| Apache
SparkжаЃЌЖдBlockЕФВщбЏЁЂДцДЂЙмРэЃЌЪЧЭЈЙ§ЮЈвЛЕФBlock IDРДНјааЧјЗжЕФЁЃЫљвдЃЌСЫНтBlock
IDЕФЩњГЩЙцЃЌФмЙЛАяжњЮвУЧСЫНтBlockВщбЏЁЂДцДЂЙ§ГЬжаЪЧШчКЮЖЈЮЛBlockвдМАШчКЮДІРэЛЅГтДцДЂ/ЖСШЁЭЌвЛИіBlockЕФЁЃ
ПЩвдЯыЕНЃЌЭЌвЛИіSpark ApplicationЃЌвдМАЖрИідЫааЕФApplicationжЎМфЃЌЖдгІЕФBlockЖМОпгаЮЈвЛЕФIDЃЌЭЈЙ§ДњТыПЩвдПДЕНЃЌBlockIDАќРЈЃКRDDBlockIdЁЂShuffleBlockIdЁЂShuffleDataBlockIdЁЂShuffleIndexBlockIdЁЂBroadcastBlockIdЁЂTaskResultBlockIdЁЂTempLocalBlockIdЁЂTempShuffleBlockIdет8жжIDЃЌПЩвдЯъМћШчЯТДњТыЖЈвхЃК
@DeveloperApi
case class RDDBlockId(rddId: Int, splitIndex:
Int)
extends BlockId {
override def name: String = "rdd_"
+ rddId + "_" +
splitInd}
// Format of the shuffle block ids (including
data
and index) should be kept in sync with
// org.apache.spark.network.shuffle.ExternalShuf
fleBlockResolver#getBlockData().
@DeveloperApi
case class ShuffleBlockId(shuffleId: Int, mapId:
Int, reduceId:Int) extends BlockId {
override def name: String = "shuffle_"
+ shuffleI+
"_" + mapId@DeveloperApi
case class ShuffleDataBlockId(shuffleId: Int,
mapId
: Int, reduceId: Int) extends BlockId {
override def name: String = "shuffle_"
+ shuffleId
+ "_" + mapId +"_" + reduceId
+ ".data"}
@DeveloperApi
case class ShuffleIndexBlockId(shuffleId: Int,
mapId: Int, reduceId:Int) extends BlockId {
override def name: String = "shuffle_"
+ shuffleId + "_" + mapId +
"_" + reduceId + ".index"
}
@DeveloperApi
case class BroadcastBlockId(broadcastId: Long,
field: String = "")
extends BlockId {
override def name: String = "broadcast_"
+ broadcastId + (if (field
== "") "" else "_"
+ field)
}
@DeveloperApi
case class TaskResultBlockId(taskId: Long) extends
BlockId {
override def name: String = "taskresult_"
+ taskId
}
@DeveloperApi
case class StreamBlockId(streamId: Int, uniqueId:
Long) extends
BlockId {
override def name: String = "input-"
+ streamId + "-" + uniqueId
}
/** Id associated with temporary local data
managed as blocks.
Not serializable. */
