| 
ЁЁЁЁSpark зїЮЊвЛИіЛљгкФкДцЕФЗжВМЪНМЦЫув§ЧцЃЌЦфФкДцЙмРэФЃПщдкећИіЯЕЭГжаАчбнзХЗЧГЃживЊЕФНЧЩЋЁЃРэНт
Spark ФкДцЙмРэЕФЛљБОдРэЃЌгажњгкИќКУЕиПЊЗЂ Spark гІгУГЬађКЭНјааадФмЕїгХЁЃБОЮФжМдкЪсРэГі
Spark ФкДцЙмРэЕФТіТчЃЌХззЉв§гёЃЌв§ГіЖСепЖдетИіЛАЬтЕФЩюШыЬНЬжЁЃБОЮФжаВћЪіЕФдРэЛљгк Spark
2.1 АцБОЃЌдФЖСБОЮФашвЊЖСепгавЛЖЈЕФ Spark КЭ Java ЛљДЁЃЌСЫНт RDDЁЂShuffleЁЂJVM
ЕШЯрЙиИХФюЁЃ
ЁЁЁЁдкжДаа Spark ЕФгІгУГЬађЪБЃЌSpark МЏШКЛсЦєЖЏ Driver КЭ Executor
СНжж JVM НјГЬЃЌЧАепЮЊжїПиНјГЬЃЌИКд№ДДНЈ Spark ЩЯЯТЮФЃЌЬсНЛ Spark зївЕ(Job)ЃЌВЂНЋзївЕзЊЛЏЮЊМЦЫуШЮЮё(Task)ЃЌдкИїИі
Executor НјГЬМфаЕїШЮЮёЕФЕїЖШЃЌКѓепИКд№дкЙЄзїНкЕуЩЯжДааОпЬхЕФМЦЫуШЮЮёЃЌВЂНЋНсЙћЗЕЛиИј DriverЃЌЭЌЪБЮЊашвЊГжОУЛЏЕФ
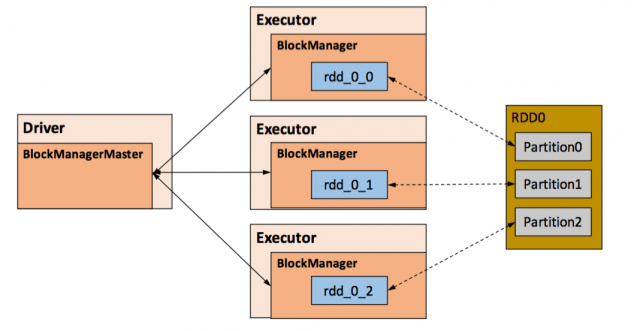
RDD ЬсЙЉДцДЂЙІФм[1]ЁЃгЩгк Driver ЕФФкДцЙмРэЯрЖдРДЫЕНЯЮЊМђЕЅЃЌБОЮФжївЊЖд Executor
ЕФФкДцЙмРэНјааЗжЮіЃЌЯТЮФжаЕФ Spark ФкДцОљЬижИ Executor ЕФФкДцЁЃ
ЁЁЁЁ1. ЖбФкКЭЖбЭтФкДцЙцЛЎ
ЁЁЁЁзїЮЊвЛИі JVM НјГЬЃЌExecutor ЕФФкДцЙмРэНЈСЂдк JVM ЕФФкДцЙмРэжЎЩЯЃЌSpark
Жд JVM ЕФЖбФк(On-heap)ПеМфНјааСЫИќЮЊЯъЯИЕФЗжХфЃЌвдГфЗжРћгУФкДцЁЃЭЌЪБЃЌSpark в§ШыСЫЖбЭт(Off-heap)ФкДцЃЌЪЙжЎПЩвджБНгдкЙЄзїНкЕуЕФЯЕЭГФкДцжаПЊБйПеМфЃЌНјвЛВНгХЛЏСЫФкДцЕФЪЙгУЁЃ

ЁЁЁЁЭМ 1 . ЖбФкКЭЖбЭтФкДцЪОвтЭМ
ЁЁЁЁ1.1 ЖбФкФкДц
ЁЁЁЁЖбФкФкДцЕФДѓаЁЃЌгЩ Spark гІгУГЬађЦєЖЏЪБЕФ ЈCexecutor-memory Лђ spark.executor.memory
ВЮЪ§ХфжУЁЃExecutor ФкдЫааЕФВЂЗЂШЮЮёЙВЯэ JVM ЖбФкФкДцЃЌетаЉШЮЮёдкЛКДц RDD Ъ§ОнКЭЙуВЅ(Broadcast)Ъ§ОнЪБеМгУЕФФкДцБЛЙцЛЎЮЊДцДЂ(Storage)ФкДцЃЌЖјетаЉШЮЮёдкжДаа
Shuffle ЪБеМгУЕФФкДцБЛЙцЛЎЮЊжДаа(Execution)ФкДцЃЌЪЃгрЕФВПЗжВЛзіЬиЪтЙцЛЎЃЌФЧаЉ Spark
ФкВПЕФЖдЯѓЪЕР§ЃЌЛђепгУЛЇЖЈвхЕФ Spark гІгУГЬађжаЕФЖдЯѓЪЕР§ЃЌОљеМгУЪЃгрЕФПеМфЁЃВЛЭЌЕФЙмРэФЃЪНЯТЃЌетШ§ВПЗжеМгУЕФПеМфДѓаЁИїВЛЯрЭЌ(ЯТУцЕк
2 аЁНкЛсНјааНщЩм)ЁЃ
ЁЁЁЁSpark ЖдЖбФкФкДцЕФЙмРэЪЧвЛжжТпМЩЯЕФЁБЙцЛЎЪНЁБЕФЙмРэЃЌвђЮЊЖдЯѓЪЕР§еМгУФкДцЕФЩъЧыКЭЪЭЗХЖМгЩ
JVM ЭъГЩЃЌSpark жЛФмдкЩъЧыКѓКЭЪЭЗХЧАМЧТМетаЉФкДцЃЌЮвУЧРДПДЦфОпЬхСїГЬЃК
ЁЁЁЁЩъЧыФкДцЃК
ЁЁЁЁSpark дкДњТыжа new вЛИіЖдЯѓЪЕР§
