| НќаЉФъРДЃЌИїжжЛЅСЊЭј+ЕФЙЋЫОШчгъКѓДКЫёАуГіЯжЃЌзівЛИідкЯпЦНЬЈЛђепзівЛИіAPPЛљБОГЩЮЊетаЉЙЋЫОЕФБъХфЁЃWebЯЕЭГЕФСїааЃЌЪ§ОнЪеМЏдНРДдНШнвзЃЌДйЪЙИїРрЪ§ОнПтЯЕЭГгІгУЕУдНРДдНЙуЗКЁЃ
ЮвУЧдкЦНЪБЕФММЪѕЬжТлЛђепЪЕМЪгІгУжаОГЃЛсЬсЕНДЋЭГЪ§ОнПтЁЃЬсЕНДЋЭГЪ§ОнПтЃЌКмЖрШЫЛсКмШнвзСЊЯыЕНOracleЁЂMySQLЁЂSQL
ServerЕШДјгаКмУїЯдЙиЯЕаЭЪ§ОнПтЬиеїЕФЪ§ОнПтЯЕЭГЁЃдкЮвПДРДЃЌДЋЭГЪ§ОнПтВЂВЛЕШгкетаЉЪ§ОнПтЃЌЖјЪЧПДФудѕУДгУЕФЁЃвЛАуРДЫЕЃЌДЋЭГЪ§ОнПтАќРЈвдЯТШ§ИіЯЪУїЕФЬиЕуЃК
1ЁЂЪТЮёЕФБЃеЯЃКACID
ACIDвЛбдвдБЮжЎОЭЪЧдзгадЁЂвЛжТадЁЂИєРыадЁЂГжОУЛЏЪТЮёЃЌЫќЪЧЫФИіЕЅДЪЕФЫѕаДЃК
1.Atomicity дзгад ЪТЮёжаЫљгаВйзївЊУДШЋВПЭъГЩЃЌвЊУДШЋЪЇАмЁЃ
2.Consistency вЛжТад дкЪТЮёПЊЪМЪБЛђепНсЪјЪБЃЌЪ§ОнПтгІИУДІгкЭЌвЛзДЬЌЁЃ
3.Isolation ИєРыад ЪТЮёНЋМйЖЈжЛгаЫќздМКдкВйзїЪ§ОнПтЃЌБЫДЫВЛжЊЯўЁЃ
4.Durablity вЛЕЉЪТЮёЭъГЩЃЌОЭВЛФмЗЕЛиЁЃ
вЊзіЕНACIDЃЌДгБрГЬЕФНЧЖШРДЫЕЃЌЪ§ОнПтЯЕЭГвЛЖЈЛсгУЕНЫјЁЃ
вЛАуЖдЪТЮёвЊЧѓБШНЯИпЕФжївЊЪЧНЛвзГЁОАЃЌвјааЯЕЭГЁЂДѓаЭдкЯпЕчЩЬНЛвзЯЕЭГгУЕУБШНЯЖрЁЃЖдгкОјДѓЖрЪ§ДДвЕЙЋЫОЖјбдЃЌЪТЮёЪЧвЛИіЦЋРэТлЕФИХФюЁЃЪЕМЪЩЯдкЃЌдкЯпЯЕЭГжаЃЌЪТЮёЪЧвЛИіКмгагУЕФЖЋЮїЃЌЮвУЧОйИіРѕзгЃК
гУЛЇAдкЦНЬЈЙКТђдіжЕЗўЮёЕФГЁОАЃЌЛсгаКмЖржжДІРэЗНЪНЁЃ
