вЛЁЂаЏГЬЪЕЪБгУЛЇЪ§ОнВЩМЏЯЕЭГЩшМЦЪЕМљ
ЫцзХвЦЖЏЛЅСЊЭјЕФаЫЦ№ЃЌЬиБ№ЪЧНќФъРДЃЌжЧФмЪжЛњЁЂpadЕШвЦЖЏЩшБИЦОНшБуНнЁЂИпаЇЕФЬиЕуЗчУвШЋЧђЃЌЭЌЪБИїРрAPPЕФПьЫйЗЂеЙНјвЛВННЕЕЭСЫвЦЖЏЛЅСЊЭјЕФНгШыУХМїЃЌдНРДдНЖрЕФЭјУёПЊЪМДгДЋЭГPCзЊвЦжСвЦЖЏжеЖЫЩЯЁЃЕЋДЋЭГЕФЛљгкPCЭјеОКЭЗУЮЪШежОЕФгУЛЇЪ§ОнВЩМЏЯЕЭГвбОЮоЗЈТњзуЪЕЪБЗжЮігУЛЇааЮЊЁЂЪЕЪБЭГМЦСїСПЪєадКЭЛљгкЮЛжУЗўЮёЃЈLBSЃЉЕШЗНУцЕФашЧѓЁЃ
ЮвУЧеыЖдДЋЭГгУЛЇЪ§ОнВЩМЏЯЕЭГдкЪЕЪБадЁЂЭЬЭТСПЁЂжеЖЫИВИЧТЪЕШЗНУцЕФВЛзуЃЌЗжЮіСЫдквЦЖЏЛЅСЊЭјСїСПОчдіЕФБГОАЯТЃЌгУЛЇЪ§ОнВЩМЏЯЕЭГЕФашЧѓЃЌбаОПдкЖржжЗУЮЪжеЖЫКЭЖржжЭјТчРраЭЕФГЁОАЯТЃЌгУЛЇЪ§ОнЪЕЪБЁЂИпаЇВЩМЏЕФЗНЗЈЃЌВЂдкДЫЛљДЁЩЯЩшМЦКЭЪЕЯжЪЕЪБЁЂгаађКЭНЁзГЕФгУЛЇЪ§ОнВЩМЏЯЕЭГЁЃДЫЯЕЭГЛљгкJava NIOЭјТчЭЈаХПђМмЃЈNettyЃЉКЭЗжВМЪНЯћЯЂЖгСаЃЈKafkaЃЉДцДЂПђМмЪЕЯжЃЌЦфОпгаЪЕЪБадЁЂИпЭЬЭТЁЂЭЈгУадКУЕШгХЕуЁЃ
1ЁЂММЪѕбЁаЭКЭЩшМЦЗНАИ
вЛИіЕфаЭЕФЪ§ОнВЩМЏЗжЮіЭГМЦЦНЬЈЃЌЖдЪ§ОнЕФДІРэЃЌжївЊгЩШчЯТЮхИіВНжшзщГЩЃК
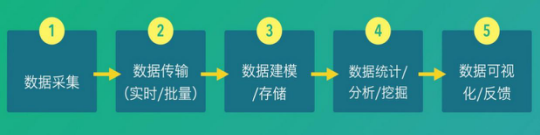
ЭМ1 Ъ§ОнЦНЬЈДІРэСїГЬ
ЦфжаЃЌЪ§ОнВЩМЏВНжшЪЧзюКЫаФЕФЮЪЬтЃЌЪ§ОнВЩМЏЪЧЗёЗсИЛЁЂзМШЗКЭЪЕЪБЃЌЖМжБНггАЯьећИіЪ§ОнЗжЮіЦНЬЈЕФгІгУЕФаЇЙћЁЃБОТлЮФЙизЂЕФВНжшжївЊдкЪ§ОнВЩМЏЁЂЪ§ОнДЋЪфКЭЪ§ОнНЈФЃДцДЂетШ§ВПЗжЁЃ
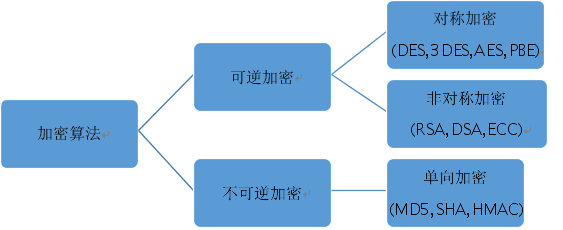
ЮЊТњзуЪ§ОнВЩМЏЗўЮёЪЕЪБЁЂИпаЇадЁЂИпЭЬЭТСПКЭАВШЋадЕШЗНУцЕФвЊЧѓЃЌЭЌЪБФмНшМјЛЅСЊЭјДѓЪ§ОнаавЕвЛаЉгХауПЊдДЕФНтОіЗНАИЃЌЫљвдећИіЯЕЭГЖМНЋЛљгкJavaММЪѕеЛНјааЩшМЦКЭЪЕЯжЁЃећИіЪ§ОнВЩМЏЗжЮіЦНЬЈЯЕЭГМмЙЙШчЯТЭМЫљЪОЃК
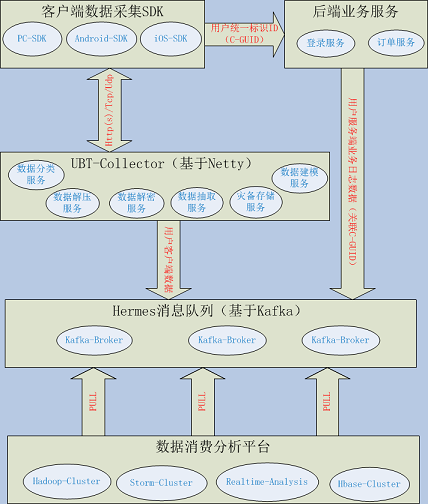
ЭМ2 Ъ§ОнВЩМЏЗжЮіЦНЬЈЯЕЭГМмЙЙ
