| SparkМђНщ
SparkЪЧећИіBDASЕФКЫаФзщМўЃЌЪЧвЛИіДѓЪ§ОнЗжВМЪНБрГЬПђМмЃЌВЛНіЪЕЯжСЫMapReduceЕФЫузгmap
КЏЪ§КЭreduceКЏЪ§МАМЦЫуФЃаЭЃЌЛЙЬсЙЉИќЮЊЗсИЛЕФЫузгЃЌШчfilterЁЂjoinЁЂgroupByKeyЕШЁЃЪЧвЛИігУРДЪЕЯжПьЫйЖјЭЌгУЕФМЏШКМЦЫуЕФЦНЬЈЁЃ
SparkНЋЗжВМЪНЪ§ОнГщЯѓЮЊЕЏадЗжВМЪНЪ§ОнМЏЃЈRDDЃЉЃЌЪЕЯжСЫгІгУШЮЮёЕїЖШЁЂRPCЁЂађСаЛЏКЭбЙЫѕЃЌВЂЮЊдЫаадкЦфЩЯЕФЩЯВузщМўЬсЙЉAPIЁЃЦфЕзВуВЩгУScalaетжжКЏЪ§ЪНгябдЪщаДЖјГЩЃЌВЂЧвЫљЬсЙЉЕФAPIЩюЖШНшМјScalaКЏЪ§ЪНЕФБрГЬЫМЯыЃЌЬсЙЉгыScalaРрЫЦЕФБрГЬНгПк
Sparkon Yarn
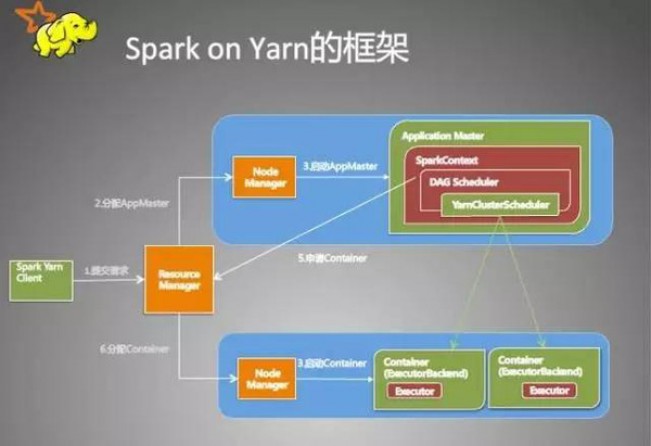
ДггУЛЇЬсНЛзївЕЕНзївЕдЫааНсЪјећИідЫааЦкМфЕФЙ§ГЬЗжЮіЁЃ
вЛЁЂПЭЛЇЖЫНјааВйзї
1.ИљОнyarnConfРДГѕЪМЛЏyarnClientЃЌВЂЦєЖЏyarnClient
2.ДДНЈПЭЛЇЖЫApplicationЃЌВЂЛёШЁApplicationЕФIDЃЌНјвЛВНХаЖЯМЏШКжаЕФзЪдДЪЧЗёТњзуexecutorКЭApplicationMasterЩъЧыЕФзЪдДЃЌШчЙћВЛТњзудђХзГіIllegalArgumentExceptionЃЛ
3. ЩшжУзЪдДЁЂЛЗОГБфСПЃКЦфжаАќРЈСЫЩшжУApplicationЕФStagingФПТМЁЂзМБИБОЕизЪдДЃЈjarЮФМўЁЂlog4j.propertiesЃЉЁЂЩшжУApplicationЦфжаЕФЛЗОГБфСПЁЂДДНЈContainerЦєЖЏЕФContextЕШЃЛ
4. ЩшжУApplicationЬсНЛЕФContextЃЌАќРЈЩшжУгІгУЕФУћзжЁЂЖгСаЁЂAMЕФЩъЧыЕФContainerЁЂБъМЧИУзївЕЕФРраЭЮЊSparkЃЛ
5. ЩъЧыMemoryЃЌВЂзюжеЭЈЙ§yarnClient.submitApplicationЯђResourceManagerЬсНЛИУApplicationЁЃ
ЕБзївЕЬсНЛЕНYARNЩЯжЎКѓЃЌПЭЛЇЖЫОЭУЛЪТСЫЃЌЩѕжСдкжеЖЫЙиЕєФЧИіНјГЬвВУЛЪТЃЌвђЮЊећИізївЕдЫаадкYARNМЏШКЩЯНјааЃЌдЫааЕФНсЙћНЋЛсБЃДцЕНHDFSЛђепШежОжаЁЃ
ЖўЁЂЬсНЛЕНYARNМЏШКЃЌYARNВйзї
1.дЫааApplicationMasterЕФrunЗНЗЈЃЛ
2.ЩшжУКУЯрЙиЕФЛЗОГБфСПЁЃ
3.ДДНЈamClientЃЌВЂЦєЖЏЃЛ
4.дкSpark UIЦєЖЏжЎЧАЩшжУSpark UIЕФAmIpFilterЃЛ
5.дкstartUserClassКЏЪ§зЈУХЦєЖЏСЫвЛИіЯпГЬЃЈУћГЦЮЊDriverЕФЯпГЬЃЉРДЦєЖЏгУЛЇЬсНЛЕФApplicationЃЌвВОЭЪЧЦєЖЏСЫDriverЁЃдкDriverжаНЋЛсГѕЪМЛЏSparkContextЃЛ
