0x00 ЧАбд
зюНќдкЪЙгУimpalaЃЌЫГБубЇЯАвЛЯТЯрЙиЕФдРэВПЗжЁЃ
ЯТУцЕФзщжЏНсЙЙЛсЯШНщЩмвЛЯТimpalaЕФДѓжТдРэКЭЩцМАЕФММЪѕЃЌШЛКѓЖдУППщЩцМАЕНЕФММЪѕзівЛИіЪсРэЃЌзюКѓдйЩюШывЛЕуimpalaЕФдРэЁЃ
impalaЪЧЪВУД
- ПЊдДЪ§ОнПтЯЕЭГ
- РрMPPВЂааЪ§ОнПтжДаа
- DremelЯЕ
- Лљгкhadoop
0x01 MPP
вЛЁЂЗўЮёЦїШ§ДѓЬхЯЕЃКSMPЁЂNUMAЁЂMPP
ДгЯЕЭГМмЙЙРДПДЃЌЩЬгУЗўЮёЦїДѓЬхПЩвдЗжЮЊШ§РрЃК
- SMPЃКЖдГЦЖрДІРэЦїНсЙЙ(Symmetric Multi-Processor)ЃЌ
- NUMAЃКЗЧвЛжТДцДЂЗУЮЪНсЙЙ(Non-Uniform Memory Access)ЃЌ
- MPPЃКвдМАКЃСПВЂааДІРэНсЙЙ(Massive Parallel Processing)ЁЃ
SMPЃК
ЫљЮНЖдГЦЖрДІРэЦїНсЙЙЃЌЪЧжИЗўЮёЦїжаЖрИіCPUЖдГЦЙЄзїЃЌЮожїДЮЛђДгЪєЙиЯЕЁЃИїCPUЙВЯэЯрЭЌЕФЮяРэФкДцЃЌУПИі CPUЗУЮЪФкДцжаЕФШЮКЮЕижЗЫљашЪБМфЪЧЯрЭЌЕФЃЌвђДЫSMPвВБЛГЦЮЊвЛжТДцДЂЦїЗУЮЪНсЙЙ(UMAЃКUniform Memory Access)ЁЃ
ШБЕуЃКSMPЗўЮёЦїЕФжївЊЬиеїЪЧЙВЯэЃЌЯЕЭГжаЫљгазЪдД(CPUЁЂФкДцЁЂI/OЕШ)ЖМЪЧЙВЯэЕФЁЃвВе§ЪЧгЩгкетжжЬиеїЃЌЕМжТСЫSMPЗўЮёЦїЕФжївЊЮЪЬтЃЌФЧОЭЪЧЫќЕФРЉеЙФмСІЗЧГЃгаЯоЁЃ
NUMAЃК
гЩгкSMPдкРЉеЙФмСІЩЯЕФЯожЦЃЌШЫУЧПЊЪМЬНОПШчКЮНјаагааЇЕиРЉеЙДгЖјЙЙНЈДѓаЭЯЕЭГЕФММЪѕЃЌNUMAОЭЪЧетжжХЌСІЯТЕФНсЙћжЎвЛЁЃРћгУNUMAММЪѕЃЌПЩвдАбМИЪЎИіCPU(ЩѕжСЩЯАйИіCPU)зщКЯдквЛИіЗўЮёЦїФкЁЃ
