| 这是机器学习和深度学习领域2016年盘点系列文章的第四篇。
第一篇介绍了该领域的重要趋势,包括有关偏见的担忧,互操作性,深度学习的爆发式增长,更加平易近人的超级计算,以及机器学习云平台的涌现。
第二篇介绍了开源机器学习项目,例如R、Python、Spark、Flink、H2O、TensorFlow等的重大进展。
第三篇介绍了在软件开发和营销方面有大笔预算,业界领先的大型科技公司在机器学习和深度学习领域的举措。
这一系列的第四篇文章,将介绍机器学习和深度学习领域的11家初创公司。在Crunchbase使用“机器学习”作为关键字可以搜索到2,264家公司,其中包括诸如MemSQL这样绝对没有提供机器学习产品,但出于营销等目的进行炒作的公司;同时也包括诸如Zebra
Medical Imaging这样的应用程序软件和服务供应商,他们在自己提供的服务中融合了机器学习功能。
本文涉及的所有公司均以软件或服务的方式为数据科学家或业务用户提供机器学习工具。这样的范畴使得这些公司的形态非常多样:
Continuum Analytics、Databricks和H2O.ai推动开源项目(分别为Anaconda、Apache
Spark,以及H2O)的发展,并为其提供商业化支持。
Alpine Data、Dataiku和Domino Data Lab为数据科学家团队提供商业化许可的协作工具,这些工具都基于开源平台。
KNIME和RapidMiner立足欧洲,培养了庞大的用群体。这两家公司都为业务用户提供了操作大数据平台的接口。
Fuzzy Logix和Skytree主要为数据科学家提供专业化的功能。
DataRobot为数据科学家和业务用户的预测分析工作提供了完全自动化的工作流,可运行在开源平台上。
有四家公司由于“多年来的不懈努力而值得一提”,但还没有深入介绍过:
两家初创公司BigML和SkyMind依然处于种子期投资阶段,下文不准备详细介绍,但他们都很值得关注。BigML是一种机器学习云服务,SkyMind主要从事DL4J开源项目在深度学习方面的发展。
另外两家并不是初创公司,他们的业务已经有超过30年的历史。Salford
Systems为CART和Random Forests开发了最初使用的软件,多年来该公司在自己的产品中逐渐融入了更多技术,已经培养出一批忠实客户。最近被戴尔放弃的Statistica提供了包含多种功能的统计学程序,在用户满意度调查中,该公司的表现非常稳定。
另外我还想在这里感谢为这一系列文章出谋划策的人:Sri Ambati、Betty Candel、Leslie
Miller、Bob Muenchen、Thomas Ott、Peter Prettenhofer、Jesus
Puente、Dan Putler、David Smith,以及Oliver Vagner。
Alpine Data
这家原名Alpine Data Labs的公司在2016年改名换帅。Alpine从品牌名中取消了“Labs”的字眼,我猜他们不希望人们误以为他们是那种检测标本的公司,所以这家公司现在叫Alpine
Data。公司前任CEO Joe Otto现在担任“顾问”,CEO一职由Dan Udoutch接任,这位“经验丰富的高管”有着超过30年的业务经验,但对机器学习或深度分析领域全无了解。该公司还在2016年换掉了自己的CFO和销售主管,也许是因为他们的投资人对Alpine的业务成果极为满意吧。