6.ЕШД§SparkContextГѕЪМЛЏЭъГЩЃЌзюЖрЕШД§spark.yarn.applicationMaster.waitTriesДЮЪ§ЃЈФЌШЯЮЊ10ЃЉЃЌШчЙћЕШД§СЫЕФДЮЪ§ГЌЙ§СЫХфжУЕФЃЌГЬађНЋЛсЭЫГіЃЛЗёдђгУSparkContextГѕЪМЛЏyarnAllocatorЃЛ
7.ЕБSparkContextЁЂDriverГѕЪМЛЏЭъГЩЕФЪБКђЃЌЭЈЙ§amClientЯђResourceManagerзЂВсApplicationMaster
8.ЗжХфВЂЦєЖЏExecuteorsЁЃдкЦєЖЏExecuteorsжЎЧАЃЌЯШвЊЭЈЙ§yarnAllocatorЛёШЁЕНnumExecutorsИіContainerЃЌШЛКѓдкContainerжаЦєЖЏExecuteorsЁЃ
ФЧУДетИіApplicationНЋЪЇАмЃЌНЋApplication StatusБъУїЮЊFAILEDЃЌВЂНЋЙиБеSparkContextЁЃЦфЪЕЃЌЦєЖЏExecuteorsЪЧЭЈЙ§ExecutorRunnableЪЕЯжЕФЃЌЖјExecutorRunnableФкВПЪЧЦєЖЏCoarseGrainedExecutorBackendЕФЁЃ
9.зюКѓЃЌTaskНЋдкCoarseGrainedExecutorBackendРяУцдЫааЃЌШЛКѓдЫаазДПіЛсЭЈЙ§AkkaЭЈжЊCoarseGrainedSchedulerЃЌжБЕНзївЕдЫааЭъГЩЁЃ
SparkНкЕуЕФИХФю
вЛЁЂSparkЧ§ЖЏЦїЪЧжДааГЬађжаЕФmain()ЗНЗЈЕФНјГЬЁЃЫќжДаагУЛЇБраДЕФгУРДДДНЈSparkContext(ГѕЪМЛЏ)ЁЂДДНЈRDDЃЌвдМАдЫааRDDЕФзЊЛЏВйзїКЭааЖЏВйзїЕФДњТыЁЃ
Ч§ЖЏЦїНкЕуdriverЕФжАд№ЃК
1.АбгУЛЇГЬађзЊЮЊШЮЮёtask(driver)
SparkЧ§ЖЏЦїГЬађИКд№АбгУЛЇГЬађзЊЛЏЮЊЖрИіЮяРэжДааЕЅдЊЃЌетаЉЕЅдЊвВБЛГЦжЎЮЊШЮЮёtask(ЯъНтМћБИзЂ)
2.ЮЊжДааЦїНкЕуЕїЖШШЮЮё(executor)
гаСЫЮяРэМЦЛЎжЎКѓЃЌSparkЧ§ЖЏЦїдкИїИіжДааЦїНкЕуНјГЬМфаЕїШЮЮёЕФЕїЖШЁЃSparkЧ§ЖЏЦїГЬађЛсИљОнЕБЧАЕФжДааЦїНкЕуЃЌАбЫљгаШЮЮёЛљгкЪ§ОнЫљдкЮЛжУЗжХфИјКЯЪЪЕФжДааЦїНјГЬЁЃЕБжДааШЮЮёЪБЃЌжДааЦїНјГЬЛсАбЛКДцЕФЪ§ОнДцДЂЦ№РДЃЌЖјЧ§ЖЏЦїНјГЬЭЌбљЛсИњзйетаЉЛКДцЪ§ОнЕФЮЛжУЃЌВЂРћгУетаЉЮЛжУаХЯЂРДЕїЖШвдКѓЕФШЮЮёЃЌвдОЁСПМѕЩйЪ§ОнЕФЭјТчДЋЪфЁЃЃЈОЭЪЧЫљЮНЕФвЦЖЏМЦЫуЃЌЖјВЛвЦЖЏЪ§Он)ЁЃ
ЖўЁЂжДааЦїНкЕу
зїгУЃК
1. ИКд№дЫаазщГЩSparkгІгУЕФШЮЮёЃЌВЂНЋНсЙћЗЕЛиИјЧ§ЖЏЦїНјГЬЃЛ
2. ЭЈЙ§здЩэЕФПщЙмРэЦї(blockManager)ЮЊгУЛЇГЬађжавЊЧѓЛКДцЕФRDDЬсЙЉФкДцЪНДцДЂЁЃRDDЪЧжБНгЛКДцдкжДааЦїНјГЬФкЕФЃЌвђДЫШЮЮёПЩвддкдЫааЪБГфЗжРћгУЛКДцЪ§ОнМгПьдЫЫуЁЃ