private[spark] case class TempLocalBlockId(id:
UUID) extends
BlockId {
override def name: String = "temp_local_"
+ id
}
/** Id associated with temporary shuffle data
managed as blocks
. Not serializable. */
private[spark] case class TempShuffleBlockId(id:
UUID) extends
BlockId {
override def name: String = "temp_shuffle_"
+ id
} |
ЮвУЧвдRDDBlockIdЕФЩњГЩЙцдђЮЊР§ЃЌЫќЪЧвдЧАзКзжЗћДЎЁАrdd_ЁБЮЊЧАзКЁЂЗжХфЕФШЋОжRDD IDЁЂЯТЛЎЯпЁА_ЁБЁЂPartition
IDет4ВПЗжЦДНгЖјГЩЃЌвђЮЊRDD IDЪЧЮЈвЛЕФЃЌЫљвдзюжеЙЙдьКУЕФRDDBlockIdЖдгІЕФзжЗћДЎОЭЪЧЮЈвЛЕФЁЃШчЙћИУBlockДцдкЃЌВщбЏПЩвдЮЈвЛЖЈЮЛЕНИУBlockЃЌДцДЂвВВЛЛсГіЯжИВИЧЦфЫћRDDBlockIdЕФЮЪЬтЁЃ
ЯТУцЃЌЮвУЧЭЈЙ§ЗжЮіMemoryStoreЁЂDiskStoreЁЂBlockManagerЁЂBlockInfoManagerет4ИізюКЫаФЕФгыBlockЙмРэЯрЙиЕФЪЕЯжРрЃЌРДРэНтSparkЖдBlockЕФЙмРэЁЃШЋЮФжаЃЌЮвУЧжївЊеыЖдRDDBlockIdЖдгІЕФBlockЪ§ОнЕФДІРэЁЂДцДЂЁЂВщбЏЁЂЖСШЁЃЌРДЗжЮіBlockЕФЙмРэЁЃ
MemoryStore
ЯШЫЕУївЛЯТMemoryStoreЃЌЫќжївЊгУРДдкФкДцжаДцДЂBlockЪ§ОнЃЌПЩвдБмУтжиИДМЦЫуЭЌвЛИіRDDЕФPartitionЪ§ОнЁЃвЛИіBlockЖдгІзХвЛИіRDDЕФвЛИіPartitionЕФЪ§ОнЁЃЕБStorageLevelЩшжУЮЊШчЯТжЕЪБЃЌЖМЛсПЩФмЛсашвЊЪЙгУMemoryStoreРДДцДЂЪ§ОнЃК
MEMORY_ONLY MEMORY_ONLY_2
MEMORY_ONLY_SER
MEMORY_ONLY_SER_2
MEMORY_AND_DISK
MEMORY_AND_DISK_2
MEMORY_AND_DISK_SER
MEMORY_AND_DISK_SER_2
OFF_HEAP |
ЫљвдЃЌMemoryStoreЬсЙЉЖдBlockЪ§ОнЕФДцДЂЁЂЖСШЁЕШВйзїAPIЃЌMemoryStoreвВЬсЙЉСЫЖржжДцДЂЗНЪНЃЌЯТУцЯъЯИЫЕУїУПжжЗНЪНЁЃ
вдађСаЛЏИёЪНБЃДцBlockЪ§Он
def putBytes[T: ClassTag](
blockId: BlockId,
size: Long,
memoryMode: MemoryMode,
_bytes: () => ChunkedByteBuffer): Boolean |
ЪзЯШЃЌЭЈЙ§MemoryManagerРДЩъЧыStorageФкДцЃЌЕїгУputBytesЗНЗЈЃЌЛсИљОнsizeДѓаЁШЅЩъЧыStorageФкДцЃЌШчЙћЩъЧыГЩЙІЃЌдђЛсНЋblockIdЖдгІЕФBlockЪ§ОнБЃДцдкФкВПЕФLinkedHashMap[BlockId,
MemoryEntry[_]]гГЩфБэжаЃЌШЛКѓвдSerializedMemoryEntryетжжађСаЛЏЕФИёЪНДцДЂЃЌЪЕМЪSerializedMemoryEntryОЭЪЧМђЕЅжИЯђBufferжаЪ§ОнЕФв§гУЖдЯѓЃК
private case class SerializedMemoryEntry[T]( buffer: ChunkedByteBuffer,
memoryMode: MemoryMode,
classTag: ClassTag[T]) extends MemoryEntry[T] {
