| вЛЁЂБГОА
дкHadoopМЏШКећИіЩњУќжмЦкРяЃЌгЩгкЕїећВЮЪ§ЁЂPatchЁЂЩ§МЖЕШЖржжГЁОАашвЊЦЕЗБВйзїNameNodeжиЦєЃЌВЛТлВЩгУКЮжжМмЙЙЃЌжиЦєЦкМфМЏШКећЬхДцдкПЩгУадКЭПЩППадЕФЗчЯеЃЌЫљвдгХЛЏNameNodeжиЦєЗЧГЃЙиМќЁЃ
БОЮФЛљгкHadoop-2.xКЭHA with QJMЩчЧјМмЙЙКЭЯЕЭГЩшМЦЃЈШчЭМ1ЫљЪОЃЉЃЌЭЈЙ§ЪсРэNameNodeжиЦєСїГЬЃЌВЂдкДЫЛљДЁЩЯЃЌВћЪіЖдNameNodeжиЦєгХЛЏЪЕМљЁЃ
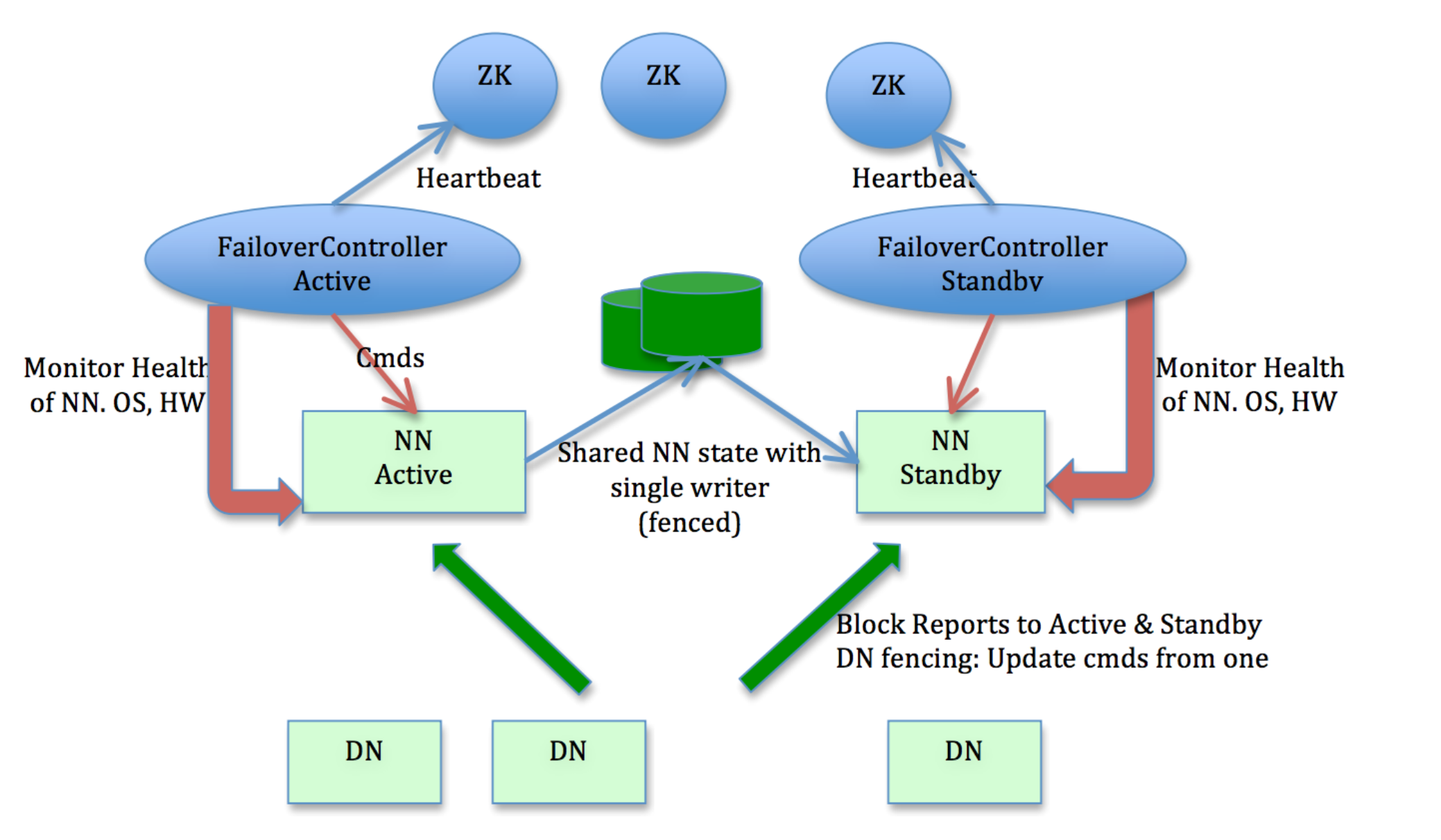
ЭМ1 HDFS HA with QJMМмЙЙЭМЪО
ЖўЁЂNameNodeжиЦєСїГЬ
дкHDFSЕФећИідЫааЦкРяЃЌЫљгадЊЪ§ОнОљдкNameNodeЕФФкДцМЏжаЙмРэЃЌЕЋЪЧгЩгкФкДцвзЪЇЬиадЃЌвЛЕЉГіЯжНјГЬЭЫГіЁЂхДЛњЕШвьГЃЧщПіЃЌЫљгадЊЪ§ОнЖМЛсЖЊЪЇЃЌИјећИіЯЕЭГЕФЪ§ОнАВШЋЛсдьГЩВЛПЩЛжИДЕФджФбЁЃЮЊСЫИќКУЕФШнДэФмСІЃЌNameNodeЛсжмЦкНјааCheckPointЃЌНЋЦфжаЕФвЛВПЗждЊЪ§ОнЃЈЮФМўЯЕЭГЕФФПТМЪїNamespaceЃЉЫЂЕНГжОУЛЏЩшБИЩЯЃЌМДЖўНјжЦЮФМўFSImageЃЌетбљЕФЛАМДЪЙNameNodeГіЯжвьГЃвВФмДгГжОУЛЏЩшБИЩЯЛжИДдЊЪ§ОнЃЌБЃжЄСЫЪ§ОнЕФАВШЋПЩППЁЃ
ЕЋЪЧНіжмЦкНјааCheckPointШдШЛЮоЗЈБЃжЄЫљгаЪ§ОнЕФПЩППЃЌШчЧАДЮCheckPointжЎКѓаДШыЕФЪ§ОнвРШЛДцдкЖЊЪЇЕФЮЪЬтЃЌЫљвдНЋСНДЮCheckPointжЎМфЖдNamespaceаДВйзїЪЕЪБаДШыEditLogЮФМўЃЌЭЈЙ§етжжЗНЪНПЩвдБЃжЄHDFSдЊЪ§ОнЕФОјЖдАВШЋПЩППЁЃ
ЪТЪЕЩЯЃЌГ§NamespaceЭтЃЌNameNodeЛЙЙмРэЗЧГЃживЊЕФдЊЪ§ОнBlocksMapЃЌУшЪіЪ§ОнПщBlockгыDataNodeНкЕужЎМфЕФЖдгІЙиЯЕЁЃNameNodeВЂУЛгаЖдетВПЗждЊЪ§ОнЭЌбљВйзїГжОУЛЏЃЌдвђЪЧУПИіDataNodeвбОГжгаЪєгкздМКЙмРэЕФBlockМЏКЯЃЌНЋЫљгаDataNodeЕФBlockМЏКЯЛузмКѓМДПЩЙЙдьГіЭъећBlocksMapЁЃ
HA with QJMМмЙЙЯТЃЌNameNodeЕФећИіжиЦєЙ§ГЬжаЪМжевдSBNЃЈStandbyNameNodeЃЉНЧЩЋЭъГЩЁЃгыЧАЪіСїГЬЖдгІЃЌЦєЖЏЙ§ГЬЗжвдЯТМИИіНзЖЮЃК
МгдиFSImageЃЛ
ЛиЗХEditLogЃЛ
жДааCheckPointЃЈЗЧБиаыВНжшЃЌНсКЯЪЕМЪЧщПіКЭВЮЪ§ШЗЖЈЃЌКѓајЯъЪіЃЉЃЛ
ЪеМЏЫљгаDataNodeЕФзЂВсКЭЪ§ОнПщЛуБЈЁЃ
ФЌШЯЧщПіЯТЃЌNameNodeЛсБЃДцСНИіFSImageЮФМўЃЌгыДЫЖдгІЃЌвВЛсБЃДцЖдгІСНДЮCheckPointжЎКѓЕФЫљгаEditLogЮФМўЁЃвЛАуРДЫЕЃЌNameNodeжиЦєКѓЃЌЭЈЙ§ЖдFSImageЮФМўУћГЦХаЖЯЃЌбЁдёМгдизюаТЕФFSImageЮФМўМАЛиЗХИУCheckPointжЎКѓЩњГЩЕФЫљгаEditLogЃЌЭъГЩКѓИљОнМгдиЕФEditLogжаВйзїЬѕФПЪ§МАОрЩЯДЮCheckPointЪБМфМфИєЃЈКѓајЯъЪіЃЉШЗЖЈЪЧЗёашвЊжДааCheckPointЃЌжЎКѓНјШыЕШД§ЫљгаDataNodeзЂВсКЭдЊЪ§ОнЛуБЈНзЖЮЃЌЕБетВПЗжЪ§ОнЪеМЏЭъГЩКѓЃЌNameNodeЕФжиЦєСїГЬНсЪјЁЃ