ЦфжаећИіЦНЬЈЯЕЭГжївЊАќРЈвдЩЯЮхВПЗжЃКПЭЛЇЖЫЪ§ОнВЩМЏSDKвдHttp(s)/Tcp/UdpавщИљОнВЛЭЌЕФЭјТчЛЗОГАДвЛЖЈВпТдНЋЪ§ОнЗЂЫЭЕНMechanic(UBT-Collector)ЗўЮёЦїЁЃЗўЮёЦїЖдВЩМЏЕФЪ§ОнНјаавЛЯЕСаДІРэжЎКѓНЋЪ§ОнвьВНаДШыHermes(Kafka)ЗжВМЪНЯћЯЂЖгСаЯЕЭГЁЃЮЊСЫЙиСЊвЕЮёЗўЮёЖЫгУЛЇвЕЮёВйзїТёЕуЁЂШежОЃЌвЕЮёЗўЮёЦїашвЊЛёШЁгЩПЭЛЇЖЫSDKЭГвЛЩњГЩЕФгУЛЇБъЪЖЃЈC-GUIDЃЉЃЌШЛКѓвЕЮёЗўЮёЦїНЋгУЛЇвЕЮёВйзїТёЕуЁЂШежОаХЯЂвдвьВНЗНЪНаДШыHermes(Kafka)ЖгСаЁЃзюКѓЪ§ОнЯћЗбЗжЮіЦНЬЈЃЌЖМДгHermes(Kafka)жаЯћЗбВЩМЏЪ§ОнЃЌНјааЪ§ОнЪЕЪБЛђепРыЯпЗжЮіЁЃЦфжаMechanic(UBT-Collector)ЯЕЭГЛЙАќРЈЖдВЩМЏЪ§ОнКЭздЩэЯЕЭГЕФМрПиЃЌетаЉМрПиаХЯЂЯШаДШыHbaseМЏШКЃЌШЛКѓЭЈЙ§DashboardНчУцНјааЪЕЪБМрПиЁЃ
ЃЈ1ЃЉЛљгкNIOЕФNettyЭјТчПђМмЗНАИ
вЊТњзуЧАУцЬсЕНЕФИпЭЬЭТЁЂИпВЂЗЂКЭЖравщжЇГжЕШЗНУцЕФвЊЧѓЁЃЮвУЧЕїбаСЫМИжжПЊдДвьВНIOЭјТчЗўЮёзщМўЃЈШчNettyЁЂMINIЁЂxSocketЃЉЃЌгУЫќУЧКЭNginx WebЗўЮёЦїНјааСЫадФмЖдБШЃЌОіЖЈВЩгУNettyзїЮЊВЩМЏЗўЮёЭјТчзщМўЁЃЯТУцЖдЫќНјаавЛаЉИХвЊНщЩмЃКNettyЪЧвЛИіИпадФмЁЂвьВНЪТМўЧ§ЖЏЕФNIOПђМмЃЌЫќЬсЙЉСЫЖдTCPЁЂUDPКЭЮФМўДЋЪфЕФжЇГжЃЌNettyЕФЫљгаIOВйзїЖМЪЧвьВНЗЧзшШћЕФЃЌЭЈЙ§Future-ListenerЛњжЦЃЌгУЛЇПЩвдЗНБуЕФжїЖЏЛёШЁЛђепЭЈЙ§ЭЈжЊЛњжЦЛёЕУIOВйзїНсЙћЁЃ
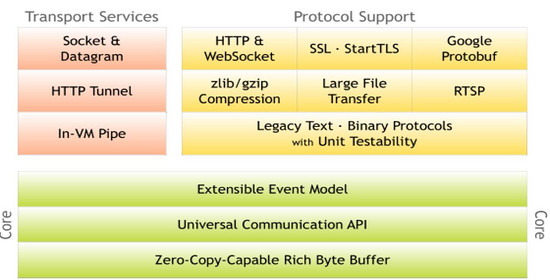
ЭМ3 NettyПђМмФкВПзщМўТпМНсЙЙ
NettyЕФгХЕугаЃК
- ЙІФмЗсИЛЃЌФкжУСЫЖржжЪ§ОнБрНтТыЙІФмЁЂжЇГжЖржжЭјТчавщЁЃ
- ИпадФмЃЌЭЈЙ§гыЦфЫќжїСїNIOЭјТчПђМмЖдБШЃЌЫќЕФзлКЯадФмзюМбЁЃ
- РЉеЙадКУЃЌПЩЭЈЙ§ЫќЬсЙЉЕФChannelHandlerзщМўЖдЭјТчЭЈаХЗНУцНјааСщЛюРЉеЙЁЃ
- взгУадЃЌAPIЪЙгУМђЕЅЁЃ
- ОЙ§СЫаэЖрЩЬвЕгІгУЕФПМбщЃЌдкЛЅСЊЭјЁЂЭјТчгЮЯЗЁЂДѓЪ§ОнЁЂЕчаХШэМўЕШжкЖраавЕЕУЕНГЩЙІЩЬгУЁЃ
NettyВЩгУСЫЕфаЭЕФШ§ВуЭјТчМмЙЙНјааЩшМЦЃЌТпММмЙЙЭМШчЯТЃК
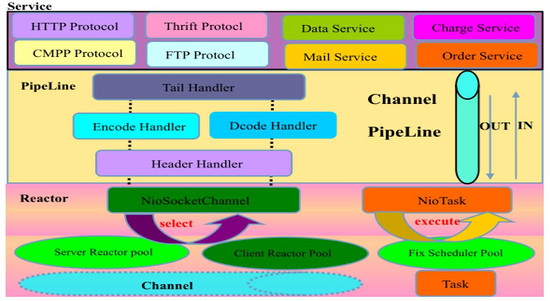
ЭМ4 NettyШ§ВуЭјТчТпММмЙЙ
ЕквЛВуЃКReactorЭЈаХЕїЖШВуЁЃИУВуЕФжївЊжАд№ОЭЪЧМрЬ§ЭјТчЕФСЌНгКЭЖСаДВйзїЃЌИКд№НЋЭјТчВуЕФЪ§ОнЖСШЁЕНФкДцЛКГхЧјжаЃЌШЛКѓДЅЗЂИїжжЭјТчЪТМўЃЌР§ШчСЌНгДДНЈЁЂСЌНгМЄЛюЁЂЖСЪТМўЁЂаДЪТМўЕШЃЌНЋетаЉЪТМўДЅЗЂЕНPipelineжаЃЌдйгЩPipelineГфЕБЕФжАд№СДРДНјааКѓајЕФДІРэ