ЁЁЁЁJVM ДгЖбФкФкДцЗжХфПеМфЃЌДДНЈЖдЯѓВЂЗЕЛиЖдЯѓв§гУ
ЁЁЁЁSpark БЃДцИУЖдЯѓЕФв§гУЃЌМЧТМИУЖдЯѓеМгУЕФФкДц
ЁЁЁЁЪЭЗХФкДцЃК
ЁЁЁЁSpark МЧТМИУЖдЯѓЪЭЗХЕФФкДцЃЌЩОГ§ИУЖдЯѓЕФв§гУ
ЁЁЁЁЕШД§ JVM ЕФРЌЛјЛиЪеЛњжЦЪЭЗХИУЖдЯѓеМгУЕФЖбФкФкДц
ЁЁЁЁЮвУЧжЊЕРЃЌJVM ЕФЖдЯѓПЩвдвдађСаЛЏЕФЗНЪНДцДЂЃЌађСаЛЏЕФЙ§ГЬЪЧНЋЖдЯѓзЊЛЛЮЊЖўНјжЦзжНкСїЃЌБОжЪЩЯПЩвдРэНтЮЊНЋЗЧСЌајПеМфЕФСДЪНДцДЂзЊЛЏЮЊСЌајПеМфЛђПщДцДЂЃЌдкЗУЮЪЪБдђашвЊНјааађСаЛЏЕФФцЙ§ГЬЁЊЁЊЗДађСаЛЏЃЌНЋзжНкСїзЊЛЏЮЊЖдЯѓЃЌађСаЛЏЕФЗНЪНПЩвдНкЪЁДцДЂПеМфЃЌЕЋдіМгСЫДцДЂКЭЖСШЁЪБКђЕФМЦЫуПЊЯњЁЃ
ЁЁЁЁЖдгк Spark жаађСаЛЏЕФЖдЯѓЃЌгЩгкЪЧзжНкСїЕФаЮЪНЃЌЦфеМгУЕФФкДцДѓаЁПЩжБНгМЦЫуЃЌЖјЖдгкЗЧађСаЛЏЕФЖдЯѓЃЌЦфеМгУЕФФкДцЪЧЭЈЙ§жмЦкадЕиВЩбљНќЫЦЙРЫуЖјЕУЃЌМДВЂВЛЪЧУПДЮаТдіЕФЪ§ОнЯюЖМЛсМЦЫувЛДЮеМгУЕФФкДцДѓаЁЃЌетжжЗНЗЈНЕЕЭСЫЪБМфПЊЯњЕЋЪЧгаПЩФмЮѓВюНЯДѓЃЌЕМжТФГвЛЪБПЬЕФЪЕМЪФкДцгаПЩФмдЖдЖГЌГідЄЦк[2]ЁЃДЫЭтЃЌдкБЛ
Spark БъМЧЮЊЪЭЗХЕФЖдЯѓЪЕР§ЃЌКмгаПЩФмдкЪЕМЪЩЯВЂУЛгаБЛ JVM ЛиЪеЃЌЕМжТЪЕМЪПЩгУЕФФкДцаЁгк Spark
МЧТМЕФПЩгУФкДцЁЃЫљвд Spark ВЂВЛФмзМШЗМЧТМЪЕМЪПЩгУЕФЖбФкФкДцЃЌДгЖјвВОЭЮоЗЈЭъШЋБмУтФкДцвчГі(OOM,
Out of Memory)ЕФвьГЃЁЃ
ЁЁЁЁЫфШЛВЛФмОЋзМПижЦЖбФкФкДцЕФЩъЧыКЭЪЭЗХЃЌЕЋ Spark ЭЈЙ§ЖдДцДЂФкДцКЭжДааФкДцИїздЖРСЂЕФЙцЛЎЙмРэЃЌПЩвдОіЖЈЪЧЗёвЊдкДцДЂФкДцРяЛКДцаТЕФ
RDDЃЌвдМАЪЧЗёЮЊаТЕФШЮЮёЗжХфжДааФкДцЃЌдквЛЖЈГЬЖШЩЯПЩвдЬсЩ§ФкДцЕФРћгУТЪЃЌМѕЩйвьГЃЕФГіЯжЁЃ
ЁЁЁЁ1.2 ЖбЭтФкДц
ЁЁЁЁЮЊСЫНјвЛВНгХЛЏФкДцЕФЪЙгУвдМАЬсИп Shuffle ЪБХХађЕФаЇТЪЃЌSpark в§ШыСЫЖбЭт(Off-heap)ФкДцЃЌЪЙжЎПЩвджБНгдкЙЄзїНкЕуЕФЯЕЭГФкДцжаПЊБйПеМфЃЌДцДЂОЙ§ађСаЛЏЕФЖўНјжЦЪ§ОнЁЃРћгУ
JDK Unsafe API(Дг Spark 2.0 ПЊЪМЃЌдкЙмРэЖбЭтЕФДцДЂФкДцЪБВЛдйЛљгк TachyonЃЌЖјЪЧгыЖбЭтЕФжДааФкДцвЛбљЃЌЛљгк
JDK Unsafe API ЪЕЯж[3])ЃЌSpark ПЩвджБНгВйзїЯЕЭГЖбЭтФкДцЃЌМѕЩйСЫВЛБивЊЕФФкДцПЊЯњЃЌвдМАЦЕЗБЕФ
GC ЩЈУшКЭЛиЪеЃЌЬсЩ§СЫДІРэадФмЁЃЖбЭтФкДцПЩвдБЛОЋШЗЕиЩъЧыКЭЪЭЗХЃЌЖјЧвађСаЛЏЕФЪ§ОнеМгУЕФПеМфПЩвдБЛОЋШЗМЦЫуЃЌЫљвдЯрБШЖбФкФкДцРДЫЕНЕЕЭСЫЙмРэЕФФбЖШЃЌвВНЕЕЭСЫЮѓВюЁЃ
ЁЁЁЁдкФЌШЯЧщПіЯТЖбЭтФкДцВЂВЛЦєгУЃЌПЩЭЈЙ§ХфжУ spark.memory.offHeap.enabled
