫ Spark jobs. ДгЩЯЖјЯТЗжВМНтЪЭЃК
1. ЪфШыСїжа, СїШыЕФЯћЯЂЛКДцдкШнЦїжаЃЌЪБМфДАПкгаЮЂаЭХњДІРэЗжХф.
2. дк discretized stream ВНжшжа, ЛКДцЕФЮЂаЭХњДІРэзЊЛЏГЩ DStream RDDs.
- Mapped DStream ЪЧЭЈЙ§ЪЙгУзЊЛЛКЏЪ§ДгдЪМЕФ DStreamжаЛёЕУЕФ. етШ§ИіВНжшЙЙГЩСЫдкдЄЖЈвхЪБМфДАПкЕФЫљНгЪеЪ§ОнЕФзЊЛЛЁЃ ЕзВуЕФЪ§ОнНсЙЙЪЧRDD, ЮвУЧБЃСєСЫзЊЛЛжаЕФЪ§ОнЪРЯЕЁЃ
- зюКѓвЛВНЪЧ RDDЩЯЕФвЛИіЖЏзїЃЌДЅЗЂСЫSpark job.
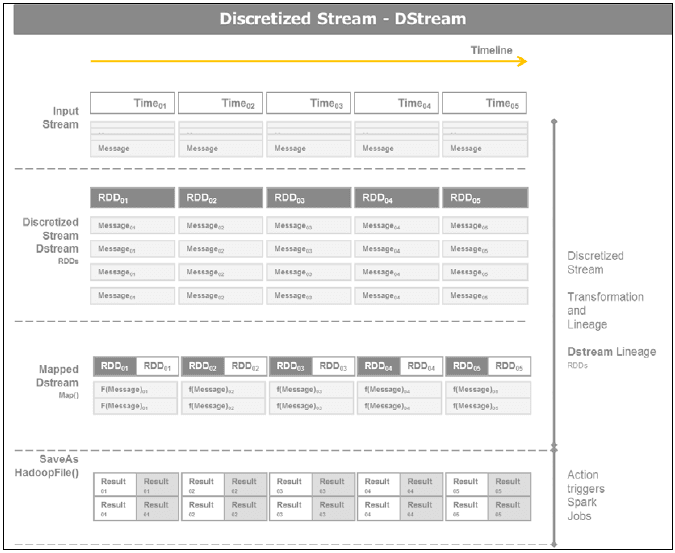
5-5 Dstream
Ъ§ОнзЊЛЛПЩвдЮозДЬЌЕФЛђепгазДЬЌЕФЁЃЮозДЬЌвтЮЖзХУЛгазДЬЌашвЊГЬађЮЌЛЄЃЌЖјгазДЬЌвтЮЖзХГЬађБЃГжзДЬЌЃЌЧАУцЫљМЧзЁЕФВйзїПЩФмгАЯьЕБЧАЕФВйзїЁЃвЛИігазДЬЌВйзїашвЊЛђаоИФвЛаЉЯЕЭГЕФзДЬЌЃЌЮозДЬЌВйзїдђВЛЪЧЁЃ ЮозДЬЌЪ§ОнзЊЛЛдквЛИіЪБМфЕуДІРэУПИіХњДІРэжаЕФвЛИі DStream. газДЬЌЪ§ОнзЊЛЛДІРэЖрИіХњДІРэРДЛёЕУНсЙћЃЌашвЊПЩХфжУЕФФПТММьВщЕуЁЃМьВщЕуЪЧШнДэЬхЯЕЕФжївЊЛњжЦЃЌ Spark Streaming жмЦкадДцДЂвЛИігІгУЕФЪ§ОнКЭдЊЪ§ОнЁЃSpark Streaming жаЕФгазДЬЌЪ§ОнзЊЛЛгаСНжжРраЭЃКupdateStateByKey КЭ windowed transformations.
updateStateByKey ЮЌЛЄСЫдк Pair RDD жавЛИіСїжаЕФУПИіМќжЕЕФзДЬЌЁЃЕБDStreamжаЕФМќжЕеЧЭЃБЛИќаТЪБЗЕЛивЛИіаТЕФзДЬЌЁЃ вЛИіР§згЪЧtweetsЕФstream жадЫааСЫgiven hashtags ЕФИіЪ§ЭГМЦЁЃWindowed transformations дкЖрИіХњДІРэЕФЛЌЖЏДАПкжажДааЁЃвЛИіДАПкгавЛИіЖЈвхКУЕФГЄЖШЛђЪБМфЕЅдЊЕФЧјМфЃЌЪЧЖрИіЕЅвЛ DStream ДІРэЕФМфИєЃЌЖЈвхСЫвЛИіДАПкзЊЛЛжагаЖрЩйИіХњДІРэЛђДАПкзЊЛЛжаМЦЫуЕФЦЕТЪЁЃ ЯТУцЕФ schema дк DStreamsЩЯЕФДАПкВйзїЃЌдкИјЖЈГЄЖШКЭЛЌЖЏМфИєЪБЩњГЩ window DStreams :
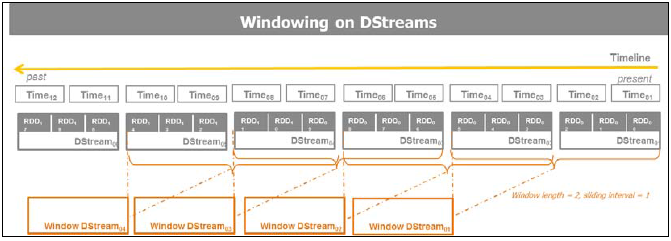
5-6 Windowing on Dstreams
КЏЪ§ЪОР§ЪЧ countByWindow (windowLength, slideInterval). дк DStreamЩЯЕФвЛИіЛЌЖЏДАПкжаЃЌМЦЫуУПИіЕЅдЊЫиRDDЕФдЊЫиИіЪ§ЃЌЗЕЛивЛИіаТЕФDStream. ЭЈЙ§УП60УыМЦЫувЛДЮtweetsСїжажИЖЈЕФhashtagsЕФЪ§ОнзїЮЊЪОР§ЕФНтЪЭЁЃ ДАПкЕФЪБМфжЁЪЧжИЖЈЕФЁЃЗжжгМЖЕФДАПкГЄЖШЪЧгаЕРРэЕФЁЃ гЩгкЪЧМЦЫуКЭФкДцУмМЏаЭЕФЃЌЫљвдаЁЪБМЖЕФДАПкГЄЖШЪЧВЛЭЦМіЕФЁЃдкCassandra Лђ HBase етбљЕФЪ§ОнжаОлКЯЪ§ОнИќЮЊЗНБуЁЃДАПкЪ§ОнзЊЛЛМЦЫуГіЕФНсЙћЪЧЛљгкДАПкГЄЖШКЭДАПкЛЌЖЏМфИєЕФЁЃ
Spark ЕФадФмЪмДАПкГЄЖШЃЌДАПкЛЌЖЏМфИєЃЌКЭГжОУЛЏЕФгАЯьЁЃ
ЙЙНЈШнДэЯЕЭГ
ЪЕЪБСїДІРэЯЕЭГБиаыЪЧ 24/7ПЩгУЕФЃЌеташвЊдкИїжжДэЮѓЗЂЩњЪБЯЕЭГЪЧПЩППЕФЁЃ Spark КЭ RDD ГщЯѓ БЛЩшМЦГЩПЩвдЮоЗьДІРэМЏШКжаШЮКЮНкЕуЕФЙЪеЯ.
