| ����
������ѧ����δ���� ��ʳƷ��ҵ�е�ϸ��������������֢������ϣ����� DNA ������Ӧ�ò��ϳ��֣���ͬʱ�������Ӧ��Ҳ�����źܴ���ս�������¼������·�����Ӧ�õ��������з���Ӧ���У�����
Spark��FPGA �Լ� GPU Э���������ٵȣ���Щ������Ӧ�ò����ܹ�ʹ��������ѧ�����Ӧ�ã�������Դ��
ISV �������ڲ���Ҫ���ӵ� MPI ��������ʵ�ֲ��л�������ͬʱ Spark �ڴ��ڼ��㼼��Ҳ�ܹ���߷���Ч�ʣ����ٹ������̣�
���̷���ʱ�䣬�Ӷ��и����µķ��֡����Ľ������������ Spark �������г��õĻ������з���Ӧ�ã�������
Spark ��ͬģʽ�µ����з����� ���й����Լ����н�����������Ƚ��ڲ�ͬ����ƽ̨�Լ���ͬ���в�������µ����ܺͼ��ٱȡ�
1. ���������������
�������з����������� GATK �����ʵ��Ϊ������������� FASTQ �ļ�Ϊ���룬�� BWA-mem
���� GATK �� HaploTyperCaller����ɶ���������IJ��������
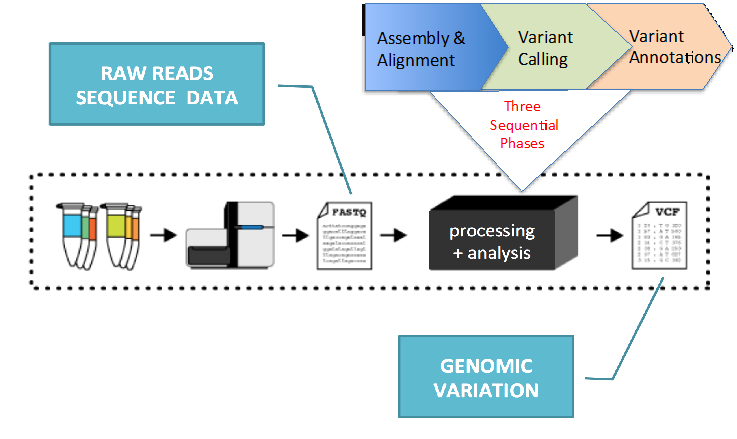
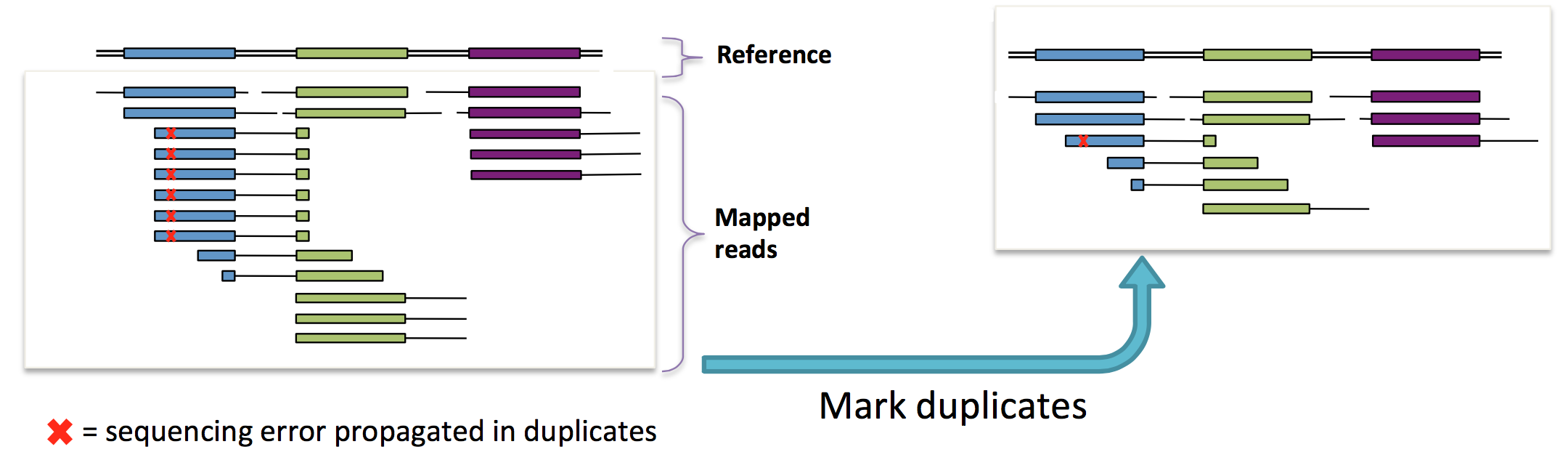
ͼ 1��GATK ���ʵ��
�ڲ��������ĵ�һ�Σ�BWA-mem �������ļ� FASTQ ִ�бȶԣ��������бȶԺ�ӳ���ļ� SAM��Ȼ��ͨ��
SortSam ����һ����������� BAM �ļ���ʵ���ϣ�BAM �ļ��� SAM �ļ��Ķ�������ʽ���˺�Ĵ���������
BAM �������ļ���
BAM �ļ����� Picard ���� MarkDuplicates, ȥ���ظ���Ƭ�Σ�������һ���ϲ��ġ�ȥ���ظ�Ƭ�ε�
BAM �ļ������µļ�����RealignerTargetCreator��IndelRealigner��BaseRecalibrator��PrintReads
�� HaplotypeCaller ���� GATK ��һ���֣��ǶԸ������������ݽ��з�������������
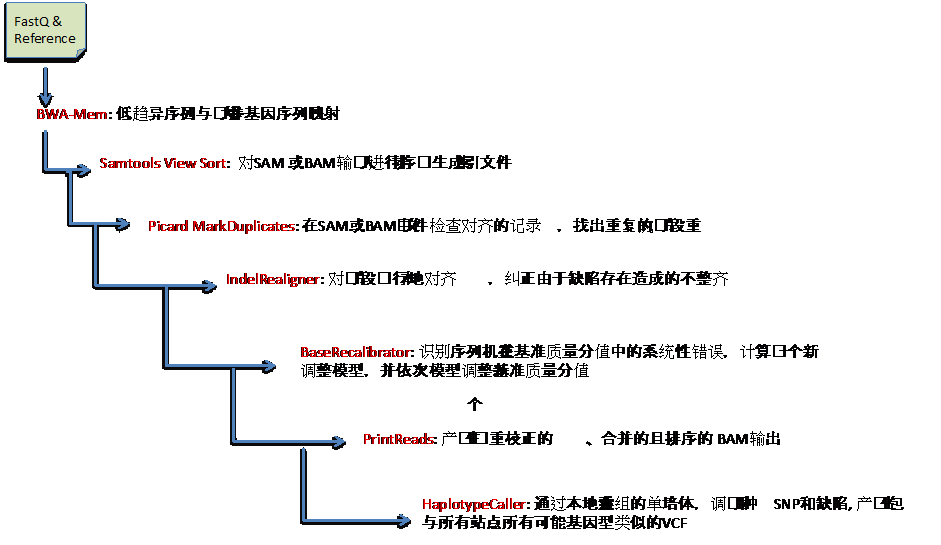
ͼ 2��������������ֽ�
���з�������Ҫ����������ǰ�������������������ݿ���Ϊ�����ķ������������á�ǰ�����Σ��ȶԺ������Ǽ����ܼ��ұȽϺķ�ʱ��Ĺ��̣�����ͨ���ദ��������̵߳ķ�ʽ�������Ч�ʣ�������ʵ�ʹ��������ڼ��㷽���ĸ��ӳ̶��Լ���Ҫ������������Ѹ�����ӣ���ǰһ������������Ȼ���ܻ��ѳ���
1 ��ʱ�䣬���ô� 200 ��Ԫ�� 600 ��Ԫ���ȡ�Spark �������Խ����еķ������л��������ݷֶ��Ż������ж�̬���ؾ��������Ч�ʡ�
GATK4 ���� Broad �Ƴ��Ļ��� Spark �����Ļ������з�����������GATK4 ����ǰ�����������ǣ�
