| КЭаДСїГЬЯрБШЃЌHBaseЖСЪ§ОнЪЧвЛИіИќМгИДдгЕФВйзїСїГЬЃЌетжївЊЛљгкСНИіЗНУцЕФдвђЃК
ЦфвЛЪЧвђЮЊећИіHBaseДцДЂв§ЧцЛљгкLSM-LikeЪїЪЕЯжЃЌвђДЫвЛДЮЗЖЮЇВщбЏПЩФмЛсЩцМАЖрИіЗжЦЌЁЂЖрПщЛКДцЩѕжСЖрИіЪ§ОнДцДЂЮФМў;
ЦфЖўЪЧвђЮЊHBaseжаИќаТВйзївдМАЩОГ§ВйзїЪЕЯжЖМКмМђЕЅЃЌИќаТВйзїВЂУЛгаИќаТдгаЪ§ОнЃЌЖјЪЧЪЙгУЪБМфДСЪєадЪЕЯжСЫЖрАцБОЁЃ
ЩОГ§ВйзївВВЂУЛгаеце§ЩОГ§дгаЪ§ОнЃЌжЛЪЧВхШыСЫвЛЬѕДђЩЯЁБdeletedЁББъЧЉЕФЪ§ОнЃЌЖјеце§ЕФЪ§ОнЩОГ§ЗЂЩњдкЯЕЭГвьВНжДааMajor_CompactЕФЪБКђЁЃКмЯдШЛЃЌетжжЪЕЯжЬзТЗДѓДѓМђЛЏСЫЪ§ОнИќаТЁЂЩОçѿГЬЃЌЕЋЪЧЖдгкЪ§ОнЖСШЁРДЫЕШДвтЮЖзХЬзЩЯСЫВуВуМЯЫјЃЌЖСШЁЙ§ГЬашвЊИљОнАцБОНјааЙ§ТЫЃЌЭЌЪБЖдвбОБъМЧЩОГ§ЕФЪ§ОнвВвЊНјааЙ§ТЫЁЃ
змжЎЃЌАбетУДИДдгЕФЪТЧщНВУїАзВЂВЛЪЧвЛМўМђЕЅЕФЪТЧщЃЌЮЊСЫИќМгЬѕРэЛЏЕиЗжЮіећИіВщбЏЙ§ГЬЃЌНгЯТРДБЪепЛсгУСНЦЊЮФеТРДНВНтећИіЙ§ГЬЃЌЪзЦЊЮФеТжївЊЛсДгПђМмЕФНЧЖШДжСЃЖШЕиЗжЮіscanЕФећЬхСїГЬЃЌВЂВЛЛсЩцМАЬЋЖрЕФЯИНкЪЕЯжЁЃДѓЖрЪ§ПДПЭЭЈЙ§ЪзЦЊЮФеТЛљБООЭПЩвдГѕВНСЫНтscanЕФЙЄзїЫМТЗ;ЮЊСЫФмЙЛДгЯИНкРэЧхГўећИіscanСїГЬЃЌНгзХЕкЖўЦЊЮФеТНЋЛсдкЕквЛЦЊЕФЛљДЁЩЯв§ШыИќЖрЕФЪЕЯжЯИНквдМАHBaseЖдгкscanЫљзіЕФЛљДЁгХЛЏЁЃвђЮЊРэНтЮЪЬтПЩФмЛсгачЂТЉЃЌЯЃЭћПЩвдвЛЦ№ЬНЬжНЛСїЃЌЛЖгХФзЉ~
Client-ServerНЛЛЅТпМ
дЫЮЌПЊЗЂСЫКмГЄвЛЖЮЪБМфHBaseЃЌОГЃгавЕЮёЭЌбЇзЩбЏЮЊЪВУДПЭЛЇЖЫХфжУЮФМўжаУЛгаХфжУRegionServerЕФЕижЗаХЯЂЃЌетРяеыЖдетжжвЩЮЪМђЕЅЕФзіЯТНтЪЭЃЌПЭЛЇЖЫгыHBaseЯЕЭГЕФНЛЛЅНзЖЮжївЊгаШчЯТМИИіВНжшЃК
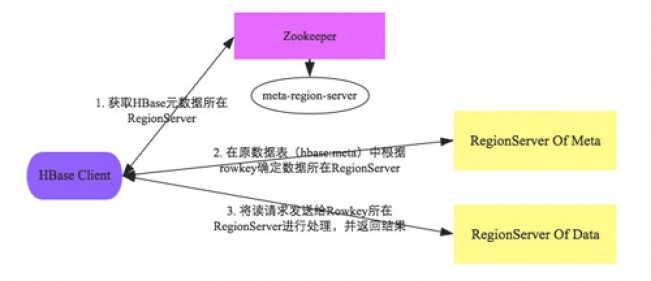
