| 
Hive�ǻ���Hadoop�����ݲֿ�ߣ��ɶԴ洢��HDFS�ϵ��ļ��е����ݼ��������������������ѯ�ͷ����������ṩ��������SQL���ԵIJ�ѯ���ԨCHiveQL����ͨ��HQL���ʵ�ּ�MRͳ�ƣ�Hive��HQL���ת����MR�������ִ�С�
һ������
1-1 ���ݲֿ����
���ݲֿ�(Data Warehouse)��һ�����������(Subject Oriented)�����ɵ�(Integrated)������ȶ���(Non-Volatile)����Ӧ��ʷ�仯(Time
Variant)�����ݼ��ϣ�����֧�ֹ������ߡ�
���ݲֿ���ϵ�ṹͨ�����ĸ���Σ�����Դ�����ݴ洢���������ݷ�������Ӧ�á�
����Դ�������ݲֿ��������Դ�����ⲿ���ݡ�����ҵ��ϵͳ���ĵ����ϵ�;
���ݼ��ɣ�������ݵij�ȡ����ϴ��ת���ͼ�����������Դ�е����ݲ���ETL(Extract-Transform-Load)�����Թ̶������ڼ��ص����ݲֿ��С�
���ݴ洢�������˲����Ҫ�漰�����ݵĴ洢�����������ݲֿ⡢���ݼ��С����ݲֿ��⡢������ά�����ߺ�Ԫ���ݹ����ȡ�
���ݷ���Ϊǰ�˺�Ӧ���ṩ���ݷ���ֱ�Ӵ����ݲֿ��л�ȡ���ݹ�ǰ��Ӧ��ʹ�ã�Ҳ��ͨ��OLAP(OnLine
Analytical Processing��������������)������Ϊǰ��Ӧ���ṩ��������ݷ���
����Ӧ�ã��˲��ֱ�������û��������ݲ�ѯ���ߡ����ɱ������ߡ����ݷ������ߡ������ھߺ���Ӧ��ϵͳ��
1-2 ��ͳ���ݲֿ������
��������������ĺ������ݴ洢����ͳ���ݲֿ���ڹ�ϵ�����ݿ⣬������չ�Խϲ������չ���ޡ�
��������ͬ���͵����ݣ���ͳ���ݲֿ�ֻ�ܴ洢�ṹ�����ݣ���ҵҵ��չ������Դ�ĸ�ʽԽ��Խ�ḻ��
��ͳ���ݲֿ⽨���ڹ�ϵ�����ݲֿ�֮�ϣ�����ʹ����������㣬���������ﵽTB�����������úõ����ܡ�
1-3 Hive
Hive�ǽ�����Hadoop֮�ϵ����ݲֿ⣬��Facebook��������ij�̶ֳ��Ͽ��Կ������û���̽ӿڣ����������洢�ʹ������ݣ�������HDFS�洢���ݣ�����MR�������ݡ�����SQL����HiveQL������ȫ֧��SQL�����磬��֧�ָ��²������������������Ӳ�ѯ�����Ӳ���Ҳ���ںܶ����ơ�
Hive��HQL���ת����MR��������������ķ�ʽ�Ժ������ݽ��д��������ݲֿ�洢���Ǿ�̬���ݣ����ʺϲ���MR������������Hive���ṩ��һϵ�ж����ݽ�����ȡ��ת�������صĹ��ߣ����Դ洢����ѯ�ͷ����洢��HDFS�ϵ����ݡ�
1-4 Hive��Hadoop��̬ϵͳ����������Ĺ�ϵ
Hive������HDFS�洢���ݣ�����MR��������;
Pig����ΪHive��������ߣ���һ�����������Ժ����л������ʺ�������Hadoopƽ̨�ϲ�ѯ��ṹ�����ݼ���������ETL���̵�һ���֣������ⲿ����װ�ص�Hadoop��Ⱥ�У�ת��Ϊ�û���Ҫ�����ݸ�ʽ;
