| �κ�ϵͳ�����и��ָ��������⣬��Щ��ϵͳ����������⣬��Щȴ��ʹ���������⡣HBaseҲһ��������ʵ�������ϴ�һ����ٶ��������ܶ����⣬��Щ��HBase����Ҫ���Ƶģ���Щ������ȷʵ�����˽�̫�١��ܽ������������������Ҫ��������Full
GC�쳣����崻����⡢RIT���⡢д������̫���Լ����ӳٽϴ�
Full GC����֮ǰ��һЩ���������Ѿ�������������ȥ������Ҫ�Ľ������Ŀǰ��Ҫ����������Ҫע�⣬һ������Ҫ�鿴GC��־ȷ��������Full
GC������Full GC���Ͷ�JVM�������е��ţ���һ������Ҫȷ���Ƿ�����BucketCache��offheapģʽ������ʹ��LRUBlockCache��ͯЬ����ת�Ƶ�BucketCache������Ȼ���ǻ��Ǻ��ڴ��ٷ�2.0.0�汾�����ĸ���offheapģ�顣
RIT���⣬�����Ÿ�������Ϊ���Ƕ��䲻�˽⣬����ԭ�����Դ� ���� ���������Ŀǰ��������������ʹ�ùٷ��ṩ��HBCK������(HBCK����һֱ���ó�������������Ŀǰ���������࣬�Ⱥ����и��స���Ļ����ó���˵)��ʹ��֮���ǽ�����˵Ļ�����Ҫ�ֶ����ļ�����Ԫ���ݱ���
������д������̫���Լ����ӳ�̫����Ż����⣬����Ҳ�ͺܶ����ѽ��й�̽�֣���ƪ���¾��Զ��ӳ��Ż�Ϊ��������չ�����������HBase���ж��ӳ��Ż�����Щ��·���Լ���Щ��·֮��ľ���ԭ����ϣ������ڿ���֮���ܹ������Щ��·�����Լ���ϵͳ��
һ������£��������ӳٽϴ�ͨ���������ֳ������ֱ�Ϊ��
1.����ijҵ���ӳٽϴ�Ⱥ����ҵ������
2.������Ⱥ����ҵ��ӳ�ӳٽϴ�
3.ij��ҵ������֮��Ⱥ��������ҵ���ӳٽϴ�
�����ֳ����DZ���ͨ��ijҵ��Ӧ�ӳ��쳣��������Ҫ��ȷ���������ֳ�����Ȼ������Խ�����⡣��ͼ�ǶԶ��Ż�˼·��һ���ܽᣬ��Ҫ��Ϊ�ĸ����棺�ͻ����Ż������������Ż�����������Ż��Լ�HDFS����Ż�������ÿһ��С�㶼�ᰴ�ճ������࣬���������й����ܽᡣ����ֱ������ϸ���⣺
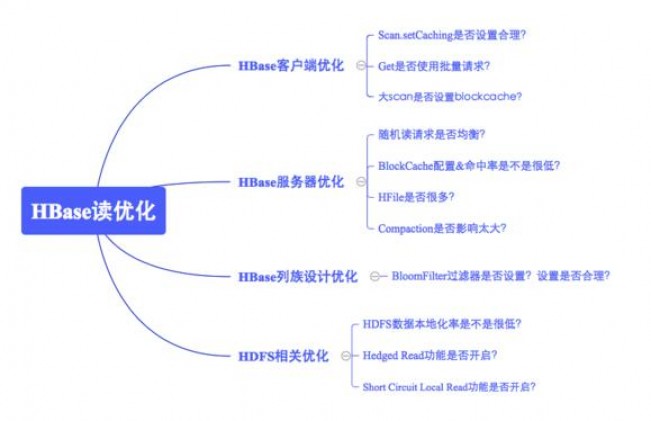
HBase�ͻ����Ż�
�ʹ����ϵͳһ�����ͻ�����Ϊҵ���д����ڣ�����ʹ�ò���ȷͨ���ᵼ�� ��ҵ����ӳٽϸ� ʵ���ϴ���һЩʹ�����Ƶ��Ƽ��÷�������һ����Ҫ��ע�ĸ����⣺
1. scan�����Ƿ����ú���?
