| 1
ИХЪі
KakfaЦ№ГѕЪЧгЩLinkedInЙЋЫОПЊЗЂЕФвЛИіЗжВМЪНЕФЯћЯЂЯЕЭГЃЌКѓГЩЮЊApacheЕФвЛВПЗжЃЌЫќЪЙгУScalaБраДЃЌвдПЩЫЎЦНРЉеЙКЭИпЭЬЭТТЪЖјБЛЙуЗКЪЙгУЁЃФПЧАдНРДдНЖрЕФПЊдДЗжВМЪНДІРэЯЕЭГШчClouderaЁЂApache
StormЁЂSparkЕШЖМжЇГжгыKafkaМЏГЩЁЃ
KafkaЦОНшзХздЩэЕФгХЪЦЃЌдНРДдНЪмЕНЛЅСЊЭјЦѓвЕЕФЧрэљЃЌЮЈЦЗЛсвВВЩгУKafkaзїЮЊЦфФкВПКЫаФЯћЯЂв§ЧцжЎвЛЁЃKafkaзїЮЊвЛИіЩЬвЕМЖЯћЯЂжаМфМўЃЌЯћЯЂПЩППадЕФживЊадПЩЯыЖјжЊЁЃШчКЮШЗБЃЯћЯЂЕФОЋШЗДЋЪфЃПШчКЮШЗБЃЯћЯЂЕФзМШЗДцДЂЃПШчКЮШЗБЃЯћЯЂЕФе§ШЗЯћЗбЃПетаЉЖМЪЧашвЊПМТЧЕФЮЪЬтЁЃБОЮФЪзЯШДгKafkaЕФМмЙЙзХЪжЃЌЯШСЫНтЯТKafkaЕФЛљБОдРэЃЌШЛКѓЭЈЙ§ЖдkakfaЕФДцДЂЛњжЦЁЂИДжЦдРэЁЂЭЌВНдРэЁЂПЩППадКЭГжОУадБЃжЄЕШЕШвЛВНВНЖдЦфПЩППадНјааЗжЮіЃЌзюКѓЭЈЙ§benchmarkРДдіЧПЖдKafkaИпПЩППадЕФШЯжЊЁЃ
2 KafkaЬхЯЕМмЙЙ
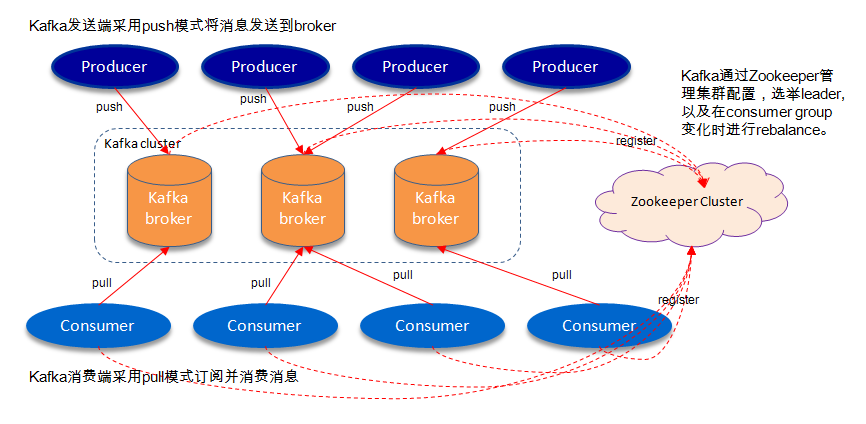
ШчЩЯЭМЫљЪОЃЌвЛИіЕфаЭЕФKafkaЬхЯЕМмЙЙАќРЈШєИЩProducerЃЈПЩвдЪЧЗўЮёЦїШежОЃЌвЕЮёЪ§ОнЃЌвГУцЧАЖЫВњЩњЕФpage
viewЕШЕШЃЉЃЌШєИЩbrokerЃЈKafkaжЇГжЫЎЦНРЉеЙЃЌвЛАуbrokerЪ§СПдНЖрЃЌМЏШКЭЬЭТТЪдНИпЃЉЃЌШєИЩConsumer
(Group)ЃЌвдМАвЛИіZookeeperМЏШКЁЃKafkaЭЈЙ§ZookeeperЙмРэМЏШКХфжУЃЌбЁОйleaderЃЌвдМАдкconsumer
groupЗЂЩњБфЛЏЪБНјааrebalanceЁЃProducerЪЙгУpush(ЭЦ)ФЃЪННЋЯћЯЂЗЂВМЕНbrokerЃЌConsumerЪЙгУpull(Р)ФЃЪНДгbrokerЖЉдФВЂЯћЗбЯћЯЂЁЃ
УћДЪНтЪЭЃК

2.1 Topic & Partition
вЛИіtopicПЩвдШЯЮЊвЛИівЛРрЯћЯЂЃЌУПИіtopicНЋБЛЗжГЩЖрИіpartitionЃЌУПИіpartitionдкДцДЂВуУцЪЧappend
logЮФМўЁЃШЮКЮЗЂВМЕНДЫpartitionЕФЯћЯЂЖМЛсБЛзЗМгЕНlogЮФМўЕФЮВВПЃЌУПЬѕЯћЯЂдкЮФМўжаЕФЮЛжУГЦЮЊoffset(ЦЋвЦСП)ЃЌoffsetЮЊвЛИіlongаЭЕФЪ§зжЃЌЫќЮЈвЛБъМЧвЛЬѕЯћЯЂЁЃУПЬѕЯћЯЂЖМБЛappendЕНpartitionжаЃЌЪЧЫГађаДДХХЬЃЌвђДЫаЇТЪЗЧГЃИпЃЈОбщжЄЃЌЫГађаДДХХЬаЇТЪБШЫцЛњаДФкДцЛЙвЊИпЃЌетЪЧKafkaИпЭЬЭТТЪЕФвЛИіКмживЊЕФБЃжЄЃЉЁЃ
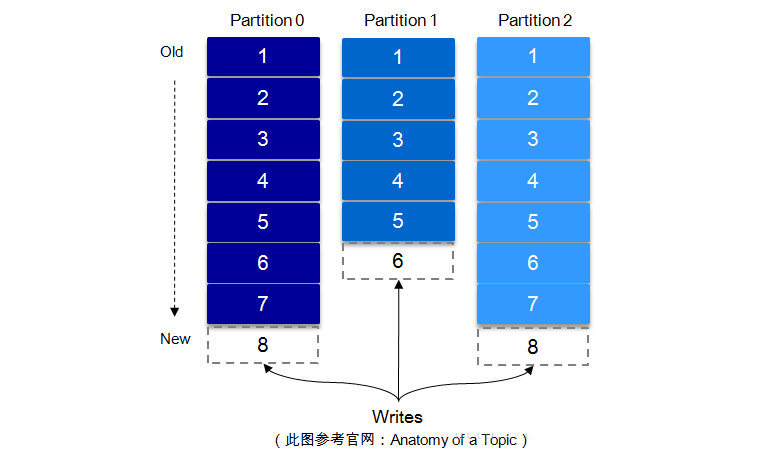
УПвЛЬѕЯћЯЂБЛЗЂЫЭЕНbrokerжаЃЌЛсИљОнpartitionЙцдђбЁдёБЛДцДЂЕНФФвЛИіpartitionЁЃШчЙћpartitionЙцдђЩшжУЕФКЯРэЃЌЫљгаЯћЯЂПЩвдОљдШЗжВМЕНВЛЭЌЕФpartitionРяЃЌетбљОЭЪЕЯжСЫЫЎЦНРЉеЙЁЃЃЈШчЙћвЛИіtopicЖдгІвЛИіЮФМўЃЌФЧетИіЮФМўЫљдкЕФЛњЦїI/OНЋЛсГЩЮЊетИіtopicЕФадФмЦПОБЃЌЖјpartitionНтОіСЫетИіЮЪЬтЃЉЁЃдкДДНЈtopicЪБПЩвддк$KAFKA_HOME/config/server.propertiesжажИЖЈетИіpartitionЕФЪ§СПЃЈШчЯТЫљЪОЃЉЃЌЕБШЛПЩвддкtopicДДНЈжЎКѓШЅаоИФpartitionЕФЪ§СПЁЃ
# The default number of log partitions per topic.
More partitions allow greater
# parallelism for consumption,
but this will also result in more files across
# the brokers.
num.partitions=3
|
дкЗЂЫЭвЛЬѕЯћЯЂЪБЃЌПЩвджИЖЈетИіЯћЯЂЕФkeyЃЌproducerИљОнетИіkeyКЭpartitionЛњжЦРДХаЖЯетИіЯћЯЂЗЂЫЭЕНФФИіpartitionЁЃpartitionЛњжЦПЩвдЭЈЙ§жИЖЈproducerЕФpartition.classетвЛВЮЪ§РДжИЖЈЃЌИУclassБиаыЪЕЯжkafka.producer.PartitionerНгПкЁЃ
гаЙиTopicгыPartitionЕФИќЖрЯИНкЃЌПЩвдВЮПМЯТУцЕФЁАKafkaЮФМўДцДЂЛњжЦЁБетвЛНкЁЃ
3 ИпПЩППадДцДЂЗжЮі
KafkaЕФИпПЩППадЕФБЃеЯРДдДгкЦфНЁзГЕФИББОЃЈreplicationЃЉВпТдЁЃЭЈЙ§ЕїНкЦфИББОЯрЙиВЮЪ§ЃЌПЩвдЪЙЕУKafkaдкадФмКЭПЩППаджЎМфдЫзЊЕФгЮШагагрЁЃKafkaДг0.8.xАцБОПЊЪМЬсЙЉpartitionМЖБ№ЕФИДжЦ,replicationЕФЪ§СППЩвддк$KAFKA_HOME/config/server.propertiesжаХфжУЃЈdefault.replication.refactorЃЉЁЃ
етРяЯШДгKafkaЮФМўДцДЂЛњжЦШыЪжЃЌДгзюЕзВуСЫНтKafkaЕФДцДЂЯИНкЃЌНјЖјЖдЦфЕФДцДЂгаИіЮЂЙлЕФШЯжЊЁЃжЎКѓЭЈЙ§KafkaИДжЦдРэКЭЭЌВНЗНЪНРДВћЪіКъЙлВуУцЕФИХФюЁЃзюКѓДгISRЃЌHWЃЌleaderбЁОйвдМАЪ§ОнПЩППадКЭГжОУадБЃжЄЕШЕШИїИіЮЌЖШРДЗсИЛЖдKafkaЯрЙижЊЪЖЕуЕФШЯжЊЁЃ
3.1 KafkaЮФМўДцДЂЛњжЦ
KafkaжаЯћЯЂЪЧвдtopicНјааЗжРрЕФЃЌЩњВњепЭЈЙ§topicЯђKafka brokerЗЂЫЭЯћЯЂЃЌЯћЗбепЭЈЙ§topicЖСШЁЪ§ОнЁЃШЛЖјtopicдкЮяРэВуУцгжФмвдpartitionЮЊЗжзщЃЌвЛИіtopicПЩвдЗжГЩШєИЩИіpartitionЃЌФЧУДtopicвдМАpartitionгжЪЧдѕУДДцДЂЕФФиЃПpartitionЛЙПЩвдЯИЗжЮЊsegmentЃЌвЛИіpartitionЮяРэЩЯгЩЖрИіsegmentзщГЩЃЌФЧУДетаЉsegmentгжЪЧЪВУДФиЃПЯТУцЮвУЧРДвЛвЛНвЯўЁЃ
ЮЊСЫБугкЫЕУїЮЪЬтЃЌМйЩшетРяжЛгавЛИіKafkaМЏШКЃЌЧветИіМЏШКжЛгавЛИіKafka brokerЃЌМДжЛгавЛЬЈЮяРэЛњЁЃдкетИіKafka