def size: Long = buffer.size
} |
ШчЙћЮоЗЈЩъЧыЕНsizeДѓаЁЕФStorageФкДцЃЌдђДцДЂЪЇАмЃЌЖдгкГіЯжетжжЪЇАмЕФЧщПіЃЌашвЊЪЙгУMemoryStoreДцДЂAPIЕФЕїгУепШЅДІРэвьГЃЧщПіЁЃ
ЛљгкМЧТМЕќДњЦїЃЌвдЗДађСаЛЏJavaЖдЯѓаЮЪНБЃДцBlockЪ§Он
private[storage] def putIteratorAsValues[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T]): Either[PartiallyUnro
\lledIterator[T], Long]
|
етжжЗНЪНЃЌЕїгУепЯЃЭћНЋBlockЪ§ОнМЧТМвдЗДађСаЛЏЕФЗНЪНБЃДцдкФкДцжаЃЌШчЙћФкДцжаФмЗХЕУЯТЃЌдђЗЕЛизюжеBlockЪ§ОнМЧТМЕФДѓаЁЃЌЗёдђЗЕЛивЛИіPartiallyUnrolledIterator[T]ЕќДњЦїЃЌЦфжаЖдгІШчЯТ2жжЧщПіЃК
ЕквЛжжЃЌBlockЪ§ОнМЧТМФмЙЛЭъШЋЗХЕНФкДцжаЃККЭЧАУцЕФЗНЪНРрЫЦЃЌФмЙЛШЋВПЗХЕНФкДцЃЌЕЋЪЧВЛЭЌЕФЪЧЃЌетжжЗНЪНЖдгІЕФЪ§ОнИёЪНЪЧЗДађСаЛЏЕФJavaЖдЯѓИёЪНЃЌЖдгІЪЕЯжРрDeserializedMemoryEntry[T]ЃЌЫќвВЛсБЛжБНгДцЗХЕНMemoryStoreФкВПЕФLinkedHashMap[BlockId,
MemoryEntry[_]]гГЩфБэжаЁЃDeserializedMemoryEntry[T]РрЖЈвхШчЯТЫљЪОЃК
private case class DeserializedMemoryEntry[T]( value: Array[T],
size: Long,
classTag: ClassTag[T]) extends MemoryEntry[T] {
val memoryMode: MemoryMode = MemoryMode.ON_HEAP
} |
ЫќгыSerializedMemoryEntryЖМЪЧMemoryEntry[T]ЕФзгРрЃЌЫљгаБЛЗХЕНЭЌвЛИігГЩфБэLinkedHashMap[BlockId,
MemoryEntry[_]] entriesжаЁЃ
СэЭтЃЌвВДцдкетжжПЩФмЃЌЭЈЙ§MemoryManagerЩъЧыЕФUnrollФкДцДѓаЁДѓгкИУBlockДђПЊашвЊЕФФкДцЃЌдђЛсЗЕЛиШчЯТНсЙћЖдЯѓЃК
Left(new PartiallyUnrolledIterator( this,
unrollMemoryUsedByThisBlock,
unrolled = arrayValues.toIterator, rest
= Iterator.empty)) |
ЩЯУцunrolled = arrayValues.toIteratorЃЌrest = Iterator.emptyЃЌБэЪОдкФкДцжаПЩвдДђПЊЕќДњЦїжаШЋВПЕФЪ§ОнМЧТМЃЌДђПЊЖдЯѓРраЭЮЊDeserializedMemoryEntry[T]ЁЃ
ЕкЖўжжЃЌBlockЪ§ОнМЧТМжЛФмВПЗжЗХЕНФкДцжаЃКвВОЭЪЧЫЕDriverЛђExecutorЩЯЕФФкДцгаЯоЃЌжЛПЩвдЗХЕУЯТВПЗжМЧТМЃЌСэвЛВПЗжМЧТМФкДцжаЗХВЛЯТЁЃvaluesМЧТМЕќДњЦїЖдгІЕФШЋВПМЧТМЪ§ОнЮоЗЈЭъШЋЗХдкФкДцжаЃЌЫљвдЮЊСЫБЃжЄВЛЗЂЩњOOMвьГЃЃЌЪзбЁЛсЕїгУMemoryManagerЕФacquireUnrollMemoryЗНЗЈШЅЩъЧыUnrollФкДцЃЌШчЙћПЩвдЩъЧыЕНЃЌдкЕќДњvaluesЕФЙ§ГЬжаЃЌашвЊРлМгМЦЫуДђПЊЃЈUnrollЃЉЕФМЧТМЖдЯѓДѓаЁжЎКЭЃЌЪЙЦфДѓаЁВЛФмДѓгкЩъЧыЕНЕФUnrollФкДцЃЌжБЕНЛЙгавЛВПЗжМЧТМЮоЗЈЗХЕНЩъЧыЕФUnrollФкДцжаЁЃ
