一、执行模式
提交脚本常见的语法:
./bin/spark-submit \
--class <main-class>
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
|
脚本说明:
(1)―-class: 主类,即main函数所有的类
(2)―- master : master的URL,见下面的详细说明。
(3)―-deploy-mode:client和cluster2种模式
(4)―-conf:指定key=value形式的配置
下面对各种模式做一个说明:
1、local
本地跑程序,一般用来测试。可以指定线程数
| # Run application locally on 8 cores ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[8] \ /path/to/examples.jar \ 100 |
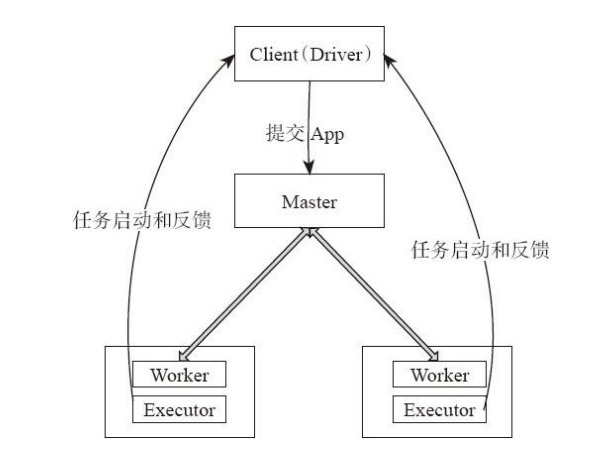
2.Standalone client
该方式应用执行流程:
(1)用户启动客户端,之后客户端运行用户程序,启动Driver进程。在Driver中启动或实例化DAGScheduler等组件。
客户端的Driver向Master注册。
(2)Worker向Master注册,Master命令Worker启动Exeuctor。Worker通过创建ExecutorRunner线程,在ExecutorRunner线程内部启动ExecutorBackend进程。
(3)ExecutorBackend启动后,向客户端Driver进程内的SchedulerBackend注册,这样Driver进程就能找到计算资源。Driver的DAGScheduler解析应用中的RDD
DAG并生成相应的Stage,每个Stage包含的TaskSet通过TaskScheduler分配给Executor。
在Executor内部启动线程池并行化执行Task。
示例脚本:
| # Run on a Spark Standalone cluster in client deploy mode ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://207.184.161.138:7077 \ --executor-memory 20G \ --total-executor-cores 100 \ /path/to/examples.jar \ 1000 |
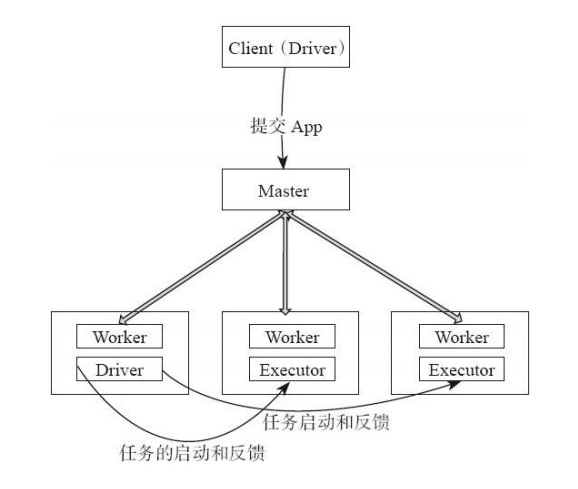
3、standalone cluster
该方式应用执行流程:
(1)用户启动客户端,客户端提交应用程序给Master。
(2)Master调度应用,针对每个应用分发给指定的一个Worker启动Driver,即Scheduler-Backend。
Worker接收到Master命令后创建DriverRunner线程,在DriverRunner线程内创建SchedulerBackend进程。Driver充当整个作业的主控进程。Master会指定其他Worker启动Exeuctor,即ExecutorBackend进程,提供计算资源。流程和上面很相似,(3)Worker创建ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
(4)ExecutorBackend启动后,向Driver的SchedulerBackend注册,这样Driver获取了计算资源就可以调度和将任务分发到计算节点执行。SchedulerBackend进程中包含DAGScheduler,它会根据RDD的DAG切分Stage,生成TaskSet,并调度和分发Task到Executor。对于每个Stage的TaskSet,都会被存放到TaskScheduler中。TaskScheduler将任务分发到Executor,执行多线程并行任务。
示例脚本:
| # Run on a Spark Standalone cluster in cluster deploy mode with supervise ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://207.184.161.138:7077 \ --deploy-mode cluster --supervise --executor-memory 20G \ --total-executor-cores 100 \ /path/to/examples.jar \ 1000 |
4、yarn-client
在yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor
container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
客户端的Driver将应用提交给Yarn后,Yarn会先后启动ApplicationMaster和executor,另外ApplicationMaster和executor都
是装载在container里运行,container默认的内存是1G,ApplicationMaster分配的内存是driver-
memory,executor分配的内存是executor-memory。同时,因为Driver在客户端,所以程序的运行结果可以在客户端显
示,Driver以进程名为SparkSubmit的形式存在。
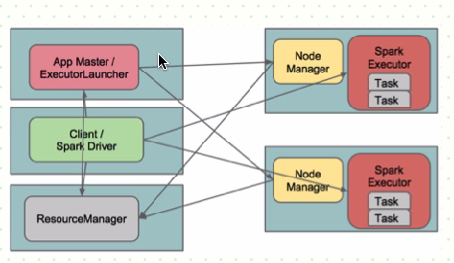
Yarn-client模式下作业执行流程:
1. 客户端生成作业信息提交给ResourceManager(RM)
2. RM在本地NodeManager启动container并将Application Master(AM)分配给该NodeManager(NM)
3. NM接收到RM的分配,启动Application Master并初始化作业,此时这个NM就称为Driver
4. Application向RM申请资源,分配资源同时通知其他NodeManager启动相应的Executor
5. Executor向本地启动的Application Master注册汇报并完成相应的任务
示例脚本:
| # Run on a YARN client export HADOOP_CONF_DIR=XXX ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn-client \ --executor-memory 20G \ --num-executors 50 \ /path/to/examples.jar \ 1000 |
5、Yarn-cluster
Spark Driver首先作为一个ApplicationMaster在YARN集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark
Master/Client,应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况
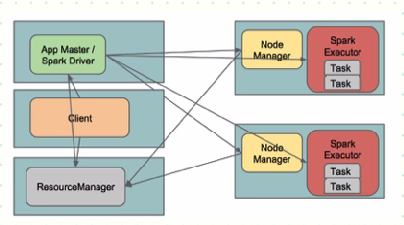
Yarn-cluster模式下作业执行流程:
1. 客户端生成作业信息提交给ResourceManager(RM)
2. RM在某一个NodeManager(由Yarn决定)启动container并将Application
Master(AM)分配给该NodeManager(NM)
3. NM接收到RM的分配,启动Application Master并初始化作业,此时这个NM就称为Driver
4. Application向RM申请资源,分配资源同时通知其他NodeManager启动相应的Executor
5. Executor向NM上的Application Master注册汇报并完成相应的任务
示例脚本:
| # Run on a YARN cluster export HADOOP_CONF_DIR=XXX ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn-cluster \ --executor-memory 20G \ --num-executors 50 \ /path/to/examples.jar \ 1000 |
二、执行注意事项
1、关于jar包
hadoop和spark的配置会被自动加载到SparkContext,因此,提交application时只需要提交用户的代码以及其它依赖包,这有2种做法:
(1)将用户代码打包成jar,然后在提交application时使用―-jar来添加依赖jar包(推荐使用这种方法)
(2)将用户代码与依赖一起打包成一个大包 assembly jar (打一个jar包,有可能整个jar打出来上百M,打包和发布过程慢)
2、调试模式
Spark Standlong模式:
只支持FIFO
Spark On Mesos模式:有两种调度模式
1) 粗粒度模式(Coarse-grained Mode)
2) 细粒度模式(Fine-grained Mode)
Spark On YARN模式:
目前仅支持粗粒度模式(Coarse-grained Mode)
3、读取配置优先级
在代码中的SparkConf中的配置参数具有最高优先级,其次是传送spark-submit脚本的参数,最后是配置文件(conf/spark-defaults.conf)中的参数。
如果不清楚配置参数从何而来,可以使用spark-submit的―verbose选项来打印出细粒度的调度信息。
|