brokerжаХфжУЃЈ$KAFKA_HOME/config/server.propertiesжаЃЉlog.dirs=/tmp/kafka-logsЃЌвдДЫРДЩшжУKafkaЯћЯЂЮФМўДцДЂФПТМЃЌгыДЫЭЌЪБДДНЈвЛИіtopicЃКtopic_zzh_testЃЌpartitionЕФЪ§СПЮЊ4ЃЈ$KAFKA_HOME/bin/kafka-topics.sh
ЈCcreate ЈCzookeeper localhost:2181 ЈCpartitions 4 ЈCtopic
topic_vms_test ЈCreplication-factor 4ЃЉЁЃФЧУДЮвУЧДЫЪБПЩвддк/tmp/kafka-logsФПТМжаПЩвдПДЕНЩњГЩСЫ4ИіФПТМЃК
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_zzh_test-0
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_zzh_test-1
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_zzh_test-2
drwxr-xr-x 2 root root 4096 Apr 10 16:10 topic_zzh_test-3
|
дкKafkaЮФМўДцДЂжаЃЌЭЌвЛИіtopicЯТгаЖрИіВЛЭЌЕФpartitionЃЌУПИіpartitonЮЊвЛИіФПТМЃЌpartitionЕФУћГЦЙцдђЮЊЃКtopicУћГЦ+гаађађКХЃЌЕквЛИіађКХДг0ПЊЪММЦЃЌзюДѓЕФађКХЮЊpartitionЪ§СПМѕ1ЃЌpartitionЪЧЪЕМЪЮяРэЩЯЕФИХФюЃЌЖјtopicЪЧТпМЩЯЕФИХФюЁЃ
ЩЯУцЬсЕНpartitionЛЙПЩвдЯИЗжЮЊsegmentЃЌетИіsegmentгжЪЧЪВУДЃПШчЙћОЭвдpartitionЮЊзюаЁДцДЂЕЅЮЛЃЌЮвУЧПЩвдЯыЯѓЕБKafka
producerВЛЖЯЗЂЫЭЯћЯЂЃЌБиШЛЛсв§Ц№partitionЮФМўЕФЮоЯоРЉеХЃЌетбљЖдгкЯћЯЂЮФМўЕФЮЌЛЄвдМАвбОБЛЯћЗбЕФЯћЯЂЕФЧхРэДјРДбЯжиЕФгАЯьЃЌЫљвдетРявдsegmentЮЊЕЅЮЛгжНЋpartitionЯИЗжЁЃУПИіpartition(ФПТМ)ЯрЕБгквЛИіОоаЭЮФМўБЛЦНОљЗжХфЕНЖрИіДѓаЁЯрЕШЕФsegment(ЖЮ)Ъ§ОнЮФМўжаЃЈУПИіsegment
ЮФМўжаЯћЯЂЪ§СПВЛвЛЖЈЯрЕШЃЉетжжЬиадвВЗНБуold segmentЕФЩОГ§ЃЌМДЗНБувбБЛЯћЗбЕФЯћЯЂЕФЧхРэЃЌЬсИпДХХЬЕФРћгУТЪЁЃУПИіpartitionжЛашвЊжЇГжЫГађЖСаДОЭааЃЌsegmentЕФЮФМўЩњУќжмЦкгЩЗўЮёЖЫХфжУВЮЪ§ЃЈlog.segment.bytesЃЌlog.roll.{ms,hours}ЕШШєИЩВЮЪ§ЃЉОіЖЈЁЃ
segmentЮФМўгЩСНВПЗжзщГЩЃЌЗжБ№ЮЊЁА.indexЁБЮФМўКЭЁА.logЁБЮФМўЃЌЗжБ№БэЪОЮЊsegmentЫїв§ЮФМўКЭЪ§ОнЮФМўЁЃетСНИіЮФМўЕФУќСюЙцдђЮЊЃКpartitionШЋОжЕФЕквЛИіsegmentДг0ПЊЪМЃЌКѓајУПИіsegmentЮФМўУћЮЊЩЯвЛИіsegmentЮФМўзюКѓвЛЬѕЯћЯЂЕФoffsetжЕЃЌЪ§жЕДѓаЁЮЊ64ЮЛЃЌ20ЮЛЪ§зжзжЗћГЄЖШЃЌУЛгаЪ§зжгУ0ЬюГфЃЌШчЯТЃК
00000000000000000000.index 00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
|
вдЩЯУцЕФsegmentЮФМўЮЊР§ЃЌеЙЪОГіsegmentЃК00000000000000170410ЕФЁА.indexЁБЮФМўКЭЁА.logЁБЮФМўЕФЖдгІЕФЙиЯЕЃЌШчЯТЭМЃК
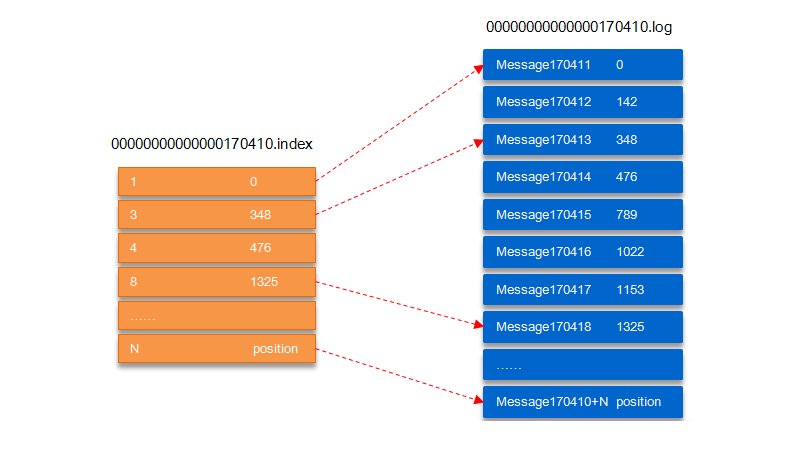
ШчЩЯЭМЃЌЁА.indexЁБЫїв§ЮФМўДцДЂДѓСПЕФдЊЪ§ОнЃЌЁА.logЁБЪ§ОнЮФМўДцДЂДѓСПЕФЯћЯЂЃЌЫїв§ЮФМўжаЕФдЊЪ§ОнжИЯђЖдгІЪ§ОнЮФМўжаmessageЕФЮяРэЦЋвЦЕижЗЁЃЦфжавдЁА.indexЁБЫїв§ЮФМўжаЕФдЊЪ§Он[3,
348]ЮЊР§ЃЌдкЁА.logЁБЪ§ОнЮФМўБэЪОЕк3ИіЯћЯЂЃЌМДдкШЋОжpartitionжаБэЪО170410+3=170413ИіЯћЯЂЃЌИУЯћЯЂЕФЮяРэЦЋвЦЕижЗЮЊ348ЁЃ
ФЧУДШчКЮДгpartitionжаЭЈЙ§offsetВщевmessageФиЃП
вдЩЯЭМЮЊР§ЃЌЖСШЁoffset=170418ЕФЯћЯЂЃЌЪзЯШВщевsegmentЮФМўЃЌЦфжа00000000000000000000.indexЮЊзюПЊЪМЕФЮФМўЃЌЕкЖўИіЮФМўЮЊ00000000000000170410.indexЃЈЦ№ЪМЦЋвЦЮЊ170410+1=170411ЃЉЃЌЖјЕкШ§ИіЮФМўЮЊ00000000000000239430.indexЃЈЦ№ЪМЦЋвЦЮЊ239430+1=239431ЃЉЃЌЫљвдетИіoffset=170418ОЭТфЕНСЫЕкЖўИіЮФМўжЎжаЁЃЦфЫћКѓајЮФМўПЩвдвРДЮРрЭЦЃЌвдЦфЪЕЦЋвЦСПУќУћВЂХХСаетаЉЮФМўЃЌШЛКѓИљОнЖўЗжВщевЗЈОЭПЩвдПьЫйЖЈЮЛЕНОпЬхЮФМўЮЛжУЁЃЦфДЮИљОн00000000000000170410.indexЮФМўжаЕФ[8,1325]ЖЈЮЛЕН00000000000000170410.logЮФМўжаЕФ1325ЕФЮЛжУНјааЖСШЁЁЃ
вЊЪЧЖСШЁoffset=170418ЕФЯћЯЂЃЌДг00000000000000170410.logЮФМўжаЕФ1325ЕФЮЛжУНјааЖСШЁЃЌФЧУДдѕУДжЊЕРКЮЪБЖСЭъБОЬѕЯћЯЂЃЌЗёдђОЭЖСЕНЯТвЛЬѕЯћЯЂЕФФкШнСЫЃП
етИіОЭашвЊСЊЯЕЕНЯћЯЂЕФЮяРэНсЙЙСЫЃЌЯћЯЂЖМОпгаЙЬЖЈЕФЮяРэНсЙЙЃЌАќРЈЃКoffsetЃЈ8 BytesЃЉЁЂЯћЯЂЬхЕФДѓаЁЃЈ4
BytesЃЉЁЂcrc32ЃЈ4 BytesЃЉЁЂmagicЃЈ1 ByteЃЉЁЂattributesЃЈ1 ByteЃЉЁЂkey
lengthЃЈ4 BytesЃЉЁЂkeyЃЈK BytesЃЉЁЂpayload(N Bytes)ЕШЕШзжЖЮЃЌПЩвдШЗЖЈвЛЬѕЯћЯЂЕФДѓаЁЃЌМДЖСШЁЕНФФРяНижЙЁЃ
3.2 ИДжЦдРэКЭЭЌВНЗНЪН
KafkaжаtopicЕФУПИіpartitionгавЛИідЄаДЪНЕФШежОЮФМўЃЌЫфШЛpartitionПЩвдМЬајЯИЗжЮЊШєИЩИіsegmentЮФМўЃЌЕЋЪЧЖдгкЩЯВугІгУРДЫЕПЩвдНЋpartitionПДГЩзюаЁЕФДцДЂЕЅдЊЃЈвЛИігаЖрИіsegmentЮФМўЦДНгЕФЁАОоаЭЁБЮФМўЃЉЃЌУПИіpartitionЖМгЩвЛаЉСагаађЕФЁЂВЛПЩБфЕФЯћЯЂзщГЩЃЌетаЉЯћЯЂБЛСЌајЕФзЗМгЕНpartitionжаЁЃ
