| ���������кܶ�С������һ��ʹ���˺ܳ�ʱ���Caffe���ѧϰ��ܣ�Ҳ�dz�ϣ���Ӵ���������Caffe��ʵ�ִӶ�ʵ���¹��ܵĶ��ơ����Ľ�������ܹ��͵ײ�ʵ�ֵ��ӽǣ���CaffeԴ����н�����
Caffe����ܹ�
Caffe�����Ҫ����������Blob��Solver��Net��Layer��Proto����ṹͼ����ͼ1��ʾ��Solver������������ѵ����ÿ��Solver�а���һ��ѵ����������һ�������������ÿ�������������ɸ�Layer���ɡ�ÿ��Layer����������Feature
map��ʾΪInput Blob��Output Blob��Blob��Caffeʵ�ʴ洢���ݵĽṹ����һ������ά�ľ�����Caffe��һ��������ʾһ����ֱ����ά�����ĸ�ά�ȷֱ��ӦBatch
Size(N)��Feature Map��ͨ����(C),Feature Map�߶�(H)�Ϳ���(W)��Proto�����Google��Protobuf��Դ��Ŀ����һ������XML�����ݽ�����ʽ���û�ֻ��Ҫ����ʽ�����������ݳ�Ա�������ڶ���������ʵ�ֶ�������л��뷴���л�����Caffe����������ģ�͵Ľṹ���塢�洢�Ͷ�ȡ��
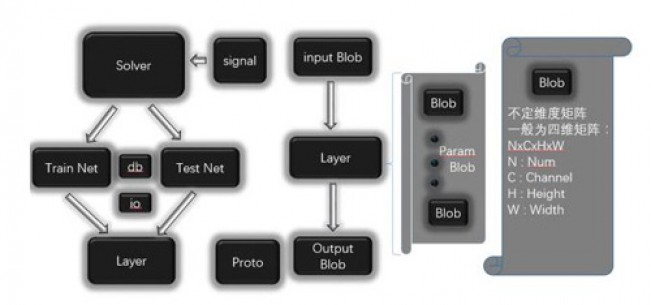
ͼ1 CaffeԴ������ܹ�ͼ
Blob����
�������Caffe�еĻ������ݴ洢��Blob��Blobʹ��SyncedMemory��������ݴ洢�����ݳ�Ա
data_ָ��ʵ�ʴ洢���ݵ��ڴ���Դ�飬shape_�洢�˵�ǰblob��ά����Ϣ��diff_��������˷���ʱ����ݶ���Ϣ����Blob����ʵ����ֻ��num��channel��height��width������ά��ʽ������һ������ά�ȵ����ݽṹ��������չ���洢����ά�ȵ�������һ��vector
���͵�shape_�����У�����ÿ��ά�ȶ���������仯��
��һ��Blob�Ĺؼ�������data_at����������Զ�ȡ�Ĵ洢�ڴ����е����ݣ�diff_at����������ȡ����������˳�������ʾ������ʹ��data_at(const
vector& index)���������ݡ�Reshape����������blob�Ĵ洢��С��count�������ش洢���ݵ�������BlobProto�ฺ���˽�Blob���ݽ��д�����л���Caffe��ģ���С�
����ģʽ˵��
����������һ�����ģʽFactory Pattern��Caffe ��Solver��Layer����Ĵ�����ʹ���˴�ģʽ�����ȿ�����ģʽ��UML����ͼ��
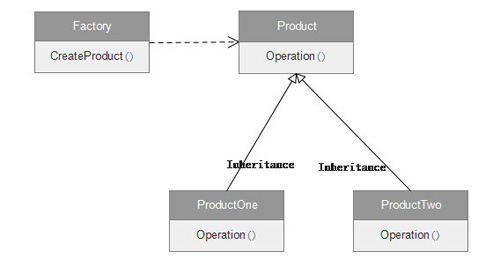
ͼ2 ����ģʽUML��ͼ
��ͬFactory����ͬһ���ܵ��Dz�ͬ�ͺŲ�Ʒһ������Щ��Ʒʵ����ͬ��Operation���ܶ��˿��˹���ģʽ�Ĵ��룬���������������Ϊ�β�newһ�������أ�����newһ�������ƺ�Ҳûʲô����ɡ�����������������ڴ����ع�������Ƹ��ˣ����߹��캯�������仯(���ӻ���ٲ���)���������������N��new������ࡣ�������û�ù�������ֻ��һ��һ�������ġ�����ģʽ�����þ�����ʹ�����ٶԲ�Ʒ�������˽⣬����ʹ���Ѷȡ�����ù�����ֻ��Ҫ�Ĺ�����Ĵ������������ʵ�֣����������벻���ܵ�Ӱ�졣
�ٸ����ӣ�д�����ٲ��ö���Ҫ�Ӱ�ȥ��ҹ�������͵ļ���Ϳϵ»��ļ��ᶼ��MM���ԵĶ�������Ȼ��ζ������ͬ�����������MMȥ���ͻ�ϵ»���ֻ�������Ա˵�����ĸ����ᡱ�����ˡ����ͺͿϵ»��������������Factory��
Solver����
�������л����⣬���ǿ���Solver����Ż�������Caffe�������ʵ�ֵġ�SolverRegistry�����������ǿ����������factory�࣬���������һ���Ż��㷨�IJ�Ʒ���ⲿֻ��Ҫ�����ݺ�����ṹ����ã����Ϳ����Լ��Ż��ˡ�
Solver* CreateSolver(const SolverParameter& param)����������ǹ���ģʽ�µ�CreateProduct�IJ�����
Caffe�����SolverRegistry����������ṩ������6�ֲ�Ʒ(�Ż��㷨)��

�����ֲ�Ʒ�Ĺ��ܶ���ʵ������IJ������£�ֻ��ʵ�ַ�ʽ��һ�������������������ǵ�ʹ�����̰ɡ���Ȼ��Щ��Ʒ��������Product���е�Operation��ÿһ��Solver����̳�Solve��Step��������ÿ��Solver�ж��еĽ�����ApplyUpdate�����������ִ�е����ݲ�һ�����ӿ���һ�µģ���Ҳ������֮ǰ˵�Ĺ������������IJ�Ʒһ������һ����ϸ�����в��죬���������緹�Ҷ����Ĺ��ܣ�����ÿһ�ֵ緹���ļ��ȷ�ʽ���ܲ�ͬ���е��̼��ȵĻ���������ȵĵȡ����������ǿ���Solver�еĹؼ�������
Solver��Solve����������ͼ���£�
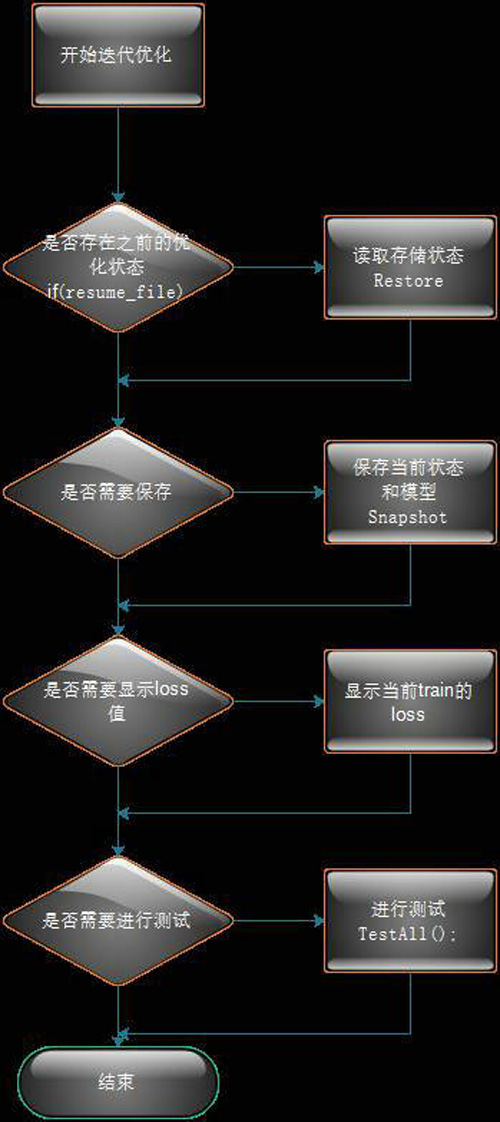
ͼ3 Solver��Solve��������ͼ
Solver����Step��������ͼ��
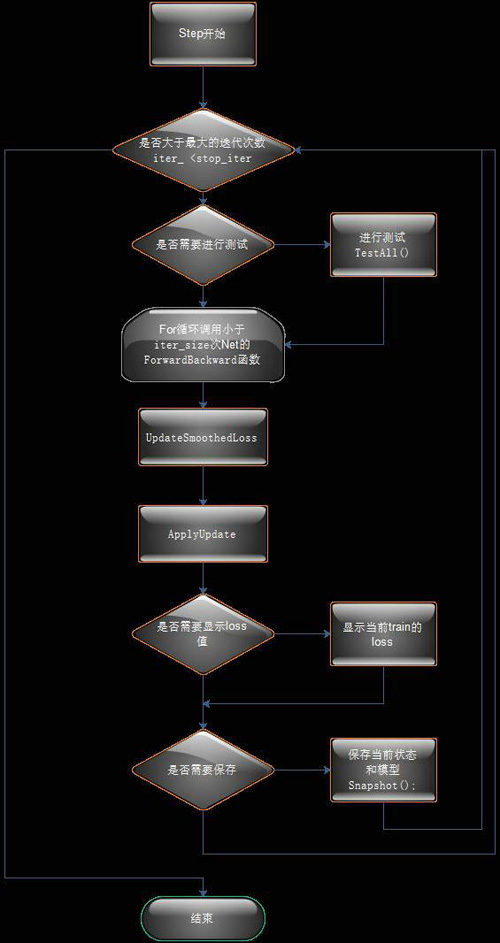
ͼ4 Solver��Step��������ͼ
Solver�йؼ��ľ��ǵ���Sovle������Step���������̣���ֻ��Ҫ����Solver�������������ľ���ʵ�֣�����������������ͼ�Ϳ�������Caffeѵ��ִ�еĹ����ˡ�
Net�����
������Solver֮��������������Net���һЩ�ؼ����������������ʹ��Proto������������������������ฺ������������ǰ��ͷ��ݡ�������Net��ij�ʼ������NetInit�����������̣�
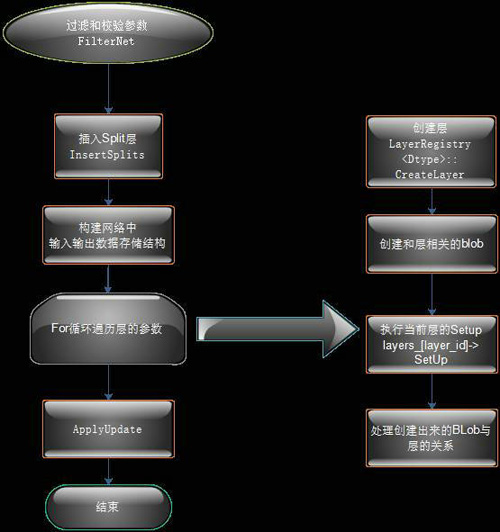
ͼ5 Net��NetInit��������ͼ
Net�����еĹؼ�����������
ForwardBackward����˳�������Forward��Backward��
ForwardFromTo(int start, int end)��ִ�д�start�㵽end���ǰ�ݣ����ü�forѭ�����á�
BackwardFromTo(int start, int end)����ǰ���ForwardFromTo�������ƣ����ô�start�㵽end��ķ��ݡ�
ToProto���������������л����ļ���ѭ��������ÿ�����ToProto������
Layer����
Layer��Net�Ļ�����ɵ�Ԫ������һ���������һ��Pooling�㡣��С�ڽ�����Layer���ʵ�֡�
Layer�ļ̳нṹ
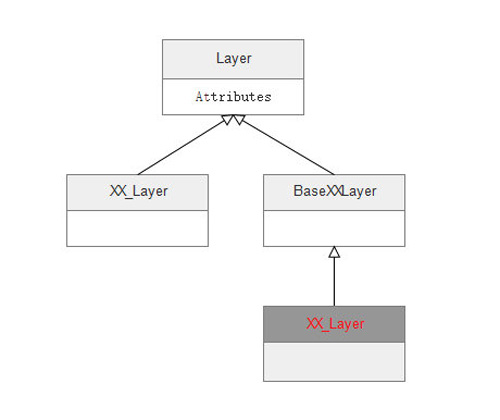
ͼ6 Layer��ļ̳нṹ
Layer�Ĵ���
��Solver�Ĵ�����ʽ����Layer�Ĵ���ʹ�õ�Ҳ�ǹ���ģʽ�������˵���¼����꺯����
REGISTER_LAYER_CREATOR��������������LayerRegistry��

����������������㴴���ĺ��������ɺ�REGISTER_LAYER_CLASS�����Կ����꺯���Ƚϼģ���������Ϊ�������Ƶ�һ���֣������Ϳ��Բ�����һ����������������������������LayerRegistry��

REGISTER_LAYER_CREATOR(type, Creator_##type##Layer)
��δ�����split_layer.cpp�ļ���

REGISTER_LAYER_CLASS(Split)��
�������ǽ�type�滻���Ժ����������������ο�����Ĵ��롣

��Ȼ����Ĵ�������������ֱ�ӵ��ã�û���漰������֮ǰ����ģʽ��һЩ���⡣���еIJ�����������?��Ȼ���ǣ�������ϸ�۲�����ࡣ

��������ôû�д��������أ���Ȼ���ǣ������IJ�Ĵ���������LayerFactory.cpp�У���ͼ����ҿ��£�����������£�

�����������͵�Layer�Ĵ������������˶�Ӧ������������ֱ��˵��������cudnnʵ�ֵIJ㣬�����㶼�Dz��õ�һ�ַ�ʽʵ�ֵĴ���������������cudnnʵ�ֵIJ㶼���õĵڶ��ַ�ʽʵ�ֵĴ���������
Layer�ij�ʼ��
�����괴�����ǿ���������ļ�����������ʲôʱ���õġ�
�ؼ�����Setup�˺�����֮ǰ������ͼ�е�NetInitʱ���ã��������£�

��������Layer��ʼ���Ĺ����У�CheckBlobCounts�����ȵ��ã�Ȼ���������LayerSetUp���������Reshape��������SetLossWeights������Layer��ʼ�����������ڴ�Ҿ������˽⡣
Layer�����������Ľ���
Layer��Forward������Backward��������������ǰ��ͷ��ݣ��������������Լ�ʵ���µIJ����Ҫʵ�֡�����Backward����bottom��blob��diff_����������������ķ�����
Protobuf����
Caffe�е�Caffe.proto�ļ�����������Caffe����Ĺ������ָ�����Caffemodel�Ĵ洢�Ͷ�ȡ��������һ�����ӽ���Protobuf�Ĺ�����ʽ��
����protobuffer���ߴ洢512ά��ͼ��������
message ��д���½�txt�ļ�������Ϊproto,��д�Լ���message���£��������ѹ��protobuff���ļ�����;

���У�dwFaceFeatSize��ʾ����������;pfFaceFeat��ʾ����������
��windows�����(cmd.exe)��->cd�ո�protobuff���ļ�·������ճ����ȥ����>enter;
����ָ��protoc *.proto �Ccpp_out=. ������>enter
���Կ����ļ����������ɡ� .pb.h���͡�.pb.cpp�������ļ���˵���ɹ���

������Ժ��Լ��Ĵ��������ˣ�
�½����Լ��Ĺ��̣��ѡ� .pb.h���͡�.pb.cpp�������ļ����ӵ��Լ��Ĺ������д��#include��
*.pb.h��
�������Ľ̳̰ѿ������¾Ϳ�����
VS��Protobuf����ⷽ����
���������->�һ���������->����
(1)c/c++��>���桪>���Ӱ���Ŀ¼��>
($your protobuffer include path)\protobuffer
(2)c/c++��>�������C>���桪>���ӿ�Ŀ¼�C>
($your protobuffer lib path)\protobuffer
(3) c/c++��>�������C>���롪>����������C>
libprotobufd.lib;(��d��Ϊdebugģʽ)
��libprotobuf.lib;(����d,Ϊreleaseģʽ)
ʹ��protobuf���д���ķ������´��룺

Caffe��ģ�����л�
BlobProto��ʵ����Blob���л���Proto���࣬Caffeģ���ļ�ʹ���˸��ࡣNet����ÿ�����Toproto������ÿ�����Toproto����������Blob���ToProto����������������ģ�;ͱ������л���proto�����ˡ����ֻҪ�����proto�̳���message��Ķ������л����ļ��������ģ��д���ļ���Caffe���ģ�͵�ʱ���ֻ�Ǽ�����WriteProtoToBinaryFile������������������������������£�

Proto.txt�ļ�˵��
Caffe����Ĺ�����Solver�IJ���������ɴ������ļ���ɡ�Net���������е���ReadProtoFromTextFile�����е�����������롣Ȼ�������������̽�������caffe����Ĺ���������ļ�����������ʹ�ô���caffe
model�е�ÿ��blob��������ʲô�ģ����û��������ļ�caffe��ģ���ļ�����ʹ�ã���Ϊģ����ֻ�洢�˸��ָ�����blob���ݣ�����ֻ��floatֵ���������з���Щ��������prototxt�ļ������ġ�
Caffe�ļܹ��ڿ���ϲ����˷������ȥ��̬������������Net��Protobuf�����϶�����graph������������ɺ����map�ṹ�γɵģ�Ȼ��ʹ�ù���ģʽȥʵ�ָ��ָ�����Ĵ�������Ȼ������һ�㶨�����ò���xml����json������Ŀ��д��������proto�ļ������������װ��
�ܽ�
����ΪCaffe����ܹ���һ��������ܣ�ϣ���ܽ�˰���������С����ҵ����ƻ�Caffe���ŵ�Կ�ס���������ϣ�������ש��������������˽�Caffe�����ѧϰ��ܵײ�ʵ�ֵ�ͬ�н����� |