Ч§ЖЏЦїЕФжАд№ЃК
ЫљгаЕФSparkГЬађЖМзёбЭЌбљЕФНсЙЙЃКГЬађДгЪфШыЪ§ОнДДНЈвЛЯЕСаRDDЃЌдйЪЙгУзЊЛЏВйзїХЩЩњГЩаТЕФRDDЃЌзюКѓЪЙгУааЖЏВйзїЪжЛњЛђДцДЂНсЙћRDDЃЌSparkГЬађЦфЪЕЪЧвўЪНЕиДДНЈГіСЫвЛИігЩВйзїзщГЩЕФТпМЩЯЕФгаЯђЮоЛЗЭМDAGЁЃЕБЧ§ЖЏЦїГЬађжДааЪБЃЌЫќЛсАбетИіТпМЭМзЊЮЊЮяРэжДааМЦЛЎЁЃ
етбљ SparkОЭАбТпММЦЛЎзЊЮЊвЛЯЕСаВНжш(stage)ЃЌЖјУПИіВНжшгжгЩЖрИіШЮЮёзщГЩЁЃетаЉШЮЮёЛсБЛДђАќЫЭЕНМЏШКжаЁЃ
SparkГѕЪМЛЏ
1.УПИіSparkгІгУЖМгЩвЛИіЧ§ЖЏЦїГЬађРДЗЂЦ№МЏШКЩЯЕФИїжжВЂааВйзїЁЃЧ§ЖЏЦїГЬађАќКЌгІгУЕФmainКЏЪ§ЃЌВЂЧвЖЈвхСЫМЏШКЩЯЕФЗжВМЪНЪ§ОнМЏЃЌвдМАЖдИУЗжВМЪНЪ§ОнМЏгІгУСЫЯрЙиВйзїЁЃ
2. Ч§ЖЏЦїГЬађЭЈЙ§вЛИіSparkContextЖдЯѓРДЗУЮЪspark,етИіЖдЯѓДњБэЖдМЦЫуМЏШКЕФвЛИіСЌНгЁЃЃЈБШШчдкsparkshellЦєЖЏЪБвбОздЖЏДДНЈСЫвЛИіSparkContextЖдЯѓЃЌЪЧвЛИіНазіSCЕФБфСПЁЃ(ЯТЭМЃЌВщПДБфСПsc)

3.вЛЕЉДДНЈСЫsparkContextЃЌОЭПЩвдгУЫќРДДДНЈRDDЁЃБШШчЕїгУsc.textFile()РДДДНЈвЛИіДњБэЮФБОжаИїааЮФБОЕФRDDЁЃЃЈБШШчvallinesRDD
= sc.textFile(ЁАyangsy.textЁБ),val spark = linesRDD.filter
(line=>line.contains (ЁАsparkЁБ),spark.count()ЃЉ
жДааетаЉВйзїЃЌЧ§ЖЏЦїГЬађвЛАувЊЙмРэЖрИіжДааЦї,ОЭЪЧЮвУЧЫљЫЕЕФexecutorНкЕуЁЃ
4. дкГѕЪМЛЏSparkContextЕФЭЌЪБЃЌМгдиsparkConfЖдЯѓРДМгдиМЏШКЕФХфжУЃЌДгЖјДДНЈsparkContextЖдЯѓЁЃ
ДгдДТыжаПЩвдПДЕНЃЌдкЦєЖЏthriftserverЪБЃЌЕїгУСЫspark-
daemon.shЮФМўЃЌИУЮФМўдДТыШчзѓЭМЃЌМгдиspark_homeЯТЕФconfжаЕФЮФМўЁЃ
ЃЈдкжДааКѓЬЈДњТыЪБЃЌашвЊЪзЯШДДНЈconfЖдЯѓЃЌМгдиЯргІВЮЪ§ЃЌ val
sparkConf = newSparkConf().setMaster("local") .setAppName("cocapp") .set("spark.executor.memory", "1g"),
val sc: SparkContext = new SparkContext(sparkConf))
RDDЙЄзїдРэЃК
RDD(Resilient DistributedDatasets)[1]
