| 分类模型的场景: 1.预测互联网用户对在线广告的点击概率(二分类问题);2.检测欺诈(二分类问题,欺诈或者不欺诈);3.预测拖欠贷款(二分类问题);4.对图片、音频、视频进行分类(多分类问题);5.对新闻、网页或者其他内容进行分类或者打标签(多分类);6.发现垃圾邮件、垃圾页面、网络入侵和其他恶意行为
;7.检测故障,比如计算机系统或者网络故障检测;8.预测顾客或者客户中谁有可能停止使用某个产品或服务。
分类模型的种类:
1.线性模型
原理:对样本的预测结果(目标变量)进行建模,即对输入特征应用简单的线性预测函数。
1.1 逻辑回归
1.2 线性支持向量机
2.朴素贝叶斯模型(前提:假设各个特征之间条件独立)
3.决策树模型
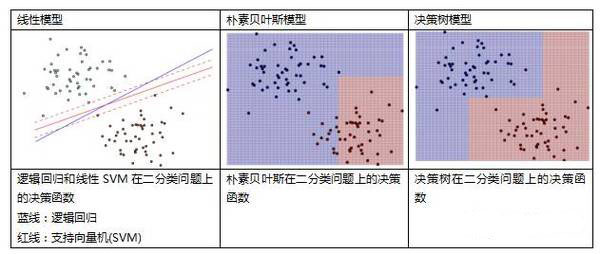
三种分类模型的决策函数:
MLlib构建分类模型如何使用?
1.从数据集中抽取合适的特征
MLlib中的分类模型通过LabelPoint对象操作,其中了目标变量(Label)与特征向量:
case class LabePoint(label : Double, features : Vector)
待训练数据:
val data = records.map{ r => ... LabelPoint(lable,
Vectors.dense(features)) }
2.训练分类模型
2.1 训练线性回归模型:
2.2 训练SVM模型
2.3 训练NaiveBays模型
2.4 训练决策树模型
3.使用分类模型预测
val prediction = xxModel.predict(dataPoint.features)
注意:逻辑回归、SVM、NaiveBays在二分类中的预测值为1 或 0,但决策树的预测值为0到1之间的实数,使用时需要使用阈值判断。

评估分类模型的性能
通常在二分类中使用的评估方法包括:预测正确率与错误率、准确率与召回率、准确率-召回率下方的面积、ROC曲线、ROC曲
线下的面积和F-Measure。
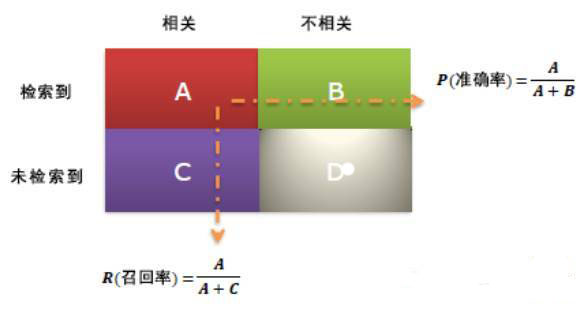
?错误率:训练样本中被错误分类的数目除以样本总数? 准确率(Precision)
= 系统检索到的相关文件 / 系统所有检索到的文件总数(搜索引擎)? 召回率(Recall) = 系统检索到的相关文件
/ 系统所有相关的文件总数(搜索引擎)
通常,准确率和召回率地负相关,高准确率常常对应低召回率,反之亦然。如果两者都低,说明模型出了问题。
不同场景下准确率和召回率的要求不同,如果是做搜索,那就是保证召回的情况下提升准确率(宁可错判,不能漏判);如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回(宁可漏判,不能错判)。
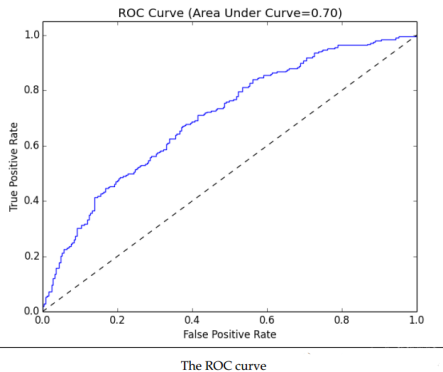
ROC(Receiver Operating Characteristic)曲线:
真阳性率:真阳性的样本数 / (真阳性 + 假阴性样本数之和)假阳性率:假阳性的样本数
/ (假阳性 + 真阴性样本数之和)AUC:ROC下的面积(AUC为1.0时表示一个完美的分类器,0.5表示一个随机的性能)
说明:
用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC
curve下方的那部分面积的大小。
通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。
P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用前者,分类、识别等用后者。
AP是为解决P,R,F-measure的单点值局限性的。为了得到 一个能够反映全局性能的指标,可以看考察下图。
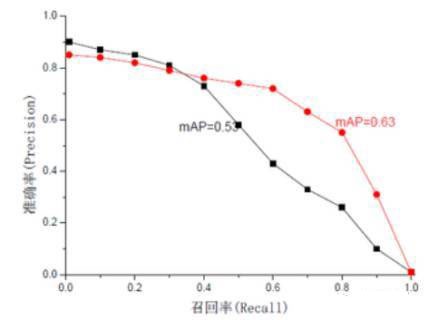
可以看出,虽然两个系统的性能曲线有所交叠但是以圆点标示的系统的性能在绝大多数情况下要远好于用方块标示的系统。从中我们可以
发现一点,如果一个系统的性能较好,其曲线应当尽可能的向上突出。
更加具体的,曲线与坐标轴之间的面积应当越大。最理想的系统, 其包含的面积应当是1。
如何提升模型的性能?
1.特征标准化
原始数据标准化后特征满足正态分布,即每个特征是0均值和单位标准差,方法:
标准化工具:
Spark的StandardScaler方法,

2.对类别特征使用 1-of-k编码
例如:某个特征有10个类别,则需创建一个长为10的向量,然后根据样本所属类别索引,将对应的维度赋值1,其他为0。
3.模型参数调优
根据不同模型训练时使用的不同参数,利用上一页模型性能评价指标,训练出最佳的模型。
4.交叉验证
原理:测试模型在未知数据上的性能
方式:将数据随机的分为训练集和测试集,常用分法50/50、60/40、80/20。
|