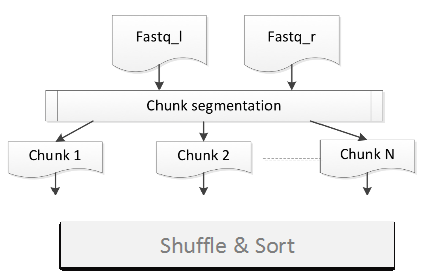
ͼ 3������ Spark ��������ǰ����
�ϲ������ļ��Ͳο��ļ�
�ֳ����ݿ�
���ݿ������ȡ���ڼ�Ⱥ��С�Ϳ�����Դ
��������Ϊ�༶�������ݴ���֮ǰֻ����һ��
�ּ������� Mapreduce
TaskManager ��������� executor
BlockManager ���� spark.broadcast.blockSize ���ÿ��ÿһ��Ƭ�Ĵ�С����ֵ̫���ڹ㲥�����л��С������ʹ���б����������ǣ���ֵ̫Сʱ��BlockManager
�����ܻ���Ӱ�죬ȱʡ�� 4M
ʣ���ڴ�ռ䲻�ϼ��٣���ʣ���ڴ�̫Сʱ��������жϲ����߳���Spark �᳢���������������趨���������������ɹ�ʱ����ҵ�ͷ�����������
GATK4 �Դ��ڲ��Ͽ������������ƵĹ����У������ṩ�Ĺ��ߺ�����Ҳ�ڲ������ӣ�Ŀǰ���°汾�� GATK4
�ṩ�Ĺ�����������
BQSRPipelineSpark
�� Spark ��ִ�� BQSR ����������(BaseRecalibrator �� ApplyBQSR)
BwaAndMarkDuplicatesPipelineSpark
������������ļ�Ϊ�������� BWA �� MarkDuplicates.
ReadsPipelineSpark
�� BWA ��У��Ƭ��Ϊ�������� MarkDuplicates �� BQSR����������ں����ķ���
ͼ 4 �� ReadsPipelineSpark ������ʾ��ͼ��
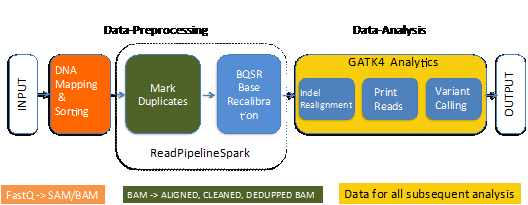
ͼ 4�� ReadsPipelineSpark
������
2. ���з����Ż�����
���з����еIJ�ͬӦ�ö�ϵͳ��Դ��ͬ��������ͼ 5 ���Կ������е�Ӧ��ռ�� CPU ��Դ�Ƚϸߣ��� BWA
����ռ�ô�����������Դ��������ʱ�䳤�����е�Ӧ������Ҫ�����ڴ棬����ʱ��ͬ���Ƚϳ����� HaploTyperCaller��
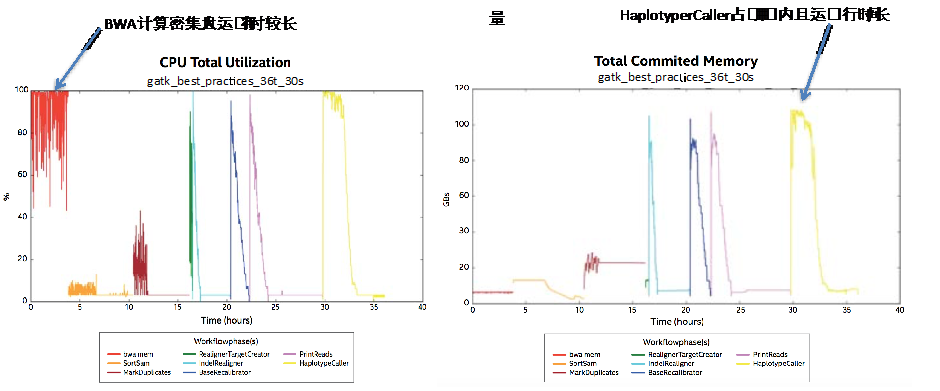
ͼ 5����ͬӦ�ö�ϵͳ��Դ������
һ��أ������ַ����Ի��������̽����Ż��ͼ��٣�
-nt ������ engine ������в��У����д����������еIJ�ͬ����
-nct �� walker ������в��У����ٴ�����������ÿ����������
MapReduce ͬʱ��������ʵ����ÿ��ʵ�������������еIJ�ͬ�ģ�����ģ�����
���ÿ�ѧ���Ż�
�� GATK �������п���ͨ������-nt ��-nct �����������ҵ����Ч�ʡ�
GATK4 �� GATK ���� Spark �����İ汾�����кܶ������ Spark ���������еĹ��ߺ������������÷ּ��ķ�ʽ������ҵ���乤������������
Mapreduce ���� 3 ������ģʽ��
