| ММЪѕЭХЖгдкЙЙНЈШэМўЪБУцСйЕФРЇФбзмЪЧЯрЫЦЕФЃКЕНзюКѓЫћУЧзмЪЧВЛЕУВЛжиаТЩшМЦЫћУЧЫљЪЙгУЕФЪ§ОнФЃаЭЃЌвдДЫРДжЇГжИќИЩОЛЕФГщЯѓКЭИќИДдгЕФЙІФмЁЃдкЩњВњЛЗОГРяЃЌетПЩФмОЭвЊвтЮЖзХЧЈвЦМИАйЭђЬѕЛюдОЕФЪ§ОнЃЌвдМАжиЙЙЪ§вдЧЇааМЦЕФДњТыЁЃ StripeЕФгУЛЇЯЃЭћЮвУЧЬсЙЉЕФAPIвЊОпБИПЩгУадКЭвЛжТадЁЃетвтЮЖзХдкзіЧЈвЦЪБЃЌЮвУЧБиаыЗЧГЃаЁаФЃКДцДЂдкЮвУЧЯЕЭГжаЕФЪ§ОнвЊгаЗЧГЃзМШЗЕФжЕЃЌЖјЧвStripeЕФЗўЮёБиаыЪБПЬБЃжЄПЩгУЁЃ
дкетЦЊЮФеТжаЃЌЮвУЧНЋЗжЯэЮвУЧЪЧШчКЮАВШЋЕиЭъГЩСЫвЛДЮЩцМАЩЯвкЪ§ОнСПЕФДѓЧЈвЦОРњЁЃ
ЮЊЪВУДЧЈвЦзмЪЧетУДФбЃП
ЙцФЃ
StripeгаЩЯвкЙцФЃЕФЖЉдФЪ§ОнЁЃЖдгкЮвУЧЕФЩњВњЪ§ОнПтРДЫЕЃЌзівЛДЮгыЫљгаетаЉЪ§ОнЖМЯрЙиЕФДѓаЭЧЈвЦОЭвтЮЖзХЗЧГЃЗЧГЃЖрЕФЙЄзїЁЃ ЯыЯѓвЛЯТЃЌМйШчвдвЛжжЫГађЕФЗНЪНЃЌУПЧЈвЦвЛЬѕЖЉдФЪ§ОнвЊвЛУыжгЃЌФЧвЊЭъГЩЩЯвкЬѕЪ§ОнЕФЧЈвЦОЭвЊКФЪБГЌЙ§Ш§ФъЁЃ
дкЯпЪБМф
StripeЭјеОЩЯЕФЗўЮёЪЧвЛжБдкдЫааЕФЁЃЮвУЧЕФУПвЛДЮЩ§МЖВйзїЖМЪЧдкЯпНјааЕФЃЌЖјВЛФмдкФГИіМЦЛЎКУЕФЮЌЛЄДАПкФкВйзїЁЃвђЮЊдкЧЈвЦЙ§ГЬжаЮвУЧВЛФмМђЕЅЕижажЙЖЉдФЗўЮёЃЌЫљвдЮвУЧБиаы100%ЕидкЫљгаЗўЮёЖМдкЯпЕФЧщПіЯТЭъГЩЧЈвЦВйзїЁЃ
Ъ§ОнзМШЗ