ЕкЖўВуЃКжАд№СДPipelineВуЁЃИКд№ЪТМўдкжАд№СДжагаађЕФЯђЧАЃЈКѓЃЉДЋВЅЃЌЭЌЪБИКд№ЖЏЬЌЕФБрХХжАд№СДЁЃPipelineПЩвдбЁдёМрЬ§КЭДІРэздМКЙиаФЕФЪТМўЁЃ
ЕкШ§ВуЃКвЕЮёТпМДІРэВуЃЌвЛАуПЩЗжЮЊСНРрЃКa. ДПДтЕФвЕЮёТпМДІРэЃЌР§ШчШежОЁЂЖЉЕЅДІРэЁЃb. гІгУВуавщЙмРэЃЌР§ШчHTTP(S)авщЁЂFTPавщЕШЁЃ
ЮвУЧЖМжЊЕРгАЯьЭјТчЗўЮёЭЈаХадФмЕФжївЊвђЫигаЃКЭјТчI/OФЃаЭЁЂЯпГЬЃЈНјГЬЃЉЕїЖШФЃаЭКЭЪ§ОнађСаЛЏЗНЪНЁЃ
дкЭјТчI/OФЃаЭЗНУцЃЌNettyВЩгУЛљгкЗЧзшШћI/OЕФЪЕЯжЃЌЕзВувРРЕЕФЪЧJDK NIOПђМмЕФSelectorЁЃ
дкЯпГЬЕїЖШФЃаЭЗНУцЃЌNettyВЩгУReactorЯпГЬФЃаЭЁЃГЃгУЕФReactorЯпГЬФЃаЭгаШ§жжЃЌЗжБ№ЪЧЃК
- ReactorЕЅЯпГЬФЃаЭЃКReactorЕЅЯпГЬФЃаЭЃЌжИЕФЪЧЫљгаЕФI/OВйзїЖМдкЭЌвЛИіNIOЯпГЬЩЯУцЭъГЩЁЃЖдгквЛаЉаЁШнСПгІгУГЁОАЃЌПЩвдЪЙгУЕЅЯпГЬФЃаЭЁЃ
- ReactorЖрЯпГЬФЃаЭЃКRectorЖрЯпГЬФЃаЭгыЕЅЯпГЬФЃаЭзюДѓЕФЧјБ№ОЭЪЧгавЛзщNIOЯпГЬДІРэI/OВйзїЁЃжївЊгУгкИпВЂЗЂЁЂДѓвЕЮёСПГЁОАЁЃ
- жїДгReactorЖрЯпГЬФЃаЭЃКжїДгReactorЯпГЬФЃаЭЕФЬиЕуЪЧЗўЮёЖЫгУгкНгЪеПЭЛЇЖЫСЌНгЕФВЛдйЪЧвЛИіЕЅЖРЕФNIOЯпГЬЃЌЖјЪЧвЛИіЖРСЂЕФNIOЯпГЬГиЁЃРћгУжїДгNIOЯпГЬФЃаЭЃЌПЩвдНтОівЛИіЗўЮёЖЫМрЬ§ЯпГЬЮоЗЈгааЇДІРэЫљгаПЭЛЇЖЫСЌНгЕФадФмВЛзуЮЪЬтЁЃNettyЯпГЬФЃаЭВЂЗЧЙЬЖЈВЛБфЕФЃЌЫќПЩвджЇГжШ§жжReactorЯпГЬФЃаЭЁЃ
дкЪ§ОнађСаЛЏЗНУцЃЌгАЯьађСаЛЏадФмЕФжївЊвђЫигаЃК
- ађСаЛЏКѓЕФТыСїДѓаЁЃЈЭјТчДјПэеМгУЃЉЁЃ
- ађСаЛЏКЭЗДађСаЛЏВйзїЕФадФмЃЈCPUзЪдДеМгУЃЉЁЃ
- ВЂЗЂЕїгУЪБЕФадФмБэЯжЃКЮШЖЈадЁЂЯпаддіГЄЕШЁЃ
NettyФЌШЯЬсЙЉСЫЖдGoogle ProtobufЖўНјжЦађСаЛЏПђМмЕФжЇГжЃЌЕЋЭЈЙ§РЉеЙNettyЕФБрНтТыНгПкЃЌПЩвдЪЕЯжЦфЫќЕФИпадФмађСаЛЏПђМмЃЌР§ШчAvroЁЂThriftЕФбЙЫѕЖўНјжЦБрНтТыПђМмЁЃ
ЭЈЙ§ЖдNettyЭјТчПђМмЕФЗжЮібаОПвдМАЖдБШВтЪдЃЈМћКѓУцЕФПЩааадЗжЮіВтЪдБЈИцЃЉПЩХаЖЯЃЌЛљгкNettyЕФЪ§ОнВЩМЏЗНАИФмНтОіИпЪ§ОнЭЬЭТСПКЭЪ§ОнЪЕЪБЪеМЏЕФФбЕуЁЃ
ЃЈ2ЃЉПЭЛЇЖЫЪ§ОнМгНтУмКЭбЙЫѕЗНАИ