�Ż�ԭ�����ڽ����������֮ǰ��������Ҫ����ʲô��scan���棬ͨ������һ��scan�᷵�ش������ݣ���˿ͻ��˷���һ��scan����ʵ�ʲ�����һ�ξͽ��������ݼ��ص����أ����Ƿֳɶ��RPC������м��أ��������һ��������Ϊ��������������ܻᵼ����������������Ľ���Ӱ������ҵ����һ����Ҳ�п�����Ϊ������̫���±��ؿͻ��˷���OOM���������������ϵ���û������ȼ���һ�������ݵ����أ�Ȼ������������ټ�����һ�������ݵ����ش��������������ֱ���������ݶ�������ɡ����ݼ��ص����ؾʹ����scan�����У�Ĭ��100�����ݴ�С��
ͨ������£�Ĭ�ϵ�scan�������þͿ������������ġ�������һЩ��scan(һ��scan������Ҫ��ѯ����������ʮ��������)��˵��ÿ������100��������ζ��һ��scan��Ҫ����������ǧ��RPC�������ֽ����Ĵ��������Ǻܴ�ġ���˿��Կ��ǽ�scan����������������Ϊ500����1000�Ϳ��ܸ��Ӻ��ʡ�����֮ǰ����һ�����飬��һ��scanɨ��10w+���������������£���scan�����100���ӵ�1000��������Ч����scan����������ӳ٣��ӳٻ���������25%���ҡ�
�Ż����飺��scan�����½�scan�����100����500����1000�����Լ���RPC����
2. get�����Ƿ����ʹ����������?
�Ż�ԭ����HBase�ֱ��ṩ�˵���get�Լ�����get��API�ӿڣ�ʹ������get�ӿڿ��Լ��ٿͻ��˵�RegionServer֮���RPC����������߶�ȡ���ܡ�������Ҫע����ǣ�����get����Ҫô�ɹ����������������ݣ�Ҫô�׳��쳣��
�Ż����飺ʹ������get���ж�ȡ����
3. �����Ƿ������ʾָ�����������?
�Ż�ԭ����HBase�ǵ��͵��������ݿ⣬��ζ��ͬһ��������ݴ洢��һ�𣬲�ͬ��������ݷֿ��洢�ڲ�ͬ��Ŀ¼�¡����һ�����ж�����壬ֻ�Ǹ���Rowkey����ָ��������м����Ļ���ͬ�����������Ҫ�������м��������ܱ�Ȼ���ָ������IJ�ѯ��ܶ࣬�ܶ��������������2����3����������ʧ��
�Ż����飺����ָ����������н��о�ȷ���ҵľ���ָ������
4. ����������ȡ�����Ƿ����ý�ֹ����?
�Ż�ԭ����ͨ������������ȡ���ݻ����һ����ȫ��ɨ�裬һ�����������ܴ���һ��������ֻ��ִ��һ�Ρ����ֳ��������ʹ��scanĬ�����ã��ͻὫ���ݴ�HDFS���س���֮��ŵ����档�����֪���������ݽ��뻺��ؽ�����ʵʱҵ���ȵ����ݼ���������ҵ�ò���HDFS���أ�������������ԵĶ��ӳ�ë��
�Ż����飺����������ȡ�������ý��û��棬scan.setBlockCache(false)
HBase���������Ż�
һ�����˶�����һ������ҵ��������ӳٽϴ�Ļ���ͨ���Ǽ�Ⱥ����ģ���������Ⱥ��ҵ�ᷴӳ���ӳٽϴ��Դ�4���������֣�
1. �������Ƿ����?
�Ż�ԭ������������¼������еĶ���������һ̨RegionServer��ij����Region�ϣ���һ���治�ܷ���������Ⱥ�IJ���������������һ�����Ʊ���ɴ�̨RegionServer��Դ��������(����IO�ľ���handler�ľ���)�����ڸ�̨RegionServer�ϵ�����ҵ�������ܵ��ܴ�IJ������ɼ����������ⲻ������ɱ���ҵ�����ܺܲ��������Ӱ������ҵ��Ȼ��д������Ҳ��������Ƶ����⣬�ɼ����ز�������HBase�Ĵ�ɡ�
�۲�ȷ�ϣ��۲�����RegionServer�Ķ�����QPS���ߣ�ȷ���Ƿ���ڶ�����������
�Ż����飺RowKey�������ɢ�л�����(����MD5ɢ��)��ͬʱ�����������Ԥ��������
2. BlockCache�Ƿ����ú���?
�Ż�ԭ����BlockCache��Ϊ�����棬���ڶ�������˵������Ҫ��Ĭ�������BlockCache��Memstore��������ԱȽϾ���(��ռ40%)�����Ը��ݼ�Ⱥҵ������������������д��ҵ����Խ�BlockCacheռ�ȵ�����һ���棬BlockCache�IJ���ѡ��Ҳ����Ҫ����ͬ���ԶԶ�������˵Ӱ�첢���Ǻܴ��Ƕ�GC��Ӱ��ȴ�൱����������BucketCache��offheapģʽ��GC���ֺ���Խ�����⣬HBase
2.0��offheap�ĸ���(HBASE-11425)����ʹHBase�Ķ����ܵõ�2��4����������ͬʱGC���ֻ����!
