| 1
简介
Hive作为Hadoop家族历史最悠久的组件之一,一直以其优秀的兼容性支持和稳定性而著称,越来越多的企业将业务数据从传统数据库迁移至Hadoop平台,并通过Hive来进行数据分析。但是我们在迁移的过程中难免会碰到如何将传统数据库的功能也迁移到Hadoop的问题,比如说事务。事务作为传统数据库很重要的一个功能,在Hive中是如何实现的呢?Hive的实现有什么不一样的地方呢?我们将传统数据库的应用迁移到Hive如果有事务相关的场景我们该如何去转换并要注意什么问题呢?
本文会通过很多真实测试案例来比较Hive与传统数据库事务的区别,并在文末给出一些在Hive平台上使用事务相关的功能时的指导和建议。
2 ACID与实现原理
为了方便解释和说明后面的一些问题,这里重提传统数据库事务相关的概念,以下内容来源于网络。
2.1 ACID说明
1.原子性(Atomicity)
2.一个事务是一个不可再分割的工作单位,事务中的所有操作要么都发生,要么都不发生。
3.一致性(Consistency)
4.事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。这是说数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。
5.隔离性(Isolation)
6.多个事务并发访问,事务之间是隔离的,一个事务不影响其它事务运行效果。这指的是在并发环境中,当不同的事务同时操作相同的数据时,每个事务都有各自完整的数据空间。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改后的状态,事务不会查看到中间状态的数据。
7.事务之间的相应影响,分别为:脏读、不可重复读、幻读、丢失更新。
8.持久性(Durability)
9.意味着在事务完成以后,该事务锁对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
2.2 ACID的实现原理
事务可以保证ACID原则的操作,那么事务是如何保证这些原则的?解决ACID问题的两大技术点是:
1.预写日志(Write-ahead logging)保证原子性和持久性
2.锁(locking)保证隔离性
这里并没有提到一致性,是因为一致性是应用相关的话题,它的定义一个由业务系统来定义,什么样的状态才是一致?而实现一致性的代码通常在业务逻辑的代码中得以体现。
注:锁是指在并发环境中通过读写锁来保证操作的互斥性。根据隔离程度不同,锁的运用也不同。
3 测试环境
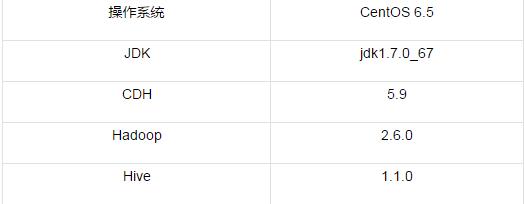
4 Hive的ACID测试
4.1 Hive中的锁(不开启事务)
Hive中定义了两种锁的模式:共享锁(S)和排它锁(X),顾名思义,多个共享锁(S)可以同时获取,但是排它锁(X)会阻塞其它所有锁。在本次测试中,CDH5.9的Concurrency参数是默认开启的(hive.support.concurrency=true),以下分别对开启Concurrency和关闭进行相关测试。
首先在测试之前,创建一个普通的hive表:
| create table test_notransaction(user_id Int,name String);
|
向test_transaction表中插入测试数据:
| insert into test_notransaction values(1,'peach1'),(2,'peach2'),(3, 'peach3'),(4, 'peach4');
|
查看插入的数据:
(点击放大图像)

4.1.1 开启Concurrency
1. 对catalog_sales表进行并发select操作
执行的sql语句:select count(*) from catalog_sales;
执行单条sql查询时,获取一个共享锁(S),sql语句正常执行
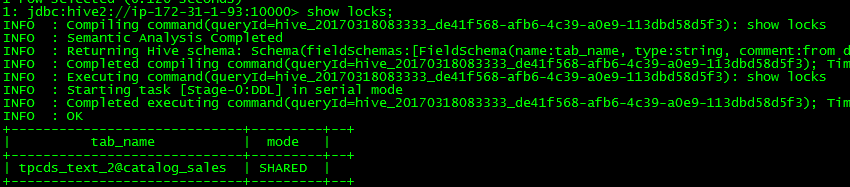
同时执行两条sql查询是,获取两个共享锁,并且sql语句均正常执行