None-spark standalone ģʽ
Spark standalone ģʽ
Spark cluster ģʽ
���������ݺͲο��ļ�������ȷ������£��� GATK4 ���߶������� Spark ��Ⱥģʽ�³ɹ����С�
��ЩӦ���ڼ�Ⱥģʽ�µ����н�����Եõ��������������� CountReadsSpark���е�Ӧ�ã��ر��ǵ�����������Ҫ�����ϵͳ��Դʱ����
spark standalone ģʽ�������У��ᱨ��"Not enough space to
cache RDD in memory"������ Spark Cluster ģʽ������˳�����У�
�� CollectInsertSizeMetricsSpark ��
ͼ 6��CollectInsertSizeMetricsSpark
���
�����з���Ӧ�ü��ٵ���һ�ַ������ṩ���� POWER8 ���������Ż���ѧ�⡣�� HaplotypeCaller
����Ϊ�������ڷ���������ռ�ô������ڴ棬����ʱ�������ͬ����Ҳ�ڿ��������Լ�����ջ�ļ��ٿ⣬�� Intel
GKL �����ں˿⡣

IBM �ṩһ���� POWER8 ϵͳ���Ż��� PairHMM �㷨������ַ����� POWER8 ϵͳ���µ�������Ӳ�����ԣ�Ŀǰ�����Ż���ѧ�����������
POWER8 Ubuntu14 �� RHEL7 ����ϵͳ�ϡ�
���°汾�Ŀ�ѧ�������� POWER8 �� Java ��ͬ�ĸ��㾫�ȶ� HaplotyperCaller
���м��٣�ͬʱ��������ò������߳� SMT �Լ�����ָ����� HaplotypeCaller �ļ������ܳ�����ǰ�İ汾���ر����ڵ��߳�ģʽ����
�Cnct ѡ��δָ�������ڵ��߳�ģʽ�£����� PairHMM ���٣�HaplotypeCaller ���ĵ�ʱ��ֻ��һ�룬���ٱȴﵽ
1.88 ����
�� P8 ϵͳ�ϵ��� PairHMM��

���ٻ������Ӧ�õ��������������� FPGA��GPGPU �����Լ�ȫӲ�����ٵ� Edico Dragon
Solution �ȣ����ڱ��ĵ����۷�Χ��
3. Spark ��������
Spark ��һ���� Hadoop ���Ƶļ�Ⱥ���㻷���� �� Spark �������ڴ�ֲ����ݼ��� ��ijЩ�������ط�����ֵø�����Խ�������ܹ��ṩ����ʽ��ѯ�⣬Spark
�������Ż������������ء�
Spark ����Ҫ�ص������
�ٶȿ�
Spark �����Ƚ��� DAG ִ�����棬֧�ֵ������������ڴ��ڼ��㣬Ӧ�ó���ִ���ٶ��� Hadoop
���ڴ��� MapReduce �� 100 �������ڴ����ϵ� 10 ����

����ʹ��
�� Java��Scala��Python �� R ���ٱ�дӦ�ã� Spark �ṩ���� 80 �ָ���������������Ӧ�÷dz����㣬���ҿ�����
Scala ��Python �� R �������
ͨ��
Spark ֧��һϵ�к����������ջ������ SQL��DataFrames������ѧϰ MLlib��GraphX