该公司最初的产品主要运行在Greenplum数据库上,并在2013年上半年将一些算法移植到MapReduce。随着Hadoop兴起,Alpine在2013年11月结束了风投轮投资,正是在那时大家开始意识到MapReduce并不适用于机器学习。该公司很快转向Spark,Databricks在2014年对Alpine的Spark技术进行了认证,随后该公司逐渐将自己的分析产品移植到其他新框架。
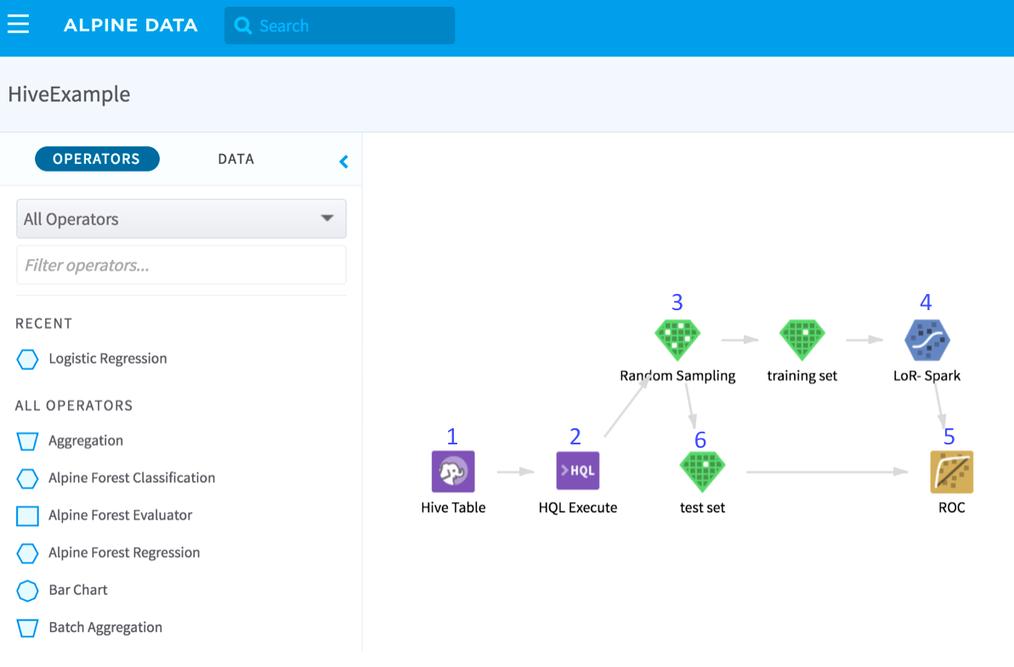
似乎针对Spark重建对Alpine来说是个苦差事,因为该公司自2013年起再没能吸引新一轮投资。作为一种“共识”,有成果的初创公司会每12-24个月获得新一轮的投资,而无法获得新一轮投资的公司主要是因为成果不够醒目。投资人并不蠢,他们更像是从不乱叫的狗,无法获得风投轮的投资对于一家公司的前景来说“别有深意”。
产品新闻方面,该公司在5月发布了一个大版本:Chorus 6,并在9月发布了Chorus
6.1。新版的改进包括:
1.与Jupyter notebooks集成。
2.更多机器学习算法。
3.Spark自动调优。Chorus可将处理任务推送至Spark,同时Alpine开发了一种可以对所生成的Spark代码进行调优的优化器。
4.PFA支持模型导出。这是一项很棒、很先进的功能。
5.运行时性能改进。
6.用户体验调整。
Alpine的工程副总裁Lawrence Spracklen将在波士顿举行的Spark
Summit East活动中介绍Spark的自动调优。
潜在用户与客户应当寻找能证明这是一家“能活下来的公司”的证明,例如新一轮投资,或能证明该公司现金流良性发展的金融审计。
Continuum Analytics
Continuum Analytics开发并支持着Anaconda,这是一种面向数据科学家的开源Python发行版。Anaconda产品的核心包括:管理应用程序、软件包、环境以及渠道的桌面GUI工具Navigator;数据科学领域广泛运用的150个Python软件包;以及有关性能的优化。Continuum还为Anaconda提供了商业化许可,借此可获得更好的缩放性、更高性能,以及更好的易用性。
Anaconda 2.5发布于2月,该版本真对Intel Math Kernel
Library进一步优化了性能。从这个版本开始,Continuum将Anaconda与Microsoft
R Open捆绑在了一起,后者是一款增强的免费R发行版。
2016年,Continuum为自己的Anaconda平台增加了两个重要的补充技术:
1.Anaconda Enterprise Notebooks,一种增强版的Jupyter
notebooks。
2.Anaconda Mosaic,一种对异构数据创建编录的工具。
该公司还公布了与Cloudera、Intel,以及IBM等合作。9月,Continuum披露了总额4百万美元的股权融资。该公司的这一轮融资非常低调,甚至没有新闻通稿,估计是因为认购不足吧。
Continuum的AnacondaCon 2017大会将于2月7-9日在奥斯丁举办。
Databricks
Databricks领导着Apache Spark的开发(已在本系列文章的第二篇进行过介绍),并提供了基于Spark的托管式云服务。该公司还提供有培训和认证,并负责组织Spark峰会。