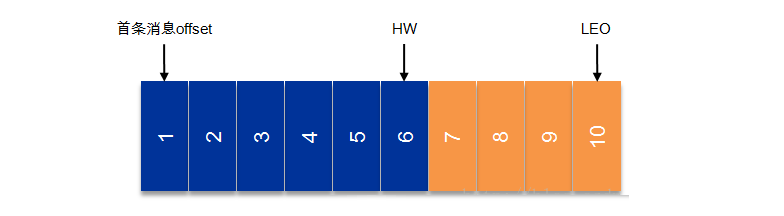
ЩЯЭМжагаСНИіаТУћДЪЃКHWКЭLEOЁЃетРяЯШНщЩмЯТLEOЃЌLogEndOffsetЕФЫѕаДЃЌБэЪОУПИіpartitionЕФlogзюКѓвЛЬѕMessageЕФЮЛжУЁЃHWЪЧHighWatermarkЕФЫѕаДЃЌЪЧжИconsumerФмЙЛПДЕНЕФДЫpartitionЕФЮЛжУЃЌетИіЩцМАЕНЖрИББОЕФИХФюЃЌетРяЯШЬсМАвЛЯТЃЌЯТНкдйЯъБэЁЃ
бдЙще§ДЋЃЌЮЊСЫЬсИпЯћЯЂЕФПЩППадЃЌKafkaУПИіtopicЕФpartitionгаNИіИББОЃЈreplicasЃЉЃЌЦфжаN(ДѓгкЕШгк1)ЪЧtopicЕФИДжЦвђзгЃЈreplica
fatorЃЉЕФИіЪ§ЁЃKafkaЭЈЙ§ЖрИББОЛњжЦЪЕЯжЙЪеЯздЖЏзЊвЦЃЌЕБKafkaМЏШКжавЛИіbrokerЪЇаЇЧщПіЯТШдШЛБЃжЄЗўЮёПЩгУЁЃдкKafkaжаЗЂЩњИДжЦЪБШЗБЃpartitionЕФШежОФмгаађЕиаДЕНЦфЫћНкЕуЩЯЃЌNИіreplicasжаЃЌЦфжавЛИіreplicaЮЊleaderЃЌЦфЫћЖМЮЊfollower,
leaderДІРэpartitionЕФЫљгаЖСаДЧыЧѓЃЌгыДЫЭЌЪБЃЌfollowerЛсБЛЖЏЖЈЦкЕиШЅИДжЦleaderЩЯЕФЪ§ОнЁЃ
ШчЯТЭМЫљЪОЃЌKafkaМЏШКжага4Иіbroker, ФГtopicга3Иіpartition,ЧвИДжЦвђзгМДИББОИіЪ§вВЮЊ3ЃК
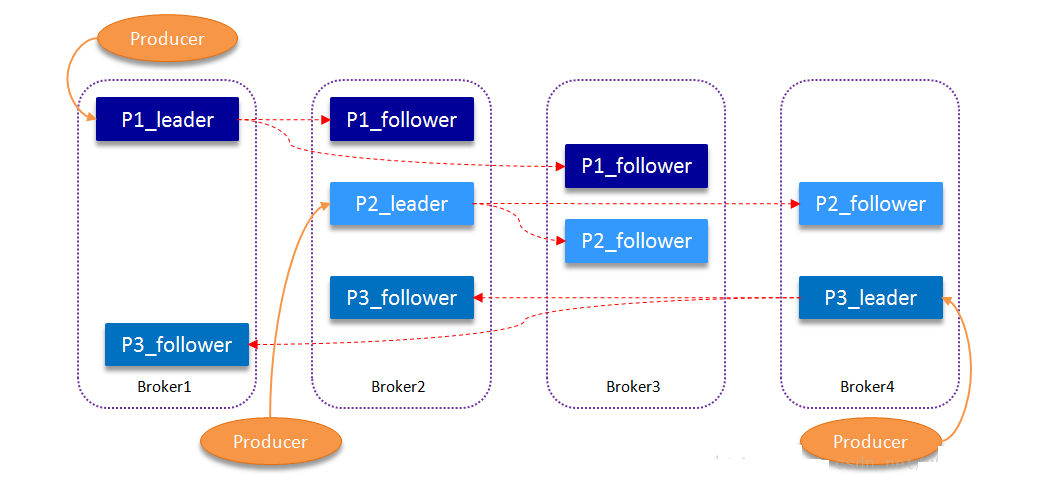
KafkaЬсЙЉСЫЪ§ОнИДжЦЫуЗЈБЃжЄЃЌШчЙћleaderЗЂЩњЙЪеЯЛђЙвЕєЃЌвЛИіаТleaderБЛбЁОйВЂБЛНгЪмПЭЛЇЖЫЕФЯћЯЂГЩЙІаДШыЁЃKafkaШЗБЃДгЭЌВНИББОСаБэжабЁОйвЛИіИББОЮЊleaderЃЌЛђепЫЕfollowerзЗИЯleaderЪ§ОнЁЃleaderИКд№ЮЌЛЄКЭИњзйISR(In-Sync
ReplicasЕФЫѕаДЃЌБэЪОИББОЭЌВНЖгСаЃЌОпЬхПЩВЮПМЯТНк)жаЫљгаfollowerжЭКѓЕФзДЬЌЁЃЕБproducerЗЂЫЭвЛЬѕЯћЯЂЕНbrokerКѓЃЌleaderаДШыЯћЯЂВЂИДжЦЕНЫљгаfollowerЁЃЯћЯЂЬсНЛжЎКѓВХБЛГЩЙІИДжЦЕНЫљгаЕФЭЌВНИББОЁЃЯћЯЂИДжЦбгГйЪмзюТ§ЕФfollowerЯожЦЃЌживЊЕФЪЧПьЫйМьВтТ§ИББОЃЌШчЙћfollowerЁАТфКѓЁБЬЋЖрЛђепЪЇаЇЃЌleaderНЋЛсАбЫќДгISRжаЩОГ§ЁЃ
3.3 ISR
ЩЯНкЮвУЧЩцМАЕНISR (In-Sync Replicas)ЃЌетИіЪЧжИИББОЭЌВНЖгСаЁЃИББОЪ§ЖдKafkaЕФЭЬЭТТЪЪЧгавЛЖЈЕФгАЯьЃЌЕЋМЋДѓЕФдіЧПСЫПЩгУадЁЃФЌШЯЧщПіЯТKafkaЕФreplicaЪ§СПЮЊ1ЃЌМДУПИіpartitionЖМгавЛИіЮЈвЛЕФleaderЃЌЮЊСЫШЗБЃЯћЯЂЕФПЩППадЃЌЭЈГЃгІгУжаНЋЦфжЕ(гЩbrokerЕФВЮЪ§offsets.topic.replication.factorжИЖЈ)ДѓаЁЩшжУЮЊДѓгк1ЃЌБШШч3ЁЃ
ЫљгаЕФИББОЃЈreplicasЃЉЭГГЦЮЊAssigned ReplicasЃЌМДARЁЃISRЪЧARжаЕФвЛИізгМЏЃЌгЩleaderЮЌЛЄISRСаБэЃЌfollowerДгleaderЭЌВНЪ§ОнгавЛаЉбгГйЃЈАќРЈбгГйЪБМфreplica.lag.time.max.msКЭбгГйЬѕЪ§replica.lag.max.messagesСНИіЮЌЖШ,
ЕБЧАзюаТЕФАцБО0.10.xжажЛжЇГжreplica.lag.time.max.msетИіЮЌЖШЃЉЃЌШЮвтвЛИіГЌЙ§уажЕЖМЛсАбfollowerЬоçóISR,
ДцШыOSRЃЈOutof-Sync ReplicasЃЉСаБэЃЌаТМгШыЕФfollowerвВЛсЯШДцЗХдкOSRжаЁЃAR=ISR+OSRЁЃ
Kafka 0.10.xАцБОКѓвЦГ§СЫreplica.lag.max.messagesВЮЪ§ЃЌжЛБЃСєСЫreplica.lag.time.max.msзїЮЊISRжаИББОЙмРэЕФВЮЪ§ЁЃЮЊЪВУДетбљзіФиЃПreplica.lag.max.messagesБэЪОЕБЧАФГИіИББОТфКѓleaederЕФЯћЯЂЪ§СПГЌЙ§СЫетИіВЮЪ§ЕФжЕЃЌФЧУДleaderОЭЛсАбfollowerДгISRжаЩОГ§ЁЃМйЩшЩшжУreplica.lag.max.messages=4ЃЌФЧУДШчЙћproducerвЛДЮДЋЫЭжСbrokerЕФЯћЯЂЪ§СПЖМаЁгк4ЬѕЪБЃЌвђЮЊдкleaderНгЪмЕНproducerЗЂЫЭЕФЯћЯЂжЎКѓЖјfollowerИББОПЊЪМРШЁетаЉЯћЯЂжЎЧАЃЌfollowerТфКѓleaderЕФЯћЯЂЪ§ВЛЛсГЌЙ§4ЬѕЯћЯЂЃЌЙЪДЫУЛгаfollowerвЦГіISRЃЌЫљвдетЪБКђreplica.lag.max.messageЕФЩшжУЫЦКѕЪЧКЯРэЕФЁЃЕЋЪЧproducerЗЂЦ№ЫВЪБИпЗхСїСПЃЌproducerвЛДЮЗЂЫЭЕФЯћЯЂГЌЙ§4ЬѕЪБЃЌвВОЭЪЧГЌЙ§replica.lag.max.messagesЃЌДЫЪБfollowerЖМЛсБЛШЯЮЊЪЧгыleaderИББОВЛЭЌВНСЫЃЌДгЖјБЛЬпГіСЫISRЁЃЕЋЪЕМЪЩЯетаЉfollowerЖМЪЧДцЛюзДЬЌЕФЧвУЛгаадФмЮЪЬтЁЃФЧУДдкжЎКѓзЗЩЯleader,ВЂБЛжиаТМгШыСЫISRЁЃгкЪЧОЭЛсГіЯжЫќУЧВЛЖЯЕиЬоГіISRШЛКѓжиаТЛиЙщISRЃЌетЮовЩдіМгСЫЮоЮНЕФадФмЫ№КФЁЃЖјЧветИіВЮЪ§ЪЧbrokerШЋОжЕФЁЃЩшжУЬЋДѓСЫЃЌгАЯьеце§ЁАТфКѓЁБfollowerЕФвЦГ§ЃЛЩшжУЕФЬЋаЁСЫЃЌЕМжТfollowerЕФЦЕЗБНјГіЁЃЮоЗЈИјЖЈвЛИіКЯЪЪЕФreplica.lag.max.messagesЕФжЕЃЌЙЪДЫЃЌаТАцБОЕФKafkaвЦГ§СЫетИіВЮЪ§ЁЃ
зЂЃКISRжаАќРЈЃКleaderКЭfollowerЁЃ