�� Spark Streaming�����Խ���Щ����ؼ��ɵ�ͬһ��Ӧ�ã��� SQL�����Լ����ӷ��������һ��
�������κεط�
Spark ���������� Hadoop��Mesos��standalone ģʽ���ơ������Է��ʶ��ֶ��������ݣ�����
HDFS��Cassandra��HBase �� S3�������Բ�ͬģʽ���� Spark����������ģʽ��Standalone
ģʽ��Mesoes ģʽ�� yarn ģʽ��
IBM Spectrum Conductor with Spark �ܹ���Դ�����ݷ���ƽ̨ Apache
Spark �IJ��𣬽�������ٶ������� 60%����Ϊһ�ֿ�Դ�����ݷ�����ܣ�Apache Spark �ṩ�����ŷ����������ơ�
ʵʩ Spark ������ս�ԣ�����Ͷ���µ�רҵ���������ߺ������ȡ�������ʱ Spark ��Ⱥ���ܵ�������Ч������Դ�������������Ͱ�ȫ��ս��IBM
Spectrum Conductor with Spark �ɰ��������Щ���⡣���� Spark ��������Դ�������ܹ��������������ڹ������ɣ��Ծ���ķ�ʽ������ҵ�����⻧
Spark ������Ϊ�˰����������ٱ�Ǩ�� Spark �������ڣ�IBM Spectrum Conductor
with Spark ֧��ͬ ʱ���� Spark �Ķ���ʵ���Ͱ汾��
���ĵ������IJ��ԣ��ǻ��� IBM Conductor with Spark �ܹ��������� 3 ̨ Firestone
��������1 ̨ Driver �ڵ㣬2 ̨ Worker �ڵ㣬�� 1+2 �ṹ����ͼ 6 ��ʾ��

Conductor with spark
��Ⱥ�ܹ�
���л����� Conductor with spark, Spark �汾�� 1.6.1, ���� Spark
ȱʡ�� DAGScheduler �������������� gatk-launch ��ѡ���� --sparkRunner
SPARK --sparkMaster spark://c712f6n10:7077��
4. ���� Spark ������������������
�� ReadsPipelineSpark ������Ϊ�������� GATK4 Ԥ�����һ������������ BAM
�ļ�Ϊ���룬���� MarkDuplicate �� BQSR ��������ļ���������һ�η�����
�ظ���ָһ�����Ƭ������ͬ�ġ�δ���ε���ʼ�ͽ�����MarkDuplicate ����Ҫ��ѡ��"��ѵ�"���ƣ��Ӷ���������ЧӦ��
BQSR ��һ���Ѿ�������� BAM �ļ��ĺϳɲ������ݻ���������ֵ�������µ��������µ������� BAM
�����ÿ��Ƭ���� QUAL ���и���ȷ���䱨���������ֵ���ӽ��ڲο������ʵ�ʿ����ԡ�
�������
�嵥 1.
./gatk/gatk-launch \
ReadsPipelineSpark \ # Pipeline name
-I $bam \ # Input file