HBase��һ�������еġ��ֲ�ʽ�����������ݿ⣬���ṩ���ݵ�ʵʱ���ʹ��ܣ���Hiveֻ�ܴ�����̬���ݣ���Ҫ��BI�������ݣ�Hive�ij�����Ϊ���ٸ���MRӦ�ó���ı�д������HBase����Ϊ��ʵ�ֶ����ݵ�ʵʱ���ʡ�
1-5 Hive�봫ͳ���ݿ�ĶԱ�

1-6 Hive�IJ����Ӧ��
1-6-1 Hive����ҵ�����ݷ���ƽ̨�е�Ӧ��
��ǰ��ҵ�в���Ĵ����ݷ���ƽ̨����Hadoop�Ļ������HDFS��MR�⣬�����ʹ��Hive��Pig��HBase��Mahout���Ӷ����㲻ͬҵ������
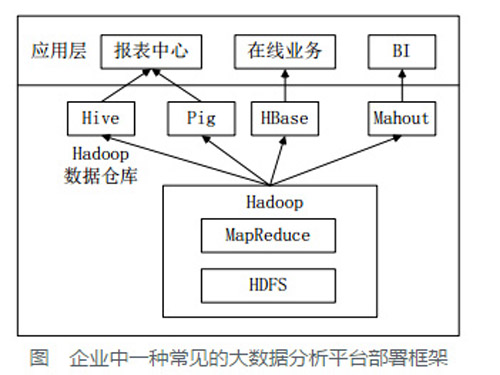
��ͼ����ҵ��һ�ֳ����Ĵ����ݷ���ƽ̨������ �������ֲ���ܹ��У�
Hive��Pig���ڱ������ģ�Hive���ڷ���������Pig���ڱ��������ݵ�ת��������
HBase��������ҵ��HDFS��֧�������д��������HBase����Ϊ�˿������ɽϺõ�֧��ʵʱ�������ݡ�
Mahout�ṩһЩ����չ�Ļ���ѧϰ����ľ����㷨ʵ�֣����ڴ�����������(BI)Ӧ�ó���
����Hiveϵͳ�ܹ�
��ͼ��ʾHive����Ҫ���ģ�顢Hive�����Hadoop�����������Լ����ⲿ����Hive�ļ��ֵ��ͷ�ʽ��
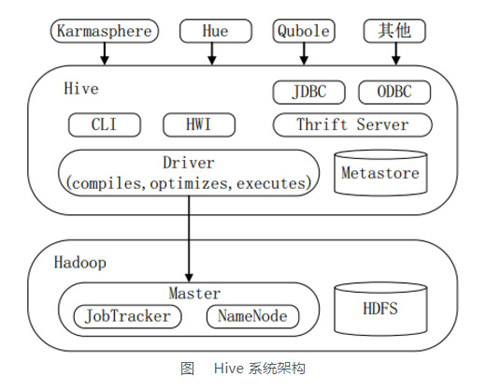
Hive��Ҫ����������ģ����ɣ�
�û��ӿ�ģ�飬��CLI��HWI��JDBC��Thrift Server�ȣ�����ʵ�ֶ�Hive�ķ��ʡ�CLI��Hive�Դ��������н���;HWI��Hive��һ������ҳ����;JDBC��ODBC�Լ�Thrift
Server�����û��ṩ���б�̵Ľӿڣ�����Thrift Server�ǻ���Thrift������ܿ����ģ��ṩHive��RPCͨ�Žӿڡ�
����ģ��(Driver)�������������Ż�����ִ�����ȣ������HiveQL���ת����һϵ��MR��ҵ����������Ͳ�ѯ�����������ģ�飬ͨ����ģ��Ľ������죬�Լ�����̽����Ż���Ȼ����ָ���IJ���ִ�С�
Ԫ���ݴ洢ģ��(Metastore)����һ�������Ĺ�ϵ�����ݿ⣬ͨ����MySQL���ݿ����Ӻ���һ��MySQLʵ����Ҳ������Hive�Դ���Derby���ݿ�ʵ������ģ����Ҫ�����ģʽ������ϵͳԪ���ݣ���������ơ������м������ԡ����ķ����������ԡ��������ԡ�������������λ����Ϣ�ȡ�
ϲ��ͼ�ν�����û����ɲ��ü��ֵ��͵��ⲿ���ʹ��ߣ�Karmasphere��Hue��Qubole�ȡ�
����Hive����ԭ��
3-1 SQL���ת����MapReduce��ҵ�Ļ���ԭ��
3-1-1 ��MapReduceʵ�����Ӳ���
��������(join)���������ֱ����û���User(uid,name)�Ͷ�����Order(uid,orderid)�������SQL���
SELECT name, orderid FROM User u JOIN
Order o ON u.uid=o.uid;
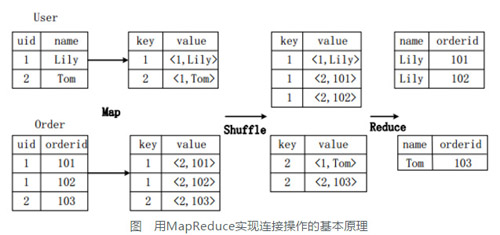
��ͼ���������Ӳ���ת��ΪMapReduce��������ľ���ִ�й��̡�
���ȣ���Map�Σ�
User����uidΪkey����name�ͱ��ı��λ(����User�ı��λ��Ϊ1)Ϊvalue������Map�������ѱ��м�¼ת������һϵ��KV�Ե���ʽ�����磬User���м�¼(1,Lily)ת��Ϊ��ֵ��(1,<1,Lily>)�����е�һ����1����uid��ֵ���ڶ�����1���DZ�User�ı��λ��������ʾ�����ֵ������User��;
ͬ����Order����uidΪkey����orderid�ͱ��ı��λ(�����Order�ı��λ��Ϊ2)Ϊֵ����Map�������ѱ��еļ�¼ת������һϵ��KV�Ե���ʽ;
���ţ���Shuffle�Σ���User����Order�����ɵ�KV����ֵ����Hash��Ȼ������Ӧ��Reduce����ִ�С�����KV��(1,<1,Lily>)��(1,<2,101>)��(1,<2,102>)���͵�ͬһ̨Reduce�����ϡ���Reduce�������յ���ЩKV��ʱ�����谴���ı��λ����Щ��ֵ�Խ����������Ż����Ӳ���;
�����Reduce�Σ���ͬһ̨Reduce�����ϵļ�ֵ�ԣ����ݡ�ֵ��(value)�еı����λ�������Ա�User��Order�����ݽ��еѿ��������Ӳ��������������յĽ���������ֵ��(1,<1,Lily>)���ֵ��(1,<2,101>)��(1,<2,102>)�����ӽ����(Lily,101)��(Lily,102)��
3-1-2 ��MRʵ�ַ������
���������Score(rank, level)������rank(����)��level(����)�������ԣ���Ҫ����һ������(Group
By)�����������ǰѱ�Score�IJ�ͬƬ�ΰ���rank��level�����ֵ���кϲ��������㲻ͬ�����ֵ�м�����¼��SQL����������£�
SELECT rank,level,count(*) as value
FROM score GROUP BY rank,level;
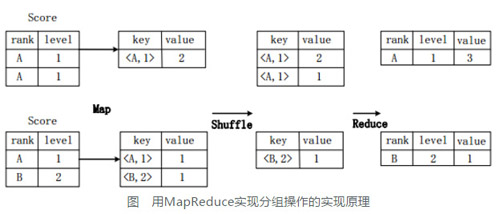
��ͼ�����������ת��ΪMapReduce����ľ���ִ�й��̡�
���ȣ���Map�Σ��Ա�Score����Map����������һϵ��KV�ԣ����Ϊ<rank, level>��ֵΪ��ӵ�и�<rank,
level>���ֵ�ļ�¼�������������磬Score���ĵ�һƬ������������¼(A,1)�����Խ���Map������ת��Ϊ��ֵ��(<A,1>,2);
������Shuffle�Σ���Score�����ɵļ�ֵ�ԣ����ա�������ֵ����Hash��Ȼ�����Hash���������Ӧ��Reduce����ȥִ�С����磬��ֵ��(<A,1>,2)��(<A,1>,1)���͵�ͬһ̨Reduce�����ϣ���ֵ��(<B,2>,1)������һReduce�����ϡ�Ȼ��Reduce�����Խ��յ�����Щ��ֵ�ԣ�����������ֵ��������;
��Reduce�Σ��Ѿ�����ͬ�������м�ֵ�Եġ�ֵ�������ۼӣ����ɷ�������ս�������磬��ͬһ̨Reduce�����ϵļ�ֵ��(<A,1>,2)��(<A,1>,1)Reduce�������������Ϊ(A,1,3)��
3-2 Hive��SQL��ѯת����MR��ҵ�Ĺ���
��Hive���յ�һ��HQL������Ҫ��Hadoop������������ɸò�����HQL���Ƚ�������ģ�飬������ģ���еı������������룬�����Ż����Ըò��������Ż����㣬Ȼ��ִ����ȥִ�С�ִ����ͨ������һ������MR������ʱҲ������(��SELECT
* FROM tb1��ȫ��ɨ�裬������ͶӰ��ѡ�����)

��ͼ��Hive��HQL���ת����MR�������ִ�е���ϸ���̡�
������ģ���еı������CAntlr����ʶ�ߣ����û������SQL�����дʷ������������HQL���ת���ɳ������(AST
Tree)����ʽ;
�������������ת����QueryBlock��ѯ��Ԫ����ΪAST�ṹ���ӣ�������ֱ�ӷ����MR�㷨��������QueryBlock��һ���������SQL���ɵ�Ԫ����������Դ��������̡���������������;
����QueryBlock������OperatorTree(������)��OperatorTree�ɺܶ�����������ɣ���TableScanOperator��SelectOperator��FilterOperator��JoinOperator��GroupByOperator��ReduceSinkOperator�ȡ���Щ������������Map��Reduce�����ijһ�ض�����;
Hive����ģ���е����Ż�����OperatorTree�����Ż����任OperatorTree����ʽ���ϲ�����IJ�����������MR���������Լ�Shuffle�ε�������;
�����Ż����OperatorTree������OperatorTree�е���������������Ҫִ�е�MR����;
����Hive����ģ���е������Ż����������ɵ�MR��������Ż����������յ�MR����ִ�мƻ�;
�����Hive����ģ���е�ִ�����������յ�MR����ִ�������
Hive����ģ���е�ִ����ִ�����յ�MR����ʱ��Hive������������MR�㷨������ͨ��һ����ʾ��Jobִ�мƻ�����XML�ļ������������õġ�ԭ����Mapper��Reducerģ�顣Hiveͨ����JobTrackerͨ������ʼ��MR��������ֱ�Ӳ�����JobTracker���ڹ����ڵ���ִ�С�ͨ���ڴ��ͼ�Ⱥ�У�����ר�ŵ����ػ�������Hive���ߣ���Щ���ػ���������Ҫ��Զ�̲��������ڵ��ϵ�JobTrackerͨ����ִ������HiveҪ�����������ļ����洢��HDFS�ϣ�HDFS�����ƽڵ�(NameNode)��������
JobTracker/TaskTracker
NameNode/DataNode
�ġ�Hive HA����ԭ��
��ʵ��Ӧ���У�HiveҲ��¶�����ȶ������⣬�ڼ���������£�����ֶ˿ڲ���Ӧ����̶�ʧ���⡣Hive
HA(High Availablity)���Խ���������⡣
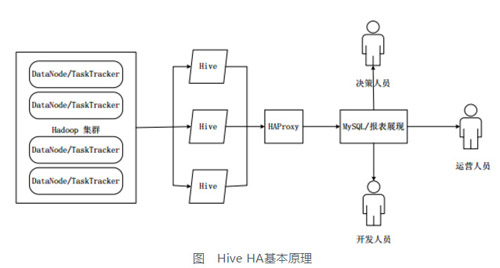
��Hive HA�У���Hadoop��Ⱥ�Ϲ��������ݲֿ����ɶ��Hiveʵ�����й����ģ���ЩHiveʵ�������뵽һ����Դ���У���HAProxy�ṩͳһ�Ķ���ӿڡ��ͻ��˵IJ�ѯ�������ȷ���HAProxy����HAProxy�Է����������ת����HAProxy�յ��������ѯ��Դ���п��õ�Hiveʵ����ִ���������Բ��ԡ�
���ij��Hiveʵ�������ã��ͻ�ѿͻ��˵ķ�������ת����Hiveʵ����;
���ij��ʵ�������ã��Ͱ������������������������Դ����ȡ����һ��Hiveʵ�������������Բ��ԡ�
���ں������е�Hive��Hive HA��ÿ��һ��ʱ�����ͳһ���������ȳ���������Hiveʵ������������ɹ������ٴΰ���������Դ���С�
����HAProxy�ṩͳһ�Ķ�����ʽӿڣ���ˣ����ڳ�����Ա��˵���ɰ�������һ̨��ǿ��Hive����
�塢Impala
5-1 Impala���
Impala��Cloudera��˾�������ṩSQL���壬�ɲ�ѯ�洢��Hadoop��HBase�ϵ�PB���������ݡ�HiveҲ�ṩSQL���壬���ײ�ִ�������Խ�����MR��ʵʱ�Բ��ã���ѯ�ӳٽϸߡ�
Impala��Ϊ��һ����Դ�����ݷ������棬�������Dremel(��Google�����Ľ���ʽ���ݷ���ϵͳ)��֧��ʵʱ���㣬�ṩ��Hive���ƵĹ��ܣ��������ϸ߳�Hive3~30����Impala���ܻᳬ��Hive��ʹ�����ܳ�ΪHadoop�������е�ʵʱ����ƽ̨��Impala���������ò��й�ϵ���ݿ����Ƶķֲ�ʽ��ѯ���棬��ֱ�Ӵ�HDFS��HBase����SQL����ѯ���ݣ������SQL���ת����MR�������ӳ٣��ɺܺõ�����ʵʱ��ѯ����
Impala�����滻Hive�����ṩһ��ͳһ��ƽ̨����ʵʱ��ѯ��Impala������������Hive��Ԫ����(Metastore)��Impala��Hive������ͬ��SQL���ODBC����������û��ӿڣ���ͳһ����Hive��Impala�ȷ������ߣ�ͬʱ֧����������ʵʱ��ѯ��
5-2 Impalaϵͳ�ܹ�
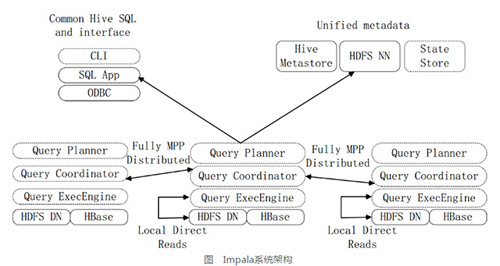
��ͼ��Impalaϵͳ�ṹͼ������ģ������Impala�����Impala��Hive��HDFS��HBaseͳһ������Hadoopƽ̨�ϡ�Impala��Impalad��State
Store��CLI��������ɡ�
Implalad����Impala��һ�����̣�����Э���ͻ����ṩ�IJ�ѯִ�У�������Impalad���������Լ��ռ�����Impalad��ִ�н�����л��ܡ�ImpaladҲ��ִ������Impalad��������������Ҫ�ǶԱ���HDFS��HBase��IJ������ݽ��в�����Impalad������Ҫ��Query
Planner��Query Coordinator��Query Exec Engine����ģ�飬��HDFS�����ݽڵ�(HDFS
DataNode)������ͬһ�ڵ��ϣ�����ȫ�ֲ�������MPP(���ģ���д���ϵͳ)�ܹ��ϡ�
State Store���ռ��ֲ��ڼ�Ⱥ�ϸ���Impalad���̵���Դ��Ϣ�����ڲ�ѯ�ĵ��ȣ����ᴴ��һ��statestored���̣������ټ�Ⱥ�е�Impalad�Ľ���״̬��λ����Ϣ��statestored����ͨ����������߳�������Impalad��ע�ᶩ���Լ�����Impalad�����������ӣ����⣬��Impalad���Ỻ��һ��State