ЮвУЧЕФДњТыПтжааэЖрЕиЗНЖМгУЕНСЫЖЉдФЗўЮёЕФЪ§ОнБэЁЃШчЙћЮвУЧЯывЊвЛДЮИФЖЏЖЉдФЗўЮёЕФМИЧЇааДњТыЕФЛАЃЌФЧОЭПЩвдПЯЖЈвЛЖЈЛсгаФГаЉЬиЪтГЁОАБЛвХТЉЕєЁЃЮвУЧБиаыШЗБЃУПИіЗўЮёЖМФмГжајЕиВйзїзМШЗЕФЪ§ОнЁЃ
дкЯпЧЈвЦЕФФЃЪН
АбЪ§вдАйЭђМЦЕФЪ§ОнДгвЛеХЪ§ОнПтБэЧЈвЦЕНСэвЛеХжаЃЌетКмРЇФбЃЌЕЋЖдгкаэЖрЙЋЫОРДЫЕетгжЪЧВЛЕУВЛзіЕФЪТЁЃ дкзіРрЫЦЕФДѓаЭЧЈвЦЪБЃЌгажжДѓМвЗЧГЃШнвзНгЪмЕФЫФВНЫЋаДФЃЪНЁЃетРяЪЧОпЬхЕФВНжшЁЃ
1.ЯђОЩБэКЭаТБэЫЋжиаДШыЃЌвдБЃГжЫќУЧжЎМфЪ§ОнЕФЭЌВНЃЛ
2.АбДњТыПтжаЫљгаЖСЪ§ОнЕФВйзїЖМжИЯђаТБэЃЛ
3.АбДњТыПтжаЫљгааДЪ§ОнЕФВйзїЖМжИЯђаТБэЃЛ
4.АбвРРЕОЩЪ§ОнФЃаЭЕФОЩЪ§ОнЩОЕєЁЃ
ЖЉдФЃКЮвУЧЕФЧЈвЦР§зг
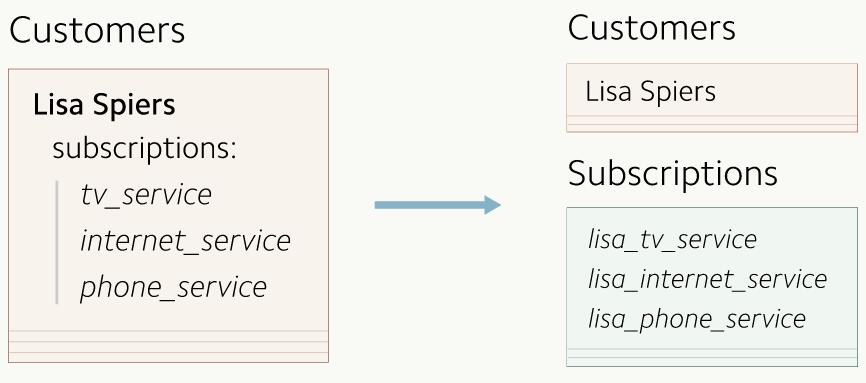
ЪзЯШвЊНВНВЁАЖЉдФЁБЪЧЪВУДЃЌвдМАЮЊЪВУДЮвУЧвЊзіЧЈвЦЁЃ StripeЕФЖЉдФЙІФмАяжњЯёDigitalOceanКЭSquarespaceетбљЕФПЭЛЇЙЙНЈКЭЙмРэЫћУЧгУЛЇЕФМЦЗбеЫЕЅЁЃдкЙ§ШЅЕФМИФъРяЃЌЮвУЧГжајВЛЖЯЕидіМгСЫаэЖрЙІФмЃЌРДжЇГжЫћУЧдНРДдНИДдгЕФМЦЗбФЃаЭЃЌБШШчЖржиЖЉдФЁЂЪдгУЁЂгХЛнШЏКЭЗЂЦБЕШЁЃ дкзюПЊЪМЪБЃЌУПИіCustomerЖдЯѓзюЖржЛЛсгавЛЬѕЖЉдФЪ§ОнЁЃЫљвдЮвУЧЕФПЭЛЇЪ§ОнЖМБЃДцГЩСЫЕЅЬѕМЧТМЁЃвђЮЊгУЛЇКЭЖЉдФжЎМфЕФгГЩфЙиЯЕЗЧГЃжБНгЃЌЫљвдЖЉдФаХЯЂОЭКЭгУЛЇЪ§ОнБЃДцдкСЫвЛЦ№ЁЃ
class Customer Subscription subscription