ДгЯпЩЯNameNodeРњДЮжиЦєЪБМфЪ§ОнПДЃЌИїНзЖЮКФЪБеМБШЛљБОНгНќШчЭМ2ЫљЪОЁЃ
ЭМ2 NameNodeжиЦєИїНзЖЮКФЪБеМБШ
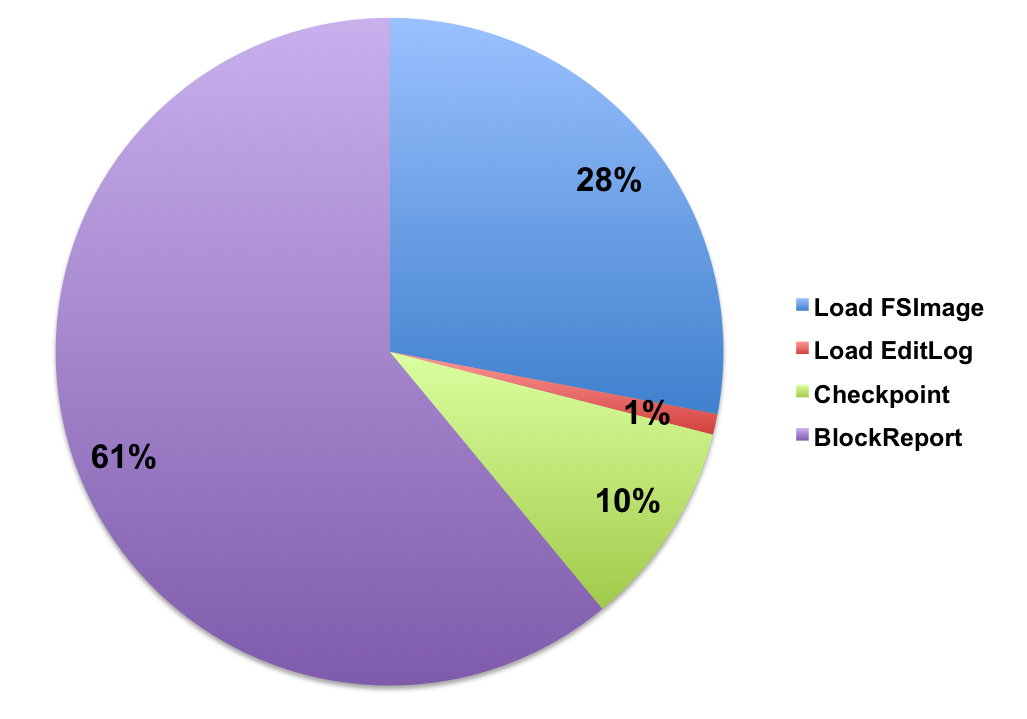
ОЙ§гХЛЏЃЌдкдЊЪ§ОнзмСП540MЃЈФПТМЪї240MЃЌЪ§ОнПщ300MЃЉЃЌГЌЙ§4KЙцФЃЕФМЏШКЩЯжиЦєNameNodeзмЪБМф~35minЃЌЦфжаМгдиFSImageКФЪБ~15minЃЌУыМЖЛиЗХEditLogЃЌЪ§ОнПщЛуБЈКФЪБ~20minЃЌЛљБОФмЙЛТњзуЩњВњЛЗОГЕФашЧѓЁЃ
2.1 МгдиFSImage
ШчЧАЪіЃЌFSImageЮФМўМЧТМСЫHDFSећИіФПТМЪїNamespaceЯрЙиЕФдЊЪ§ОнЁЃДгHadoop-2.4.0Ц№ЃЌFSImageПЊЪМВЩгУGoogle
ProtobufБрТыИёЪНУшЪіЃЈHDFS-5698ЃЉЃЌЯъЯИУшЪіЮФМўМћfsimage.protoЁЃИљОнУшЪіЮФМўКЭЪЕЯжТпМЃЌFSImageЮФМўИёЪНШчЭМ3ЫљЪОЁЃ
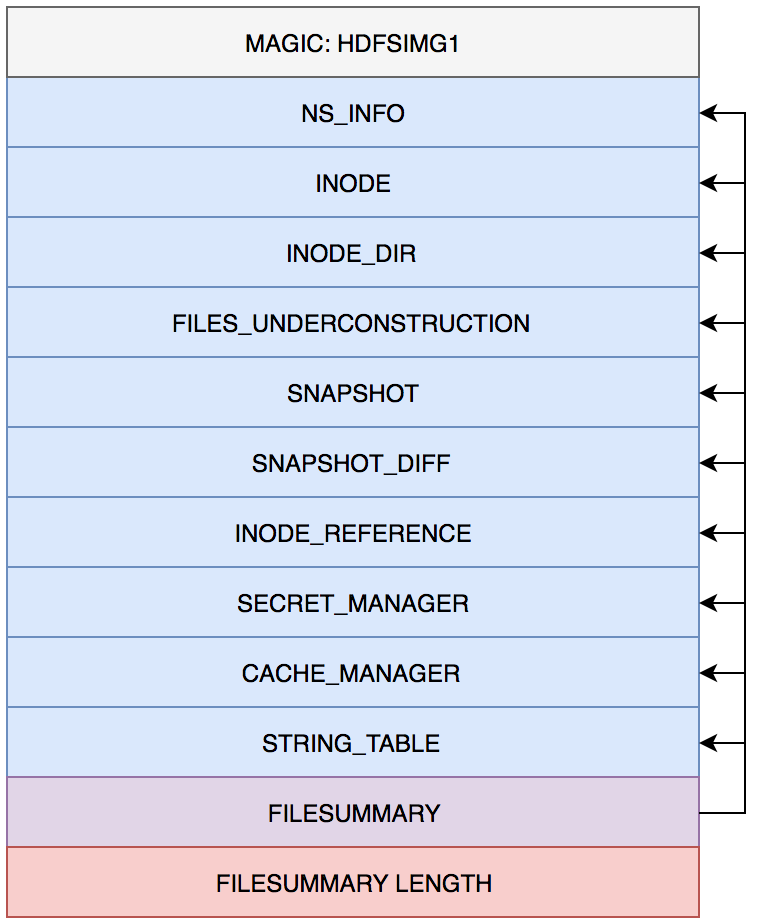
ЭМ3 FSImageЮФМўИёЪН
Дгfsimage.protoКЭFSImageЮФМўДцДЂИёЪНШнвзПДЕНЃЌГ§СЫБивЊЕФЮФМўЭЗВПаЃбщЃЈMAGICЃЉКЭЮВВПЮФМўЫїв§ЃЈFILESUMMARYЃЉЭтЃЌжївЊАќКЌвдЯТКЫаФЪ§ОнЃК
NS_INFOЃЈNameSystemSectionЃЉЃКМЧТМHDFSЮФМўЯЕЭГЕФШЋОжаХЯЂЃЌАќРЈNameSystemЕФIDЃЌЕБЧАвбОЗжХфГіШЅЕФзюДѓBlock
IDвдМАTransaction IDЕШаХЯЂЃЛ
INODEЃЈINodeSectionЃЉЃКећИіФПТМЪїЫљгаНкЕуЪ§ОнЃЌАќРЈ
INodeFile/INodeDirectory/INodeSymlink ЕШЫљгаРраЭНкЕуЕФЪєадЪ§ОнЃЌЦфжаМЧТМСЫШчНкЕуIDЃЌНкЕуУћГЦЃЌЗУЮЪШЈЯоЃЌДДНЈКЭЗУЮЪЪБМфЕШЕШаХЯЂЃЛ
INODE_DIRЃЈINodeDirectorySectionЃЉЃКећИіФПТМЪїжаЫљгаНкЕужЎМфЕФИИзгЙиЯЕЃЌХфКЯINODEПЩЙЙНЈЭъећЕФФПТМЪїЃЛ
FILES_UNDERCONSTRUCTION ЃЈFilesUnderConstructionSectionЃЉЃКЩаЮДЭъГЩаДШыЕФЮФМўМЏКЯЃЌжївЊЮЊжиЦєЪБжиНЈLeaseМЏКЯЃЛ
SNAPSHOTЃЈSnapshotSectionЃЉЃКМЧТМSnapshotЪ§ОнЃЌПьееЪЧHadoop 2.1.0в§ШыЕФаТЬиадЃЌгУгкЪ§ОнБИЗнЁЂЛиЙіЃЌвдЗРжЙвђгУЛЇЮѓВйзїЕМжТМЏШКГіЯжЪ§ОнЮЪЬтЃЛ
SNAPSHOT_DIFFЃЈ SnapshotDiffSectionЃЉЃКжДааПьееВйзїЕФФПТМ/ЮФМўЕФDiffМЏКЯЪ§ОнЃЌгыSNAPSHOTвЛЦ№ЙЙНЈНЯЭъећЕФПьееЙмРэФмСІЃЛ
SECRET_MANAGER ЃЈSecretManagerSectionЃЉЃКМЧТМDelegationKe
yКЭ DelegationTokenЪ§ОнЃЌИљОнDelegationKeyМАгЩDelegationTokenЙЙдьГіЕФDelegationTokenIdentifierЗНБуНјвЛВНМЦЫуУмТыЃЌвдЩЯЪ§ОнПЩвдЭъЩЦЫљгаКЯЗЈTokenМЏКЯЃЛ
