| ���Ŵ�����ƽ̨�Ͳ�Ʒ���������Ӧ��ʵ����Docker��Դ���������죬ҵ���в��ٵĴ������з��Ŷӿ�ʼӵ��Docker������˵��Docker����Hadoopƽ̨������Ӽ�ݡ����з��Ͳ����ŶӼ��ɽ����������ݸ�Ч���ò���������ά�������������ϣ����ⱳ���ҵ���;����ʵ����������Щ?��Docker�����������������ƵĹ����У�������ƽ̨��ƷDockerģʽ��Ӧ��������ν����?���DZ��������ز����ġ�
ʵ���з�������
����һ
�ڴ�����ƽ̨�Ͳ�Ʒ�Ŀ��������У�����Ҫ������ģ���������Hadoop��HBase��Hive��Spark��Sqoop��Solr��Zookeeper�����ȶ�Xʮ����Դ�����Ϊ�˲�Ӱ���Ŷӳ�Ա��Ĺ�������Эͬ��������Ա��ʵ�dz���Ҫ�Լ���һ�����ļ�Ⱥ�������Ա㷴�������Լ������ģ�飬����ʵ����ҵ������������ֻ��һ����������⼯Ⱥ�������ô��?�ѵ�Ҫ��ÿ��������Ա���伸̨��������������?

������
���ÿһ���°汾�ķ�������Ʒ�����鶼��Ҫ��������װ����ƽ̨�Ա㷢�����⣬�����籾��ǰ����������������������ƽ̨��������������࣬��ͬ���ģ�������ĵײ��Ҳ������ͬ����������ָ���������ͻ���⣬��һ����װ��ɣ��ͺ�������Linuxϵͳ�ָ���һ���dz��ɾ���״̬��ͨ��Remove��UnInstall��rpm
-e���ֶ���ʽж�أ�������Ҫ���Ѻܳ���ʱ�䣬����β��ܿ��ٵػָ�������ƽ̨��Ⱥ��ϵͳ����? 
������
��������Ա�ڲ��Դ�����ƽ̨�����з�����һ��Bug����Ҫ�����ֳ��������������صĴ�����������á�����״̬��������־������һЩ�м����ݣ����ǣ�ƽ̨��Ⱥ�������ڵ������ܶ࣬���ÿ�����̵�����Ŀ¼����־�ļ�������Խ϶�����һ�㶼��Ҫרҵ�Ŀ�������ʦ������ά����ʦ������ط������ڵ㣬���ղ�ͬ����ĸ��Ի�������Ϣ���ֹ���ʽ�ռ�����ĸ�����Ŀ��Ϣ��Ȼ�����㼯����־���ķ���������ͳһ��������Ŀǰҵ�粢û��һ���ܹ��Զ��ֲ�ʽ�ռ�������ص���־ϵͳ�������Թ�����Ҫ��������ô��? 
������
��ΰ�һ������õĴ�����ƽ̨���ٵ�Ǩ�Ƶ������ط�?
���ע�����¼��㣺
����ǹؼ�ҵ��ϵͳ�����ݲ��ܶ�;
�����Ǩ�����������������ܻỵ;
����Dz����ʵʱ����ҵ��Ҫ��֤����ƽ���л���

��ͳ���������ȱ��
��Ҫ�����Щ���⣬��һ���뵽�ķ�����Ȼ����������������߾������Ŷӣ�֮ǰҲȷʵ�õľ���������������ַ�ʽ�����������Ľ���������⣬���磺
��Ȼ�����Ҳ�������ϵͳ������Ǩ�ƣ����Ⲣ���������ó��ģ��������ܱ��ء�
������Ŀ��տ��Ա��浱ǰ��״̬����Ҫ�ָ���ȥ���͵ðѵ�ǰ�������е�������رգ����Բ����ʺ�Ƶ�����浱ǰ״̬��ҵ����
��Ȼ���Ը�ÿ���˶����伸��������ã�������һ��������ϵͳ��������Ҫ�϶����Դ���ײ�����������Դ�ܿ�ͱ������ˣ�����������ҪѰ��������ʽ���ֲ���Щ���㡣
Docker����������
Docker ��Ŀ��Ŀ����ʵ���������IJ���ϵͳ���⻯������������仰˵�������������ǰ�һ̨����������ɶ�̨��ʹ�ã������������Ա����ġ�����Ǩ�Ƶ������ط����������С�ȵȺô����ܹ��ܺý������֮ǰ���������⡣
��Ϊʲô�������������?
