| в§бдЁЊHDFSЕФживЊадЃК
HadoopЕФЖЈвхЃКЪЪКЯДѓЪ§ОнЕФЗжВМЪНДцДЂгыМЦЫуЕФвЛИіЦНЬЈЃЌЦфжаДѓЪ§ОнЕФЗжВМЪНДцДЂОЭЪЧгЩHDFSРДЭъГЩЕФЃЌвђДЫеЦЮеКУHDFSЕФЯрЙиИХФюгыгІгУЗЧГЃживЊЃЁ
БОЦЊВЉПЭНЋДгвдЯТМИИіЗНУцНВЪіHDFSЃК
1ЁЂЗжВМЪНЮФМўЯЕЭГгыHDFS
2ЁЂHDFSЕФЬхЯЕНсЙЙ
3ЁЂHDFSЁЊ-NameNodeЯрЙиИХФю
4ЁЂHDFSЁЊ-DataNodeЯрЙиИХФю
5ЁЂHDFSЁЊ-blockПщЯрЙиИХФю
6ЁЂHDFSЁЊ-ИББОЪ§ЯрЙиИХФю
7ЁЂHDFSЕФОпЬхВйзїЗНЪН
ЃЈвЛЃЉЗжВМЪНЮФМўЯЕЭГгыHDFS
ЂйЗжВМЪНЮФМўЯЕЭГDFSЕФгЩРДЃК
ЫцзХЮвУЧЕФЪ§ОнСПдНРДдНДѓ,дквЛИіВйзїЯЕЭГжаДцЗХЪ§ОнОЭЗХВЛЯТСЫ,вђДЫШчЙћЪ§ОндквЛЬЈЕчФдЩЯЗХВЛЯТжЛФмЗХЕНСэЭтвЛЬЈЕчФдЩЯ,ДЫЪБЮЪЬтОЭгаСЫ:ШчЙћАбЪ§ОнЗжЩЂЕНЖрЬЈЕчФдЩЯЕФЛА,ЮвУЧЖдЪ§ОнЕФЙмРэвВОЭБфЕУдНРДдНТщЗГСЫЃЌетИіЮЪЬтШчКЮНтОіЃП
ЦкД§вЛИіЙмРэЯЕЭГФмЙЛШУЮвУЧЮоЗьЕФЙмРэЖрЬЈВйзїЯЕЭГЩЯУцЕФЪ§Он,дкВйзїЖрЬЈЕчФдЩЯЪ§ОнЕФЪБКђ,ОЭКУЯёЪЧдквЛЬЈЕчФдЩЯВйзївЛбљ,етОЭЪЧЗжВМЪНЮФМўЯЕЭГЕФгЩРДЁЃ