Spark Streaming ШнДэДІРэЕФжївЊЛњжЦЪЧ КЫЖдМьбщЕуЃЌздЖЏжиЦєЧ§ЖЏЃЌ КЭздЖЏЙЪеЯЧаЛЛЁЃМьбщЕужаДцДЂСЫгІгУЕФзДЬЌЃЌЪЙЫќ SparkФмЙЛДгЧ§ЖЏЙЪеЯжаЙњФъЛжИДЁЃ
Spark Version 1.2 ЭЈЙ§аДЧАШежО, ПЩППЕФНгЪеЦї, КЭЮФМўСїБЃжЄСЫЪ§ОнЕФСуЖЊЪЇЁЃ аДЧАШежОДњБэСЫНгЪеЪ§ОнЕФШнДэДцДЂЁЃГіЯжЙЪеЯвЊЧѓжиаТМЦЫуНсЙћЁЃ DStream ВйзХгазХзМШЗЕФгявтЁЃЪ§ОнзЊЛЛПЩФмМЦЫуЖрДЮЃЌЕЋВњЩњЯрЭЌЕФНсЙћЁЃ DStream ЪфГіВйзїжСЩйгавЛИігявтЁЃЪфГіВйзївВПЩФмжДааЖрДЮЁЃ
вдTCP socketsДІРэЪЕЪБЪ§Он
РэНтСЫСїВйзїЕФЛљДЁЃЌЯШдкTCP socket ЩЯзїЪЕбщЁЃ TCP socket НЈСЂдкПЭЛЇЖЫКЭЗўЮёЦїжЎМф ЕФЫЋЙЄЭЈаХЃЌЭЈЙ§вбНЈЕФСЌНгНЛЛЅЪ§ОнЁЃ WebSocket гыHttp СЌНгВЛвЛбљЃЌЪЧГЄСЌНгЁЃ HTTP ВЛЛсдкserverВрБЃГжвЛИіСЌНгВЂСЌајЭЦЫЭЪ§ОнЕНwebфЏРРЦїЁЃКмЖр webгІгУвђЖјЭЈЙ§AJAXКЭXMLЧыЧѓВЩгУСЫГЄТжбЏ . WebSockets ЪЧHTML5 жаЪЕЯжЕФБъзМЃЌжЇГжЯжДњЕФ webфЏРРЦїВЂГЦЮЊСЫЪЕЪБЭЈбЖЕФПчЦНЬЈБъзМЁЃ
ДДНЈTCP sockets
дЫааnetcat ДДНЈвЛИі TCP Socket Server, етЪЧLinuxЯЕЭГжаЕФвЛИіаЁЙЄОпПЩвдзїЮЊЪ§ОнЗўЮёЦїЃЌУќСюШчЯТ:
#
# Socket Server
#
an@an-VB:~$ nc -lk 9999
hello world
how are you
hello world
cool it works |
вЛЕЉ netcatдЫааЦ№РДЃЌ вдSpark Streaming ЕФПЭЛЇЖЫДђПЊЕкЖўИіПижЦЬЈРДНгЪеКЭДІРэЪ§ОнЁЃ вЛЕЉ Spark Streaming ПЭЛЇЖЫПижЦЬЈМрЬ§ЮвУЧЕФМќШыЕЅДЪВЂДІРэ, ОЭЪЧЗДРЁ, hello world.
ДІРэЪЕЪБЪ§Он
ЮвУЧНЋЪЙгУ Spark ЬсЙЉЕФSpark Streaming ЪОР§ГЬађ network_wordcount.py. ПЩвдДгGitHub ЛёЕУ https://github.com/apache/spark /blob/master/examples/src/main /python/streaming/network_wordcount.py.
ДњТыШчЯТ:
""" Counts words in UTF8 encoded, '\n' delimited text received from the network every second. Usage: network_wordcount.py <hostname> <port> <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data. To run this on your local machine, you need to first run a Netcat server `$ nc -lk 9999` and then run the example `$ bin/spark-submit examples/src/main/python/streaming/network_ wordcount.py localhost 9999` """
from __future__ import print_function
import sys
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: network_wordcount.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext( appName="PythonStreamingNetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" "))\ .map(lambda word: (word, 1))\
.reduceByKey(lambda a, b: a+b)
ssc.start()
ssc.awaitTermination() |
НтЪЭвЛЯТГЬађЕФЙ§ГЬ:
ЕквЛааДњТыГѕЪМЛЏ : ssc = StreamingContext(sc, 1)
2.НгзХ, НЈСЂСїЪНМЦЫу.
- СЌНгlocalhost Лђ 127.0.0.1 ЕФ9999ЖЫПкДгНгЪеЪ§ОнжаЕУЕНвЛИіЛђЖрИі DStream ЖдЯѓ : stream = ssc.socketTextStream("127.0.0.1", 9999)
- ЖЈвхDStream ЕФМЦЫу: Ъ§ОнзЊЛЛКЭЪфГіВйзї: stream.map(x: lambda (x,1)) .reduce(a+b) .print()
- ПЊЪММЦЫу: ssc.start()
- ЪжЙЄЙЮЦ№ЛюДэЮѓДІРэЭъГЩЪБжаЖЯГЬађЃК ssc.awaitTermination()
- ЕБЕНДяЭъГЩЬѕМўЪБЃЌПЩвдЪжЙЄЭъГЩДІРэ: ssc.stop() ЭЈЙ§фЏРРSpark ЕФМрВтжївГlocalhostЃК4040 ПЩвдМрВтSpark Streaming СїгІгУ .
- етРяЪЧГЬађдЫааЕФНсЙћвдМАnetcatМЧТМЕФзжЗћ:
# # Socket Client #
an@an-VB:~/spark/spark-1.5.0-bin-hadoop2.6$ ./bin/spark-submit
examples/src/main/python/streaming/ network_wordcount.py localhost 9999 |
СЌНгlocalhost ЕФ9999ЖЫПк дЫааSpark Streaming network_count ГЬађ:
an@an-VB:~/spark/spark-1.5.0-bin-hadoop2.6$ ./bin/spark-submit examples/
src/main/python/streaming/ network_wordcount.py localhost 9999
-------------------------------------------
Time: 2015-10-18 20:06:06
-------------------------------------------
(u'world', 1)
(u'hello', 1)
-------------------------------------------
Time: 2015-10-18 20:06:07
-------------------------------------------
. . .
-------------------------------------------
Time: 2015-10-18 20:06:17
-------------------------------------------
(u'you', 1)
(u'how', 1)
(u'are', 1)
-------------------------------------------
Time: 2015-10-18 20:06:18
-------------------------------------------
. . .
-------------------------------------------
Time: 2015-10-18 20:06:26
-------------------------------------------
(u'', 1)
(u'world', 1)
(u'hello', 1) |
вђДЫ, вбОНЈСЂСЫБОЕи9999ЖЫПкЕФsocketСЌНг,СїЪНДІРэ netcat ЗЂЫЭЕФЪ§Он , жДааЗЂЫЭЯћЯЂЕФЕЅДПЭГМЦЁЃ
ЪЕЪБПижЦTwitterЪ§Он
Twitter ЬсЙЉСЫСНИі APIs. ЫбЫї APIдЪаэЮвУЧИљОнЫбЫїЬѕФПЛёЕУЙ§ШЅЕФ tweets. етОЭЪЧЮвУЧЧАУцеТНкШчКЮДгTwitterВЩМЏЪ§ОнЕФЗНЪНЁЃЮвУЧЕФФПЕФЪЧЭЈЙ§,Twitter ЬсЙЉЕФЪЕЪБstreaming API ЃЌДгВЉПЭЪРНчНгЪегУЛЇИеЗЂЫЭЕФ tweets .
ЪЕЪБДІРэTweets
ЯТУцЕФГЬађСЌНгСЫ TwitterЗўЮёЃЌДІРэСїШыЕФ tweetsЕЅВЛАќРЈвбЩОГ§ЛђЮоаЇЕФ tweetsЃЌЪЕЪБНтЮіЯрЙиtweetЬсШЁ screen УћГЦ, Лђ tweet text, retweet count, geo-location аХЯЂ. ДІРэЙ§ЕФ tweets ЭЈЙ§Spark Streaming ЪеМЏЕНвЛИіRDD QueueЃЌШЛКѓУПИєвЛУыЯдЪОдкПижЦЬЈЩЯ :
```
"""
Twitter Streaming API Spark Streaming into an RDD-Queue to process tweets live Create a queue of RDDs that will be mapped/reduced one at a time in 1 second intervals.
To run this example use
'$ bin/spark-submit examples/AN_Spark/AN_Spark_Code/s07_
twitterstreaming.py'
"""
#
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import twitter
import dateutil.parser
import json
ЃЃ Connecting Streaming Twitter with Streaming Spark via Queue
class Tweet(dict):
def init(self, tweet_in):
super(Tweet, self).init(self)
if tweet_in and 'delete' not in tweet_in:
self['timestamp'] = dateutil.parser.parse(tweet_
in[u'created_at']
).replace(tzinfo=None).isoformat()
self['text'] = tweet_in['text'].encode('utf-8') |
#self['text'] = tweet_in['text']
self['hashtags'] = [x['text'].encode('utf-8') for x in
tweet_in['entities']['hashtags']]
#self['hashtags'] = [x['text'] for x in tweet_
in['entities']['hashtags']]
self['geo'] = tweet_in['geo']['coordinates'] if tweet_
in['geo'] else None
self['id'] = tweet_in['id']
self['screen_name'] = tweet_in['user']['screen_name'].
encode('utf-8')
#self['screen_name'] = tweet_in['user']['screen_name']
self['user_id'] = tweet_in['user']['id'`
def connect_twitter():
twitter_stream = twitter.TwitterStream (auth=twitter.OAuth(
token = "get_your_own_credentials",
token_secret = "get_your_own_credentials",
consumer_key = "get_your_own_credentials",
consumer_secret = "get_your_own_credentials"))
return twitter_stream
def get_next_tweet(twitter_stream):
stream = twitter_stream.statuses.sample(block=True)
tweet_in = None
while not tweet_in or 'delete' in tweet_in:
tweet_in = stream.next()
tweet_parsed = Tweet(tweet_in)
return json.dumps(tweet_parsed)
def process_rdd_queue(twitter_stream):
# Create the queue through which RDDs can be pushed to
# a QueueInputDStream
rddQueue = []
for i in range(3):
rddQueue += [ssc.sparkContext. parallelize([get_next_
tweet(twitter_stream)], 5)]
lines = ssc.queueStream(rddQueue)
lines.pprint()
if __name__ == "__main__":
sc = SparkContext(appName= "PythonStreamingQueueStream")
ssc = StreamingContext(sc, 1)
# Instantiate the twitter_stream
twitter_stream = connect_twitter()
# Get RDD queue of the streams json or parsed
process_rdd_queue(twitter_stream)
ssc.start()
time.sleep(2)
ssc.stop(stopSparkContext=True, stopGraceFully=True) |
дЫааетИіГЬађЃЌгаШчЯТЪфГі:
an@an-VB:~/spark/spark-1.5.0-bin-hadoop2.6$ bin/spark-submit examples/
AN_Spark/AN_Spark_Code/ s07_twitterstreaming.py
-------------------------------------------
Time: 2015-11-03 21:53:14
-------------------------------------------
{"user_id": 3242732207, "screen_name": "cypuqygoducu", "timestamp":
"2015-11-03T20:53:04", "hashtags": [], "text": "RT @VIralBuzzNewss:
Our Distinctive Edition Holiday break Challenge Is In this article!
Hooray!... - https://t.co/ 9d8wumrd5v https://t.co/\u2026", "geo": null,
"id": 661647303678259200}
-------------------------------------------
Time: 2015-11-03 21:53:15
-------------------------------------------
{"user_id": 352673159, "screen_name": "melly_boo_orig", "timestamp":
"2015-11-03T20:53:05", "hashtags": ["eminem"], "text": "#eminem
