| ��ƪ���������ǽ�ѧϰ���ʹ��Apache
Spark streaming��Kafka��Node.js��Socket.IO��Highcharts����ʵʱ����Dashboard��

��������
���������Ż�ϣ������һ��ʵʱ�����DZ��̣���ÿ���ӷ����Ķ��������������ӻ����Ӷ��Ż�������Ч�ʡ�
�������
�������֮ǰ���ȿ��ٿ������ǽ�ʹ�õĹ��ߣ�
Apache Spark�C һ��ͨ�õĴ��ģ���ݿ��ٴ������档Spark���������ٶȱ�Hadoop
MapReduce���10�������ڴ��е����ݷ����ٶ�����100���� ���� ����Apache Spark����Ϣ��
Python�C Python��һ�ֹ㷺ʹ�õĸ���ͨ�ã����ͣ���̬������ԡ�
���� ����Python����Ϣ��
Kafka�C һ�������������ֲ�ʽ��Ϣ��������ϵͳ�� ���� ����Kafka����Ϣ��
Node.js�C �����¼�������I/O��������JavaScript������������V8�����ϡ�
���� ����Node.js����Ϣ��
Socket.io�C Socket.IO��һ������ʵʱWebӦ�ó����JavaScript�⡣��֧��Web�ͻ��˺ͷ�����֮���ʵʱ��˫��ͨ�š�
���� ����Socket.io����Ϣ��
Highcharts�C ��ҳ�Ͻ���ʽJavaScriptͼ���� ���� ����Highcharts����Ϣ��
CloudxLab�C �ṩһ����ʵ�Ļ����ƵĻ�����������ϰ��ѧϰ���ֹ��ߡ������ͨ������
ע�� ������ʼ��ϰ��
��������Pipeline?
����������Pipeline�߲�ܹ�ͼ
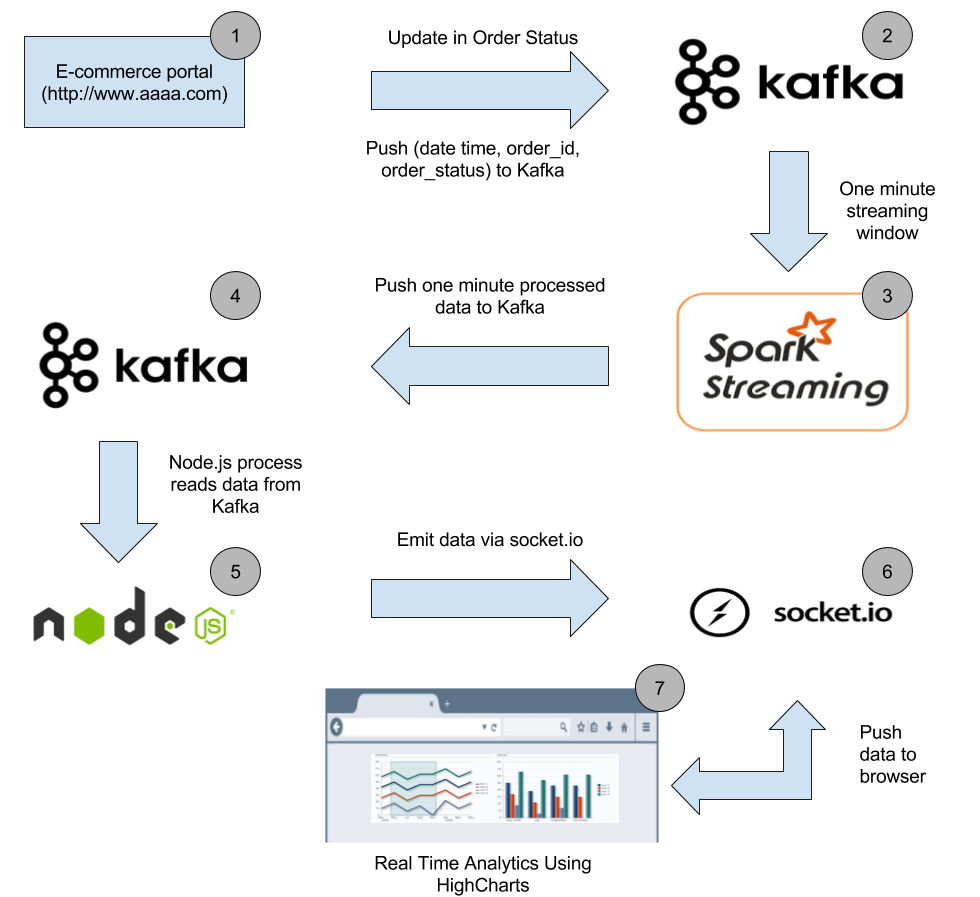
����Pipeline
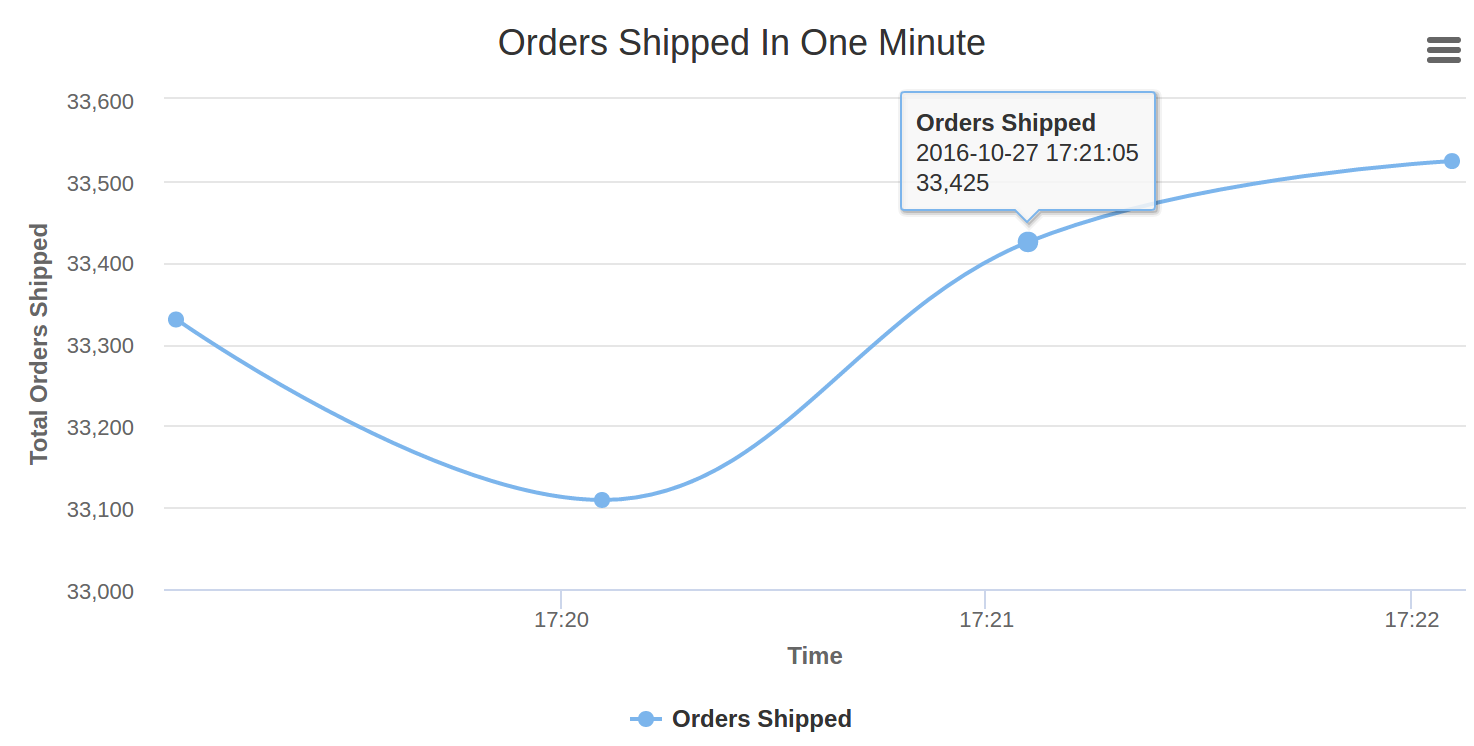
ʵʱ����Dashboard
�����Ǵ�����Pipeline�е�ÿ���ε�������ʼ������ɽ�������Ĺ�����
��1
���ͻ�����ϵͳ�е���Ʒ������ϵͳ�еĶ���״̬�仯ʱ����Ӧ�Ķ���ID�Լ�����״̬��ʱ�佫�����͵���Ӧ��Kafka�����С�
���ݼ�
����û����ʵ�����ߵ��������Ż���վ����������CSV�ļ������ݼ���ģ�⡣�����ǿ������ݼ���
DateTime, OrderId, Status
2016-07-13 14:20:33,xxxxx-xxx,processing
2016-07-13 14:20:34,xxxxx-xxx,shipped
2016-07-13 14:20:35,xxxxx-xxx,delivered |
���ݼ��������зֱ��ǣ���DateTime������OrderId���͡�Status�������ݼ��е�ÿһ�б�ʾ�ض�ʱ��ʱ������״̬�����������á�xxxxx-xxx����������ID������ֻ��ÿ���ӷ����Ķ���������Ȥ�����Բ���Ҫʵ�ʵĶ���ID��
���ݼ�λ����Ŀ�� spark-streaming/data/order_data
�ļ����С�
�������ݼ���Kafka
shell�ű�������ЩCSV�ļ��зֱ��ȡÿһ�в����͵�Kafka��������һ��CSV�ļ���Kafka֮����Ҫ�ȴ�1������������һ��CSV�ļ�����������ģ��ʵʱ���������Ż���������������еĶ���״̬���Բ�ͬ��ʱ�������µġ�����ʵ���������£�������״̬�ı�ʱ����Ӧ�Ķ�����ϸ��Ϣ�ᱻ���͵�Kafka��
�������ǵ�shell�ű����������͵�Kafka�����С���¼�� CloudxLab
Web����̨ �������������
# Clone the repository
git clone https://github.com/singhabhinav/cloudxlab.git
# Create the order-data topic in Kafka
export PATH=$PATH:/usr/hdp/current/kafka-broker/bin
kafka-topics.sh --create --zookeeper localhost:2181
--replication-factor 1 --partitions 1 --topic
order-data
# Go to Kafka directory
cd cloudxlab/spark-streaming/kafka
# Run the Script for pushing data to Kafka topic
# ip-172-31-13-154.ec2.internal is the hostname
of broker.