ПЭЛЇЖЫЪзЯШЛсИљОнХфжУЮФМўжаzookeeperЕижЗСЌНгzookeeperЃЌВЂЖСШЁ//meta-region-serverНкЕуаХЯЂЃЌИУНкЕуаХЯЂДцДЂHBaseдЊЪ§Он(hbase:meta)БэЫљдкЕФRegionServerЕижЗвдМАЗУЮЪЖЫПкЕШаХЯЂЁЃгУЛЇПЩвдЭЈЙ§zookeeperУќСю(get
//meta-region-server)ВщПДИУНкЕуаХЯЂЁЃ
ИљОнhbase:metaЫљдкRegionServerЕФЗУЮЪаХЯЂЃЌПЭЛЇЖЫЛсНЋИУдЊЪ§ОнБэМгдиЕНБОЕиВЂНјааЛКДцЁЃШЛКѓдкБэжаШЗЖЈД§МьЫїrowkeyЫљдкЕФRegionServerаХЯЂЁЃ
ИљОнЪ§ОнЫљдкRegionServerЕФЗУЮЪаХЯЂЃЌПЭЛЇЖЫЛсЯђИУRegionServerЗЂЫЭеце§ЕФЪ§ОнЖСШЁЧыЧѓЁЃЗўЮёЦїЖЫНгЪеЕНИУЧыЧѓжЎКѓашвЊНјааИДдгЕФДІРэЃЌОпЬхЕФДІРэСїГЬНЋЛсЪЧетИізЈЬтЕФжиЕуЁЃ
ЭЈЙ§ЩЯЪіЖдПЭЛЇЖЫвдМАHBaseЯЕЭГЕФНЛЛЅЗжЮіЃЌПЩвдЛљБОУїШЗСНЕуЃК
ПЭЛЇЖЫжЛашвЊХфжУzookeeperЕФЗУЮЪЕижЗвдМАИљФПТМЃЌОЭПЩвдНјаае§ГЃЕФЖСаДЧыЧѓЁЃВЛашвЊХфжУМЏШКЕФRegionServerЕижЗСаБэЁЃ
ПЭЛЇЖЫЛсНЋhbase:metaдЊЪ§ОнБэЛКДцдкБОЕиЃЌвђДЫЩЯЪіВНжшжаЧАСНВНжЛЛсдкПЭЛЇЖЫЕквЛДЮЧыЧѓЕФЪБКђЗЂЩњЃЌжЎКѓЫљгаЧыЧѓЖМжБНгДгЛКДцжаМгдидЊЪ§ОнЁЃШчЙћМЏШКЗЂЩњФГаЉБфЛЏЕМжТhbase:metaдЊЪ§ОнИќИФЃЌПЭЛЇЖЫдйИљОнБОЕидЊЪ§ОнБэЧыЧѓЕФЪБКђОЭЛсЗЂЩњвьГЃЃЌДЫЪБПЭЛЇЖЫашвЊжиаТМгдивЛЗнзюаТЕФдЊЪ§ОнБэЕНБОЕиЁЃ
RegionServerНгЪеЕНПЭЛЇЖЫЕФget/scanЧыЧѓжЎКѓЃЌЯШКѓзіСЫСНМўЪТЧщЃКЙЙНЈscannerЬхЯЕ(ЪЕМЪЩЯОЭЪЧзівЛаЉscanЧАЕФзМБИЙЄзї)ЃЌдкДЫЬхЯЕЛљДЁЩЯвЛаавЛааМьЫїЁЃОйИіВЛЬЋКЯЪЪЕЋвзгкРэНтЕФР§згЃЌscanЪ§ОнОЭКЭПЊЗЂЩЬИЧЗПвЛбљЃЌвВЪЧЗжГЩСНВНЃКзщНЈЪЉЙЄЖгЬхЯЕЃЌУїШЗУПИіЙЄШЫЕФжАд№;вЛВувЛВуИЧТЅЁЃ