分析:由此对比可得出hive在执行sql查询时获取Share锁,在并发的情况下可获取多个共享锁。
2. 对test表进行并发Insert操作
创建表:
| create table test(name string, id int);
|
执行sql语句:
| insert into test values('test11aaa1',1252); insert into test values('test1',52);
|
执行单条insert语句时,获取一个X锁,sql语句正常执行

同时执行两条insert语句时,只能获取一个test表X锁,第一条insert语句正常执行,第二条insert语句处于等待状态,在第一条insert语句释放test表的X锁,第二条sql语句正常执行.
分析:由此对比可得出hive在执行insert操作时,只能获取一个X锁且锁不能共享,只能在sql执行完成释放锁后,后续sql方可继续执行。
3. 对test表执行select的同时执行insert操作
执行sql语句:
| select count(*) from test; insert into test values("test123",123);
|
步骤:
1) 执行select语句,在select未运行完时,在新的窗口同时执行insert语句观察两条sql执行情况,select语句正常执行,insert语句处于等待状态。
2) 此时查看test表锁状态

在步骤1的执行过程中,获取到test表的锁为共享锁(S)
3) 在select语句执行完成后,观察insert语句开始正常执行,此时获取test表锁为排它锁(X)。注意:在select语句执行完成后,大概过40s左右insert语句才正常执行,这是由hive.lock.sleep.between.retries参数控制,默认60

分析: 由上述操作可得出,hive中一个表只能有一个排它锁(X)且锁不能共享,在获取排它锁时,表上不能有其它锁包括共享锁(S),只有在表上所有的锁都释放后,insert操作才能继续,否则处于等待状态。
对注意部分进行参数调整,将hive.lock.sleep.between.retries设置为10s,再次进行测试发现,在select语句执行完成后,大概过6s左右insert语句开始执行,通过两次测试发现,等待时间均在10s以内,由此可以得出此参数影响sql操作获取锁的间隔(在未获取到锁的情况下),如果此时未到获取锁触发周期,执行其它sql则,该sql会优于等待的sql执行。
4. 对test表执行insert的同时执行select操作
执行sql语句:
| insert into test values("test123",123); select count(*) from test;
|
操作步骤:
1) 在命令窗口执行insert语句,在insert操作未执行完成时,在新的命令窗口执行select语句,观察两个窗口的sql执行情况,insert语句正常执行,select语句处于等待状态。
2) 此时查看test表锁状态,只有insert操作获取的排它锁(X)

3) 在insert语句执行完成后,观察select语句开始正常执行,此时查看test表锁状态为共享锁(S),之前的insert操作获取的排它锁(X)已被释放

分析:在test表锁状态为排它锁(X)时,所有的操作均被阻塞处于等待状态,只有在排它锁(X)释放其它操作可继续进行。
5. 测试update和delete修改test表数据
sql语句:
update test set name='aaaa' where id=1252; delete test set name='bbbb' where id=123;
|
1) 表中数据,更新前

2) 在beeline窗口执行update操作

执行update操作报错,异常提示“Attempt to do update or delete using
transaction manager that does not support these operations”,在非事务模式下不支持update
和 delete。
4.1.2 关闭Concurrency
1. 执行insert操作的同时执行select操作
sql语句:
insert into test_notransaction values(1,'peach1'),(2,'peach2'),(3, 'peach3'),(4, 'peach4'); select count(*) from test_notransaction;
|
操作sql前,查看表数据
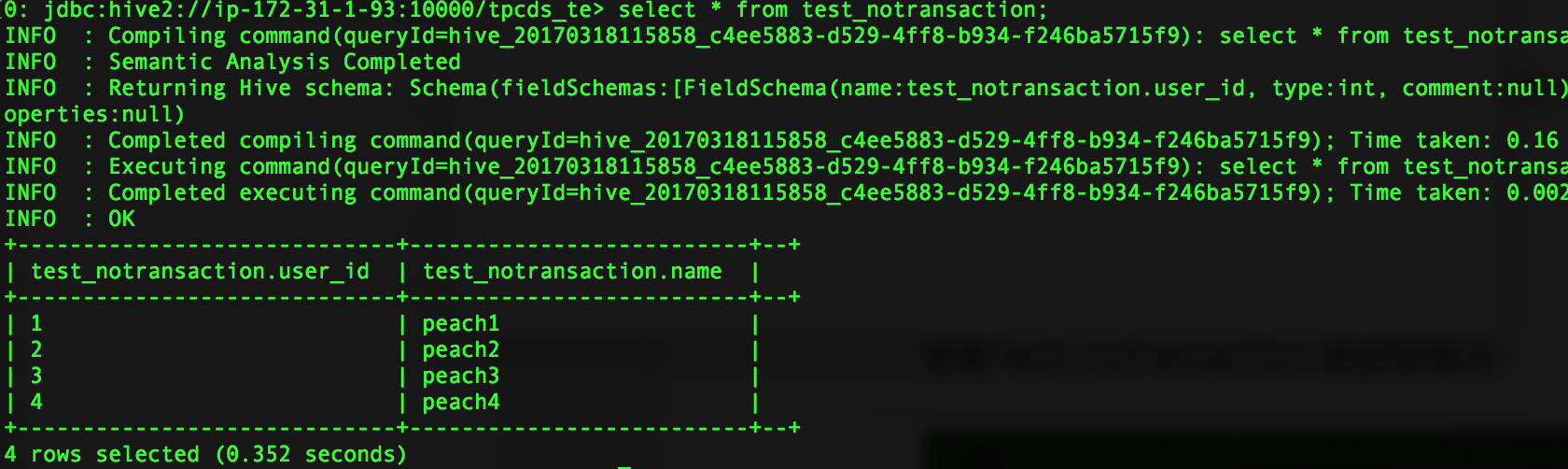
查看test_notransaction表获取情况,show locks;

