дкБОЦЊЮФеТЃЌзїепНЋЬжТлЛњЦїбЇЯАИХФювдМАШчКЮЪЙгУSpark MLlibРДНјаадЄВтЗжЮіЁЃКѓУцНЋЛсЪЙгУвЛИіР§згеЙЪОSpark MLlibдкЛњЦїбЇЯАСьгђЕФЧПКЗЁЃ
1.в§бд
SparkЛњЦїбЇЯАAPIАќКЌСНИіpackageЃКspark.mllib КЭspark.mlЁЃ
spark.mllib АќКЌЛљгкЕЏадЪ§ОнМЏЃЈRDDЃЉЕФдЪМSparkЛњЦїбЇЯАAPIЁЃЫќЬсЙЉЕФЛњЦїбЇЯАММЪѕгаЃКЯрЙиадЁЂЗжРрКЭЛиЙщЁЂаЭЌЙ§ТЫЁЂОлРрКЭЪ§ОнНЕЮЌЁЃ
spark.mlЬсЙЉНЈСЂдкDataFrameЕФЛњЦїбЇЯАAPIЃЌDataFrameЪЧSpark SQLЕФКЫаФВПЗжЁЃетИіАќЬсЙЉПЊЗЂКЭЙмРэЛњЦїбЇЯАЙмЕРЕФЙІФмЃЌПЩвдгУРДНјааЬиеїЬсШЁЁЂзЊЛЛЁЂбЁдёЦїКЭЛњЦїбЇЯАЫуЗЈЃЌБШШчЗжРрКЭЛиЙщКЭОлРрЁЃ
БОЦЊЮФеТОлНЙдкSpark MLlibЩЯЃЌВЂЬжТлИїИіЛњЦїбЇЯАЫуЗЈЁЃ
2.ЛњЦїбЇЯАКЭЪ§ОнПЦбЇ
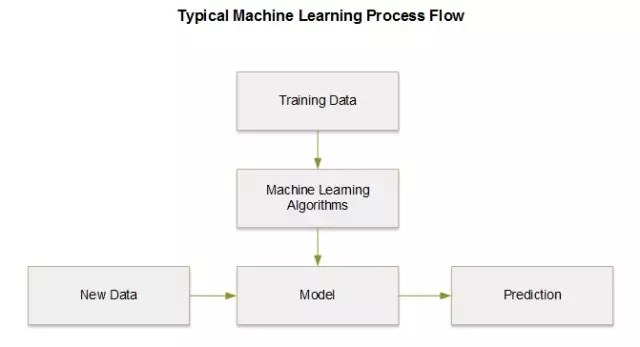
ЛњЦїбЇЯАЪЧДгвбОДцдкЕФЪ§ОнНјаабЇЯАРДЖдНЋРДНјааЪ§ОндЄВтЃЌЫќЪЧЛљгкЪфШыЪ§ОнМЏДДНЈФЃаЭзіЪ§ОнЧ§ЖЏОіВпЁЃ
Ъ§ОнПЦбЇЪЧДгКЃРяЪ§ОнМЏЃЈНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЃЉжаГщШЁжЊЪЖЃЌЮЊЩЬвЕЭХЖгЬсЙЉЪ§ОнЖДВьвдМАгАЯьЩЬвЕОіВпКЭТЗЯпЭМЁЃЪ§ОнПЦбЇМвЕФЕиЮЛБШвдЧАгУДЋЭГЪ§жЕЗНЗЈНтОіЮЪЬтЕФШЫвЊживЊЁЃ
вдЯТЪЧМИРрЛњЦїбЇЯАФЃаЭЃК
МрЖНбЇЯАФЃаЭ
ЗЧМрЖНбЇЯАФЃаЭ
АыМрЖНбЇЯАФЃаЭ
діЧПбЇЯАФЃаЭ
ЯТУцМђЕЅЕФСЫНтЯТИїЛњЦїбЇЯАФЃаЭЃЌВЂНјааБШНЯЃК
МрЖНбЇЯАФЃаЭЃКМрЖНбЇЯАФЃаЭЖдвбБъМЧЕФбЕСЗЪ§ОнМЏбЕСЗГіНсЙћЃЌШЛКѓЖдЮДБъМЧЕФЪ§ОнМЏНјаадЄВтЃЛ
МрЖНбЇЯАгжАќКЌСНИізгФЃаЭЃКЛиЙщФЃаЭКЭЗжРрФЃаЭЁЃ
ЗЧМрЖНбЇЯАФЃаЭЃКЗЧМрЖНбЇЯАФЃаЭЪЧгУРДДгдЪМЪ§ОнЃЈЮобЕСЗЪ§ОнЃЉжаевЕНвўВиЕФФЃЪНЛђепЙиЯЕЃЌвђЖјЗЧМрЖНбЇЯАФЃаЭЪЧЛљгкЮДБъМЧЪ§ОнМЏЕФЃЛ