ЙЙНЈscannerЬхЯЕ-зщНЈЪЉЙЄЖг
scannerЬхЯЕЕФКЫаФдкгкШ§ВуscannerЃКRegionScannerЁЂStoreScannerвдМАStoreFileScannerЁЃШ§епЪЧВуМЖЕФЙиЯЕЃЌвЛИіRegionScannerгЩЖрИіStoreScannerЙЙГЩЃЌвЛеХБэгЩЖрИіСазхзщГЩЃЌОЭгаЖрЩйИіStoreScannerИКд№ИУСазхЕФЪ§ОнЩЈУшЁЃвЛИіStoreScannerгжЪЧгЩЖрИіStoreFileScannerзщГЩЁЃУПИіStoreЕФЪ§ОнгЩФкДцжаЕФMemStoreКЭДХХЬЩЯЕФStoreFileЮФМўзщГЩЃЌЯрЖдгІЕФЃЌStoreScannerЖдЯѓЛсЙЭгЖвЛИіMemStoreScannerКЭNИіStoreFileScannerРДНјааЪЕМЪЕФЪ§ОнЖСШЁЃЌУПИіStoreFileЮФМўЖдгІвЛИіStoreFileScannerЃЌзЂвтЃКStoreFileScannerКЭMemstoreScannerЪЧећИіscanЕФзюжежДааепЁЃ
ЖдгІгкНЈТЅЯюФПЃЌвЛЖАТЅЭЈГЃгЩКУМИИіЕЅдЊТЅЙЙГЩ(УПИіЕЅдЊТЅЖдгІгквЛИіStore)ЃЌУПИіЕЅдЊТЅЛсЧывЛИіМрЙЄ(StoreScanner)ИКд№ИУЕЅдЊТЅЕФНЈдьЁЃЖјМрЙЄвЛАуВЛзіОпЬхЕФЪТЧщЃЌЫћИКд№еаФМКмЖрЙЄШЫ(StoreFileScanner)ЃЌетаЉЙЄШЫВХЪЧНЈТЅЕФжїЬхЁЃЯТЭМЪЧећИіЙЙНЈСїГЬЭМЃК
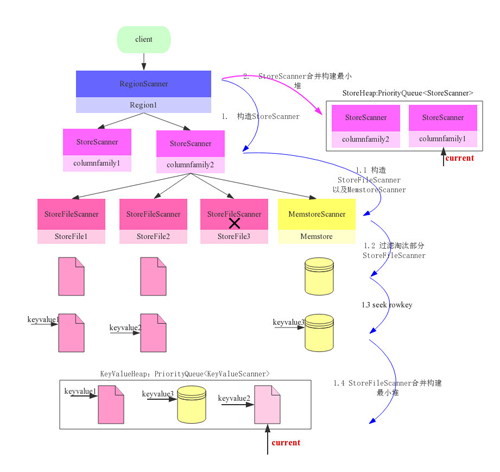
RegionScannerЛсИљОнСазхЙЙНЈStoreScannerЃЌгаЖрЩйСазхОЭЙЙНЈЖрЩйStoreScannerЃЌгУгкИКд№ИУСазхЕФЪ§ОнМьЫї
1.1 ЙЙНЈStoreFileScannerЃКУПИіStoreScannerЛсЮЊЕБЧАИУStoreжаУПИіHFileЙЙдьвЛИіStoreFileScannerЃЌгУгкЪЕМЪжДааЖдгІЮФМўЕФМьЫїЁЃЭЌЪБЛсЮЊЖдгІMemstoreЙЙдьвЛИіMemstoreScannerЃЌгУгкжДааИУStoreжаMemstoreЕФЪ§ОнМьЫїЁЃИУВНжшЖдгІгкМрЙЄдкШЫВХЪаГЁеаФМНЈТЅЫљашЕФИїжжРраЭЙЄНГЁЃ
1.2 Й§ТЫЬдЬStoreFileScannerЃКИљОнTime RangeвдМАRowKey
