| 基本概念
Spark是一个分布式的内存计算框架,其特点是能处理大规模数据,计算速度快。Spark延续了Hadoop的MapReduce计算模型,相比之下Spark的计算过程保持在内存中,减少了硬盘读写,能够将多个操作进行合并后计算,因此提升了计算速度。同时Spark也提供了更丰富的计算API。
MapReduce是Hadoop和Spark的计算模型,其特点是Map和Reduce过程高度可并行化;过程间耦合度低,单个过程的失败后可以重新计算,而不会导致整体失败;最重要的是数据处理中的计算逻辑可以很好的转换为Map和Reduce操作。对于一个数据集来说,Map对每条数据做相同的转换操作,Reduce可以按条件对数据分组,然后在分组上做操作。除了Map和Reduce操作之外,Spark还延伸出了如filter,flatMap,count,distinct等更丰富的操作。
RDD的是Spark中最主要的数据结构,可以直观的认为RDD就是要处理的数据集。RDD是分布式的数据集,每个RDD都支持MapReduce类操作,经过MapReduce操作后会产生新的RDD,而不会修改原有RDD。RDD的数据集是分区的,因此可以把每个数据分区放到不同的分区上进行计算,而实际上大多数MapReduce操作都是在分区上进行计算的。Spark不会把每一个MapReduce操作都发起运算,而是尽量的把操作累计起来一起计算。Spark把操作划分为转换(transformation)和动作(action),对RDD进行的转换操作会叠加起来,直到对RDD进行动作操作时才会发起计算。这种特性也使Spark可以减少中间结果的吞吐,可以快速的进行多次迭代计算。
系统结构
Spark自身只对计算负责,其计算资源的管理和调度由第三方框架来实现。常用的框架有YARN和Mesos。本文以YARN为例进行介绍。先看一下Spark
on YARN的系统结构图:
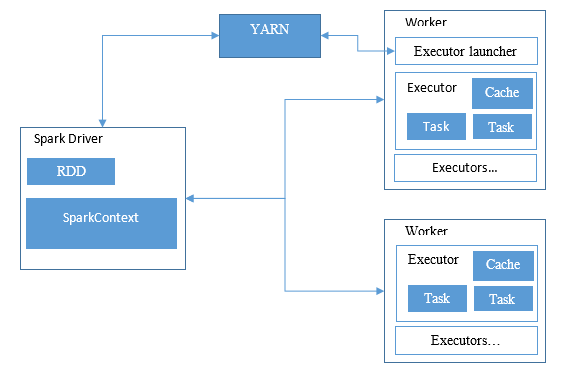
Spark on YARN系统结构图
图中共分为三大部分:Spark Driver, Worker, Cluster manager。其中Driver
program负责将RDD转换为任务,并进行任务调度。Worker负责任务的执行。YARN负责计算资源的维护和分配。
Driver可以运行在用户程序中,或者运行在其中一个Worker上。Spark中的每一个应用(Application)对应着一个Driver。这个Driver可以接收RDD上的计算请求,每个动作(Action)类型的操作将被作为一个Job进行计算。Spark会根据RDD的依赖关系构建计算阶段(Stage)的有向无环图,每个阶段有与分区数相同的任务(Task)。这些任务将在每个分区(Partition)上进行计算,任务划分完成后Driver将任务提交到运行于Worker上的Executor中进行计算,并对任务的成功、失败进行记录和重启等处理。
Worker一般对应一台物理机,每个Worker上可以运行多个Executor,每个Executor都是独立的JVM进程,Driver提交的任务就是以线程的形式运行在Executor中的。如果使用YARN作为资源调度框架的话,其中一个Worker上还会有Executor
launcher作为YARN的ApplicationMaster,用于向YARN申请计算资源,并启动、监测、重启Executor。
计算过程