NUMAЗўЮёЦїЕФЛљБОЬиеїЪЧОпгаЖрИіCPUФЃПщЃЌУПИіCPUФЃПщгЩЖрИіCPU(Шч4Иі)зщГЩЃЌВЂЧвОпгаЖРСЂЕФБОЕиФкДцЁЂI/OВлПкЕШЁЃгЩгкЦфНкЕужЎМфПЩвдЭЈЙ§ЛЅСЊФЃПщ(ШчГЦЮЊCrossbar Switch)НјааСЌНгКЭаХЯЂНЛЛЅЃЌвђДЫУПИіCPUПЩвдЗУЮЪећИіЯЕЭГЕФФкДцЁЃЯдШЛЃЌЗУЮЪБОЕиФкДцЕФЫйЖШНЋдЖдЖИпгкЗУЮЪдЖЕиФкДц(ЯЕЭГФкЦфЫќНкЕуЕФФкДц)ЕФЫйЖШЃЌетвВЪЧЗЧвЛжТДцДЂЗУЮЪNUMAЕФгЩРДЁЃгЩгкетИіЬиЕуЃЌЮЊСЫИќКУЕиЗЂЛгЯЕЭГадФмЃЌПЊЗЂгІгУГЬађЪБашвЊОЁСПМѕЩйВЛЭЌCPUФЃПщжЎМфЕФаХЯЂНЛЛЅЁЃ
ШБЕуЃКгЩгкЗУЮЪдЖЕиФкДцЕФбгЪБдЖдЖГЌЙ§БОЕиФкДцЃЌвђДЫЕБCPUЪ§СПдіМгЪБЃЌЯЕЭГадФмЮоЗЈЯпаддіМгЁЃ
MPPЃК
КЭNUMAВЛЭЌЃЌMPPЬсЙЉСЫСэЭтвЛжжНјааЯЕЭГРЉеЙЕФЗНЪНЃЌЫќгЩЖрИіSMPЗўЮёЦїЭЈЙ§вЛЖЈЕФНкЕуЛЅСЊЭјТчНјааСЌНгЃЌаЭЌЙЄзїЃЌЭъГЩЯрЭЌЕФШЮЮёЃЌДггУЛЇЕФНЧЖШРДПДЪЧвЛИіЗўЮёЦїЯЕЭГЁЃЦфЛљБОЬиеїЪЧгЩЖрИіSMPЗўЮёЦї(УПИіSMPЗўЮёЦїГЦНкЕу)ЭЈЙ§НкЕуЛЅСЊЭјТчСЌНгЖјГЩЃЌУПИіНкЕужЛЗУЮЪздМКЕФБОЕизЪдД(ФкДцЁЂДцДЂЕШ)ЃЌЪЧвЛжжЭъШЋЮоЙВЯэ(Share Nothing)НсЙЙЃЌвђЖјРЉеЙФмСІзюКУЃЌРэТлЩЯЦфРЉеЙЮоЯожЦЁЃ
дкMPPЯЕЭГжаЃЌУПИіSMPНкЕувВПЩвддЫааздМКЕФВйзїЯЕЭГЁЂЪ§ОнПтЕШЁЃЕЋКЭNUMAВЛЭЌЕФЪЧЃЌЫќВЛДцдквьЕиФкДцЗУЮЪЕФЮЪЬтЁЃЛЛбджЎЃЌУПИіНкЕуФкЕФCPUВЛФмЗУЮЪСэвЛИіНкЕуЕФФкДцЁЃНкЕужЎМфЕФаХЯЂНЛЛЅЪЧЭЈЙ§НкЕуЛЅСЊЭјТчЪЕЯжЕФЃЌетИіЙ§ГЬвЛАуГЦЮЊЪ§ОнжиЗжХф(Data Redistribution)ЁЃ
ЖўЁЂMPP database
ЛљгкMPPМмЙЙЕФЪ§ОнПтЯЕЭГЁЃ
0x02 Dremel