АыМрЖНбЇЯАФЃаЭЃКАыМрЖНбЇЯАФЃаЭгУдкМрЖНКЭЗЧМрЖНЛњЦїбЇЯАжазідЄВтЗжЮіЃЌЦфМШгаБъМЧЪ§ОнгжгаЮДБъМЧЪ§ОнЁЃЕфаЭЕФГЁОАЪЧЛьКЯЩйСПБъМЧЪ§ОнКЭДѓСПЮДБъМЧЪ§ОнЁЃАыМрЖНбЇЯАвЛАуЪЙгУЗжРрКЭЛиЙщЕФЛњЦїбЇЯАЗНЗЈЃЛ
діЧПбЇЯАФЃаЭЃКдіЧПбЇЯАФЃаЭЭЈЙ§ВЛЭЌЕФааЮЊРДбАевФПБъЛиБЈКЏЪ§зюДѓЛЏЁЃ
ЯТУцИјИїИіЛњЦїбЇЯАФЃаЭОйИіСазгЃК
МрЖНбЇЯАЃКвьГЃМрВтЃЛ
ЗЧМрЖНбЇЯАЃКЩчНЛЭјТчЃЌгябддЄВтЃЛ
АыМрЖНбЇЯАЃКЭМЯёЗжРрЁЂгявєЪЖБ№ЃЛ
діЧПбЇЯАЃКШЫЙЄжЧФмЃЈAIЃЉЁЃ
3.ЛњЦїбЇЯАЯюФПВНжш
ПЊЗЂЛњЦїбЇЯАЯюФПЪБЃЌЪ§ОндЄДІРэЁЂЧхЯДКЭЗжЮіЕФЙЄзїЪЧЗЧГЃживЊЕФЃЌгыНтОівЕЮёЮЪЬтЕФЪЕМЪЕФбЇЯАФЃаЭКЭЫуЗЈвЛбљживЊЁЃ
ЕфаЭЕФЛњЦїбЇЯАНтОіЗНАИЕФвЛАуВНжшЃК
ЬиеїЙЄГЬ
ФЃаЭбЕСЗ
ФЃаЭЦРЙР
ЭМ1
дЪМЪ§ОнШчЙћВЛФмЧхЯДЛђепдЄДІРэЃЌдђЛсдьГЩзюжеЕФНсЙћВЛзМШЗЛђепВЛПЩгУЃЌЩѕжСЖЊЪЇживЊЕФЯИНкЁЃ
бЕСЗЪ§ОнЕФжЪСПЖдзюжеЕФдЄВтНсЙћЗЧГЃживЊЃЌШчЙћбЕСЗЪ§ОнВЛЙЛЫцЛњЃЌЕУГіЕФНсЙћФЃаЭВЛОЋШЗЃЛШчЙћЪ§ОнСПЬЋаЁЃЌЛњЦїбЇЯАГіЕФФЃаЭвВВЛзМШЗЁЃ
ЪЙгУАИР§ЃК
вЕЮёЪЙгУАИР§ЗжВМгкИїИіСьгђЃЌАќРЈИіадЛЏЭЦМів§ЧцЃЈЪГЦЗЭЦМів§ЧцЃЉЃЌЪ§ОндЄВтЗжЮіЃЈЙЩМлдЄВтЛђепдЄВтКНАрбгГйЃЉЃЌЙуИцЃЌвьГЃМрВтЃЌЭМЯёКЭЪгЦЕФЃаЭЪЖБ№ЃЌвдМАЦфЫћИїРрШЫЙЄжЧФмЁЃ
НгзХРДПДСНИіБШНЯСїааЕФЛњЦїбЇЯАгІгУЃКИіадЛЏЭЦМів§ЧцКЭвьГЃМрВтЁЃ
4.ЛњЦїбЇЯАгІгУ
4.1ЁЂЭЦМів§Чц
ИіадЛЏЭЦМів§ЧцЪЙгУЩЬЦЗЪєадКЭгУЛЇааЮЊРДНјаадЄВтЁЃЭЦМів§ЧцвЛАугаСНжжЫуЗЈЪЕЯжЃКЛљгкФкШнЙ§ТЫКЭаЭЌЙ§ТЫЁЃ