https://t.co/GlEjPJnwxy", "geo": null, "id": 661647307847409668}
-------------------------------------------
Time: 2015-11-03 21:53:16
-------------------------------------------
{"user_id": 500620889, "screen_name": "NBAtheist", "timestamp": "2015-11-
03T20:53:06", "hashtags": ["tehInterwebbies", "Nutters"], "text": "See
That didn't take long or any actual effort. This is #tehInterwebbies
... #Nutters Abound! https://t.co/QS8gLStYFO", "geo": null, "id":
661647312062709761} |
ЮвУЧгаСЫвЛИігУSparkСїЪННгЪеВЂЗЩЫйЕиДІРэЫќУЧ.
ЙЙНЈвЛИіЮШЖЈЫѕЗХЕФСїЪНгІгУ
ЩуШЁЪ§ОнЪЧДгИїжждДжаЛёШЁЪ§ОнВЂТэЩЯДІРэЛђДцДЂЦ№РДЩдКѓДІРэЕФЙ§ГЬЁЃЪ§ОнЯћЗбЯЕЭГЪЧЗжЩЂЕФЃЌПЩвдДгМмЙЙЛђЮяРэЩЯгыЪ§ОндДЗжПЊЁЃЪ§ОнЩуШЁОГЃЭЈЙ§ЪжЙЄНХБОЪЕЯжЛђЛљБОЕФздЖЏЛЏЁЃЪЕМЪЩЯЃЌПЩвдЕїгУЯѓ Flume КЭKafkaетбљЕФИпВуПђМмЁЃЪ§ОнЩуШЁЕФЬєеНРДзддЪ§ОнЕФЮяРэЗжЩЂКЭднЬЌЕМжТЕФМЏГЩМЏГЩДрШѕадЁЃЖдгкЬьЦјЃЌНЛЭЈЃЌЩчНЛУНЬхЃЌЭјТчааЮЊЃЌДЋИаЦїЃЌАВШЋЃЌМрПиРДЫЕЃЌЪ§ОнВњЦЗЪЧСЌајЕФЁЃ
ВЛЖЯдіГЄЕФЪ§ОнШнСПКЭСїСПвдМАБфЛЏЕФЪ§ОнНсЙЙКЭгявтЪЧЪ§ОнЩуШЁЛьТвВЂгаДэЮѓЧуЯђЁЃ
ЮвУЧЕФФПБъЪЧИќМгЕФУєНнЃЌПЩППКЭЩьЫѕадЁЃЪ§ОнЩуШЁЕФУєНнадЃЌПЩППадКЭЩьЫѕадОіЖЈСЫСїЫЎЯпЕФНЁПЕГЬЖШЁЃУєНнадвтЮЖзХПЩвдМЏГЩаТЕФЪ§ОндДЃЌВЂАДашИФБфЯжДцЕФЪ§ОндДЁЃ ЮЊСЫБЃжЄАВШЋПЩППЃЌ ашвЊДгЛљДЁЩшЪЉЩЯЗРжЙЪ§ОнЖЊЪЇЃЌЗРжЙЯТгЮгІгУдкШыПкДІЕУЕНЕФЪ§ОндтЕНЦЦЛЕЁЃЩьЫѕадБмУтСЫЩуШЁЦПОБЃЌФмЙЛБЃГжЪ§ОнЕФПьЫйДІРэЁЃ
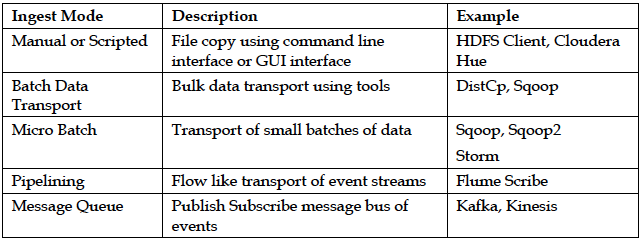
5-7 Ъ§ОнЩуШЁФЃЪН
ЪЙЫљгаЪ§ОнЕУЕНПьЫйЕФЯьгІЃЌКЫаФЧ§ЖЏЪЧЭГвЛШежОЁЃЭГвЛШежОЪЧЪЕЪБЖЉдФЕФМЏжаЛЏЦѓвЕНсЙЙЛЏШежОЁЃЫљгаЕФзщжЏЪ§ОнЗХЕНвЛИіжааФЛЏЕФШежОжаЁЃМЧТМБрКХДгСуПЊЪМЃЌБЛПДзїЪЧвЛИіЬсНЛШежОЛђеп journal. Unified Log ЕФИХФюЪЧKappa МмЙЙЕФКЫаФзкжМЁЃ Unified Log ЕФЬиадШчЯТ:
-
Unified: еыЖдЫљгазщжЏЕФЕЅвЛВПЪ№ЁЃ
- Append only: ЪТМўЪЧПЩзЗМгЧвВЛПЩБфЕФ
- Ordered: дквЛИіЧаЦЌФкУПИіЪТМўгаЮЛЮЉвЛЕФЦЋвЦСП
- Distributed: ПМТЧШнДэ, Unified Log ШпгрЗжВМдкМЏШКЕФИїЬЈжїЛњЩЯ
- Fast: ЯЕЭГУПУыЩуШЁГЩЧЇЩЯЭђЕФЯћЯЂ
ДюНЈ Kafka
ЮЊСЫЖРСЂЪ§ОнЩЯааКЭЪ§ОнЯћЗбЃЌашвЊЖдЪ§ОнЬсЙЉепКЭЯћЗбепНтёюКЯЁЃ гЩгкЫЋЗНгаВЛЭЌЕФжмЦкКЭдМЪј, Kafka ПЩвдНтёюКЯЪ§ОнДІРэЕФСїЫЎЯп.Apache Kafka ЪЧвЛИіЗжВМЪНЕФЗЂВМЖЉдФЯћЯЂЯЕЭГЃЌвВПЩвдРэНтГЩвЛИіЗжВМЪНЕФЬсНЛШежОЁЃЯћЯЂАДееЛАЬтДцДЂ.
Apache Kafka гаШчЯТЬиад. ЫќжЇГж:
- ИпШнСПЪТМўЕФИпЭЬЭТСП
- аТЕФКЭХЩЩњЕФ feeds ЕФЪЕЪБДІРэ
- ЕЭЪБбгЕФЦѓвЕМЖЯћЯЂЯЕЭГ
- ШнДэЙщЙІгкЗжЧјФкЕФЗжВМЪНЯћЯЂДцДЂЃЌУПИіЯћЯЂЖМгавЛИіЮЉвЛЕФађСа ID Назі offset. Consumers ЭЈЙ§ дЊзщ(offset, partition, topic)МьВщЫќУЧЕФжИеы.
ЩюШыНтЦЪвЛЯТ Kafka.Kafka гаШ§ИіЛљБОзщМў: producers, consumers КЭbrokers. Producers
ЭЦЫЭВЂаДЪ§ОнЕНbrokers. Consumers Дгbroker РШЁВЂЖСЕНЪ§Он. BrokersВЛЭЦЫЭЯћЯЂИјconsumers. Consumers ДгbrokersРШЁЪ§Он. ЗжВМЪНазїгЩ Apache ZookeeperЭъГЩ. brokersвдЛАЬтаЮЪНДцДЂКЭЙмРэЪ§Он. ЛАЬтЗжИюЕНИДжЦЗжЧјФкЁЃЪ§ОнГжОУЛЏbroker, дкДцСєЦкМфВЂВЛвЦГ§. ШчЙћвЛИіconsumer ЪЇАмСЫ, ЫќзмЪЧЛиЕНbroker дйДЮЛёШЁЪ§Он.
Kafka ашвЊ Apache ZooKeeperжЇГж. ZooKeeper ЪЧЗжВМЪНгІгУЕФвЛИіИпадФмаЕїЗўЮёЁЃЫќМЏжаЙмРэХфжУЃЌзЂВсЛђУќУћЗўЮёЃЌзщЕФГЩдБЙиЯЕЃЌЫјЃЌ ЗўЮёЦїМфЕФЭЌВНаЕїЃЌЬсЙЉСЫВуДЮЛЏУќУћПеМфЃЌгадЊЪ§ОнЃЌМрВтЭГМЦКЭМЏШКзДЬЌЁЃ ZooKeeper ПЩвдПьЫйЕив§Шы brokersКЭ consumersЃЌШЛКѓдкМЏШКФкжиаТОљКтЁЃ
Kafka producers ВЛашвЊ ZooKeeper. Kafka brokers ЪЙгУ ZooKeeperЬсЙЉЭЈгУЕФзДЬЌаХЯЂдкЙЪеЯЕФЪБКђбЁОйleader. Kafka consumers ЪЙгУZooKeeper ИњзйЯћЯЂЕФЦЋвЦСП. аТАцБОЕФ Kafka НЋЭЈЙ§ ZooKeeper БЃДцconsumersЃЌВЂЬсШЁKafka жаЬиЖЈЕФЛАЬтаХЯЂ .Kafka ЮЊproducersЬсЙЉСЫздЖЏЕФИКдиОљКт. ЯТЭМУшЪіСЫKafka ЕФНЈСЂЙ§ГЬ:
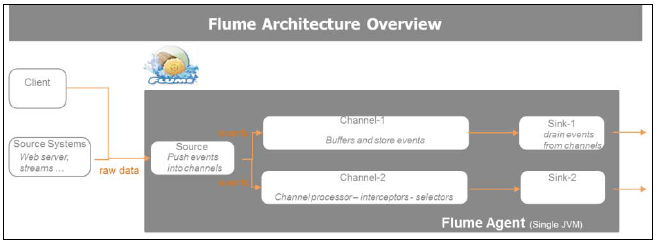
5-8 Kafka МмЙЙ
АВзАВтЪдKafka
ЯТди Apache Kafka жДааЮФМў http://kafka.apache.org/ downloads.html АДЯТСаВНжшАВзАШэМў:
1.ЯТдиДњТы .