end |
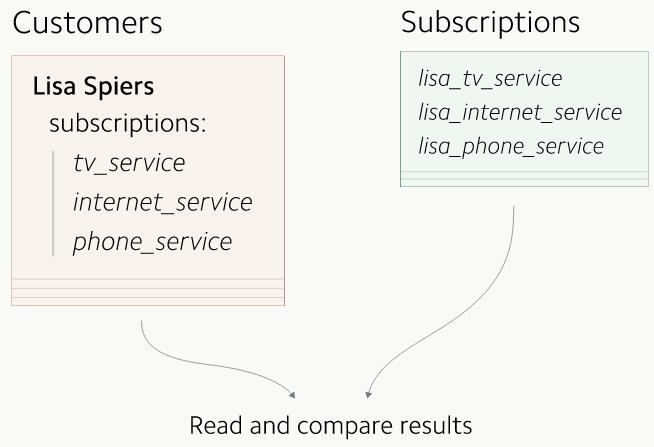
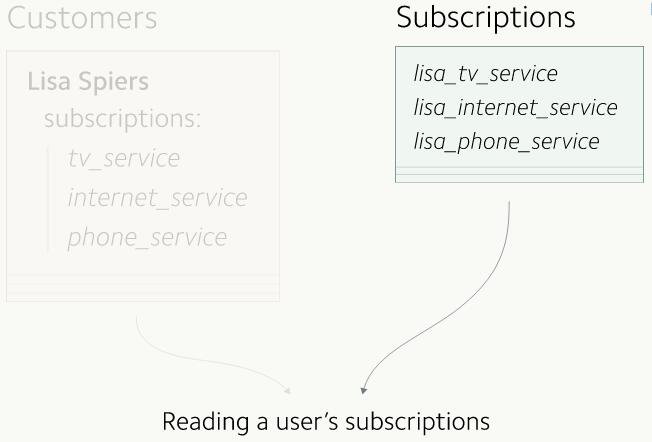
КѓРДЃЌЮвУЧЗЂЯжгааЉПЭЛЇЯЃЭћЫћУЧДДНЈЕФCustomerЖдЯѓПЩвдЖдгІЖрЬѕЖЉдФЪ§ОнЁЃгкЪЧЮвУЧОіЖЈАбЗўЮёгкЕЅДЮЖЉдФЕФЕЅЬѕЖЉдФЪ§ОнЩ§МЖвЛЯТЃЌЛЛГЩвЛИіЖЉдФЪ§зщЃЌвдДЫРДБЃДцЖрЬѕгааЇЕФЖЉдФЪ§ОнЁЃ
class Customer array: Subscription subscriptions
end |
дкМЬајЬэМгаТЙІФмЕФЪБКђЃЌетбљЕФЪ§ОнФЃаЭОЭГіЮЪЬтСЫЁЃУПвЛДЮЖдгУЛЇЕФЖЉдФаХЯЂЕФИФЖЏЖМвтЮЖзХвЊИќаТећЬѕгУЛЇМЧТМЃЌвдМАВщбЏгУЛЇЪ§ОнЕФгыЖЉдФЯрЙиЕФМьЫїгяОфЁЃгкЪЧЮвУЧОіЖЈАбетаЉЖЉдФаХЯЂЕЅЖРБЃДцЦ№РДЁЃ
ЮвУЧжиаТЩшМЦЕФЪ§ОнФЃаЭАбЖЉдФаХЯЂвЦЕНСЫЫќУЧздМКЕФБэРяЁЃ ИДЯАвЛЯТЃЌЮвУЧЕФЫФВНЧЈвЦСїГЬЮЊЃК
1.ЯђОЩБэКЭаТБэЫЋжиаДШыЃЌвдБЃГжЫќУЧжЎМфЪ§ОнЕФЭЌВНЃЛ
2.АбДњТыПтжаЫљгаЖСЪ§ОнЕФВйзїЖМжИЯђаТБэЃЛ
3.АбДњТыПтжаЫљгааДЪ§ОнЕФВйзїЖМжИЯђаТБэЃЛ
4.АбвРРЕОЩЪ§ОнФЃаЭЕФОЩЪ§ОнЩОЕєЁЃ
НгЯТРДЮвУЧПДПДетРэТлЩЯЕФЫФИіНзЖЮдкЮвУЧЕФЪЕМЪЯюФПжаЪЧдѕбљЪЕЪЉЕФЁЃ
ЕквЛВПЗжЃКЫЋжиаДШы
ЮвУЧдкЧЈвЦжЎЧАЯШДДНЈСЫвЛеХаТЕФЪ§ОнБэЁЃЕквЛВНОЭЪЧПЊЦєИДжЦаТаДШыЕФЪ§ОнЃЌетбљЫќОЭПЩвдаДЕНаТОЩСНеХБэРяСЫЁЃШЛКѓЮвУЧдйАбаТЪ§ОнБэжаШБЪЇЕФЪ§ОнТ§Т§ЕиВЙГфЙ§РДЃЌетбљаТОЩСНеХБэРяЕФЪ§ОнОЭЭъШЋвЛжТСЫЁЃ