ЩЯУцвЛНкЛЙЩцМАЕНвЛИіИХФюЃЌМДHWЁЃHWЫзГЦИпЫЎЮЛЃЌHighWatermarkЕФЫѕаДЃЌШЁвЛИіpartitionЖдгІЕФISRжазюаЁЕФLEOзїЮЊHWЃЌconsumerзюЖржЛФмЯћЗбЕНHWЫљдкЕФЮЛжУЁЃСэЭтУПИіreplicaЖМгаHW,leaderКЭfollowerИїздИКд№ИќаТздМКЕФHWЕФзДЬЌЁЃЖдгкleaderаТаДШыЕФЯћЯЂЃЌconsumerВЛФмСЂПЬЯћЗбЃЌleaderЛсЕШД§ИУЯћЯЂБЛЫљгаISRжаЕФreplicasЭЌВНКѓИќаТHWЃЌДЫЪБЯћЯЂВХФмБЛconsumerЯћЗбЁЃетбљОЭБЃжЄСЫШчЙћleaderЫљдкЕФbrokerЪЇаЇЃЌИУЯћЯЂШдШЛПЩвдДгаТбЁОйЕФleaderжаЛёШЁЁЃЖдгкРДздФкВПbroKerЕФЖСШЁЧыЧѓЃЌУЛгаHWЕФЯожЦЁЃ
ЯТЭМЯъЯИЕФЫЕУїСЫЕБproducerЩњВњЯћЯЂжСbrokerКѓЃЌISRвдМАHWКЭLEOЕФСїзЊЙ§ГЬЃК
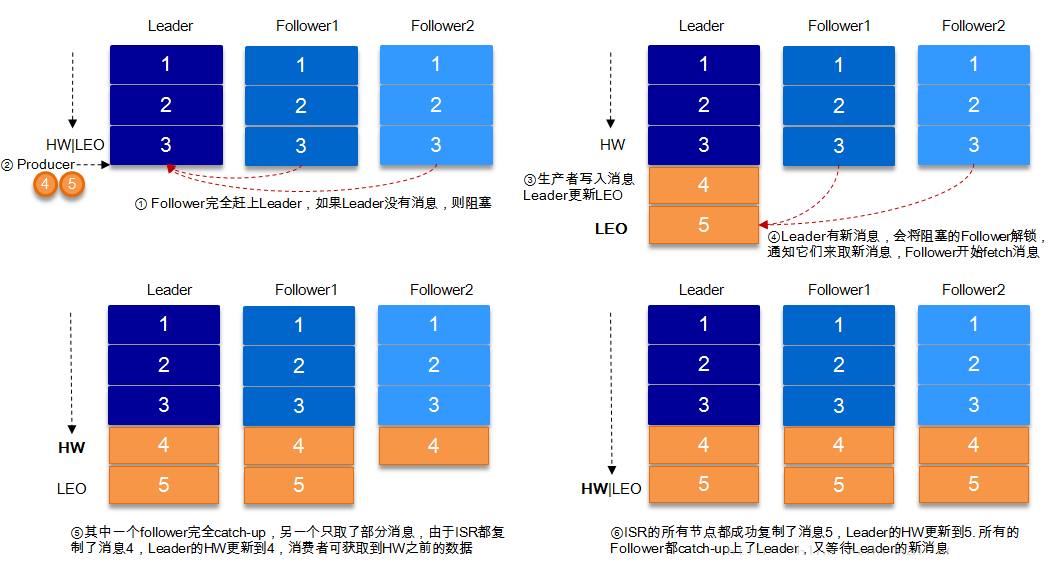
гЩДЫПЩМћЃЌKafkaЕФИДжЦЛњжЦМШВЛЪЧЭъШЋЕФЭЌВНИДжЦЃЌвВВЛЪЧЕЅДПЕФвьВНИДжЦЁЃЪТЪЕЩЯЃЌЭЌВНИДжЦвЊЧѓЫљгаФмЙЄзїЕФfollowerЖМИДжЦЭъЃЌетЬѕЯћЯЂВХЛсБЛcommitЃЌетжжИДжЦЗНЪНМЋДѓЕФгАЯьСЫЭЬЭТТЪЁЃЖјвьВНИДжЦЗНЪНЯТЃЌfollowerвьВНЕФДгleaderИДжЦЪ§ОнЃЌЪ§ОнжЛвЊБЛleaderаДШыlogОЭБЛШЯЮЊвбОcommitЃЌетжжЧщПіЯТШчЙћfollowerЖМЛЙУЛгаИДжЦЭъЃЌТфКѓгкleaderЪБЃЌЭЛШЛleaderхДЛњЃЌдђЛсЖЊЪЇЪ§ОнЁЃЖјKafkaЕФетжжЪЙгУISRЕФЗНЪНдђКмКУЕФОљКтСЫШЗБЃЪ§ОнВЛЖЊЪЇвдМАЭЬЭТТЪЁЃ
KafkaЕФISRЕФЙмРэзюжеЖМЛсЗДРЁЕНZookeeperНкЕуЩЯЁЃОпЬхЮЛжУЮЊЃК/brokers/topics/[topic]/partitions/[partition]/stateЁЃФПЧАгаСНИіЕиЗНЛсЖдетИіZookeeperЕФНкЕуНјааЮЌЛЄЃК
ControllerРДЮЌЛЄЃКKafkaМЏШКжаЕФЦфжавЛИіBrokerЛсБЛбЁОйЮЊControllerЃЌжївЊИКд№PartitionЙмРэКЭИББОзДЬЌЙмРэЃЌвВЛсжДааРрЫЦгкжиЗжХфpartitionжЎРрЕФЙмРэШЮЮёЁЃдкЗћКЯФГаЉЬиЖЈЬѕМўЯТЃЌControllerЯТЕФLeaderSelectorЛсбЁОйаТЕФleaderЃЌISRКЭаТЕФleader_epochМАcontroller_epochаДШыZookeeperЕФЯрЙиНкЕужаЁЃЭЌЪБЗЂЦ№LeaderAndIsrRequestЭЈжЊЫљгаЕФreplicasЁЃ
leaderРДЮЌЛЄЃКleaderгаЕЅЖРЕФЯпГЬЖЈЦкМьВтISRжаfollowerЪЧЗёЭбРыISR, ШчЙћЗЂЯжISRБфЛЏЃЌдђЛсНЋаТЕФISRЕФаХЯЂЗЕЛиЕНZookeeperЕФЯрЙиНкЕужаЁЃ
3.4 Ъ§ОнПЩППадКЭГжОУадБЃжЄ
ЕБproducerЯђleaderЗЂЫЭЪ§ОнЪБЃЌПЩвдЭЈЙ§request.required.acksВЮЪ§РДЩшжУЪ§ОнПЩППадЕФМЖБ№ЃК
1ЃЈФЌШЯЃЉЃКетвтЮЖзХproducerдкISRжаЕФleaderвбГЩЙІЪеЕНЕФЪ§ОнВЂЕУЕНШЗШЯКѓЗЂЫЭЯТвЛЬѕmessageЁЃШчЙћleaderхДЛњСЫЃЌдђЛсЖЊЪЇЪ§ОнЁЃ
0ЃКетвтЮЖзХproducerЮоашЕШД§РДздbrokerЕФШЗШЯЖјМЬајЗЂЫЭЯТвЛХњЯћЯЂЁЃетжжЧщПіЯТЪ§ОнДЋЪфаЇТЪзюИпЃЌЕЋЪЧЪ§ОнПЩППадШЗЪЧзюЕЭЕФЁЃ
-1ЃКproducerашвЊЕШД§ISRжаЕФЫљгаfollowerЖМШЗШЯНгЪеЕНЪ§ОнКѓВХЫувЛДЮЗЂЫЭЭъГЩЃЌПЩППадзюИпЁЃЕЋЪЧетбљвВВЛФмБЃжЄЪ§ОнВЛЖЊЪЇЃЌБШШчЕБISRжажЛгаleaderЪБЃЈЧАУцISRФЧвЛНкНВЕНЃЌISRжаЕФГЩдБгЩгкФГаЉЧщПіЛсдіМгвВЛсМѕЩйЃЌзюЩйОЭжЛЪЃвЛИіleaderЃЉЃЌетбљОЭБфГЩСЫacks=1ЕФЧщПіЁЃ
ШчЙћвЊЬсИпЪ§ОнЕФПЩППадЃЌдкЩшжУrequest.required.acks=-1ЕФЭЌЪБЃЌвВвЊmin.insync.replicasетИіВЮЪ§(ПЩвддкbrokerЛђепtopicВуУцНјааЩшжУ)ЕФХфКЯЃЌетбљВХФмЗЂЛгзюДѓЕФЙІаЇЁЃmin.insync.replicasетИіВЮЪ§ЩшЖЈISRжаЕФзюаЁИББОЪ§ЪЧЖрЩйЃЌФЌШЯжЕЮЊ1ЃЌЕБЧвНіЕБrequest.required.acksВЮЪ§ЩшжУЮЊ-1ЪБЃЌДЫВЮЪ§ВХЩњаЇЁЃШчЙћISRжаЕФИББОЪ§Щйгкmin.insync.replicasХфжУЕФЪ§СПЪБЃЌПЭЛЇЖЫЛсЗЕЛивьГЃЃКorg.apache.
kafka.common.errors.NotEnoughReplicasExceptoin: Messages
are rejected since there are fewer in-sync replicas
than requiredЁЃ
НгЯТРДЖдacks=1КЭ-1ЕФСНжжЧщПіНјааЯъЯИЗжЮіЃК
1. request.required.acks=1
producerЗЂЫЭЪ§ОнЕНleaderЃЌleaderаДБОЕиШежОГЩЙІЃЌЗЕЛиПЭЛЇЖЫГЩЙІЃЛДЫЪБISRжаЕФИББОЛЙУЛгаРДЕУМАРШЁИУЯћЯЂЃЌleaderОЭхДЛњСЫЃЌФЧУДДЫДЮЗЂЫЭЕФЯћЯЂОЭЛсЖЊЪЇЁЃ
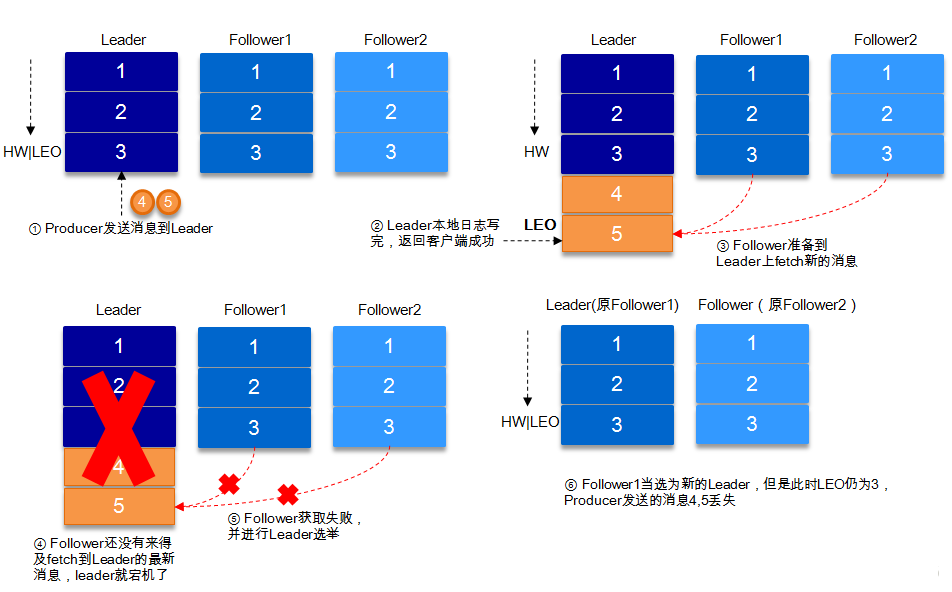
2. request.required.acks=-1
ЭЌВНЃЈKafkaФЌШЯЮЊЭЌВНЃЌМДproducer.type=syncЃЉЕФЗЂЫЭФЃЪНЃЌreplication.factor>=2
Чвmin.insync.replicas>=2ЕФЧщПіЯТЃЌВЛЛсЖЊЪЇЪ§ОнЁЃ
гаСНжжЕфаЭЧщПіЁЃacks=-1ЕФЧщПіЯТЃЈШчЮоЬиЪтЫЕУїЃЌвдЯТacksЖМБэЪОЮЊВЮЪ§request.required.acksЃЉЃЌЪ§ОнЗЂЫЭЕНleader,
ISRЕФfollowerШЋВПЭъГЩЪ§ОнЭЌВНКѓЃЌleaderДЫЪБЙвЕєЃЌФЧУДЛсбЁОйГіаТЕФleaderЃЌЪ§ОнВЛЛсЖЊЪЇЁЃ
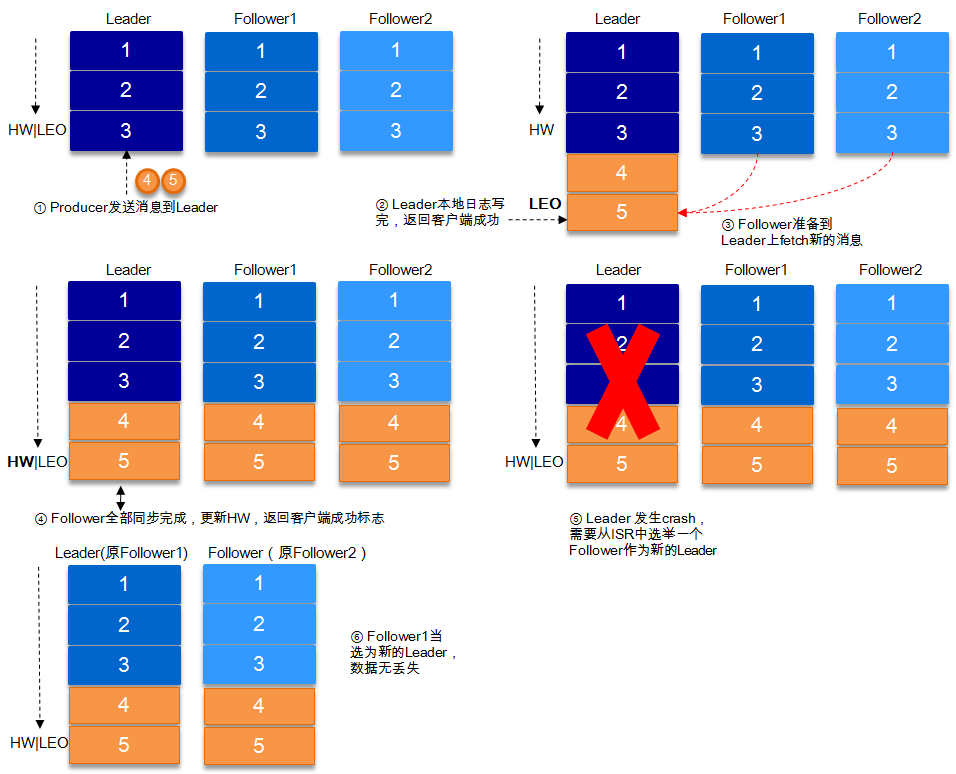
acks=-1ЕФЧщПіЯТЃЌЪ§ОнЗЂЫЭЕНleaderКѓ ЃЌВПЗжISRЕФИББОЭЌВНЃЌleaderДЫЪБЙвЕєЁЃБШШчfollower1hКЭfollower2ЖМгаПЩФмБфГЩаТЕФleader,
producerЖЫЛсЕУЕНЗЕЛивьГЃЃЌproducerЖЫЛсжиаТЗЂЫЭЪ§ОнЃЌЪ§ОнПЩФмЛсжиИДЁЃ
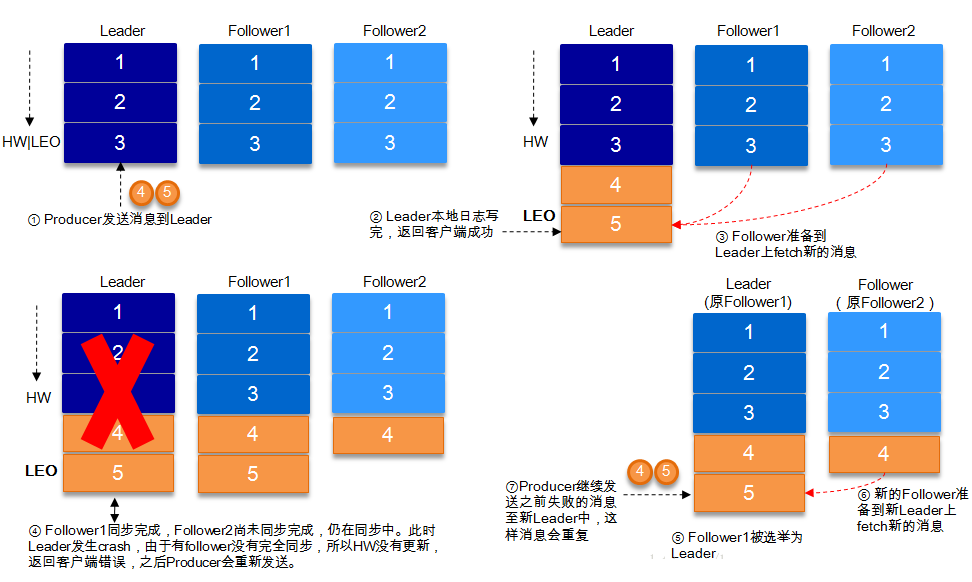
ЕБШЛЩЯЭМжаШчЙћдкleader crashЕФЪБКђЃЌfollower2ЛЙУЛгаЭЌВНЕНШЮКЮЪ§ОнЃЌЖјЧвfollower2БЛбЁОйЮЊаТЕФleaderЕФЛАЃЌетбљЯћЯЂОЭВЛЛсжиИДЁЃ