зюКѓЃЌЗЕЛиЕФНсЙћЖдЯѓШчЯТЫљЪОЃК
Left(new PartiallyUnrolledIterator( this, unrollMemoryUsedByThisBlock, unrolled =
vector.iterator, rest = values)) |
ЩЯУцЕФPartiallyUnrolledIteratorжаrestЖдгІЕФvaluesОЭЪЧputIteratorAsValuesЗНЗЈДЋНјРДЕФЕќДњЦїВЮЪ§жЕЃЌИУЕќДњЦївбОЕќДњГіВПЗжМЧТМЃЌЗХЕНСЫФкДцжаЃЌЕїгУепПЩвдМЬајЕќДњИУЕќДњЦїШЅДІРэЮДДђПЊЃЈUnrollЃЉЕФМЧТМЃЌЖјunrolledЖдгІвЛИіДђПЊМЧТМЕФЕќДњЦїЁЃетРяЃЌPartiallyUnrolledIteratorЕќДњЦїАќзАСЫvector.iteratorКЭвЛИіЕќДњГіВПЗжМЧТМЕФvaluesЕќДњЦїЃЌЕїгУепЖдPartiallyUnrolledIteratorНјааЭГвЛЕќДњФмЙЛЛёШЁЕНШЋВПМЧТМЃЌРяУцАќКЌСНжжРраЭЕФМЧТМЃКDeserializedMemoryEntry[T]КЭTЁЃ
ЛљгкМЧТМЕќДњЦїЃЌвдађСаЛЏЖўНјжЦИёЪНБЃДцBlockЪ§Он
private[storage] def putIteratorAsBytes[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T],
memoryMode: MemoryMode): Either[Partially
SerializedBlock[T], Long] |
етжжЗНЪНЃЌЕїгУетжжЯЃЭћНЋBlockЪ§ОнМЧТМвдЖўНјжЦЕФИёЪНБЃДцдкФкДцжаЁЃШчЙћФкДцжаФмЗХЕУЯТЃЌдђЗЕЛизюжеЕФДѓаЁЃЌЗёдђЗЕЛивЛИіPartiallySerializedBlock[T]ЕќДњЦїЁЃ
ШчЙћBlockЪ§ОнМЧТМФмЙЛЭъШЋЗХЕНФкДцжаЃЌдђвдSerializedMemoryEntry[T]ИёЪНЗХЕНФкДцЕФгГЩфБэжаЁЃШчЙћBlockЪ§ОнМЧТМжЛФмВПЗжЗХЕНФкДцжаЃЌдђЗЕЛиШчЯТЖдЯѓЃК
Left( new PartiallySerializedBlock(
this,
serializerManager,
blockId,
serializationStream,
redirectableStream,
unrollMemoryUsedByThisBlock,
memoryMode,
bbos.toChunkedByteBuffer,
values,
classTag)) |
РрЫЦЕиЃЌЗЕЛиНсЙћЖдЯѓЖдЕїгУепБЃГжЭГвЛЕФЕќДњAPIЪгЭМЁЃ
DiskStore
DiskStoreЬсЙЉСЫНЋBlockЪ§ОнаДШыЕНДХХЬЕФЛљБОВйзїЃЌЫќЪЧЭЈЙ§DiskBlockManagerРДЙмРэТпМЩЯBlockЕНЮяРэДХХЬЩЯBlockЮФМўТЗОЖЕФгГЩфЙиЯЕЁЃЕБStorageLevelЩшжУЮЊШчЯТжЕЪБЃЌЖМПЩФмЛсашвЊЪЙгУDiskStoreРДДцДЂЪ§ОнЃК
DISK_ONLY DISK_ONLY_2
MEMORY_AND_DISK
MEMORY_AND_DISK_2
MEMORY_AND_DISK_SER
MEMORY_AND_DISK_SER_2
OFF_HEAP |
DiskBlockManagerЙмРэСЫУПИіBlockЪ§ОнДцДЂЮЛжУЕФаХЯЂЃЌАќРЈДгBlock IDЕНДХХЬЩЯЮФМўЕФгГЩфЙиЯЕЁЃDiskBlockManagerжївЊгаШчЯТМИИіЙІФмЃК
ИКд№ДДНЈвЛИіБОЕиНкЕуЩЯЕФжИЖЈДХХЬФПТМЃЌгУРДДцДЂBlockЪ§ОнЕНжИЖЈЮФМўжа
1.ШчЙћBlockЪ§ОнЯывЊТфХЬЃЌашвЊЭЈЙ§ЕїгУgetFileЗНЗЈРДЗжХфвЛИіЮЈвЛЕФЮФМўТЗОЖ
2.ШчЙћЯывЊВщбЏвЛИіBlockЪЧЗёдкДХХЬЩЯЃЌЭЈЙ§ЕїгУcontainsBlockЗНЗЈРДВщбЏ
3.ВщбЏЕБЧАНкЕуЩЯЙмРэЕФШЋВПBlockЮФМў
4.ЭЈЙ§ЕїгУcreateTempLocalBlockЗНЗЈЃЌЩњГЩвЛИіЮЈвЛBlock
IDЃЌВЂДДНЈвЛИіЮЈвЛЕФСйЪБЮФМўЃЌгУРДДцДЂжаМфНсЙћЪ§Он
5.ЭЈЙ§ЕїгУcreateTempShuffleBlockЗНЗЈЃЌЩњГЩвЛИіЮЈвЛBlock
IDЃЌВЂДДНЈвЛИіЮЈвЛЕФСйЪБЮФМўЃЌгУРДДцДЂShuffleЙ§ГЬЕФжаМфНсЙћЪ§Он
6.DiskStoreЬсЙЉЕФЛљБОВйзїНгПкЃЌгыMemoryStoreРрЫЦЃЌБШНЯМђЕЅЃЌШчЯТЫљЪОЃК
ЭЈЙ§ЮФМўСїаДBlockЪ§Он
ИУжжЗНЪНЖдгІЕФНгПкЗНЗЈЃЌШчЯТЫљЪОЃК
def put(blockId: BlockId)(writeFunc:
FileOutputStream => Unit): Unit |
ВЮЪ§жИЖЈBlock IDЃЌЛЙгавЛИіаДBlockЪ§ОнЕНДђПЊЕФЮФМўСїЕФКЏЪ§ЃЌдкЕїгУputЗНЗЈЪБЃЌЪзЯШЛсДгDiskBlockManagerЗжХфвЛИіBlock
IDЖдгІЕФДХХЬЮФМўТЗОЖЃЌШЛКѓНЋЪ§ОнаДШыЕНИУЮФМўжаЁЃ
НЋЖўНјжЦBlockЪ§ОнаДШыЮФМў
putBytesЗНЗЈЪЕЯжСЫЃЌНЋвЛИіBufferжаЕФBlockЪ§ОнаДШыжИЖЈЕФBlock IDЖдгІЕФЮФМўжаЃЌЗНЗЈЖЈвхШчЯТЫљЪОЃК
def putBytes(blockId: BlockId, bytes:
ChunkedByteBuffer):
Unit |
ЪЕМЪЩЯЃЌЫќЪЧЕїгУЩЯУцЕФputЗНЗЈЃЌНЋbytesжаЕФBlockЖўНјжЦЪ§ОнаДШыЕНBlockЮФМўжаЁЃ
ДгДХХЬЮФМўЖСШЁBlockЪ§Он
ЖдгІЗНЗЈШчЯТЫљЪОЃК
def getBytes(blockId: BlockId):
ChunkedByteBuffer |
ЭЈЙ§ИјЖЈЕФblockIdЃЌЛёШЁДХХЬЩЯЖдгІЕФBlockЮФМўЕФЪ§ОнЃЌвдChunkedByteBufferЕФаЮЪНЗЕЛиЁЃ
ЩОГ§BlockЮФМў
ЖдгІЕФЩОГ§ЗНЗЈЖЈвхЃЌШчЯТЫљЪОЃК
def remove(blockId: BlockId): Boolean
|
ЭЈЙ§DiskBlockManagerВщевЕНblockIdЖдгІЕФBlockЮФМўЃЌШЛКѓЩОГ§ЕєЁЃ
BlockManager
ЬИЕНSparkжаЕФBlockЪ§ОнДцДЂЃЌЮвУЧКмШнвзФмЙЛЯыЕНBlockManagerЃЌЫћИКд№ЙмРэдкУПИіDirverКЭExecutorЩЯЕФBlockЪ§ОнЃЌПЩФмЪЧБОЕиЛђепдЖГЬЕФЁЃОпЬхВйзїАќРЈВщбЏBlockЁЂНЋBlockБЃДцдкжИЖЈЕФДцДЂжаЃЌШчФкДцЁЂДХХЬЁЂЖбЭтЃЈOff-heapЃЉЁЃЖјBlockManagerвРРЕЕФКѓЖЫЃЌЖдBlockЪ§ОнНјааФкДцЁЂДХХЬДцДЂЗУЮЪЃЌЖМЪЧЛљгкЧАУцНВЕНЕФMemoryStoreЁЂDiskStoreЁЃ
дкSparkМЏШКжаЃЌЕБЬсНЛвЛИіApplicationжДааЪБЃЌИУApplicationЖдгІЕФDriverвдМАЫљгаЕФExecutorЩЯЃЌЖМДцдквЛИіBlockManagerЁЂBlockManagerMasterЃЌЖјBlockManagerMasterЪЧИКд№ЙмРэИїИіBlockManagerжЎМфЭЈаХЃЌетИіBlockManagerЙмРэМЏШКЃЌШчЯТЭМЫљЪОЃК
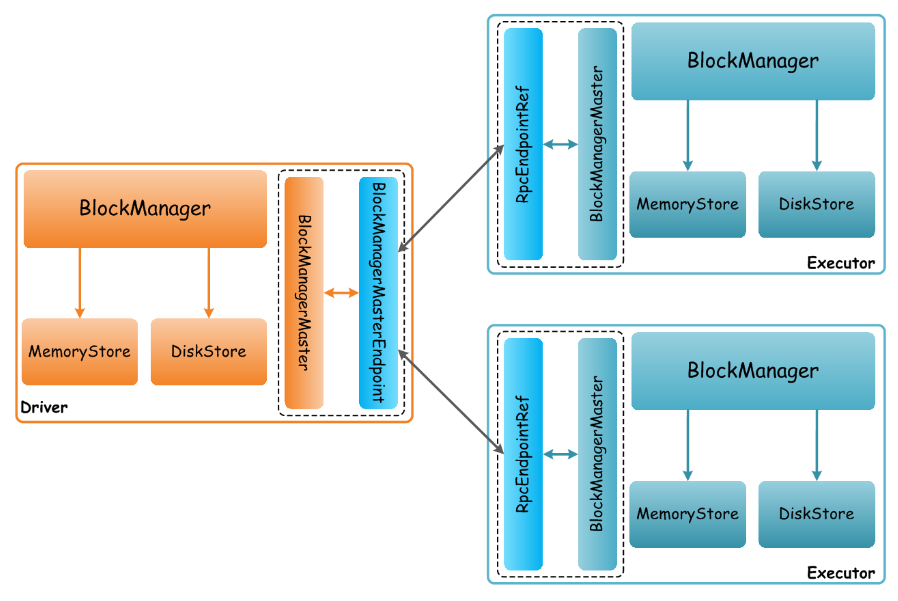