,ЕЏадЗжВМЪНЪ§ОнМЏЃЌЪЧЗжВМЪНФкДцЕФвЛИіГщЯѓИХФюЃЌRDDЬсЙЉСЫвЛжжИпЖШЪмЯоЕФЙВЯэФкДцФЃаЭЃЌМДRDDЪЧжЛЖСЕФМЧТМЗжЧјЕФМЏКЯЃЌжЛФмЭЈЙ§дкЦфЫћRDDжДааШЗЖЈЕФзЊЛЛВйзїЃЈШчmapЁЂjoinКЭgroup
byЃЉЖјДДНЈЃЌШЛЖјетаЉЯожЦЪЙЕУЪЕЯжШнДэЕФПЊЯњКмЕЭЁЃЖдПЊЗЂепЖјбдЃЌRDDПЩвдПДзїЪЧSparkЕФвЛИіЖдЯѓЃЌЫќБОЩэдЫаагкФкДцжаЃЌШчЖСЮФМўЪЧвЛИіRDDЃЌЖдЮФМўМЦЫуЪЧвЛИіRDDЃЌНсЙћМЏвВЪЧвЛИіRDD
ЃЌВЛЭЌЕФЗжЦЌЁЂЪ§ОнжЎМфЕФвРРЕЁЂkey-valueРраЭЕФmapЪ§ОнЖМПЩвдПДзіRDDЁЃ
жївЊЗжЮЊШ§ВПЗжЃКДДНЈRDDЖдЯѓЃЌDAGЕїЖШЦїДДНЈжДааМЦЛЎЃЌTaskЕїЖШЦїЗжХфШЮЮёВЂЕїЖШWorkerПЊЪМдЫааЁЃ
SparkContext(RDDЯрЙиВйзї)ЁњЭЈЙ§(ЬсНЛзївЕ)Ёњ(БщРњRDDВ№ЗжstageЁњЩњГЩзївЕ)DAGSchedulerЁњЭЈЙ§ЃЈЬсНЛШЮЮёМЏЃЉЁњШЮЮёЕїЖШЙмРэ(TaskScheduler)ЁњЭЈЙ§ЃЈАДеезЪдДЛёШЁШЮЮё)ЁњШЮЮёЕїЖШЙмРэ(TaskSetManager)
TransformationЗЕЛижЕЛЙЪЧвЛИіRDDЁЃЫќЪЙгУСЫСДЪНЕїгУЕФЩшМЦФЃЪНЃЌЖдвЛИіRDDНјааМЦЫуКѓЃЌБфЛЛГЩСэЭтвЛИіRDDЃЌШЛКѓетИіRDDгжПЩвдНјааСэЭтвЛДЮзЊЛЛЁЃетИіЙ§ГЬЪЧЗжВМЪНЕФЁЃ
ActionЗЕЛижЕВЛЪЧвЛИіRDDЁЃЫќвЊУДЪЧвЛИіScalaЕФЦеЭЈМЏКЯЃЌвЊУДЪЧвЛИіжЕЃЌвЊУДЪЧПеЃЌзюжеЛђЗЕЛиЕНDriverГЬађЃЌЛђАбRDDаДШыЕНЮФМўЯЕЭГжа
зЊЛЛ(Transformations)(ШчЃКmap, filter,
groupBy, joinЕШ)ЃЌTransformationsВйзїЪЧLazyЕФЃЌвВОЭЪЧЫЕДгвЛИіRDDзЊЛЛЩњГЩСэвЛИіRDDЕФВйзїВЛЪЧТэЩЯжДааЃЌSparkдкгіЕНTransformationsВйзїЪБжЛЛсМЧТМашвЊетбљЕФВйзїЃЌВЂВЛЛсШЅжДааЃЌашвЊЕШЕНгаActionsВйзїЕФЪБКђВХЛсеце§ЦєЖЏМЦЫуЙ§ГЬНјааМЦЫуЁЃ
Вйзї(Actions)(ШчЃКcount, collect, saveЕШ)ЃЌActionsВйзїЛсЗЕЛиНсЙћЛђАбRDDЪ§ОнаДЕНДцДЂЯЕЭГжаЁЃActionsЪЧДЅЗЂSparkЦєЖЏМЦЫуЕФЖЏвђЁЃ
ЫќУЧБОжЪЧјБ№ЪЧЃКTransformationЗЕЛижЕЛЙЪЧвЛИіRDDЁЃЫќЪЙгУСЫСДЪНЕїгУЕФЩшМЦФЃЪНЃЌЖдвЛИіRDDНјааМЦЫуКѓЃЌБфЛЛГЩСэЭтвЛИіRDDЃЌШЛКѓетИіRDDгжПЩвдНјааСэЭтвЛДЮзЊЛЛЁЃетИіЙ§ГЬЪЧЗжВМЪНЕФЁЃActionЗЕЛижЕВЛЪЧвЛИіRDDЁЃЫќвЊУДЪЧвЛИіScalaЕФЦеЭЈМЏКЯЃЌвЊУДЪЧвЛИіжЕЃЌвЊУДЪЧПеЃЌзюжеЛђЗЕЛиЕНDriverГЬађЃЌЛђАбRDDаДШыЕНЮФМўЯЕЭГжаЁЃЙигкетСНИіЖЏзїЃЌдкSparkПЊЗЂжИФЯжаЛсгаОЭНјвЛВНЕФЯъЯИНщЩмЃЌЫќУЧЪЧЛљгкSparkПЊЗЂЕФКЫаФЁЃ
RDDЛљДЁ
1.SparkжаЕФRDDОЭЪЧвЛИіВЛПЩБфЕФЗжВМЪНЖдЯѓМЏКЯЁЃУПИіRDDЖМБЛЗжЮЊЖрИіЗжЧјЃЌетаЉЗжЧјдЫаадкМЏШКЕФВЛЭЌНкЕуЩЯЁЃДДНЈRDDЕФЗНЗЈгаСНжжЃКвЛжжЪЧЖСШЁвЛИіЭтВПЪ§ОнМЏЃЛвЛжжЪЧдкШКЖЋГЬађРяЗжЗЂЧ§ЖЏЦїГЬађжаЕФЖдЯѓМЏКЯЃЌВЛШчИеВХЕФЪОР§ЃЌЖСШЁЮФБОЮФМўзїЮЊвЛИізжЗћДЎЕФRDDЕФЪОР§ЁЃ
2.ДДНЈГіРДКѓЃЌRDDжЇГжСНжжРраЭЕФВйзї:зЊЛЏВйзїКЭааЖЏВйзї
зЊЛЏВйзїЛсгЩвЛИіRDDЩњГЩвЛИіаТЕФRDDЁЃЃЈБШШчИеВХЕФИљОнЮНДЪЩИбЁЃЉ
ааЖЏВйзїЛсЖдRDDМЦЫуГівЛИіНсЙћЃЌВЂАбНсЙћЗЕЛиЕНЧ§ЖЏЦїГЬађжаЃЌЛђАбНсЙћДцДЂЕНЭтВПДцДЂЯЕЭГЃЈБШШчHDFSЃЉжаЁЃБШШчfirst()ВйзїОЭЪЧвЛИіааЖЏВйзїЃЌЛсЗЕЛиRDDЕФЕквЛИідЊЫиЁЃ
зЂЃКзЊЛЏВйзїгыааЖЏВйзїЕФЧјБ№дкгкSparkМЦЫуRDDЕФЗНЪНВЛЭЌЁЃЫфШЛФуПЩвддкШЮКЮЪБКђЖЈвхвЛИіаТЕФRDDЃЌЕЋSparkжЛЛсЖшадМЦЫуетаЉRDDЁЃЫќУЧжЛгаЕквЛИідквЛИіааЖЏВйзїжагУЕНЪБЃЌВХЛсеце§ЕФМЦЫуЁЃжЎЫљвдетбљЩшМЦЃЌЪЧвђЮЊБШШчИеВХЕїгУsc.textFile(...)ЪБОЭАбЮФМўжаЕФЫљгаааЖМЖСШЁВЂДцДЂЦ№РДЃЌОЭЛсЯћКФКмЖрДцДЂПеМфЃЌЖјЮвУЧТэЩЯгжвЊЩИбЁЕєЦфжаЕФКмЖрЪ§ОнЁЃ
етРяЛЙашвЊзЂвтЕФвЛЕуЪЧЃЌsparkЛсдкФуУПДЮЖдЫќУЧНјааааЖЏВйзїЪБжиаТМЦЫуЁЃШчЙћЯыдкЖрИіааЖЏВйзїжажигУЭЌвЛИіRDDЃЌФЧУДПЩвдЪЙгУRDD.persist()ЛђRDD.collect()ШУSparkАбетИіRDDЛКДцЯТРДЁЃЃЈПЩвдЪЧФкДцЃЌвВПЩвдЪЧДХХЬ)
3.SparkЛсЪЙгУЦзЯЕЭМРДМЧТМетаЉВЛЭЌRDDжЎМфЕФвРРЕЙиЯЕЃЌSparkашвЊгУетаЉаХЯЂРДАДашМЦЫуУПИіRDDЃЌвВПЩвдвРППЦзЯЕЭМдкГжОУЛЏЕФRDDЖЊЪЇВПЗжЪ§ОнЪБгУРДЛжИДЫљЖЊЪЇЕФЪ§ОнЁЃ(ШчЯТЭМЃЌЙ§ТЫerrorsRDDгыwarningsRDD,зюжеЕїгУunion()КЏЪ§)
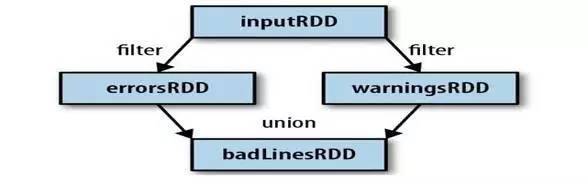
RDDМЦЫуЗНЪН
RDDЕФПэевРРЕ
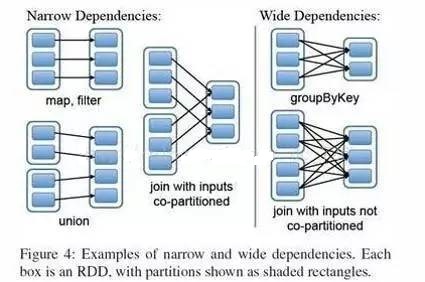
евРРЕ (narrowdependencies) КЭПэвРРЕ (widedependencies)