Dremel ЪЧGoogle ЕФЁАНЛЛЅЪНЁБЪ§ОнЗжЮіЯЕЭГЁЃGoogleПЊЗЂСЫDremelНЋДІРэЪБМфЫѕЖЬЕНУыМЖЃЌзїЮЊMapReduceЕФгаСІВЙГфЁЃDremelзїЮЊGoogle BigQueryЕФreportв§ЧцЃЌЛёЕУСЫКмДѓЕФГЩЙІЁЃ
ИљОнGoogleЙЋПЊЕФТлЮФЁЖDremel: Interactive Analysis of WebScaleDatasetsЁЗПЩвдПДЕНDremelЕФЩшМЦдРэЁЃЛЙгавЛаЉВтЪдБЈИцЁЃТлЮФаДгк2006ФъЃЌЙЋПЊгк2010ФъЁЃ
вЛЁЂBigQuery
BigQueryдЪаэгУЛЇЩЯДЋЫћУЧЕФГЌДѓСПЪ§ОнВЂЭЈЙ§ЦфжБНгНјааНЛЛЅЪНЗжЮіЃЌДгЖјВЛБиЭЖзЪНЈСЂздМКЕФЪ§ОнжааФЁЃ
ЖўЁЂDremelЬиЕу
- ДѓЙцФЃЯЕЭГЁЃдквЛИіPBМЖБ№ЕФЪ§ОнМЏЩЯУцЃЌНЋШЮЮёЫѕЖЬЕНУыМЖЃЌЮовЩашвЊДѓСПЕФВЂЗЂЁЃ
- MRНЛЛЅЪНВщбЏФмСІВЛзуЕФВЙГфЁЃашвЊGFSетбљЕФЮФМўЯЕЭГзїЮЊДцДЂВуЁЃ
- Ъ§ОнФЃаЭЪЧЧЖЬз(nested)ЕФЁЃDremelжЇГжвЛИіЧЖЬз(nested)ЕФЪ§ОнФЃаЭЃЌРрЫЦгкJsonЁЃ
- СаЪНДцДЂЁЃМѕЩйCPUКЭДХХЬЕФЗУЮЪСПЁЃ
- ЖрМЖЗўЮёЪїВщбЏЃЌНЋвЛИіЯрЖдОоДѓИДдгЕФВщбЏЃЌЗжИюГЩНЯаЁНЯМђЕЅЕФВщбЏЁЃДѓЪТЛЏаЁЃЌаЁЪТЛЏСЫЃЌФмВЂЗЂЕФдкДѓСПНкЕуЩЯХмЁЃ
- SQL-likeЕФНгПкЃЌОЭЯёHiveКЭPigФЧбљЁЃ
Ш§ЁЂDremelдРэ
ДѓжТзмНсвЛаЉDremelЕФдРэЃЌЛЙгаКУЖрУЛУїАз......
1.СаЪНДцДЂ
АДМЧТМЃКдкАДМЧТМДцДЂЕФФЃЪНжаЃЌвЛИіМЧТМЕФЖрСаЪЧСЌајЕФаДдквЛЦ№ЕФЁЃ
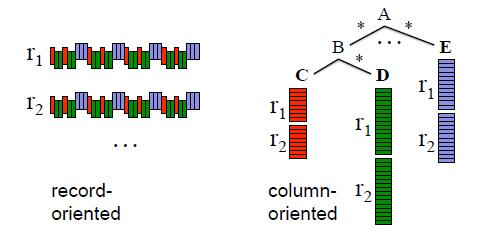
АДСаЃКдкАДСаДцДЂжаЃЌПЩвдНЋЪ§ОнАДСаЗжПЊЁЃвВОЭЪЧЫЕЃЌПЩвдНіНіЩЈУшA.B.CЖјВЛШЅЖСA.EЛђепA.B.CЁЃ