вЛАуЕФГЬађдБЛсШчЯТДІРэЃК
1.дкВЦЮёБэжадіМгвЛЬѕгУЛЇAЕФПлЗбМЧТМЁЃЃЈПлЗбЃЉ
2.дкгУЛЇдіжЕЗўЮёБэжадіМгвЛЬѕгУЛЇAЕФдіжЕЗўЮёМЧТМЁЃЃЈПЊЭЈЗўЮёЃЉ
гУЛЇжСЩЯЕФГЬађдБЛсШчЯТДІРэЃК
1.дкгУЛЇдіжЕЗўЮёБэжадіМгвЛЬѕгУЛЇAЕФдіжЕЗўЮёМЧТМЁЃЃЈПЊЭЈЗўЮёЃЉ
2.дкВЦЮёБэжадіМгвЛЬѕгУЛЇAЕФПлЗбМЧТМЁЃЃЈПлЗбЃЉ
Ш§ФъвдЩЯЙЄзїОбщЕФГЬађдБЛсШчЯТДІРэЃК
1.дкВЦЮёБэжадіМгвЛЬѕгУЛЇAЕФПлЗбМЧТМЁЃЃЈПлЗбЃЉ
2.ХаЖЯВЦЮёБэжаЪЧЗёПлЗбГЩЙІЃЌВЛГЩЙІЭЈжЊЯЕЭГНЛвзЪЇАмЁЃ
3.дкгУЛЇдіжЕЗўЮёБэжадіМгвЛЬѕгУЛЇAЕФдіжЕЗўЮёМЧТМЁЃЃЈПЊЭЈЗўЮёЃЉ
4.ХаЖЯгУЛЇдіжЕЗўЮёБэжаЪЧЗёдіМгГЩЙІЃЌВЛГЩЙІЩОГ§ВЦЮёБэжаЕФПлЗбВЂЧвЭЈжЊЯЕЭГНЛвзЪЇАмЁЃ
ФЧУДгУЩЯЪТЮёжЎКѓЃЌФужЛвЊЬсНЛИјЪ§ОнПтвЛАуГЬађдБВйзїЃЌЪ§ОнПтОЭЛсИјФуШ§ФъвдЩЯЙЄзїОбщЕФГЬађдБЕФВйзїНсЙћЃЌдкжїДгМмЙЙЖСаДЗжРыЕФЪ§ОнПтНсЙЙжааЇЙћЛЙЛсИќКУЁЃ
2ЁЂЗсИЛЕФЪ§ОнРраЭКЭSQLЕФВйзїЗНЪН
ДЋЭГЕФЪ§ОнПтЯЕЭГПЩвдДцКмЖржжРраЭЕФЪ§ОнЃЌжївЊАќРЈЃК
1.Ъ§зжМвзхЁЂећЪ§КЭаЁЪ§ЁЃећЪ§гжПЩвдЗжЮЊ32ЮЛЕФЃЌ64ЮЛЕФЁ
2.зжЗћДЎРраЭЁЃзжЗћДЎгжЗжЮЊЙЬЖЈГЄЖШЕФКЭПЩБфГЄЖШЕФЁ
3.ЪБМфМвзхЁЃШеЦкЁЂЪБМфЁ
4.ЖўНјжЦСїЁ