ЁЃевРРЕЪЧжИ ИИ RDD ЕФУПИіЗжЧјЖМжЛБЛзг RDD ЕФвЛИіЗжЧјЫљЪЙгУ ЁЃЯргІЕФЃЌФЧУДПэвРРЕОЭЪЧжИИИ
RDD ЕФЗжЧјБЛЖрИізг RDD ЕФЗжЧјЫљвРРЕЁЃР§ШчЃЌ map ОЭЪЧвЛжжевРРЕЃЌЖј join дђЛсЕМжТПэвРРЕ
етжжЛЎЗжгаСНИігУДІЁЃЪзЯШЃЌевРРЕжЇГждквЛИіНсЕуЩЯЙмЕРЛЏжДааЁЃР§ШчЛљгквЛЖдвЛЕФЙиЯЕЃЌПЩвддк
filter жЎКѓжДаа map ЁЃЦфДЮЃЌевРРЕжЇГжИќИпаЇЕФЙЪеЯЛЙдЁЃвђЮЊЖдгкевРРЕЃЌжЛгаЖЊЪЇЕФИИ RDD
ЕФЗжЧјашвЊжиаТМЦЫуЁЃЖјЖдгкПэвРРЕЃЌвЛИіНсЕуЕФЙЪеЯПЩФмЕМжТРДздЫљгаИИ RDD ЕФЗжЧјЖЊЪЇЃЌвђДЫОЭашвЊЭъШЋжиаТжДааЁЃвђДЫЖдгкПэвРРЕЃЌSpark
ЛсдкГжгаИїИіИИЗжЧјЕФНсЕуЩЯЃЌНЋжаМфЪ§ОнГжОУЛЏРДМђЛЏЙЪеЯЛЙдЃЌОЭЯё MapReduce ЛсГжОУЛЏ map
ЕФЪфГівЛбљЁЃ
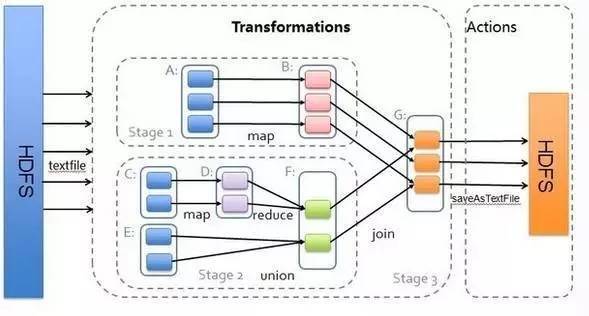
SparkExample

ВНжш 1 ЃКДДНЈ RDD
ЁЃЩЯУцЕФР§згГ§ШЅзюКѓвЛИі collect ЪЧИіЖЏзїЃЌВЛЛсДДНЈ RDD жЎЭтЃЌЧАУцЫФИізЊЛЛЖМЛсДДНЈГіаТЕФ
RDD ЁЃвђДЫЕквЛВНОЭЪЧДДНЈКУЫљга RDD( ФкВПЕФЮхЯюаХЯЂ ) ЁЃ
ВНжш 2 ЃКДДНЈжДааМЦЛЎЁЃSpark
ЛсОЁПЩФмЕиЙмЕРЛЏЃЌВЂЛљгкЪЧЗёвЊжиаТзщжЏЪ§ОнРДЛЎЗж НзЖЮ (stage) ЃЌР§ШчБОР§жаЕФ groupBy()
зЊЛЛОЭЛсНЋећИіжДааМЦЛЎЛЎЗжГЩСННзЖЮжДааЁЃзюжеЛсВњЩњвЛИі DAG(directedacyclic graph
ЃЌгаЯђЮоЛЗЭМ ) зїЮЊТпМжДааМЦЛЎЁЃ
ВНжш 3 ЃКЕїЖШШЮЮёЁЃ
НЋИїНзЖЮЛЎЗжГЩВЛЭЌЕФ ШЮЮё (task) ЃЌУПИіШЮЮёЖМЪЧЪ§ОнКЭМЦЫуЕФКЯЬхЁЃдкНјааЯТвЛНзЖЮЧАЃЌЕБЧАНзЖЮЕФЫљгаШЮЮёЖМвЊжДааЭъГЩЁЃвђЮЊЯТвЛНзЖЮЕФЕквЛИізЊЛЛвЛЖЈЪЧжиаТзщжЏЪ§ОнЕФЃЌЫљвдБиаыЕШЕБЧАНзЖЮЫљгаНсЙћЪ§ОнЖММЦЫуГіРДСЫВХФмМЬајЁЃ
МйЩшБОР§жаЕФ hdfs://names ЯТгаЫФИіЮФМўПщЃЌФЧУД HadoopRDD
жа partitions ОЭЛсгаЫФИіЗжЧјЖдгІетЫФИіПщЪ§ОнЃЌЭЌЪБ preferedLocations
ЛсжИУїетЫФИіПщЕФзюМбЮЛжУЁЃЯждкЃЌОЭПЩвдДДНЈГіЫФИіШЮЮёЃЌВЂЕїЖШЕНКЯЪЪЕФМЏШКНсЕуЩЯЁЃ
SparkЪ§ОнЗжЧј
1.SparkЕФЬиадЪЧЖдЪ§ОнМЏдкНкЕуМфЕФЗжЧјНјааПижЦЁЃдкЗжВМЪНЯЕЭГжаЃЌЭЈбЖЕФДњМлЪЧОоДѓЕФЃЌПижЦЪ§ОнЗжВМвдЛёЕУзюЩйЕФЭјТчДЋЪфПЩвдМЋДѓЕиЬсЩ§ећЬхадФмЁЃSparkГЬађПЩвдЭЈЙ§ПижЦRDDЗжЧјЗНЪНРДМѕЩйЭЈбЖЕФПЊЯњ