�۲�ȷ�ϣ��۲�����RegionServer�Ļ���δ�����ʡ������ļ����������һ��GC��־��ȷ��BlockCache�Ƿ�����Ż�
�Ż����飺JVM�ڴ������� < 20G��BlockCache����ѡ��LRUBlockCache;����ѡ��BucketCache���Ե�offheapģʽ;�ڴ�HBase
2.0�ĵ���!
3. HFile�ļ��Ƿ�̫��?
�Ż�ԭ����HBase��ȡ����ͨ�����ȻᵽMemstore��BlockCache�м���(��ȡ���д������&�ȵ�����)��������Ҳ����ͻᵽ�ļ��м�����HBase����LSM�ṹ�ᵼ��ÿ��store��������HFile�ļ����ļ�Խ�࣬���������IO������ȻԽ�࣬��ȡ�ӳ�Ҳ��Խ�ߡ��ļ�����ͨ��ȡ����Compaction��ִ�в��ԣ�һ����������ò����йأ�hbase.hstore.compactionThreshold��hbase.hstore.compaction.max.size��ǰ�߱�ʾһ��store�е��ļ����������پ�Ӧ�ý��кϲ������߱�ʾ�����ϲ����ļ���С����Ƕ��٣������˴�С���ļ����ܲ���ϲ���������������������̫���ɡ�(ǰ�߲�������̫���߲�������̫С)������Compaction�ϲ��ļ���ʵ��Ч�������ԣ������ܶ��ļ��ò����ϲ��������ͻᵼ��HFile�ļ�����ࡣ
�۲�ȷ�ϣ��۲�RegionServer�����Լ�Region�����storefile����ȷ��HFile�ļ��Ƿ����
�Ż����飺hbase.hstore.compactionThreshold���ò���̫��Ĭ����3��;������Ҫ����Region��Сȷ����ͨ�����Լ���Ϊhbase.hstore.compaction.max.size
= RegionSize / hbase.hstore.compactionThreshold
4. Compaction�Ƿ�����ϵͳ��Դ����?
�Ż�ԭ����Compaction�ǽ�С�ļ��ϲ�Ϊ���ļ�����ߺ���ҵ����������ܣ�����Ҳ�����IO�Ŵ��Լ�������������(����Զ�̶�ȡ�Լ�������д�붼������ϵͳ����)���������������Minor
Compaction����������ܴ��ϵͳ��Դ���ģ�������Ϊ���ò���������Minor Compaction̫��Ƶ��������Region����̫������·���Major
Compaction��
�۲�ȷ�ϣ��۲�ϵͳIO��Դ�Լ�������Դʹ��������ٹ۲�Compaction���г��ȣ�ȷ���Ƿ�����Compaction����ϵͳ��Դ���Ĺ���
�Ż����飺
(1)Minor Compaction���ã�hbase.hstore.compactionThreshold���ò���̫С���ֲ�������̫����˽�������Ϊ5��6;hbase.hstore.compaction.max.size
= RegionSize / hbase.hstore.compactionThreshold
(2)Major Compaction���ã���Region���ӳ�����ҵ��( 100G����)ͨ�������鿪���Զ�Major
Compaction���ֶ��ͷ��ڴ�����СRegion�����ӳٲ�����ҵ����Կ���Major Compaction����������������;
(3)�ڴ����������Compaction���ԣ�������stripe-compaction�����ṩ�ȶ�����
HBase��������Ż�
HBase������ƶԶ�����Ӱ��Ҳ������Ҫ�����ص���ֻӰ�쵥��ҵ�������������Ⱥ����̫��Ӱ�졣���������Ҫ�����������飺
1. Bloomfilter�Ƿ�����?�Ƿ����ú���?
�Ż�ԭ����Bloomfilter��Ҫ�������˲����ڴ�����RowKey����Row-Col��HFile�ļ����������õ�IO��������������������HFile�ļ����Ƿ���ܴ��ڴ�������KV����������ڣ��Ϳ��Բ�������IO���ļ�����seek������Ȼ��ͨ������Bloomfilter�������������д�����ܡ�
Bloomfilterȡֵ��������row�Լ�rowcol����Ҫ����ҵ����ȷ������ʹ�����֡����ҵ�����������ѯ����ʹ��row��Ϊ��ѯ������Bloomfilterһ��Ҫ����Ϊrow�������������������ѯʹ��row+cf��Ϊ��ѯ������Bloomfilter��Ҫ����Ϊrowcol�������ȷ��ҵ���ѯ���ͣ�����Ϊrow��
�Ż����飺�κ�ҵ��Ӧ������Bloomfilter��ͨ������Ϊrow�Ϳ��ԣ�����ȷ��ҵ�������ѯ����Ϊrow+cf����������Ϊrowcol
HDFS����Ż�
HDFS��ΪHBase�������ݴ洢ϵͳ��ͨ����ʹ�����������Դ洢HBase�����ļ��Լ���־�ļ�����HDFS�ĽǶ����ϲ㿴��HBase�������Ŀͻ��ˣ�HBaseͨ���������Ŀͻ��˽������ݶ�д���������HDFS������Ż�Ҳ��Ӱ��HBase�Ķ�д���ܡ�������Ҫ��ע�����������棺