RangeЖдStoreFileScannerвдМАMemstoreScannerНјааЙ§ТЫЃЌЬдЬПЯЖЈВЛДцдкД§МьЫїНсЙћЕФScannerЁЃЩЯЭМжаStoreFile3вђЮЊМьВщRowKeyRangeВЛДцдкД§МьЫїRowkeyЫљвдБЛЬдЬЁЃИУВНжшеыЖдОпЬхЕФНЈТЅЗНАИЃЌВУГЗЕєВПЗжВЛашвЊЕФЙЄНГЃЌБШШчетЖАТЅВЛашвЊЕиХЏАВзАЃЌЖдгІЕФЙЄНГОЭПЩвдГЗЕєЁЃ
1.3 Seek rowkeyЃКЫљгаStoreFileScannerПЊЪМзізМБИЙЄзїЃЌдкИКд№ЕФHFileжаЖЈЮЛЕНТњзуЬѕМўЕФЦ№ЪМRowЁЃЙЄНГвВПЊЪМзМБИздМКЕФНЈдьЙЄОпЃЌНЈдьВФСЯЃЌевЕНздМКЕФЙЄзїЕиЕуЃЌЕШД§вЛЩљУќЯТЁЃОЭЯёЫљгаживЊЯюФПЕФзМБИЙЄзїЖМКмКЫаФвЛбљЃЌSeekЙ§ГЬ(ДЫДІТдЙ§Lazy
SeekгХЛЏ)вВЪЧвЛИіКмКЫаФЕФВНжшЃЌЫќжївЊАќКЌЯТУцШ§ВНЃК
ЖЈЮЛBlock OffsetЃКдкBlockcacheжаЖСШЁИУHFileЕФЫїв§ЪїНсЙЙЃЌИљОнЫїв§ЪїМьЫїЖдгІRowKeyЫљдкЕФBlock
OffsetКЭBlock Size
Load BlockЃКИљОнBlockOffsetЪзЯШдкBlockCacheжаВщевData
BlockЃЌШчЙћВЛдкЛКДцЃЌдйдкHFileжаМгди
Seek KeyЃКдкData BlockФкВПЭЈЙ§ЖўЗжВщевЕФЗНЪНЖЈЮЛОпЬхЕФRowKey
ећЬхСїГЬЯИНкВЮМћЁЖHBaseдРэ-ЬНЫїHFileЫїв§ЛњжЦЁЗЃЌЮФжаЯъЯИЫЕУїСЫHFileЫїв§НсЙЙвдМАШчКЮЭЈЙ§Ыїв§НсЙЙЖЈЮЛОпЬхЕФBlockвдМАRowKey
1.4 StoreFileScannerКЯВЂЙЙНЈзюаЁЖбЃКНЋИУStoreжаЫљгаStoreFileScannerКЭMemstoreScannerКЯВЂаЮГЩвЛИіheap(зюаЁЖб)ЃЌЫљЮНheapЪЧвЛИігХЯШМЖЖгСаЃЌЖгСажадЊЫиЪЧЫљгаscannerЃЌХХађЙцдђАДееscanner
seekЕНЕФkeyvalueДѓаЁгЩаЁЕНДѓНјааХХађЁЃетРяашвЊжиЕуЙизЂШ§ИіЮЪЬтЃЌЪзЯШЮЊЪВУДетаЉScannerашвЊгЩаЁЕНДѓХХађЃЌЦфДЮkeyvalueЪЧЪВУДбљЕФНсЙЙЃЌзюКѓЃЌkeyvalueЫДѓЫаЁЪЧШчКЮШЗЖЈЕФЃК
ЮЊЪВУДетаЉScannerашвЊгЩаЁЕНДѓХХађ?