CACHE_MANAGERЃЈCacheManagerSectionЃЉЃКМЏжаЪНЛКДцЬиадШЋОжаХЯЂЃЌМЏжаЪНЛКДцЬиадЪЧHadoop-2.3.0ЮЊЬсЩ§Ъ§ОнЖСадФмв§ШыЕФаТЬиадЃЛ
STRING_TABLEЃЈStringTableSectionЃЉЃКзжЗћДЎЕНIDЕФгГЩфБэЃЌЮЌЛЄФПТМ/ЮФМўЕФPermissionзжЗћЕНIDЕФгГЩфЃЌНкЪЁДцДЂПеМфЁЃ
NameNodeжДааCheckPointЪБЃЌзёбProtobufЖЈвхМАЩЯЪіЮФМўИёЪНУшЪіЃЌжиЦєМгдиFSImageЪБЃЌЭЌбљАДееProtobufЖЈвхЕФИёЪНДгЮФМўСїжаЖСГіЯргІЪ§ОнЙЙНЈећИіФПТМЪїNamespaceМАЦфЫћдЊЪ§ОнЁЃНЋFSImageЮФМўДгГжОУЛЏЩшБИМгдиЕНФкДцВЂЙЙНЈГіФПТМЪїНсЙЙКѓЃЌЪЕМЪЩЯВЂУЛгаЭъШЋЛжИДдЊЪ§ОнЕНзюаТзДЬЌЃЌвђЮЊУПДЮCheckPointжЎКѓЛЙПЩФмДцдкДѓСПHDFSаДВйзїЁЃ
2.2 ЛиЗХEditLog
NameNodeдкЯьгІПЭЛЇЖЫЕФаДЧыЧѓЧАЃЌЛсЪзЯШИќаТФкДцЯрЙидЊЪ§ОнЃЌШЛКѓдйАбетаЉВйзїМЧТМдкEditLogЮФМўжаЃЌПЩвдПДЕНФкДцзДЬЌЪЕМЪЩЯвЊБШEditLogЪ§ОнИќМАЪБЁЃ
МЧТМдкEditLogжЎжаЕФУПИіВйзїгжГЦЮЊвЛИіЪТЮёЃЌЖдгІвЛИіећЪ§аЮЪНЕФЪТЮёБрКХЁЃдкЕБЧАЪЕЯжжаЖрИіЪТЮёзщГЩвЛИіSegmentЃЌЩњГЩЖРСЂЕФEditLogЮФМўЃЌЦфжаЮФМўУћГЦБъМЧСЫЦ№жЙЕФЪТЮёБрКХЃЌе§дкаДШыЕФEditLogЮФМўНіБъМЧЦ№ЪМЪТЮёБрКХЁЃEditLogЮФМўЕФИёЪНЗЧГЃМђЕЅЃЌУЛдйЭЈЙ§Google
ProtobufУшЪіЃЌЮФМўИёЪНШчЭМ4ЫљЪОЁЃ

ЭМ4 EditLogЮФМўИёЪН
вЛИіЭъећЕФEditLogЮФМўАќРЈЫФИіВПЗжФкШнЃЌЗжБ№ЪЧЃК
LAYOUTVERSIONЃКАцБОаХЯЂЃЛ
OP_START_LOG_SEGMENTЃКБъЪЖЮФМўПЊЪМЃЛ
RECORDЃКЫГађж№ИіМЧТМHDFSаДВйзїЕФЪТЮёФкШнЃЛ
OP_END_LOG_SEGMENTЃКБъМЧЮФМўНсЪјЁЃ
NameNodeМгдиFSImageЭъГЩКѓЃЌМДПЊЪМЖдИУFSImageЮФМўжЎКѓЃЈЭЈЙ§БШНЯFSImageЮФМўУћГЦжаАќКЌЕФЪТЮёБрКХгыEditLogЮФМўУћГЦЕФЦ№ЪМЪТЮёБрКХДѓаЁШЗЖЈЃЉЩњГЩЕФЫљгаEditLogбЯИёАДееЪТЮёБрКХДгаЁЕНДѓж№ИізёбЩЯЪіЕФИёЪННјааУПвЛИіHDFSаДВйзїЪТЮёЛиЗХЁЃ
NameNodeМгдиЭъЫљгаБиашЕФEditLogЮФМўЪ§ОнКѓЃЌФкДцжаЕФФПТМЪїМДЛжИДЕНСЫзюаТзДЬЌЁЃ
2.3 DataNodeзЂВсЛуБЈ
ОЙ§ЧАУцСНИіВНжшЃЌжївЊЕФдЊЪ§ОнБЛЙЙНЈЃЌHDFSЕФећИіФПТМЪїБЛЭъећНЈСЂЃЌЕЋЪЧВЂУЛгаеЦЮеЪ§ОнПщBlockгыDataNodeжЎМфЕФЖдгІЙиЯЕBlocksMapЃЌЩѕжСЖдDataNodeЕФЧщПіЖМВЛеЦЮеЃЌЫљвдашвЊЕШД§DataNodeзЂВсЃЌВЂЭъГЩЖдДгDataNodeЛуБЈЩЯРДЕФЪ§ОнПщЛузмЁЃД§ЛузмЕФЪ§ОнСПДяЕНдЄЩшБШР§ЃЈdfs.namenode.safemode.threshold-pctЃЉКѓЭЫГіSafemodeЁЃ