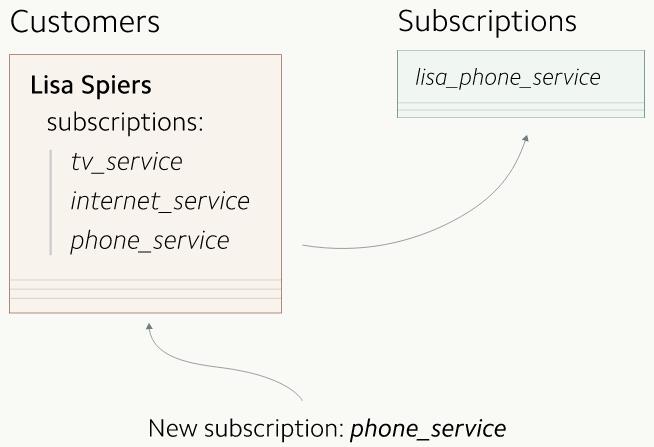
ЫљгааТЕФаДШыЖМвЊИќаТСНеХЪ§ОнБэЁЃ дкЮвУЧЕФАИР§РяЃЌЮвУЧЛсАбЫљгааТЩњГЩЕФЖЉдФаХЯЂЖМЭЌЪБаДШыгУЛЇБэКЭЖЉдФБэЁЃдкПЊЪМЫЋжиаДШыСНеХБэжЎЧАЃЌвЛЖЈвЊШЯецПМТЧвЛЯТетвЛЗнЖюЭтЕФаДШыВйзїИјЩњВњПтЕФадФмДјРДЕФгАЯьЁЃгажжМѕЧсадФмгАЯьЕФЗНЗЈОЭЪЧТ§Т§ЕидіДѓПЊЦєИДжЦЕФЪ§ОнСПЃЌетЭЌЪБвЛЖЈвЊзаЯИЕиЖЂзХИїЯюдЫгЊжИБъЁЃ ЕНСЫетвЛВНЃЌЫљгааТаДШыЕФЪ§ОнОЭЖМЭЌЪБДцдкгкаТОЩСНеХБэРяСЫЃЌЖјБШНЯОЩЕФЪ§ОндђжЛБЃДцдкОЩБэжаЁЃгкЪЧЮвУЧПЩвдвдвЛжжЛКТ§ЕФФЃЪНПЊЪМПНБДвбгаЕФЖЉдФаХЯЂЃКУПЕБгаЪ§ОнБЛИќаТЕФЪБКђЃЌОЭздЖЏЕиАбЫќУЧвВИДжЦЕНаТЕФБэжаЁЃетжжЗНЗЈШУЮвУЧПЩвдПЊЪМдіСПЕиЧЈвЦвбгаЕФЖЉдФЪ§ОнЁЃ
зюжеЃЌЮвУЧЛсАбЫљгавбгаЕФгУЛЇЖЉдФЪ§ОнЖМВЙГфЕНаТЕФЖЉдФБэжаШЅЁЃ
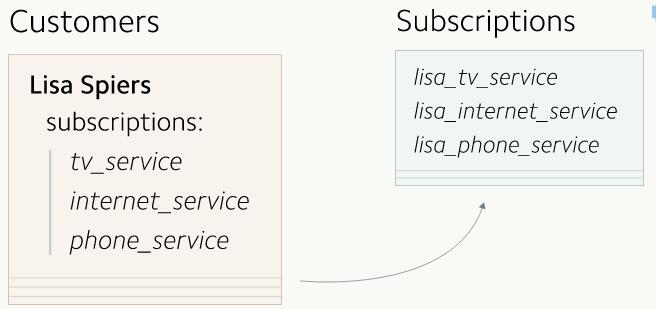
ЮвУЧЛсАбЫљгавбгаЕФгУЛЇЖЉдФЪ§ОнЖМВЙГфЕНаТЕФЖЉдФБэжаШЅЁЃ дкЩњВњЪ§ОнПтРяВЙГфаТБэЪ§ОнЕФВйзїЃЌДњМлзюДѓЕФВПЗжЦфЪЕОЭЪЧвЊевГіЫљгаашвЊЧЈвЦЕФЪ§ОнЖјвбЁЃЭЈЙ§МьЫїЪ§ОнПтРДевГіЫљгаетбљЕФЪ§ОнашвЊМьЫїЩњВњПтКмЖрДЮЃЌетЛсЛЈЗбКмДѓДњМлЁЃавдЫЕФЪЧЃЌЮвУЧПЩвдАбетИіДњМлзЊгУвЛИіРыЯпЕФЗНЪНЭъГЩЃЌвђДЫЖдЩњВњПтОЭКСЮогАЯьСЫЁЃЮвУЧЛсЮЊЪ§ОнЩњГЩПьееЃЌВЂЩЯДЋЕНHadoopМЏШКжаЃЌШЛКѓОЭПЩвдгУMapReduceЕФЗНЗЈРДПьЫйЕивдРыЯпЁЂВЂааЁЂЗжВМЪНЕФЗНЪНДІРэЪ§ОнСЫЁЃ ЮвУЧгУScaldingРДЙмРэЮвУЧЕФMapReduceШЮЮёЁЃScaldingЪЧвЛИігУScalaаДГЩЕФЗЧГЃгагУЕФПтЃЌгУЫќРДаДMapReduceШЮЮёЗЧГЃШнвзЃЈаДвЛИіМђЕЅШЮЮёЕФЛАСЌ10ааДњТыЖМВЛгУЃЉЁЃдкетИіАИР§жаЃЌЮвУЧгУScaldingРДевГіЫљгаЕФЖЉдФЪ§ОнЁЃОпЬхВНжшШчЯТЃК
1.аДИіScaldingШЮЮёРДЩњГЩЫљгаашвЊЧЈвЦЕФЖЉдФЪ§ОнЕФIDСаБэЃЛ
2.зівЛДЮДѓаЭЕФЁЂЖрЯпГЬЕФЧЈвЦВйзїЃЌРДВЂааЕиАбЫљгаашвЊЧЈвЦЕФЖЉдФЪ§ОнПьЫйПНБДИДжЦЙ§ШЅЃЛ
3.ЕБЧЈвЦНсЪјжЎКѓЃЌдйдЫаавЛДЮScaldingШЮЮёЃЌШЗБЃЫљгаОЩЖЉдФБэжаЕФЖЉдФЪ§ОнЖМЧЈвЦЕНСЫаТБэРяЃЌУЛгавХТЉЃЛ
ЕкЖўВПЗжЃКЧаЛЛЫљгаЕФЖСВйзї
ЯждкаТОЩСНеХЪ§ОнБэжаЕФЪ§ОнЖМДІгкЭЌВНзДЬЌСЫЃЌЯТвЛВНОЭЪЧАбЫљгаЕФЖСВйзїЖМЧЈвЦЕНаТЪ§ОнБэЩЯРДЁЃ
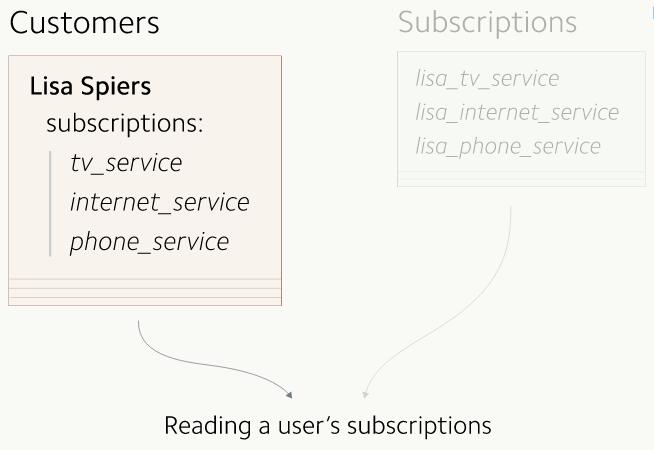
ЕНетвЛВНЪБЃЌЫљгаЕФЖСВйзїЖМШдШЛдкЪЙгУОЩЕФгУЛЇБэЃКЮвУЧвЊЧаЛЛЕНаТЕФЖЉдФБэЩЯРДЁЃ ЮвУЧвЊКмШЗаХПЩвдДгаТЕФЖЉдФБэжае§ГЃЖСГіЪ§ОнЃЌетвВвтЮЖзХЮвУЧЕФЖЉдФЪ§ОнБиаыЪЧвЛжТЕФЁЃЮвУЧгУGitHubЕФScientistРДАяЮвУЧзібщжЄЁЃScientistЪЧвЛИіRubyПтЃЌПЩвдШУЮвУЧжДааВтЪдЃЌБШНЯСНЖЮВЛЭЌЕФДњТыЕФжДааНсЙћЃЌШчЙћдкЩњВњЛЗОГжаСНЖЮТпМЛсВњЩњВЛЭЌЕФНсЙћЃЌЫќОЭЛсЗЂГіОЏИцЁЃгаСЫScientistЃЌЮвУЧОЭПЩвдЪЕЪБЕиЮЊВЛЭЌЕФНсЙћВњЩњИцОЏКЭЛёЕУжИБъЁЃЭђвЛВтЪдгУЕФДњТыВњЩњСЫДэЮѓвВУЛгаЙиЯЕЃЌЮвУЧЕФГЬађЕФЦфЫќВПЗжВЂВЛЛсЪмЕНгАЯьЁЃ ЮвУЧЛсзіЯТУцЕФбщжЄЃК
1.гУScientistШЅЗжБ№ДгЖЉдФБэКЭгУЛЇБэжаЖСГіЪ§ОнЃЛ
2.ШчЙћНсЙћВЛЭЌЃЌОЭХзГіДэЮѓЃЌЬсабММЪѕШЫдБЪ§ОнВЛвЛжТЃЛ
GitHubЕФScientistШУЮвУЧПЩвдЭЌЪБДгСНеХБэжаЖСГіЪ§ОнЃЌВЂЧвБШНЯНсЙћЁЃ
ШчЙћбщжЄЭЈЙ§ЃЌЫљгаЪ§ОнЖМФмЖдЕУЩЯЃЌЮвУЧОЭПЩвдДгаТБэжаЖСШыЪ§ОнСЫЁЃ
ЮвУЧЕФбщжЄКмГЩЙІЃКЫљгаЕФЖСВйзїЖМЪЙгУаТЕФЖЉдФБэСЫЁЃ
ЕкШ§ВПЗжЃКЧаЛЛЫљгааДВйзї
НгЯТРДЃЌЮвУЧвЊАбЫљгааДВйзїЖМЧаЛЛЕНаТЕФЪ§ОнБэЩЯРДЁЃЮвУЧЕФФПБъЪЧНЅНјЪНЕиЭЦНјетаЉБфЖЏЃЌвђДЫЮвУЧвЊВЩгУЗЧГЃЯИжТЕФеНЪѕЁЃ
ЕНФПЧАЮЊжЙЃЌЮвУЧвЛжБдкЯђОЩЪ§ОнБэжааДШыЪ§ОнЃЌВЂИДжЦЕНаТБэжаЃК

ЯждкЮвУЧвЊЕїЛЛетИіЫГађЃКЯђаТЪ§ОнБэжааДШыЪ§ОнЃЌВЂЧвЭЌВНЕНОЩЪ§ОнБэжаШЅЁЃЭЈЙ§БЃГжетСНеХЪ§ОнБэжЎМфЕФЪ§ОнвЛжТЃЌЮвУЧОЭПЩвдВЛЖЯЕизідіСПИќаТЃЌВЂЧвЯИжТЕиЙлВьУПДЮИФЖЏЕФгАЯьЁЃ АбЫљгаДІРэЖЉдФЪ§ОнЕФДњТыЖМжиЙЙЕєЃЌетвЛПщгІИУЪЧећИіЧЈвЦЙ§ГЬжазюгаЬєеНадЕФСЫЁЃStripeДІРэЖЉдФВйзїЕФТпМЗжВМдкШєИЩИіЗўЮёЕФМИЧЇааДњТыжаЁЃ ГЩЙІжиЙЙЕФЙиМќОЭдкгкЮвУЧЕФНЅНјЪНСїГЬЃКЮвУЧЛсОЁПЩФмЕиАбЪ§ОнДІРэТпМЯожЦЕНзюаЁЕФЗЖЮЇФкЃЌетбљЮвУЧОЭПЩвдКмаЁаФЕигІгУУПвЛДЮИФЖЏЁЃдкУПИіНзЖЮРяЃЌЮвУЧЕФаТОЩСНеХБэжаЕФЪ§ОнЖМЛсБЃГжвЛжТЁЃ ЖдгкУПвЛДІДњТыТпМЃЌЮвУЧЖМЛсгУШЋУцЕФЗНЗЈРДБЃжЄЮвУЧЕФИФЖЏЪЧАВШЋЕФЁЃЮвУЧВЛФмМђЕЅЕигУаТЪ§ОнЬцЛЛОЩЪ§ОнЃКУПвЛПщТпМЖМБиаыОЙ§ЩѓжиЕиПМТЧЁЃВЛЙмЮвУЧТЉЕєСЫФФжжЬиЪтЧщПіЃЌЖМгаПЩФмЛсЕМжТзюжеЕФЪ§ОнВЛвЛжТЁЃавдЫЕФЪЧЃЌЮвУЧПЩвддкећИіЙ§ГЬжаВЛЖЯЕидЫааScientistВтЪдРДЬсабЮвУЧФФРяПЩФмЛсгаВЛвЛжТЕФЧщПіЗЂЩњЁЃ
ЮвУЧМђЛЏСЫЕФаТаДШыЗНЪНДѓИХЪЧетбљЕФЃК

ЕНзюКѓЮвУЧМгШыТпМЃЌШчЙћгаШЮКЮЕїгУетбљЙ§ЦкЕФЖЉдФЪ§ОнЕФЧщПіЗЂЩњЃЌЮвУЧОЭЛсЧПжЦХзГівЛИіДэЮѓЁЃетбљЮвУЧОЭПЩвдБЃжЄдйвВУЛгаДњТыЛсгУЕНЫќСЫЁЃ
class Customer
def subscriptions
hard_assertion_failed("Accessing
subscriptions array on customer")
end |
ЕкЫФВПЗжЃКЩОГ§ОЩЪ§Он
ЮвУЧзюКѓвВЪЧзюгаГЩОЭИаЕФвЛВНЃЌОЭЪЧАбаДШыОЩЪ§ОнБэЕФДњТыЩОЕєЃЌзюКѓдйАбОЩЪ§ОнБэЩОЕєЁЃ
ЕБЮвУЧШЗШЯдйвВУЛгаДњТывРРЕвбБЛЬдЬЕФОЩЖЉдФЪ§ОнФЃаЭЪБЃЌЮвУЧОЭдйвВВЛгУаДШыОЩЪ§ОнБэжаСЫЃК