hive在未开启concurrency 的情况下,show locks不能正常获取表的锁,同时对同一张表执行insert和select操作时并发执行,获取数据取决于sql执行速度,因此在select
的时候未获取到插入数据。
2. 执行select操作的同时执行insert操作
sql语句:
select count(*) from test_notransaction; insert into test_notransaction values(1,'peach1'),(2,'peach2'),(3, 'peach3'),(4, 'peach4');
|
在执行select的同时执行insert操作,操作可以同时并行操作,未产生阻塞等待的过程。
3. 同时执行多条insert操作
sql语句:
insert into test_notransaction values(1,'peach1'),(2,'peach2'),(3, 'peach3'),(4, 'peach4'); insert into test_notransaction values(1,'peach1'),(2,'peach2'),(3, 'peach3'),(4, 'peach4');
|
同时执行insert操作时,可同时执行未产生阻塞等待的过程。
4. 执行update操作,将表中user_id为2的用户名修改为peach22
sql语句:
update test_notransaction set name='peach22' where user_id=2;
|
执行update操作,执行结果如下:

在未配置hive的Transaction和ACID时,不支持update操作。
5. 执行delete操作,将表中user_id为1信息删除
sql语句:
delete from test_notransaction where user_id=1;
|
执行delete操作,执行结果如下:

hive未配置Transaction和ACID,不支持delete操作。
6. 查看表获取锁类型
show locks;
无法正常执行;
4.2 Hive的事务
4.2.1 Hive的事务配置
Hive从0.13开始加入了事务支持,在行级别提供完整的ACID特性,Hive在0.14时加入了对INSERT...VALUES,UPDATE,and
DELETE的支持。对于在Hive中使用ACID和Transactions,主要有以下限制:
不支持BEGIN,COMMIT和ROLLBACK
只支持ORC文件格式
表必须分桶
不允许从一个非ACID连接写入/读取ACID表
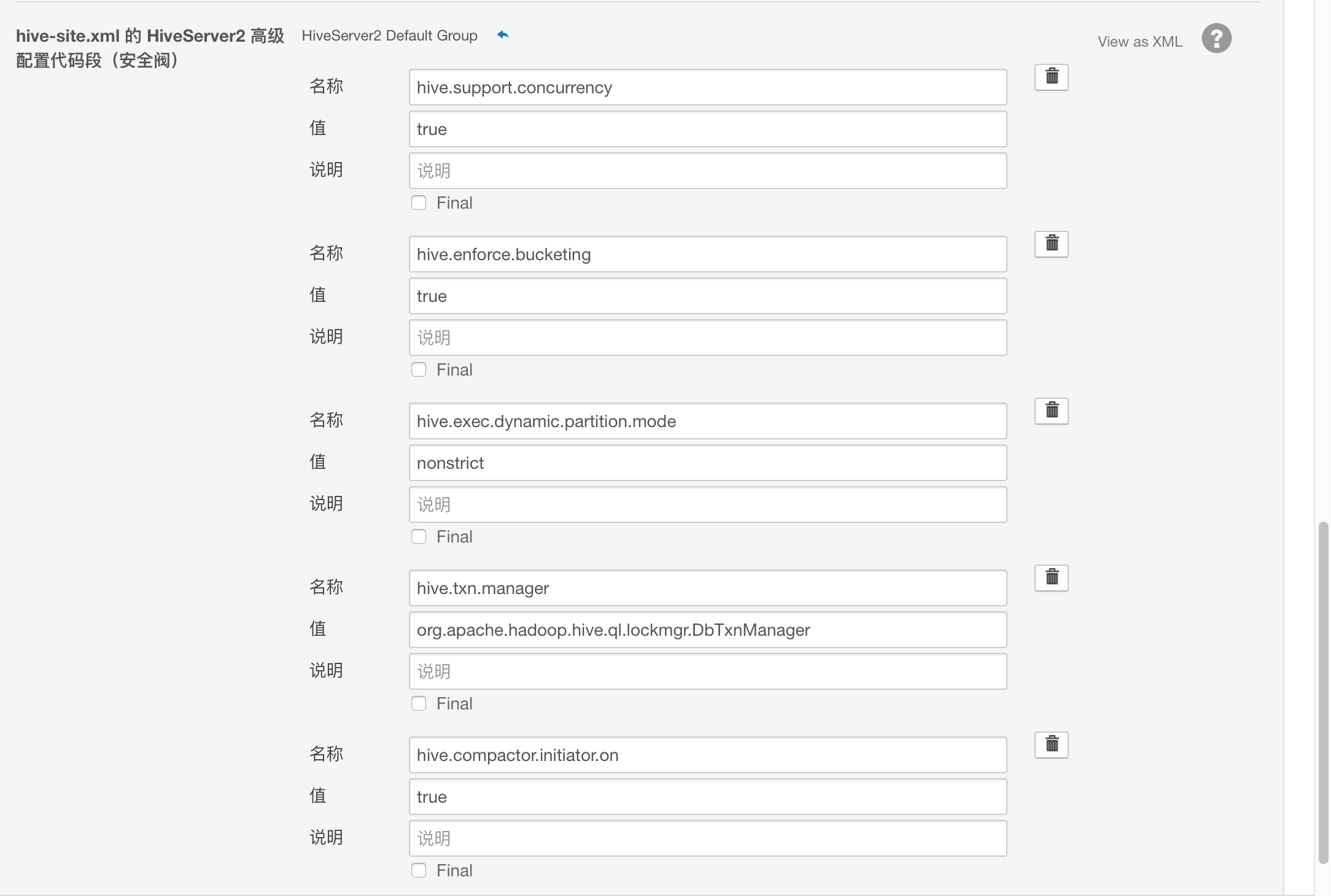
为了使Hive支持事务操作,需将以下参数加入到hive-site.xml文件中。
<property><name>hive.support.concurrency</name> <value>true</value> </property> <property> <name>hive.enforce.bucketing</name> <value>true</value> </property> <property> <name>hive.exec.dynamic.partition.mode</name> <value>nonstrict</value> </property> <property> <name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value> </property> <property> <name>hive.compactor.initiator.on</name> <value>true</value> </property> <property> <name>hive.compactor.worker.threads </name> <value>1</value> </property>