2.ЯТди 0.8.2.0 АцБОВЂНтбЙ:
tar -xzf kafka_2.10-0.8.2.0.tgz
cd kafka_2.10-0.8.2.0 |
3.ЦєЖЏzooeeper. ЪЙгУвЛИіЗНБуЕФНХВНШУKafka ЕУЕН ZooKeeper ЕФвЛИіЕЅНкЕуЪЕР§
. > bin/zookeeper-server-start.sh config/zookeeper.properties
an@an-VB:~/kafka/kafka_2.10-0.8.2.0$ bin/zookeeper-server-start.sh config/zookeeper.properties
[2015-10-31 22:49:14,808] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum. QuorumPeerConfig)
[2015-10-31 22:49:14,816] INFO autopurge.snapRetainCount set to 3 (org.apache.zookeeper.server. DatadirCleanupManager).. |
4.ЦєЖЏ Kafka server:
> bin/kafka-server-start.sh config/server.properties
an@an-VB:~/kafka/kafka_2.10-0.8.2.0$ bin/kafka-server-start.sh config/server.properties
[2015-10-31 22:52:04,643] INFO Verifying properties (kafka.utils. VerifiableProperties)
[2015-10-31 22:52:04,714] INFO Property broker.id is overridden to 0 (kafka.utils.VerifiableProperties)
[2015-10-31 22:52:04,715] INFO Property log.cleaner.enable is overridden to false (kafka.utils.VerifiableProperties)
[2015-10-31 22:52:04,715] INFO Property log.dirs is overridden to /tmp/kafka-logs (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties) |
5.ДДНЈжїЬт. етРяДДНЈвЛИіУћЮЊ test ЕФжїЬтЃЌжЛгавЛИіЗжЧјКЭвЛИіИББО :
| > bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test |
6.ШчЙћдЫаа list topic УќСюЃЌПЩвдПДЕНетвЛжїЬт:
> bin/kafka-topics.sh --list --zookeeper localhost:2181 Test
an@an-VB:~/kafka/kafka_2.10-0.8.2.0$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
an@an-VB:~/kafka/kafka_2.10-0.8.2.0$ bin/kafka-topics.sh --list --zookeeper localhost:2181 test |
7.ЭЈЙ§ДДНЈвЛИі producer and consumerРДМьВщKafka ЕФАВзАЁЃ ЯШДДНЈвЛИі producer ЃЌДгПижЦЬЈМќШыЯћЯЂ:
an@an-VB:~/kafka/kafka_2.10-0.8.2.0$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
[2015-10-31 22:54:43,698] WARN Property topic is not valid (kafka. utils.VerifiableProperties)
This is a message
This is another message |
8. ЦєЖЏвЛИі consumer МьВщНгЪеЕНЕФЯћЯЂ: an@an-VB:~$ cd kafka/ an@an-
VB:~/kafka$ cd kafka_2.10-0.8.2.0/
an@an-VB:~/kafka/kafka_2.10-0.8.2.0$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message |
consumer е§ШЗНгЪеЯћЯЂЕФЙ§ГЬ:
1.МьВщKafka КЭ Spark Streaming consumer. ЪЙгУ Spark Streaming Kafka ЕЅДЪЭГМЦЪОР§. вЊзЂвтЕФЪЧ: ЕБЗЂЫЭSpark jobЕФЪБКђЃЌБиаыАѓЖЈ Kafka Аќ, --packages org.apache. spark:spark-streaming- kafka_2.10:1.5.0. УќСюШчЯТ:
| ./bin/spark-submit --packages org.apache.spark:spark- streaming- kafka_2.10:1.5.0 \ examples/src/main/python/ streaming/kafka_ wordcount.py \ localhost:2181 test |
2 ЕБгУKafka ЦєЖЏSpark Streaming ЕЅДЪМЦЫуГЬађЕФЪБКђ, ЕУЕНЯТУцЕФЪфГі:
an@an-VB:~/spark/spark-1.5.0-bin-hadoop2.6$ ./bin/spark-submit --packages org.apache.spark: spark-streaming-kafka_2.10:1.5.0 examples/src/main/python/streaming /kafka_wordcount.py localhost:2181 test
-------------------------------------------
Time: 2015-10-31 23:46:33
-------------------------------------------
(u'', 1)
(u'from', 2)
(u'Hello', 2)
(u'Kafka', 2)
-------------------------------------------
Time: 2015-10-31 23:46:34
-------------------------------------------
-------------------------------------------
Time: 2015-10-31 23:46:35
------------------------------------------- |
3.АВзАKafka Python driver вдБуЖд Producers and Consumers БрГЬЃЌВЂЪЙгУpython гыKafka and Spark НЛЛЅ. ЮвУХЪЙгУDavid ArthurПЊЗЂЕФПт, aka, Mumrah on GitHub ЭјжЗ (https://github.com/mumrah). АВзАУїССШчЯТ:
> pip install kafka-python an@an-VB:~$ pip install kafka-python
Collecting kafka-python
Downloading kafka-python- 0.9.4.tar.gz (63kB) ...
Successfully installed kafka-python-0.9.4 |
ПЊЗЂ producers
ЯТУцЕФГЬађДДНЈСЫвЛИіМђЕЅЕФKafka Producer ,РДЗЂЫЭвЛИіЯћЯЂ this is a message sent from the Kafka producer: 5ДЮЃЌДјЪБМфДС:
# # kafka producer # #
import time
from kafka.common import LeaderNotAvailableError
from kafka.client import KafkaClient
from kafka.producer import SimpleProducer
from datetime import datetime
def print_response(response=None):
if response:
print('Error: {0}'.format(response[0].error))
print('Offset: {0}'.format(response[0].offset))
def main():
kafka = KafkaClient("localhost:9092")
producer = SimpleProducer(kafka)
try:
time.sleep(5)
topic = 'test'
for i in range(5):
time.sleep(1)
msg = 'This is a message sent from the kafka producer: ' \
+ str(datetime.now().time()) + ' -- '\
+ str(datetime.now().strftime("%A, %d %B %Y
%I:%M%p"))
print_response (producer.send_messages(topic, msg))
except LeaderNotAvailableError:
# https://github.com/ mumrah/kafka-python/issues/249
time.sleep(1)
print_response (producer.send_messages(topic, msg))
kafka.close()
if __name__ == "__main__":
main() |
дЫааГЬађЃЌВњЩњШчЯТЪфГі:
an@an-VB:~/spark/spark-1.5.0-bin-hadoop 2.6/examples/AN_Spark/AN_Spark_
Code$ python s08_kafka_producer_01.py
Error: 0
Offset: 13
Error: 0
Offset: 14
Error: 0
Offset: 15
Error: 0
Offset: 16
Error: 0
Offset: 17
an@an-VB:~/spark/spark-1.5.0-bin-hadoop2.6 /examples/AN_Spark/AN_Spark_Code$ |
УЛгаДэЮѓЃЌВЂЧвKafka broker ИјГіСЫЯћЯЂЕФЦЋвЦСПЁЃ
ПЊЗЂ consumers
ЮЊСЫДг Kafka brokersЛёШЁЯћЯЂ, ПЊЗЂвЛИіKafka consumer:
# kafka consumer
# consumes messages from "test" topic and writes them to console.
#
from kafka.client import KafkaClient
from kafka.consumer import SimpleConsumer
def main():
kafka = KafkaClient("localhost:9092")
print("Consumer established connection to kafka")
consumer = SimpleConsumer(kafka, "my-group", "test")
for message in consumer:
# This will wait and print messages as they become available
print(message)
if __name__ == "__main__":
main() |
дЫааГЬађ, ПЩвдШЗШЯconsumer ЪеЕНСЫЫљгаЯћЯЂ:
an@an-VB:~$ cd ~/spark/spark-1.5.0-bin- hadoop2.6/examples/AN_Spark/AN_Spark_Code/
an@an-VB:~/spark/spark-1.5.0-binЃ hadoop2.6/examples/AN_Spark/AN_Spark_Code$ python s08_kafka_consumer_01.py
Consumer established connection to kafka
OffsetAndMessage(offset=13, message=Message(magic=0, attributes=0,
key=None, value='This is a message sent from the kafka producer:
11:50:17.867309Sunday, 01 November 2015 11:50AM'))
...