ВЮЪ§ЦєгУЃЌВЂгЩ spark.memory.offHeap.size ВЮЪ§ЩшЖЈЖбЭтПеМфЕФДѓаЁЁЃГ§СЫУЛга
other ПеМфЃЌЖбЭтФкДцгыЖбФкФкДцЕФЛЎЗжЗНЪНЯрЭЌЃЌЫљгадЫаажаЕФВЂЗЂШЮЮёЙВЯэДцДЂФкДцКЭжДааФкДцЁЃ
ЁЁЁЁ1.3 ФкДцЙмРэНгПк
ЁЁЁЁSpark ЮЊДцДЂФкДцКЭжДааФкДцЕФЙмРэЬсЙЉСЫЭГвЛЕФНгПкЁЊЁЊMemoryManagerЃЌЭЌвЛИі
Executor ФкЕФШЮЮёЖМЕїгУетИіНгПкЕФЗНЗЈРДЩъЧыЛђЪЭЗХФкДц:
ЁЁЁЁЧхЕЅ 1 . ФкДцЙмРэНгПкЕФжївЊЗНЗЈ
//ЩъЧыДцДЂФкДц
def acquireStorageMemory(blockId: BlockId,
numBytes: Long, memoryMode: MemoryMode):
Boolean
//ЩъЧыеЙПЊФкДц
def acquireUnrollMemory(blockId: BlockId,
numBytes:
Long, memoryMode: MemoryMode): Boolean
//ЩъЧыжДааФкДц
def acquireExecutionMemory(numBytes: Long,
taskAttemptId:
Long, memoryMode: MemoryMode): Long
//ЪЭЗХДцДЂФкДц
def releaseStorageMemory(numBytes: Long,
memoryMode:
MemoryMode): Unit
//ЪЭЗХжДааФкДц
def releaseExecutionMemory(numBytes: Long,
taskAttemptId:
Long, memoryMode: MemoryMode): Unit
//ЪЭЗХеЙПЊФкДц
def releaseUnrollMemory(numBytes: Long,
memoryMode:
MemoryMode): Unit |
ЮвУЧПДЕНЃЌдкЕїгУетаЉЗНЗЈЪБЖМашвЊжИЖЈЦфФкДцФЃЪН(MemoryMode)ЃЌетИіВЮЪ§ОіЖЈСЫЪЧдкЖбФкЛЙЪЧЖбЭтЭъГЩетДЮВйзїЁЃ
ЁЁЁЁMemoryManager ЕФОпЬхЪЕЯжЩЯЃЌSpark 1.6 жЎКѓФЌШЯЮЊЭГвЛЙмРэ(Unified
Memory Manager)ЗНЪНЃЌ1.6 жЎЧАВЩгУЕФОВЬЌЙмРэ(Static Memory Manager)ЗНЪНШдБЛБЃСєЃЌПЩЭЈЙ§ХфжУ
spark.memory.useLegacyMode ВЮЪ§ЦєгУЁЃСНжжЗНЪНЕФЧјБ№дкгкЖдПеМфЗжХфЕФЗНЪНЃЌЯТУцЕФЕк
2 аЁНкЛсЗжБ№ЖдетСНжжЗНЪННјааНщЩмЁЃ
ЁЁЁЁ2 . ФкДцПеМфЗжХф
ЁЁЁЁ2.1 ОВЬЌФкДцЙмРэ
ЁЁЁЁдк Spark зюГѕВЩгУЕФОВЬЌФкДцЙмРэЛњжЦЯТЃЌДцДЂФкДцЁЂжДааФкДцКЭЦфЫћФкДцЕФДѓаЁдк Spark
гІгУГЬађдЫааЦкМфОљЮЊЙЬЖЈЕФЃЌЕЋгУЛЇПЩвдгІгУГЬађЦєЖЏЧАНјааХфжУЃЌЖбФкФкДцЕФЗжХфШчЭМ 2 ЫљЪОЃК
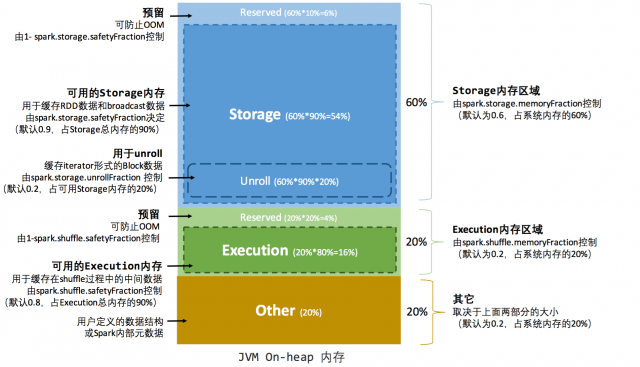
ЭМ 2 . ОВЬЌФкДцЙмРэЭМЪОЁЊЁЊЖбФк
ЁЁЁЁПЩвдПДЕНЃЌПЩгУЕФЖбФкФкДцЕФДѓаЁашвЊАДееЯТУцЕФЗНЪНМЦЫуЃК
ЁЁЁЁЧхЕЅ 2 . ПЩгУЖбФкФкДцПеМф
ПЩгУЕФДцДЂФкДц = systemMaxMemory * spark.storage
.memoryFraction * spark.storage.safetyFraction
ПЩгУЕФжДааФкДц = systemMaxMemory * spark.shuffle.