етУДЖрРраЭЃЌШЗЪЕКмЗсИЛЁЃЮвУЧЫљПДЕНЕФЃЌЖМПЩвдЪЧзжЗћЃЌОЭЫуЖўНјжЦСїЃЌвВПЩвдЭЈЙ§Base64зЊТыгУзжЗћДЎБэЪОЁЃЕБШЛЃЌдкНВзжЗћДЎЕФЪБКђЃЌЮвУЧЪЧАбБрГЬгябдНјЛЏЕНСЫвЛИіКмИпМЖЕФГЬЖШЃЌПЊЗЂЕФгбКУадДѓгкДцДЂГЩБОЁЃ
ЖдгкДЋЭГЪ§ОнПтЯЕЭГЕФГЃгУВйзїЃЌЮвУЧвЛАуЛсЫЕCURDЁЃМДЖдБэЕФдіЩОИФВщЃЌЛљБОЖМгУSQLгяОфРДЪЕЯжЁЃSQLгяОфЕФНсЙЙжївЊЗжЮЊвдЯТМИДѓВПЗжЃК
1.ВйзїЃЌselectЁЂinsertЁЂupdateЁЂdeleteЁЃ
2.БэЖдЯѓЁЃ
3.зжЖЮЗЖЮЇ(*/f1/f2Ё)ЁЃ
4.WhereЬѕМўЁЃ
5.OrderХХађ(desc/asc)ЁЃ
6.ВщбЏЗЖЮЇЯожЦЃЈtop/limitЃЉЁЃ
ЁЁ
SQLгяОфЪЧЮЊЪЙгУепгбКУЖјЩшМЦЕФЃЌЮоТлКЮжжЪ§ОнПтв§ЧцЃЌSQLзюКѓЖМБЛгГЩфГЩЮЊIOКЭФкДцВйзїЁЃ
3ЁЂбЯИёЕФЪ§ОнФЃаЭЃКааЪНДцДЂ
дкДЋЭГЪ§ОнПтЯЕЭГжаЃЌвЛАуРДЫЕдкЕквЛДЮаДШыЪ§ОнжЎЧАЃЌЖМашвЊДДНЈПтКЭДДНЈБэЃЌЖјУПвЛИіБэЖМгаШЗЖЈЕФБэЭЗЃЌШЗЖЈСаЪ§ЃЌУПвЛСаЕФУћзжвдМАШЗЖЈЕФЪ§ОнРраЭЁЃдкаТЪ§ОнЕФаДШыЛђепЪ§ОнЕФаоИФЕФЪБКђЃЌЪ§ОнПтЯЕЭГЛсИљОнДДНЈКУЕФБэНсЙЙбЯИёаЃбщЪ§ОнЕФКЯЗЈадЃЌЖдБэНсЙЙЕФЕїећвЛАуЖМашвЊКмДѓЕФаоИФДњМлЁЃ
дкДцДЂЕЅдЊРяЃЌЭЌвЛааЕФЪ§ОнЛсЗжВМдкЯрСкЕФДцДЂЕЅдЊРяЁЃ
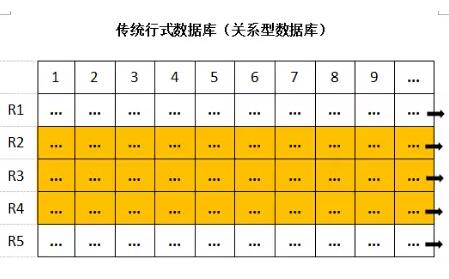
СаЪНДцДЂЯрЖдгкааЪНДцДЂЖјбдЃЌЦфЭЌвЛСаЕФЪ§ОнЛсЗжВМдкЯрСкЕФДцДЂЕЅдЊРяЁЃ
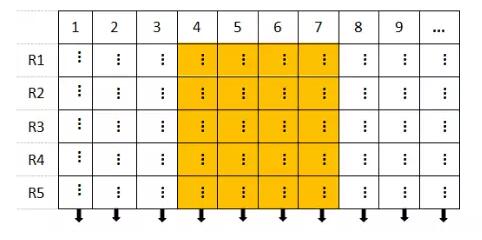