����˵����Ϊ�������������㣬����һ��Docker����ֻҪ�����ֵ�ʱ�䣬��һ̨�������Ͽ��Դ���������ǧ�����������������������
�������������Docker���ַ�����ʵ��ԭ���� 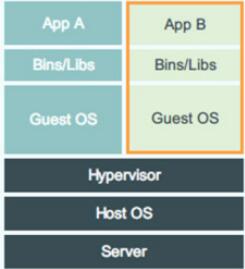
VM���ͼ
�����ʵ����Դ����ķ��������ö�����OS��������Hypervisor���⻯CPU���ڴ桢IO�豸��ʵ�ֵġ����磬Ϊ������CPU��Hypervisor��Ϊÿ�������CPU����һ�����ݽṹ��ģ��CPU��ȫ���Ĵ�����ֵ�����ʵ���ʱ����ٲ�����Щֵ����Ҫָ�������ڴ��������£����������������ֱ������Ӳ���ϵģ�������ҪHypervisor���롣ֻ����һЩȨ�ߵ������£�Guest
OS��Ҫ�����ں�̬��CPU�ļĴ������ݣ�Hypervisor����룬�IJ�ά�������CPU״̬��
Hypervisor���⻯�ڴ�ķ����Ǵ���һ��shadow page table������������£�һ��page
table��������ʵ�ִ������ڴ浽�����ڴ�ķ��롣�����⻯������£�������ν�������ڴ���Ȼ������ģ����shadow
page table��Ҫ�����������ڴ�->����������ڴ�->�����������ڴ档 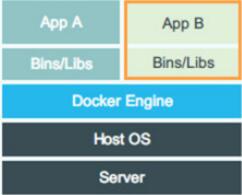
Docker���ͼ
�Ա������ʵ����Դ�ͻ�������ķ�����docker���Եü����ܶࡣdocker Engine���Լ��ɶ�Linux��NameSpace��Cgroup����������ļ�ϵͳ�����ķ�װ��docker��û�к������һ������һ����ȫ������Guest
OSʵ�ֻ������룬�����õ���ĿǰLinux�ں˱���֧�ֵ�������ʽʵ����Դ�ͻ������롣��˵��docker����namespaceʵ��ϵͳ�����ĸ���;����Cgroupʵ����Դ����;���þ���ʵ�ָ�Ŀ¼�����ĸ��롣
���½�һ������ʱ��docker����Ҫ�������һ�����¼��ز���ϵͳ�ںˡ�����֪�������������ز���ϵͳ�ں���һ���ȽϷ�ʱ����Դ�Ĺ��̣����½�һ�������ʱ�������������Ҫ����Guest
OS������½������Ƿ��Ӽ���ġ���docker����ֱ�������������IJ���ϵͳ����ʡ����������̣�����½�һ��docker����ֻ��Ҫ�����ӡ����⣬�ִ�����ϵͳ�Ǹ��ӵ�ϵͳ����һ̨��������������һ������ϵͳ����Դ�����DZȽϴ�ģ���ˣ�docker�Ա����������Դ������Ҳռ�бȽϴ�����ơ���ʵ�ϣ���һ̨�����������ǿ��Ժ��������ɰ���ǧ����������ֻ�ܽ��������������
�ɼ��������ڲ���ϵͳ������ʵ�����⻯��ֱ�Ӹ��ñ��������IJ���ϵͳ������ͳ��ʽ������Ӳ������ʵ�֡���Ȼ��һЩ��������ģ�������ڸ߰汾�ںˣ����ڲ��ְ汾�������⡣
��λ���Dockerʵ�ִ�����ƽ̨�����ݲ�������ά?
