| 本文是无人驾驶技术系列的第三篇,着重介绍基于计算机视觉的无人驾驶感知系统。在现有的无人驾驶系统中,LiDAR是当仁不让的感知主角。但是由于LiDAR的成本高等因素,业界有许多是否可以使用成本较低的摄像头去承担更多感知任务的讨论。本文探索了基于计算机视觉的无人驾驶感知方案。首先,验证一个方案是否可行需要一个标准的测试方法,我们介绍了广泛被使用的无人驾驶视觉感知数据集KITTI。然后,我们讨论了在无人驾驶场景中使用到的具体计算机视觉技术,包括Optical
Flow和立体视觉、物体的识别和跟踪以及视觉里程计算法。
无人驾驶的感知
在无人驾驶技术中,感知是最基础的部分,没有对车辆周围三维环境的定量感知,就有如人没有了眼睛,无人驾驶的决策系统就无法正常工作。为了安全与准确的感知,无人驾驶系统使用了多种传感器,其中可视为广义“视觉”的有超声波雷达、毫米波雷达、激光雷达(LiDAR)和摄像头等。超声波雷达由于反应速度和分辨率的问题主要用于倒车雷达,毫米波雷达和激光雷达承担了主要的中长距测距和环境感知,而摄像头主要用于交通信号灯和其他物体的识别。
LiDAR由于出色的精度和速度,一直是无人驾驶感知系统中的主角,是厘米级的高精度定位中不可或缺的部分。但是正如本系列第一篇文章《光学雷达在无人驾驶技术中的应用》分析,LiDAR存在成本昂贵、空气中的悬浮物影响精度等问题,毫米波雷达虽然相比LiDAR可以适应较恶劣的天气和灰尘,但也需要防止其他通讯设备和雷达间的电磁波干扰。
传统计算机视觉领域的主要研究方向是基于可见光的摄像头的视觉问题,从摄像头采集的二维图像推断三维物理世界的信息。那么最常见、成本较低的摄像头能不能承担更多的感知任务呢?在本文中,我们将探索基于计算机视觉的无人驾驶感知方案。首先,要验证一个方案是否可行,我们需要一个标准的测试方法。本文将介绍由德国卡尔斯鲁厄技术研究院(KIT)和丰田芝加哥技术研究院(TTIC)共同开发的KITTI数据集。在有了标准的数据集之后,研究人员可以开发基于视觉的无人驾驶感知算法,并使用数据集对算法进行验证。我们将介绍计算机视觉在无人驾驶感知方面的前沿研究,包括光流(Optical
Flow)和立体视觉、物体的检测和跟踪以及视觉里程计算法。
KITTI数据集
KITTI数据集是由KIT和TTIC在2012年开始的一个合作项目,网站在http://www.cvlibs.net/datasets/kitti/,这个项目的主要目的是建立一个具有挑战性的、来自真实世界的测试集。他们使用的数据采集车配备了:
一对140万像素的彩色摄像头Point Grey Flea2(FL2-14S3C-C),采集频率10赫兹。
一对140万像素的黑白摄像头Point Grey Flea2(FL2-14S3M-C),采集频率10赫兹。
一个激光雷达Velodne HDL-64E。
一个GPS/IMU定位系统OXTSRT 3003。

图1 数据采集车
图1这辆车在卡尔斯鲁厄的高速公路和城区的多种交通环境下收集了数据,用激光雷达提供的数据作为ground
truth,建立了面向多个测试任务的数据集:
Stereo/Optical Flow数据集:如图2,数据集由图片对组成。一个Stereo图片对是两个摄像头在不同的位置同时拍摄的,Optical
Flow图片对是同一个摄像头在相邻时间点拍摄的。训练数据集有194对,测试数据集有195对,大约50%的像素有确定的偏移量数据。 
图2 Stereo/Optical Flow数据集
视觉里程测量数据集:如图3,数据集由22个Stereo图片对序列组成,一个4万多帧,覆盖39.2公里的里程。

图3 视觉里程测量数据集
三维物体检测数据集:手工标注,包含轿车、厢车、卡车、行人、自行车者、电车等类别,用三维框标注物体的大小和朝向,有多种遮挡情况,并且一张图片通常有多个物体实例,如图4。 
图4 三维物体检测数据集
物体追踪数据集:手工标注,包含21个训练序列和29个测试序列,主要追踪目标类型是行人和轿车,如图5。 
图5 物体追踪数据集
路面和车道检测数据集:手工标注,包含未标明车道、标明双向单车道和标明双向多车道三种情况,289张训练图片和290张测试图片,ground
truth包括路面(所有车道)和自车道,如图6。 
图6 路面和车道检测数据集
和以往计算机视觉领域的数据集相比,KITTI数据集有以下特点:
由无人驾驶车上常见的多种传感器收集,用LiDAR提供高精度的三维空间数据,有较好的ground truth。
不是用计算机图形学技术生成的,更加接近实际情况。
覆盖了计算机视觉在无人驾驶车上应用的多个方面。
由于这些特点,越来越多的研究工作基于这个数据集开展,一个新的算法在这个数据集上的测试结果有较高的可信度。
计算机视觉能帮助无人驾驶解决的问题
计算机视觉在无人车上的使用有一些比较直观的例子,比如交通标志和信号灯的识别(Google)、高速公路车道的检测定位(特斯拉)。现在基于LiDAR信息实现的一些功能模块,其实也可以用摄像头基于计算机视觉来实现。下面我们介绍计算机视觉在无人驾驶车上的几个应用前景。当然,这只是计算机视觉在无人车上的部分应用,随着技术的发展,越来越多的基于摄像头的算法会让无人车的感知更准确、更快速、更全面。
计算机视觉在无人车场景中解决的最主要的问题可以分为两大类:物体的识别与跟踪,以及车辆本身的定位。
物体的识别与跟踪:通过深度学习的方法,我们可以识别在行驶途中遇到的物体,比如行人、空旷的行驶空间、地上的标志、红绿灯以及旁边的车辆等。由于行人以及旁边的车辆等物体都是在运动的,我们需要跟踪这些物体以达到防止碰撞的目的,这就涉及到Optical
Flow等运动预测算法。
车辆本身的定位:通过基于拓扑与地标算法,或者是基于几何的视觉里程计算法,无人车可以实时确定自身位置,满足自主导航的需求。
Optical Flow和立体视觉
物体的识别与跟踪,以及车辆本身的定位都离不开底层的Optical Flow与立体视觉技术。在计算机视觉领域,Optical
Flow是图片序列或者视频中像素级的密集对应关系,例如在每个像素上估算一个2维的偏移矢量,得到的Optical