зюжБНгЕФНтЪЭЪЧscanЕФНсЙћашвЊгЩаЁЕНДѓЪфГіИјгУЛЇЃЌЕБШЛЃЌетВЂВЛШЋУцЃЌзюКЯРэЕФНтЪЭЪЧжЛгагЩаЁЕНДѓХХађВХФмЪЙЕУscanаЇТЪзюИпЁЃОйИіМђЕЅЕФР§згЃЌHBaseжЇГжЪ§ОнЖрАцБОЃЌМйЩшгУЛЇжЛЯыЛёШЁзюаТАцБОЃЌФЧжЛашвЊНЋетаЉЪ§ОнгЩзюаТЕНзюОЩНјааХХађЃЌШЛКѓШЁЖгЪздЊЫиЗЕЛиОЭПЩвдЁЃФЧУДЃЌШчЙћВЛХХађЃЌОЭжЛФмБщРњЫљгадЊЫиЃЌВщПДЗћВЛЗћКЯгУЛЇВщбЏЬѕМўЁЃетОЭЪЧХХЖгЕФвтвхЁЃ
ЙЄНГУЧвВашвЊХХађЃЌЯШзіЕиАхЕФХХЧАУцЃЌзіЧНЬхЕФДЮжЎЃЌзюКѓЪЧзіУХДАЛЇЕФЁЃзіЧНЬхЕФФкВПЛЙашвЊдйХХађЃЌзіФкЧНЕФХХЧАУцЃЌзіЭтЧНЕФХХКѓУцЃЌетбљЃЌМйШчЩшМЦЪІСйЪБОіЖЈВЛзіЭтЧНЕФЛАЃЌОЭПЩвджБНгЬјЙ§ЭтЧНВПЗжЙЄзїЁЃКмЯдШЛЃЌШчЙћВЛХХађЕФЛАЃЌЪЧУЛАьЗЈСйЪБзіОіЖЈЕФЃЌвђЮЊетВПЗжЙЄзївбОПЩФмзіЕєСЫЁЃ
HBaseжаKeyValueЪЧЪВУДбљЕФНсЙЙ?
HBaseжаKeyValueВЂВЛЪЧМђЕЅЕФKVЪ§ОнЖдЃЌЖјЪЧвЛИіОпгаИДдгдЊЫиЕФНсЙЙЬхЃЌЦфжаKeyгЩRowKeyЃЌColumnFamilyЃЌQualifier
ЃЌTimeStampЃЌKeyTypeЕШЖрВПЗжзщГЩЃЌValueЪЧвЛИіМђЕЅЕФЖўНјжЦЪ§ОнЁЃKeyжадЊЫиKeyTypeБэЪОИУKeyValueЕФРраЭЃЌШЁжЕЗжБ№ЮЊPut/Delete/Delete
Column/Delete FamilyЫФжжЁЃKeyValueПЩвдБэЪОЮЊШчЯТЭМЫљЪОЃК
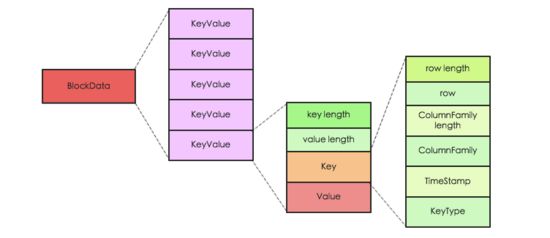