ЂкЗжВМЪНЮФМўЯЕЭГЕФгХЕуЃК
1ЁЂЪЧвЛжждЪаэЮФМўЭЈЙ§ЭјТчдкЖрЬЈжїЛњЩЯЗжЯэЕФЮФМўЯЕЭГЃЌПЩвдШУЖрЬЈЛњЦїЩЯЕФЖрЛЇЛЇЗжЯэЮФМўКЭДцДЂПеМфЁЃ
2ЁЂЭЈЭИадЃКШУЪЕМЪЩЯЪЧЭЈЙ§ЭјТчРДЗУЮЪЮФМўЕФЖЏзїЃЌгЩГЬађгыгУЛЇПДРДЃЌОЭЯёЪЧЗУЮЪБОЕиДХХЬвЛбљЁЃ
3ЁЂШнДэЃКМДЪЙЯЕЭГжагаФГаЉНкЕуЙвЕєЃЌећЬхРДЫЕЯЕЭГШдШЛПЩвдМЬајдЫзїЖјВЛЛсгаЪ§ОнЕФЖЊЪЇЁЃ
ЗжВМЪНЮФМўЙмРэЯЕЭГгаКмЖрЃЌHDFSжЛЪЧЦфжаЕФвЛжжЁЃЪЪКЯгквЛДЮаДШыЖрДЮВщбЏЕФЕФЧщПіЃЌВЛжЇГжВЂЗЂаДЧщПіЃЌаЁЮФМўВЛКЯЪЪЁЃ
вЛОфЛАУшЪіHDFSЃКАбПЭЛЇЖЫЕФДѓЮФМўДцЗХдкКмЖрНкЕу(ЗўЮёЦї)ЕФЪ§ОнПщжаЁЃ
ЃЈЖўЃЉHDFSЕФЬхЯЕНсЙЙ
HDFSЕФЬхЯЕНсЙЙЪЧвЛИіжїДгНсЙЙ,жїНкЕуNamenodeжЛгавЛИі,ДгНкЕуDatanodeгаКмЖрИі.жїНкЕуNamenodeгыДгНкЕуDatanodeЪЕМЪЩЯжИЕФЪЧВЛЭЌЕФЮяРэЛњЦї,МДгавЛИіЛњЦїХмЕФНјГЬЪЧNamenode.КмЖрЛњЦїЩЯХмЕФНјГЬЪЧDatanodeЁЃ
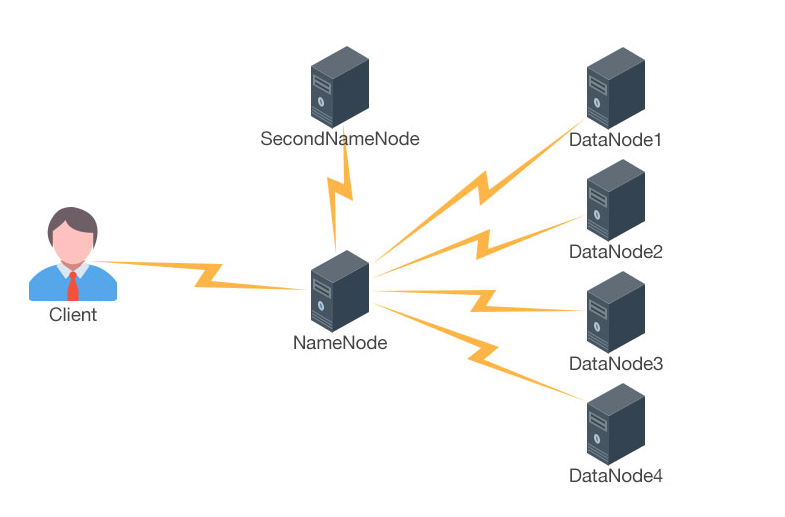