# Find list of brokers in Ambari (a.cloudxlab.com:8080).
# Use hostname of any one of the brokers
# order-data is the Kafka topic
/bin/bash put_order_data_in_topic.sh ../data/order_data/
ip-172-31-13-154.ec2.internal:6667 order-data
# Script will push CSV files one by one to Kafka
topic
after every one minute interval
# Let the script run. Do not close the terminal |
��2
�ڵ�1�κ�Kafka��order-data�������е�ÿ����Ϣ����������ʾ
2016-07-13 14:20:33,xxxxx-xxx,processing |
��3
Spark streaming���뽫��60���ʱ�䴰���дӡ�order-data����Kafka�����ȡ���ݲ����������������ڸ�60��ʱ�䴰����Ϊÿ��״̬�Ķ���������������ÿ��״̬�������ܼ��������͵���order-one-min-data����Kafka�����С�
����Web����̨��������ЩSpark streaming����
# Login to CloudxLab web console in the second tab
# Create order-one-min-data Kafka topic
export PATH=$PATH:/usr/hdp/current/kafka-broker/bin
kafka-topics.sh --create --zookeeper localhost:2181
--replication-factor 1 --partitions 1 --topic
order-one-min-data
# Go to spark directory
cd cloudxlab/spark-streaming/spark
# Run the Spark Streaming code
spark-submit --jars spark-streaming-kafka-assembly_2.10-1.6.0.jar
spark_streaming_order_status.py localhost:2181
order-data
# Let the script run. Do not close the terminal |
��4
������Σ�Kafka���⡰order-one-min-data���е�ÿ����Ϣ��������������JSON�ַ���
{
"shipped": 657,
"processing": 987,
"delivered": 1024
} |
��5
����Node.js server
�������ǽ�����һ��node.js��������ʹ�á�order-one-min-data��Kafka�������Ϣ�����������͵�Web������������Ϳ�����Web���������ʾ��ÿ���ӷ����Ķ���������
����Web����̨��������������������node.js������
# Login to CloudxLab web console in the third tab
# Go to node directory
cd cloudxlab/spark-streaming/node
# Install dependencies as specified in package.json
npm install
# Run the node server
node index.js
# Let the server run. Do not close the terminal |
����node�������������ڶ˿�3001�ϡ����������node������ʱ���֡�EADDRINUSE��������༭index.js�ļ������˿����θ���Ϊ3002...3003...3004�ȡ���ʹ��3001-3010��Χ�ڵ�������ö˿�������node��������
�����������
����node����������ת�� http://YOUR_WEB_CONSOLE:PORT_NUMBER
����ʵʱ����Dashboard���������Web����̨��f.cloudxlab.com������node���������ڶ˿�3002�����У���ת��
http://f.cloudxlab.com:3002 ����Dashboard��
�����Ƿ��������URLʱ��socket.io-client�ⱻ���ص�����������Ὺ���������������֮���˫��ͨ���ŵ���
��6
һ����Kafka�ġ�order-one-min-data��������������Ϣ���node���̾ͻ������������ѵ���Ϣ��ͨ��socket.io����Web�������
��7
һ��web������е�socket.io-client���յ�һ���µġ�message���¼����¼��е����ݽ��ᱻ������������յ������еĶ���״̬�ǡ�shipped���������ᱻ���ӵ�HighCharts����ϵ�ϲ���ʾ��������С�
��ͼ
�����ѳɹ�����ʵʱ����Dashboard������һ������ʾ������ʾ��μ���Spark-streaming��Kafka��node.js��socket.io������ʵʱ����Dashboard�����ڣ�����������Щ����֪ʶ�����ǾͿ���ʹ���������߹��������ӵ�ϵͳ�� |