ЖдвЛаЉУїИаЕФВЩМЏЪ§ОнЃЌашвЊдкЪ§ОнДЋЪфЙ§ГЬжаНјааМгУмДІРэЁЃФПЧАДцдкЕФЮЪЬтЪЧЃЌПЭЛЇЖЫВЩМЏДњТыБШНЯШнвзБЛФфУћгУЛЇЛёШЁВЂЗДБрвыЃЈР§ШчAndroidЁЂJavaScriptЃЉЃЌЕМжТЪ§ОнМгУмЕФЫуЗЈКЭУмдПБЛгУЛЇЧдШЁЃЌНЯФбБЃжЄЪ§ОнЕФАВШЋадЁЃИљОнМгУмНсЙћЪЧЗёПЩвдБЛНтУмЃЌЫуЗЈПЩвдЗжЮЊПЩФцМгУмКЭВЛПЩФцМгУмЃЈЕЅЯђМгУмЃЉЁЃОпЬхЕФЗжРрНсЙЙШчЯТЃК
ЭМ5 МгУмЫуЗЈЗжРр
УмдПЃКЖдгкПЩФцМгУмЃЌУмдПЪЧМгУмНтЫуЗЈжаЕФвЛИіВЮЪ§ЃЌЖдГЦМгУмЖдгІЕФМгНтУмУмдПЪЧЯрЭЌЕФЃЛЗЧЖдГЦМгУмЖдгІЕФУмдПЗжЮЊЙЋдПКЭЫНдПЃЌЙЋдПгУгкМгУмЃЌЫНдПгУгкНтУмЁЃЫНдПЪЧВЛЙЋПЊВЛДЋЫЭЕФЃЌНіНігЩЭЈаХЫЋЗНГжгаБЃСєЃЛЖјЙЋдПЪЧПЩвдЙЋПЊДЋЫЭЕФЁЃЗЧЖдГЦУмдПЛЙЬсЙЉвЛжжЙІФмЃЌМДЪ§зжЧЉУћЁЃЭЈЙ§ЫНдПНјааЧЉУћЃЌЙЋдПНјааШЯжЄЃЌДяЕНЩэЗнШЯжЄЕФФПЕФЁЃ
ИљОнЪ§ОнВЩМЏПЭЛЇЖЫЕФЬиЕуЃЌЖдгкВЩМЏЪ§ОнЪЙгУЖдГЦМгУмЫуЗЈЪЧКмУїжЧЕФбЁдёЃЌЙиМќЪЧвЊБЃжЄЖдГЦУмдПЕФАВШЋадЁЃФПЧАПМТЧЕФЗНАИжївЊгаЃК
- НЋМгНтУмУмдПЗХШыAPPжаФГаЉБрвыКУЕФsoЮФМўжаЃЌШчЙћЪЧJavaScriptВЩМЏЕФЛАЃЌЙЙдьвЛИігУCБраДЕФЫуЗЈгУгкЩњГЩУмдПЃЌШЛКѓНшжњEmscriptenАбCДњТызЊЛЏЮЊJavaScriptДњТыЃЌетжжЗНАИгаНЯКУЕФЛьЯ§зїгУЃЌШУЧдЬ§епВЛЬЋШнвзЛёШЁЕНЖдГЦУмдПЁЃ
- НЋУмдПБЃДцЕНЗўЮёЦїЖЫЃЌУПДЮЗЂЫЭЪ§ОнЧАЃЌЭЈЙ§HTTPSЕФЗНЪНЛёШЁМгУмУмдПЃЌШЛКѓЖдВЩМЏЪ§ОнНјааМгУмКЭЗЂЫЭЁЃ
- ПЭЛЇЖЫКЭЗўЮёЦїЖЫБЃДцвЛЗнЙЋдПЃЌПЭЛЇЖЫЩњГЩвЛИіЖдГЦУмдПKЃЈОпгаЫцЛњадКЭЪБаЇадЃЉЃЌЪЙгУЙЋдПМгУмПЭЛЇЖЫЭЈаХШЯжЄФкШнЃЈUID+KЃЉЃЌВЂЗЂЫЭЕНЗўЮёЦїЖЫЃЌЗўЮёЖЫЪеЕНЭЈаХШЯжЄЧыЧѓЃЌЪЙгУЫНдПНјааНтУмЃЌЛёШЁЕНUIDКЭЖдГЦУмдПKЃЌКѓУцУПДЮВЩМЏЕФЪ§ОнЖМгУПЭЛЇЖЫФкДцжаЕФKНјааМгУмЃЌЗўЮёЦїЖЫИљОнUIDевЕНЖдгІЕФЖдГЦУмдПKЃЌНјааЪ§ОнНтУмЁЃ
етШ§жжПЭЛЇЖЫЪ§ОнМгУмЗНЪНЛљБОФмНтОіПЭЛЇЖЫВЩМЏЪ§ОнДЋЪфЕФАВШЋадФбЬтЁЃ
ВЩМЏЪ§ОнбЙЫѕЁЃЮЊСЫНкЪЁСїСПКЭДјПэЃЌИпаЇЗЂЫЭПЭЛЇЖЫВЩМЏЕФЪ§ОнЃЌашвЊЪЙгУПьЫйЧвИпбЙЫѕБШЕФбЙЫѕЫуЗЈЃЌФПЧАПМТЧЪЙгУБъзМЕФGZIPКЭЖЈжЦЕФLZ77ЫуЗЈЁЃ
ЃЈ3ЃЉЛљгкаЏГЬЗжВМЪНЯћЯЂжаМфМўHermesЕФЪ§ОнДцДЂЗНАИ
HermesЪЧЛљгкПЊдДЕФЯћЯЂжаМфМўKafkaЧвгЩаЏГЬзджїЩшМЦбаЗЂЁЃећЬхМмЙЙШчЭМЃК