NameNodeжиЦєОЙ§МгдиFSImageКЭЛиЗХEditLogКѓЃЌЫљгаDataNodeВЛЙмНјГЬЪЧЗёЗЂЩњЙ§жиЦєЃЌЖМБиаыОЙ§вдЯТСНИіВНжшЃК
DataNodeжиаТзЂВсRegisterDataNodeЃЛ
DataNodeЛуБЈЫљгаЪ§ОнПщBlockReportЁЃ
ЖдгкНкЕуЙцФЃНЯДѓКЭдЊЪ§ОнСПНЯДѓЕФМЏШКЃЌетИіНзЖЮЕФКФЪБЛсЗЧГЃПЩЙлЁЃжївЊгаШ§ЕудвђЃК
ДІРэBlockReportЕФТпМБШНЯИДдгЃЌЯрЖдЦфЫћRPCВйзїКФЪБНЯГЄЁЃЭМ5ЖдБШСЫBlockReportКЭAddBlockСНжжВЛЭЌRPCЕФДІРэЪБМфЃЌОЁЙмAddBlockВйзївВЯрЖдИДдгЃЌЕЋЪЧЖдБШРДПДЃЌBlockReportЕФДІРэЪБМфЯджјИпгкAddBlockДІРэЪБМфЃЛ
NameNodeЖдУПвЛИіBlockReportЕФRPCЧыЧѓДІРэЖМашвЊГжгаШЋОжЫјЃЌвВОЭЪЧЫЕЖдгкBlockReportРраЭRPCЧыЧѓЪЕМЪЩЯЪЧДЎааДІРэЃЛ
NameNodeжиЦєЪБЫљгаDataNodeМЏжадкЭЌвЛЪБМфЖЮНјааBlockReportЧыЧѓЁЃ
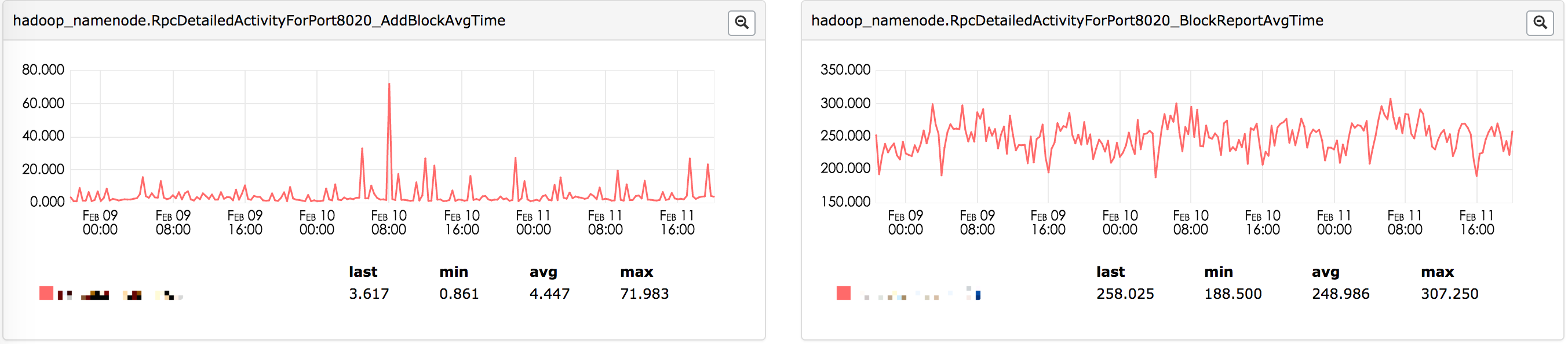
ЭМ5 BlockReportКЭAddBlockСНИіRPCДІРэЪБМфЖдБШ
жЎЧАЮвУЧдкNameNodeФкДцШЋОАвЛЮФжаЯъЯИУшЪіЙ§BlockдкNameNodeдЊЪ§ОнжаЕФЙиМќзїгУМАгыNamespace/DataNode/BlocksMapЕФИДдгЙиЯЕЃЌДгжавВПЩвдПДГіЃЌУПИіаТдіBlockашвЊЮЌЛЄЖрИіЙиЯЕЃЌИќКЮПіжиЦєЙ§ГЬжаЫљгаBlockЖМашвЊНЈСЂЭЌбљИДдгЙиЯЕЃЌЫљвдКФЪБЯрЖдНЯИпЁЃ
Ш§ЁЂжиЦєгХЛЏ
ИљОнЧАУцЖдNameNodeжиЦєЙ§ГЬЕФМђЕЅЪсРэЃЌдкИїИіНзЖЮПЩвдЪЪЕБЕФЪЕЪЉгХЛЏвдМгПьNameNodeжиЦєЙ§ГЬЁЃ
HDFS-7097 НтОіжиЦєЙ§ГЬжаSBNжДааCheckPointЪБВЛФмДІРэBlockReportЧыЧѓЕФЮЪЬт
FixЃК2.7.0
Hadoop-2.7.0АцБОЧАЃЌSBNЃЈStandbyNameNodeЃЉдкжДааCheckPointВйзїЧАЛсЯШЛёЕУШЋОжЖСаДЫјfsLockЃЌдкДЫЦкМфЃЌBlockReportЧыЧѓгЩгкВЛФмЛёЕУШЋОжаДЫјЛсГжајДІгкЕШД§зДЬЌЃЌжБЕНCheckPointЭъГЩКѓЪЭЗХСЫfsLockЫјКѓВХФмМЬајЁЃNameNodeжиЦєЕФЕкШ§ИіНзЖЮЃЌЭЌбљДцдкетжжЧщПіЁЃЖјЧвЖдгкЙцФЃНЯДѓЕФМЏШКЃЌУПДЮCheckPointЪБМфдкЗжжгМЖБ№ЃЌЖдећИіжиЦєЙ§ГЬгАЯьЗЧГЃДѓЁЃЪЕМЪЩЯЃЌCheckPointЪЧЖдФПТМЪїЕФГжОУЛЏВйзїЃЌВЂВЛЩцМАBlocksMapЪ§ОнНсЙЙЃЌЫљвдCheckPointЦкМфЪЧПЩвдШУBlockReportЧыЧѓжБНгЭЈЙ§ЃЌетбљПЩвдНкЪЁЦкМфBlockReportХХЖгЕШД§ДјРДЕФЪБМфПЊЯњЃЌHDFS-7097е§ЪЧНЋЫјСЃЖШЗХаЁНтОіСЫCheckPointЙ§ГЬВЛФмДІРэBlockReportРраЭRPCЧыЧѓЕФЮЪЬтЁЃ
гыHDFS-7097ЯрЖдЃЌСэвЛжжЫМТЗвВжЕЕУНшМјЃЌОЭЪЧжиЦєЙ§ГЬОЁПЩФмБмУтГіЯжCheckPointЁЃДЅЗЂCheckPointгаСНжжЧщПіЃКЪБМфжмЦкЛђHDFSаДВйзїЪТЮёЪ§ЃЌЗжБ№ЭЈЙ§ВЮЪ§