СЫНтСЫKeyValueЕФТпМНсЙЙКѓЃЌЮвУЧВЛЗСдйНјвЛВНДгдРэЕФНЧЖШЯыЯыHBaseЕФПЊЗЂепУЧЮЊЪВУДШчДЫЖдЦфЩшМЦЁЃетИіОЭЕУДгHBaseЫљжЇГжЕФЪ§ОнВйзїЫЕЦ№СЫЃЌHBaseжЇГжЫФжжжївЊЕФЪ§ОнВйзїЃЌЗжБ№ЪЧGet/Scan/Put/DeleteЃЌЦфжаGetКЭScanДњБэЪ§ОнВщбЏЃЌPutВйзїДњБэЪ§ОнВхШыЛђИќаТ(ШчЙћPutЕФRowKeyВЛДцдкдђЮЊВхШыВйзїЁЂЗёдђЮЊИќаТВйзї)ЃЌЬиБ№ашвЊзЂвтЕФЪЧHBaseжаИќаТВйзїВЂВЛЪЧжБНгИВИЧаоИФдЪ§ОнЃЌЖјЪЧЩњГЩаТЕФЪ§ОнЃЌаТЪ§ОнКЭдЪ§ОнОпгаВЛЭЌЕФАцБО(ЪБМфДС);DeleteВйзїжДааЪ§ОнЩОГ§ЃЌКЭЪ§ОнИќаТВйзїЯрЭЌЃЌHBaseжДааЪ§ОнЩОç€ВЛЛсТэЩЯНЋЪ§ОнДгЪ§ОнПтжагРОУЩОГ§ЃЌЖјжЛЪЧЩњГЩвЛЬѕЩОГ§МЧТМЃЌзюКѓдкЯЕЭГжДааЮФМўКЯВЂЕФЪБКђдйЭГвЛЩОГ§ЁЃ
HBaseжаИќаТЩОГ§ВйзїВЂВЛжБНгВйзїдЪ§ОнЃЌЖјЪЧЩњГЩвЛИіаТМЭТМЃЌФЧЮЪЬтРДСЫЃЌШчКЮжЊЕРвЛЬѕМЧТМЕНЕзЪЧВхШыВйзїЛЙЪЧИќаТВйзїврЛђЪЧЩОГ§ВйзїФи?ете§ЪЧKeyTypeКЭTimestampЕФгУЮфжЎЕиЁЃЩЯЮФжаЬсЕНKeyTypeШЁжЕЮЊЗжБ№ЮЊPut/Delete/Delete
Column/Delete FamilyЫФжжЃЌШчЙћKeyTypeШЁжЕЮЊPutЃЌБэЪОИУЬѕМЧТМЮЊВхШыЛђепИќаТВйзїЃЌЖјЮоТлЪЧВхШыЛђепИќаТЃЌЖМПЩвдЪЙгУАцБОКХ(Timestamp)ЖдМЧТМНјаабЁдё;ШчЙћKeyTypeЮЊDeleteЃЌБэЪОИУЬѕМЧТМЮЊећааЩОГ§Вйзї;ЯргІЕФKeyTypeЮЊDelete
ColumnКЭDelete FamilyЗжБ№БэЪОЩОГ§ФГааФГСавдМАФГааФГСазхВйзї;
ВЛЭЌKeyValueжЎМфШчКЮНјааДѓаЁБШНЯ?