memoryFraction * spark.shuffle.safetyFraction |
Цфжа systemMaxMemory ШЁОігкЕБЧА JVM ЖбФкФкДцЕФДѓаЁЃЌзюКѓПЩгУЕФжДааФкДцЛђепДцДЂФкДцвЊдкДЫЛљДЁЩЯгыИїздЕФ
memoryFraction ВЮЪ§КЭ safetyFraction ВЮЪ§ЯрГЫЕУГіЁЃЩЯЪіМЦЫуЙЋЪНжаЕФСНИі
safetyFraction ВЮЪ§ЃЌЦфвтвхдкгкдкТпМЩЯдЄСєГі 1-safetyFraction етУДвЛПщБЃЯеЧјгђЃЌНЕЕЭвђЪЕМЪФкДцГЌГіЕБЧАдЄЩшЗЖЮЇЖјЕМжТ
OOM ЕФЗчЯе(ЩЯЮФЬсЕНЃЌЖдгкЗЧађСаЛЏЖдЯѓЕФФкДцВЩбљЙРЫуЛсВњЩњЮѓВю)ЁЃжЕЕУзЂвтЕФЪЧЃЌетИідЄСєЕФБЃЯеЧјгђНіНіЪЧвЛжжТпМЩЯЕФЙцЛЎЃЌдкОпЬхЪЙгУЪБ
Spark ВЂУЛгаЧјБ№ЖдД§ЃЌКЭЁБЦфЫќФкДцЁБвЛбљНЛИјСЫ JVM ШЅЙмРэЁЃ
ЁЁЁЁЖбЭтЕФПеМфЗжХфНЯЮЊМђЕЅЃЌжЛгаДцДЂФкДцКЭжДааФкДцЃЌШчЭМ 3 ЫљЪОЁЃПЩгУЕФжДааФкДцКЭДцДЂФкДцеМгУЕФПеМфДѓаЁжБНггЩВЮЪ§
spark.memory.storageFraction ОіЖЈЃЌгЩгкЖбЭтФкДцеМгУЕФПеМфПЩвдБЛОЋШЗМЦЫуЃЌЫљвдЮоашдйЩшЖЈБЃЯеЧјгђЁЃ
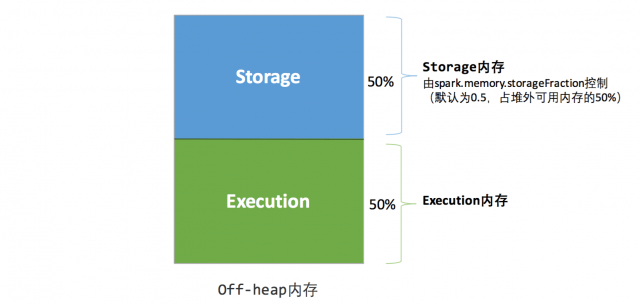
ЁЁЁЁЭМ 3 . ОВЬЌФкДцЙмРэЭМЪОЁЊЁЊЖбЭт
ЁЁЁЁОВЬЌФкДцЙмРэЛњжЦЪЕЯжЦ№РДНЯЮЊМђЕЅЃЌЕЋШчЙћгУЛЇВЛЪьЯЄ Spark ЕФДцДЂЛњжЦЃЌЛђУЛгаИљОнОпЬхЕФЪ§ОнЙцФЃКЭМЦЫуШЮЮёЛђзіЯргІЕФХфжУЃЌКмШнвздьГЩЁБвЛАыКЃЫЎЃЌвЛАыЛ№бцЁБЕФОжУцЃЌМДДцДЂФкДцКЭжДааФкДцжаЕФвЛЗНЪЃгрДѓСПЕФПеМфЃЌЖјСэвЛЗНШДдчдчБЛеМТњЃЌВЛЕУВЛЬдЬЛђвЦГіОЩЕФФкШнвдДцДЂаТЕФФкШнЁЃгЩгкаТЕФФкДцЙмРэЛњжЦЕФГіЯжЃЌетжжЗНЪНФПЧАвбОКмЩйгаПЊЗЂепЪЙгУЃЌГігкМцШнОЩАцБОЕФгІгУГЬађЕФФПЕФЃЌSpark
ШдШЛБЃСєСЫЫќЕФЪЕЯжЁЃ
ЁЁЁЁ2.2 ЭГвЛФкДцЙмРэ
ЁЁЁЁSpark 1.6 жЎКѓв§ШыЕФЭГвЛФкДцЙмРэЛњжЦЃЌгыОВЬЌФкДцЙмРэЕФЧјБ№дкгкДцДЂФкДцКЭжДааФкДцЙВЯэЭЌвЛПщПеМфЃЌПЩвдЖЏЬЌеМгУЖдЗНЕФПеЯаЧјгђЃЌШчЭМ
4 КЭЭМ 5 ЫљЪО
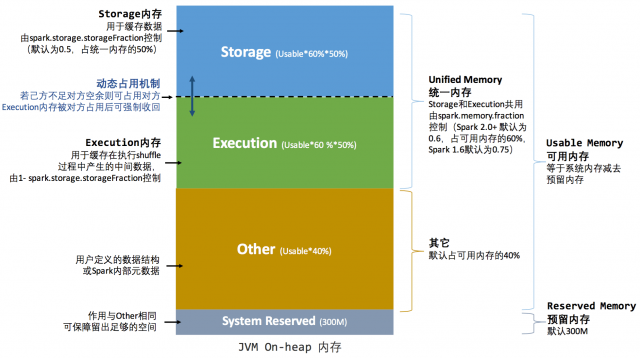
ЁЁЁЁЭМ 4 . ЭГвЛФкДцЙмРэЭМЪОЁЊЁЊЖбФк

ЁЁЁЁЭМ 5 . ЭГвЛФкДцЙмРэЭМЪОЁЊЁЊЖбЭт
ЁЁЁЁЦфжазюживЊЕФгХЛЏдкгкЖЏЬЌеМгУЛњжЦЃЌЦфЙцдђШчЯТЃК
ЁЁЁЁЩшЖЈЛљБОЕФДцДЂФкДцКЭжДааФкДцЧјгђ(spark.storage.storageFraction
ВЮЪ§)ЃЌИУЩшЖЈШЗЖЈСЫЫЋЗНИїздгЕгаЕФПеМфЕФЗЖЮЇ
ЁЁЁЁЫЋЗНЕФПеМфЖМВЛзуЪБЃЌдђДцДЂЕНгВХЬ;ШєМКЗНПеМфВЛзуЖјЖдЗНПегрЪБЃЌПЩНшгУЖдЗНЕФПеМф;(ДцДЂПеМфВЛзуЪЧжИВЛзувдЗХЯТвЛИіЭъећЕФ
Block)
ЁЁЁЁжДааФкДцЕФПеМфБЛЖдЗНеМгУКѓЃЌПЩШУЖдЗННЋеМгУЕФВПЗжзЊДцЕНгВХЬЃЌШЛКѓЁБЙщЛЙЁБНшгУЕФПеМф
ЁЁЁЁДцДЂФкДцЕФПеМфБЛЖдЗНеМгУКѓЃЌЮоЗЈШУЖдЗНЁБЙщЛЙЁБЃЌвђЮЊашвЊПМТЧ Shuffle Й§ГЬжаЕФКмЖрвђЫиЃЌЪЕЯжЦ№РДНЯЮЊИДдг[4]
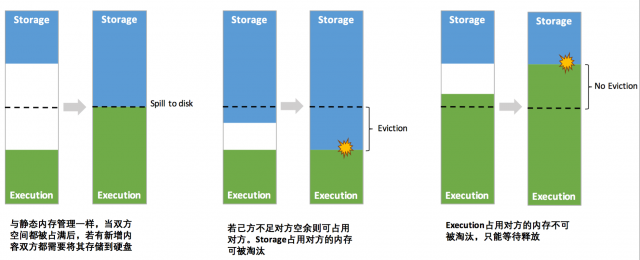
ЁЁЁЁЭМ 6 . ЖЏЬЌеМгУЛњжЦЭМЪО
ЁЁЁЁЦОНшЭГвЛФкДцЙмРэЛњжЦЃЌSpark дквЛЖЈГЬЖШЩЯЬсИпСЫЖбФкКЭЖбЭтФкДцзЪдДЕФРћгУТЪЃЌНЕЕЭСЫПЊЗЂепЮЌЛЄ