HDFSЬхЯЕНсЙЙЁЊЁЊNameNode 
ДгЩЯУцЕФдДТыПЩвдПДГіЃЌдкШЮКЮЗжВМЪНЮФМўЯЕЭГЕФВПЪ№ЕБжажЛДцдквЛИідЫааЕФNameNodeЃЌГ§ЗЧДцдкЕкЖўИіБИЗнЛђЙЪеЯзЊвЦNameNodeЁЃ
NameNodeживЊадЃК
1>NamenodeИКд№НгЪегУЛЇЕФВйзїЧыЧѓ,ЪЧећИіЮФМўЯЕЭГЕФЙмРэНкЕу
2>ЮЌЛЄзХећИіЮФМўЯЕЭГЕФФПТМНсЙЙЃЌЫљЮНФПТМНсЙЙРрЫЦгкwindowsЮФМўМаЕФЬхЯЕНсЙЙ
3>ЛЙБЃЙмзХЮвУЧЮФМўЛђФПТМЕФдЊЪ§ОнаХЯЂ(metadata),ЫљЮНдЊЪ§ОнаХЯЂжИЕФЪЧГ§СЫЪ§ОнБОЩэжЎЭтЩцМАЕНЮФМўздЩэЕФЯрЙиаХЯЂ:аоИФЪБМфЁЂДѓаЁЁЂЗУЮЪШЈЯоЁЂИББОЪ§ЕШЕШ
УќСюЃКdu -sh * 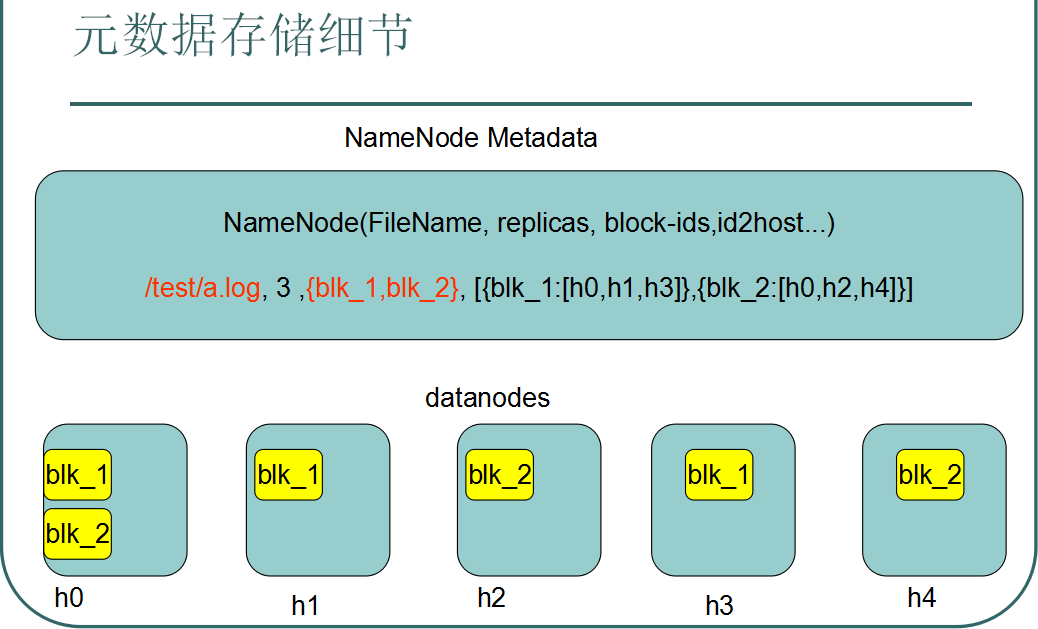
4>жЊЕРЮФМўгыblockПщађСажЎМфЕФЖдгІЙиЯЕЁЂИКд№МЧТМЮФМўЪЧШчКЮБЛЗжИюГЩЪ§ОнПщЕФ,вдМАетаЉЪ§ОнПщЗжБ№ДцДЂЕНФФаЉНкЕуЩЯЕШ.
змНсРДЫЕЃКNameNodeОЭЪЧИКд№ЙмРэЙЄзїЕФЁЃ
NameNodeКЫаФдДТыЗжЮіЃК 
ЭЈЙ§дДТыПЩвдЗЂЯжЃКNameNodeетИіНкЕуЙмРэзХСНеХКЫаФЕФБэЃЌЕквЛеХБэЙмРэзХЮФМўгыblockПщађСажЎМфЕФЖдгІЙиЯЕЃЌЕкЖўеХБэЙмРэзХblockПщгыDataNodeНкЕужЎМфЕФЖдгІЙиЯЕЁЃ