|
可以在Cloudera Manager进行以下配置:
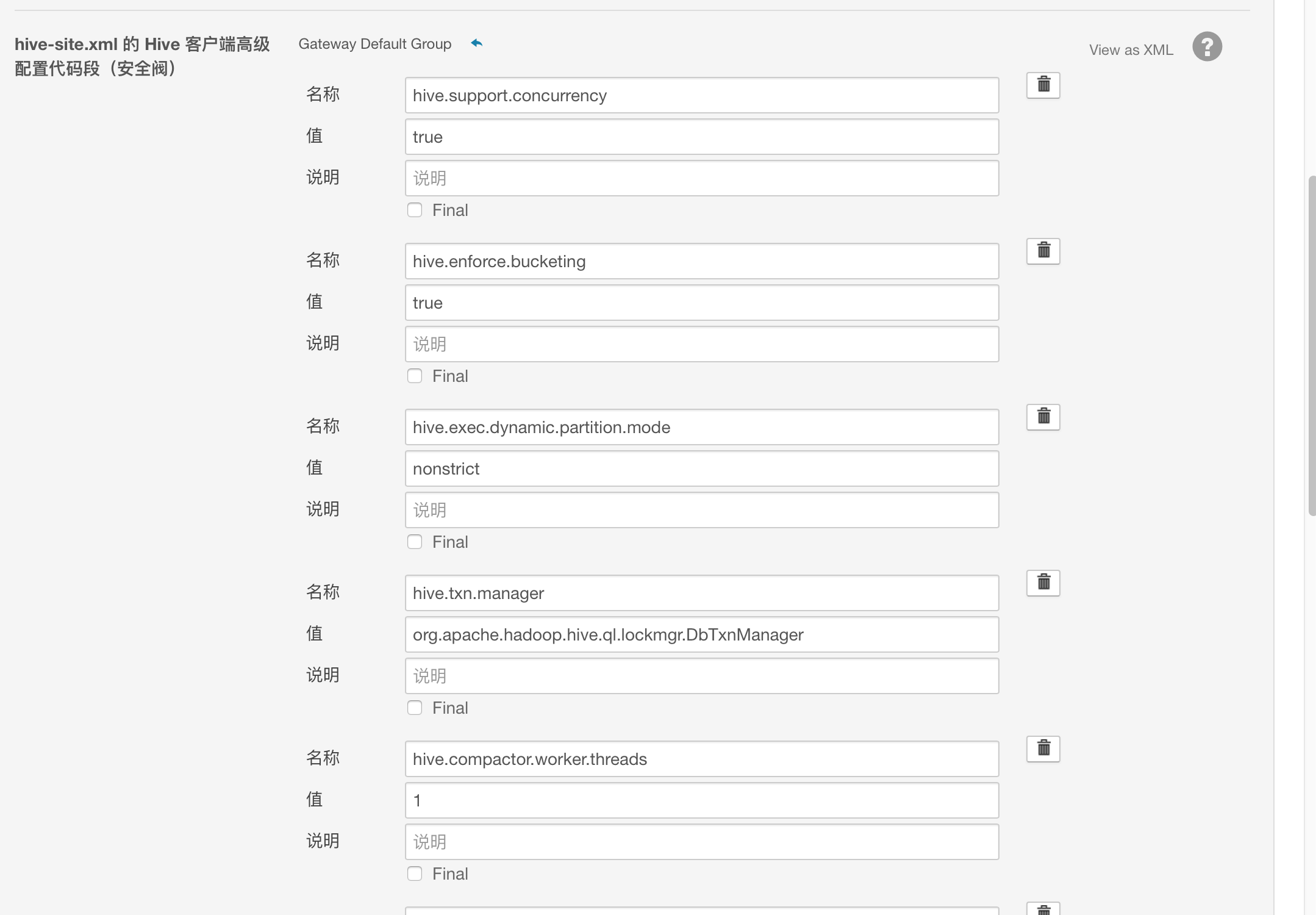
为了让beeline支持还需要配置:
4.2.2 Hive事务测试
环境准备
1、创建一个支持ACID的表
建表语句:
create table test_trancaction (user_id Int,name String) clustered by (user_id) into 3 buckets stored as orc TBLPROPERTIES ('transactional'='true');
|
将表名修改为test_transaction
alter table test_trancaction rename to test_transaction;
|
2、准备测试数据,向数据库中插入数据
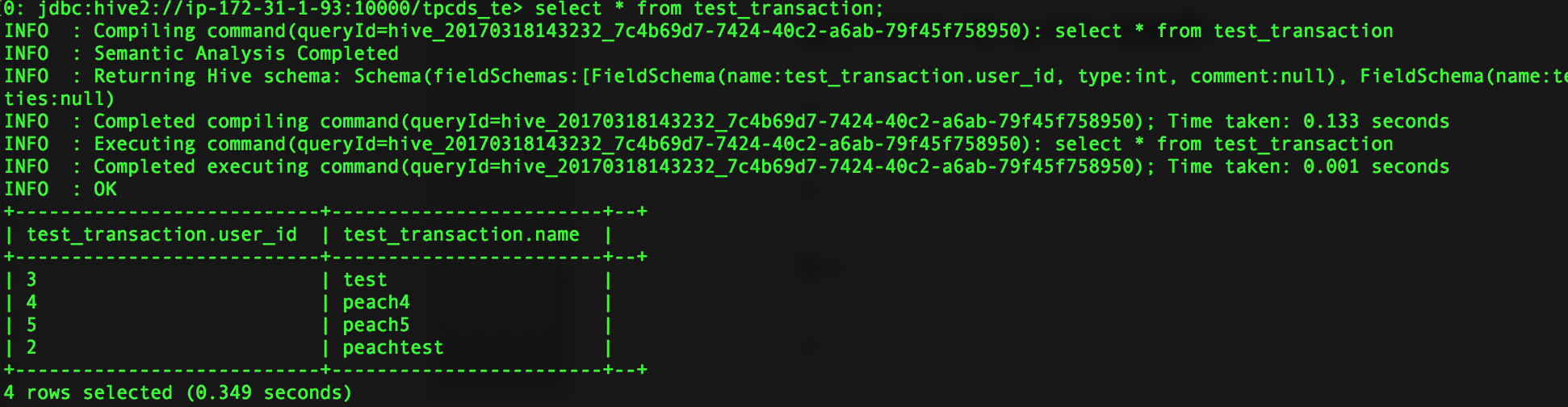
insert into test_transaction values(1,'peach'),(2,'peach2'),(3,'peach3'),(4,'peach4'),(5,'peach5');
|
用例测试
1.执行update操作,将user_id的name修改为peach_update
sql语句:
update test_transaction set name='peach_update' where user_id=1;
|
执行修改操作,查看表获取锁类型