这里我们从RDD到输出结果的整个计算过程为主线,探究Spark的计算过程。这个计算过程可以分为:
RDD构建:构建RDD之间的依赖关系,将RDD转换为阶段的有向无环图。
任务调度:根据空闲计算资源情况进行任务提交,并对任务的运行状态进行监测和处理。
任务计算:搭建任务运行环境,执行任务并返回任务结果。
Shuffle过程:两个阶段之间有宽依赖时,需要进行Shuffle操作。
计算结果收集:从每个任务收集并汇总结果。
在这里我们用一个简洁的CharCount程序为例,这个程序把含有a-z字符的列表转化为RDD,对此RDD进行了Map和Reduce操作计算每个字母的频数,最后将结果收集。其代码如下:
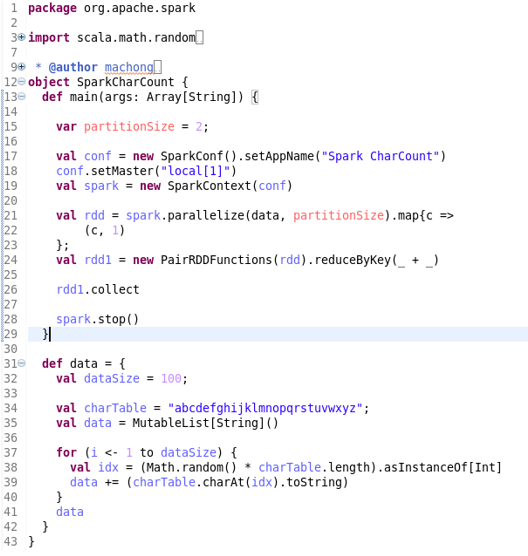
CharCount例子程序
RDD构建和转换
RDD按照其作用可以分为两种类型,一种是对数据源的封装,可以把数据源转换为RDD,这种类型的RDD包括NewHadoopRDD,ParallelCollectionRDD,JdbcRDD等。另一种是对RDD的转换,从而实现一种计算方法,这种类型的RDD包括MappedRDD,ShuffledRDD,FilteredRDD等。数据源类型的RDD不依赖于其他RDD,计算类的RDD拥有自己的RDD依赖。
RDD有三个要素:分区,依赖关系,计算逻辑。分区是保证RDD分布式的特性,分区可以对RDD的数据进行划分,划分后的分区可以分布到不同的Executor中,大部分对RDD的计算都是在分区上进行的。依赖关系维护着RDD的计算过程,每个计算类型的RDD在计算时,会将所依赖的RDD作为数据源进行计算。根据一个分区的输出是否被多分区使用,Spark还将依赖分为窄依赖和宽依赖。RDD的计算逻辑是其功能的体现,其计算过程是以所依赖的RDD为数据源进行的。
例子中共产生了三个RDD,除了第一个RDD之外,每个RDD与上级RDD有依赖关系。
1.spark.parallelize(data, partitionSize)方法将产生一个数据源型的ParallelCollectionRDD,这个RDD的分区是对列表数据的切分,没有上级依赖,计算逻辑是直接返回分区数据。
2.map函数将会创建一个MappedRDD,其分区与上级依赖相同,会有一个依赖于ParallelCollectionRDD的窄依赖,计算逻辑是对ParallelCollectionRDD的数据做map操作。
3.reduceByKey函数将会产生一个ShuffledRDD,分区数量与上面的MappedRDD相同,会有一个依赖于MappedRDD的宽依赖,计算逻辑是Shuffle后在分区上的聚合操作。
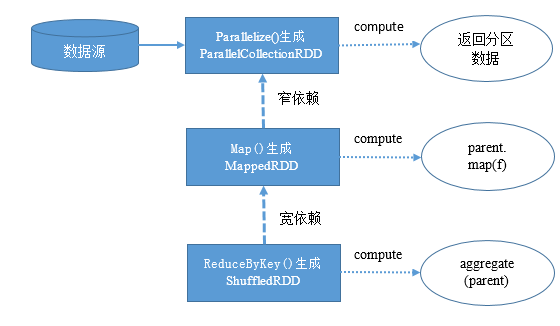
RDD的依赖关系
Spark在遇到动作类操作时,就会发起计算Job,把RDD转换为任务,并发送任务到Executor上执行。从RDD到任务的转换过程是在DAGScheduler中进行的。其总体思路是根据RDD的依赖关系,把窄依赖合并到一个阶段中,遇到宽依赖则划分出新的阶段,最终形成一个阶段的有向无环图,并根据图的依赖关系先后提交阶段。每个阶段按照分区数量划分为多个任务,最终任务被序列化并提交到Executor上执行。
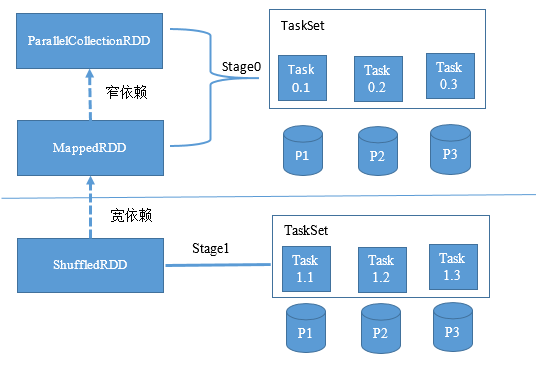
RDD到Task的构建过程