dfs.namenode.checkpoint.period КЭ dfs.namenode.checkpoint.txns
ПижЦЃЌФЌШЯжЕЗжБ№ЪЧ3600sКЭ1,000,000ЃЌМДФЌШЯЧщПіЯТвЛИіаЁЪБЛђепаДВйзїЕФЪТЮёЪ§ГЌЙ§1,000,000ДЅЗЂвЛДЮCheckPointЁЃЮЊСЫБмУтдкжиЦєЙ§ГЬжаЦЕЗБжДааCheckPointЃЌПЩвдЪЪЕБЕїДѓdfs.namenode.checkpoint.txnsЃЌНЈвщжЕ10,000,000
~ 20,000,000ЃЌДјРДЕФгАЯьЪЧEditLogЮФМўРлМЦЕФИіЪ§ЛсЩдгадіМгЁЃДгЪЕМљОбщЩЯПДЃЌЖдвЛИігавкМЖБ№дЊЪ§ОнСПЕФNameNodeЃЌЛиЗХвЛИіEditLogЮФМўЃЈФЌШЯ1,000,000аДВйзїЪТЮёЃЉЪБМфдкУыМЖЃЌЕЋЪЧжДаавЛДЮCheckPointЪБМфЭЈГЃдкЗжжгМЖБ№ЃЌзлКЯШЈКтМѕЩйCheckPointДЮЪ§КЭдіМгEditLogЮФМўЪ§ЪевцБШНЯУїЯдЁЃ
HDFS-6763 НтОіSBNУПМфИє1minШЋОжМЦЫуКЭбщжЄQuotaжЕЕМжТНјГЬHangзЁЪ§УыЕФЮЪЬт
FixЃК2.8.0
ANNЃЈActiveNameNodeЃЉНЋHDFSаДВйзїЪЕЪБаДШыJNЕФEditLogЮФМўЃЌЮЊЭЌВНЪ§ОнЃЌSBNФЌШЯМфИє1minДгJNРШЁвЛДЮEditLogЮФМўВЂНјааЛиЗХЃЌЭъГЩКѓжДааШЋОжQuotaМьВщКЭМЦЫуЃЌЕБNamespaceЙцФЃБфДѓКѓЃЌШЋОжМЦЫуКЭМьВщQuotaЛсЗЧГЃКФЪБЃЌдкДЫЦкМфЃЌећИіSBNЕФNamenodeНјГЬЛсБЛHangзЁЃЌвджСгкАќРЈDNаФЬјКЭBlockReportдкФкЕФЫљгаRPCЧыЧѓЖМВЛФмМАЪБДІРэЁЃNameNodeжиЦєЙ§ГЬжаетИіЮЪЬтгАЯьЭЛГіЁЃ
ЪЕМЪЩЯЃЌSBNдкEditLog TailerНзЖЮМЦЫуКЭМьВщQuotaЭъШЋУЛгаБивЊЃЌHDFS-6763НЋетЖЮДІРэТпМКѓвЦЕНжїДгЧаЛЛЪБНјааЃЌНтОіSBNНјГЬМфИє1minБЛHangзЁЕФЮЪЬтЁЃ
ДггХЛЏаЇЙћЩЯПДЃЌЖдвЛИігЕгаНгНќЮхвкдЊЪ§ОнСПЃЌЦфжаСНвкЪ§ОнПщЕФNameNodeЃЌгХЛЏЧАЪ§ОнПщЛуБЈНзЖЮКФЪБ~30minЃЌЦфжаДЅЗЂГЌЙ§20ДЮгЩгкМЦЫуКЭМьВщQuotaЕМжТНјГЬHangзЁ~20sЕФЧщПіЃЌећИіBlockReportНзЖЮДцдкГЌЙ§5minЮоаЇЪБМфПЊЯњЃЌгХЛЏКѓПЩЕН~25minЁЃ
HDFS-7980 МђЛЏЪзДЮBlockReportДІРэТпМгХЛЏжиЦєЪБМф
FixЃК2.7.1
NameNodeМгдиЭъдЊЪ§ОнКѓЃЌЫљгаDataNodeГЂЪдПЊЪМНјааЪ§ОнПщЛуБЈЃЌШчЙћЛуБЈЕФЪ§ОнПщЯрЙидЊЪ§ОнЛЙУЛгаМгдиЃЌЯШднДцЯћЯЂЖгСаЃЌЕБNameNodeЭъГЩМгдиЯрЙидЊЪ§ОнКѓЃЌдйДІРэИУЯћЯЂЖгСаЁЃЖдЕквЛДЮПщЛуБЈЕФДІРэБШНЯЬиБ№ЃЈNameNodeжиЦєКѓЃЌЫљгаDataNodeЕФBlockReportЖМЛсБЛБъМЧГЩЪзДЮЪ§ОнПщЛуБЈЃЉЃЌЮЊЬсИпДІРэЫйЖШЃЌНібщжЄПщЪЧЗёЫ№ЛЕЃЌжЎКѓХаЖЯПщзДЬЌЪЧЗёЮЊFINALIZEDЃЌШєЪЧНЈСЂЪ§ОнПщгыDataNodeЕФгГЩфЙиЯЕЃЌНЈСЂгыФПТМЪїжаЮФМўЕФЙиСЊЙиЯЕЃЌЦфЫћаХЯЂвЛИХднВЛДІРэЁЃЖдгкЗЧГѕДЮЪ§ОнПщЛуБЈЃЌДІРэТпМвЊИДдгКмЖрЃЌЖдБЈИцЕФУПИіЪ§ОнПщЃЌВЛНіМьВщЪЧЗёЫ№ЛЕЃЌЪЧЗёЮЊFINALIZEDзДЬЌЃЌЛЙЛсМьВщЪЧЗёЮоаЇЃЌЪЧЗёашвЊЩОГ§ЃЌЪЧЗёЮЊUCзДЬЌЕШЕШЃЛбщжЄЭЈЙ§КѓНЈСЂЪ§ОнПщгыDataNodeЕФгГЩфЙиЯЕЃЌНЈСЂгыФПТМЪїжаЮФМўЕФЙиСЊЙиЯЕЁЃ