-R $ref \ # Reference file
-O $bamout \ # Output file
�CbamPartitionSize 134217728 \
# maximum number of bytes to read from a file into each partition of reads.
�CknownSites $dbsnp \ # knownSites (see notes)
�CshardedOutput true \ # Write output to multiple pieces
�Cduplicates_scoring_strategy # MarkDuplicatesScoringStrategy
SUM_OF_BASE_QUALITIES \
�CsparkRunner SPARK \ # Run mode
�CsparkMaster spark://c712f6n10:7077 # Spark cluster
--conf spark.driver.memory=5g --conf spark.executor.memory=16g
|
�����ļ���
| -I
CEUTrio.HiSeq.WEx.b37.NA12892.bam
-R human_g1k_v37.2bit
-knownSites dbsnp_138.b37.excluding_sites_after_129.vcf
|
���ò�ͬ����Դ�������������Զ���Cnum-executors, --executor-mem, --executor-cores���Ӷ����ݼ�����Դ�Ĵ�С��������͵�����Դ��
5. ���ܺͼ��ٱȷ���
���ĵ��� CountReadsSpark Ϊ�����Աȷ����ڲ�ͬģʽ�µ����н����
�������� Spark ģʽ������ CountReads:
�嵥 2.
| #./gatk-launch
CountReads -I /home/dlspark/SRR034975.Sort_all.bam
Running:
/home/dlspark/gatk/build/install/gatk/bin/gatk
CountReads -I /home/dlspark/SRR034975.Sort_all.bam
[May 31, 2016 9:52:01 PM EDT] org.broadinstitute.hellbender.tools.CountReads
--input /home/dlspark/SRR034975.Sort_all.bam --disable_all_read_filters
false --interval_set_rule UNION --interval_padding
0 --readValidationStringency SILENT --secondsBetweenProgressUpdates
10.0 --disableSequenceDictionaryValidation false
--createOutputBamIndex true --createOutputBamMD5
false --addOutputSAMProgramRecord true --help
false --version false --verbosity INFO --QUIET
false
Output: 34929382
Elapsed time: 12.14 minutes
|
�� Spark Standalone ģʽ������ CountReadsSpark
�嵥 3.