数据修改成功,且不影响其它数据。

2.同时修改同一条数据,将user_id为1的用户名字修改为peach,另一条sql将名字修改为peach_
sql语句:
update test_transaction set name='peach' where user_id=1;update test_transaction set name='peach_' where user_id=1;
|
sql执行顺序为peach,其次为peach_
此时查看表获取到的锁

通过获取到锁分析,在同时修改同一条数据时,优先执行的sql获取到了SHARED_WRITE,而后执行的sql获取锁的状态为WAITING状态,表示还未获取到SHARED_WRITE锁,等待第一条sql执行结束后方可获取到锁对数据进行操作。
通过上不执行操作分析,数据user_id为1的用户名字应被修改为peach_

3.同时修改不同数据,修改id为2的name为peachtest,修改id为3的name为peach_test
sql语句:
update test_transaction set name='peachtest' where user_id=2; update test_transaction set name='peach_test' where user_id=3;
|
sql执行顺序为peachtest,其次为peach_test
此时查看表获取到的锁
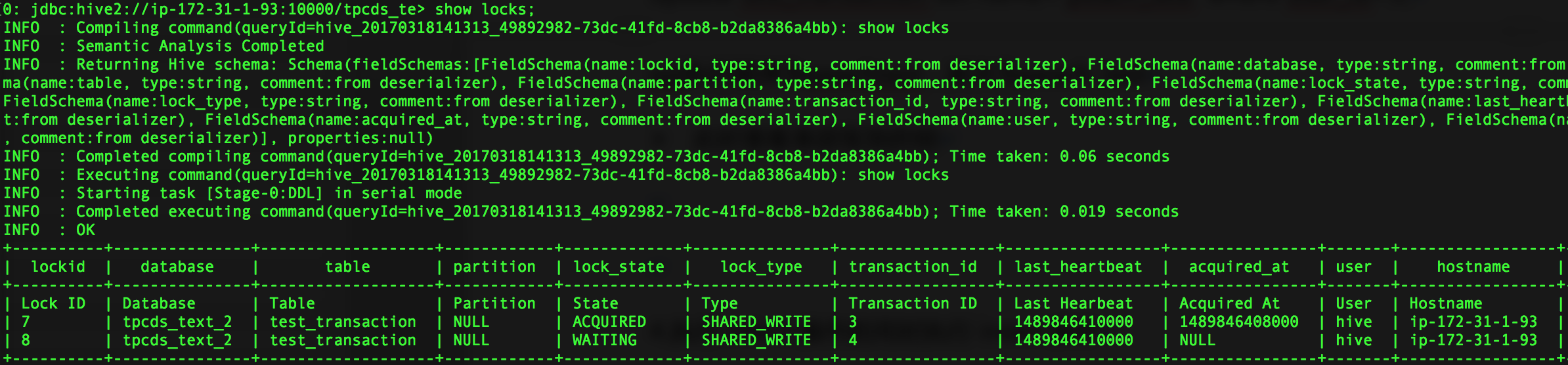
通过sql操作获取锁分析,在同时修改不同数据时,优先执行的sql获取到了SHARED_WRITE,而后执行的sql获取锁的状态为WAITING状态,表示还未获取到SHARED_WRITE锁,等待第一条sql执行结束后方可获取到锁对数据进行操作。
4.执行select操作的同时执行insert操作
sql语句:
select count(*) from test_transaction; insert into test_transaction values(3,'peach3');
|
步骤:
先执行select操作,再执行insert操作,执行完成后查看表获取到的锁