ЬтЭтЛАЃКГ§СЫааДцДЂКЭСаДцДЂЃЌГЃМћЛЙгаЮФЕЕФЃаЭЃЌЕфаЭЕФДњБэОЭЪЧMongoDBЁЃШчЙћгУДЋЭГЕФааЕФНЧЖШРДПДЃЌВЛЭЌЕФааСаЪ§ПЩвдВЛвЛбљЃЌСаЕФУћзжКЭЪ§ОнРраЭвВПЩвдВЛвЛбљЃЌСаРяУцПЩвдЪЧСэвЛИіЧЖЬзЕФааЁЃ
ЛЅСЊЭјЕФашЧѓ
дкЛЅСЊЭјЛЏЕФДѓЛЗОГЯТЃЌКмЖрЯЕЭГЖМКмШнвздкЖЬЪБМфФкЯЕЭГЪеМЏЩЯвкЕФЪ§ОнЃЌВЂЧветаЉЪ§ОнОЙ§МгЙЄЃЌЛЙвЊЮЊМИЪЎЭђЁЂМИАйЭђЩѕжСИќЖргУЛЇЬсЙЉЗУЮЪЁЃДгЦНЬЈНЧЖШРДЫЕЃЌвЛАуОЭЪЧДгаЁЕНДѓЃЌДгМђЕЅЕНИДдгЕФЙ§ГЬЁЃжївЊРДЫЕЃЌОпгавЛЯТШ§ЗНУцЬиЕуЃК
1.ЖдЪ§ОнИпВЂЗЂЖСаДЕФвЊЧѓ
Ъ§ОнПтЖСаДбЙСІОоДѓЃЌгВХЬIOЮоЗЈГаЪмЁЃвЛАуДІРэЗНЗЈЪЧжїДгМмЙЙЃЌЖСаДЗжРыЃЌЗжПтЁЂЗжБэЃЌЛКНтаДбЙСІЃЌдіЧПЖСПтЕФПЩРЉеЙадЁЃ
2.ЖдКЃСПЪ§ОнЕФДцДЂКЭЗУЮЪ
ДцДЂМЧТМЪ§СПгаЯоЃЌSQLВщбЏаЇТЪМЋЕЭЕФЧщПіЯТЁЃЭЈЙ§ЗжПтЁЂЗжБэЃЌЛКНтЪ§ОндіГЄбЙСІЁЃ
3.ЩьЫѕадЃЌПЩгУадЃЌПЩППадЗНУцЕФашЧѓ
КсЯђРЉеЙМшФбЃЌЮоЗЈЭЈЙ§ПьЫйдіМгЗўЮёЦїНкЕуЪЕЯжЃЌЯЕЭГЩ§МЖКЭЮЌЛЄдьГЩЗўЮёВЛПЩгУЁЃЭЈЙ§жїДгМмЙЙЃЌдіЧПЖСПтЕФРЉеЙадЃЌРћгУMMMМмЙЙДІРэаДЕФЦПОБЁЃ
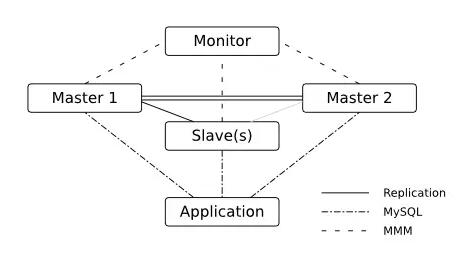
ДЋЭГЪ§ОнПтЕФЦПОБ
ЗжПтЗжБэШБЕуЃК 1.ЪмвЕЮёЙцдђгАЯьЃЌашЧѓБфЖЏЕМжТЗжПтЗжБэЕФЮЌЛЄИДдгЁЃ
2.ЯЕЭГЪ§ОнЗУЮЪВуДњТыашвЊаоИФЁЃ
жїДгМмЙЙШБЕуЃК 1.SlaveЪЕЪБадЕФБЃеЯЃЌЖдгкЪЕЪБадКмИпЕФГЁКЯПЩФмашвЊзівЛаЉДІРэЃЈдкЕквЛИіЙКТђдіжЕЗўЮёЕФР§згжаЃЌЬэМгПлЗбМЧТМжЎКѓЃЌдкЖСаДЗжРыЕФГЁОАЯТЃЌСЂТэШЅДгПтВщбЏПлЗбМЧТМВЛвЛЖЈФмВщЕНЃЉЁЃ