1. Short-Circuit Local Read�����Ƿ���?
�Ż�ԭ������ǰHDFS��ȡ���ݶ���Ҫ����DataNode���ͻ��˻���DataNode���Ͷ�ȡ���ݵ�����DataNode���ܵ�����֮���Ӳ���н��ļ�����������ͨ��TPC�����ͻ��ˡ�Short
Circuit���������ͻ����ƹ�DataNodeֱ�Ӷ�ȡ�������ݡ�(����ԭ���ο� �˴� )
�Ż����飺����Short Circuit Local Read���ܣ��������ô� ����
2. Hedged Read�����Ƿ���?
�Ż�ԭ����HBase������HDFS��һ�㶼��洢���ݣ��������Ȼ�ͨ��Short-Circuit Local
Read���ܳ��Ա��ض���������ijЩ��������£��п��ܻ������Ϊ�����������������������Ķ�ʱ�䱾�ض�ȡʧ�ܣ�Ϊ��Ӧ���������⣬��������������˲������Ի���
�C Hedged Read���û��ƻ�������ԭ��Ϊ���ͻ��˷���һ�����ض���һ��һ��ʱ��֮��û�з��أ��ͻ��˽���������DataNode������ͬ���ݵ�������һ�������ȷ��أ���һ���ͻᱻ������
�Ż����飺����Hedged Read���ܣ��������òο� ����
3. ���ݱ������Ƿ�̫��?
���ݱ����ʣ�HDFS����ͨ���洢���ݣ����統ǰRegionA����Node1�ϣ�����aд���ʱ��������Ϊ(Node1,Node2,Node3)������bд����������(Node1,Node4,Node5)������cд��������(Node1,Node3,Node5)�����Կ�������������д�뱾��Node1�϶���дһ�ݣ����ݶ��ڱ��ؿ��Զ�����������ݱ�������100%�����ڼ���RegionA��Ǩ�Ƶ���Node2�ϣ�ֻ������a�ڸýڵ��ϣ���������(b��c)��ȡֻ��Զ�̿�ڵ���������ʾ�Ϊ33%(����a��b��c�����ݴ�С��ͬ)��
�Ż�ԭ�������ݱ�����̫�ͺ���Ȼ����������Ŀ�����IO����Ȼ�ᵼ�¶������ӳٽϸߣ����������ݱ����ʿ�����Ч�Ż���������ܡ����ݱ����ʵ͵�ԭ��һ������ΪRegionǨ��(�Զ�balance������RegionServer崻�Ǩ�ơ��ֶ�Ǩ�Ƶ�),���һ�������ͨ������Region��Ǩ�����������ݱ����ʣ���һ����������ݱ����ʺܵͣ�Ҳ����ͨ��ִ��major_compact�������ݱ����ʵ�100%��
�Ż����飺����Region��Ǩ�ƣ�����ر��Զ�balance��RS崻���ʱ����Ǩ��Ʈ�ߵ�Region��;��ҵ��ͷ���ִ��major_compact�������ݱ�����
HBase�������Ż�����
�ڱ��Ŀ�ʼ��ʱ���ᵽ���ӳٽϴ������ֳ����ı�����ҵ��������Ⱥ��������Լ�ij��ҵ�������֮������ҵ���ܵ�Ӱ�쵼��������ӳٺܴ��˽��곣���Ŀ��ܵ��¶��ӳٽϴ��һЩ����֮�����ǽ���Щ����������¹��࣬���߿����ڿ�������֮���ڶ�Ӧ�������б��н��о��嶨λ��



HBase�������Ż��ܽ�
�����Ż����κ�һ��ϵͳ���������Ļ��⣬ÿ��ϵͳҲ�����Լ����Ż���ʽ�� HBase��Ϊ�ֲ�ʽKV���ݿ⣬�Ż����ָ��ⲻͬ������������˷ֲ�ʽ�����Լ��洢ϵͳ�Ż����ԡ������ܽ��˶��Ż��Ļ���ͻ�Ƶ㣬��ʲô���Եĵط�����ָ�����в����Ҳ����һ��̽�ֽ���! |