ЩЯЮФЬсЕНKeyValueжаKeyгЩRowKeyЃЌColumnFamilyЃЌQualifier
ЃЌTimeStampЃЌKeyTypeЕШ5ВПЗжзщГЩЃЌHBaseЩшЖЈKeyДѓаЁЪзЯШБШНЯRowKeyЃЌRowKeyдНаЁKeyОЭдНаЁ;RowKeyШчЙћЯрЭЌОЭПДCFЃЌCFдНаЁKeyдНаЁ;CFШчЙћЯрЭЌПДQualifierЃЌQualifierдНаЁKeyдНаЁ;QualifierШчЙћЯрЭЌдйПДTimestampЃЌTimestampдНДѓБэЪОЪБМфдНаТЃЌЖдгІЕФKeyдНаЁЁЃШчЙћTimestampЛЙЯрЭЌЃЌОЭПДKeyTypeЃЌKeyTypeАДееDeleteFamily
-> DeleteColumn -> Delete -> Put ЫГађвРДЮЖдгІЕФKeyдНРДдНДѓЁЃ
2. StoreScannerКЯВЂЙЙНЈзюаЁЖбЃКЩЯЮФЬжТлЕФЪЧвЛИіМрЙЄШчКЮЙЙНЈздМКЕФЙЄНГЪІЭХЖгвдМАЙЄНГЪІШчКЮзізМБИЙЄзїЁЂХХађЙЄзїЁЃЪЕМЪЩЯЃЌМрЙЄвВашвЊНјааХХађЃЌБШШчвЛЕЅдЊЕФМрЙЄХХЧАУцЃЌЖўЕЅдЊЕФМрЙЄХХжЎКѓЁ
StoreScannerвЛбљЃЌСазхаЁЕФStoreScannerХХЧАУцЃЌСазхДѓЕФStoreScannerХХКѓУцЁЃ
scanВщбЏ-ВуВуНЈТЅ
ЙЙНЈScannerЬхЯЕЪЧЮЊСЫИќКУЕижДааscanВщбЏЃЌОЭЯёзщНЈЙЄНГЪІЭХЖгОЭЪЧЮЊСЫИЧЗПзгвЛбљЁЃscanВщбЏзмЪЧвЛаавЛааВщбЏЕФЃЌЯШВщЕквЛааЕФЫљгаЪ§ОнЃЌдйВщЕкЖўааЕФЫљгаЪ§ОнЃЌЕЋУПвЛааЕФВщбЏСїГЬШДУЛгаЪВУДБОжЪЧјБ№ЁЃИЧЗПзгвВвЛбљЃЌЮоТлЪЧИЧ8ВуЛЙЪЧИЧ18ВуЃЌЖМашвЊвЛВувЛВуЭљЩЯИЧЃЌЖјЧвУПвЛВуЕФИЧЗЈВЂУЛгаЪВУДЧјБ№ЁЃЫљвдЪЕМЪЩЯЮвУЧжЛашвЊЙизЂЦфжавЛааЪ§ОнЪЧШчКЮВщбЏЕФОЭПЩвдЁЃ
ЖдгквЛааЪ§ОнЕФВщбЏЃЌгжПЩвдЗжНтЮЊЖрИіСазхЕФВщбЏЃЌБШШчRowKey=row1ЕФвЛааЪ§ОнВщбЏЃЌЪзЯШВщбЏСазх1ЩЯИУааЕФЪ§ОнМЏКЯЃЌдйВщбЏСазх2РяИУааЕФЪ§ОнМЏКЯЁЃЭЌбљЪЧИЧЕквЛВуЗПзгЃЌЯШИЧвЛЕЅдЊЕФвЛВуЃЌдйИФЖўЕЅдЊЕФвЛВуЃЌИЧЭъжЎКѓВХЫувЛВуИЧЭъЃЌНгзХПЊЪМИЧЕкЖўВуЁЃЫљвдЮвУЧвВжЛашвЊЙизЂФГвЛааФГИіСазхЕФЪ§ОнЪЧШчКЮВщбЏЕФОЭПЩвдЁЃ