2.ИпПЩгУадЮЪЬтЃЌMasterОЭЪЧФЧИіжТУќЕуЃЌШнвзВњЩњЕЅЕуЙЪеЯЁЃ
MMMШБЕуЃК
БОЩэРЉеЙадВюЃЌвЛДЮжЛФмвЛИіMasterПЩвдаДШыЃЌжЛФмНтОігаЯоЪ§ОнСПЯТЕФПЩгУадЁЃ
ЗжВМЪНЛљДЁРэТл
1ЁЂCAP
ЗжВМЪНСьгђCAPРэТл
1.Consistency вЛжТадЃКЪ§ОнвЛжТИќаТЃЌЫљгаЪ§ОнБфЖЏЖМЪЧЭЌВНЕФЁЃ
2.Availability(ПЩгУад)ЃККУЕФЯьгІадФмЁЃ
3.Partition toleranceЃКЗжЧјШнШЬадЁЃ
дкЗжВМЪНЯЕЭГжаЃЌетШ§ИівЊЫизюЖржЛФмЭЌЪБЪЕЯжСНЕуЃЌВЛПЩФмШ§епМцЙЫЃЛЖдгкЗжВМЪНЪ§ОнЯЕЭГЃЌЗжЧјШнШЬадЪЧЛљБОвЊЧѓЃЛЖдгкДѓЖрЪ§WebгІгУЃЌЮўЩќвЛжТадЖјЛЛШЁИпПЩгУадЃЌЪЧФПЧАЖрЪ§ЗжВМЪНЪ§ОнПтВњЦЗЕФЗНЯђЁЃ
2ЁЂBase
1.Basically AvailableЃКЛљБОПЩгУ жЇГжЗжЧјЪЇАмЁЃ
2.Soft state ШэзДЬЌЃКзДЬЌПЩвдгавЛЖЮЪБМфВЛЭЌВНЃЌвьВНЁЃ
3.Eventually consistentЃКзюжевЛжТад ЃЌзюжеЪ§ОнЪЧвЛжТЕФОЭПЩвдСЫЃЌЖјВЛЪЧЪБЪБвЛжТЁЃ
3ЁЂNoSQLдЫЖЏСНИіКЫаФРэТл
GoogleЕФBigTable
BigTableЬсГіСЫвЛжжКмгаШЄЕФЪ§ОнФЃаЭЃЌЫќНЋИїСаЪ§ОнНјааХХађДцДЂЁЃЪ§ОнжЕАДЗЖЮЇЗжВМдкЖрЬЈЛњЦїЃЌЪ§ОнИќаТВйзїгабЯИёЕФвЛжТадБЃжЄЁЃ
AmazonЕФDynamo
DynamoЪЙгУЕФЪЧСэЭтвЛжжЗжВМЪНФЃаЭЁЃDynamoЕФФЃаЭИќМђЕЅЃЌЫќНЋЪ§ОнАДkeyНјааhashДцДЂЁЃЦфЪ§ОнЗжЦЌФЃаЭгаБШНЯЧПЕФШнджадЃЌвђДЫЫќЪЕЯжЕФЪЧЯрЖдЫЩЩЂЕФШѕвЛжТадЃКзюжевЛжТадЁЃ