OffsetAndMessage(offset=17, message=Message(magic=0, attributes=0,
key=None, value='This is a message sent from the kafka producer:
11:50:22.051423Sunday, 01 November 2015 11:50AM')) |
дкKafka ЩЯПЊЗЂSpark Streaming consumer
ЛљгкSpark Streaming жаЬсЙЉЕФЪОР§ДњТы, ДДНЈ вЛИіKafkaЕФ Spark Streaming consumerЃЌВЂЖдBrokersжаДцДЂЕФЯћЯЂжДаа ЕЅДЪЭГМЦ:
#
# Kafka Spark Streaming Consumer
#
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: kafka_spark_consumer_01.py <zk> <topic>",
file=sys.stderr)
exit(-1)
sc = SparkContext(appName= "PythonStreamingKafkaWordCount")
ssc = StreamingContext(sc, 1)
zkQuorum, topic = sys.argv[1:]
kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-
consumer", {topic: 1})
lines = kvs.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination() |
жДааГЬађЃЌВЂдЫаа Spark submit УќСю:
./bin/spark-submit --packages org.apache.spark:spark-streaming-
kafka_2.10:1.5.0 examples/AN_Spark /AN_Spark_Code/s08_kafka_spark_
consumer_01.py localhost:2181 test |
ЕУЕНШчЯТЪфГіЃК
an@an-VB:~$ cd spark/spark-1.5.0- bin-hadoop2.6/
an@an-VB:~/spark/spark-1.5.0-bin- hadoop2.6$ ./bin/spark-submit \
--packages org.apache.spark:spark -streaming-kafka_2.10:1.5.0 \
examples/AN_Spark/AN_Spark_Code /s08_kafka_spark_consumer_01.py
localhost:2181 test
...
:: retrieving :: org.apache.spark#spark-submit-parent
confs: [default]
0 artifacts copied, 10 already retrieved (0kB/18ms)
-------------------------------------------
Time: 2015-11-01 12:13:16
-------------------------------------------
-------------------------------------------
Time: 2015-11-01 12:13:17
-------------------------------------------
-------------------------------------------
Time: 2015-11-01 12:13:18
-------------------------------------------
-------------------------------------------
Time: 2015-11-01 12:13:19
-------------------------------------------
(u'a', 5)
(u'the', 5)
(u'11:50AM', 5)
(u'from', 5)
(u'This', 5)
(u'11:50:21.044374Sunday,', 1)
(u'message', 5)
(u'11:50:20.036422Sunday,', 1)
(u'11:50:22.051423Sunday,', 1)
(u'11:50:17.867309Sunday,', 1)
...
-------------------------------------------
Time: 2015-11-01 12:13:20
-------------------------------------------
-------------------------------------------
Time: 2015-11-01 12:13:21
------------------------------------------- |
ЬНЫїflume
Flume ЪЧвЛИіСЌајЩуШЁЪ§ОнЕФЯЕЭГЃЌзюГѕБЛЩшМЦГЩвЛИіШежООлЛсЯЕЭГЃЌЕЋбнБфЮЊПЩвдДІРэШЮКЮРраЭЕФСїЪТМўЪ§ОнЁЃ Flume ЪЧвЛИіЗжВМЪНЃЌПЩППЕФЃЌОпгаЩьЫѕадЕФСїЫЎЯпЯЕЭГЃЌПЩвдгааЇЕиВЩМЏЃЌОлЛсЃЌДЋЪфДѓШнСПЪ§ОнЃЌФкжУжЇГжЩЯЯТЮФТЗгЩЃЌЙ§ТЫИДжЦЃЌКЭЖрТЗИДгУЁЃ ШнДэКЭНЁзГадКУЃЌгЕгаПЩЕїЕФПЩППадЛњжЦЃЌЖржжЙЪеЯЧаЛЛКЭЛжИДЛњжЦ. ЫќЪЙгУМђЕЅПЩРЉеЙЕФЪ§ОнФЃаЭгІгУгкЪЕЪБЗжЮіЁЃ
Flume ЬсЙЉСЫ:
- БЃжЄДЋЪфЕФгявт
- ЕЭЪБбгПЩППЕФЪ§ОнДЋЪф
- ВЛашвЊБрТыЕФЩљУїЪНХфжУ
- ПЩРЉеЙКЭЖЈжЦЕФЩшжУ
- МЏГЩСЫДѓЖрЪ§ЭЈгУЕФЖЫЕуЪ§ОндД
Flume АќРЈвдЯТдЊЫи:
- Event: вЛИіЪТМўЪЧFlumeДгдДЕНФПЕФЕижЗДЋЪфЪ§ОнЕФЛљБОЕЅдЊ. ЯѓвЛЬѕЯћЯЂФЧбљЃЌЖд Flume ЖјбдЪЧВЛЭИУїЕФзжНкЪ§зщЃЌЭЈЙ§ПЩбЁЕФЭЗаХЯЂРДзіЩЯЯТЮФТЗгЩЁЃ
- Client: вЛИі client ЩњВњКЭДЋЪфЪТМў. ПЭЛЇЖЫАб FlumeКЭЪ§ОнЯћЗбепНтёюКЯЃЌЪЧвЛИіЩњГЩЪТМўВЂАбЫќУЧЗЂЫЭЕНвЛИіЛђЖрИіДњРэ ЕФЪЕЬхЃЌПЩвдЪЧЖЈжЦЕФПЭЛЇЖЫЛђеп Flume log4J ГЬађ Лђ ЧБШыЕНгІгУжаЕФДњРэ.
- Agent: вЛИіДњРэЪЧвЛИіШнЦїЃЌГадиСЫдДЃЌаХЕРЃЌ sinks, КЭЦфЫќдЊЫиЪЙЪ§ОнФмдкВЛЭЌЕижЗМфДЋЪфЁЃЫќЖдЭаЙмЕФзщМўЬсЙЉСЫХфжУЃЌЩњУќжмЦкЙмРэКЭМрПиЁЃДњРэдкЮяРэЩЯЪЧвЛИідЫаа FlumeЕФJava ащФтЛњЁЃ
- Source: дДЪІFlume НгЪеЪТМўЕФЪЕЬхЃЌжСЩйЪЙгУвЛИіаХЕРЃЌЭЈЙ§ИУаХЕРТжбЏЪ§ОнЛђепЕШД§Ъ§ОнЗЂЫЭИјЫќЃЌгаИїжжВЩМЏЪ§ОнЕФдДЃЌР§Шч log4j logs КЭ syslogs.
- Sink: Sink ЪЧвЛИіЪЕЬхЃЌНЋаХЕРжаЕФЪ§ОнХХПеВЂЗЂЫЭЕНЯТвЛИіФПЕФЕижЗЁЃ sinks дЪаэЪ§ОнБЛСїЪНЗЂЫЭЕНвЛЖЈЗЖЮЇЕФФПЕФЕижЗЁЃ Sinks жЇГжађСаЛЏЕНгУЛЇЕФИёЪН. Р§Шч HDFS sink НЋЪТМўаДЕН HDFS.