Flow以2维矢量场表示。立体视觉则是从两个或更多的视角得到的图像中建立对应关系。这两个问题有高度相关性,一个是基于单个摄像头在连续时刻的图像,另一个是基于多个摄像头在同一时刻的图片。解决这类问题时有两个基本假设:
不同图像中对应点都来自物理世界中同一点的成像,所以“外观”相似。
不同图像中的对应点集合的空间变换基本满足刚体条件,或者说空间上分割为多个刚体的运动。从这个假设我们自然得到Optical
Flow的二维矢量场片状平滑的结论。
在今年6月于美国拉斯维加斯召开的CVRP大会上,多伦多大学的Raquel Urtasun教授和她的学生改进了深度学习中的Siamese网络,用一个内积层代替了拼接层,把处理一对图片的时间从一分钟左右降低到一秒以内。
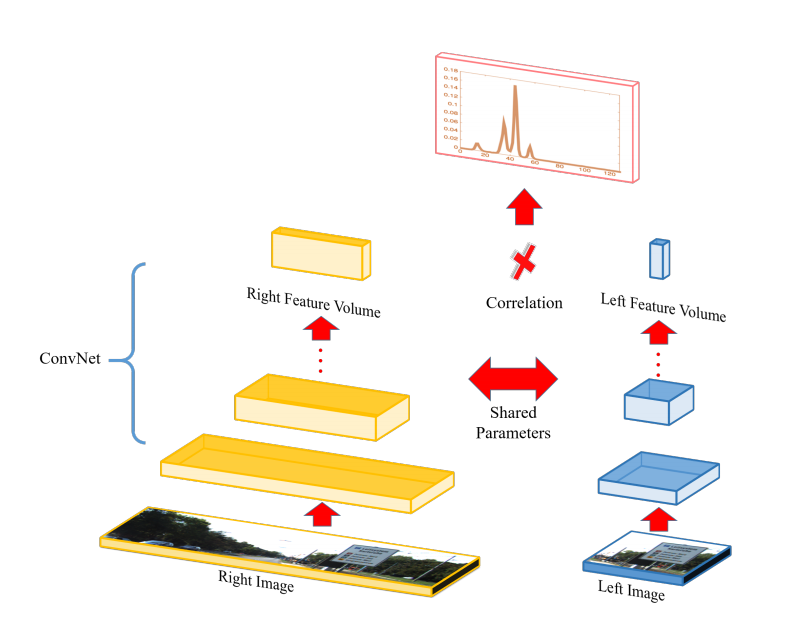
图7 Siamese结构的深度神经网络
如图7所示,这个Siamese结构的深度神经网络分左右两部分,各为一个多层的卷积神经网络(CNN),两个CNN共享网络权重。Optical
Flow的偏移矢量估计问题转化为一个分类问题,输入是两个9x9的图片块,输出是128或者256个可能的偏移矢量y。通过从已知偏移矢量的图片对中抽取的图片块输入到左右两个CNN,然后最小化交叉熵(cross-entropy):
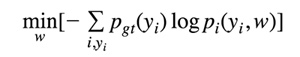
我们可以用监督学习的方法训练整个神经网络。
i是像素的指标。
y_i是像素i可能的偏移矢量。
p_gt是一个平滑过的目标分布,用来给一两个像素的预估误差反馈一个非0的概率,gt表示ground truth。
p_i (y_i,w)是神经网络输出的给定w时y_i的概率。
在KITTI的Stereo2012数据集上,这样一个算法可以在0.34秒完成计算,并达到相当出色的精度,偏移估计误差在3-4像素左右,对大于3像素的偏移估计误差在8.61像素,都好于其他速度慢很多的算法。
在得到每个像素y_i上的分布后,我们还需要加入空间上的平滑约束,这篇文章试验了三种方法:
最简单直接的5x5窗口平均。
加入了相邻像素一致性的半全局块匹配(Semi Global Block Matching,SGBM)。
超像素+3维斜面。
这些平滑方法一起,能把偏移估计的误差再降低大约50%,这样一个比较准确的2维偏移矢量场就得到了。基于它,我们就能够得到如图8所示场景3维深度/距离估计。这样的信息对无人驾驶非常重要。

图8 深度信息图
物体的识别与追踪
从像素层面的颜色、偏移和距离信息到物体层面的空间位置和运动轨迹,是无人车视觉感知系统的重要功能。无人车的感知系统需要实时识别和追踪多个运动目标(Multi-ObjectTracking,MOT),例如车辆和行人。物体识别是计算机视觉的核心问题之一,最近几年由于深度学习的革命性发展,计算机视觉领域大量使用CNN,物体识别的准确率和速度得到了很大提升,但总的来说物体识别算法的输出一般是有噪音的:物体的识别有可能不稳定,物体可能被遮挡,可能有短暂误识别等。自然地,MOT问题中流行的Tracking-by-detection方法就要解决这样一个难点:如何基于有噪音的识别结果获得鲁棒的物体运动轨迹。在ICCV