HBaseЬиеї
HBaseЪЧGoogle BigtableЕФПЊдДЪЕЯжЃЌРрЫЦGoogle
BigtableРћгУGFSзїЮЊЦфЮФМўДцДЂЯЕЭГЃЌHBaseРћгУHadoop HDFSзїЮЊЦфЮФМўДцДЂЯЕЭГЃЛGoogleдЫааMapReduceРДДІРэBigtableжаЕФКЃСПЪ§ОнЃЌHBaseЭЌбљРћгУHadoop
MapReduceРДДІРэHBaseжаЕФКЃСПЪ§ОнЃЛGoogle BigtableРћгУ ChubbyзїЮЊаЭЌЗўЮёЃЌHBaseРћгУZooKeeperзїЮЊЖдгІЁЃ
жївЊЬиЕу
СаЕФПЩвдЖЏЬЌдіМгЃЌВЂЧвСаЮЊПеОЭВЛДцДЂЪ§ОнЃЌНкЪЁДцДЂПеМфЁЃ
HBaseздЖЏЧаЗжЪ§ОнЃЌЪЙЕУЪ§ОнДцДЂздЖЏОпгаЫЎЦНscalabilityЁЃ
HBaseПЩвдЬсЙЉИпВЂЗЂЖСаДВйзїЕФжЇГжЃЌЗжВМЪНМмЙЙЃЌЖСаДЫјЕШД§ЕФИХТЪДѓДѓНЕЕЭЁЃ
ВЛФмжЇГжЬѕМўВщбЏЃЌжЛжЇГжАДееRowkeyРДВщбЏЁЃ
днЪБВЛФмжЇГжMaster serverЕФЙЪеЯЧаЛЛЃЌЕБMasterхДЛњКѓЃЌећИіДцДЂЯЕЭГОЭЛсЙвЕєЁЃ
HBaseЕзВуМмЙЙ
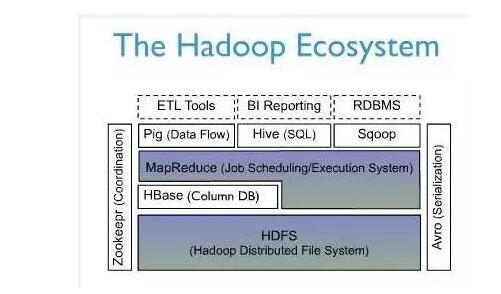
HBaseЪЧвЛИіСаЪНДцДЂЕФЪ§ОнПтЯЕЭГЃЌИњЫљгаЕФЪ§ОнПтЯЕЭГвЛбљЃЌЪ§ОнПтЪЧвРРЕЮФМўЯЕЭГЕФЃЌдкДЋЭГЪ§ОнПтРяУцЮвУЧОГЃЬсЕНДцДЂв§ЧцЃЌР§ШчMySQLгаMyISAM/InnoDBЃЌOracle/SqlServerВЛПЊдДЃЌУЛгаФЧУДЖрбЁдёЃЌЕЋЖМЛсгаздМКЕФДцДЂв§ЧцЃЌЫЕЕУЭЈЫзвЛЕуОЭЪЧащФтЮФМўЯЕЭГЃЌHBaseЕФЮФМўЯЕЭГЪЧHDFSЃЌвЛжжЗжВМЪНЮФМўЯЕЭГЃЌЫљвдHBaseЬьШЛОпБИЗжВМЪНЕФЬиадЁЃЭЌЪБHadoop