ГѕДЮЪ§ОнПщЛуБЈЕФДІРэТпМЖРСЂГіРДЃЌжївЊдвђгаСНЗНУцЃК
МгПьNameNodeЕФЦєЖЏЪБМфЃЛВтЪдЪ§ОнЯдЪОКЌ~500MдЊЪ§ОнЕФNameNodeдкДІРэ800KИіЪ§ОнПщЕФГѕДЮПщЛуБЈЕФДІРэЪБМфБШе§ГЃПщЛуБЈЕФДІРэЪБМфПЩНЕЕЭвЛИіЪ§СПМЖЃЛ
ЦєЖЏЙ§ГЬжаЃЌВЛЬсЙЉе§ГЃЖСаДЗўЮёЃЌЫљвджЛвЊШЗБЃе§ГЃЪ§ОнЃЈећИіNamespaceКЭЫљгаFINALIZEDзДЬЌBlocksЃЉЮоЮѓЃЌЮоаЇКЭШпгрЪ§ОнДІРэЭъШЋПЩвдбгКѓЕНIBRЃЈIncrementalBlockReportЃЉЛђЯТДЮBRЃЈBlockReportЃЉЁЃ
етБОРДЪЧЗЧГЃКЯРэКЭе§ГЃЕФЩшМЦТпМЃЌЕЋЪЧЪЕЯжЪБNameNodeдкХаЖЯЪЧЗёЮЊЪзДЮЪ§ОнПщПщЛуБЈЕФТпМвЛжБДцдкЮЪЬтЃЌЕМжТетЖЮЗЧГЃКУЕФИФНјЕуТпМЪЕМЪЩЯГЄЦкВЂЮДеце§жДааЕНЃЌжБЕНHDFS-7980дкHadoop-2.7.1аоИДИУЮЪЬтЁЃHDFS-7980ЕФгХЛЏаЇЙћЗЧГЃУїЯдЃЌВтЪдЯдЪОЃЌЖдКЌ80K
BlocksЕФBlockReport RPCЧыЧѓЕФДІРэЪБМфДг~500msПЩгХЛЏЕН~100msЃЌДгжиЦєЦкећИіBlockReportНзЖЮПДЃЌдкГЌЙ§600MдЊЪ§ОнЃЌЦфжа300MЪ§ОнПщЕФNameNodeЯдЪОИУНзЖЮДг~50minгХЛЏЕН~25minЁЃ
HDFS-7503 НтОіжиЦєЧАДѓЩОГ§ВйзїЛсдьГЩжиЦєКѓЫјФкаДШежОНЕЕЭДІРэФмСІ
FixЃК2.7.0
ШєNameNodeжиЦєЧАВњЩњЙ§ДѓЩОГ§ВйзїЃЌЕБNameNodeМгдиЭъFSImageВЂЛиЗХСЫЫљгаEditLogЙЙНЈЦ№зюаТФПТМЪїНсЙЙКѓЃЌдкДІРэDataNodeЕФBlockReportЪБЃЌЛсЗЂЯжгаДѓСПBlockВЛЪєгкШЮКЮЮФМўЃЌHadoop-2.7.0АцБОЧАЃЌЖдгкетРрЧщПіЕФЪфГіШежОТпМдкШЋОжЫјФкЃЌгЩгкДцдкДѓСПIOВйзїЕФКФЪБЃЌЛсбЯжиРГЄДІРэBlockReportЕФДІРэЪБМфЃЌгАЯьNameNodeжиЦєЪБМфЁЃHDFS-7503ЕФНтОіАьЗЈЗЧГЃМђЕЅЃЌАбШежОЪфГіТпМвЦГіШЋОжЫјЭтЁЃЯпЩЯаЇЙћЩЯПДЖдЭЌРрГЁОАгХЛЏБШНЯУїЯдЃЌВЛЙ§ШчЙћжиЦєЧАВЛДЅЗЂДѓЕФЩОГ§ВйзїгАЯьВЛДѓЁЃ
ЗРжЙШШБИНкЕуSBNЃЈStandbyNameNodeЃЉ/РфБИНкЕуSNNЃЈSecondaryNameNodeЃЉГЄЪБМфЮДе§ГЃдЫааЖбЛ§ДѓСПEditlogЭЯТ§NameNodeжиЦєЪБМф
