| ���������˼�ʻ����ϵ�еĵ���ƪ�����ؽ�����ǿѧϰ�����˼�ʻ�е�Ӧ�á���ǿѧϰ��Ŀ����ͨ���ͻ���������ѧϰ�������Ӧ�۲��в�ȡ������Ϊ����ȴ�ͳ�Ļ���ѧϰ�������������ƣ����ȣ����ڲ���Ҫ��ע�Ĺ��̣����Ը���Ч�ؽ�������д��ڵ������������Σ���������ϵͳ��Ϊһ�����壬�Ӷ������е�һЩģ�����³���������ǿѧϰ���ԱȽ�����ѧϰ��һϵ����Ϊ����Щ����ʮ���������Զ���ʻ���߹��̣������ڱ�������̽����ǿѧϰ��������˼�ʻ���߹����з������á�
��ǿѧϰ���
��ǿѧϰ����������л���ѧϰ��������½�չ����ǿѧϰ��Ŀ����ͨ���ͻ�������ѧϰ���������Ӧ�Ĺ۲��в�ȡ������Ϊ����Ϊ�ĺû�����ͨ���������Ľ�����ȷ������ͬ�Ļ����в�ͬ�Ĺ۲�ͽ��������磬��ʻ�л����۲�������ͷ�ͼ����״�ɼ�������Χ������ͼ��͵��ƣ��Լ������Ĵ������������������ʻ�ٶȡ�GPS��λ����ʻ����ʻ�еĻ����Ľ�����������IJ�ͬ������ͨ�������յ���ٶȡ����ʶȺͰ�ȫ�Ե�ָ��ȷ����
��ǿѧϰ�ʹ�ͳ����ѧϰ�������������ǿѧϰ��һ���ջ�ѧϰ��ϵͳ����ǿѧϰ�㷨ѡȡ����Ϊ��ֱ��Ӱ�쵽����������Ӱ�쵽���㷨֮��ӻ����еõ��Ĺ۲⡣��ͳ�Ļ���ѧϰͨ�����ռ�ѵ�����ݺ�ģ��ѧϰ��Ϊ���������Ĺ��̡����磬���������Ҫѧϰһ�����������ģ�͡���ͳ����ѧϰ����������Ҫ��Ӷ��ע�߱�עһ������ͼ�����ݣ�Ȼ������Щ������ѧϰģ�ͣ�������ǿ���ѵ������������ʶ��ģ������ʵ��Ӧ���н��в��ԡ�
������ֲ��Խ�������룬��ô������Ҫ����ģ���д������⣬�������Ŵ������ռ�����ģ��ѵ����Ѱ��ԭ��Ȼ�����Щ�����н����Щ���⡣����ͬ�������⣬��ǿѧϰ���õķ�����ͨ��������ʶ���ϵͳ�г��Խ���Ԥ�⣬����ͨ���û�����������̶��������Լ���Ԥ�⣬�Ӷ�ͳһ�ռ�ѵ�����ݺ�ģ��ѧϰ�Ĺ��̡���ǿѧϰ�ͻ����������̵Ŀ�ͼ��ͼ1��ʾ��
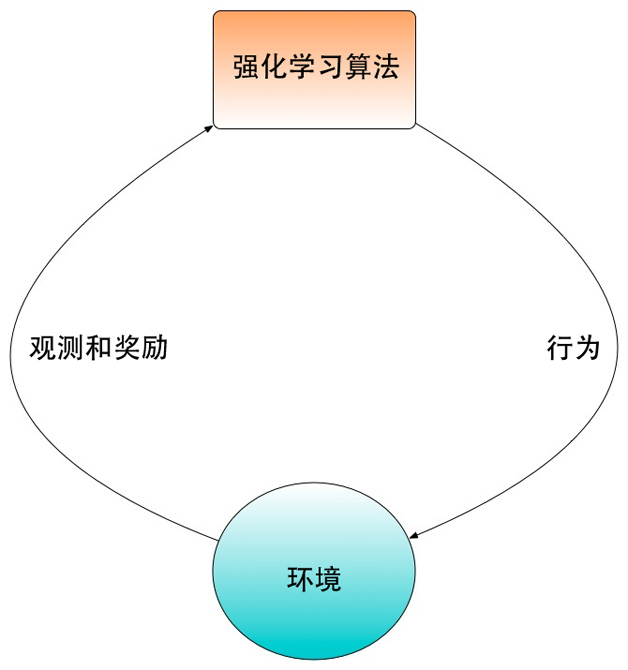
ͼ1 ��ǿѧϰ�ͻ��������Ŀ�ͼ
��ǿѧϰ�����źܶഫͳ����ѧϰ�����߱�����ս�����ȣ���Ϊ����ǿѧϰ��û��ȷ����ÿһʱ��Ӧ�ò�ȡ�ĸ���Ϊ����Ϣ����ǿѧϰ�㷨����ͨ��̽�����ֿ��ܵ���Ϊ�����жϳ����ŵ���Ϊ�������Ч���ڿ�����Ϊ�����϶���������Ч̽��������ǿѧϰ������Ҫ������֮һ����Σ�����ǿѧϰ��һ����Ϊ�������ܻ�Ӱ�쵱ǰʱ�̵Ľ��������һ����ܻ�Ӱ��֮������ʱ�̵Ľ��������������£�һ������Ϊ�����ڵ�ǰʱ�̻�ý����������ںܶಽ��ִ����ȷ����ܵõ�����������������£���ǿѧϰ��Ҫ�жϳ������ͺܶಽ֮ǰ����Ϊ�йطdz����Ѷȡ�
��Ȼ��ǿѧϰ���ںܶ���ս����Ҳ�ܹ�����ܶഫͳ�Ļ���ѧϰ���ܽ�������⡣���ȣ����ڲ���Ҫ��ע�Ĺ��̣�
��ǿѧϰ���Ը���Ч�ؽ���������������ŵ�������������磬���˳������п��ܻ�������˺Ͷ����Ҵ���·�����������ֻҪ���ǵ�ģ�����ܹ�ģ�����Щ�����������ǿѧϰ�Ϳ���ѧϰ����ô����Щ���������������ȷ����Ϊ����Σ���ǿѧϰ��������ϵͳ��Ϊһ�������ϵͳ���Ӷ������е�һЩģ�����³�������磬�Զ���ʻ�еĸ�֪ģ�鲻����������ȫ�ɿ���ǰһ��ʱ�䣬Tesla���˼�ʻ���¹ʾ�����Ϊ��ǿ����и�֪ģ��ʧЧ���µġ���ǿѧϰ������������ʹ��ijЩģ��ʧЧ�������Ҳ������������Ϊ�������ǿѧϰ���ԱȽ�����ѧϰ��һϵ����Ϊ���Զ���ʻ����Ҫִ��һϵ����ȷ����Ϊ���ܳɹ��ļ�ʻ�����ֻ�б�ע���ݣ�ѧϰ����ģ�����ÿ��ʱ��ƫ����һ�㣬�������ܾͻ�ƫ�Ʒdz��࣬���������Եĺ��������ǿѧϰ�ܹ�ѧ���Զ�����ƫ�ơ�
������������ǿѧϰ���Զ���ʻ���й�����ǰ�������Ļ������ǿѧϰ�ij����㷨�Լ������Զ���ʻ�е�Ӧ�á�ϣ���ܹ�������������̽���Թ�����
��ǿѧϰ�㷨
��ǿѧϰ�е�ÿ��ʱ��t��{0,1,2,��}�У����ǵ��㷨�ͻ���ͨ��ִ����Ϊat���н��������Եõ��۲�st�ͽ���rt��һ������У����Ǽ��軷���Ǵ��������Ʒ����ʵģ��������ı仯��ȫ����ͨ��״̬ת�Ƹ���Pass��=Pr{st+1=s��|st=s,at=a}�̻�������Ҳ����˵����������һʱ�̹۲�ֻ�͵�ǰʱ�̵Ĺ۲����Ϊ�йأ���֮ǰ����ʱ�̵Ĺ۲����Ϊ��û�й�ϵ����������t+1ʱ�̷��صĽ����ڵ�ǰ״̬����Ϊȷ���µ��������Ա�ʾΪ��Ras=E{rt+1|st=s,at=a}.
��ǿѧϰ�㷨��ÿһ��ʱ��ִ����Ϊ�IJ��Կ���ͨ�����ʦ�(s,a,��)=Pr{at=a|st=s;��}����ʾ�����Ц�����Ҫѧϰ�IJ��Բ�����������Ҫѧϰ�����ŵ���ǿѧϰ���ԣ�Ҳ����ѧϰ���ܹ�ȡ����߽����IJ��ԡ�
��(��)=E{��t=1�ަ�t?1rt|s0,�� ��1��
���Ц�����ǿѧϰ�е��ۿ�ϵ����������ʾ��֮��ʱ�̵õ��Ľ����ۿۡ�ͬ���Ľ�������õ�ʱ��Խ�磬��ǿѧϰϵͳ�����ܵ��Ľ���Խ�ߡ�
ͬʱ�����ǿ��������·�ʽ����Q������Q����Qpi(s,a)��ʾ������״̬Ϊs��ִ����Ϊa֮���ʱ�̶�ʹ�ò��Ԧ�ѡ����Ϊ�ܹ��õ��Ľ����������ܹ�ѧϰ��ȷ��Q��������ôʹQ������ߵ���Ϊ����������Ϊ��
Q��(s,a)=E{��k=1�ަ�k?1rr+k|st=s,at=a,��}=Es��[r+��Qpi(s��,a��)|s,a,��]
��2��
��ǿѧϰ��Ŀ�ģ������ڸ������������ͨ���Ի�������̽��ѧϰ����ѵIJ��Ժ��������rho(��)��������½������ǻ���ܳ��õ���ǿѧϰ�㷨������REINFORCE�㷨��Deep
Q-learning�㷨��
REINFORCE
REINFORCE�����reinforcement learning�㷨�������˼����ͨ���ڻ�������ִ�е�ǰ�IJ���ֱ��һ���غϽ�����������Ϸ�����������ݵõ��Ľ������Լ������ǰ���Ե��ݶȡ����ǿ���������ݶȸ��µ�ǰ�IJ��Եõ��²��ԡ�������Ļغϣ����������µIJ����ظ�������̣�һֱ����������ݶ��㹻СΪֹ�����õ��IJ��Ծ������Ų��ԡ�
�������ǵ�ǰ�IJ��Ը����ǦЦ�(x)=Pr{at=a|st=s;��} (���Dz��Բ�������ÿ���غϣ��㷨ʵ��ִ�е���Ϊat�ǰ��ո��ʦ�(x)�������õ��ġ��㷨�ڵ�ǰ�غ�ʱ��t��õĽ�����rt��ʾ����ô�������ݶȿ���ͨ�����µĹ�ʽ���㡣
?�Ȧ�(��)=��t=1T����log��(at|st;��)Rt ��3��
���Ц�(at|st;��)�Dz����ڹ۲stʱѡ��at�ĸ��ʡ�Rt=��Tt��=t��t��-trt�����㷨�ڲ�ȡ�˵�ǰ����֮������õ��ܵ��ۿۺ�Ľ�����Ϊ�˼���Ԥ����ݶȵķ������һ���ʹ��(Rt-bt)������Rt��btһ�����E��[Rt]��Ҳ���ǵ�ǰtʱ�̵Ļ�����ʹ�ò��Ԧ�֮���ܻ�õ��ۿۺ�����������
���������֮�����ǿ���ʹ�æ�=��+���Ȧ�(��)���²����õ��µIJ��ԡ�
REINFORCE�ĺ���˼����ͨ���ӻ����л�õĽ����ж�ִ����Ϊ�ĺû������һ����Ϊִ��֮���õĽ����Ƚϸߣ���ô������ݶ�Ҳ��Ƚϸߣ������ڸ��º�IJ����и���Ϊ���������ĸ���Ҳ��Ƚϸߡ���֮������ִ��֮���ý����Ƚϵ͵���Ϊ����Ϊ��������ݶȵͣ����º�IJ����и���Ϊ���������ĸ���Ҳ��Ƚϵ͡�ͨ������������з���ִ�и�����Ϊ��REIFORCE���Դ���ȷ�ع��Ƴ�������Ϊ����ȷ�ݶȣ��Ӷ��Բ����и�����Ϊ�IJ�������������Ӧ������
��Ϊ��IJ����㷨��REINFORCE�õ��˹㷺Ӧ�ã�����ѧϰ�Ӿ���ע�������ƺ�ѧϰ����ģ�͵�Ԥ����Զ��õ���REINFORCE�㷨����ʵ֤������ģ����Լ���������Բ�ǿ�Ļ����£�REINFORCE�㷨���Դﵽ�ܺõ�Ч����
���ǣ�REINFORCE�㷨Ҳ�������������⡣���ȣ�REINFORCE�㷨�У�ִ����һ����Ϊ֮������н���������Ϊ����Ϊ�����Ϊ�����ģ�����Ȼ����������Ȼ��ִ���˲����㹻��Ĵ���Ȼ��Լ�������ݶȽ���ƽ��֮��REINFORCE�Ժܴ���ʼ������ȷ���ݶȡ�������ʵ��ʵ���У�����Ч�ʿ��ǣ�ͬһ�������ڸ���֮ǰ�������ڻ�����ִ��̫��Ρ�����������£�REINFORCE��������ݶ��п��ܻ��бȽϴ������Σ�REINFROCE�㷨�п��ܻ�������һ���ֲ����ŵ㡣��������Ѿ�ѧ����һ�����ԣ���������дֵ���Ϊ���Խ���1�ĸ��ʲ���������ô����ʹ������Բ������ŵģ�REINFORCE�㷨Ҳ����ѧϰ����θĽ�������ԡ���Ϊ������ȫû��ִ��������������Ϊ0����Ϊ����֪����Щ��Ϊ�ĺû������REINFORCE�㷨֮���ڻ������ڻغϵĸ����ʱ����ܹ�ʹ�á���������ڻ����ĸ��REINFORCE�㷨Ҳ��ʹ�á�
�����DeepMind�����ʹ��Deep Q-learning�㷨ѧϰ���ԣ��˷���REINFORCE�㷨��ȱ�㣬��Atari��Ϸѧϰ�����ĸ��ӵ�������ȡ�������˾�ϲ��Ч����
Deep Q-learning
Deep Q-learning��һ�ֻ���Q��������ǿѧϰ�㷨�����㷨���ڸ��ӵ�ÿ����Ϊ֮����ڽ�ǿ������Ի����кܺõ�Ч����Deep
Q-learningѧϰ�㷨�Ļ�����Bellman��ʽ��������ǰ����½��Ѿ�������Q�����Ķ��壬������ʾ��
Qpi(s,a)=E{��k=1�ަ�k-1rr+k|st=s,at=a,��}=Es��[r+��Qpi(s��,a��)|s,a,��]
��4��
�������ѧϰ����������Ϊ��Ӧ��Q����Q*(s,a)����ô�������Ӧ�����������Bellman��ʽ��
Q*(s,a)=Es��[r+��maxa��Q*(s,a)|s,a] ��5��
���⣬���ѧϰ����������Ϊ��Ӧ��Q����Q*(s,a)����ô������ÿһʱ�̵õ��˹۲�st֮��ѡ��ʹ��Q*(s,a)��ߵ���Ϊ��Ϊִ�е���Ϊat��
���ǿ�����һ��������������Q��������Q(s,a;w)����ʾ������w��������IJ���������ϣ��ѧϰ������Q��������Bellman��ʽ����˿��Զ����������ʧ���������������Bellman��ʽ��L2������¡�
L(w)=E[(r+��maxa��Q*(s��,a��;w)-Q(s,a;w))2]��6��
����r����s�Ĺ۲�ִ����Ϊa��õ��Ľ�����s����ִ����Ϊa֮����һ��ʱ�̵Ĺ۲⡣�����ʽ��ǰ�벿��r+��maxa��Q*(s��,a��,w)Ҳ����ΪĿ�꺯��������ϣ��Ԥ�����Q�����ܹ���ͨ�����ʱ�̵õ��Ľ������¸�ʱ��״̬�õ���Ŀ�꺯�������ܽӽ���ͨ�������ʧ���������ǿ��Լ���������ݶȡ�
?L(w)?w=E[(r+��maxa��Q*(s��,a��;w)-Q(s,a;w))?Q(s,a;w?w)
��7��
����ͨ����������ݶȣ�ʹ���ݶ��½��㷨���²���w��
ʹ��������������ƽ�Q�������ںܶ����⡣���ȣ���һ���غ��ڲɼ����ĸ���ʱ�̵������Ǵ���������Եġ���ˣ��������ʹ����һ���غ��ڵ�ȫ�����ݣ���ô���Ǽ�������ݶ�����ƫ�ġ���Σ�����ȡ��ʹQ����������Ϊ�����������ɢ�ģ���ʹQ�����仯��С���������õ�����ΪҲ���ܲ��ܴ��������ᵼ��ѵ��ʱ���Գ��������Q�����Ķ�̬��Χ�п��ܻ�ܴ������Ǻ���Ԥ��֪��Q�����Ķ�̬��Χ����Ϊ�����Ƕ�һ������û���㹻���˽��ʱ���Ѽ������������п��ܵõ������������������ʹQ-learning�����ݶȿ��ܻ�ܴ���ѵ�����ȶ���
���ȣ�Deep Q-learning�㷨ʹ���˾���ط��㷨�������˼���Ǽ�ס�㷨�����������ִ�е���ʷ��Ϣ��������̺������ѧϰ�������ơ�������ѧϰִ����Ϊ�IJ���ʱ������ֻͨ����ǰִ�еIJ��Խ������ѧϰ������������֮ǰ����ʷִ�в��Ծ������ѧϰ����ˣ�����ط��㷨��֮ǰ�㷨��һ�������е����о��鶼�����������ѧϰ��ʱ���ԴӾ����в�����һ����������ת��Ϣ(st,at,rt+1,st+1)��Ҳ���ǵ����ڻ�����Ȼ��������Щ��Ϣ������ݶ�ѧϰģ�͡���Ϊ��ͬ����ת��Ϣ�ǴӲ�ͬ�غ��в��������ģ���������֮�䲻����ǿ����ԡ�����������̻����Խ��ͬһ���غ��еĸ���ʱ�̵�������������⡣
���ң�Deep Q-learning�㷨ʹ����Ŀ��Q���������ѧϰ�����е������⡣���ǿ��Զ���һ��Ŀ��Q����Q(s,a;w-)���������Ľṹ������ִ�е�Q����ṹ��ȫ��ͬ��Ψһ��ͬ����ʹ�õIJ���w-�����ǵ�Ŀ�꺯������ͨ��Ŀ��Q������㡣
r+��maxa��Q*(s��,a��;w-) ��8��
Ŀ��Q��������ںܳ�ʱ���ڱ��ֲ��䣬ÿ����Q����ѧϰ��һ��ʱ��֮����Q����IJ���w�滻Ŀ��Q����IJ���w-������Ŀ�꺯���ںܳ���ʱ���ﱣ���ȶ������Խ��ѧϰ�����е������⡣
���Ϊ�˷�ֹQ������ֵ̫�����ݶȲ��ȶ���Deep Q-learning���㷨�Խ���������������Сֵ��һ������Ϊ[-1,
+1]�������ǻ�����н������ŵ������Χ�������㷨��������ݶȸ����ȶ���
Q-learning�㷨�Ŀ�ͼ��ͼ2��ʾ��
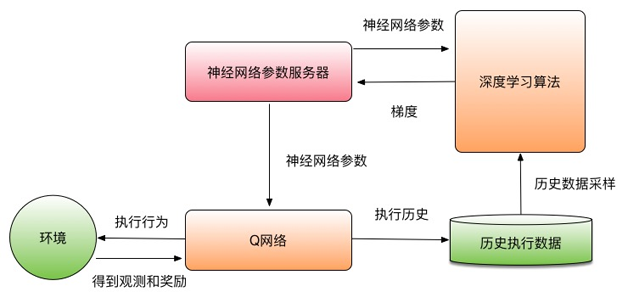
ͼ2 Q-learning�㷨��ͼ
��Ϊʹ���������������ѧϰQ������Deep Q-learning�����ֱ����ͼ����Ϊ����ѧϰ���ӵIJ��ԡ�����һ��������ѧϰAtari��Ϸ�����Ǽ������Ϸ��������ʽ��һ��ͼ��Ƚϴֲڣ���Ҫ�����Ҫ��ͼ��������⣬����ִ�и��ӵIJ��ԣ������ܣ������ӵ������Թ��ȡ�һЩAtari��Ϸ��������ͼ3��ʾ�����а�����һ����������Ϸ��
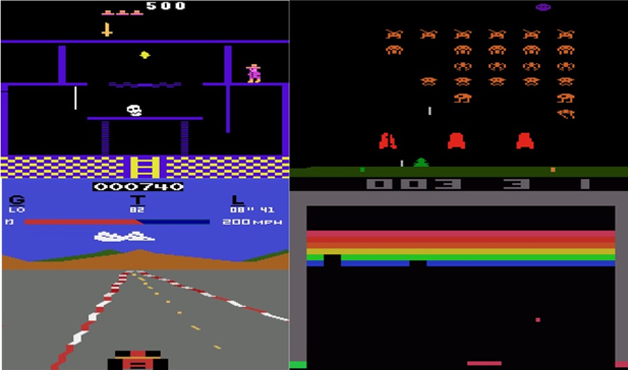
ͼ3 Atari��Ϸʾ��
Deep Q-learning�㷨��û���κζ���֪ʶ������£���ȫ��ͼ��ͻ�õĽ����������롣�ڴ�Atari��Ϸ�ж�������������ܡ��������ѧϰ������ǿѧϰ����ǰ��ȫ��������ɵ�����Atari��Ϸ�ǵ�һ��Deep
Q-learning������������㷨������������⣬�����ʾ�˽����ѧϰ����ǿѧϰ��ϵ���Խ�Ժ�ǰ����
ʹ����ǿѧϰ��������
���е������ǿѧϰ����������У�����ִ�е���Ϊһ��ֻ�Ի����ж���Ӱ�졣���磬��Atari������Ϸ�У�����ֻ��Ҫ���������ķ�����ٶ������������ܵ���ʻ�����Ҷ�����������Ϳ��Ի�����ŵIJ��ԡ����Ƕ��ڸ����Ӿ��ߵ��龰��������ֻͨ�����ڽ����õ����Ų��ԡ�һ�����͵����������Թ��������Թ���������У��ж�һ����Ϊ�Ƿ����������Ӷ��ڵĽ������õ���ֻ�е��ߵ��յ�ʱ�����ܵõ�����������������£�ֱ��ѧϰ����ȷ��Q�����dz����ѡ�����ֻ�аѻ��������ĺͻ�����ǿѧϰ���㷨��ϣ�������Ч����������⡣
���������㷨һ����ͨ����������ʵ�ֵġ��������ȿ��Խ��һ������ڻ�����̽�������⣨�������Թ�����Ҳ���Խ�������Ҿ��������⣨����Χ�壩��������Χ��Ϊ���������������Ļ������Χ����Ϸ��������ң��ֱ��ɰ��Ӻͺ��Ӵ�����Χ���������ߵĽ�����ǿ������ӵĵط���������ҷֱ��������°��Ӻͺ��ӡ�һ��һƬ���ӻ���ӱ��෴��ɫ���Ӱ�Χ����ô��Ƭ�Ӿͻᱻ��������³�Ϊ�հ�������Ϸ��������еĿհ�����ռ����ǰ�Χ��ռ��Ͱ�Χ����Ƚϴ��һ����ʤ��
��Χ�������Ϸ�У����Ǵӻ����еõ��Ĺ۲�st�����̵�״̬��Ҳ���ǰ��Ӻͺ��ӵķֲ�������ִ�е���Ϊ�����°��ӻ��ߺ��ӵ�λ�á����������õ��Ľ������Ը�����Ϸ�Ƿ�ȡʤ�õ���ȡʤ��һ��+1��ʧ�ܵ�һ��-1����Ϸ���̿���ͨ����������������ʾ���������е�ÿ���ڵ��Ӧ��һ������״̬��ÿһ���߶�Ӧ��һ�����ܵ���Ϊ������ͼ4��ʾ���������У��������У����ĸ��ڵ��Ӧ�����̵ij�ʼ״̬s0��a1��a2��Ӧ�ź������ֿ��ܵ�����λ�ã�ʵ�ʵ�Χ���У����ܵ���ΪԶ�����ֶࣩ��ÿ����Ϊai��Ӧ��һ���µ����̵�״̬si1���������ð����ߣ�����ͬ���������߷�b1��b2������ÿ�����̵�״̬si1�����ֲ�ͬ���߷��ֻ��������ֲ�ͬ״̬�����������һֱ����Ϸ���������ǾͿ�����Ҷ�ӽڵ��л����Ϸ����ʱ�����õĽ��������ǿ���ͨ����Щ���������ѵ�״̬��
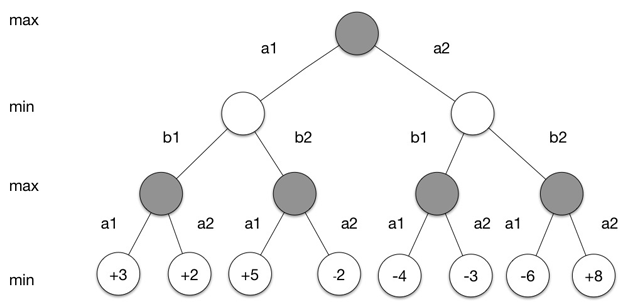
ͼ4 ������������
ͨ������������������������Ͱ���IJ��Ԧ�=[��1,��2]�����ǿ��Զ�������ֵ����Ϊ������˫���ֱ�ִ�в��Ԧ�1�ͦ�2ʱ���������ܻ�ý�����������
v��(s)=E��[Gt|St=s] ��9��
������ҪѰ�ҵ����Ų�����Ҫ���Ż��������£��������ܵõ��Ľ��������Ƕ������ֵ����Ϊ��С���ֵ��������������Ų��Ծ����ܹ��ﵽ���ֵ�����IJ��Ԧ�1��
v*(s)=max��1min��2v��(s) ��10��
��������ܹ������������ÿ���ڵ㣬��ô���ǿ��Ժ������õݹ鷽ʽ�������С���ֵ�����ͺ�������Ų��ԡ�����ʵ�ʵ�Χ���У�ÿһ������Ͱ�����Բ��õ���Ϊ�����dz��࣬���������Ľڵ���Ŀ�����������ָ����������ˣ�������ö�����нڵ�����ȷ����С���ֵ��������ֻ��ͨ��ѧϰv(s;w)~v*(s)��Ϊ������С���ֵ���������ǿ���ͨ�����ַ���ʹ��������ƺ��������ȣ����ǿ���ʹ��������ƺ���ȷ�����������ȼ�������һ���ڵ㣬������ߺ�������ж����߷�������Ӧ����������������С���ֵ�����Ƚϸ߽ڵ����Ϊ����Ϊ��ʵ����Ϸ�У���ʵ���һ���ѡ����Щ��ԱȽϺõ���Ϊ����Σ����ǿ���ʹ��������ƺ��������Ʒ�Ҷ�ӽڵ����С���ֵ�������Щ�ڵ����С���ֵ�dz��ͣ���ô��Щ�ڵ㼸�������ܶ�Ӧ�����Ų��ԡ�������������ʱ��Ҳ���ÿ�����Щ�ڵ㡣
�����Ҫ���������ѧϰ��������С���ֵ����v(s;w)�����ǿ���ʹ������ѧϰ����Χ���㷨�Լ����Լ���Χ����Ϸ��Ȼ��ͨ����ǿѧϰ�㷨���½�����С���ֵ�����IJ���w����������һ����Ϸ֮�����ǿ���ʹ������REINFORCE�㷨�ĸ��·�ʽ��
��w=��(Gt-v(st;w))��wv(st;w) ��11��
�����ʽ����Gt��ʾ������tʱ��֮���õĽ�������Ϊ��Χ�������Ϸ�У�����ֻ�����ʱ�̻�ý���������Gt��Ӧ��������õĽ���������Ҳ����ʹ������Q-learning�ķ�ʽ��TD��������²�����
��w=��(v(st+1;w)-v(st;w))��wv(st;w)��12��
��ΪΧ�������Ϸ�У�����ֻ�����ʱ�̻�ý�����һ��ʹ��REINFORCE�㷨�ĸ��·�ʽЧ���ȽϺá���ѧϰ��һ���õĽ�����С���ֵ����֮���Դ��ӿ�����Ч�ʡ������ѧϰΧ��Ĺ������ƣ�����ѧϰΧ��Ĺ����У�����ض��������γɸо�����һ�۾��жϳ����еĺû��������ö���ķ�չ���������������ͨ��ѧϰ������С���ֵ�������������Ĺ��̡�
ͨ��ѧϰ������С���ֵ������Google DeepMind��Χ������ȡ����ͻ���ͽ����ڽ������½��еı����У�AlphaGo���ı�һսʤ��Χ������ھ�����ʯ��AlphaGo�ĺ����㷨����ͨ����ʷ��ֺ��Լ�����ѧϰ������С���ֵ������AlphaGo�ijɹ���ֵ���ʾ����ǿѧϰ�������������Ҫ���ڹ滮�����ϵ�DZ������������Ҫע����ǣ����н���ǿѧϰ��������ϵ��㷨ֻ������ȷ���ԵĻ����С�ȷ���ԵĻ����и���һ���۲��һ����Ϊ����һ���۲���ȷ���ģ��������ת�ƺ�������֪�ġ��ڻ�����ȷ��������ת�ƺ���δ֪������£���ΰ���ǿѧϰ��������ϻ�����ǿѧϰ������û�н�������⡣
�Զ���ʻ�ľ��߽���
�Զ���ʻ���˹����ܰ����˸�֪�����ߺͿ����������档��ָ֪�������ͨ������ͷ�����������������������Χ��������Ϣ����������Щ�ϰ���ϰ�����ٶȺ;��룬��·�Ŀ��Ⱥ����ʵȡ�����������Զ���ʻ�Ļ������ǵ�ǰ�Զ���ʻ�о�����Ҫ������ǰ�������Ѿ��н��⡣������ָ����������һ��Ŀ�꣬������ת30�ȣ����ͨ�����������Ļ�е�����ﵽ���Ŀ�ꡣ��������Ѿ�����ԱȽϳ�����㷨�ܹ���������ڱ��ĵ����۷�Χ֮�ڡ����ڣ��������ؽ����Զ���ʻ�ľ��߲��֡�
�Զ���ʻ�ľ�����ָ������֪ģ��������Ļ�����Ϣ��ο�����������Ϊ���ﵽ��ʻĿ�ꡣ���磬�������١����١���ת����ת���������������Ǿ���ģ������������ģ�鲻����Ҫ���ǵ������İ�ȫ�������ԣ���֤���쵽��Ŀ��ص㣬����Ҫ���Ա߳��������ʻ������±�֤�˿Ͱ�ȫ����ˣ�����ģ��һ������Ҫ���г��ƻ����г��ڹ滮����һ���滹��Ҫ����Χ���������˵���Ϊ����Ԥ�⡣���ң��Զ���ʻ�еľ���ģ���ȫ�Ϳɿ��������ϸ�Ҫ�������Զ���ʻ�ľ���ģ��һ����ݹ�������Ȼ����Ӧ���ּ�ʻ��������ڼ�ʻ�п��ܳ��ֵĸ���ͻ����������ڹ���ľ���ϵͳ������ö�ٵ�����ͻ�������������Ҫһ������Ӧϵͳ��Ӧ�Լ�ʻ�����г��ֵĸ���ͻ�������
�����Զ���ʻ�ľ���ϵͳ�ֻ��ڹ���ϵͳ�ֿ���������״̬����ʾ�����磬�Զ���ʻ�ĸ߲���Ϊ���Է�Ϊ���������һ��������桢����ͣ��������ϵͳ����Ŀ����Ծ���ִ�и߲���Ϊ��������Ҫִ�еĸ߲���Ϊ������ϵͳ��������Ӧ�Ĺ������ɳ��ײ���Ϊ�����ڹ������ϵͳ����Ҫȱ����ȱ������ԡ��������е�ͻ�����������Ҫдһ�����ߡ����ַ�ʽ���Ѷ����е�ͻ��ϵͳ����㵽��
�Զ���ʻģ����
�Զ���ʻ�ľ��߹����У�ģ�������ŷdz���Ҫ�����á�����ģ��������Ի����г����ij�������ģ�⣬���糵�������·��������ϰ���ֲ�����Ϊ�������ȡ�ͬʱ�����Խ���ʵ�����вɼ��������ݽ��лطš�����ģ�����Ľӿں��泵�Ľӿڱ���һ�£��������Ա�֤���泵��ʹ�õľ����㷨����ֱ����ģ���������С����˾���ģ����֮�⣬�Զ���ʻ��ģ�����������˸�֪ģ�����Ϳ���ģ������������֤��֪�Ϳ���ģ�顣��Щģ�������ڱ��ĵ����۷�Χ֮��
����ϸ���CSDN������Ա��2016��8�¡�����Spark��ROS�ķֲ�ʽ���˼�ʻģ��ƽ̨������
�Զ���ʻģ�����ĵ�һ����Ҫ��������֤���ڵ��������㷨�Ĺ����У�������Ҫ�Ƚ����غ����㷨���ܡ����磬��Ҫȷ���¾����㷨��֮ǰ�ܹ���ȷ���кͳ����ij������ܹ���ȫ���С����ǻ���Ҫ�����¾����㷨�Գ��������İ�ȫ�ԡ�����ԡ������Դ�֡����Dz�����ÿ���ڸ����㷨ʱ����ʵ�ʳ����в��ԣ���ʱ��һ���ܿɿ���ӳ��ʵ���������˼�ʻģ�����Ƿdz���Ҫ�ġ�
ģ��������һ����Ҫ�Ĺ����ǽ�����ǿѧϰ������ģ�������ͻ�������Ȼ����ǿѧϰ�㷨����������Щͻ������л�õĽ�����ѧϰ���Ӧ�ԡ�������ֻҪ�ܹ�ģ����㹻��ͻ���������ǿѧϰ�㷨�Ϳ���ѧϰ����Ӧ�Ĵ���������������ÿ��ͻ�����������д�����������ң�ģ����Ҳ���Ը���֮ǰ��ǿѧϰ����ͻ������Ĵ��������������������ǰ����ǿѧϰ�㷨�������ͻ�����Ӷ���ǿѧϰЧ�ʡ�
�����������Զ���ʻģ�����Ծ���ģ�����֤��ѧϰ������������Ҫ�����ã������˼�ʻ����ĺ��ļ�������δ������ܹ�ģ�����ʵ���������Ǵ�ͻ����������Һ���ʵ�������ӿڼ��ݵ�ģ���������Զ���ʻ�з����ѵ�֮һ��
��ǿѧϰ���Զ���ʻ�е�Ӧ�ú�չ��
��ǿѧϰ���Զ���ʻ�к���ǰ����������TORCSģ������ʹ����ǿѧϰ������̽���ԵĹ�����TORCS��һ������ģ��������ҵ������dz�������AI����������ٶȴﵽ�յ㡣��ȻTORCS�е��������ʵ���Զ���ʻ�����кܴ����𡣵������㷨�����ܷdz�����������TORCSģ������ͼ5��ʾ����ǿѧϰ�㷨һ�������ǰ���ͺ�����ͼ����Ϊ���룬Ҳ���Ի���״̬��Ϊ���루�����ٶȣ���������Ե�ľ�����������ľ��룩��

ͼ5 TORCSģ������ͼ
��������ʹ���˻���״̬��Ϊ���롣ʹ��Deep Q-learning��Ϊѧϰ�㷨ѧϰ��������������Ϊ�ڵ�λʱ�̳������ܵ���ǰ�����롣���⣬����������ܵ����ߺ������ij�����ײ����õ�����ͷ�������״̬�����������ٶȡ����ٶȡ����ܵ������ұ�Ե�ľ��룬�Լ��ܵ������нǣ��ڸ�������������ij��ľ���ȵȡ�������Ϊ�������ϻ��������»��������١����١���������̡����Ҵ����̵ȵȡ�
����ͨ��Deep Q-learning��ȣ������������µĸĽ������ȣ�ʹ���˶ಽTD�㷨���и��¡��ಽTD�㷨�ܱȵ����㷨ÿ��ѧϰʱ���������ִ�в��������Ҳ�ܸ������������Σ�����ʹ����Actor-Critic�ļܹ��������㷨�IJ��Ժ�����ֵ�����ֱ�ʹ�����������ʾ�������ı�ʾ�������ŵ㣺1.
���Ժ�������ʹ�üලѧϰ�ķ�ʽ���г�ʼ��ѧϰ��2. �ڻ����Ƚϸ��ӵ�ʱ��ѧϰֵ�����dz������ѡ��Ѳ��Ժ�����ֵ�����ֿ�ѧϰ���Խ��Ͳ��Ժ���ѧϰ���Ѷȡ�
ʹ���˸Ľ����Deep Q-learning�㷨������ѧϰ���IJ�����TORCS�п���ʵ�����ܵ����ߣ���������������Ϊ�������ﵽ��TORCS�����еĻ�����ʻ����Ҫ��Google
DeepMindֱ��ʹ��ͼ����Ϊ���룬Ҳ����˺ܺõ�Ч������ѵ���Ĺ���Ҫ���ܶࡣ
���е���ǿѧϰ�㷨���Զ���ʻģ����л���˺���ϣ���Ľ�������ǿ��Կ����������Ҫ��ǿѧϰ�����ܹ����Զ���ʻ�ij�����Ӧ�ã�����Ҫ�кܶ�Ľ�����һ���Ľ���������ǿѧϰ������Ӧ���������е���ǿѧϰ�㷨�ڻ������ʷ����ı�ʱ����Ҫ�Դ��ܶ�β���ѧϰ����ȷ����Ϊ�������ڻ��������ı������£�ֻ��Ҫ���ٴ��Դ��Ϳ���ѧϰ����ȷ����Ϊ�����ֻ�÷dz���������ѧϰ����ȷ����Ϊ����ǿѧϰ�ܹ�ʵ�õ���Ҫ������
�ڶ�����Ҫ�ĸĽ�������ģ�͵Ŀɽ����ԡ�������ǿѧϰ�еIJ��Ժ�����ֵ��������������������ʾ�ģ���ɽ����ԱȽϲ��ʵ�ʵ�ʹ���г������⣬�����ҵ�ԭ��Ҳ�Ƚ������Ų顣���Զ���ʻ������������������У����ҵ�ԭ������ȫ�����ܵġ�
��������Ҫ�ĸĽ���������������������������ѧϰ�Ĺ����кܶ�ʱ����Ҫ��һ�����������������������磬�ڼ�ʻʱ�������������ԣ�Ҳ֪��Σ�յ���Ϊ����������Եĺ����
������Ϊ��������������һ���㹻�õ�ģ��������������������Ӧ��Ϊ���ܻᷢ���ĺ�������������������ڴ���Σ����Ϊ�Ļ������·dz���Ҫ���ڰ�ȫ�Ļ�����Ҳ���Դ��ӿ������ٶȡ�
ֻ������Щ����������ʵ��ͻ�ƣ���ǿѧϰ��������ʹ�õ��Զ���ʻ���ǻ�����������Ҫ�������С�ϣ��������־֮ʿ��Ͷ�������о���Ϊ�˹����ܵķ�չ���׳��Լ��������� |