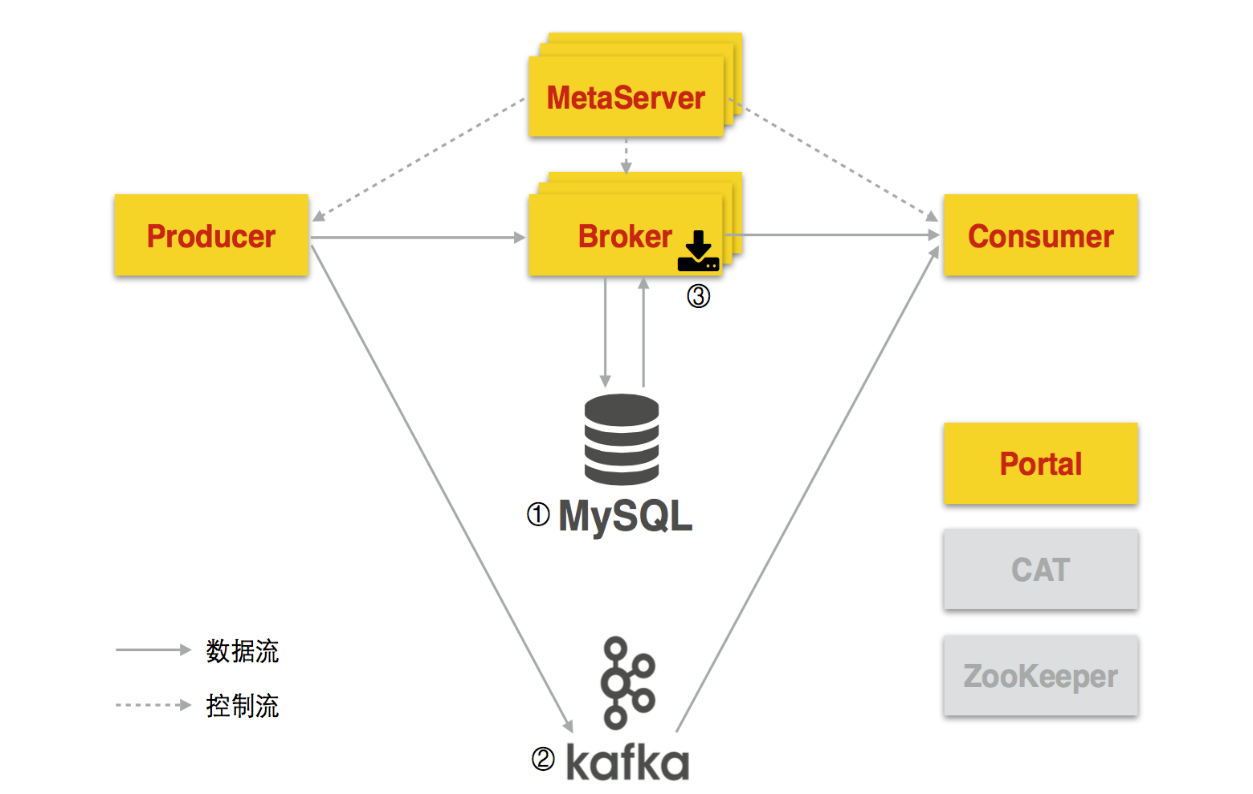
ЭМ6 HermesЯћЯЂЖгСаећЬхМмЙЙ
HermesЯћЯЂЖгСаДцДЂгаШ§жжРраЭЃК
- MySQLЪЪгУгкЯћЯЂСПжаЕШМАвдЯТЃЌЖдЯћЯЂжЮРэгаНЯИпвЊЧѓЕФГЁОАЁЃ
- KafkaЪЪгУгкЯћЯЂСПДѓЕФГЁОАЁЃ
- BrokerЗжВМЪНЮФМўДцДЂЃЈРЉеЙKafkaЁЂЖЈжЦДцДЂЙІФмЃЉЁЃ
гЩгкЪ§ОнВЩМЏЗўЮёЕФЯћЯЂСПЗЧГЃДѓЃЌЫљвдВЩМЏЪ§ОнашвЊДцДЂЕНKafkaжаЁЃKafkaЪЧвЛжжЗжВМЪНЕФЃЌЛљгкЗЂВМ/ЖЉдФЕФЯћЯЂЯЕЭГЁЃЫќФмТњзуВЩМЏЗўЮёИпЭЬЭТСПЁЂИпВЂЗЂКЭЪЕЪБЪ§ОнЗжЮіЕФвЊЧѓЁЃЫќгаШчЯТгХауЕФЬиадЃК
- вдЪБМфИДдгЖШЮЊO(1)ЕФЗНЪНЬсЙЉЯћЯЂГжОУЛЏФмСІЃЌМДЪЙЖдTBМЖвдЩЯЪ§ОнвВФмБЃжЄГЃЪ§ЪБМфИДдгЖШЕФЗУЮЪадФмЁЃ
- ИпЭЬЭТТЪЁЃМДЪЙдкЗЧГЃСЎМлЕФЩЬгУЛњЦїЩЯвВФмзіЕНЕЅЛњжЇГжУПУы100KЬѕвдЩЯЯћЯЂЕФДЋЪфЁЃ
- жЇГжKafka ServerМфЕФЯћЯЂЗжЧјЃЌМАЗжВМЪНЯћЗбЃЌЭЌЪББЃжЄУПИіPartitionФкЕФЯћЯЂЫГађДЋЪфЁЃ
- ЭЌЪБжЇГжРыЯпЪ§ОнДІРэКЭЪЕЪБЪ§ОнДІРэЁЃ
- Scale outЃЌМДжЇГждкЯпЫЎЦНРЉеЙЁЃ
вЛИіЕфаЭЕФKafkaМЏШКжаАќКЌШєИЩProducerЃЈПЩвдЪЧWebЧАЖЫВњЩњЕФВЩМЏЪ§ОнЃЌЛђепЪЧЗўЮёЦїШежОЃЌЯЕЭГCPUЁЂMemoryЕШЃЉЃЌШєИЩbrokerЃЈKafkaжЇГжЫЎЦНРЉеЙЃЌвЛАуbrokerЪ§СПдНЖрЃЌМЏШКЭЬЭТТЪдНИпЃЉЃЌШєИЩConsumer GroupЃЌвдМАвЛZookeeperМЏШКЁЃKafkaЭЈЙ§ZookeeperЙмРэМЏШКХфжУЃЌбЁОйleaderЃЌвдМАдкConsumer GroupЗЂЩњБфЛЏЪБНјааrebalanceЁЃProducerЪЙгУpushФЃЪННЋЯћЯЂЗЂВМЕНbrokerЃЌConsumerЪЙгУpullФЃЪНДгbrokerЖЉдФВЂЯћЗбЯћЯЂЁЃKafkaЭиЦЫНсЙЙЭМШчЯТЃК
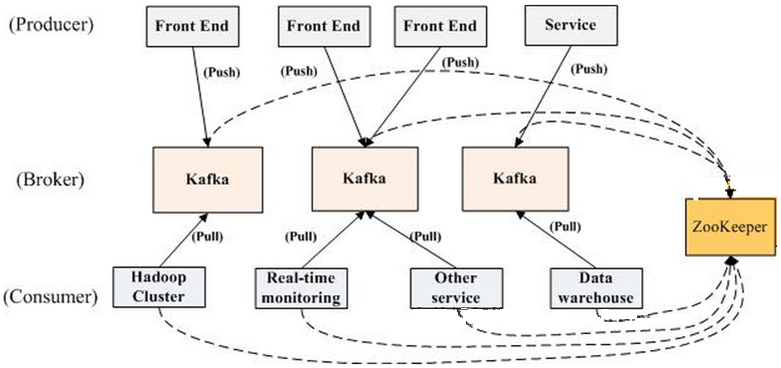
ЭМ7 KafkaЭиЦЫНсЙЙ
ЮвУЧжЊЕРЃЌПЭЛЇЖЫгУЛЇЪ§ОнЕФгаађадВЩМЏКЭДцДЂЖдКѓУцЕФЪ§ОнЯћЗбКЭЗжЮіЗЧГЃЕФживЊЃЌЕЋЪЧдквЛИіЗжВМЪНЛЗОГЯТЃЌвЊБЃжЄЯћЯЂЕФгаађадЪЧЗЧГЃРЇФбЕФЃЌЖјKafkaЯћЯЂЖгСаЫфШЛВЛФмБЃжЄЯћЯЂЕФШЋОжгаађадЃЌЕЋФмБЃжЄУПвЛИіPartitionФкЕФЯћЯЂЪЧгаађЕФЁЃдкгУЛЇЪ§ОнВЩМЏКЭЗжЮіЕФЯЕЭГжаЃЌЮвУЧжївЊЙизЂЕФЪЧЭЌвЛИігУЛЇЕФЪ§ОнЪЧЗёФмБЃжЄгаађЃЌШчЙћЮвУЧдкЪ§ОнВЩМЏЗўЮёЖЫФмНЋЭЌвЛИігУЛЇЕФЪ§ОнДцДЂЕНKafkaЕФЭЌвЛИіPartitionжаЃЌФЧУДОЭФмБЃжЄЭЌвЛИігУЛЇЕФЪ§ОнЪЧгаађЕФЃЌвђДЫЛљБОЩЯФмНтОіВЩМЏЪ§ОнЕФгаађадЁЃ