MapReduceЮЊHBaseЬсЙЉСЫИпадФмЕФМЦЫуФмСІЃЌZookeeperЮЊHBaseЬсЙЉСЫЮШЖЈЗўЮёКЭfailoverЛњжЦЁЃ
HBaseЩшМЦвЊЕу
1ЁЂТпМЪ§ОнФЃаЭ
1.Table
2.Region
3.ColumnFamily
4.Row
5.Column
6.Value
7.TimeStamp
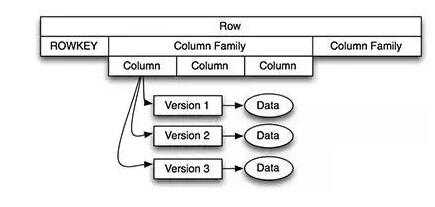
ФувВПЩвдАбHBaseПДГЩвЛИіЖрЮЌЖШЕФMapФЃаЭШЅРэНтЫќЕФЪ§ОнФЃаЭЁЃе§ШчЯТЭМЁЃ
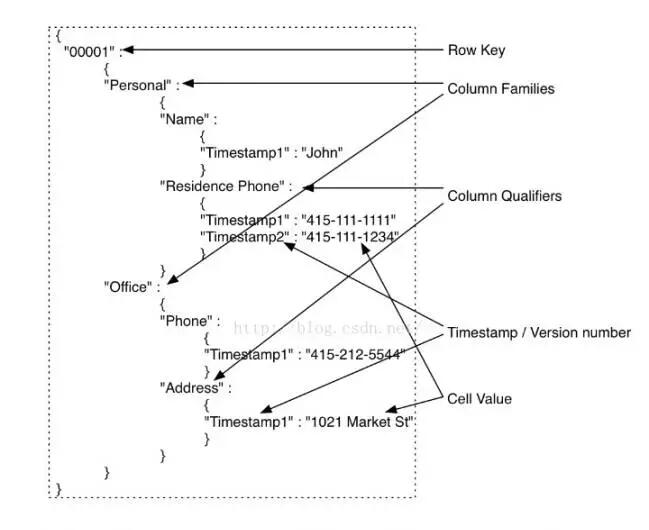

2ЁЂHBaseЕФЬхЯЕзщГЩ
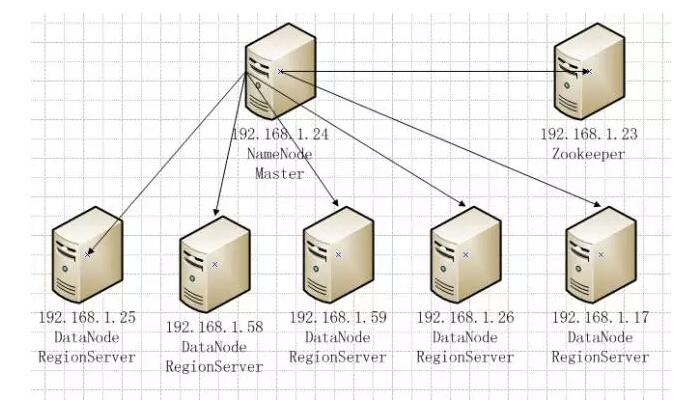
NameNodeДцДЂDataNodeаХЯЂЃЌZooKeeperИКд№ЕїЖШЁЃ
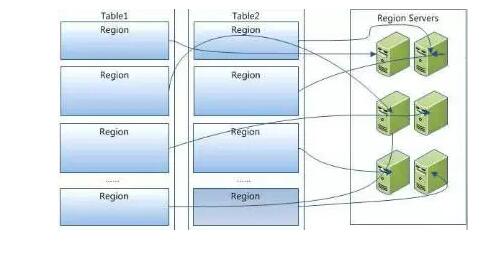
вЛИіRegionжЛЛсДцдквЛЬЈRegionServerЩЯЃЌвЛЬЈRegionServerЩЯПЩвдАќКЌЖрИіRegionЁЃ
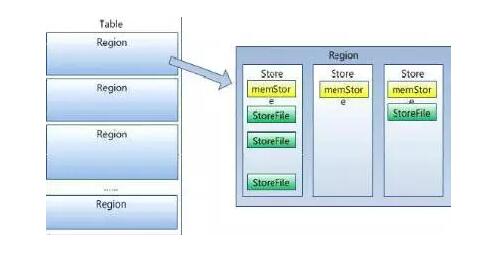
вЛИіТпМЕФБэАќКЌЖрИіRegionЃЌЗжВМдкИїИіRegionServerЩЯЃЌЖдгІгУГЬађРДЫЕжЛгавЛИіДѓБэВЛгУЙмЗжБэЗжПтЁЃ
RegionЕФЖЈЮЛ
-ROOT- .META
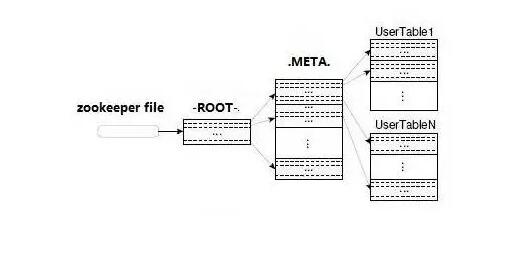
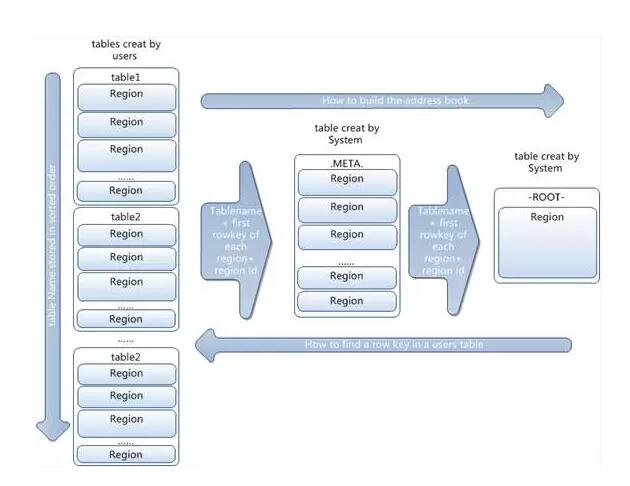
ДцДЂЗжВМ
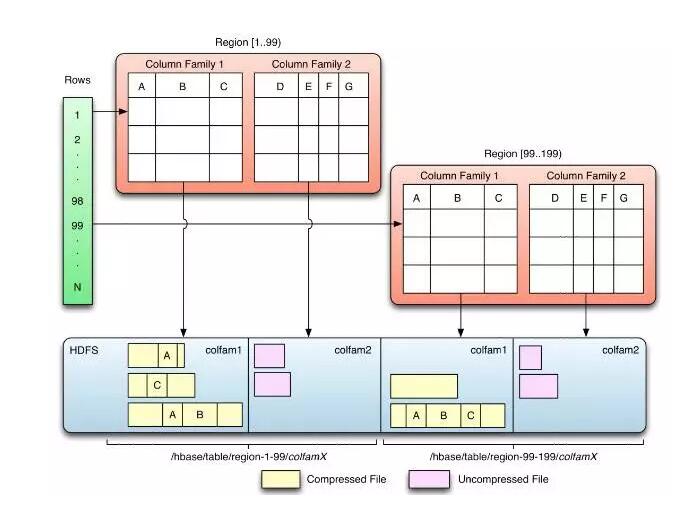
УПвЛааАќКЌNИіСаЃЌвдСаЕФаЮЪНЗжВМдкВЛЭЌRegionРяУцЁЃ
3ЁЂHBaseИїЖдЯѓжАд№
Client
HBaseЕФЗУЮЪНгПкЃЌЮЌЛЄcacheМгПьHBaseЕФЗУЮЪЁЃ
Zookeeper
МрПиMasterЃЌБЃжЄжЛгавЛИіMasterЃЛ
ДцДЂRegionЕФШыПкЕижЗЃЛ