зЂЃКKafkaжЛДІРэfail/recoverЮЪЬт,ВЛДІРэByzantineЮЪЬтЁЃ
3.5 ЙигкHWЕФНјвЛВНЬНЬж
ПМТЧЩЯЭМЃЈМДacks=-1,ВПЗжISRИББОЭЌВНЃЉжаЕФСэвЛжжЧщПіЃЌШчЙћдкLeaderЙвЕєЕФЪБКђЃЌfollower1ЭЌВНСЫЯћЯЂ4,5ЃЌfollower2ЭЌВНСЫЯћЯЂ4ЃЌгыДЫЭЌЪБfollower2БЛбЁОйЮЊleaderЃЌФЧУДДЫЪБfollower1жаЕФЖрГіЕФЯћЯЂ5ИУзіШчКЮДІРэФиЃП
етРяОЭашвЊHWЕФаЭЌХфКЯСЫЁЃШчЧАЫљЪіЃЌвЛИіpartitionжаЕФISRСаБэжаЃЌleaderЕФHWЪЧЫљгаISRСаБэРяИББОжазюаЁЕФФЧИіЕФLEOЁЃРрЫЦгкФОЭАдРэЃЌЫЎЮЛШЁОігкзюЕЭФЧПщЖЬАхЁЃ
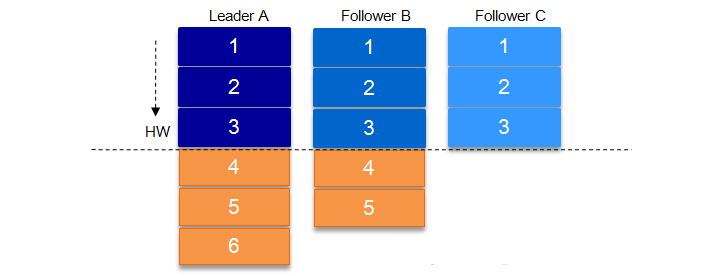
ШчЩЯЭМЃЌФГИіtopicЕФФГpartitionгаШ§ИіИББОЃЌЗжБ№ЮЊAЁЂBЁЂCЁЃAзїЮЊleaderПЯЖЈЪЧLEOзюИпЃЌBНєЫцЦфКѓЃЌCЛњЦїгЩгкХфжУБШНЯЕЭЃЌЭјТчБШНЯВюЃЌЙЪЖјЭЌВНзюТ§ЁЃетИіЪБКђAЛњЦїхДЛњЃЌетЪБКђШчЙћBГЩЮЊleaderЃЌМйШчУЛгаHWЃЌдкAжиаТЛжИДжЎКѓЛсзіЭЌВН(makeFollower)ВйзїЃЌдкхДЛњЪБlogЮФМўжЎКѓжБНгзізЗМгВйзїЃЌЖјМйШчBЕФLEOвбОДяЕНСЫAЕФLEOЃЌЛсВњЩњЪ§ОнВЛвЛжТЕФЧщПіЃЌЫљвдЪЙгУHWРДБмУтетжжЧщПіЁЃ
AдкзіЭЌВНВйзїЕФЪБКђЃЌЯШНЋlogЮФМўНиЖЯЕНжЎЧАздМКЕФHWЕФЮЛжУЃЌМД3ЃЌжЎКѓдйДгBжаРШЁЯћЯЂНјааЭЌВНЁЃ
ШчЙћЪЇАмЕФfollowerЛжИДЙ§РДЃЌЫќЪзЯШНЋздМКЕФlogЮФМўНиЖЯЕНЩЯДЮcheckpointedЪБПЬЕФHWЕФЮЛжУЃЌжЎКѓдйДгleaderжаЭЌВНЯћЯЂЁЃleaderЙвЕєЛсжиаТбЁОйЃЌаТЕФleaderЛсЗЂЫЭЁАжИСюЁБШУЦфгрЕФfollowerНиЖЯжСздЩэЕФHWЕФЮЛжУШЛКѓдйРШЁаТЕФЯћЯЂЁЃ
ЕБISRжаЕФИіИББОЕФLEOВЛвЛжТЪБЃЌШчЙћДЫЪБleaderЙвЕєЃЌбЁОйаТЕФleaderЪБВЂВЛЪЧАДееLEOЕФИпЕЭНјаабЁОйЃЌЖјЪЧАДееISRжаЕФЫГађбЁОйЁЃ
3.6 LeaderбЁОй
вЛЬѕЯћЯЂжЛгаБЛISRжаЕФЫљгаfollowerЖМДгleaderИДжЦЙ§ШЅВХЛсБЛШЯЮЊвбЬсНЛЁЃетбљОЭБмУтСЫВПЗжЪ§ОнБЛаДНјСЫleaderЃЌЛЙУЛРДЕУМАБЛШЮКЮfollowerИДжЦОЭхДЛњСЫЃЌЖјдьГЩЪ§ОнЖЊЪЇЁЃЖјЖдгкproducerЖјбдЃЌЫќПЩвдбЁдёЪЧЗёЕШД§ЯћЯЂcommitЃЌетПЩвдЭЈЙ§request.required.acksРДЩшжУЁЃетжжЛњжЦШЗБЃСЫжЛвЊISRжагавЛИіЛђепвдЩЯЕФfollowerЃЌвЛЬѕБЛcommitЕФЯћЯЂОЭВЛЛсЖЊЪЇЁЃ
гавЛИіКмживЊЕФЮЪЬтЪЧЕБleaderхДЛњСЫЃЌдѕбљдкfollowerжабЁОйГіаТЕФleaderЃЌвђЮЊfollowerПЩФмТфКѓКмЖрЛђепжБНгcrashСЫЃЌЫљвдБиаыШЗБЃбЁдёЁАзюаТЁБЕФfollowerзїЮЊаТЕФleaderЁЃвЛИіЛљБОЕФддђОЭЪЧЃЌШчЙћleaderВЛдкСЫЃЌаТЕФleaderБиаыгЕгадРДЕФleader
commitЕФЫљгаЯћЯЂЁЃетОЭашвЊзівЛИіелжаЃЌШчЙћleaderдкБэУћвЛИіЯћЯЂБЛcommitЧАЕШД§ИќЖрЕФfollowerШЗШЯЃЌФЧУДдкЫќЙвЕєжЎКѓОЭгаИќЖрЕФfollowerПЩвдГЩЮЊаТЕФleaderЃЌЕЋетвВЛсдьГЩЭЬЭТТЪЕФЯТНЕЁЃ
вЛжжЗЧГЃГЃгУЕФбЁОйleaderЕФЗНЪНЪЧЁАЩйЪ§ЗўДгЖрЪ§ЁБЃЌKafkaВЂВЛЪЧВЩгУетжжЗНЪНЁЃетжжФЃЪНЯТЃЌШчЙћЮвУЧга2f+1ИіИББОЃЌФЧУДдкcommitжЎЧАБиаыБЃжЄгаf+1ИіreplicaИДжЦЭъЯћЯЂЃЌЭЌЪБЮЊСЫБЃжЄФме§ШЗбЁОйГіаТЕФleaderЃЌЪЇАмЕФИББОЪ§ВЛФмГЌЙ§fИіЁЃетжжЗНЪНгаИіКмДѓЕФгХЪЦЃЌЯЕЭГЕФбгГйШЁОігкзюПьЕФМИЬЈЛњЦїЃЌвВОЭЪЧЫЕБШШчИББОЪ§ЮЊ3ЃЌФЧУДбгГйОЭШЁОігкзюПьЕФФЧИіfollowerЖјВЛЪЧзюТ§ЕФФЧИіЁЃЁАЩйЪ§ЗўДгЖрЪ§ЁБЕФЗНЪНвВгавЛаЉСгЪЦЃЌЮЊСЫБЃжЄleaderбЁОйЕФе§ГЃНјааЃЌЫќЫљФмШнШЬЕФЪЇАмЕФfollowerЪ§БШНЯЩйЃЌШчЙћвЊШнШЬ1ИіfollowerЙвЕєЃЌФЧУДжСЩйвЊ3ИівдЩЯЕФИББОЃЌШчЙћвЊШнШЬ2ИіfollowerЙвЕєЃЌБиаывЊга5ИівдЩЯЕФИББОЁЃвВОЭЪЧЫЕЃЌдкЩњВњЛЗОГЯТЮЊСЫБЃжЄНЯИпЕФШнДэТЪЃЌБиаывЊгаДѓСПЕФИББОЃЌЖјДѓСПЕФИББОгжЛсдкДѓЪ§ОнСПЯТЕМжТадФмЕФМБОчЯТНЕЁЃетжжЫуЗЈИќЖргУдкZookeeperетжжЙВЯэМЏШКХфжУЕФЯЕЭГжаЖјКмЩйдкашвЊДѓСПЪ§ОнЕФЯЕЭГжаЪЙгУЕФдвђЁЃHDFSЕФHAЙІФмвВЪЧЛљгкЁАЩйЪ§ЗўДгЖрЪ§ЁБЕФЗНЪНЃЌЕЋЪЧЦфЪ§ОнДцДЂВЂВЛЪЧВЩгУетбљЕФЗНЪНЁЃ
ЪЕМЪЩЯЃЌleaderбЁОйЕФЫуЗЈЗЧГЃЖрЃЌБШШчZookeeperЕФZabЁЂRaftвдМАViewstamped
ReplicationЁЃЖјKafkaЫљЪЙгУЕФleaderбЁОйЫуЗЈИќЯёЪЧЮЂШэЕФPacificAЫуЗЈЁЃ
KafkaдкZookeeperжаЮЊУПвЛИіpartitionЖЏЬЌЕФЮЌЛЄСЫвЛИіISRЃЌетИіISRРяЕФЫљгаreplicaЖМИњЩЯСЫleaderЃЌжЛгаISRРяЕФГЩдБВХФмгаБЛбЁЮЊleaderЕФПЩФмЃЈunclean.leader.election.enable=falseЃЉЁЃдкетжжФЃЪНЯТЃЌЖдгкf+1ИіИББОЃЌвЛИіKafka
topicФмдкБЃжЄВЛЖЊЪЇвбОcommitЯћЯЂЕФЧАЬсЯТШнШЬfИіИББОЕФЪЇАмЃЌдкДѓЖрЪ§ЪЙгУГЁОАЯТЃЌетжжФЃЪНЪЧЪЎЗжгаРћЕФЁЃЪТЪЕЩЯЃЌЮЊСЫШнШЬfИіИББОЕФЪЇАмЃЌЁАЩйЪ§ЗўДгЖрЪ§ЁБЕФЗНЪНКЭISRдкcommitЧАашвЊЕШД§ЕФИББОЕФЪ§СПЪЧвЛбљЕФЃЌЕЋЪЧISRашвЊЕФзмЕФИББОЕФИіЪ§МИКѕЪЧЁАЩйЪ§ЗўДгЖрЪ§ЁБЕФЗНЪНЕФвЛАыЁЃ