2015会议上,斯坦福大学的研究者发表了基于马尔可夫决策过程(MDP)的MOT算法来解决这个问题,下面我们就详细介绍这个工作。
运动目标的追踪用一个MDP来建模(图9):
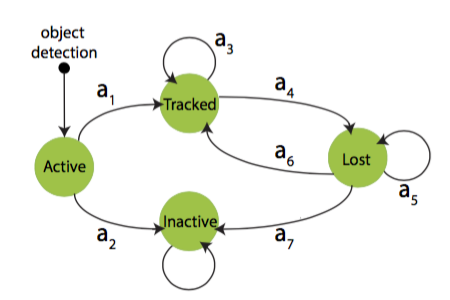
图9 DMM状态图
运动目标的状态:s∈S=S_active∪S_tracked∪S_lost∪S_inactive,这几个子空间各自包含无穷多个目标状态。被识别到的目标首先进入active状态,如果是误识别,目标进入inactive状态,否则进入tracked状态。处于tracked状态的目标可能进入lost状态,处于lost状态的目标可能返回tracked状态,或者保持lost状态,或者在足够长时间之后进入inactive状态。
作用a∈A,所有作用都是确定性的。
状态变化函数T:S×A→S定义了在状态s和作用a下目标状态变为s'。
奖励函数R:S×A→R定义了作用a之后到达状态s的即时奖励,这个函数是从训练数据中学习的。
规则π:S→A决定了在状态s采用的作用a。
如图10,这个MDP的状态空间变化如下:
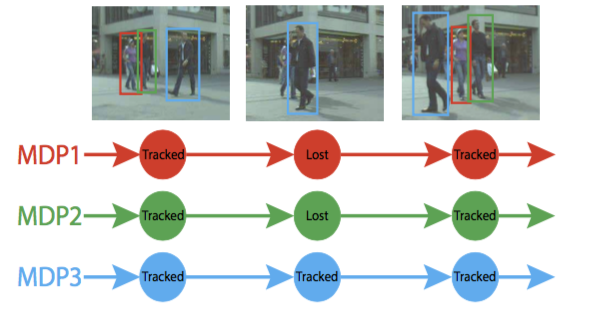
图10 状态转换实例
在active状态下,物体识别算法提出的物体候选通过一个线下训练的支持向量机(SVM),判断下一步的作用是a_1还是a_2,这个SVM的输入是候选物体的特征向量,空间位置大小等,它决定了在S_active中的MDP规则π_active。
在tracked状态下,一个基于tracking-learning-detection追踪算法的物体线上外观模型被用来决定目标物体是否保持在tracker状态还是进入lost状态。这个外观模型(appearance
model)使用当前帧中目标物体所在的矩形(bounding box)作为模板(template),所有在tracked状态下收集的物体外观模板在lost状态下被用来判断目标物体是否回到tracked状态。另外在tracked状态下,物体的追踪使用上述外观模型模板,矩形范围内的Optical
Flow和物体识别算法提供的候选物体和目标物体的重合比例来决定是否保持在tracked状态,如果是,那么目标物体的外观模板自动更新。
在lost状态下,如果一个物体保持lost状态超过一个阈值帧数,就进入inactive状态;物体是否返回tracked状态由一个基于目标物体和候选物体相似性特征向量的分类器决定,对应了S_lost中的π_lost。
这个基于MDP的算法在KITTI数据集的物体追踪评估中达到了业界领先水平。
视觉里程计算法
基于视觉的定位算法有两大分类:一种是基于拓扑与地标的算法,另一种是基于几何的视觉里程计算法。基于拓扑与地标的算法把所有的地标组成一个拓扑图,然后当无人车监测到某个地标时,便可以大致推断出自己所在的位置。基于拓扑与地标的算法相对于基于几何的方法容易,但是要求预先建立精准的拓扑图,比如将每个路口的标志物做成地标。基于几何的视觉里程计算法计算比较复杂,但是不需要预先建立精准的拓扑图,这种算法可以在定位的同时扩展地图。以下着重介绍视觉里程计算法。