2.SparkжаЫљгаЕФМќжЕЖдRDDЖМПЩвдНјааЗжЧјЁЃШЗБЃЭЌвЛзщЕФМќГіЯждкЭЌвЛИіНкЕуЩЯЁЃБШШчЃЌЪЙгУЙўЯЃЗжЧјНЋвЛИіRDDЗжГЩСЫ100ИіЗжЧјЃЌДЫЪБМќЕФЙўЯЃжЕЖд100ШЁФЃЕФНсЙћЯрЭЌЕФМЧТМЛсБЛЗХдквЛИіНкЕуЩЯЁЃ
ЃЈПЩЪЙгУpartitionBy(newHashPartitioner
(100)).persist()РДЙЙдь100ИіЗжЧј)
3.SparkжаЕФаэЖрВйзїЖМв§ШыСЫНЋЪ§ОнИљОнМќПчНчЕуНјааЛьЯДЕФЙ§ГЬЁЃ(БШШчЃКjoin(),leftOuterJoin(),
groupByKey(),reducebyKey()ЕШ)ЖдгкЯёreduceByKey()етбљжЛзїгУгкЕЅИіRDDЕФВйзїЃЌдЫаадкЮДЗжЧјЕФRDDЩЯЕФЪБКђЛсЕМжТУПИіМќЕФЫљгаЖдгІжЕЖМдкУПЬЈЛњЦїЩЯНјааБОЕиМЦЫуЁЃ
SparkSQLЕФshuffleЙ§ГЬ
Spark SQLЕФКЫаФЪЧАбвбгаЕФRDDЃЌДјЩЯSchemaаХЯЂЃЌШЛКѓзЂВсГЩРрЫЦsqlРяЕФЁБTableЁБЃЌЖдЦфНјааsqlВщбЏЁЃетРяУцжївЊЗжСНВПЗжЃЌвЛЪЧЩњГЩSchemaRDЃЌЖўЪЧжДааВщбЏЁЃ
ШчЙћЪЧspark-hiveЯюФПЃЌФЧУДЖСШЁmetadataаХЯЂзїЮЊSchemaЁЂЖСШЁhdfsЩЯЪ§ОнЕФЙ§ГЬНЛИјHiveЭъГЩЃЌШЛКѓИљОнетСЉВПЗжЩњГЩSchemaRDDЃЌдкHiveContextЯТНјааhql()ВщбЏЁЃ
SparkSQLНсЙЙЛЏЪ§Он
1.ЪзЯШЫЕвЛЯТApacheHiveЃЌHiveПЩвддкHDFSФкЛђепдкЦфЫћДцДЂЯЕЭГЩЯДцДЂЖржжИёЪНЕФБэЁЃSparkSQLПЩвдЖСШЁHiveжЇГжЕФШЮКЮБэЁЃвЊАбSpark
SQLСЌНгвбгаЕФhiveЩЯЃЌашвЊЬсЙЉHiveЕФХфжУЮФМўЁЃhive-site.xmlЮФМўИДжЦЕНsparkЕФconfЮФМўМаЯТЁЃдйДДНЈГіHiveContextЖдЯѓ(sparksqlЕФШыПк)ЃЌШЛКѓОЭПЩвдЪЙгУHQLРДЖдБэНјааВщбЏЃЌВЂвдгЩаазужЄЕФRDDЕФаЮЪНФУЕНЗЕЛиЕФЪ§ОнЁЃ
2.ДДНЈHivecontextВЂВщбЏЪ§Он
importorg.apache .spark.sql.hive.HiveContext
valhiveCtx = new org.apache.spark.sql.hive .HiveContext(sc)
valrows = hiveCtx.sql(ЁАSELECT name,age
FROM usersЁБ)
valfitstRow ЈC rows.first()
println (fitstRow.getSgtring(0)) //зжЖЮ0ЪЧnameзжЖЮ
3.ЭЈЙ§jdbcСЌНгЭтВПЪ§ОндДИќаТгыМгди
Class.forName("com.mysql.jdbc.Driver")