ЩЯЮФЬсЕНЃЌдкISRжажСЩйгавЛИіfollowerЪБЃЌKafkaПЩвдШЗБЃвбОcommitЕФЪ§ОнВЛЖЊЪЇЃЌЕЋШчЙћФГвЛИіpartitionЕФЫљгаreplicaЖМЙвСЫЃЌОЭЮоЗЈБЃжЄЪ§ОнВЛЖЊЪЇСЫЁЃетжжЧщПіЯТгаСНжжПЩааЕФЗНАИЃК
ЕШД§ISRжаШЮвтвЛИіreplicaЁАЛюЁБЙ§РДЃЌВЂЧвбЁЫќзїЮЊleader
бЁдёЕквЛИіЁАЛюЁБЙ§РДЕФreplicaЃЈВЂВЛвЛЖЈЪЧдкISRжаЃЉзїЮЊleader
етОЭашвЊдкПЩгУадКЭвЛжТадЕБжазїГівЛИіМђЕЅЕФОёдёЁЃШчЙћвЛЖЈвЊЕШД§ISRжаЕФreplicaЁАЛюЁБЙ§РДЃЌФЧВЛПЩгУЕФЪБМфОЭПЩФмЛсЯрЖдНЯГЄЁЃЖјЧвШчЙћISRжаЫљгаЕФreplicaЖМЮоЗЈЁАЛюЁБЙ§РДСЫЃЌЛђепЪ§ОнЖЊЪЇСЫЃЌетИіpartitionНЋгРдЖВЛПЩгУЁЃбЁдёЕквЛИіЁАЛюЁБЙ§РДЕФreplicaзїЮЊleader,ЖјетИіreplicaВЛЪЧISRжаЕФreplica,ФЧМДЪЙЫќВЂВЛБЃеЯвбОАќКЌСЫЫљгавбcommitЕФЯћЯЂЃЌЫќвВЛсГЩЮЊleaderЖјзїЮЊconsumerЕФЪ§ОндДЁЃФЌШЯЧщПіЯТЃЌKafkaВЩгУЕкЖўжжВпТдЃЌМДunclean.leader.election.enable=trueЃЌвВПЩвдНЋДЫВЮЪ§ЩшжУЮЊfalseРДЦєгУЕквЛжжВпТдЁЃ
unclean.leader.election.enableетИіВЮЪ§ЖдгкleaderЕФбЁОйЁЂЯЕЭГЕФПЩгУадвдМАЪ§ОнЕФПЩППадЖМгажСЙиживЊЕФгАЯьЁЃЯТУцЮвУЧРДЗжЮіЯТМИжжЕфаЭЕФГЁОАЁЃ
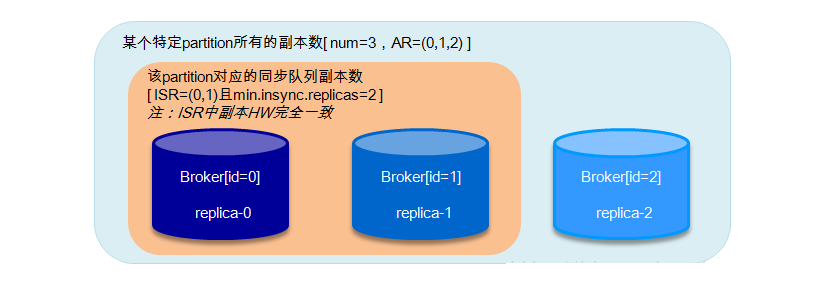
ШчЙћЩЯЭМЫљЪОЃЌМйЩшФГИіpartitionжаЕФИББОЪ§ЮЊ3ЃЌreplica-0, replica-1,
replica-2ЗжБ№ДцЗХдкbroker0, broker1КЭbroker2жаЁЃAR=(0,1,2)ЃЌISR=(0,1)ЁЃ
ЩшжУrequest.required.acks=-1, min.insync.replicas=2ЃЌ
unclean.leader.election.enable=falseЁЃетРяНВbroker0жаЕФИББОвВГЦжЎЮЊbroker0Ц№Гѕbroker0ЮЊleaderЃЌbroker1ЮЊfollowerЁЃ
ЕБISRжаЕФreplica-0ГіЯжcrashЕФЧщПіЪБЃЌbroker1бЁОйЮЊаТЕФleader[ISR=(1)]ЃЌвђЮЊЪмmin.insync.replicas=2гАЯьЃЌwriteВЛФмЗўЮёЃЌЕЋЪЧreadФмМЬаје§ГЃЗўЮёЁЃДЫжжЧщПіЛжИДЗНАИЃК
ГЂЪдЛжИД(жиЦє)replica-0ЃЌШчЙћФмЦ№РДЃЌЯЕЭГе§ГЃЃЛ
ШчЙћreplica-0ВЛФмЛжИДЃЌашвЊНЋmin.insync.replicasЩшжУЮЊ1ЃЌЛжИДwriteЙІФмЁЃ
ЕБISRжаЕФreplica-0ГіЯжcrashЃЌНєНгзХreplica-1вВГіЯжСЫcrash, ДЫЪБ[ISR=(1),leader=-1],ВЛФмЖдЭтЬсЙЉЗўЮёЃЌДЫжжЧщПіЛжИДЗНАИЃК
ГЂЪдЛжИДreplica-0КЭreplica-1ЃЌШчЙћЖМФмЦ№РДЃЌдђЯЕЭГЛжИДе§ГЃЃЛ
ШчЙћreplica-0Ц№РДЃЌЖјreplica-1ВЛФмЦ№РДЃЌетЪБКђШдШЛВЛФмбЁГіleaderЃЌвђЮЊЕБЩшжУunclean.leader.election.enable=falseЪБЃЌleaderжЛФмДгISRжабЁОйЃЌЕБISRжаЫљгаИББОЖМЪЇаЇжЎКѓЃЌашвЊISRжазюКѓЪЇаЇЕФФЧИіИББОФмЛжИДжЎКѓВХФмбЁОйleader,
МДreplica-0ЯШЪЇаЇЃЌreplica-1КѓЪЇаЇЃЌашвЊreplica-1ЛжИДКѓВХФмбЁОйleaderЁЃБЃЪиЕФЗНАИНЈвщАбunclean.leader.election.enableЩшжУЮЊtrue,ЕЋЪЧетбљЛсгаЖЊЪЇЪ§ОнЕФЧщПіЗЂЩњЃЌетбљПЩвдЛжИДreadЗўЮёЁЃЭЌбљашвЊНЋmin.insync.replicasЩшжУЮЊ1ЃЌЛжИДwriteЙІФмЃЛ
replica-1ЛжИДЃЌreplica-0ВЛФмЛжИДЃЌетИіЧщПіЩЯУцгіЕНЙ§ЃЌreadЗўЮёПЩгУЃЌашвЊНЋmin.insync.replicasЩшжУЮЊ1ЃЌЛжИДwriteЙІФмЃЛ
replica-0КЭreplica-1ЖМВЛФмЛжИДЃЌетжжЧщПіПЩвдВЮПМЧщаЮ2.
ЕБISRжаЕФreplica-0, replica-1ЭЌЪБхДЛњ,ДЫЪБ[ISR=(0,1)],ВЛФмЖдЭтЬсЙЉЗўЮёЃЌДЫжжЧщПіЛжИДЗНАИЃКГЂЪдЛжИДreplica-0КЭreplica-1ЃЌЕБЦфжаШЮвтвЛИіИББОЛжИДе§ГЃЪБЃЌЖдЭтПЩвдЬсЙЉreadЗўЮёЁЃжБЕН2ИіИББОЛжИДе§ГЃЃЌwriteЙІФмВХФмЛжИДЃЌЛђепНЋНЋmin.insync.replicasЩшжУЮЊ1ЁЃ
3.7 KafkaЕФЗЂЫЭФЃЪН
KafkaЕФЗЂЫЭФЃЪНгЩproducerЖЫЕФХфжУВЮЪ§producer.typeРДЩшжУЃЌетИіВЮЪ§жИЖЈСЫдкКѓЬЈЯпГЬжаЯћЯЂЕФЗЂЫЭЗНЪНЪЧЭЌВНЕФЛЙЪЧвьВНЕФЃЌФЌШЯЪЧЭЌВНЕФЗНЪНЃЌМДproducer.type=syncЁЃШчЙћЩшжУГЩвьВНЕФФЃЪНЃЌМДproducer.type=asyncЃЌПЩвдЪЧproducerвдbatchЕФаЮЪНpushЪ§ОнЃЌетбљЛсМЋДѓЕФЬсИпbrokerЕФадФмЃЌЕЋЪЧетбљЛсдіМгЖЊЪЇЪ§ОнЕФЗчЯеЁЃШчЙћашвЊШЗБЃЯћЯЂЕФПЩППадЃЌБиаывЊНЋproducer.typeЩшжУЮЊsyncЁЃ
ЖдгквьВНФЃЪНЃЌЛЙга4ИіХфЬзЕФВЮЪ§ЃЌШчЯТЃК

вдbatchЕФЗНЪНЭЦЫЭЪ§ОнПЩвдМЋДѓЕФЬсИпДІРэаЇТЪЃЌkafka producerПЩвдНЋЯћЯЂдкФкДцжаРлМЦЕНвЛЖЈЪ§СПКѓзїЮЊвЛИіbatchЗЂЫЭЧыЧѓЁЃbatchЕФЪ§СПДѓаЁПЩвдЭЈЙ§producerЕФВЮЪ§ЃЈbatch.num.messagesЃЉПижЦЁЃЭЈЙ§діМгbatchЕФДѓаЁЃЌПЩвдМѕЩйЭјТчЧыЧѓКЭДХХЬIOЕФДЮЪ§ЃЌЕБШЛОпЬхВЮЪ§ЩшжУашвЊдкаЇТЪКЭЪБаЇадЗНУцзівЛИіШЈКтЁЃдкБШНЯаТЕФАцБОжаЛЙгаbatch.sizeетИіВЮЪ§ЁЃ
4 ИпПЩППадЪЙгУЗжЮі
4.1 ЯћЯЂДЋЪфБЃеЯ