当RDD的动作类操作被调用时,RDD将调用SparkContext开始提交Job,SparkContext将调用DAGScheduler把RDD转化为阶段的有向无环图,然后首先将有向无环图中没有未完成的依赖的阶段进行提交。在阶段被提交时,每个阶段将产生与分区数量相同的任务,这些任务称之为一个TaskSet。任务的类型分为
ShuffleMapTask和ResultTask,如果阶段的输出将用于下个阶段的输入,也就是需要进行Shuffle操作,则任务类型为ShuffleMapTask。如果阶段的输入即为Job结果,则任务类型为ResultTask。任务创建完成后会交给TaskSchedulerImpl进行TaskSet级别的调度执行。
任务调度
在任务调度的分工上,DAGScheduler负责总体的任务调度,SchedulerBackend负责与Executors通信,维护计算资源信息,并负责将任务序列化并提交到Executor。TaskSetManager负责对一个阶段的任务进行管理,其中会根据任务的数据本地性选择优先提交的任务。TaskSchedulerImpl负责对TaskSet进行调度,通过调度策略确定TaskSet优先级。同时是一个中介者,其将DAGScheduler,SchedulerBackend和TaskSetManager联结起来,对Executor和Task的相关事件进行转发。
在任务提交流程上,DAGScheduler提交TaskSet到TaskSchedulerImpl,使TaskSet在此注册。TaskSchedulerImpl通知SchedulerBackend有新的任务进入,SchedulerBackend调用makeOffers根据注册到自己的Executors信息,确定是否有计算资源执行任务,如有资源则通知TaskSchedulerImpl去分配这些资源。
TaskSchedulerImpl根据TaskSet调度策略优先分配TaskSet接收此资源。TaskSetManager再根据任务的数据本地性,确定提交哪些任务。最终任务的闭包被SchedulerBackend序列化,并传输给Executor进行执行。
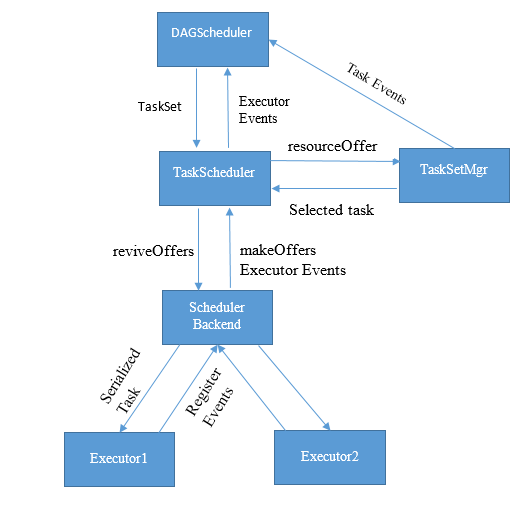
Spark的任务调度
根据以上过程,Spark中的任务调度实际上分了三个层次。第一层次是基于阶段的有向无环图进行Stage的调度,第二层次是根据调度策略(FIFO,FAIR)进行TaskSet调度,第三层次是根据数据本地性(Process,Node,Rack)在TaskSet内进行调度。
任务计算
任务的计算过程是在Executor上完成的,Executor监听来自SchedulerBackend的指令,接收到任务时会启动TaskRunner线程进行任务执行。在TaskRunner中首先将任务和相关信息反序列化,然后根据相关信息获取任务所依赖的Jar包和所需文件,完成准备工作后执行任务的run方法,实际上就是执行ShuffleMapTask或ResultTask的run方法。任务执行完毕后将结果发送给Driver进行处理。
在Task.run方法中可以看到ShuffleMapTask和ResultTask有着不同的计算逻辑。ShuffleMapTask是将所依赖RDD的输出写入到ShuffleWriter中,为后面的Shuffle过程做准备。ResultTask是在所依赖RDD上应用一个函数,并返回函数的计算结果。在这两个Task中只能看到数据的输出方式,而看不到应有的计算逻辑。实际上计算过程是包含在RDD中的,调用RDD.