аЕїЙ§ТЫЕФНтОіЗНАИБШЦфЫћЫуЗЈвЊКУЃЌSpark MLlibЪЕЯжСЫALSаЭЌЙ§ТЫЫуЗЈЁЃSpark MLlibЕФаЭЌЙ§ТЫгаСНжжаЮЪНЃКЯдЪНЗДРЁКЭвўЪдЗДРЁЁЃЯдЪНЗДРЁЪЧЛљгкгУЛЇЙКТђЕФЩЬЦЗЃЈБШШчЃЌЕчгАЃЉЃЌЯдЪНЗДРЁЫфКУЃЌЕЋКмЖрЧщПіЯТЛсГіЯжЪ§ОнЧуаБЃЛвўЪдЗДРЁЪЧЛљгкгУЛЇЕФааЮЊЪ§ОнЃЌБШШчЃЌфЏРРЁЂЕуЛїЁЂЯВЛЖЕШааЮЊЁЃвўЪдЗДРЁЯждкДѓЙцФЃгІгУдкЙЄвЕЩЯНјааЪ§ОндЄВтЗжЮіЃЌвђЮЊЦфКмШнвзЪеМЏИїРрЪ§ОнЁЃ
СэЭтгаЛљгкФЃаЭЕФЗНЗЈЪЕЯжЭЦМів§ЧцЃЌетРяднЧвТдЙ§ЁЃ
4.2вьГЃМрВт
вьГЃМрВтЪЧЛњЦїбЇЯАжаСэЭтвЛИігІгУЗЧГЃЙуЗКЕФММЪѕЃЌвђЮЊЦфПЩвдПьЫйКЭзМШЗЕиНтОіН№ШкаавЕЕФМЌЪжЮЪЬтЁЃН№ШкЗўЮёвЕашвЊдкМИАйКСУыФкХаЖЯГівЛБЪдкЯпНЛвзЪЧЗёЗЧЗЈЁЃ
ЩёОЭјТчММЪѕБЛгУРДНјааЯњЪлЕуЕФвьГЃМрВтЁЃБШШчЯёPayPalЕШЙЋЫОЪЙгУВЛЭЌЕФЛњЦїбЇЯАЫуЗЈЃЈБШШчЃЌЯпадЛиЙщЃЌЩёОЭјТчКЭЩюЖШбЇЯАЃЉРДНјааЗчЯеЙмРэЁЃ
Spark MLlibПтЬсЙЉИјСЫМИИіЪЕЯжЕФЫуЗЈЃЌБШШчЃЌЯпадSVMЁЂТпМЛиЙщЁЂОіВпЪїКЭБДвЖЫЙЫуЗЈЁЃСэЭтЃЌвЛаЉМЏГЩФЃаЭЃЌБШШчЫцЛњЩСжКЭgradient-boostingЪїЁЃ
ФЧУДЯждкПЊЪМЮвУЧЕФЪЙгУApache SparkПђМмНјааЛњЦїбЇЯАжЎТУЁЃ
5.Spark Mlib
Spark MLlibЪЕЯжЕФЛњЦїбЇЯАПтЪЙЕУЛњЦїбЇЯАФЃаЭПЩРЉеЙКЭвзЪЙгУЃЌАќРЈЗжРрЫуЗЈЁЂЛиЙщЫуЗЈЁЂОлРрЫуЗЈЁЂаЭЌЙ§ТЫЫуЗЈЁЂНЕЮЌЫуЗЈЃЌВЂЬсЙЉСЫЯргІЕФAPIЁЃГ§СЫетаЉЫуЗЈЭтЃЌSpark MLlibЛЙЬсЙЉСЫИїжжЪ§ОнДІРэЙІФмКЭЪ§ОнЗжЮіЙЄОпЮЊДѓМвЪЙгУЃК
ЭЈЙ§FP-growthЫуЗЈНјааЦЕЗБЯюМЏЭкОђКЭЙиСЊЗжЮіЃЛ
ЭЈЙ§PrefixSpanЫуЗЈНјааађСаФЃЪНЭкОђЃЛ
ЬсЙЉИХРЈадЭГМЦКЭМйЩшМьбщЃЛ
ЬсЙЉЬиеїзЊЛЛЃЛ
ЛњЦїбЇЯАФЃаЭЦРЙРКЭГЌВЮЪ§ЕїгХЁЃ