ЃЈ4ЃЉЛљгкAvroИёЪНЕФЪ§ОнджБИДцДЂЗНАИ
ЕБГіЯжЭјТчбЯжижаЖЯЛђепHermes(Kafka)ЯћЯЂЖгСаЙЪеЯЧщПіЯТЃЌгУЛЇЪ§ОнашвЊНјааджБИДцДЂЃЌФПЧАПМТЧЕФЗНАИЪЧЛљгкAvroИёЪНЕФБОЕиЮФМўДцДЂЁЃЦфжаAvroЪЧвЛИіЪ§ОнађСаЛЏЗДађСаЛЏПђМмЃЌЫќПЩвдНЋЪ§ОнНсЙЙЛђЖдЯѓзЊЛЏГЩБугкДцДЂЛђДЋЪфЕФИёЪНЃЌAvroЩшМЦжЎГѕОЭгУРДжЇГжЪ§ОнУмМЏаЭгІгУЃЌЪЪКЯгкдЖГЬЛђБОЕиДѓЙцФЃЪ§ОнЕФДцДЂКЭНЛЛЛЁЃ
AvroЖЈвхСЫвЛИіМђЕЅЕФЖдЯѓШнЦїЮФМўИёЪНЁЃвЛИіЮФМўЖдгІвЛИіФЃЪНЃЌЫљгаДцДЂдкЮФМўжаЕФЖдЯѓЖМЪЧИљОнФЃЪНаДШыЕФЁЃЖдЯѓАДееПщНјааДцДЂЃЌдкПщжЎМфВЩгУСЫЭЌВНМЧКХЃЌПщПЩвдВЩгУбЙЫѕЕФЗНЪНДцДЂЁЃвЛИіЮФМўгЩСНВПЗжзщГЩЃКЮФМўЭЗКЭвЛИіЛђепЖрИіЮФМўЪ§ОнПщЁЃЦфДцДЂНсЙЙШчЯТЭМЫљЪОЃК
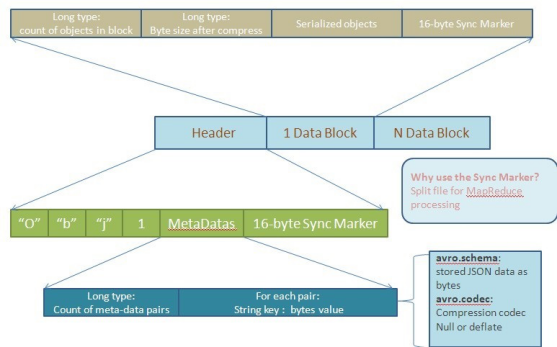
ЭМ8 AvroЖдЯѓШнЦїЮФМўИёЪН
джБИДцДЂДІРэЙ§ГЬЪЧЃКЕБЭјТчвьГЃЛђепHermes(Kafka)ЯћЯЂЖгСаГіЯжЙЪеЯЪБЃЌНЋВЩМЏЕФгУЛЇЪ§ОнНтЮіВЂзЊЛЏГЩAvroИёЪНКѓЃЌжБНгађСаЛЏДцДЂЕНБОЕиДХХЬЮФМўжаЃЌЪ§ОнАДKafka-TopicЗжГЩЖрИіЮФМўДцДЂЃЌЧвУПаЁЪБздЖЏЩњГЩвЛИіаТЕФЮФМўЁЃЕБЭјТчЛђепHermes(Kafka)ЙЪеЯЛжИДКѓЃЌКѓЖЫЯпГЬздЖЏЖСШЁДХХЬAvroЮФМўЃЌНЋЪ§ОнаДШыHermes(Kafka)ЯћЯЂЖгСаЕФЖдгІTopicКЭЗжЧјжаЁЃУПИіЮФМўаДШыГЩЙІКѓЃЌздЖЏЩОГ§джБИДцДЂЮФМўЁЃетбљФмдіМггУЛЇЪ§ОнВЩМЏЗўЮёЕФНЁзГадКЭдіЧПЗўЮёШнДэадЁЃ
2ЁЂМмЙЙЩшМЦЗНАИПЩааадЗжЮі
дкЯрЭЌХфжУЕФВтЪдЗўЮёЦїЩЯЃЈАќРЈЪ§ОнВЩМЏЗўЮёЦїЁЂHermes(Kafka)МЏШКЃЉзіШчЯТЖдБШЪЕбщВтЪдЃКЃЈЪЙгУApacheBenchmarkНјааWebадФмбЙСІВтЪдЙЄОпЃЉ
ЃЈ1ЃЉNetty VS NginxДІРэЭјТчЧыЧѓЖдБШ
дкВЛЖдВЩМЏЪ§ОнНјаавЕЮёДІРэЕФЧщПіЯТЃЈМДжЛНгЧыЧѓВЂзіЯьгІЃЌВЛзівЕЮёДІРэЃЌвВВЛДцДЂВЩМЏЪ§ОнЃЉЃЌдк5000ВЂЗЂЃЌKeepaliveФЃЪНЯТОљФмДяЕНУПУыДІРэ4ЭђЖрЧыЧѓЃЌЦфжаNginxЕФCPUЁЂФкДцЯћКФЛсаЁвЛаЉЁЃВтЪдЖдБШЪ§ОнШчЯТЃКЃЈ abВЮЪ§ЃК -k ЈCn 10000000 ЈCc 5000ЃЉ