由于select和insert操作均获取的是SHARED_READ锁,读锁为并行,所以select查询和insert同时执行,互不影响。
5.update同一条数据的同时select该条数据
sql语句:
update test_transaction set name='peach_update' where user_id=1; select * from test_transaction where user_id=1;
|
步骤:
先执行update操作,再执行select操作,获取此时表获取到的锁

通过获取锁的情况分析, 在update操作时,获取到SHARED_WRITE锁,执行select操作时获取到SHARED_READ锁,在进行修改数据时未阻塞select查询操作,update未执行完成时,select查询到的数据为未修改的数据。
6.执行delete操作,将user_id为3的数据删除
sql语句:
delete from test_transaction where user_id=3;
|
步骤:
执行delete操作,获取此时表获取到的锁

删除操作获取到的是SHARED_WRITE锁
执行成功后数据

7.同时delete同一条数据
sql语句:
delete from test_transaction where user_id=3;delete from test_transaction where user_id=3;
|
步骤:
按顺序执行两条delete操作,查看此时表获取到的锁:

通过查看delete操作获取到的锁,优先执行的操作获取到SHARED_WRITE锁,后执行的delete操作未获取到SHARED_WRITE锁,处于WAITING状态。
执行删除后结果

8.同时delete两条不同的数据
sql语句:
delete from test_transaction where user_id=1; delete from test_transaction where user_id=5;
|
步骤:
按顺序执行两条delete操作,查看此时表获取到的锁:

通过查看delete操作获取到的锁,优先执行的操作获取到SHARED_WRITE锁,后执行的delete操作未获取到SHARED_WRITE锁,处于WAITING状态。
执行删除后结果

9.执行delete的同时对删除的数据进行update操作
sql语句:
delete from test_transaction where user_id=3; update test_transaction set name='test' where user_id=3;
|
步骤:
按顺序执行两条sql,查看此时获取到表的锁:
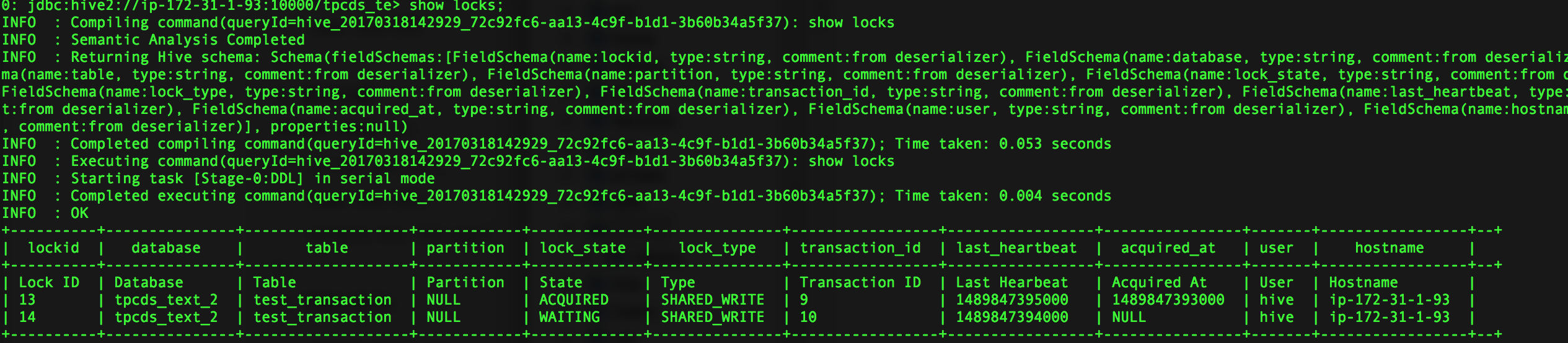
通过查看delete和update操作获取到的锁,优先执行的操作获取到SHARED_WRITE锁,后执行的操
作未获取到SHARED_WRITE锁,处于WAITING状态。
执行delete和update后结果
注意:此处在delete优先于update执行,但执行结果为update的结果,执行异常。
10.执行delete的同时对不同的数据进行update操作
sql语句:
delete from test_transaction where user_id=2; update test_transaction set name='test' where user_id=4;
|
步骤:
按顺序执行上面两条sql,查看表锁获取情况
通过查看delete和update操作获取到的锁,优先执行的操作获取到SHARED_WRITE锁,后执行的操作未获取到SHARED_WRITE锁,处于WAITING状态。
执行delete和update后结果,执行结果正常