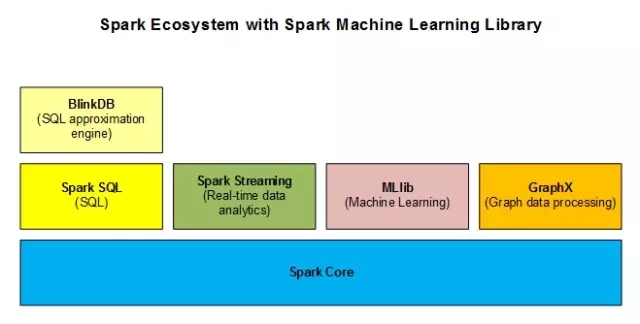
ЭМ2 еЙЪОSparkЩњЬЌ
Spark MLlib APIжЇГжScalaЃЌJavaКЭPythonБрГЬЁЃ
6.Spark MLlibгІгУЪЕМљ
ЪЙгУSpark MLlibЪЕЯжЭЦМів§ЧцЁЃЭЦМів§ЧцзюМбЪЕМљЪЧЛљгквбжЊгУЛЇЕФЩЬЦЗааЮЊЖјШЅдЄВтгУЛЇПЩФмИааЫШЄЕФЮДжЊЩЬЦЗЁЃЭЦМів§ЧцЛљгквбжЊЪ§ОнЃЈвВМДЃЌбЕСЗЪ§ОнЃЉбЕСЗГідЄВтФЃаЭЁЃШЛКѓРћгУбЕСЗКУЕФдЄВтФЃаЭРДдЄВтЁЃ
зюМбЕчгАЭЦМів§ЧцЕФЪЕЯжгаЯТУцМИВНЃК
МгдиЕчгАЪ§ОнЃЛ
МгдиФужИЖЈЕФЦРМлЪ§ОнЃЛ
МгдиЩчЧјЬсЙЉЕФЦРМлЪ§ОнЃЛ
НЋЦРМлЪ§ОнjoinГЩЕЅИіRDDЃЛ
ЪЙгУALSЫуЗЈбЕСЗФЃаЭЃЛ
ШЗШЯжИЖЈгУЛЇЃЈuserId ЃН 1ЃЉЮДЦРМлЕФЕчгАЃЛ
дЄВтЮДБЛгУЛЇЦРМлЕФЕчгАЕФЦРМлЃЛ
ЛёШЁTop NЕФЭЦМіЃЈетРяNЃН 5ЃЉЃЛ
дкжеЖЫЯдЪОЭЦМіНсЙћЁЃ
ШчЙћФуЯыЖдЪфГіЕФЪ§ОнзіНјвЛВНЗжЮіЃЌФуПЩвдАбдЄВтЕФНсЙћДцДЂЕНCassandraЛђепMongoDBЕШЪ§ОнПтЁЃ
7.ЪЙгУЕНЕФММЪѕ
етРяВЩгУJavaПЊЗЂSpark MLlibГЬађЃЌВЂдкstandЃaloneФЃаЭЯТжДааЁЃЪЙгУЕНЕФMLlib JavaРрЃКorg.apache.spark.mllib.recommendationЁЃ
ALS
MatrixFactorizationModel
Rating
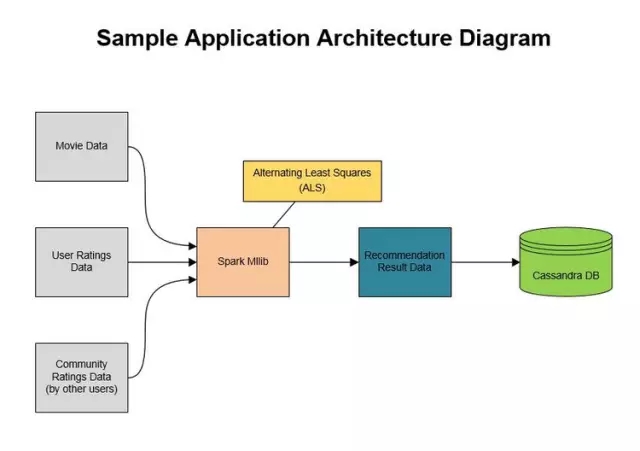
ЭМ3 SparkЛњЦїбЇЯАЕФР§згГЬађМмЙЙ
ГЬађжДааЃК
ПЊЗЂКУЕФГЬађНјааДђАќЃЌЩшжУЛЗОГБфСПЃКJDK (JAVA_HOME), Maven (MAVEN_HOME)КЭSpark (SPARK_HOME)ЁЃ
дкWindowsЛЗОГжаЃК
set JAVA_HOME=[JDK_INSTALL_DIRECTORY]
set PATH=%PATH%;%JAVA_HOME%\bin
set MAVEN_HOME=[MAVEN_INSTALL_DIRECTORY]
set PATH=%PATH%;%MAVEN_HOME%\bin
set SPARK_HOME=[SPARK_INSTALL_DIRECTORY]
set PATH=%PATH%;%SPARK_HOME%\bin