Spark ФкДцЕФФбЖШЃЌЕЋВЂВЛвтЮЖзХПЊЗЂепПЩвдИпеэЮогЧЁЃЦЉШчЃЌЫљвдШчЙћДцДЂФкДцЕФПеМфЬЋДѓЛђепЫЕЛКДцЕФЪ§ОнЙ§ЖрЃЌЗДЖјЛсЕМжТЦЕЗБЕФШЋСПРЌЛјЛиЪеЃЌНЕЕЭШЮЮёжДааЪБЕФадФмЃЌвђЮЊЛКДцЕФ
RDD Ъ§ОнЭЈГЃЖМЪЧГЄЦкзЄСєФкДцЕФ [5] ЁЃЫљвдвЊЯыГфЗжЗЂЛг Spark ЕФадФмЃЌашвЊПЊЗЂепНјвЛВНСЫНтДцДЂФкДцКЭжДааФкДцИїздЕФЙмРэЗНЪНКЭЪЕЯждРэЁЃ
ЁЁЁЁ3. ДцДЂФкДцЙмРэ
ЁЁЁЁ3.1 RDD ЕФГжОУЛЏЛњжЦ
ЁЁЁЁЕЏадЗжВМЪНЪ§ОнМЏ(RDD)зїЮЊ Spark зюИљБОЕФЪ§ОнГщЯѓЃЌЪЧжЛЖСЕФЗжЧјМЧТМ(Partition)ЕФМЏКЯЃЌжЛФмЛљгкдкЮШЖЈЮяРэДцДЂжаЕФЪ§ОнМЏЩЯДДНЈЃЌЛђепдкЦфЫћвбгаЕФ
RDD ЩЯжДаазЊЛЛ(Transformation)ВйзїВњЩњвЛИіаТЕФ RDDЁЃзЊЛЛКѓЕФ RDD гыдЪМЕФ
RDD жЎМфВњЩњЕФвРРЕЙиЯЕЃЌЙЙГЩСЫбЊЭГ(Lineage)ЁЃЦОНшбЊЭГЃЌSpark БЃжЄСЫУПвЛИі RDD
ЖМПЩвдБЛжиаТЛжИДЁЃЕЋ RDD ЕФЫљгазЊЛЛЖМЪЧЖшадЕФЃЌМДжЛгаЕБвЛИіЗЕЛиНсЙћИј Driver ЕФааЖЏ(Action)ЗЂЩњЪБЃЌSpark
ВХЛсДДНЈШЮЮёЖСШЁ RDDЃЌШЛКѓеце§ДЅЗЂзЊЛЛЕФжДааЁЃ
ЁЁЁЁTask дкЦєЖЏжЎГѕЖСШЁвЛИіЗжЧјЪБЃЌЛсЯШХаЖЯетИіЗжЧјЪЧЗёвбОБЛГжОУЛЏЃЌШчЙћУЛгадђашвЊМьВщ Checkpoint
ЛђАДеебЊЭГжиаТМЦЫуЁЃЫљвдШчЙћвЛИі RDD ЩЯвЊжДааЖрДЮааЖЏЃЌПЩвддкЕквЛДЮааЖЏжаЪЙгУ persist
Лђ cache ЗНЗЈЃЌдкФкДцЛђДХХЬжаГжОУЛЏЛђЛКДцетИі RDDЃЌДгЖјдкКѓУцЕФааЖЏЪБЬсЩ§МЦЫуЫйЖШЁЃЪТЪЕЩЯЃЌcache
ЗНЗЈЪЧЪЙгУФЌШЯЕФ MEMORY_ONLY ЕФДцДЂМЖБ№НЋ RDD ГжОУЛЏЕНФкДцЃЌЙЪЛКДцЪЧвЛжжЬиЪтЕФГжОУЛЏЁЃ
ЖбФкКЭЖбЭтДцДЂФкДцЕФЩшМЦЃЌБуПЩвдЖдЛКДц RDD ЪБЪЙгУЕФФкДцзіЭГвЛЕФЙцЛЎКЭЙм Рэ (ДцДЂФкДцЕФЦфЫћгІгУГЁОАЃЌШчЛКДц
broadcast Ъ§ОнЃЌднЪБВЛдкБОЮФЕФЬжТлЗЖЮЇжЎФк)ЁЃ
ЁЁЁЁRDD ЕФГжОУЛЏгЩ Spark ЕФ Storage ФЃПщ [7] ИКд№ЃЌЪЕЯжСЫ RDD гыЮяРэДцДЂЕФНтёюКЯЁЃStorage
ФЃПщИКд№ЙмРэ Spark дкМЦЫуЙ§ГЬжаВњЩњЕФЪ§ОнЃЌНЋФЧаЉдкФкДцЛђДХХЬЁЂдкБОЕиЛђдЖГЬДцШЁЪ§ОнЕФЙІФмЗтзАСЫЦ№РДЁЃдкОпЬхЪЕЯжЪБ
Driver ЖЫКЭ Executor ЖЫЕФ Storage ФЃПщЙЙГЩСЫжїДгЪНЕФМмЙЙЃЌМД Driver
ЖЫЕФ BlockManager ЮЊ MasterЃЌExecutor ЖЫЕФ BlockManager
ЮЊ SlaveЁЃStorage ФЃПщдкТпМЩЯвд Block ЮЊЛљБОДцДЂЕЅЮЛЃЌRDD ЕФУПИі Partition
ОЙ§ДІРэКѓЮЈвЛЖдгІвЛИі Block(BlockId ЕФИёЪНЮЊ rdd_RDD-ID_PARTITION-ID
)ЁЃMaster ИКд№ећИі Spark гІгУГЬађЕФ Block ЕФдЊЪ§ОнаХЯЂЕФЙмРэКЭЮЌЛЄЃЌЖј Slave
ашвЊНЋ Block ЕФИќаТЕШзДЬЌЩЯБЈЕН MasterЃЌЭЌЪБНгЪе Master ЕФУќСюЃЌР§ШчаТдіЛђЩОГ§вЛИі
RDDЁЃ
ЁЁЁЁЭМ 7 . Storage ФЃПщЪОвтЭМ
ЁЁЁЁдкЖд RDD ГжОУЛЏЪБЃЌSpark ЙцЖЈСЫ MEMORY_ONLYЁЂMEMORY_AND_DISK
ЕШ 7 жжВЛЭЌЕФ ДцДЂМЖБ№ ЃЌЖјДцДЂМЖБ№ЪЧвдЯТ 5 ИіБфСПЕФзщКЯЃК
ЁЁЁЁЧхЕЅ 3 . ДцДЂМЖБ№
class StorageLevel private(
private var _useDisk: Boolean, //ДХХЬ