ЙигквЛИіApplicationдЫааЙ§ГЬжаBlockЕФЙмРэЃЌжївЊЪЧЛљгкИУApplicationЫљЙиСЊЕФвЛИіDriverКЭЖрИіExecutorЙЙНЈСЫвЛИіBlockЙмРэМЏШКЃКDriverЩЯЕФ(BlockManagerMaster,
BlockManagerMasterEndpoint)ЪЧМЏШКЕФMasterНЧЩЋЃЌЫљгаExecutorЩЯЕФ(BlockManagerMaster,
RpcEndpointRef)зїЮЊМЏШКЕФSlaveНЧЩЋЁЃЕБExecutorЩЯЕФTaskдЫааЪБЃЌЛсВщбЏЖдгІЕФRDDЕФФГИіPartitionЖдгІЕФBlockЪ§ОнЪЧЗёДІРэЙ§ЃЌетИіЙ§ГЬжаЛсДЅЗЂЖрИіBlockManagerжЎМфЕФЭЈаХНЛЛЅЁЃЮвУЧвдShuffleMapTaskЕФдЫааЮЊР§ЃЌЖдгІДњТыШчЯТЫљЪОЃК
override def runTask(context: TaskContext):
MapStatus = {
// Deserialize the RDD using the broadcast
variable.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDepen
dency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.current
Thread. getContextClassLoader)
_executorDeserializeTime = System.currentTim
eMillis() - deserializeStartTime var write
r: ShuffleWriter[Any, Any] = nulltry {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffle
Handle, partitionId, context)
writer.write(rdd.iterator(partition, context).
asInstanceOf[Iterator[_ <: Product2[Any,
Any]]])
// ДІРэRDDЕФPartitionЕФЪ§Он
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer",
e)
}
throw e
}
}
|
вЛИіRDDЕФPartitionЖдгІвЛИіShuffleMapTaskЃЌвЛИіShuffleMapTaskЛсдквЛИіExecutorЩЯдЫааЃЌЫќИКд№ДІРэRDDЕФвЛИіPartitionЖдгІЕФЪ§ОнЃЌЛљБОДІРэСїГЬЃЌШчЯТЫљЪОЃК
1.ИљОнИУPartitionЕФЪ§ОнЃЌДДНЈвЛИіRDDBlockIdЃЈгЩRDD
IDКЭPartition IndexзщГЩЃЉЃЌМДЕУЕНвЛИіЮШЖЈЕФblockIdЃЈШчЙћИУPartitionЪ§ОнБЛДІРэЙ§ЃЌдђПЩФмБОЕиЛђепдЖГЬExecutorДцДЂСЫЖдгІЕФBlockЪ§ОнЃЉЁЃ
2.ЯШДгBlockManagerЛёШЁИУblockIdЖдгІЕФЪ§ОнЪЧЗёДцдкЃЌШчЙћБОЕиДцдкЃЈвбОДІРэЙ§ЃЉЃЌдђжБНгЗЕЛиBlockНсЙћЃЈBlockResultЃЉЃЛЗёдђЃЌВщбЏдЖГЬЕФExecutorЪЧЗёвбОДІРэЙ§ИУBlockЃЌДІРэЙ§дђжБНгЭЈЙ§ЭјТчДЋЪфЕНЕБЧАExecutorБОЕиЃЌВЂИљОнStorageLevelЩшжУЃЌБЃДцBlockЪ§ОнЕНБОЕиMemoryStoreЛђDiskStoreЃЌЭЌЪБЭЈЙ§BlockManagerMasterЩЯБЈBlockЪ§ОнзДЬЌЃЈЭЈжЊDriverЕБЧАЕФBlockзДЬЌЃЌврМДЃЌИУBlockЪ§ОнДцДЂдкФФИіBlockManagerжаЃЉЁЃ
3.ШчЙћБОЕиМАдЖГЬExecutorЖМУЛгаДІРэЙ§ИУPartitionЖдгІЕФBlockЪ§ОнЃЌдђЕїгУRDDЕФcomputeЗНЗЈНјааМЦЫуДІРэЃЌВЂНЋДІРэЕФBlockЪ§ОнЃЌИљОнStorageLevelЩшжУЃЌДцДЂЕНБОЕиMemoryStoreЛђDiskStoreЁЃ