зЂвтЃК ШчКЮФмЭЌЪБИпаЇЕиЩЈУшШєИЩСаЃЌВЛЯўЕУЪЧдѕУДЪЕЯжЕФЁЃ
2.Ъ§ОнФЃаЭ
дкGoogle, гУProtocol BufferГЃГЃзїЮЊађСаЛЏЕФЗНАИЁЃЦфЪ§ОнФЃаЭПЩвдгУЪ§бЇЗНЗЈбЯИёЕФБэЪОШчЯТЃК
t=dom|<A1:t[*|?],...,An:t[*|?]>
ЦфжаtПЩвдЪЧвЛИіЛљБОРраЭЛђепзщКЯРраЭЁЃЦфжаЛљБОРраЭПЩвдЪЧinteger,floatКЭstringЁЃзщКЯРраЭПЩвдЪЧШєИЩИіЛљБОРраЭЦДДеЁЃаЧКХ(*)жИЕФЪЧШЮКЮРраЭЖМПЩвджиИДЃЌОЭЪЧЪ§зщвЛбљЁЃЮЪКХ(?)жИЕФЪЧШЮвтРраЭЖМЪЧПЩвдЪЧПЩбЁЕФЁЃМђЕЅРДЫЕЃЌГ§СЫУЛгаMapЭтЃЌКЭвЛИіJsonМИКѕУЛгаЧјБ№ЁЃ
ЯТЭМЪЧР§згЃЌSchemaЖЈвхСЫвЛИізщКЯРраЭDocument.гавЛИіБибЁСаDocIdЃЌПЩбЁСаLinksЃЌЛЙгавЛИіЪ§зщСаNameЁЃПЩвдгУName.Language.CodeРДБэЪОCodeСаЁЃ
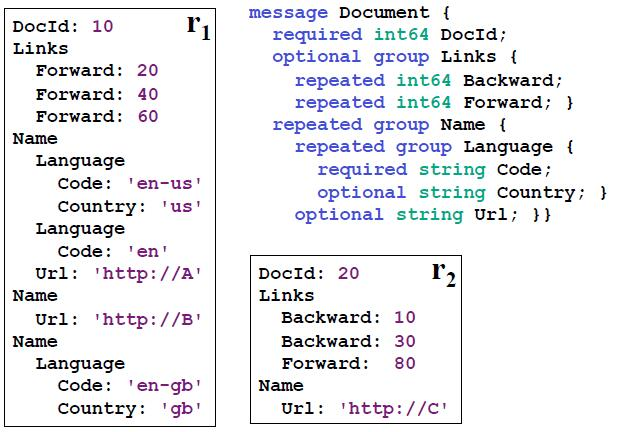
етжжЪ§ОнИёЪНЪЧгябдЮоЙиЃЌЦНЬЈЮоЙиЕФЁЃПЩвдЪЙгУJavaРДаДMRГЬађРДЩњГЩетИіИёЪНЃЌШЛКѓгУC++РДЖСШЁЁЃдкетжжСаЪНДцДЂжаЃЌФмЙЛПьЫйЭЈгУДІРэвВЪЧЗЧГЃЕФживЊЕФЁЃ
ЩЯЭМЃЌЪЧвЛИіЪОР§Ъ§ОнЕФГщЯѓЕФФЃаЭЃЛЯТЭМЪЧетЗнЪ§ОндкDremelЪЕМЪЕФДцДЂЕФИёЪНЁЃ
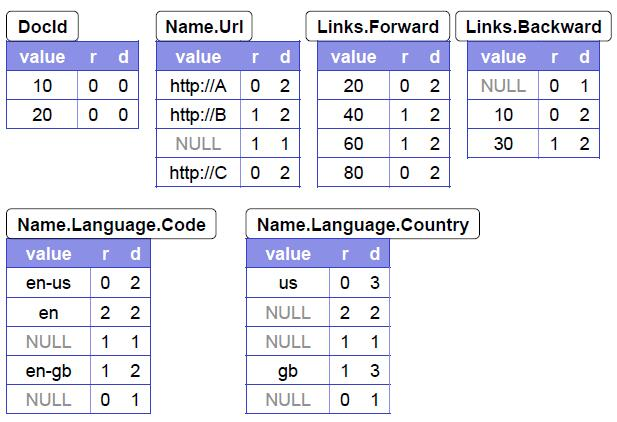
3.ЗўЮёЪїНсЙЙ
ШчЯТЭМЃЌЪЧDremelЕФЗўЮёЪїМмЙЙЕФЪОвтЭМЁЃ
root serverЃКзюЩЯВугавЛЬЈЕФИљЗўЮёЦїЃЈroot serverЃЉЃЌИКд№НгЪегУЛЇВщбЏЃЌВЂИљОнsqlУќСюевЕНУќСюжаЩшМЦЕФЪ§ОнБэЃЌЖСГіЯрЙиЪ§ОнБэЕФдЊЪ§ОнЃЌИФаДдЪМВщбЏКѓЭЦШыЯТвЛВуЗўЮёЦїЃЈжаМфЗўЮёЦїЃЉЁЃЭЌЪБИКд№НгЪежаМфЗўЮёЦїЗЕЛиЕФНсЙћЃЌНјааШЋОжОлКЯЃЌВЂЗЕЛиИјгУЛЇЁЃ