Store�е���Ϣ����State Store���ߺ�Impaladһ������State Store��������״̬ʱ���ͻ����ָ�ģʽ�������з���ע�ᡣ��State
Store���¼��뼯Ⱥ���Զ��ָ����������»������ݡ�
CLI��CLI���û��ṩ��ִ�в�ѯ�������й��ߡ�Impala���ṩ��Hue��JDBC��ODBCʹ�ýӿڡ�
5-3 Impala��ѯִ�й���
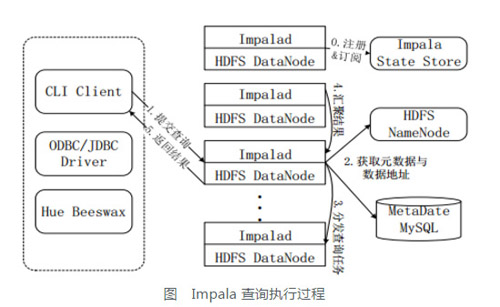
ע��Ͷ��ġ����û��ύ��ѯǰ��Impala�ȴ���һ��Impalad����������Э���ͻ����ύ�IJ�ѯ���ý��̻���State
Store�ύע�ᶩ����Ϣ��State Store�ᴴ��һ��statestored���̣�statestored����ͨ����������߳�������Impalad��ע�ᶩ����Ϣ��
�ύ��ѯ��ͨ��CLI�ύһ����ѯ��Impalad���̣�Impalad��Query Planner��SQL�����������ɽ�����;Planner���������������PlanFragment�����͵�Query
Coordinator������PlanFragment��PlanNode��ɣ��ܱ��ַ��������Ľڵ���ִ�У�ÿ��PlanNode��ʾһ����ϵ�����Ͷ���ִ���Ż���Ҫ����Ϣ��
��ȡԪ���������ݵ�ַ��Query Coordinator��MySQLԪ���ݿ��л�ȡԪ����(����ѯ��Ҫ�õ���Щ����)����HDFS�����ƽڵ��л�ȡ���ݵ�ַ(�����ݱ����浽�ĸ����ݽڵ���)���Ӷ��õ��洢�����ѯ������ݵ��������ݽڵ㡣
�ַ���ѯ����Query Coordinator��ʼ����Ӧ��Impalad�ϵ������Ѳ�ѯ�����������д洢�����ѯ������ݵ����ݽڵ㡣
��۽����Query Executorͨ����ʽ�����м����������Query Coordinator������Ը���Impalad�Ľ����
���ؽ����Query Coordinator�ѻ��ܺ�Ľ�����ظ�CLI�ͻ��ˡ�
5-4 Impala��Hive
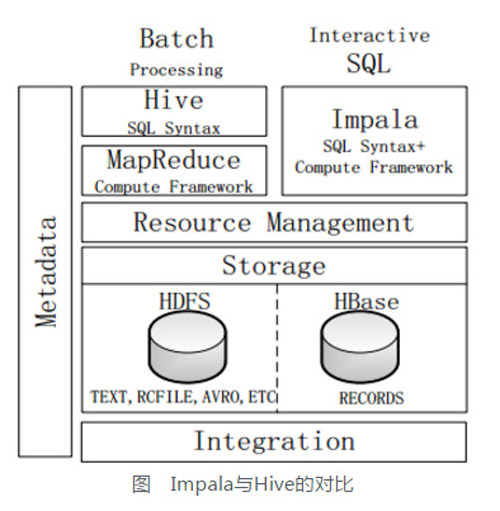
��ͬ�㣺
Hive�ʺϳ�ʱ����������ѯ����;��Impala�ʺϽ��н���ʽSQL��ѯ��
Hive������MR�����ܣ�ִ�мƻ���ϳɹܵ���MR����ģ�ͽ���ִ��;��Impala���ִ�мƻ�����Ϊһ��������ִ�мƻ������ɸ���Ȼ�طַ�ִ�мƻ�������Impaladִ�в�ѯ��
Hive��ִ�й����У����ڴ�Ų����������ݣ����ʹ����棬�Ա�֤��ѯ�ܹ�˳��ִ�����;��Impala�������ڴ�Ų�������ʱ������������棬����Impala������ѯʱ���ܵ�һ�������ơ�
��ͬ�㣺
ʹ����ͬ�Ĵ洢���ݳأ���֧�ְ����ݴ洢��HDFS��HBase�У�����HDFS֧�ִ洢TEXT��RCFILE��PARQUET��AVRO��ETC�ȸ�ʽ�����ݣ�HBase�洢���м�¼��
ʹ����ͬ��Ԫ���ݡ�
��SQL�Ľ��������Ƚ����ƣ�����ͨ���ʷ���������ִ�мƻ��� |