ЛЙМЧЕУScannerЬхЯЕЙЙНЈЕФзюжеНсЙћЪЧвЛИігЩStoreFileScannerКЭMemstoreScannerзщГЩЕФheap(зюаЁЖб)УДЃЌетРяОЭХЩЩЯгУГЁСЫЁЃЯТЭМЪЧвЛеХБэЕФТпМЪгЭМЃЌИУБэгаСНИіСазхcf1КЭcf2(ЮвУЧжЛЙизЂcf1)ЃЌcf1жЛгавЛИіСаnameЃЌБэжага5ааЪ§ОнЃЌЦфжаУПИіcellЛљБОЖМгаЖрИіАцБОЁЃcf1ЕФЪ§ОнМйШчЪЕМЪДцДЂдкШ§ИіЧјгђЃЌmemstoreжагаr2КЭr4ЕФзюаТЪ§ОнЃЌhfile1жаЪЧзюдчЕФЪ§ОнЁЃЯждкашвЊВщбЏRowKey=r2ЕФЪ§ОнЃЌАДееЩЯЮФЕФРэТлЖдгІЕФScannerжИЯђОЭШчЭМЫљЪОЃК
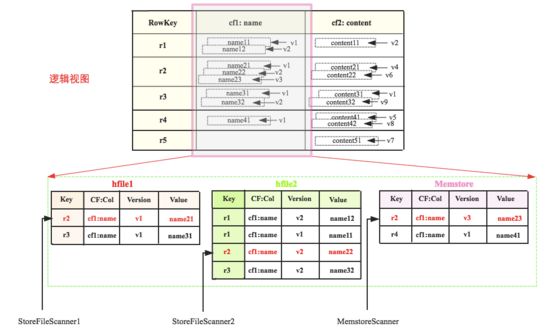
етШ§ИіScannerзщГЩЕФheapЮЊЃЌScannerгЩаЁЕНДѓХХСаЁЃВщбЏЕФЪБКђЪзЯШpopГіheapЕФЖбЖЅдЊЫиЃЌМДMemstoreScannerЃЌЕУЕНkeyvalue
= r2:cf1:name:v3:name23ЕФЪ§ОнЃЌФУЕНетИіkeyvalueжЎКѓЃЌашвЊНјааШчЯТХаЖЈЃК
МьВщИУKeyValueЕФKeyTypeЪЧЗёЪЧDeleted/DeletedColЕШЃЌШчЙћЪЧОЭжБНгКіТдИУСаЫљгаЦфЫћАцБОЃЌЬјЕНЯТСа(Сазх)
МьВщИУKeyValueЕФTimestampЪЧЗёдкгУЛЇЩшЖЈЕФTimestamp
RangeЗЖЮЇЃЌШчЙћВЛдкИУЗЖЮЇЃЌКіТд
МьВщИУKeyValueЪЧЗёТњзугУЛЇЩшжУЕФИїжжfilterЙ§ТЫЦїЃЌШчЙћВЛТњзуЃЌКіТд
МьВщИУKeyValueЪЧЗёТњзугУЛЇВщбЏжаЩшЖЈЕФАцБОЪ§ЃЌБШШчгУЛЇжЛВщбЏзюаТАцБОЃЌдђКіТдИУcellЕФЦфЫћАцБО;ЗДе§ШчЙћгУЛЇВщбЏЫљгаАцБОЃЌдђЛЙашвЊВщбЏИУcellЕФЦфЫћАцБОЁЃ
ЯждкМйЩшгУЛЇВщбЏЫљгаАцБОЖјЧвИУkeyvalueМьВщЭЈЙ§ЃЌДЫЪБЕБЧАЕФЖбЖЅдЊЫиашвЊжДааnextЗНЗЈШЅМьЫїЯТвЛИіжЕЃЌВЂжиаТзщжЏзюаЁЖбЁЃМДЭМжаMemstoreScannerНЋЛсжИЯђr4ЃЌжиаТзщжЏзюаЁЖбжЎКѓзюаЁЖбНЋЛсБфЮЊЃЌЖбЖЅдЊЫиБфЮЊStoreFileScanner2ЃЌЕУЕНkeyvalue=r2:cf1:name:v2:name22ЃЌНјаавЛЯЕСаХаЖЈЃЌдйnextЃЌдйжиаТзщжЏзюаЁЖбЁ
|