intermediate serversЃКжаМфЗўЮёЦїИФаДгЩЩЯВуЗўЮёЦїДЋЕнРДЕФВщбЏгяОфВЂвдДЫЯТЭЦЃЌжБЕНзюЕзВуЕФвЖНкЕуЗўЮёЦїЁЃдкНгЪеЕНвЖНкЕуЕФНсЙћКѓНјааОжВПОлМЏЕШВйзїЃЌзюКѓЗЕЛиИњЗўЮёЦїЁЃ
leaf serversЃК НкЕуЗўЮёЦїПЩвдЗУЮЪЪ§ОнДцДЂВуЛђепжБНгЗУЮЪБОЕиДХХЬЃЌЭЈЙ§ЩЈУшБОЕиЪ§ОнЕФЗНЪНжДааЗжХфИјздМКЕФsqlгяОфЃЌдкЛёЕУВщбЏНсЙћКѓШдШЛАДееЗўЮёЪїВуМЖгЩЕЭЕНИпж№ВуЗЕЛиНсЙћЁЃ
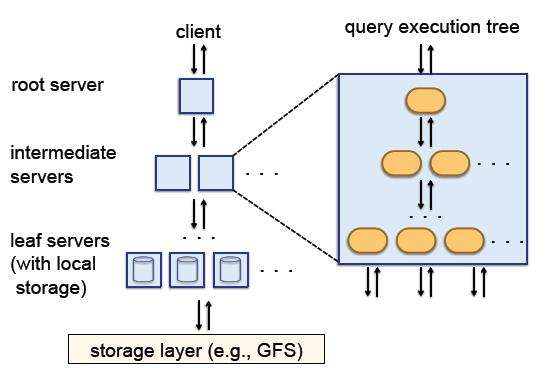
ОйИіРѕзгЃК
stage1ЃКЖдгкЧыЧѓЃК
SELECT A, COUNT(B) FROM T GROUP BY A
stage2ЃКИљНкЕуЪеЕНЧыЧѓЃЌДгдЊЪ§ОнжаЛёШЁЪ§ОнБэTЕФЫљгазгБэЃЌвдМАЦфЖдгІЕФЗўЮёЦїЃЌШЛКѓИФаДВщбЏШчЯТЃК
SELECT A, SUM(c) FROM (R1 UNION ALL ... Rn) GROUP BY A
ЦфжаRiДњБэroot serverжаДгЕк1ИіЗўЮёЦїЕНЕкnИіЗўЮёЦїНкЕужДааЕФЗЕЛиНсЙћЁЃ
stage3ЃКЖдзгБэЕФВщбЏЁЃ
Ri = SELECT A, COUNT(B) AS c FROM Ti GROUP BY A
НсЙЙМЏвЛЖЈЛсБШдЪМЪ§ОнаЁКмЖрЃЌДІРэЦ№РДвВИќПьЁЃИљЗўЮёЦїПЩвдКмПьЕФНЋЪ§ОнЛузмЁЃОпЬхЕФОлКЯЗНЪНЃЌПЩвдЪЙгУЯжгаЕФВЂааЪ§ОнПтММЪѕЁЃ
0x03 Impala
вЛЁЂжївЊзщМў
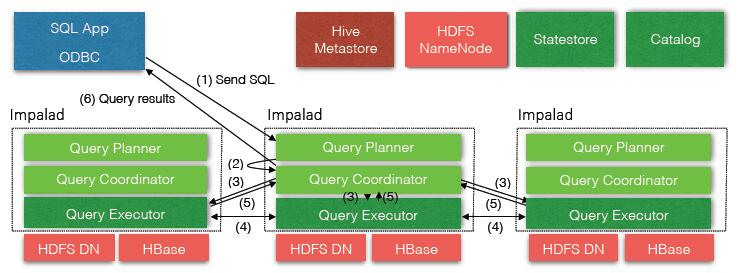
The core Impala component is a daemon process that runs on each DataNode of the cluster, physically represented by the impalad process.