private var _useMemory: Boolean, //етРяЦфЪЕЪЧжИЖбФкФкДц
private var _useOffHeap: Boolean, //ЖбЭтФкДц
private var _deserialized: Boolean, //ЪЧЗёЮЊЗЧађСаЛЏ
private var _replication: Int = 1 //ИББОИіЪ§
) |
ЁЁЁЁ
ЭЈЙ§ЖдЪ§ОнНсЙЙЕФЗжЮіЃЌПЩвдПДГіДцДЂМЖБ№ДгШ§ИіЮЌЖШЖЈвхСЫ RDD ЕФ Partition(ЭЌЪБвВОЭЪЧ
Block)ЕФДцДЂЗНЪНЃК
ЁЁЁЁДцДЂЮЛжУЃКДХХЬ/ЖбФкФкДц/ЖбЭтФкДцЁЃШч MEMORY_AND_DISK ЪЧЭЌЪБдкДХХЬКЭЖбФкФкДцЩЯДцДЂЃЌЪЕЯжСЫШпгрБИЗнЁЃOFF_HEAP
дђЪЧжЛдкЖбЭтФкДцДцДЂЃЌФПЧАбЁдёЖбЭтФкДцЪБВЛФмЭЌЪБДцДЂЕНЦфЫћЮЛжУЁЃ
ЁЁЁЁДцДЂаЮЪНЃКBlock ЛКДцЕНДцДЂФкДцКѓЃЌЪЧЗёЮЊЗЧађСаЛЏЕФаЮЪНЁЃШч MEMORY_ONLY ЪЧЗЧађСаЛЏЗНЪНДцДЂЃЌOFF_HEAP
ЪЧађСаЛЏЗНЪНДцДЂЁЃ
ЁЁЁЁИББОЪ§СПЃКДѓгк 1 ЪБашвЊдЖГЬШпгрБИЗнЕНЦфЫћНкЕуЁЃШч DISK_ONLY_2 ашвЊдЖГЬБИЗн 1
ИіИББОЁЃ
ЁЁЁЁ3.2 RDD ЛКДцЕФЙ§ГЬ
ЁЁЁЁRDD дкЛКДцЕНДцДЂФкДцжЎЧАЃЌPartition жаЕФЪ§ОнвЛАувдЕќДњЦї(Iterator)ЕФЪ§ОнНсЙЙРДЗУЮЪЃЌетЪЧ
Scala гябджавЛжжБщРњЪ§ОнМЏКЯЕФЗНЗЈЁЃЭЈЙ§ Iterator ПЩвдЛёШЁЗжЧјжаУПвЛЬѕађСаЛЏЛђепЗЧађСаЛЏЕФЪ§ОнЯю(Record)ЃЌетаЉ
Record ЕФЖдЯѓЪЕР§дкТпМЩЯеМгУСЫ JVM ЖбФкФкДцЕФ other ВПЗжЕФПеМфЃЌЭЌвЛ Partition
ЕФВЛЭЌ Record ЕФПеМфВЂВЛСЌајЁЃ
ЁЁЁЁRDD дкЛКДцЕНДцДЂФкДцжЎКѓЃЌPartition БЛзЊЛЛГЩ BlockЃЌRecord дкЖбФкЛђЖбЭтДцДЂФкДцжаеМгУвЛПщСЌајЕФПеМфЁЃНЋPartitionгЩВЛСЌајЕФДцДЂПеМфзЊЛЛЮЊСЌајДцДЂПеМфЕФЙ§ГЬЃЌSparkГЦжЎЮЊЁБеЙПЊЁБ(Unroll)ЁЃBlock
гаађСаЛЏКЭЗЧађСаЛЏСНжжДцДЂИёЪНЃЌОпЬхвдФФжжЗНЪНШЁОігкИУ RDD ЕФДцДЂМЖБ№ЁЃЗЧЗДађСаЛЏЕФ Block
вдвЛжж DeserializedMemoryEntry ЕФЪ§ОнНсЙЙЖЈвхЃЌгУвЛИіЪ§зщДцДЂЫљгаЕФ Java
ЖдЯѓЃЌЗЧађСаЛЏЕФ Block дђвд SerializedMemoryEntry ЕФЪ§ОнНсЙЙЖЈвхЃЌгУзжНкЛКГхЧј(ByteBuffer)РДДцДЂЖўНјжЦЪ§ОнЁЃУПИі
Executor ЕФ Storage ФЃПщгУвЛИіСДЪН Map НсЙЙ(LinkedHashMap)РДЙмРэЖбФкКЭЖбЭтДцДЂФкДцжаЫљгаЕФ
Block ЖдЯѓЕФЪЕР§[6]ЃЌЖдетИі LinkedHashMap аТдіКЭЩОГ§МфНгМЧТМСЫФкДцЕФЩъЧыКЭЪЭЗХЁЃ
ЁЁЁЁвђЮЊВЛФмБЃжЄДцДЂПеМфПЩвдвЛДЮШнФЩ Iterator жаЕФЫљгаЪ§ОнЃЌЕБЧАЕФМЦЫуШЮЮёдк
Unroll ЪБвЊЯђ MemoryManager ЩъЧызуЙЛЕФ Unroll ПеМфРДСйЪБеМЮЛЃЌПеМфВЛзудђ
Unroll ЪЇАмЃЌПеМфзуЙЛЪБПЩвдМЬајНјааЁЃЖдгкађСаЛЏЕФ PartitionЃЌЦфЫљашЕФ Unroll
ПеМфПЩвджБНгРлМгМЦЫуЃЌвЛДЮЩъЧыЁЃЖјЗЧађСаЛЏЕФ Partition дђвЊдкБщРњ Record ЕФЙ§ГЬжавРДЮЩъЧыЃЌМДУПЖСШЁвЛЬѕ
RecordЃЌВЩбљЙРЫуЦфЫљашЕФ Unroll ПеМфВЂНјааЩъЧыЃЌПеМфВЛзуЪБПЩвджаЖЯЃЌЪЭЗХвбеМгУЕФ Unroll
ПеМфЁЃШчЙћзюже Unroll ГЩЙІЃЌЕБЧА Partition ЫљеМгУЕФ Unroll ПеМфБЛзЊЛЛЮЊе§ГЃЕФЛКДц
RDD ЕФДцДЂПеМфЃЌШчЯТЭМ 8 ЫљЪОЁЃ