cd c:\dev\projects\spark-mllib-sample-app
mvn clean install
mvn eclipse:clean eclipse:eclipse
дкLinuxЛђепMACЯЕЭГжаЃЛ
export JAVA_HOME=[JDK_INSTALL_DIRECTORY]
export PATH=$PATH:$JAVA_HOME/bin
export MAVEN_HOME=[MAVEN_INSTALL_DIRECTORY]
export PATH=$PATH:$MAVEN_HOME/bin
export SPARK_HOME=[SPARK_INSTALL_DIRECTORY]
export PATH=$PATH:$SPARK_HOME/bin
cd /Users/USER_NAME/spark-mllib-sample-app
mvn clean install
mvn eclipse:clean eclipse:eclipse
дЫааSparkГЬађЃЌУќСюШчЯТЃК
%SPARK_HOME%\bin\spark-submit --class "org.apache.spark.examples.mllib.JavaRecommendationExample" --master local[*] target\spark-mllib-sample-1.0.jar
дкWindowsЛЗОГЯТЃК
%SPARK_HOME%\bin\spark-submit --class "org.apache.spark.examples.mllib.JavaRecommendationExample" --master local[*] target\spark-mllib-sample-1.0.jar
дкLinuxЛђепMACЛЗОГЯТЃК
$SPARK_HOME/bin/spark-submit --class "org.apache.spark.examples.mllib.JavaRecommendationExample" --master local[*] target/spark-mllib-sample-1.0.jar
Spark MLlibгІгУМрПи
ЪЙгУSparkЕФwebПижЦЬЈПЩвдНјааМрПиГЬађдЫаазДЬЌЁЃетРяжЛИјГіГЬађдЫааЕФгаЯђЮоЛЗЭМЃЈDAGЃЉЃК
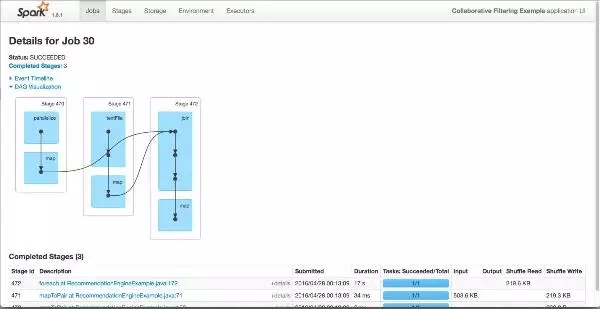
ЭМ4 DAGЕФПЩЪгЛЏ
8.НсТл
Spark MLlibЪЧSparkЪЕЯжЕФЛњЦїбЇЯАПтжаЕФвЛжжЃЌОГЃгУРДзівЕЮёЪ§ОнЕФдЄВтЗжЮіЃЌБШШчИіадЛЏЭЦМів§ЧцКЭвьГЃМрВтЯЕЭГ |