- Channel: аХЕРЪЧдДКЭsinkжЎМфЕФЙмЕРЃЌЛКДцСїШыЕФЪТМўжЎЕРsink НЋаХЕРжаЕФЪ§ОнХХПеЁЃдДИјаХЕРЬсЙЉЪТМўЃЌSink ХХПеаХЕРЁЃ аХЕРНтёюКЯСЫЩЯЯТааЯЕЭГЃЌвжжЦСЫЩЯааЪ§ОнЕФЭЛЗЂадЃЌ ПЭЗўСЫЯТааЙЪеЯЁЃЮЊСЫЪЕЯжетвЛФПЕФЃЌЙиМќЪЧЕїећДІРэЪТМўЕФаХЕРШнСПЁЃ аХЕРЬсЙЉСЫСНжжВуДЮЕФГжОУЛЏ: ФкДцаЭаХЕРКЭЮФМўаЭаХЕРЁЃЕБJVMБРРЃЪБЃЌФкДцаЭаХЕРЪЧВЛЮШЖЈЕФ, ЖјЮФМўаЭаХЕРЭЈЙ§аДЧАШежО АбаХЯЂДцДЂЕНгВХЬЃЌЫљвдПЩвдЛиИДЁЃаХЕРЪЧШЋЪТЮёаЭЕФЁЃ
ЯТЭМНтЪЭСЫетаЉИХФю:
5-8 Flume
ЛљгкFlume, KafkaКЭSparkПЊЗЂЪ§ОнСїЫЎЯп
РћгУЮвУЧвббЇЕФжЊЪЖЃЌПЩвдЙЙНЈвЛИіЕЏадЕФЪ§ОнДІРэСїЫЎЯпЁЃЭЈЙ§Flume НЋЪ§ОнЩуШЁКЭДЋЪфЗХЕНвЛЦ№ЃЌАбKafka етбљЕФПЩППЕФЗЂВМЖЉдФЯћЯЂЯЕЭГзїЮЊЪ§ОнДњРэЃЌзюКѓЪЙгУSpark Streaming ЭъГЩИпЫйЕФМЦЫуДІРэЁЃ
ЯТЭМНтЪЭСЫСїЪНЪ§ОнСїЫЎЯпЕФзщГЩ connect, collect, conduct, compose, consume, consign, КЭ control. етаЉЛюЖЏИљОнгУР§РДХфжУ:
+ Connect НЈСЂСЫstreaming APIЕФАѓЖЈ
+ Collect ДДНЈСЫВЩМЏЯпГЬ.
- Compose зЈзЂгкДІРэЪ§Он
- Consume ЮЊЯћЗбЯЕЭГЬсЙЉДІРэКѓЕФЪ§Он
- Consign ИКд№Ъ§ОнГжОУЛЏ
- Control ИКд№ЯЕЭГЁЂЪ§ОнКЭгЊбјЕФЭГГяКЭМрПиЁЃ
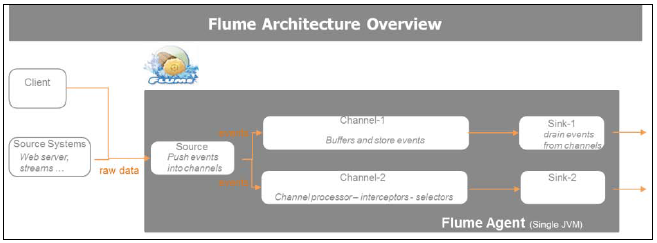
5-9 Streaming Ъ§ОнСїЫЎЯп
ЯТЭМНщЩмСЫСїЪНЪ§ОнСїЫЎЯпЕФИХФюМАЙиМќзщМў: Spark Streaming, Kafka, Flume, КЭЕЭЪБбгЪ§ОнПт. дкЯћЗбЛђПижЦаЭгІгУжаЃЌашвЊЪЕЪБМрПиЯЕЭГЃЌЛђепдкГЌГівЛЖЈуажЕЪБЪЕЪБЗЂЫЭИцОЏЁЃ
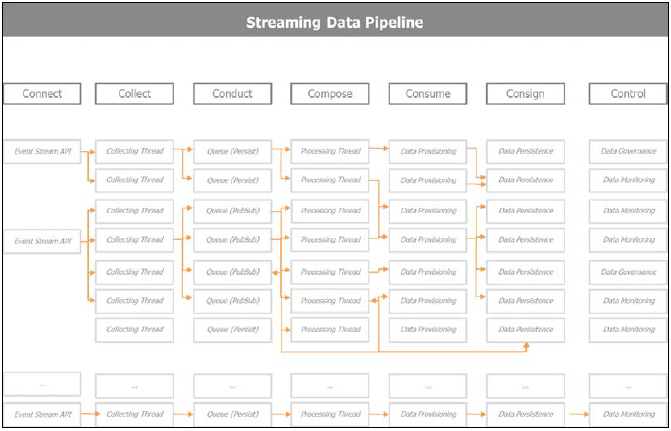
5-10 flume kafka streaming
ЯТЭМНщЩмСЫSpark дкДІРэЕЅЦНЬЈдЫЖЏЪ§ОнКЭЯажУЪ§ОнЕФЖРЬиФмСІЃЌМДИљОнВЛЭЌЕФгУР§ашЧѓгыЖрИіГжОУЛЏЪ§ОнДцДЂЮоЗьЖдНгЁЃ
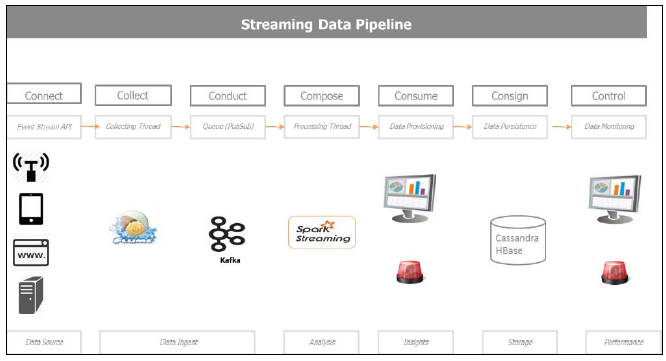
5-11 дЫЖЏЪ§ОнДІРэ
етеХЭМЪЧЕНФПЧАЮЊжЙЫљЬИТлЕФЫљгаИХФюЁЃЖЅВПУшЪіСЫСїЪНДІРэСїЫЎЯпЁЃЕзВПУшЪіСЫХњДІРэСїЫЎЯп ЃЌСНепЙВЯэЮЛгкжаМфЕФЭЈгУГжОУЛЏВуЃЌАќКЌИїжжФЃЪНЕФГжОУЛЏКЭађСаЛЏЁЃ
Lambda КЭKappa МмЙЙ
ЯждкгаСНжжСїааЕФМмЙЙЗЖЪН: Lambda КЭ Kappa МмЙЙ.
Lambda ЪЧStorm ДДНЈепКЮжївЊЬсНЛеп Nathan Marz ЕФзїЦЗ. ЫћГЋЕМдкЫљгаЪ§ОнЩЯЙЙНЈЙІФмаЭМмЙЙЁЃХњДІРэЗжжЇЪЧHadoop ЕФзюГѕЩшЯы , ЪЧРњЪЗЪ§ОнЕФИпЪБбгИпЭЬЭТСПЕФдЄДІРэЃЌШЛКѓгУгкЯћЗбЁЃЪЕЪБДІРэЗжжЇгЩStormЩшМЦЕФЃЌПЩвддіСПДІРэСїЪ§ОнЃЌПьЫйВњЩњНсТладМћНтЃЌДгДцДЂжаЪЕЪБОлКЯЪ§ОнЁЃ Kappa ЪЧKafka ЕФжївЊЬсНЛепжЎвЛ Jay Kreps КЭЫћдк Confluent (previously at LinkedIn)ЕФЭЌЪТЕФзїЦЗ. ЫќГЋЕМШЋВПСїЪНСїЫЎЯпЃЌКЭЧАУцЬИЕНЕФЭГвЛШежОЃЌЪЧЦѓвЕМЖЕФИпаЇЪЕЯж.