бЁдёHAШШБИЗНАИSBNЃЈStandbyNameNodeЃЉЛЙЪЧРфБИЗНАИSNNЃЈSecondaryNameNodeЃЉМмЙЙЃЌжДааCheckPointЕФТпММИКѕвЛжТЃЌШчЭМ6ЫљЪОЁЃШчЙћSBN/SNNЗўЮёГЄЪБМфЮДе§ГЃдЫааЃЌCheckPointВЛФмАДеедЄЦкжДааЃЌетбљЛсЛ§бЙДѓСПEditLogЁЃЛ§бЙЕФEditLogЮФМўдНЖрЃЌжиЦєNameNodeашвЊМгдиEditLogЪБМфдНГЄЁЃЫљвдОЁПЩФмБмУтГіЯжSNN/SBNГЄЪБМфЮДе§ГЃЗўЮёЕФзДЬЌЁЃ
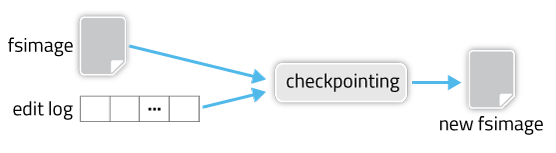
ЭМ6 CheckPointСїГЬ
дквЛИіга500MдЊЪ§ОнЕФNameNodeЩЯВтЪдМгдивЛИі200KДЮHDFSЪТЮёВйзїЕФEditLogЮФМўКФЪБ~5sЃЌАДееФЌШЯ2minЕФEditLogЙіЖЏжмЦкЃЌШчЙћвЛжмЪБМфSBN/SNNЮДФме§ГЃЙЄзїЃЌдђЛсРлЛ§~5KИіEditLogЮФМўЃЌДЫКѓвЛЕЉЗЂЩњNameNodeжиЦєЃЌНіМгдиEditLogЮФМўЕФЪБМфОЭашвЊ~7hЃЌвВОЭЪЧећИіМЏШКДцдкГЌЙ§7hВЛПЩгУЗчЯеЃЌЫљвдЧаМЧвЊБЃжЄSBN/SNNВЛФмГЄЪБМфЙЪеЯЁЃ
HDFS-6425 HDFS-6772 NameNodeжиЦєКѓDataNodeПьЫйЭЫГіblockContentsStaleзДЬЌЗРжЙPostponedMisreplicatedBlocksЙ§ДѓгАЯьЖдЦфЫћRPCЧыЧѓЕФДІРэФмСІ
Fix: 2.6.0ЃЌ 2.7.0
ЕБМЏШКжаДѓСПЪ§ОнПщЕФЪЕМЪДцДЂИББОИіЪ§ГЌЙ§ИББОЪ§ЪБЃЈПчЛњЗПМмЙЙЯТетжжЧщПіБШНЯГЃМћЃЉЃЌNameNodeжиЦєКѓЛсбИЫйЬюГфЕНPostponedMisreplicatedBlocksЃЌжБЕНЯрЙиЪ§ОнПщЫљдкЕФЫљгаDataNodeЛуБЈЭъГЩЧвЭЫГіStaleзДЬЌКѓВХФмБЛЧхРэЁЃШчЙћPostponedMisreplicatedBlocksЪ§ОнСПНЯДѓЃЌУПДЮШЋБщРњашвЊЯћКФДѓСПЪБМфЃЌЧвећИіЙ§ГЬвВвЊГжгаШЋОжЫјЃЌбЯжигАЯьДІРэBlockReportЕФадФмЃЌHDFS-6425КЭHDFS-6772ЗжБ№НЋПЩФмдкBlockReportТпМФкВПБщРњЗЧГЃДѓЕФЪ§ОнНсЙЙPostponedMisreplicatedBlocksгХЛЏЕНвьВНжДааЃЌВЂдкNameNodeжиЦєКѓШУDataNodeПьЫйЭЫГіblockContentsStaleзДЬЌБмУтPostponedMisreplicatedBlocksЙ§ДѓШыЪжгХЛЏжиЦєаЇТЪЁЃ
НЕЕЭBlockReportЪБЪ§ОнЙцФЃ
NameNodeДІРэBlockReportЕФаЇТЪЕЭжївЊдвђЛЙЪЧУПДЮBlockReportЫљДјЕФBlockЙцФЃЙ§ДѓдьГЩЃЌЫљвдПЩвдЭЈЙ§ЕїећBlockЪ§СПуажЕЃЌНЋвЛДЮBlockReportЗжГЩЖрХЬЗжБ№ЛуБЈЃЌвдЬсИпNameNodeЖдBlockReportЕФДІРэаЇТЪЁЃПЩВЮПМЕФВЮЪ§ЮЊЃКdfs.blockreport.split.thresholdЃЌФЌШЯжЕ1,000,000ЃЌМДЕБDataNodeБОЕиЕФBlockИіЪ§ГЌЙ§1,000,000ЪБВХЛсЗжХЬНјааЛуБЈЃЌНЈвщНЋИУВЮЪ§ЪЪЕБЕїаЁЃЌОпЬхЪ§жЕПЩНсКЯNameNodeЕФДІРэBlockReportЪБМфМАМЏШКжаЫљгаDataNodeЙмРэЕФBlockСПЗжВМШЗЖЈЁЃ
жиЦєЭъГЩКѓЖдБШМьВщЪ§ОнПщЩЯБЈЧщПі