ЦфжаЧАвЛеХБэЪЧОВЬЌЕФЃЌЪЧДцЗХдкДХХЬЩЯЕФЃЌЭЈЙ§fsimageКЭeditsЮФМўРДЮЌЛЄЃЌКѓвЛеХБэЪЧЖЏЬЌЕФЃЌУПЕБМЏШКЦєЖЏЕФЪБКђЛсздЖЏНЈСЂетИіаХЯЂЁЃ
ЯТУцЭЈЙ§вЛИіОпЬхЕФЪЕЧžڳОпЬхКЌвхЃК 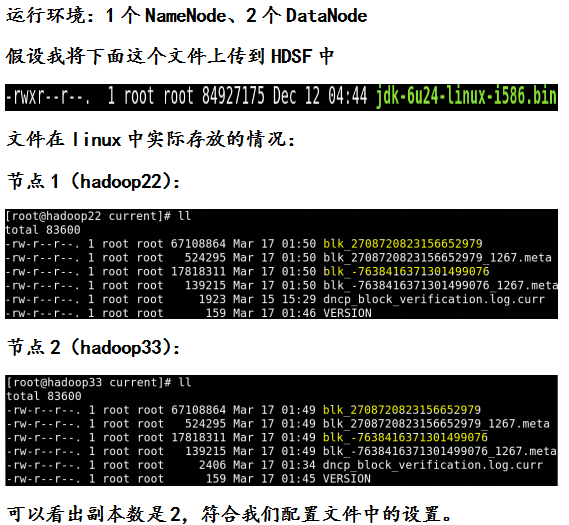
ДЫЪБNameNodeЕФСНеХКЫаФБэжаНЋМЧдизХШчЯТаХЯЂЃК 
МДЕквЛеХБэжаЙмРэзХЮФМўгыblockПщађСажЎМфЕФЖдгІЙиЯЕЃЌЕкЖўеХБэжаЙмРэзХblockПщгыDataNodeНкЕужЎМфЕФЖдгІЙиЯЕЁЃ
fsimageгыeditsДцЗХЕФТЗОЖЃК 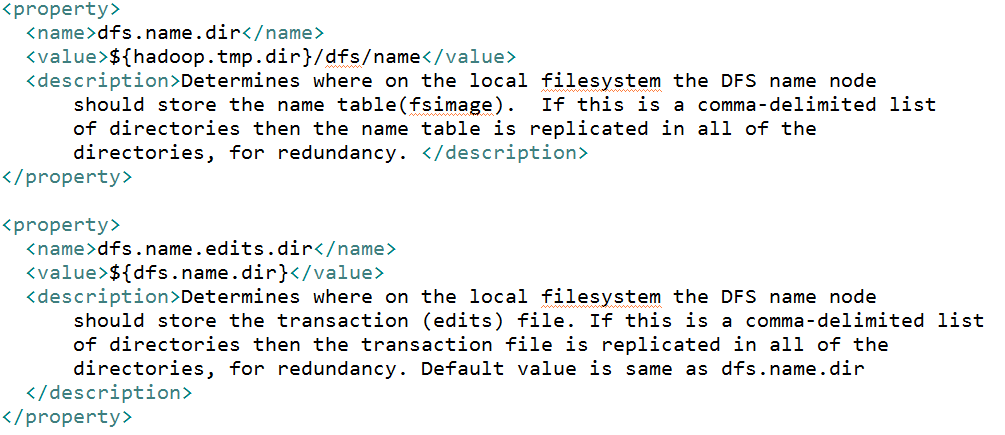
HDFSЬхЯЕНсЙЙЁЊЈCSecondaryNameNode
SecondaryNameNodeЕФживЊадЃК
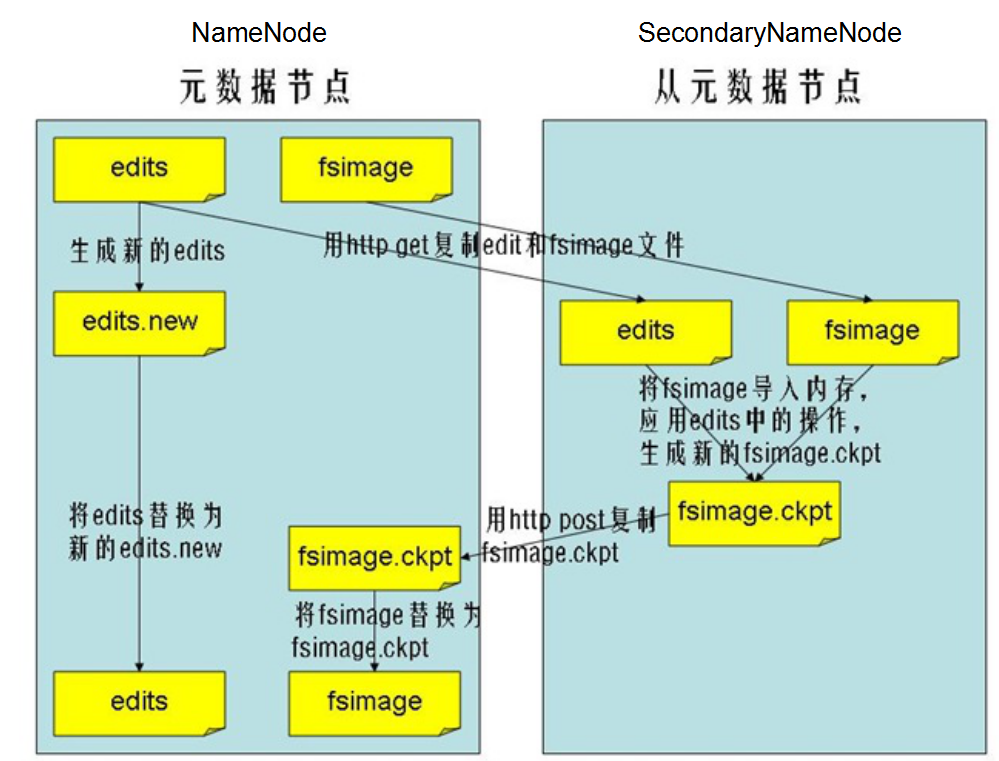
SecondnamenodeзїЮЊРЯЖў,жЛзівЛМўЪТЧщ:КЯВЂNamenodeжаЕФfsimage+edits
NamenodeгыSecondnamenodeБОЩэЪЧСНИіЖРСЂЕФJavaНјГЬ,ЫќУЧжЎМфЪ§ОнЕФНЛЛЛЪЧЭЈЙ§ЭјТчhttpзпЕФ.