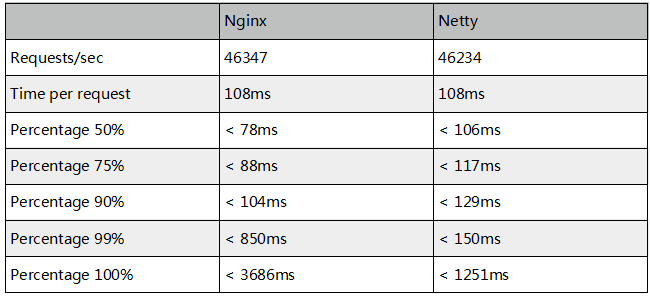
ЃЈ2ЃЉNettyЖдВЩМЏЪ§ОнНјаавЕЮёДІРэ
NettyЗўЮёМгЩЯВЩМЏЪ§ОнНтЮіЯрЙивЕЮёДІРэЃЌвдМАДІРэКѓЕФЪ§ОнаДШыHermes(Kafka)ЯћЯЂЖгСаЁЃПЩвдНјааМђЕЅЕФМфНгЙРЫуЁЃШчЙћВЩМЏЗўЮёвЊЧѓДяЕНЃКУПУыДІРэ3ЭђзѓгвЧыЧѓЃЌ99%ЕФЧыЧѓЭъГЩЪБМфаЁгк800msЕФФПБъЃЌдђВЩМЏЪ§ОнНтЮіКЭДцДЂСїГЬЕФДІРэЪБМфБиаыдк600msвдФкЁЃЖјетСНВНгжЗжЮЊЪ§ОнНтЮіКЭЪ§ОнДцДЂЃЌПЩвдЗжБ№НјаабЙСІВтЪдМгвдбщжЄЁЃ ИљОнЮвУЧЕФбЙСІВтЪдЃЌВЩМЏЪ§ОнНтЮіКЭДцДЂвВФмЭъШЋТњзуадФмвЊЧѓЁЃ
ОвдЩЯЖдБШЪЕбщВтЪдБэУїЃЌЪЙгУNettyЗўЮёзщМўЪеМЏЁЂНтЮіЪ§ОнВЂжБНгаДШыHermes(Kafka)ЗжВМЪНЯћЯЂЖгСаЕФЗНАИГѕВНОпБИПЩааадЁЃ
ЖўЁЂЯрЙиЪ§ОнЗжЮіВњЦЗНщЩм
ЛљгкЪЕЪБВЩМЏЕНЕФгУЛЇЪ§ОнКЭЯЕЭГМрПиЪ§ОнЃЌЮвУЧПЊЗЂСЫвЛЬзЯрЙиЕФЪ§ОнЗжЮіВњЦЗЁЃВњЦЗЕФФкШнжївЊЗжвдЯТМИВПЗжЃКЃЈ1ЃЉЁЂAPIКЭвГУцадФмБЈБэЃЛЃЈ2ЃЉЁЂвГУцЗУЮЪКЭСїСПЃЛЃЈ3ЃЉЁЂгУЛЇааЮЊЗжЮіЃЛЃЈ4ЃЉЁЂЯЕЭГвьГЃБРРЃЗжЮіЃЛЃЈ5ЃЉЁЂЪ§ОнЪЕЪБВщбЏЙЄОпЃЛЃЈ6ЃЉЁЂВЩМЏЪ§ОнХХеЯЙЄОпЃЛЃЈ7ЃЉЁЂЦфЫќЁЃЦфжаЯъЯИЗжРрШчЯТЭМЫљЪОЃК
ЭМ9 Ъ§ОнЗжЮіВњЦЗЗжРр
ЯжбЁШЁЦфжаМИИіБШНЯГЃМћЕФВњЦЗзіЯТМђЕЅНщЩмЃК
1ЁЂЕЅгУЛЇфЏРРИњзй
зїгУЃКЪЕЪБИњзйгУЛЇфЏРРМЧТМЃЌАяжњВњЦЗгХЛЏвГУцЗУЮЪСїГЬЁЂАяжњгУЛЇХХеЯЖЈЮЛЮЪЬтЁЃ
ЪЙгУАИР§ЃКИљОнгУЛЇдкПЭЛЇЖЫЩЯЕФЮЈвЛБъЪЖIDЃЌШчЃКЪжЛњКХЁЂEmailЁЂзЂВсгУЛЇУћЁЂClientIdЁЂVisitorIdЕШВщбЏДЫгУЛЇдкФГвЛЪБМфЖЮЫГађфЏРРЙ§ЕФвГУцКЭУПИівГУцЕФЗУЮЪЪБМфМАвГУцЭЃСєЪБГЄЕШаХЯЂЁЃШчЙћгУЛЇдкфЏРРвГУцЙ§ГЬжаЗЂЩњСЫвьГЃБРРЃЭЫГіЧщПіЃЌПЩвдНсКЯгІгУБРРЃаХЯЂЙиСЊВщбЏЕНЯрЙиаХЯЂЁЃ
2ЁЂвГУцзЊЛЏТЪ
зїгУЃКЪЕЪБВщПДИїИівГУцЕФЗУЮЪСПКЭзЊЛЏЧщПіЃЌАяжњЗжЮівГУцгУЛЇЬхбщвдМАвГУцВМОжЮЪЬтЁЃ
ЪЙгУАИР§ЃКгУЛЇЪзЯШХфжУвГУцфЏРРТЗОЖЃЌШчp1023 -> p1201 -> p1137 -> p1300ЃЌШЛКѓИљОнгУЛЇХфжУвГУцфЏРРТЗОЖВщбЏФГИіЪБМфЖЮИїИівГУцЕФзЊЛЏТЪЧщПіЁЃШчга1.4ЭђгУЛЇНјШыp1023вГУц,ЯТвЛВНга1400гУЛЇНјШыЯТвЛвГУцp1201ЁЃетбљПЩЭЦЫуГівГУцp1201ЕФзЊЛЏТЪЮЊ10%зѓгвЁЃетЪЧзюМђЕЅЕФвЛжжвГУцзЊЛЏТЪЃЌЛЙгаМфНгЕФвГУцзЊЛЏТЪЃЌМДжЛЦЅХфЕквЛИіКЭзюКѓвЛИівГУцЕФЗУЮЪСПЁЃЭЌЪБПЩвдАДИїжжЮЌЖШНјааЬѕМўЩИбЁЃЌБШШчЃКЭјТчЁЂдЫгЊЩЬЁЂЙњМвЁЂЕиЧјЁЂГЧЪаЁЂЩшБИЁЂВйзїЯЕЭГЕШЕШЁЃ