Iterator方法获取RDD的数据将触发这个RDD的计算动作(RDD. Iterator),由于此RDD的计算过程中也会使用所依赖RDD的数据。从而RDD的计算过程将递归向上直到一个数据源类型的RDD,再递归向下计算每个RDD的值。需要注意的是,以上的计算过程都是在分区上进行的,而不是整个数据集,计算完成得到的是此分区上的结果,而不是最终结果。
从RDD的计算过程可以看出,RDD的计算过程是包含在RDD的依赖关系中的,只要RDD之间是连续窄依赖,那么多个计算过程就可以在同一个Task中进行计算,中间结果可以立即被下个操作使用,而无需在进程间、节点间、磁盘上进行交换。
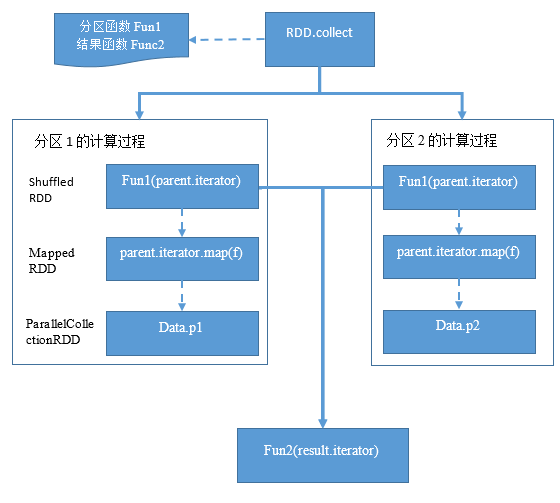
RDD计算过程
Shuffle过程
Shuffle是一个对数据进行分组聚合的操作过程,原数据将按照规则进行分组,然后使用一个聚合函数应用于分组上,从而产生新数据。Shuffle操作的目的是把同组数据分配到相同分区上,从而能够在分区上进行聚合计算。为了提高Shuffle性能,还可以先在原分区对数据进行聚合(mapSideCombine),然后再分配部分聚合的数据到新分区,第三步在新分区上再次进行聚合。
在划分阶段时,只有遇到宽依赖才会产生新阶段,才需要Shuffle操作。宽依赖与窄依赖取决于原分区被新分区的使用关系,只要一个原分区会被多个新分区使用,则为宽依赖,需要Shuffle。否则为窄依赖,不需要Shuffle。
以上也就是说只有阶段与阶段之间需要Shuffle,最后一个阶段会输出结果,因此不需要Shuffle。例子中的程序会产生两个阶段,第一个我们简称Map阶段,第二个我们简称Reduce阶段。Shuffle是通过Map阶段的ShuffleMapTask与Reduce阶段的ShuffledRDD配合完成的。其中ShuffleMapTask会把任务的计算结果写入ShuffleWriter,ShuffledRDD从ShuffleReader中读取数据,Shuffle过程会在写入和读取过程中完成。以HashShuffle为例,HashShuffleWriter在写入数据时,会决定是否在原分区做聚合,然后根据数据的Hash值写入相应新分区。HashShuffleReader再根据分区号取出相应数据,然后对数据进行聚合。
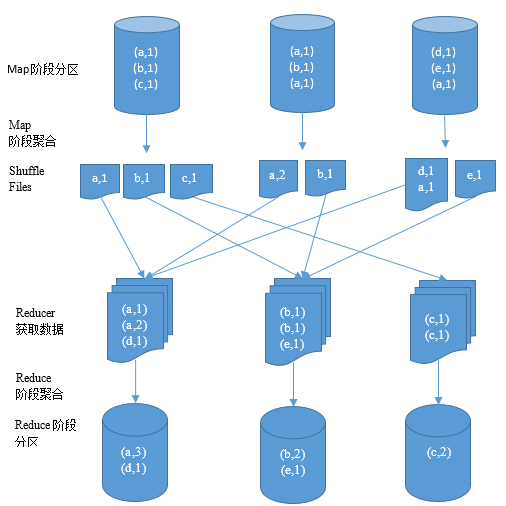
Spark的Shuffle过程
计算结果收集
ResultTask任务计算完成后可以得到每个分区的计算结果,此时需要在Driver上对结果进行汇总从而得到最终结果。
RDD在执行collect,count等动作时,会给出两个函数,一个函数在分区上执行,一个函数在分区结果集上执行。例如collect动作在分区上(Executor中)执行将Iterator转换为Array的函数,并将此函数结果返回到Driver。Driver
从多个分区上得到Array类型的分区结果集,然后在结果集上(Driver中)执行合并Array的操作,从而得到最终结果。
总结
Spark对于RDD的设计是其精髓所在。用RDD操作数据的感觉就一个字:爽!。想到RDD背后是几吨重的大数据集,而我们随手调用下map(),
reduce()就可以把它转换来转换去,一种半两拨千斤的感觉就会油然而生。我想是以下特性给我们带来了这些:
RDD把不同来源,不同类型的数据进行了统一,使我们面对RDD的时候就会产生一种信心,就会认为这是某种类型的RDD,从而可以进行RDD的所有操作。
对RDD的操作可以叠加到一起计算,我们不必担心中间结果吞吐对性能的影响。
RDD提供了更丰富的数据集操作函数,这些函数大都是在MapReduce基础上扩充的,使用起来很方便。
RDD为提供了一个简洁的编程界面,背后复杂的分布式计算过程对开发者是透明的。从而能够让我们把关注点更多的放在业务上。
|