| #
./gatk-launch CountReadsSpark -I /home/dlspark/SRR034975.Sort_all.bam
Running:
/home/dlspark/gatk/build/install/gatk/bin/gatk
CountReadsSpark -I /home/dlspark/SRR034975.Sort_all.bam
[June 1, 2016 1:11:34 AM EDT] org.broadinstitute.hellbender.tools.spark.pipelines.CountReadsSpark
--input /home/dlspark/SRR034975.Sort_all.bam --readValidationStringency
SILENT --interval_set_rule UNION --interval_padding
0 --bamPartitionSize 0 --disableSequenceDictionaryValidation
false --shardedOutput false --numReducers 0 --sparkMaster
local[*] --help false --version false --verbosity
INFO --QUIET false
Output: 34929382
Elapsed time: 9.50 minutes
|
�� Spark Cluster ģʽ������ CountReadsSpark
�嵥 4.
# ./gatk-launch CountReadsSpark -I /gpfs1/yrx/SRR034975.Sort_all.bam
-O /gpfs1/yrx/gatk4-test.output -
-sparkRunner SPARK --sparkMaster spark://c712f6n10:7077
Running:
spark-submit --master spark://c712f6n10:7077
--conf spark.kryoserializer.buffer.max=512m
--conf spark.driver.maxResultSize=0
--conf spark.driver.userClassPathFirst=true
--conf spark.io.compression.codec=lzf
--conf spark.yarn.executor.memoryOverhead=600
--conf spark.yarn.dist.files
=/home/dlspark/gatk/build/libIntelDeflater.so
--conf spark.driver.extraJavaOptions
=-Dsamjdk.intel_deflater_so_path=libIntelDeflater.so
-Dsamjdk.compression_level
=1 -DGATK_STACKTRACE_ON_USER_EXCEPTION=
true --conf spark.executor.extraJavaOptions=
-Dsamjdk.intel_deflater_so_path
=libIntelDeflater.so -Dsamjdk.compression_level
=1 -DGATK_STACKTRACE_ON_USER_EXCEPTION
=true
Output: 34929382
Elapsed time: 0.60 minutes |
�����ֲ�ͬ����ģʽ����ıȽϣ�������ʱ�俴���� Spark Cluster ģʽ�£�CountReadsSpark
������Ч�ʱ� Spark Standalone ģʽ����� 15 ����
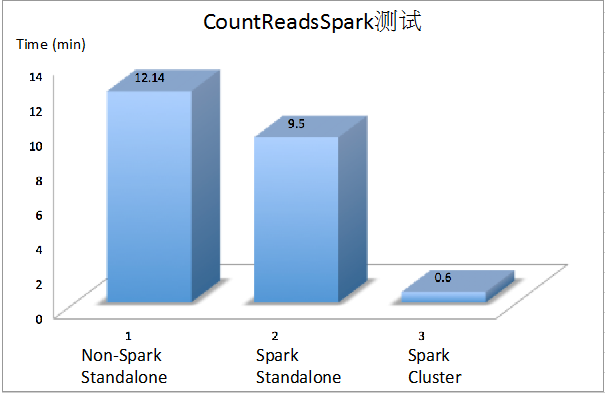
ͼ 7��3 ������ģʽ����Ƚ�
�ܽ�
ͨ�����ϵķ��������� Spark ������������ѧ����������ܹ�ʹԭ�����е�Ӧ���ڲ��Ĵ�������������������¾Ϳ���ʵ�ֲ��л����ڴ��ڼ��㣬��ʹ�ü���
Java ���뼴���ڼ�Ⱥ�ϴ������������ݣ�����Ҫ���ӵ� MPI �� OpenMP ��̣�ʹ��ѧ�ҽ��������༯�����·������о����µķ��֡����Ż���
Spark ��������ѧ��������IJ��ϳ�������ƣ�Խ��Խ��Ĺ��ߺ��������������� Spark ����ƽ̨���������ݴ����ܣ���չ��Ҳ������ߣ����л���������ѧӦ�ý���ʹ���з���ʱ���Ŀǰ��ʮ����Сʱ���̵�
1 ��Сʱ֮�ڣ�ͬʱ���÷ֲ�ʽ��ҵ���Ⱥ͵ͳɱ���Ⱥ��Ҳ�Ἣ��ؽ��ͷ����ɱ���
|