2013年,Spark的首批开发者团队创建了Databricks。该公司员工至今依然在Apache
Spark项目中扮演了重要角色,不仅大量参与项目管理委员会的职务,而且比其他任何公司为该项目贡献了更多的代码。
2016年,Databricks在自己的核心托管服务中提供了一个仪表板工具,并为作业和群集管理工作提供了一个RESTful接口。这一年里,该公司作出的最大改进主要围绕Databricks安全框架,他们通过了企业安全领域的SOC
2 Type 1认证,同时公布了HIPAA合规认证并将该技术发布至Amazon Web Services的GovCloud,主要用来处理敏感数据和在管控方面有特殊要求的工作负载。
Databricks还提供了一个免费的社区版本,在MOOC上提供了包含五部分的免费系列课程,同时完成了Spark用户社区的年度调查,并组织了三场Spark峰会。
12月,Databricks公布了总值6千万美元的“C”轮风险投资。该轮投资由New
Enterprise Associates领导,并有Andreessen Horowitz参与。
Dataiku
Dataiku主要开发并推广Data Science Studio(DSS),这是一种适用于机器学习和高级分析的工作流和协作环境。用户可通过拖拽式界面与软件交互,DSS可将处理任务推送至Hadoop和Spark。该产品还包含到各类文件系统、SQL平台、云数据存储,以及NoSQL数据库的连接器。
2016年,Dataiku发布了3.0和3.1版产品。主要新功能包括H2O集成(通过Sparkling
Water)、支持额外的数据源(IBM Netezza、SAP HANA、Google BigQuery,以及Microsoft
Azure Data Warehouse)、增加了对Spark MLLib算法的支持、性能及其他方面的改进等。
10月,Dataiku结束了金额1400万美元的“A”轮风险投资。本次投资由FirstMark
Capital领导,并有Serena Capital参与。
DataRobot
DataRobot,这家位于波士顿的初创公司由保险行业的老手成立,所提供的自动化机器学习平台将内部经验与“测试并学习”的方法有效融为一体。通过使用开源后端,与该公司同名的软件可以通过不同算法的组合进行搜索,完成预处理、特征归纳和转换任务,并对参数进行调优,借此真对具体问题确定最适合的模型。
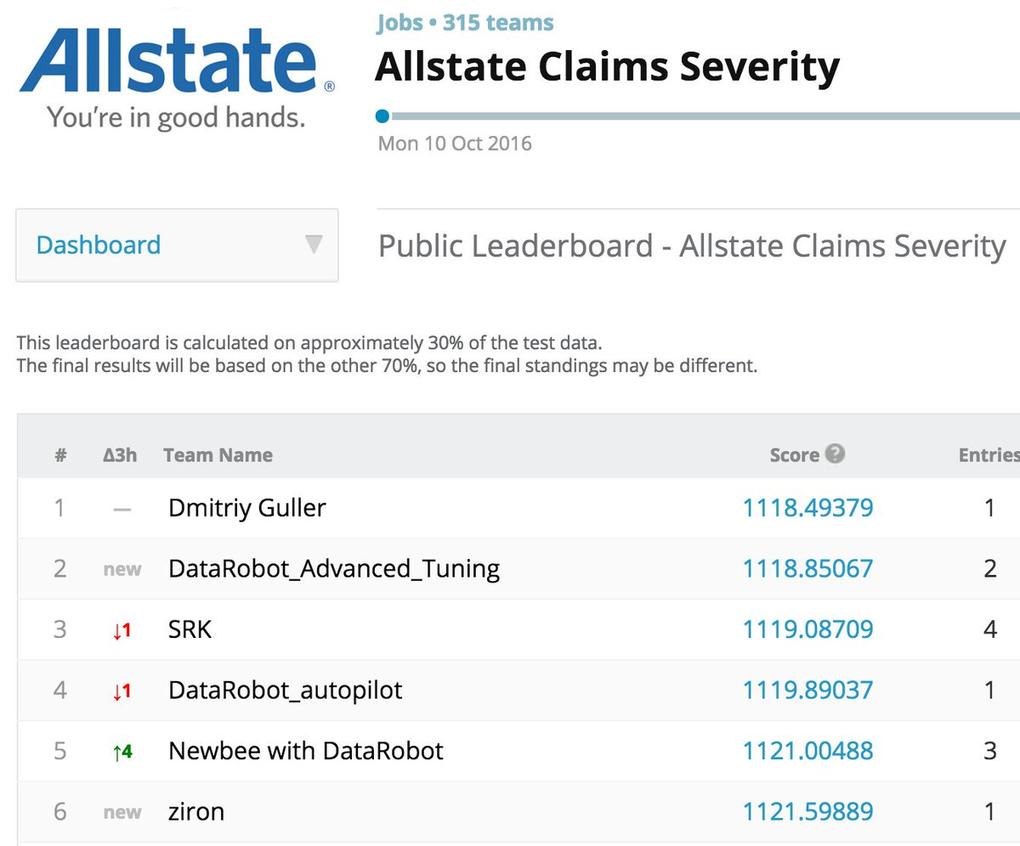
该公司的团队成员包含获奖的数据科学家Kaggle,借助此人的经验,他们可以更好地识别新出现的机器学习算法,对工程技术进行归纳,并对方法进行优化。2016年,DataRobot为自家产品增加了很多新功能,包括支持Hadoop部署,通过TensorFlow实现深度学习,能够对预测结果进行解释的推断代码,特征影响分析,以及其他模型部署功能。
DataRobot还宣布了与Alteryx和Cloudera的结盟。Cloudera为该公司颁发了顶级认证:证明该公司的软件可以集成于Spark、YARN、Cloudera
Service Descriptors以及Cloudera Parcels。
2016年上半年,DataRobot结束了3300万美元的B轮融资。New
Enterprise Associates领导此轮融资,并有Accomplice、Intel Capital、IA