КЯВЂЕФжДааЙ§ГЬ:SecondnamenodeЛсЯШАбNamenodeжаЕФfsimage+editsетаЉдЊЪ§ОнЯШПНБДЕНздМКНјГЬЕФФЧвЛПщ.ШЛКѓНЋfsimageгыeditsНјааКЯВЂ,ЩњГЩаТЕФfsimageЃЌЫцКѓНЋаТЕФfsimageЫЭЛиЕНNamenodeжа.ЭЌЪБжижУNamenodeжаЕФedits.МДНЋдРДЕФeditsжаЕФЪ§ОнЧхПеЁЃ
HDFSЬхЯЕНсЙЙЁЊЁЊDataNode
DataNodeживЊад
1>DatanodeжЛзівЛМўЪТЧщ:ДцДЂЪ§ОнЃЌHDFSжЎЫљвдПЩвдДцДЂКЃСПЪ§ОнЪЕМЪЩЯжИЕФЪЧDatanodeетИіНкЕуПЩвдНјааРЉеЙ.
2>DatanodeЪЧвдblockПщЕФЗНЪНРДДцДЂЪ§ОнЕФ.етвЛЕуВЛЭЌгкЮвУЧЕФwindowsВйзїЯЕЭГЃЌHDFSжаЕФЮФМўЪЧБЛЧаГЩblockПщРДНјааДцДЂЕФЁЃжЎЫљвдНЋЮФМўЧаЗжГЩаЁПщРДНјааДцДЂ,вВЪЧЮЊСЫБугкЮЌЛЄгыЙмРэ.ЮЊБЃжЄЪ§ОнАВШЋ,blockПщЛсгаЖрИіИББОЃЌВЂЧветаЉИББОЛсБЛДцДЂЕНВЛЭЌЕФЛњЦїЩЯУцЁЃ
DataNodeжаЕФblockПщЕНЕзЪЧДцЗХЕНФФРяФиЃПЮвУЧПЩвдЭЈЙ§ХфжУЮФМўhdfs-default.xmlНјааВщПДЃК

ЦфжаВЮЪ§dfs.data.dirЕФЪ§жЕОЭЪЧblockПщДцЗХдкLinuxЮФМўЯЕЭГжаЕФЮЛжУЃЌВЮЪ§${hadoop.tmp.dir}ЕФЪ§жЕЮвУЧздМКПЩвдНјааХфжУЃЌЮвХфжУЕФТЗОЖЮЊЃК/usr/local/hadoop/tmp,вђДЫblockПщДцЗХЕФОпЬхТЗОЖЪЧЃК
/usr/local/hadoop/tmp/dfs/data.вђДЫЭЈЙ§linuxУќСюЮвУЧПЩвдЖдЪ§ОнПщНјааЯргІЕФВщПДЃК
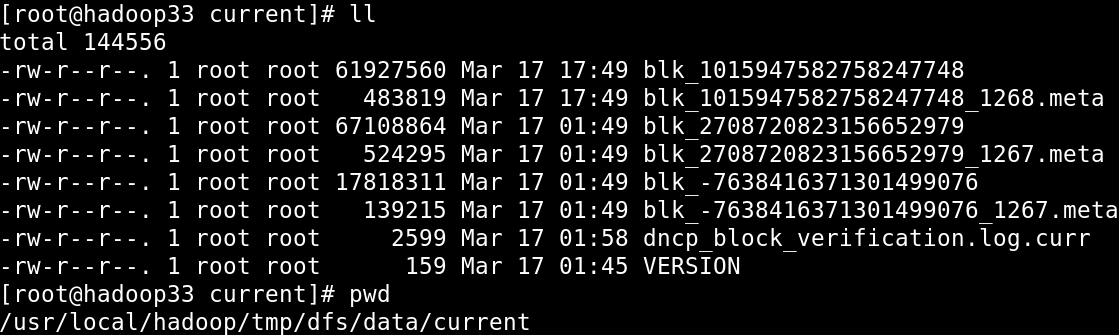
ЫМПМЃКМШШЛНЋЪ§ОнЭЈЙ§linuxЩЯДЋЕНHDFSжЎКѓ,DatanodeзюжеЛЙЪЧАбЪ§ОнЗХЕНСЫlinuxЮФМўЯЕЭГЕФФПТМЯТ,ЮЊЪВУДВЛжБНгНЋЪ§ОнЗХЕН/usr/local/hadoop/tmp/dfs/dataетИіФПТМЯТУц?