ЁЁЁЁдкЭМ 3 КЭЭМ 5 жаПЩвдПДЕНЃЌдкОВЬЌФкДцЙмРэЪБЃЌSpark дкДцДЂФкДцжазЈУХЛЎЗжСЫвЛПщ Unroll
ПеМфЃЌЦфДѓаЁЪЧЙЬЖЈЕФЃЌЭГвЛФкДцЙмРэЪБдђУЛгаЖд Unroll ПеМфНјааЬиБ№ЧјЗжЃЌЕБДцДЂПеМфВЛзуЪБЛсИљОнЖЏЬЌеМгУЛњжЦНјааДІРэЁЃ
ЁЁЁЁ3.3 ЬдЬКЭТфХЬ
ЁЁЁЁгЩгкЭЌвЛИі Executor ЕФЫљгаЕФМЦЫуШЮЮёЙВЯэгаЯоЕФДцДЂФкДцПеМфЃЌЕБгааТЕФ Block ашвЊЛКДцЕЋЪЧЪЃгрПеМфВЛзуЧвЮоЗЈЖЏЬЌеМгУЪБЃЌОЭвЊЖд
LinkedHashMap жаЕФОЩ Block НјааЬдЬ(Eviction)ЃЌЖјБЛЬдЬЕФ Block
ШчЙћЦфДцДЂМЖБ№жаЭЌЪБАќКЌДцДЂЕНДХХЬЕФвЊЧѓЃЌдђвЊЖдЦфНјааТфХЬ(Drop)ЃЌЗёдђжБНгЩОГ§ИУ BlockЁЃ
ЁЁЁЁДцДЂФкДцЕФЬдЬЙцдђЮЊЃК
ЁЁЁЁБЛЬдЬЕФОЩ Block вЊгыаТ Block ЕФ MemoryMode ЯрЭЌЃЌМДЭЌЪєгкЖбЭтЛђЖбФкФкДц
ЁЁЁЁаТОЩ Block ВЛФмЪєгкЭЌвЛИі RDDЃЌБмУтбЛЗЬдЬ
ЁЁЁЁОЩ Block ЫљЪє RDD ВЛФмДІгкБЛЖСзДЬЌЃЌБмУтв§ЗЂвЛжТадЮЪЬт
ЁЁЁЁБщРњ LinkedHashMap жа BlockЃЌАДеезюНќзюЩйЪЙгУ(LRU)ЕФЫГађЬдЬЃЌжБЕНТњзуаТ
Block ЫљашЕФПеМфЁЃЦфжа LRU ЪЧ LinkedHashMap ЕФЬиадЁЃ
ЁЁЁЁТфХЬЕФСїГЬдђБШНЯМђЕЅЃЌШчЙћЦфДцДЂМЖБ№ЗћКЯ_useDisk ЮЊ true ЕФЬѕМўЃЌдйИљОнЦф_deserialized
ХаЖЯЪЧЗёЪЧЗЧађСаЛЏЕФаЮЪНЃЌШєЪЧдђЖдЦфНјааађСаЛЏЃЌзюКѓНЋЪ§ОнДцДЂЕНДХХЬЃЌдк Storage ФЃПщжаИќаТЦфаХЯЂЁЃ
ЁЁЁЁ4. жДааФкДцЙмРэ
ЁЁЁЁ4.1 ЖрШЮЮёМфФкДцЗжХф
ЁЁЁЁExecutor ФкдЫааЕФШЮЮёЭЌбљЙВЯэжДааФкДцЃЌSpark гУвЛИі HashMap НсЙЙБЃДцСЫШЮЮёЕНФкДцКФЗбЕФгГЩфЁЃУПИіШЮЮёПЩеМгУЕФжДааФкДцДѓаЁЕФЗЖЮЇЮЊ
1/2N ~ 1/NЃЌЦфжа N ЮЊЕБЧА Executor Фке§дкдЫааЕФШЮЮёЕФИіЪ§ЁЃУПИіШЮЮёдкЦєЖЏжЎЪБЃЌвЊЯђ
MemoryManager ЧыЧѓЩъЧызюЩйЮЊ 1/2N ЕФжДааФкДцЃЌШчЙћВЛФмБЛТњзувЊЧѓдђИУШЮЮёБЛзшШћЃЌжБЕНгаЦфЫћШЮЮёЪЭЗХСЫзуЙЛЕФжДааФкДцЃЌИУШЮЮёВХПЩвдБЛЛНабЁЃ
ЁЁЁЁ4.2 Shuffle ЕФФкДцеМгУ
ЁЁЁЁжДааФкДцжївЊгУРДДцДЂШЮЮёдкжДаа Shuffle ЪБеМгУЕФФкДцЃЌShuffle ЪЧАДеевЛЖЈЙцдђЖд
RDD Ъ§ОнжиаТЗжЧјЕФЙ§ГЬЃЌЮвУЧРДПД Shuffle ЕФ Write КЭ Read СННзЖЮЖджДааФкДцЕФЪЙгУЃК
ЁЁЁЁShuffle Write
ЁЁЁЁШєдк map ЖЫбЁдёЦеЭЈЕФХХађЗНЪНЃЌЛсВЩгУ ExternalSorter НјааЭтХХЃЌдкФкДцжаДцДЂЪ§ОнЪБжївЊеМгУЖбФкжДааПеМфЁЃ
ЁЁЁЁШєдк map ЖЫбЁдё Tungsten ЕФХХађЗНЪНЃЌдђВЩгУ ShuffleExternalSorter
жБНгЖдвдађСаЛЏаЮЪНДцДЂЕФЪ§ОнХХађЃЌдкФкДцжаДцДЂЪ§ОнЪБПЩвдеМгУЖбЭтЛђЖбФкжДааПеМфЃЌШЁОігкгУЛЇЪЧЗёПЊЦєСЫЖбЭтФкДцвдМАЖбЭтжДааФкДцЪЧЗёзуЙЛЁЃ
ЁЁЁЁShuffle Read
ЁЁЁЁдкЖд reduce ЖЫЕФЪ§ОнНјааОлКЯЪБЃЌвЊНЋЪ§ОнНЛИј Aggregator ДІРэЃЌдкФкДцжаДцДЂЪ§ОнЪБеМгУЖбФкжДааПеМфЁЃ
ЁЁЁЁШчЙћашвЊНјаазюжеНсЙћХХађЃЌдђвЊНЋдйДЮНЋЪ§ОнНЛИј ExternalSorter ДІРэЃЌеМгУЖбФкжДааПеМфЁЃ