��һ�����������Docker����
��ʵ�������У�����һ���õĴ�����ƽ̨Docker������������������ǰ�Ṥ����
�˽�о���ֿ⣬����ͳһ��Ź����õľ����ļ�
�һ����װ���ֿ⣬����������Ƿ����ĸ��ְ汾�Ĵ����������װ��
���ö���������ϵ�Dcoker���������ͨ�ţ��ɲο��ٷ������ķ���
�ڶ�����Ϊ������ƽ̨���ƻ�������
1.��ȻҪ��Docker�����ڰ�װ���ǵĴ�����ƽ̨���Ǿ���Ҫһ��ͳһ��Linuxϵͳ��Ϊ���ǵ�Dcoker��������Ubuntu��CentOS�ȷ����̶��ᷢ���Լ���Docker��������Docker
Hub�ϣ����Docker Hub��ǡ��û������Ҫ�ľ���Ҳ�����Լ�������
2.������CentOS6.8��Ϊ���ǵĻ���������ô���Ȱ���pull���� 
3.Ȼ���������������һ��������������������һЩ���Ǵ�����ƽ̨�����IJ���������ntpd��httpd����ȵȣ�������������ƽ̨ר���Ļ������� 
4.���Ǻܹؼ���һ�����������Ժ�������Ա������ʱ����һ���Լ���Ҫ��Linux�����������Ա������ڽ��в�Ʒ���о���ʵ�飬��ÿ���˵Ļ���������ɣ��������ڵĻ������ƻ�����ɾ���ٴ���������һ��������һ�ͳ�����������������Ҳ��ӭ�ж��⡣
�����������Ѿ�����õļ�Ⱥ���ɾ���
���ǿ����Ѿ������˼�Ⱥ����������ɶ��־����磺ֻ������Hadoop�ļ�Ⱥ��ͬʱ����Hadoop��Zookeeper��Hbase�ļ�Ⱥ����װ����������ļ�Ⱥ�ȵȣ�Ȼ���ϴ���˽�вֿ⣬��������Ҫ��ʱ��ֱ������������Ҫ�ļ�Ⱥ�Ϳ����ˣ���Ϊ��ȥ�˲��������õȲ��裬������������˹���Ч�ʣ�Ҳ����˲�Ʒ�����ٶȡ� 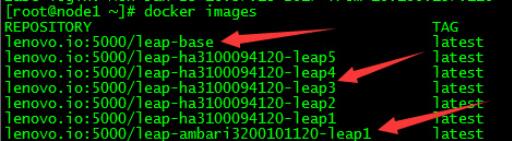
��ͼ���Ѿ����õľ���ͼ�й��������͵ľ���
��һ����ͷָ��������
�ڶ�����ͷָ�����Ѿ���װ�˴�����ƽ̨�ľ�����Ϊ�Ƿֲ�ʽ�����������
�������ǵ��ڵ��Ĵ����ݼ�Ⱥ������ֻ��һ������
���IJ�����������뱣��
Docker�ṩ��commit���ܿ��Խ�һ���������е��������������������ڲ��Թ���������һ��Bug������Ҫ�ȱ���������ִ��һ��������ɣ��磺
# docker commit container_name image:v2 |
���Ժ���Ҫ���ֵ�ʱ������������������ɣ�����������
# docker run -tid �Cname c1 image:v2 bash |
��ע�⣬����������״̬���ܱ�������������ֻ�����ļ������״̬�����ܱ����ڴ��е�״̬�������ٴ�����������ʱ�������ڵ����з����Ѿ������ֹͣ״̬����Ҫ���ֶ�����һ�Σ������͵�����Щ���͵�Bug���ܸ��֡�
������ο���ǣ�Docker�ٷ������ں���İ汾�м���checkpiont���ܣ������Ա��������е�����״̬�������Ϳ��������ظ���Bug������¹��ܵ��÷��������������� 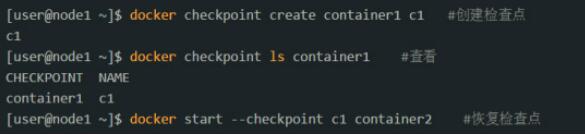
������ܶԺܶ�����˵�������Ǹ�����Ϣ!
���岽���ű������𡢼��ӡ�ɾ��
��Ȼ�ˣ�ÿ���˶���Ӧ�ðѹ���ľ���������ôʹ��Docker�������ϣ�������Ϊ�ŶӴ�������Ĺ���������İ취��Ȼ�ǰ������ظ��ԵĹ����ű�������ÿ�����ṩ�����ʹ�ýӿڣ�ֻ��Ҫһ��������Ϳ��Դ����Լ���Ҫ�ļ�Ⱥ������������Ҫ��ʱ��һ�������ɾ����������������ѧϰ�ɱ��ֽ���������������⡣
���ݱ��ߵ�ʵ�����飬�ű�����ʵ��Ӧ�����ؿ��Ǽ������棺
�������ͼ�Ⱥ�Ĵ���
��¼ÿ����Ⱥ�������ߣ�����������������������ʱ��ȵ�
��ʵʱ�鿴��������������״̬����������Դʹ�����
ɾ��ָ���ļ�Ⱥ
����
�����Ѿ��кܶԴ��Docker����������ܣ����������Ǹ��Ӷ��ģ��������������еij������������������Ĵ�����ƽ̨����ҪΪÿ���������˿�ӳ�䡢�ں�����������ľ���������������Hostname��IPӳ��ȣ���֮��Ŀǰ��Դ������ܵ������Ի��кܴ�ĸĽ��ռ䣬������һЩ�ֶ����õĹ�����
�������������ھ����ʵ�������У�һ�����������ܶ����⣬��������ֺͱ��š�������Ӧ�ò����仹�㲻���ر�ij��죬���Ѿ�ʹԭ�����������úܸ��ӵĴ�����ƽ̨��ü��٣���һ�����з��ŶӵIJ�Ʒ�����õ����١���Ȼ�������Ǵ�����ƽ̨��Ʒ������Docker��Դ���������������ڲ��ϵ������С�
|