ЧАУцвбОНщЩмСЫKafkaШчКЮНјаагааЇЕФДцДЂЃЌвдМАСЫНтСЫproducerКЭconsumerШчКЮЙЄзїЁЃНгЯТРДЬжТлЕФЪЧKafkaШчКЮШЗБЃЯћЯЂдкproducerКЭconsumerжЎМфДЋЪфЁЃгавдЯТШ§жжПЩФмЕФДЋЪфБЃеЯЃЈdelivery
guaranteeЃЉ:
At most once: ЯћЯЂПЩФмЛсЖЊЃЌЕЋОјВЛЛсжиИДДЋЪф
At least onceЃКЯћЯЂОјВЛЛсЖЊЃЌЕЋПЩФмЛсжиИДДЋЪф
Exactly onceЃКУПЬѕЯћЯЂПЯЖЈЛсБЛДЋЪфвЛДЮЧвНіДЋЪфвЛДЮ
KafkaЕФЯћЯЂДЋЪфБЃеЯЛњжЦЗЧГЃжБЙлЁЃЕБproducerЯђbrokerЗЂЫЭЯћЯЂЪБЃЌвЛЕЉетЬѕЯћЯЂБЛcommitЃЌгЩгкИББОЛњжЦЃЈreplicationЃЉЕФДцдкЃЌЫќОЭВЛЛсЖЊЪЇЁЃЕЋЪЧШчЙћproducerЗЂЫЭЪ§ОнИјbrokerКѓЃЌгіЕНЕФЭјТчЮЪЬтЖјдьГЩЭЈаХжаЖЯЃЌФЧproducerОЭЮоЗЈХаЖЯИУЬѕЯћЯЂЪЧЗёвбОЬсНЛЃЈcommitЃЉЁЃЫфШЛKafkaЮоЗЈШЗЖЈЭјТчЙЪеЯЦкМфЗЂЩњСЫЪВУДЃЌЕЋЪЧproducerПЩвдretryЖрДЮЃЌШЗБЃЯћЯЂвбОе§ШЗДЋЪфЕНbrokerжаЃЌЫљвдФПЧАKafkaЪЕЯжЕФЪЧat
least onceЁЃ
consumerДгbrokerжаЖСШЁЯћЯЂКѓЃЌПЩвдбЁдёcommitЃЌИУВйзїЛсдкZookeeperжаДцЯТИУconsumerдкИУpartitionЯТЖСШЁЕФЯћЯЂЕФoffsetЁЃИУconsumerЯТвЛДЮдйЖСИУpartitionЪБЛсДгЯТвЛЬѕПЊЪМЖСШЁЁЃШчЮДcommitЃЌЯТвЛДЮЖСШЁЕФПЊЪМЮЛжУЛсИњЩЯвЛДЮcommitжЎКѓЕФПЊЪМЮЛжУЯрЭЌЁЃЕБШЛвВПЩвдНЋconsumerЩшжУЮЊautocommitЃЌМДconsumerвЛЕЉЖСШЁЕНЪ§ОнСЂМДздЖЏcommitЁЃШчЙћжЛЬжТлетвЛЖСШЁЯћЯЂЕФЙ§ГЬЃЌФЧKafkaЪЧШЗБЃСЫexactly
once, ЕЋЪЧШчЙћгЩгкЧАУцproducerгыbrokerжЎМфЕФФГжждвђЕМжТЯћЯЂЕФжиИДЃЌФЧУДетРяОЭЪЧat
least onceЁЃ
ПМТЧетбљвЛжжЧщПіЃЌЕБconsumerЖСЭъЯћЯЂжЎКѓЯШcommitдйДІРэЯћЯЂЃЌдкетжжФЃЪНЯТЃЌШчЙћconsumerдкcommitКѓЛЙУЛРДЕУМАДІРэЯћЯЂОЭcrashСЫЃЌЯТДЮжиаТПЊЪМЙЄзїКѓОЭЮоЗЈЖСЕНИеИевбЬсНЛЖјЮДДІРэЕФЯћЯЂЃЌетОЭЖдгІгкat
most onceСЫЁЃ
ЖСЭъЯћЯЂЯШДІРэдйcommitЁЃетжжФЃЪНЯТЃЌШчЙћДІРэЭъСЫЯћЯЂдкcommitжЎЧАconsumer crashСЫЃЌЯТДЮжиаТПЊЪМЙЄзїЪБЛЙЛсДІРэИеИеЮДcommitЕФЯћЯЂЃЌЪЕМЪЩЯИУЯћЯЂвбОБЛДІРэЙ§СЫЃЌетОЭЖдгІгкat
least onceЁЃ
вЊзіЕНexactly onceОЭашвЊв§ШыЯћЯЂШЅжиЛњжЦЁЃ
4.2 ЯћЯЂШЅжи
ШчЩЯвЛНкЫљЪіЃЌKafkaдкproducerЖЫКЭconsumerЖЫЖМЛсГіЯжЯћЯЂЕФжиИДЃЌетОЭашвЊШЅжиДІРэЁЃ
KafkaЮФЕЕжаЬсМАGUID(Globally Unique Identifier)ЕФИХФюЃЌЭЈЙ§ПЭЛЇЖЫЩњГЩЫуЗЈЕУЕНУПИіЯћЯЂЕФunique
idЃЌЭЌЪБПЩгГЩфжСbrokerЩЯДцДЂЕФЕижЗЃЌМДЭЈЙ§GUIDБуПЩВщбЏЬсШЁЯћЯЂФкШнЃЌвВБугкЗЂЫЭЗНЕФУнЕШадБЃжЄЃЌашвЊдкbrokerЩЯЬсЙЉДЫШЅжиДІРэФЃПщЃЌФПЧААцБОЩаВЛжЇГжЁЃ
еыЖдGUID, ШчЙћДгПЭЛЇЖЫЕФНЧЖШШЅжиЃЌФЧУДашвЊв§ШыМЏжаЪНЛКДцЃЌБиШЛЛсдіМгвРРЕИДдгЖШЃЌСэЭтЛКДцЕФДѓаЁФбвдНчЖЈЁЃ
ВЛжЛЪЧKafka, РрЫЦRabbitMQвдМАRocketMQетРрЩЬвЕМЖжаМфМўвВжЛБЃеЯat least
once, ЧввВЮоЗЈДгздЩэШЅНјааЯћЯЂШЅжиЁЃЫљвдЮвУЧНЈвщвЕЮёЗНИљОнздЩэЕФвЕЮёЬиЕуНјааШЅжиЃЌБШШчвЕЮёЯћЯЂБОЩэОпБИУнЕШадЃЌЛђепНшжњRedisЕШЦфЫћВњЦЗНјааШЅжиДІРэЁЃ
4.3 ИпПЩППадХфжУ
KafkaЬсЙЉСЫКмИпЕФЪ§ОнШпгрЕЏадЃЌЖдгкашвЊЪ§ОнИпПЩППадЕФГЁОАЃЌЮвУЧПЩвддіМгЪ§ОнШпгрБИЗнЪ§ЃЈreplication.factorЃЉЃЌЕїИпзюаЁаДШыИББОЪ§ЕФИіЪ§ЃЈmin.insync.replicasЃЉЕШЕШЃЌЕЋЪЧетбљЛсгАЯьадФмЁЃЗДжЎЃЌадФмЬсИпЖјПЩППаддђНЕЕЭЃЌгУЛЇашвЊздЩэвЕЮёЬиаддкБЫДЫжЎМфзівЛаЉШЈКтадбЁдёЁЃ
вЊБЃжЄЪ§ОнаДШыЕНKafkaЪЧАВШЋЕФЃЌИпПЩППЕФЃЌашвЊШчЯТЕФХфжУЃК
topicЕФХфжУЃКreplication.factor>=3,МДИББОЪ§жСЩйЪЧ3ИіЃЛ2<=min.insync.replicas<=replication.factor
brokerЕФХфжУЃКleaderЕФбЁОйЬѕМўunclean.leader.election.enable=false
producerЕФХфжУЃКrequest.required.acks=-1(all)ЃЌproducer.type=sync
5 BenchMark
KafkaдкЮЈЦЗЛсгазХКмЩюЕФРњЪЗдЈдДЃЌИљОнЮЈЦЗЛсЯћЯЂжаМфМўЭХЖгЃЈVMSЭХЖгЃЉЫљеЦЮеЕФзЪСЯЯдЪОЃЌдкVMSЭХЖгдЫзЊЕФKafkaМЏШКжаЫљжЇГХЕФtopicЪ§вбНгНќ2000ЃЌУПЬьЕФЧыЧѓСПвВвбДяЧЇвкМЖЁЃетРяОЭвдKafkaЕФИпПЩППадЮЊЛљзМЕуРДЬНОПМИжжВЛЭЌГЁОАЯТЕФааЮЊБэЯжЃЌвдДЫРДМгЩюЖдKafkaЕФШЯжЊЃЌЮЊДѓМвдквдКѓИпаЇЕФЪЙгУKafkaЪБЬсЙЉвЛЗнвРОнЁЃ
5.1 ВтЪдЛЗОГ
Kafka brokerгУЕНСЫ4ЬЈЛњЦїЃЌЗжБ№ЮЊbroker[0/1/2/3]ХфжУШчЯТЃК
CPU: 24core/2.6GHZ
Memory: 62G
Network: 4000Mb
OS/kernel: CentOs release 6.6 (Final)
Disk: 1089G
KafkaАцБОЃК0.10.1.0
brokerЖЫJVMВЮЪ§ЩшжУЃК
-Xmx8G -Xms8G -serverX: +UseParNewGC
-XX:+UseConcMarkSweepGC -XX:
+CMSClassUnloadingEnabled -XX:
+CMSScavengeBeforeRemark -XX:
+DisableExplicitGC -Djava.awt.