зіСЫетаЉИФЖЏжЎКѓЃЌЮвУЧЕФДњТыОЭдйвВВЛгУЪЙгУОЩЪ§ОнБэСЫЃЌаТЕФЪ§ОнБэОЭГЩСЫЮЈвЛЕФЪ§ОнРДдДЁЃ ШЛКѓЮвУЧОЭПЩвдЩОГ§ЕєЮвУЧЕФгУЛЇЖдЯѓжаЕФЫљгаЖЉдФЪ§ОнСЫЃЌВЂЧвЮвУЧЛсТ§Т§ЕиНЅНјЪНЕизіЩОГ§ВйзїЁЃЪзЯШУПЕБМгдиЖЉдФЪ§ОнЕФЪБКђЃЌЮвУЧЖМЛсздЖЏЕиЧхПеЪ§ОнЃЌзюКѓЛсдйдЫаавЛДЮScaldingШЮЮёвдМАЧЈвЦВйзїЃЌРДевГіЫљгавХТЉЕФЮДБЛЩОГ§ЕФЪ§ОнЁЃзюжеЮвУЧЛсЕУЕНЦкЭћЕФЪ§ОнФЃаЭЃК
НсТл
дкЧЈвЦЕФЭЌЪБЛЙвЊБЃжЄStripeЕФAPIЪЧвЛжТЕФЃЌетЪТКмИДдгЁЃЮвУЧгаЯТУцетаЉОбщПЩвдКЭДѓМвЗжЯэЃК
1.ЮвУЧзмНсГіСЫЫФНзЖЮЧЈвЦВпТдЃЌетШУЮвУЧПЩвддкЩњВњЛЗОГжаВЛашвЊШЮКЮЭЃЛњЪБМфОЭПЩвдЭъГЩЪ§ОнЧаЛЛВйзїЁЃ
2.ЮвУЧВЩгУСЫHadoopЃЌгУРыЯпЕФЗНЪННјааСЫЪ§ОнДІРэЃЌетШУЮвУЧПЩвдгУMapReduceВЂааЕиДІРэДѓСПЪ§ОнЃЌЖјВЛЪЧвРППЖдЩњВњПтНјааДњМлАКЙѓЕФМьЫїВйзїЁЃ
3.ЮвУЧЫљгаЕФИФЖЏЖМЪЧНЅНјЪНЕФЁЃУПвЛДЮЮвУЧИФЖЏЕФДњТыСПЖМОјЖдВЛЛсГЌЙ§МИАйааЁЃ
4.ЮвУЧЫљгаЕФИФЖЏЖМЪЧИпЖШЭИУїКЭПЩЙлВтЕФЁЃФФХТЩњВњЛЗОГжагавЛЬѕЪ§ОнВЛвЛжТЃЌScientistВтЪдЖМЛсСЂПЬЯђЮвУЧИцОЏЁЃЭЈЙ§етжжАьЗЈЃЌЮвУЧПЩвдШЗаХЮвУЧЕФЧЈвЦВйзїЪЧАВШЋЕФЁЃ
ЮвУЧдкStripeвбОзіЙ§аэЖрДЮдкЯпЧЈвЦСЫЃЌОЙ§ЪЕМљМьбщетаЉОбщЗЧГЃгааЇЁЃЯЃЭћБ№ЕФЭХЖгдкзіДѓЙцФЃЪ§ОнЧЈвЦЪБЃЌЮвУЧЕФетаЉОбщвВПЩвдЖдЫћУЧгаЫљАяжњЁЃ |