Ventures、Recruit Strategic Partners,以及New York Life参与。
Domino Data Lab
Domino Data Lab提供的Domino Data Science
Platform(DDSP)是一种可以在本地、私有云,或Domino在AWS基础架构中托管的云环境中运行,可缩放的协作环境。
DDSP为数据科学家提供了共享的项目管理环境和可缩放的计算平台,可运行各类开源和商业化许可的软件,支持作业调度和追踪,并能通过Shiny和Flask发布。Domino支持回滚、修订历史、版本控制和复制功能。
11月,Domino公布已完成1050万美元的“A”轮融资,本次融资由Sequoia
Capital领导,并有Bloomberg Beta、In-Q-Tel,以及Zetta Venture
Partners参与。
Fuzzy Logix
Fuzzy Logix推广的DB Lytix是一种包含超过八百个机器学习和高级分析函数的库。这些函数可作为数据库表函数运行于关系型数据库(Informix、MySQL、Netezza、ParAccel、SQL
Server、Sybase IQ、Teradata Aster以及Teradata Database)中,并可通过Hive支持Hadoop。
用户可以通过SQL、R、或通过自定义Web接口使用BI工具调用DB Lytix函数。这些函数支持广泛的机器学习能力,包括特征工程(Feature
engineering),通过不同算法的组合对模型进行训练,以及模拟和蒙特卡洛分析。所有函数均支持原生的数据库内记分。该软件可扩展能力极高,Fuzzy
Logix还组建了由经验丰富的顾问和开发者组成的团队,进行自定义应用程序的开发工作。
4月,该公司宣布DB Lytix已经可用于Teradata Aster
Analytics,所有认为Aster从此“站立起来了”的人都对此感到激动。
H2O.ai
H2O.ai开发并支持着H2O,这个开源的机器学习项目曾在本系列文章的第二篇介绍过。正如在第二篇中所说,H2O.ai已将用于与Spark集成的Sparkling
Water更新至2.0版,并发布了模型部署框架Steam的生产用版本,同时发布了Deep Water预览版,这是一个供深度学习系统使用由GPU加速的后端所用的接口。
2016年,H2O.ai新发展了3,200家企业组织客户,以及超过43,000名用户,他们家的开源社区也扩展涵盖了全球超过8,000家企业和接近70,000名用户。针对数据科学家的年度性KDnuggets投票调查显示,该公司的产品用量已经翻了三倍。新增客户包括Kaiser
Permanente、Progressive、Comcast、HCA、McKesson、Macy’s,以及eBay。
KNIME
KNIME.com AG是一家位于瑞士苏黎世的商业化企业,该公司基于GPL许可发布KNIME
Analytics Platform,但同时允许第三方在自己的专有扩展中使用这些API。KNIME Analytics
Platform以图形化用户界面和形象化的工作流为主要特征,用户可以通过拖拽式工具构建任务管道,随后可以交互式或批处理的方式运行。
KNIME产品可通过商业化的许可获得更完善的缩放性、与更多数据平台的集成、协作,以及生产力功能。该公司还为这些扩展软件提供了技术支持。