headless=true -Xloggc :/apps/service/kafka/bin/../
logs/kafkaServer-gc.log -verbose:gc -XX:+PrintGCDetails
-XX:+PrintGCDateStamps -XX:
+PrintGCTimeStamps - Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.authenticate =false
-Dcom.sun.management.jmxremote.ssl =false
-Dcom.sun.management.jmxremote.port =9999 |
ПЭЛЇЖЫЛњЦїХфжУЃК
CPU: 24core/2.6GHZ
Memory: 3G
Network: 1000Mb
OS/kernel: CentOs release 6.3 (Final)
Disk: 240G
5.2 ВЛЭЌГЁОАВтЪд
ГЁОА1ЃКВтЪдВЛЭЌЕФИББОЪ§ЁЂmin.insync.replicasВпТдвдМАrequest.required.acksВпТдЃЈвдЯТМђГЦacksВпТдЃЉЖдгкЗЂЫЭЫйЖШЃЈTPSЃЉЕФгАЯьЁЃ
ОпЬхХфжУЃКвЛИіproducerЃЛЗЂЫЭЗНЪНЮЊsyncЃЛЯћЯЂЬхДѓаЁЮЊ1kBЃЛpartitionЪ§ЮЊ12ЁЃИББОЪ§ЮЊЃК1/2/4ЃЛmin.insync.replicasЗжБ№ЮЊ1/2/4ЃЛacksЗжБ№ЮЊ-1ЃЈallЃЉ/1/0ЁЃ
ОпЬхВтЪдЪ§ОнШчЯТБэЃЈmin.insync.replicasжЛдкacks=-1ЪБгааЇЃЉЃК
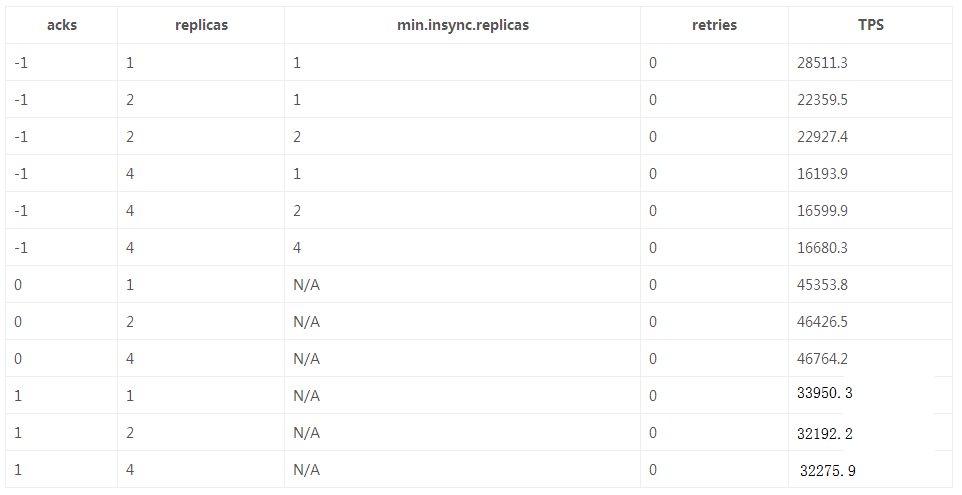
ВтЪдНсЙћЗжЮіЃК
ПЭЛЇЖЫЕФacksВпТдЖдЗЂЫЭЕФTPSгаНЯДѓЕФгАЯьЃЌTPSЃКacks_0 > acks_1 >
ack_-1;
ИББОЪ§дНИпЃЌTPSдНЕЭЃЛИББОЪ§вЛжТЪБЃЌmin.insync.replicasВЛгАЯьTPSЃЛ
acks=0/1ЪБЃЌTPSгыmin.insync.replicasВЮЪ§вдМАИББОЪ§ЮоЙиЃЌНіЪмacksВпТдЕФгАЯьЁЃ
ЯТУцНЋpartitionЕФИіЪ§ЩшжУЮЊ1ЃЌРДНјвЛВНШЗШЯЯТВЛЭЌЕФacksВпТдЁЂВЛЭЌЕФmin.insync.replicasВпТдвдМАВЛЭЌЕФИББОЪ§ЖдгкЗЂЫЭЫйЖШЕФгАЯьЃЌЯъЯИЧыПДЧщОА2КЭЧщОА3ЁЃ
ГЁОА2ЃКдкpartitionИіЪ§ЙЬЖЈЮЊ1ЃЌВтЪдВЛЭЌЕФИББОЪ§КЭmin.insync.replicasВпТдЖдЗЂЫЭЫйЖШЕФгАЯьЁЃ
ОпЬхХфжУЃКвЛИіproducerЃЛЗЂЫЭЗНЪНЮЊsyncЃЛЯћЯЂЬхДѓаЁЮЊ1kBЃЛproducerЖЫacks=-1(all)ЁЃБфЛЛИББОЪ§ЃК2/3/4ЃЛ
min.insync.replicasЩшжУЮЊЃК1/2/4ЁЃ
ВтЪдНсЙћШчЯТЃК
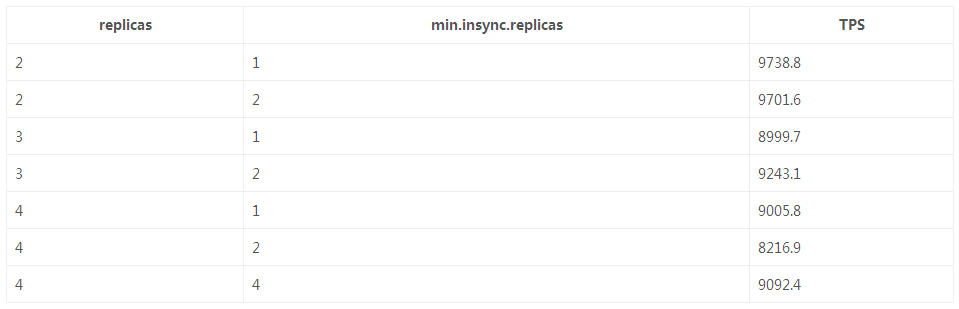
ВтЪдНсЙћЗжЮіЃКИББОЪ§дНИпЃЌTPSдНЕЭЃЈетЕугыГЁОА1ЕФВтЪдНсТлЮЧКЯЃЉЃЌЕЋЪЧЕБpartitionЪ§ЮЊ1ЪБВюОрЩѕЮЂЁЃmin.insync.replicasВЛгАЯьTPSЁЃ
ГЁОА3ЃКдкpartitionИіЪ§ЙЬЖЈЮЊ1ЃЌВтЪдВЛЭЌЕФacksВпТдКЭИББОЪ§ЖдЗЂЫЭЫйЖШЕФгАЯьЁЃ
ОпЬхХфжУЃКвЛИіproducerЃЛЗЂЫЭЗНЪНЮЊsyncЃЛЯћЯЂЬхДѓаЁЮЊ1kBЃЛmin.insync.replicas=1ЁЃtopicИББОЪ§ЮЊЃК1/2/4ЃЛacksЃК
0/1/-1ЁЃ
ВтЪдНсЙћШчЯТЃК
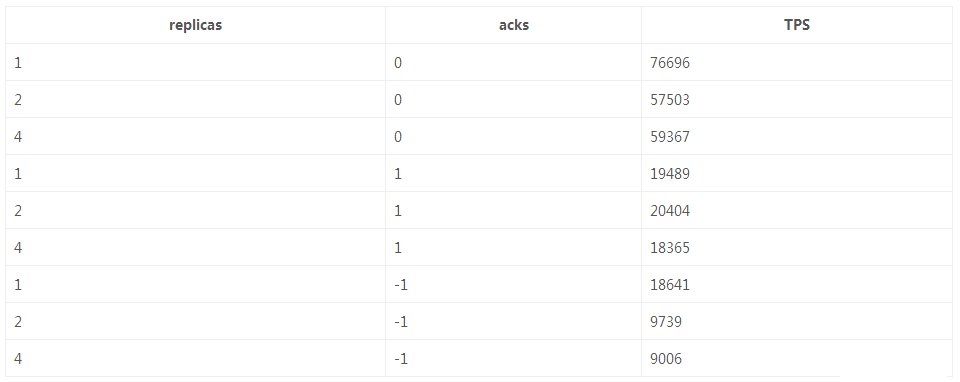
ВтЪдНсЙћЗжЮіЃЈгыЧщОА1вЛжТЃЉЃК
ИББОЪ§дНЖрЃЌTPSдНЕЭЃЛ
ПЭЛЇЖЫЕФacksВпТдЖдЗЂЫЭЕФTPSгаНЯДѓЕФгАЯьЃЌTPSЃКacks_0 > acks_1 >
ack_-1ЁЃ
ГЁОА4ЃКВтЪдВЛЭЌpartitionЪ§ЖдЗЂЫЭЫйТЪЕФгАЯь
ОпЬхХфжУЃКвЛИіproducerЃЛЯћЯЂЬхДѓаЁЮЊ1KBЃЛЗЂЫЭЗНЪНЮЊsyncЃЛtopicИББОЪ§ЮЊ2ЃЛmin.insync.replicas=2ЃЛacks=-1ЁЃpartitionЪ§СПЩшжУЮЊ1/2/4/8/12ЁЃ
ВтЪдНсЙћЃК
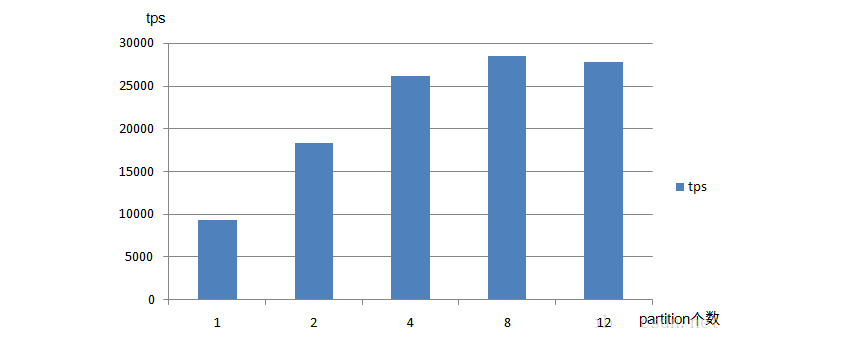
ВтЪдНсЙћЗжЮіЃКpartitionЕФВЛЭЌЛсгАЯьTPSЃЌЫцзХpartitionЕФИіЪ§ЕФдіГЄTPSЛсгаЫљдіГЄЃЌЕЋВЂВЛЪЧвЛжБГЩе§БШЙиЯЕЃЌЕНДявЛЖЈСйНчжЕЪБЃЌpartitionЪ§СПЕФдіМгЗДЖјЛсЪЙTPSТдЮЂНЕЕЭЁЃ
ГЁОА5ЃКЭЈЙ§НЋМЏШКжаВПЗжbrokerЩшжУГЩВЛПЩЗўЮёзДЬЌЃЌВтЪдЖдПЭЛЇЖЫвдМАЯћЯЂТфХЬЕФгАЯьЁЃ
ОпЬхХфжУЃКвЛИіproducerЃЛЯћЯЂЬхДѓаЁ1KB;ЗЂЫЭЗНЪНЮЊsyncЃЛtopicИББОЪ§ЮЊ4ЃЛmin.insync.replicasЩшжУЮЊ2ЃЛacks=-1ЃЛretries=0/100000000ЃЛpartitionЪ§ЮЊ12ЁЃ
ОпЬхВтЪдЪ§ОнШчЯТБэЃК

ГіДэаХЯЂЃК
ДэЮѓ1ЃКПЭЛЇЖЫЗЕЛивьГЃЃЌВПЗжЪ§ОнПЩТфХЬЃЌВПЗжЪЇАмЃКorg.apache.kafka.common.errors.NetworkException:
The server disconnected before a response was received.
ДэЮѓ2 ЃК[WARN]internals.Sender - Got error produce response
with correlation id 19369 on topic - partition default_channel_replicas_4_1-3,
retrying (999999999 attempts left). Error: NETWORK_EXCEPTION
ДэЮѓ3ЃК [WARN]internals.Sender - Got error produce response
with correlation id 77890 on topic-partition default_channel_replicas_4_1-8,
retrying (999999859 attempts left) . Error: NOT_ENOUGH_REPLICAS
ДэЮѓ4ЃК [WARN]internals.Sender - Got error produce response
with correlation id 77705 on topic - partition default_channel_replicas_4_1-3,
retrying (999999999 attempts left). Error: NOT_ENOUGH_REPLICAS _AFTER_APPEND
ВтЪдНсЙћЗжЮіЃК
killСНЬЈbrokerКѓЃЌПЭЛЇЖЫПЩвдМЬајЗЂЫЭЁЃbrokerМѕЩйКѓЃЌpartitionЕФleaderЗжВМдкЪЃгрЕФСНЬЈbrokerЩЯЃЌдьГЩСЫTPSЕФМѕаЁЃЛ
killШ§ЬЈbrokerКѓЃЌПЭЛЇЖЫЮоЗЈМЬајЗЂЫЭЁЃKafkaЕФздЖЏжиЪдЙІФмПЊЪМЦ№зїгУЃЌЕБДѓгкЕШгкmin.insync.replicasЪ§СПЕФbrokerЛжИДКѓЃЌПЩвдМЬајЗЂЫЭЃЛ
ЕБretriesВЛЮЊ0ЪБЃЌЯћЯЂгажиИДТфХЬЃЛПЭЛЇЖЫГЩЙІЗЕЛиЕФЯћЯЂЖМГЩЙІТфХЬЃЌвьГЃЪБВПЗжЯћЯЂПЩвдТфХЬЁЃ
ГЁОА6ЃКВтЪдЕЅИіproducerЕФЗЂЫЭбгГйЃЌвдМАЖЫЕНЖЫЕФбгГйЁЃ
ОпЬхХфжУЃКЃКвЛИіproducerЃЛЯћЯЂЬхДѓаЁ1KBЃЛЗЂЫЭЗНЪНЮЊsyncЃЛtopicИББОЪ§ЮЊ4ЃЛmin.insync.replicasЩшжУЮЊ2ЃЛacks=-1ЃЛpartitionЪ§ЮЊ12ЁЃ
ВтЪдЪ§ОнМАНсЙћЃЈЕЅЮЛЮЊmsЃЉЃК

ИїГЁОАВтЪдзмНсЃК
ЕБacks=-1ЪБЃЌKafkaЗЂЫЭЖЫЕФTPSЪмЯогкtopicЕФИББОЪ§СПЃЈISRжаЃЉЃЌИББОдНЖрTPSдНЕЭЃЛ
acks=0ЪБЃЌTPSзюИпЃЌЦфДЮЮЊ1ЃЌзюВюЮЊ-1ЃЌ МД TPSЃКacks_0
> acks_1 > ack_-1ЃЛ
min.insync.replicasВЮЪ§ВЛгАЯь TPSЃЛ
partitionЕФВЛЭЌЛсгАЯьTPSЃЌЫцзХpartitionЕФИіЪ§ЕФдіГЄTPSЛсгаЫљдіГЄЃЌЕЋВЂВЛЪЧвЛжБГЩе§БШЙиЯЕЃЌЕНДявЛЖЈСйНчжЕЪБЃЌpartitionЪ§СПЕФдіМгЗДЖјЛсЪЙTPSТдЮЂНЕЕЭЃЛ
Kafkaдкacks=-1, min.insync.replicas>=1ЪБЃЌОпгаИпПЩППадЃЌЫљгаГЩЙІЗЕЛиЕФЯћЯЂЖМПЩвдТфХЬЁЃ |