ImpalaЕФКЫаФзщМўЪЧдЫаадкИїИіНкЕуЩЯУцЕФimpaladетИіЪиЛЄНјГЬЃЈImpala daemonЃЉЃЌЫќИКд№ЖСаДЪ§ОнЮФМўЃЌНгЪеДгimpala-shellЁЂHueЁЂJDBCЁЂODBCЕШНгПкЗЂЫЭЕФВщбЏгяОфЃЌВЂааЛЏВщбЏгяОфКЭЗжЗЂЙЄзїШЮЮёЕНImpalaМЏШКЕФИїИіНкЕуЩЯЃЌЭЌЪБИКд№НЋБОЕиМЦЫуКУЕФВщбЏНсЙћЗЂЫЭИјаЕїЦїНкЕуЃЈcoordinator nodeЃЉЁЃ
ФуПЩвдЯђдЫаадкШЮвтНкЕуЕФImpala daemonЬсНЛВщбЏЃЌетИіНкЕуНЋЛсзїЮЊетИіВщбЏЕФаЕїЦїЃЈcoordinator nodeЃЉЃЌЦфЫћНкЕуНЋЛсДЋЪфВПЗжНсЙћМЏИјетИіаЕїЦїНкЕуЁЃгЩетИіаЕїЦїНкЕуЙЙНЈзюжеЕФНсЙћМЏЁЃдкзіЪЕбщЛђепВтЪдЕФЪБКђЮЊСЫЗНБуЃЌЮвУЧЭљЭљСЌНгЕНЭЌвЛИіImpala daemonРДжДааВщбЏЃЌЕЋЪЧдкЩњВњЛЗОГдЫааВњЦЗМЖЕФгІгУЪБЃЌЮвУЧгІИУбЛЗЃЈАДЫГађЃЉЕФдкВЛЭЌНкЕуЩЯУцЬсНЛВщбЏЃЌетбљВХФмЪЙЕУМЏШКЕФИКдиДяЕНОљКтЁЃ
Impala daemonВЛМфЖЯЕФИњstatestoreНјааЭЈаХНЛСїЃЌДгЖјШЗШЯФФИіНкЕуЪЧНЁПЕЕФФмНгЪеаТЕФЙЄзїШЮЮёЁЃЫќЭЌЪБНгЪеcatalogd daemonЃЈДгImpala 1.2жЎКѓжЇГжЃЉДЋРДЕФЙуВЅЯћЯЂРДИќаТдЊЪ§ОнаХЯЂЃЌЕБМЏШКжаЕФШЮвтНкЕуcreateЁЂalterЁЂdropШЮвтЖдЯѓЁЂЛђепжДааINSERTЁЂLOAD DATAЕФЪБКђДЅЗЂЙуВЅЯћЯЂЁЃ
2.Impala Statestore
Impala StatestoreМьВщМЏШКИїИіНкЕуЩЯImpala daemonЕФНЁПЕзДЬЌЃЌЭЌЪБВЛМфЖЯЕиНЋНсЙћЗДРЁИјИїИіImpala daemonЁЃетИіЗўЮёЕФЮяРэНјГЬУћГЦЪЧstatestoredЃЌдкећИіМЏШКжаЮвУЧНіашвЊвЛИіетбљЕФНјГЬМДПЩЁЃШчЙћФГИіImpalaНкЕугЩгкгВМўДэЮѓЁЂШэМўДэЮѓЛђепЦфЫћдвђЕМжТРыЯпЃЌstatestoreОЭЛсЭЈжЊЦфЫћЕФНкЕуЃЌБмУтЦфЫћНкЕудйЯђетИіРыЯпЕФНкЕуЗЂЫЭЧыЧѓЁЃ
гЩгкstatestoreЪЧЕБМЏШКНкЕугаЮЪЬтЕФЪБКђЦ№ЭЈжЊзїгУЃЌЫљвдЫќЖдImpalaМЏШКВЂВЛЪЧгаЙиМќгАЯьЕФЁЃШчЙћstatestoreУЛгадЫааЛђепдЫааЪЇАмЃЌЦфЫћНкЕуКЭЗжВМЪНШЮЮёЛсееГЃдЫааЃЌжЛЪЧЫЕЕБНкЕуЕєЯпЕФЪБКђМЏШКЛсБфЕУУЛФЧУДНЁзГЁЃЕБstatestoreЛжИДе§ГЃдЫааЪБЃЌЫќОЭгжПЊЪМгыЦфЫћНкЕуЭЈаХВЂНјааМрПиЁЃ
3.Impala Catalog