11.执行delete的同时执行select操作
sql语句:
delete from test_transaction where user_id=4; select count(*) from test_transaction;
|
步骤:
按顺序执行上面两条sql,查看表锁获取情况

在操作delete的同时执行select操作,两个操作均同时获取到SHARED_RED和SHARED_WRITE锁,操作并行进行未出现阻塞。
5 总结对比
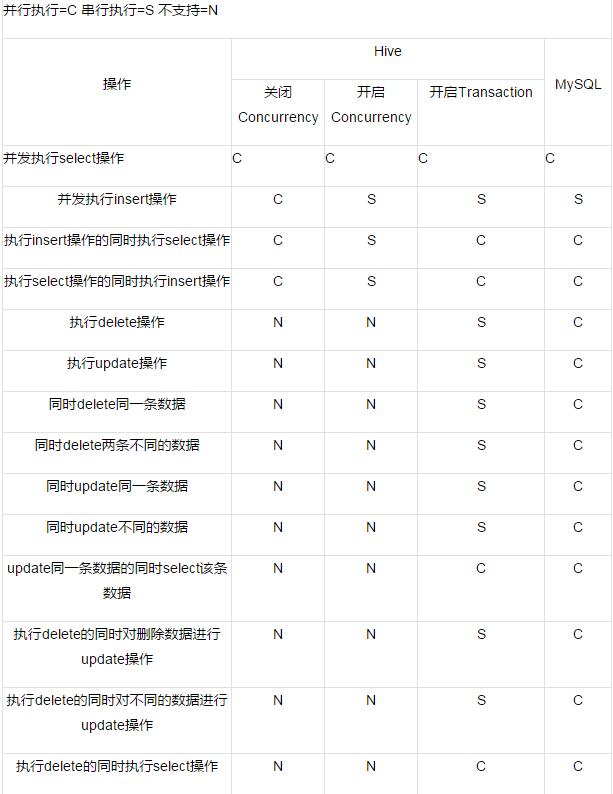
6 Hive事务使用建议
1.传统数据库中有三种模型隐式事务、显示事务和自动事务。在目前Hive对事务仅支持自动事务,因此Hive无法通过显示事务的方式对一个操作序列进行事务控制。
2.传统数据库事务在遇到异常情况可自动进行回滚,目前Hive无法支持ROLLBACK。
3.传统数据库中支持事务并发,而Hive对事务无法做到完全并发控制,多个操作均需要获取WRITE的时候则这些操作为串行模式执行(在测试用例中"delete同一条数据的同时update该数据",操作是串行的且操作完成后数据未被删除且数据被修改)未保证数据一致性。
4.Hive的事务功能尚属于实验室功能,并不建议用户直接上生产系统,因为目前它还有诸多的限制,如只支持ORC文件格式,建表必须分桶等,使用起来没有那么方便,另外该功能的稳定性还有待进一步验证。
5.CDH默认开启了Hive的Concurrency功能,主要是对并发读写的的时候通过锁进行了控制。所以为了防止用户在使用Hive的时候,报错提示该表已经被lock,对于用户来说不友好,建议在业务侧控制一下写入和读取,比如写入同一个table或者partition的时候保证是单任务写入,其他写入需控制写完第一个任务了,后面才继续写,并且控制在写的时候不让用户进行查询。另外需要控制在查询的时候不要允许有写入操作。
6.如果对于数据一致性不在乎,可以完全关闭Hive的Concurrency功能关闭,即设置hive.support.concurrency为false,这样Hive的并发读写将没有任何限制。
|