4.ИљОнShuffleManagerЖдгІЕФShuffleWriterЃЌНЋЗЕЛиЕФИУPartitionЕФBlockЪ§ОнНјааShuffleаДШыВйзї
ЯТУцЃЌЮвУЧЛљгкЩЯУцТпМЃЌЯъЯИЗжЮідкетИіДІРэЙ§ГЬжаживЊЕФНЛЛЅТпМЃК
ИљОнRDDЛёШЁвЛИіPartitionЖдгІЪ§ОнЕФМЧТМЕќДњЦї
гУЛЇЬсНЛЕФSpark ApplicationГЬађЃЌЛсЩшжУЖдгІЕФStorageLevelЃЌЫљвдЩшжУгыВЛЩшжУЖдИУДІРэТпМгавЛЖЈгАЯьЃЌОпгаСНжжЧщПіЃЌШчЯТЭМЫљЪОЃК
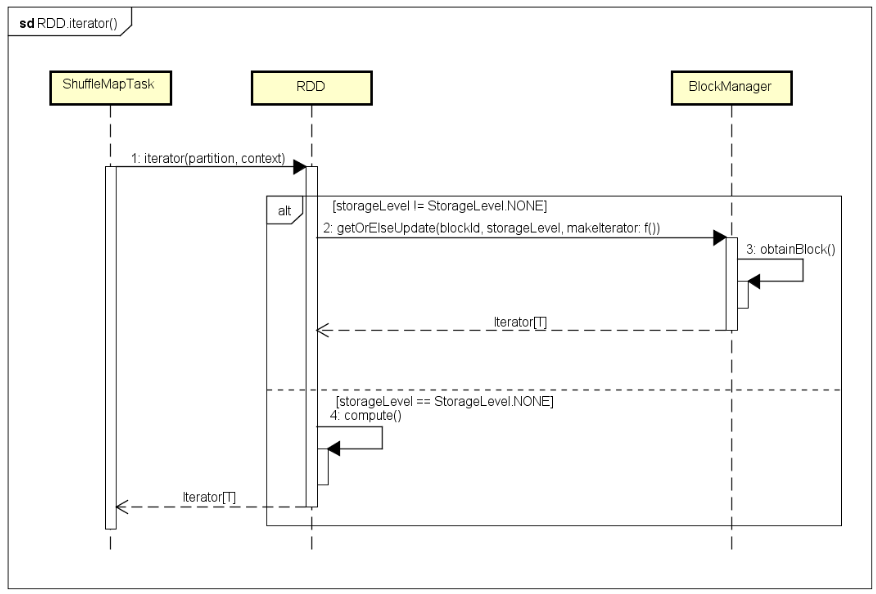
ШчЙћгУЛЇГЬађЩшжУСЫStorageLevelЃЌПЩФмИУPartitionЕФЪ§ОнвбОДІРэЙ§ЃЌФЧУДЖдгІЕФДІРэНсЙћBlockЪ§ОнПЩФмвбОДцДЂЁЃвЛАуЩшжУЕФStorageLevelЃЌЛђепНЋBlockДцДЂдкФкДцжаЃЌЛђепДцДЂдкДХХЬЩЯЃЌетРяЛсГЂЪдЕїгУgetOrElseUpdate()ЗНЗЈЛёШЁЖдгІЕФBlockЪ§ОнЃЌШчЙћДцдкдђжБНгЗЕЛиBlockЖдгІЕФМЧТМЕФЕќДњЦїЪЕР§ЃЌОЭВЛашвЊжиаТМЦЫуСЫЃЌШчЙћУЛгаевЕНЖдгІЕФвбОДІРэЙ§ЕФBlockЪ§ОнЃЌдђЕїгУRDDЕФcompute()ЗНЗЈНјааДІРэЃЌДІРэНсЙћИљОнStorageLevelЩшжУЃЌНЋBlockЪ§ОнДцДЂдкФкДцЛђДХХЬЩЯЃЌЛКДцЙЉКѓајTaskжиИДЪЙгУЁЃ
ШчЙћгУЛЇГЬађУЛгаЩшжУStorageLevelЃЌФЧУДRDDЖдгІЕФИУPartitionЕФЪ§ОнвЛЖЈУЛгаНјааДІРэЙ§ЃЌМДЪЙДІРэЙ§ЃЌШчЙћУЛгаНјааCheckpointingЃЌвВашвЊжиаТМЦЫуЃЈШчЙћНјааСЫCheckpointingЃЌПЩвджБНгДгЛКДцжаЛёШЁЃЉЃЌжБНгЕїгУRDDЕФcompute()ЗНЗЈНјааДІРэЁЃ
ДгBlockManagerВщбЏЛёШЁBlockЪ§Он
УПИіExecutorЩЯЖМгавЛИіBlockManagerЪЕР§ЃЌИКд№ЙмРэгУЛЇЬсНЛЕФИУApplicationМЦЫуЙ§ГЬжаВњЩњЕФBlockЁЃКмгаПЩФмЕБЧАExecutorЩЯДцДЂдкRDDЖдгІPartitionЕФОЙ§ДІРэКѓЕУЕНЕФBlockЪ§ОнЃЌвВгаПЩФмЕБЧАExecutorЩЯУЛгаЃЌЕЋЪЧЦфЫћExecutorЩЯвбОДІРэЙ§ВЂЛКДцСЫBlockЪ§ОнЃЌЫљвдЖдгІзХБОЕиЛёШЁЁЂдЖГЬЛёШЁСНжжПЩФмЃЌБОЕиЛёШЁНЛЛЅТпМШчЯТЭМЫљЪОЃК
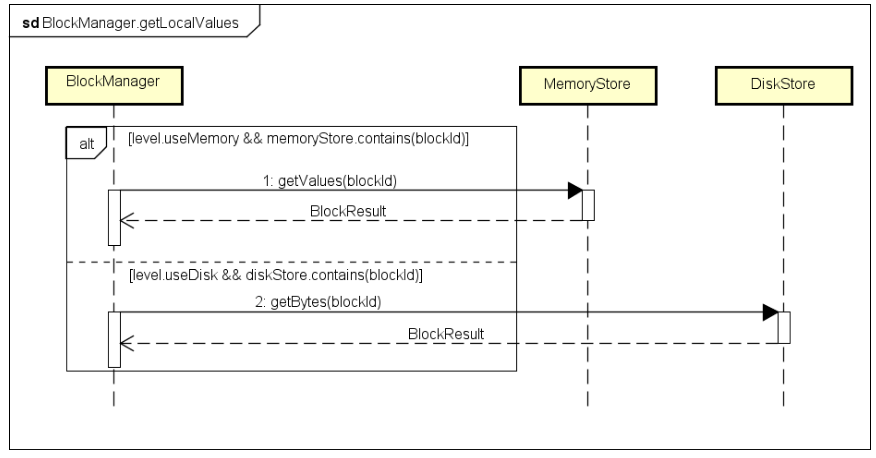
ДгБОЕиЛёШЁЃЌИљОнStorageLevelЩшжУЃЌШчЙћЪЧДцДЂдкФкДцжаЃЌдђДгБОЕиЕФMemoryStoreжаВщбЏЃЌДцдкдђЖСШЁВЂЗЕЛиЃЛШчЙћЪЧДцДЂдкДХХЬЩЯЃЌдђДгБОЕиЕФDiskStoreжаВщбЏЃЌДцдкдђЖСШЁВЂЗЕЛиЁЃБОЕиВЛДцдкЃЌдђЛсДгдЖГЬЕФExecutorЖСШЁЃЌЖдгІЕФзщМўНЛЛЅТпМЃЌШчЯТЭМЫљЪОЃК
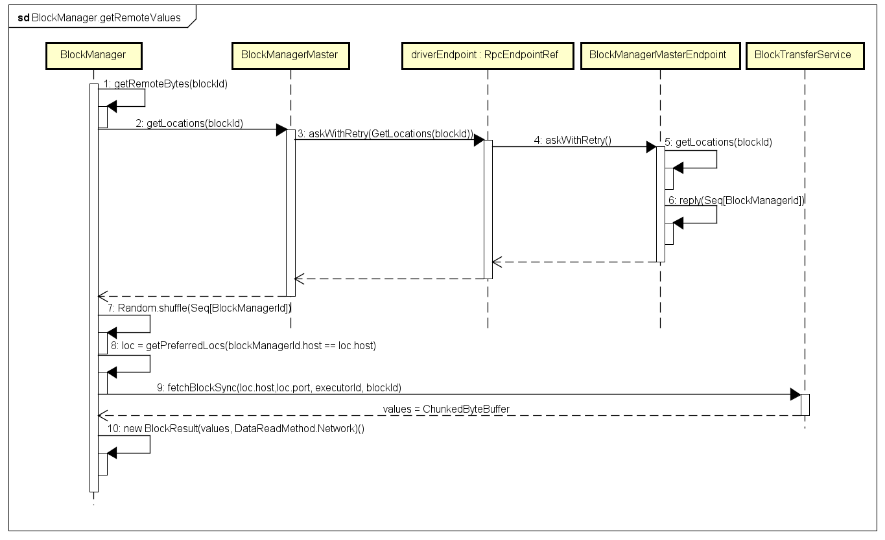
дЖГЬЛёШЁНЛЛЅТпМЯрЖдБШНЯИДдгЃКЕБЧАExecutorЩЯЕФBlockManagerЭЈЙ§BlockManagerMasterЃЌЯђдЖГЬЕФDriverЩЯЕФBlockManagerMasterEndpointВщбЏЖдгІBlock