Imppalla catalogЗўЮёНЋSQLгяОфзіГіЕФдЊЪ§ОнБфЛЏЭЈжЊИјМЏШКЕФИїИіНкЕуЃЌcatalogЗўЮёЕФЮяРэНјГЬУћГЦЪЧcatalogdЃЌдкећИіМЏШКжаНіашвЊвЛИіетбљЕФНјГЬЁЃгЩгкЫќЕФЧыЧѓЛсИњstatestore daemonНЛЛЅЃЌЫљвдзюКУШУstatestoredКЭcatalogdетСНИіНјГЬдкЭЌвЛНкЕуЩЯЁЃ
catalogЗўЮёМѕЩйСЫREFRESHКЭINVALIDATE METADATAгяОфЕФЪЙгУЁЃдкжЎЧАЕФАцБОжаЃЌЕБдкФГИіНкЕуЩЯжДааСЫCREATE DATABASEЁЂDROP DATABASEЁЂCREATE TABLEЁЂALTER TABLEЁЂЛђепDROP TABLEгяОфжЎКѓЃЌашвЊдкЦфЫќЕФИїИіНкЕуЩЯжДааУќСюINVALIDATE METADATAРДШЗБЃдЊЪ§ОнаХЯЂЕФИќаТЁЃЭЌбљЕФЃЌЕБФудкФГИіНкЕуЩЯжДааСЫINSERTгяОфЃЌдкЦфЫќНкЕуЩЯжДааВщбЏЪБОЭЕУЯШжДааREFRESH table_nameетИіВйзїЃЌетбљВХФмЪЖБ№ЕНаТдіЕФЪ§ОнЮФМўЁЃ
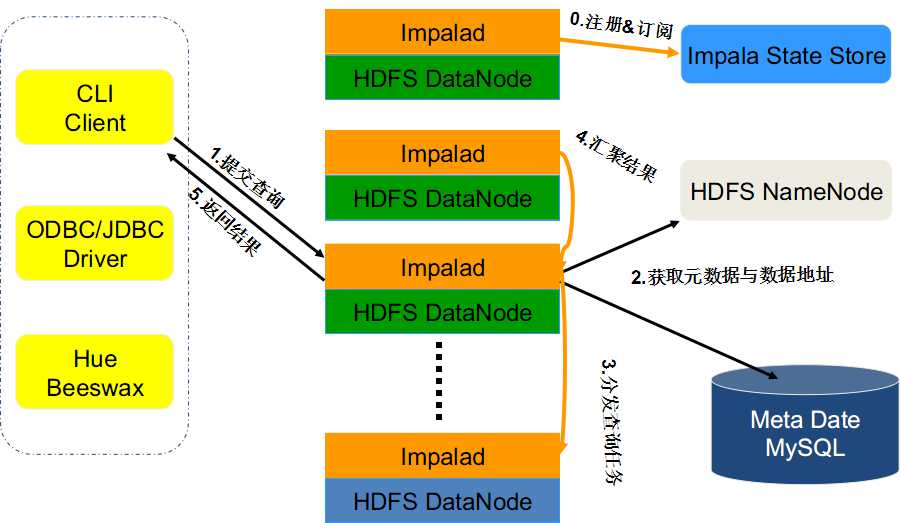
ЖўЁЂImpalaЕФВщбЏДІРэЙ§ГЬ
ШчЭМЪЧimpalaЕФВщбЏДІРэЙ§ГЬЁЃ
Ш§ЁЂВщбЏМЦЛЎ
ОйИіРѕзг
select count(*) from trace.apptalk
ЩњГЩЕФжДааМЦЛЎ
----------------
Estimated Per-Host Requirements: Memory=1.13GB VCores=1
WARNING: The following tables are missing relevant table and/or column statistics.
trace.apptalk
F01:PLAN FRAGMENT [UNPARTITIONED]
03:AGGREGATE [FINALIZE]
| output: count:merge(*)
| hosts=8 per-host-mem=unavailable
| tuple-ids=1 row-size=8B cardinality=1
|
02:EXCHANGE [UNPARTITIONED]
hosts=8 per-host-mem=unavailable
tuple-ids=1 row-size=8B cardinality=1
F00:PLAN FRAGMENT [RANDOM]
DATASTREAM SINK [FRAGMENT=F01, EXCHANGE=02, UNPARTITIONED]
01:AGGREGATE
| output: count(*)
| hosts=8 per-host-mem=10.00MB
| tuple-ids=1 row-size=8B cardinality=1
|
00:SCAN HDFS [trace.apptalk, RANDOM]
partitions=88/88 files=17578 size=67.11MB
table stats: unavailable
column stats: all
hosts=8 per-host-mem=1.13GB
tuple-ids=0 row-size=0B cardinality=unavailable
---------------- |
|