ЧАУцЬсЕНNameNodeЛузмDataNodeЩЯБЈЕФЪ§ОнПщСПДяЕНдЄЩшБШР§ЃЈdfs.namenode.safemode.threshold-pctЃЉКѓОЭЛсЭЫГіSafemodeЃЌвЛАуЧщПіЯТЃЌЕБNameNodeЭЫГіSafemodeКѓЃЌЮвУЧШЯЮЊвбООпБИЬсЙЉе§ГЃЗўЮёЕФЬѕМўЁЃЕЋЪЧЖдЙцФЃНЯДѓЕФМЏШКЃЌАДееетжжФЌШЯВпТдМАЪБжДаажїДгЧаЛЛКѓЃЌШнвзГіЯжЖЬЪБМфЖЊПщЕФЮЪЬтЁЃПМТЧдк200MЪ§ОнПщЕФМЏШКЃЌФЌШЯХфжУЯюdfs.namenode.safemode.threshold-pct=0.999ЃЌвВОЭЪЧЕБNameNodeЪеМЏЕН200M*0.999=199.8MЪ§ОнПщКѓМДПЩЭЫГіSafemodeЃЌДЫЪБЪЕМЪЩЯЛЙга200KЪ§ОнПщУЛгаЩЯБЈЃЌШчЙћЧПаажДаажїДгЧаЛЛЃЌЛсГіЯжДѓСПЕФЖЊПщЮЪЬтЃЌжБЕНЪ§ОнПщЛуБЈЭъГЩЁЃгІЖдЕФАьЗЈБШНЯМђЕЅЃЌГЂЪдЕїДѓdfs.namenode.safemode.threshold-pctЕН1ЃЌетбљжЛгаЫљгаЪ§ОнПщЩЯБЈКѓВХЛсЭЫГіSafemodeЁЃЕЋЪЧетжжАьЗЈвЛбљВЛФмБЃжЄЭђЮовЛЪЇЃЌШчЙћЦєЖЏЙ§ГЬжагаDataNodeЛуБЈЭъЪ§ОнПщКѓНјГЬЙвЕєЃЌЭЌбљДцдкЖЬЪБМфЖЊЪЇЪ§ОнЕФЮЪЬтЃЌвђЮЊNameNodeЛузмЩЯБЈЪ§ОнПщЪБВЂВЛМьВщИББОЪ§ЃЌЫљвдИќЮШЭзЕФНтОіАьЗЈЪЧРћгУжїДгNameNodeЕФJMXЪ§ОнЖдБШЫљгаDataNodeЕБЧАЛуБЈЪ§ОнПщСПЕФВювьЃЌЕБВювьЖМНЯаЁКѓдйжДаажїДгЧаЛЛПЩвдБЃжЄВЛЗЂЩњЩЯЪіЮЪЬтЁЃ
ЦфЫћ
Г§СЫгХЛЏNameNodeжиЦєЪБМфЃЌЪЕМЪдЫЮЌжаЛЙЛсгіЕНашвЊЙіЖЏжиЦєМЏШКЫљгаНкЕуЛђепвЛДЮаджиЦєећМЏШКЕФЧщПіЃЌВЛЧЁЕБЕФжиЦєЗНЪНвВЛсбЯжигАЯьЗўЮёЕФЛжИДЪБМфЃЌЫљвдКЯРэПижЦжиЦєЕФНкзрЛђбЁдёКЯЪЪЕФжиЦєЗНЪНгШЮЊЙиМќЃЌHDFSМЏШКЦєЖЏЗНЪНЗжЮівЛЮФЖдМЏШКжиЦєЗНЪННјааСЫЯъЯИЕФВћЪіЃЌетРяОЭВЛдйеЙПЊЁЃ
ОЙ§ЖрДЮгХЛЏЕїећЃЌДгЯпЩЯNameNodeРњДЮЕФжиЦєЪБМфМрПижИБъЩЯПДЃЌЪевцЗЧГЃУїЯдЃЌЭМ7НиШЁСЫЦфжаМИДЮNameNodeжиЦєЪБдЊЪ§ОнСПМАжиЦєЪБМфПЊЯњЖдБШЃЌЭМжажБЙлЯдЪОдк500MдЊЪ§ОнСПМЖЯТЃЌжиЦєЪБМфДг~4000sгХЛЏЕН~2000sЁЃ
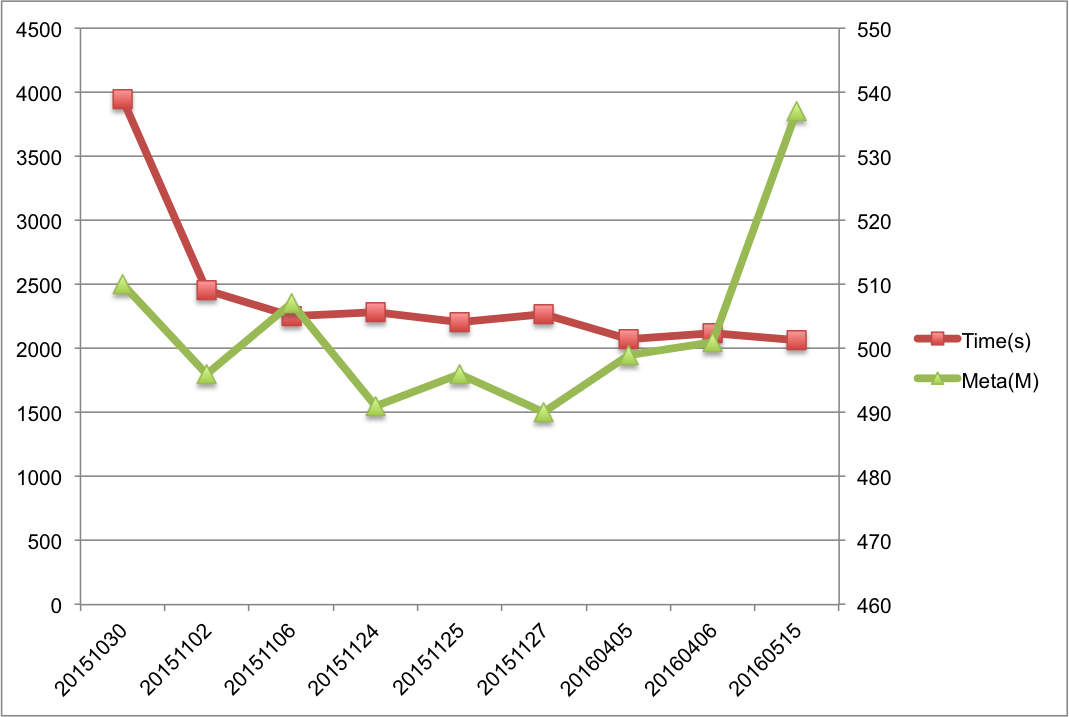
ЭМ7 NameNodeжиЦєЪБМфЖдБШ
етРяТоСаСЫвЛаЁВПЗжЪЕМљЙ§ГЬжаПЩвдгааЇгХЛЏжиЦєNameNodeЪБМфЛђепжиЦєШЋМЏШКЕФЕуЃЌЦфжаАќРЈСЫЩчЧјГЩЪьPatchКЭЯрЙиВЮЪ§гХЛЏЃЌЫфШЛЪЕЯжТпМЖМКмаЁЃЌЕЋЪЧЪЕМљЪевцЗЧГЃУїЯдЁЃЕБШЛГ§СЫЩЯЪіЬсЕНЃЌNameNodeжиЦєЛЙгаКмЖрПЩвдгХЛЏЕФЕиЗНЃЌБШШчгХЛЏFSImageИёЪНЃЌВЂааМгдиЕШЕШЃЌЩчЧјвВдкГжајЙизЂКЭгХЛЏЃЌВПЗжЬжТлЕФЫМТЗвВжЕЕУЙизЂЁЂНшМјКЭВЮПМЁЃ
ЫФЁЂзмНс
NameNodeжиЦєЩѕжСШЋМЏШКжиЦєдкећИіHadoopМЏШКЕФЩњУќжмЦкФкЪЧБШНЯЦЕЗБЕФдЫЮЌВйзїЃЌгХЛЏжиЦєЪБМфПЩвдМЋДѓЬсЩ§дЫЮЌаЇТЪЃЌБмУтПЩФмДцдкЕФЗчЯеЁЃБОЮФЭЈЙ§ЗжЮіNameNodeЦєЖЏСїГЬЃЌВЂНс |