1>ЛЛНЧЖШЫМПМЃКЪ§ОнПтOracleЪЧДцДЂЪ§ОнЕФ,ОЭКУЯёHDFSвВЪЧДцДЂЪ§ОнЕФвЛбљ,ЕЋЪЧЪ§ОнПтЕФЪ§ОнзюжеЛЙЪЧДцЗХдкСЫwindowsЩЯУц.ЮвУЧжЎЫљвдЪЙгУЪ§ОнПтНіНіЪЧЮЊСЫНтОіЪ§ОнСьгђжаЕФвЛИіЮЪЬт:ВщбЏЃЌЖјHDFSКЭЪ§ОнПтвЛбљ,вВНіНіЪЧЮЊСЫНтОіЪ§ОнСьгђжаЕФвЛИіЮЪЬт:КЃСПЪ§ОнЕФДцДЂ
2>ШчЙћжБНгЭЈЙ§ЪжЙЄНЋЪ§ОнЩЯДЋЕНDatanodeжаДцЗХЪ§ОнЕФФЧИіФПТМЯТУц,ФЧУДЭЈЙ§hadoop
fs -ls /етИіУќСюЪЧВщВЛЕНетИіЮФМўЕФ.вђЮЊШєЪжЙЄЩЯДЋ,NamenodeЪЧВЛжЊЕРЕФ,МДЪжЙЄЩЯДЋЕФЪ§ОнHDFSЪЧВЛШЯЕФ.
HDFSЁЊЁЊblockЯрЙиИХФю
blockПщЪЧHDFSзюЛљБОЕФДцДЂЕЅЮЛЃЌHDFSЛсНЋЮФМўЧаЗжГЩblockПщРДНјааДцДЂЃЌФЌШЯЕФblockПщДѓаЁЪЧ64MЃЌвдвЛИі256MЮФМўДѓаЁЮЊР§ЃЌЙВЛсБЛЧаЗжГЩ256/64=4Иіblock
blockПщЕФФЌШЯДѓаЁЃК
<property>
<name>dfs.block.size</name>
<value>67108864</value>
<description>The default block size for
new files.</description>
</property> |
HDFSЁЊ-ИББОЪ§ЯрЙиИХФю
дкHDFSДцДЂЪ§ОнЪБЮЊСЫШЗБЃЪ§ОнЕФАВШЋадЃЌв§ШыСЫИББОЕФЛњжЦЃЌФЌШЯЕФИББОЪ§ЮЊ3,ЮвУЧдкХфжУЮФМўhdfs-defaule.xmlжаПЩвдНјааВщПДЃК

ЕБШЛИББОЕФЪ§СПЮвУЧПЩвддкhdfs-site.xmlжаНјаааоИФЕФЃК

ЯТУцЮвУЧЭЈЙ§вЛИіОпЬхЕФЪЕЧžڳHDFSДцДЂдРэЃК
1ЁЂМйЩшФГИігУЛЇвЊЩЯДЋвЛИіДѓаЁЪЧ192MЕФЮФМў,ЪзЯШNameNodeНЋЛсНгЪеЕНгУЛЇЩЯДЋЪ§ОнЕФЧыЧѓЃК