val conn =DriverManager.getConnection(mySQLUrl)
val stat1 =conn.createStatement()
stat1.execute ("UPDATE CI_LABEL_INFO
set DATA_STATUS_ID = 2 , DATA_DATE ='" + dataDate
+"' where LABEL_ID in (" +allCreatedLabels.mkString (",") +")")
stat1.close() //МгдиЭтВПЪ§ОндДЪ§ОнЕНФкДц
valDIM_COC_INDEX _MODEL_TABLE_CONF
=sqlContext.jdbc (mySQLUrl,"DIM_COC_INDEX _MODEL_TABLE _CONF").cache()
val
targets =DIM_COC_INDEX_MODEL_TABLE_CONF.filter ("TABLE_DATA_CYCLE
="+ TABLE_DATA_CYCLE).collect
SparkSQLНтЮі
ЪзЯШЫЕЯТДЋЭГЪ§ОнПтЕФНтЮіЃЌДЋЭГЪ§ОнПтЕФНтЮіЙ§ГЬЪЧАДRusultЁЂData
SourceЁЂOperationЕФДЮађРДНтЮіЕФЁЃДЋЭГЪ§ОнПтЯШНЋЖСШыЕФSQLгяОфНјааНтЮіЃЌЗжБцГіSQLгяОфжаФФаЉДЪЪЧЙиМќзжЃЈШчselect,from,where)ЃЌФФаЉЪЧБэДяЪНЃЌФФаЉЪЧProjectionЃЌФФаЉЪЧData
SourceЕШЕШЁЃНјвЛВНХаЖЯSQLгяОфЪЧЗёЙцЗЖЃЌВЛЙцЗЖОЭБЈДэЃЌЙцЗЖдђАДееЯТвЛВНЙ§ГЬАѓЖЈЃЈBind)ЁЃЙ§ГЬАѓЖЈЪЧНЋSQLгяОфКЭЪ§ОнПтЕФЪ§ОнзжЕф(Са,Бэ,ЪгЭМЕШЃЉНјааАѓЖЈЃЌШчЙћЯрЙиЕФProjectionЁЂData
SourceЕШЖМДцдкЃЌОЭБэЪОетИіSQLгяОфЪЧПЩвджДааЕФЁЃдкжДааЙ§ГЬжаЃЌгаЪБКђЩѕжСВЛашвЊЖСШЁЮяРэБэОЭПЩвдЗЕЛиНсЙћЃЌБШШчжиаТдЫааИедЫааЙ§ЕФSQLгяОфЃЌжБНгДгЪ§ОнПтЕФЛКГхГижаЛёШЁЗЕЛиНсЙћЁЃдкЪ§ОнПтНтЮіЕФЙ§ГЬжаSQLгяОфЪБЃЌНЋЛсАбSQLгяОфзЊЛЏГЩвЛИіЪїаЮНсЙЙРДНјааДІРэЃЌЛсаЮГЩвЛИіЛђКЌгаЖрИіНкЕу(TreeNode)ЕФTree,ШЛКѓдйКѓајЕФДІРэеўЖдИУTreeНјаавЛЯЕСаЕФВйзїЁЃ
Spark SQLЖдSQLгяОфЕФДІРэКЭЙиЯЕЪ§ОнПтЖдSQLгяОфЕФНтЮіВЩгУСЫРрЫЦЕФЗНЗЈЃЌЪзЯШЛсНЋSQLгяОфНјааНтЮіЃЌШЛКѓаЮГЩвЛИіTreeЃЌКѓајШчАѓЖЈЁЂгХЛЏЕШДІРэЙ§ГЬЖМЪЧЖдTreeЕФВйзїЃЌЖјВйзїЗНЗЈЪЧВЩгУRule,ЭЈЙ§ФЃЪНЦЅХфЃЌЖдВЛЭЌРраЭЕФНкЕуВЩгУВЛЭЌЕФВйзїЁЃSparkSQLгаСНИіЗжжЇЃЌsqlContextКЭhiveContextЁЃsqlContextЯждкжЛжЇГжSQLгяЗЈНтЮіЦїЃЈCatalyst)ЃЌhiveContextжЇГжSQLгяЗЈКЭHiveContextгяЗЈНтЮіЦїЁЃ
|