2016年,KNIME提供了两个Dot发布和三个维护版本。在3.2和3.3版的开源版产品中增加的新功能包括:基于社区使用量统计信息进行推荐的Workflow
Coach,流式执行,特征选择,树编排和梯度提升树,DL4J深度学习,以及其他诸多改进。6月,KNIME在Microsoft
Azure上发布了KNIME Cloud Analytics Platform。
KNIME于9月在美国举办了首场峰会,并宣布将通过O’Reilly Media提供在线培训课程。
RapidMiner
位于马萨诸塞州剑桥的RapidMiner开发并支持着RapidMiner,这是一款简单易用的业务分析、预测式分析及优化软件包。该公司成立于2006年(当时名为Rapid-I),主要负责推动RapidMiner软件项目的开发、支持和推广。公司于2013年将总部搬迁至美国。
该公司软件的桌面版本名为RapidMiner Studio,分为免费版和商业化许可的版本。RapidMiner还提供了商业化许可的服务器版本以及Radoop,后者是一种扩展,可将处理任务推送至Hive、Pig、Spark和H2O。
RapidMiner在2016年公布了7.x版产品,该版本更新了用户界面。从7.0到7.3版的其他改进包括:新的数据导入功能,与Tableau的集成,并行交叉验证,以及与H2O的集成(特征深度学习、梯度提升树,以及通用的线性模型)。
该公司还提供了一个名为Single Process Pushdown的功能,该功能使得RapidMiner用户能够为RapidMiner管道提供原生的Spark和H2O算法,并通过Hadoop执行。7.3版的RapidMiner开始支持Spark
2.0。
2016年1月,RapidMiner完成了1600万美元的股权融资,本次融资由Nokia
Growth Partners领导,并有Ascent Venture Partners、Earlybird
Venture Capital、Longworth Venture Partners,以及OpenOcean参与。
Skytree
Skytree开发并推广了与公司同名的机器学习商业化许可软件包。为了将原本学术目的的机器学习项目(佐治亚理工大学的FastLab)货币化,公司创始人于2012年开始接受风投。
该公司于2013年接受1800万美元的风险投资,在这之后再没有进行融资。(这意味着什么?看看上文中我对Alpine
Data的看法吧。)更重要的是,该公司产品所用的底层算法似乎从那时起就没有进行过太多改动,不过Skytree到是陆续增加并放弃了几个加载项和外围组件。
用户可通过Skytree命令行接口(CLI)、Java和Python API,或基于浏览器的GUI用户界面与软件交互。输出结果包含以直白的英文对模型的解释。Skytree通过网格搜索(Grid
search)功能实现了参数化,并将其注册为AutoModel商标,称这是个“革命性”的功能,并试图对其申请专利。不懂网格搜索的分析师都认为这个功能很惊艳。
2016年,Skytree提供了一种基本功能免费,高级功能收费的版本,名为Skytree
Express。相信只要再坚持半年,到时候他们会付钱吸引你试用的。
与Alpine Data的情况类似,如果你喜欢Skytree的技术,请等待该公司完成下一轮融资,或让该公司提供能证明现金流一切正常的证据。 |