视觉里程计算法主要分为单目以及双目两种,纯单目的算法的问题是无法推算出观察到的物体的大小,所以使用者必须假设或者推算出一个初步的大小,或者通过与其它传感器(如陀螺仪)的结合去进行准确的定位。双目的视觉里程计算法通过左右图三角剖分(Triangulation)计算出特征点的深度,然后从深度信息中推算出物体的大小。图11展示了双目视觉里程计算法的具体计算流程:
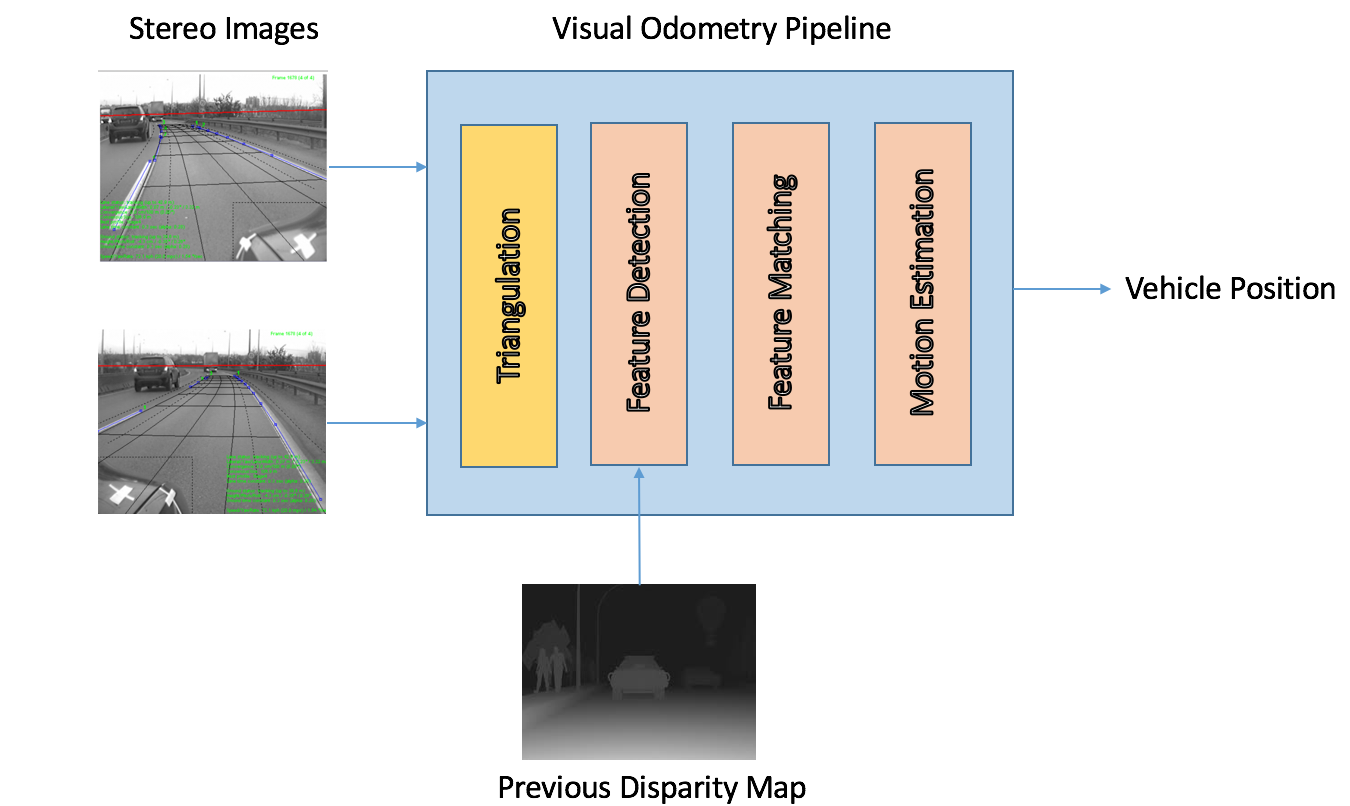
图11 双目视觉里程计算法的计算流程
双目摄像机抓取左右两图。
双目图像经过Triangulation产生当前帧的视差图(Disparity Map)。
提取当前帧与之前帧的特征点,如果之前帧的特征点已经提取好了,那么我们可以直接使用之前帧的特征点。特征点提取可以使用Harris
Corner Detector。
对比当前帧与之前帧的特征点,找出帧与帧之间的特征点对应关系。具体可以使用随机抽样一致(RANdom Sample
Consensus,RANSAC)算法。
根据帧与帧之间的特征点对应关系,推算出两帧之间车辆的运动。这个推算是最小化两帧之间的重投影误差(Reprojection
Error)实现的。
根据推算出的两帧之间车辆的运动,以及之前的车辆位置,计算出最新的车辆位置。
通过以上的视觉里程计算法,无人车可以实时推算出自己的位置,进行自主导航。但是纯视觉定位计算的一个很大问题是算法本身对光线相当敏感。在不同的光线条件下,同样的场景不能被识别。特别在光线较弱时,图像会有很多噪点,极大地影响了特征点的质量。在反光的路面,这种算法也很容易失效。这也是影响视觉里程计算法在无人驾驶场景普及的一个主要原因。一个可能的解决方法,是在光线条件不好的情况下,更加依赖根据车轮以及雷达返回的信息进行定位,这将会在后续的文章中详细讨论。
结论
在本文中,我们探索了基于视觉的无人驾驶感知方案。首先,要验证一个方案是否可行,我们需要一个标准的测试方法。为此我们介绍了无人驾驶的标准KITTI数据集。在有了标准的数据集之后,研究人员可以开发基于视觉的无人驾驶感知算法,并使用数据集对算法进行验证。然后,我们详细介绍了计算机视觉的Optical
Flow和立体视觉、物体的识别和跟踪与视觉里程计算法等技术,以及这些技术在无人驾驶场景的应用。视觉主导的无人车系统是目前研究的前沿,虽然目前各项基于视觉的技术还没完全成熟,我们相信在未来五年,如果LiDAR的成本不能降下来,基于摄像机的视觉感知会逐步取代LiDAR的功能,为无人车的普及打好基础。
从计算机视觉的角度,无人驾驶可能是一次难得的机遇,无人车产业爆发带来的资源、无人车收集的大量真实世界数据和LiDAR提供的高精度三维信息可能意味着计算机视觉将要迎来“大数据”和“大计算”带来的红利,数据的极大丰富和算法的迭代提高相辅相成,会推动计算机视觉研究前进,并使之在无人驾驶中起到更加不可或缺的作用。 |