3ЁЂгУЛЇЗУЮЪСї
зїгУЃКСЫНтУПИівГУцЕФЯрЖдгУЛЇСПЁЂИїИівГУцМфЕФЯрЖдСїСПКЭЭЫГіТЪЁЂСЫНтИїЮЌЖШЯТвГУцЕФЯрЖдСїСПЁЃ
ЪЙгУАИР§ЃКгУЛЇбЁдёВщбЏЮЌЖШКЭЪБМфЖЮНјааВщбЏЃЌОЭФмЛёШЁЕНгІгУДгЕквЛИівГУцЕНЕкNИівГУцЕФЗУЮЪТЗОЖжаЃЌУПИівГУцЕФЗУЮЪСПКЭЖРСЂгУЛЇЛсЛАЪ§ЁЂУПИівГУцЕФгУЛЇСїЯђЁЂУПИівГУцЕФгУЛЇСїЪЇСПЕШаХЯЂЁЃ
4ЁЂЕуЛїШШСІЭМ
зїгУЃКЗЂЯжгУЛЇОГЃЕуЛїЕФФЃПщЛђепЧјгђЃЌХаЖЯгУЛЇЯВКУЁЂЗжЮівГУцжаФФаЉЧјгђЛђепФЃПщгаНЯИпЕФгааЇЕуЛїЪ§ЁЂгІгУгкA/BВтЪдЃЌБШНЯВЛЭЌвГУцЕФЕуЛїЗжВМЧщПіЁЂАяжњИФНјвГУцНЛЛЅКЭгУЛЇЬхбщЁЃ
ЪЙгУАИР§ЃКЕуЛїШШСІЭМВщПДЙЄОпАќРЈWebКЭAPPЖЫЃЌЭГМЦЕФжИБъАќРЈЃКдЪМЕуЛїЪ§ЃЈЕБЧАбЁжадЊЫиЕФдЪМЕуЛїзмЪ§ЃЉЁЂвГУцфЏРРЕуЛїЪ§ЃЈЕБЧАбЁжадЊЫиЕФгааЇЕуЛїЪ§ЃЌЭЌвЛДЮвГУцфЏРРЃЌЖрДЮЕуЛїРлМЦЫу1ДЮЕуЛїЃЉЁЂЖРСЂЗУПЭЕуЛїЪ§ЃЈЕБЧАбЁжадЊЫиЕФгааЇЕуЛїЪ§ЃЌ ЭЌвЛгУЛЇЃЌЖрДЮЕуЛїРлМЦЫу1ДЮЕуЛїЃЉЁЃ
5ЁЂВЩМЏЪ§ОнбщжЄВтЪд
зїгУЃКПьЫйВтЪдЪЧЗёФме§ГЃВЩМЏЪ§ОнЁЂЪ§ОнСПЪЧЗёе§ГЃЁЂВЩМЏЕФЪ§ОнЪЧЗёТњзуашЧѓЕШЁЃ
ЪЙгУАИР§ЃКгУЛЇЪЙгУаЏГЬAPPЩЈУшЙЄОпвГУцЕФЖўЮЌТыЃЌЛёШЁгУЛЇБъЪЖаХЯЂЃЌжЎКѓе§ГЃЪЙгУаЏГЬAPPЙ§ГЬжаЃЌФмЪЕЪБЕиНЋВЩМЏЕНЕФЪ§ОнЗжРреЙЪОдкЙЄОпвГУцжаЃЌЖдЪ§ОнНјааЖдБШВтЪдбщжЄЁЃ
6ЁЂЯЕЭГадФмБЈБэ
зїгУЃКМрПиЯЕЭГИївЕЮёЗўЮёЕїгУадФмЃЈШчSOAЗўЮёЁЂRPCЕїгУЕШЃЉЁЂвГУцМгдиадФмЁЂAPPЦєЖЏЪБМфЁЂLBSЖЈЮЛЗўЮёЁЂNative-CrashеМБШЁЂJavaScriptДэЮѓеМБШЕШЁЃАДаЁЪБЭГМЦИїЗўЮёЕїгУКФЪБЁЂГЩЙІТЪЁЂЕїгУДЮЪ§ЕШБЈБэаХЯЂЁЃ
ЛљгкЧАЖЫЖрЦНЬЈЃЈАќРЈiOSЁЂAndroidЁЂWebЁЂHybridЁЂRNЁЂаЁГЬађЃЉЪ§ОнВЩМЏSDKЕФЗсИЛЕФздЖЏЛЏТёЕуЪ§ОнЃЌЮвУЧПЩвдЖдЪ§ОнЁЂгУЛЇЁЂЯЕЭГШ§ЗНУцНјааЖрЮЌЖШСЂЬхЕФЗжЮіЁЃЗўЮёгкЯЕЭГВњЦЗКЭгУЛЇЬхбщЁЂгУЛЇСєДцЁЂзЊЛЛТЪМАЮќв§аТгУЛЇЁЃ |