ЁЁЁЁдк ExternalSorter КЭ Aggregator жаЃЌSpark ЛсЪЙгУвЛжжНа AppendOnlyMap
ЕФЙўЯЃБэдкЖбФкжДааФкДцжаДцДЂЪ§ОнЃЌЕЋдк Shuffle Й§ГЬжаЫљгаЪ§ОнВЂВЛФмЖМБЃДцЕНИУЙўЯЃБэжаЃЌЕБетИіЙўЯЃБэеМгУЕФФкДцЛсНјаажмЦкадЕиВЩбљЙРЫуЃЌЕБЦфДѓЕНвЛЖЈГЬЖШЃЌЮоЗЈдйДг
MemoryManager ЩъЧыЕНаТЕФжДааФкДцЪБЃЌSpark ОЭЛсНЋЦфШЋВПФкШнДцДЂЕНДХХЬЮФМўжаЃЌетИіЙ§ГЬБЛГЦЮЊвчДц(Spill)ЃЌвчДцЕНДХХЬЕФЮФМўзюКѓЛсБЛЙщВЂ(Merge)ЁЃ
ЁЁЁЁShuffle Write НзЖЮжагУЕНЕФ Tungsten ЪЧ Databricks ЙЋЫОЬсГіЕФЖд
Spark гХЛЏФкДцКЭ CPU ЪЙгУЕФМЦЛЎ[9]ЃЌНтОіСЫвЛаЉ JVM дкадФмЩЯЕФЯожЦКЭБзЖЫЁЃSpark
ЛсИљОн Shuffle ЕФЧщПіРДздЖЏбЁдёЪЧЗёВЩгУ Tungsten ХХађЁЃTungsten ВЩгУЕФвГЪНФкДцЙмРэЛњжЦНЈСЂдк
MemoryManager жЎЩЯЃЌМД Tungsten ЖджДааФкДцЕФЪЙгУНјааСЫвЛВНЕФГщЯѓЃЌетбљдк Shuffle
Й§ГЬжаЮоашЙиаФЪ§ОнОпЬхДцДЂдкЖбФкЛЙЪЧЖбЭтЁЃУПИіФкДцвГгУвЛИі MemoryBlock РДЖЈвхЃЌВЂгУ Object
obj КЭ long offset етСНИіБфСПЭГвЛБъЪЖвЛИіФкДцвГдкЯЕЭГФкДцжаЕФЕижЗЁЃЖбФкЕФ MemoryBlock
ЪЧвд long аЭЪ§зщЕФаЮЪНЗжХфЕФФкДцЃЌЦф obj ЕФжЕЮЊЪЧетИіЪ§зщЕФЖдЯѓв§гУЃЌoffset ЪЧ long
аЭЪ§зщЕФдк JVM жаЕФГѕЪМЦЋвЦЕижЗЃЌСНепХфКЯЪЙгУПЩвдЖЈЮЛетИіЪ§зщдкЖбФкЕФОјЖдЕижЗ;ЖбЭтЕФ MemoryBlock
ЪЧжБНгЩъЧыЕНЕФФкДцПщЃЌЦф obj ЮЊ nullЃЌoffset ЪЧетИіФкДцПщдкЯЕЭГФкДцжаЕФ 64 ЮЛОјЖдЕижЗЁЃSpark
гУ MemoryBlock ЧЩУюЕиНЋЖбФкКЭЖбЭтФкДцвГЭГвЛГщЯѓЗтзАЃЌВЂгУвГБэ(pageTable)ЙмРэУПИі
Task ЩъЧыЕНЕФФкДцвГЁЃ
ЁЁЁЁTungsten вГЪНЙмРэЯТЕФЫљгаФкДцгУ 64 ЮЛЕФТпМЕижЗБэЪОЃЌгЩвГКХКЭвГФкЦЋвЦСПзщГЩЃК
ЁЁЁЁвГКХЃКеМ 13 ЮЛЃЌЮЈвЛБъЪЖвЛИіФкДцвГЃЌSpark дкЩъЧыФкДцвГжЎЧАвЊЯШЩъЧыПеЯавГКХЁЃ
ЁЁЁЁвГФкЦЋвЦСПЃКеМ 51 ЮЛЃЌЪЧдкЪЙгУФкДцвГДцДЂЪ§ОнЪБЃЌЪ§ОндквГФкЕФЦЋвЦЕижЗЁЃ
ЁЁЁЁгаСЫЭГвЛЕФбАжЗЗНЪНЃЌSpark ПЩвдгУ 64 ЮЛТпМЕижЗЕФжИеыЖЈЮЛЕНЖбФкЛђЖбЭтЕФФкДцЃЌећИі Shuffle
Write ХХађЕФЙ§ГЬжЛашвЊЖджИеыНјааХХађЃЌВЂЧвЮоашЗДађСаЛЏЃЌећИіЙ§ГЬЗЧГЃИпаЇЃЌЖдгкФкДцЗУЮЪаЇТЪКЭ
CPU ЪЙгУаЇТЪДјРДСЫУїЯдЕФЬсЩ§[10]ЁЃ
ЁЁЁЁSpark ЕФДцДЂФкДцКЭжДааФкДцгазХНиШЛВЛЭЌЕФЙмРэЗНЪНЃКЖдгкДцДЂФкДцРДЫЕЃЌSpark гУвЛИі
LinkedHashMap РДМЏжаЙмРэЫљгаЕФ BlockЃЌBlock гЩашвЊЛКДцЕФ RDD ЕФ Partition
зЊЛЏЖјГЩ;ЖјЖдгкжДааФкДцЃЌSpark гУ AppendOnlyMap РДДцДЂ Shuffle Й§ГЬжаЕФЪ§ОнЃЌдк
Tungsten ХХађжаЩѕжСГщЯѓГЩЮЊвГЪНФкДцЙмРэЃЌПЊБйСЫШЋаТЕФ JVM ФкДцЙмРэЛњжЦЁЃ
ЁЁЁЁНсЪјгя
ЁЁЁЁSpark ЕФФкДцЙмРэЪЧвЛЬзИДдгЕФЛњжЦЃЌЧв Spark ЕФАцБОИќаТБШНЯПьЃЌБЪепЫЎЦНгаЯоЃЌФбУтгаа№ЪіВЛЧхЁЂДэЮѓЕФЕиЗНЃЌШєЖСепгаКУЕФНЈвщКЭИќЩюЕФРэНтЃЌЛЙЭћВЛСпДЭНЬЁЃ |