IDЃЌгаФФаЉExecutorвбОБЃДцСЫИУBlockЪ§ОнЃЌDirverЗЕЛивЛИіАќКЌСЫИУBlockЪ§ОнЕФLocationСаБэЃЌШчЙћЖдгІЕФLocationаХЯЂгыЕБЧАShuffleMapTaskжДааЫљдкExecutorдкЭЌвЛЬЈНкЕуЩЯЃЌдђЛсгХЯШЪЙгУИУLocationЃЌвђЮЊЭЌвЛНкЕуЩЯЕФЖрИіExecutorжЎМфДЋЪфBlockЪ§ОнаЇТЪИќИпЁЃ
етРяашвЊЫЕУїЕФЪЧЃЌШчЙћЖдгІЕФBlockЪ§ОнЕФStorageLevelЩшжУЮЊаДДХХЬЃЌЭЈЙ§ЧАУцЮвУЧжЊЕРЃЌDiskStoreЪЧЭЈЙ§DiskBlockManagerНјааЙмРэДцДЂЕНДХХЬЩЯЕФBlockЪ§ОнЮФМўЕФЃЌдкЭЌвЛИіНкЕуЩЯЕФЖрИіExecutorЙВЯэЯрЭЌЕФДХХЬЮФМўТЗОЖЃЌЯрЭЌЕФBlockЪ§ОнЮФМўвВОЭЛсБЛЭЌвЛИіНкЕуЩЯЕФЖрИіExecutorЫљЙВЯэЁЃЖјЖдгІMemoryStoreЃЌвђЮЊУПИіExecutorЖдгІЖРСЂЕФJVMЪЕР§ЃЌДгЖјОпгаЖРСЂЕФStorage/ExecutionФкДцЙмРэЃЌЫљвдЪЙгУMemoryStoreВЛФмЙВЯэЭЌвЛИіBlockЪ§ОнЃЌЕЋЪЧЭЌвЛИіНкЕуЩЯЕФЖрИіExecutorжЎМфЕФMemoryStoreжЎМфПНБДЪ§ОнЃЌБШПчЭјТчДЋЪфвЊИпаЇЕФЖрЁЃ
BlockInfoManager
гУЛЇЬсНЛвЛИіSpark ApplicationГЬађЃЌШчЙћГЬађЖдгІЕФDAGЭМЯрЖдИДдгЃЌЦфжаКмЖрTaskМЦЫуЕФНсЙћBlockЪ§ОнЖМгаПЩФмБЛжиИДЪЙгУЃЌетжжЧщПіЯТШчКЮШЅПижЦФГИіExecutorЩЯЕФTaskЯпГЬШЅЖСаДBlockЪ§ОнФиЃПЦфЪЕЃЌBlockInfoManagerОЭЪЧгУРДПижЦBlockЪ§ОнЖСаДВйзїЃЌВЂЧвИњзйTaskЖСаДСЫФФаЉBlockЪ§ОнЕФгГЩфЙиЯЕЃЌетбљШчЙћСНИіTaskЖМЯыШЅДІРэЭЌвЛИіRDDЕФЭЌвЛИіPartitionЪ§ОнЃЌШчЙћУЛгаЫјРДПижЦЃЌКмПЩФмСНИіTaskЖМЛсМЦЫуВЂаДЭЌвЛИіBlockЪ§ОнЃЌДгЖјдьГЩЛьТвЁЃЮвУЧЗжЮіУПжжЧщПіЯТЃЌBlockInfoManagerЪЧШчКЮЙмРэBlockЪ§ОнЃЈЭЌвЛИіRDDЕФЭЌвЛИіPartitionЃЉЖСаДЕФЃК
ЕквЛИіTaskЧыЧѓаДBlockЪ§Он
етжжЧщПіЯТЃЌУЛгаЦфЫћTaskаДBlockЪ§ОнЃЌЕквЛИіTaskжБНгЛёШЁЕНаДЫјЃЌВЂЦєЖЏаДBlockЪ§ОнЕНБОЕиMemoryStoreЛђDiskStoreЁЃШчЙћЦфЫћаДBlockЪ§ОнЕФTaskвВЧыЧѓаДЫјЃЌдђИУTaskЛсзшШћЃЌЕШД§ЕквЛИіЛёШЁаДЫјЕФTaskЭъГЩаДBlockЪ§ОнЃЌжБЕНЕквЛИіTaskаДЭъГЩЃЌВЂЭЈжЊЦфЫћзшШћЕФTaskЃЌШЛКѓЦфЫћTaskашвЊдйДЮЛёШЁЕНЖСЫјРДЖСШЁИУBlockЪ§ОнЁЃ
ЕквЛИіTaskе§дкаДBlockЪ§ОнЃЌЦфЫћTaskЧыЧѓЖСBlockЪ§Он
етжжЧщПіЃЌBlockЪ§ОнУЛгаЭъГЩаДВйзїЃЌЦфЫћЖСBlockЪ§ОнЕФTaskжЛФмзшШћЃЌЕШД§аДBlockЕФTaskЭъГЩВЂЭЈжЊЖСTaskШЅЖСШЁBlockЪ§ОнЁЃ
TaskЧыЧѓЖСШЁBlockЪ§Он
ШчЙћИУBlockЪ§ОнВЛДцдкЃЌдђжБНгЗЕЛиПеЃЌБэЪОЕБЧАRDDЕФИУPartitionВЂУЛгаБЛДІРэЙ§ЁЃШчЙћЕБЧАBlockЪ§ОнДцдкЃЌВЂЧвУЛгаЦфЫћTaskдкаДЃЌБэЪОвбОЭъГЩСЫаЉBlockЪ§ОнВйзїЃЌдђИУTaskжБНгЖСШЁИУBlockЪ§ОнЁЃ |