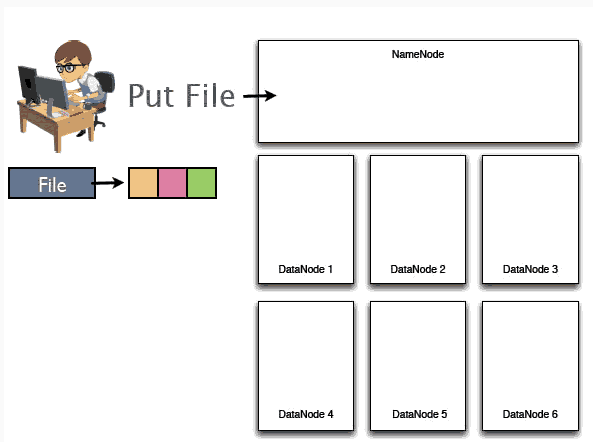
2ЁЂЫцКѓ192MЕФећИіЮФМўНЋЛсБЛЧаГЩ3ИіblockПщЗжБ№ДцДЂдк3ЬЈВЛЭЌЕФЛњЦїЩЯЃЌМДDataNodeЩЯУцЁЃгыДЫЭЌЪБNameNodeНЋЛсМЧТМетаЉЪ§ОнПщДцДЂЕНФФаЉDatanodeЩЯУцЁЂЮФМўгыblockађСажЎМфЕФЖдгІЙиЯЕЕШЕШЁЃ

3ЁЂШЛКѓHDFSдкНкЕужЎМфИДжЦетаЉЪ§ОнПщЃЌзюКѓетШ§ПщдкЖрИіНкЕужаЗжВМШчЯТЃКУПвЛИіblockПщБЛПНБДГЩСЫ3ИіИББОЃЌБЃжЄСЫЪ§ОнЕФАВШЋадЁЃ
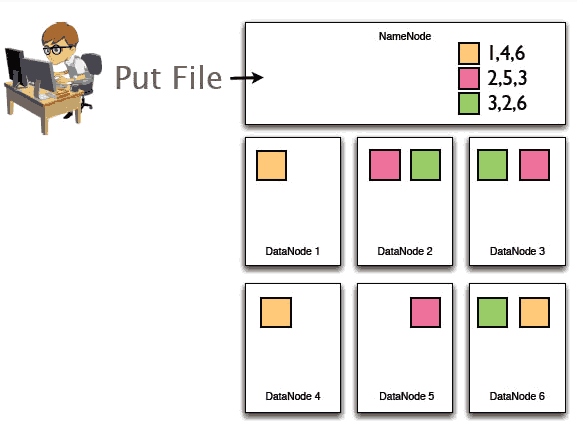
е§ШчЩЯУцЪЕР§ЫљЪОЃК
1>NameNodeМЧдизХЮФМўгыblockађСажЎМфЕФЖдгІЙиЯЕЁЂМЧТМзХblockПщДцДЂдкФФаЉНкЕуЩЯЕШЕШ
2>DataNodeОЭЪЧДцДЂЪ§ОнЕФЃЌМДblockПщЕФ
3>ИББОЛњжЦШЗБЃСЫЪ§ОнЕФАВШЋад
ЃЈШ§ЃЉHDFSЕФВйзїЗНЪН
HDFSЕФОпЬхВйзїЗНЪНЃКshellВйзїгыJavaApiВйзїСНжжЗНЪН
shellВйзїЃК
hadoop fs ЁЁ-lsЁЁ / ЃКВщПДHDFSЕФФПТМНсЙЙ
hadoop fs ЁЁ-lsr / ЃКЕнЙщВщПДHDFSЕФФПТМНсЙЙ
hadoop fs -mkdir /d1 ЁЁЃКдкHDFSЩЯУцДДНЈЮФМўМа
hadoop fs -putЁЁЁЁЁЁ ЃКЩЯДЋЪ§ОнЮФМў
hadoop fs ЁЁ-get ЃКЯТдиЪ§ОнЮФМў
hadoop fs -rmr ЃКЩОГ§HDFSжаЕФЮФМўМаЛђепЮФМў
JavaApiВйзїЃК
JavaApiЖдHDFSЕФВйзїжЛвЊЛђЕУвЛИіfileSystemЖдЯѓОЭПЩвдСЫЁЃ
FileSystem fileSystem = FileSystem.get(new URI(path0)
, new Configuration()); 
ЭЈЙ§FileSystemгУЛЇПЩвдгыNameNodeНјааЭЈаХЁЃ |