РэНт Lambda МмЙЙ
Lambda МмЙЙНсКЯСЫХњДІРэКЭСїЪНДІРэЃЌдкЫљгаЪ§ОнЩЯЬсЙЉСЫЭГвЛЕФВщбЏЛњжЦЁЃгаШ§Ву: ДцДЂдЄМЦЫуаХЯЂЕФХњДІРэВуЃЌдіСПНјааСїЪНЪЕЪБДІРэЕФЫйЖШВуЃЌЗўЮёВуКЯВЂСЫХњДІРэКЭЪЕЪБДІРэЕФЫцЛњВщбЏЁЃ ЯТЭМИјГіСЫ Lambda ЕФМмЙЙЁЃ
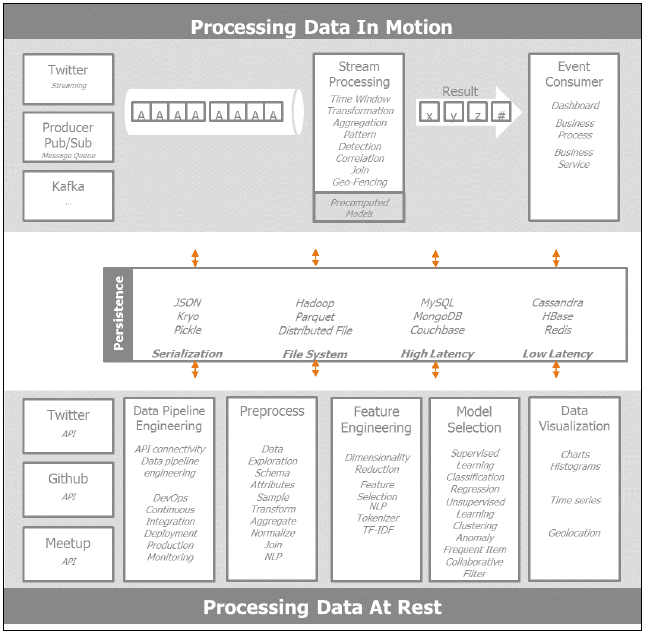
5Ѓ12 Lambda
РэНтKappa МмЙЙ
Kappa МмЙЙФПБъЪЧШЋЦѓвЕЕФСїФЃЪНЧ§ЖЏЃЌЦ№дДгк Jay Kreps КЭЫћдкLinkedInЕФЭЌЪТЕФвЛИіЦРТлЮФеТЁЃ ДгФЧЪБЦ№ЃЌЫћУЧРћгУApache Kafka ДДНЈСЫ Confluent with ApacheЃЌВЂзїЮЊ Kappa МмЙЙЕФжївЊДйГЩеп. ЛљБОзкжМЪЧЪЙгУЭГвЛШежОзїЮЊЦѓвЕаХЯЂМмЙЙЕФжїИЩЃЌНјЖјвЦЖЏЕНСїДІРэФЃЪНЁЃ
ЭГвЛШежОЪЧвЛИіМЏжаЕФЦѓвЕНсЙЙЛЏШежОЃЌгУгкЪЕЪБЖЉдФЁЃЫљгазщжЏЕФЪ§ОнЗХШыЕНвЛИіМЏжаЕФШежОЃЌМЧТМаДШыЪБДгСуПЊЪМзіБъМЧЃЌПЩвдЪБЬсМАШежОЛђШежОМЏКЯЁЃЭГвЛШежОЕФИХФюЪЧ Kappa МмЙЙЕФКЫаФзкжМ. ЭГвЛШежОЕФЬиЕуШчЯТ:
- Unified: ЫљгазщжЏЕФЭЌвЛВПЪ№
- Append only: ЪТМўЪЧПЩзЗМгЧвВЛПЩаоИФЕФ
- Ordered: УПИіЪТМўдкЗжЦЌФкгаЮЈвЛЕФЦЋвЦСП
- Distributed: ГігкШнДэПМТЧ, ЭГвЛШежОЗжВМгкдкМЏШКЕФВЛЭЌжїЛњЩЯЁЃ
- Fast: ЯЕЭГУПУыЩуШЁГЩЧЇЩЯЭђЕФЪ§Он
ЯТУцЕФНиЭМеЙЪОСЫ Jay Kreps аћГЦЖд Lambda МмЙЙЕФБЃСєвтМћ. ЫћЙигкLambdaМмЙЙЕФжївЊБЃСєвтМћЪЧдкHadoop and StormСНИіВЛЭЌЕФЯЕЭГжаЪЕЯжСЫЯрЭЌЕФЙЄзїУПИігазХИїздЕФЬиадЃЌвдМАЫцжЎЖјРДЕФИДдгадЁЃ Kappa ЭЈЙ§Apache Kafka МШДІРэСЫЪЕЪБЪ§ОнЃЌвВДІРэСЫРњЪЗЪ§ОнЁЃ
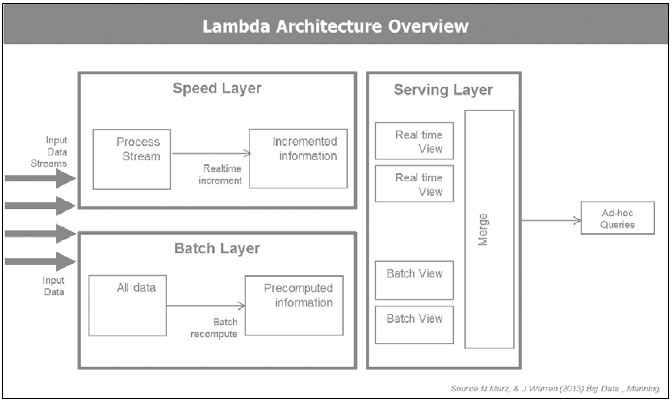
5Ѓ13 Kappa
аЁНс
ЮвУХСаОйСЫСїЪНДІРэМмЙЙгІгУЕФЛљДЁЃЌУшЪіСЫЫћУЧЕФЬєеНЃЌдМЪјКЭгХЪЦЁЃЩюШыСЫНтСЫSpark Streaming ЕФФкВПЙЄзїдРэАќРЈШчКЮSpark Core ЪЪгУЃЌвдМАгыSpark SQL КЭ Spark MLlibЖдЛАЃЌ ЭЈЙ§TCP sockets НтЪЭСЫСїДІРэИХФюЃЌНгЯТРДЃЌЪЧДгTwitter ЗўЮёжаЪЕЪБЩуШЁtweetЁЃЪЙгУKafkaзюДѓЯоЖШЕидіМгСЫСїДІРэМмЙЙЕФЕЏадЃЌЬжТлСЫЩЯЯТааЪ§ОнгыЯћЗбепжЎМфЕФНтёюКЯЁЃ ЛЙЬжТлСЫFlumeЁЊетИіПЩППЃЌСщЛюЃЌЩьЫѕадЪ§ОнЩуШЁКЭДЋЪфЕФСїЫЎЯпЯЕЭГЁЃНсКЯFlume, Kafka, КЭSpark дкЪББфСьгђНЛИЖСЫЗЧВЂааНЁзГадЃЌЫйЖШКЭУєНнад.
дкНсЮВЙлВьКЭЕуЦРСЫСНжжСїДІРэМмЙЙЗЖЪН Lambda КЭ Kappa МмЙЙ. Lambda МмЙЙдкЭЈгУЕФВщбЏЧАЖЫНсКЯСЫ ХњДІРэКЭСїЪ§Он. зюГѕЯыЗЈаЮГЩСЫ HadoopКЭStormЕФдИОА. Spark газдМКЕФХњДІРэКЭСїДІРэЗЖЪН, вдЙВгаДњТыЮЊЛљДЁЬсЙЉСЫЕЅвЛЕФЛЗОГЃЌДгЖјгааЇЕидкЯжЪЕжаЪЙгУетвЛМмЙЙЁЃKappa МмЙЙаћбяСЫЭЌвЛШежОЕФИХФю, етДДНЈСЫУцЯђЪТМўЕФМмЙЙЃЌЦѓвЕЕФЫљгаЪ§ОнЭЈЙ§аХЕРДЋЪфЕНвЛИіжааФЛЏЕФЬсНЛШежОЃЌЭЌЪБЖдЫљгаЯћЗбепЪЕЪБЪЙгУЁЃ
|