МрПиRegionServerЩЯЯТЯпЃЌВЂИцжЊMasterЃЛ
ДцДЂHbase shcemaКЭTableЕФдЊЪ§ОнЁЃ
Master
ЗжХфRegionЕНRegionServerЃЛ
RegionSeverЕФИКдиОљКтЃЛ
ЗЂЯжЪЇаЇЕФRegionServerВЂжиаТЗжХфЦфЩЯЕФRegion
ЙмРэгУЛЇЖдTableЕФдіЩОИФВщВйзїЁЃ
RegionServer
ЮЌЛЄRegionЃЌДІРэЖдетаЉRegionЕФIOЃЛ
Split&CompactЁЃ
4ЁЂгІгУЗНЪН
HBaseЪЧШ§ЮЌгаађДцДЂЕФЃЌЭЈЙ§RowKeyЃЈааМќЃЉЃЌcolumn
keyЃЈcolumn familyКЭqualifierЃЉКЭTimeStampЃЈЪБМфДСЃЉетИіШ§ИіЮЌЖШПЩвдЖдHBaseжаЕФЪ§ОнНјааПьЫйЖЈЮЛЁЃ
RowKeyЪЧHBaseБэНсЙЙЩшМЦжаКмживЊЕФвЛЛЗ ЃЌHBaseжаRowKeyПЩвдЮЈвЛБъЪЖвЛааМЧТМЃЌдкHBaseВщбЏЕФЪБКђЃЌгавдЯТ2жжЗНЪНЃК
АДжИЖЈRowKeyЛёШЁЮЈвЛвЛЬѕМЧТМЃЌgetЗНЗЈ
ЃЈorg.apache.hadoop.hbase.client.GetЃЉ
АДжИЖЈЕФЬѕМўЛёШЁвЛХњМЧТМЃЌscanЗНЗЈ
ЃЈorg.apache.hadoop.hbase.client.ScanЃЉ
ЕквЛжжРрЫЦkey-valueВщевЃЌЕкЖўжжПЩвдЪЕЯжМђЕЅЕФЬѕМўВщбЏЙІФмЁЃ
Q&A
Q1ЃКHBaseЪЧВЛЪЧУЛгаДЋЭГБэЕФИХФюСЫЁЃИаОѕЖМЯёЪЧМќжЕДцДЂЁЃ
A1ЃКШчЙћДцДЂНЧЖШПДЪЧКИЧСЫЕФЃЌЕЋЪЧШЅЕєСЫЙиЯЕЁЃ
Q2ЃКHBase гыMongoDBЕФЪЙгУГЁОАЕФЧјБ№РЯЪІФмЗёМђЕЅНщЩмвЛЯТЃП
A2ЃКHBaseЪЪКЯзіЪ§ОнЗжЮіЃЌMongoDBдкЯпЗўЮёадФмКмКУЃЌгШЦфЪЧЖСЃЌHBaseвЊНсКЯMapReduceЃЌЛЙгаОЭЪЧMongoDBЪЪКЯWebЗўЮёЃЌР§ШчPHPЁЃ
|









