|
导读:本文介绍百度基于Spark的异构分布式深度学习系统,把Spark与深度学习平台PADDLE结合起来解决PADDLE与业务逻辑间的数据通路问题,在此基础上使用GPU与FPGA异构计算提升每台机器的数据处理能力,使用YARN对异构资源做分配,支持Multi-Tenancy,让资源的使用更有效。
深层神经网络技术最近几年取得了巨大的突破,特别在语音和图像识别应用上有质的飞跃,已经被验证能够使用到许多业务上。如何大规模分布式地执行深度学习程序,使其更好地支持不同的业务线成为当务之急。在过去两年,百度深度学习实验室在徐伟的带领下开发了分布式深度学习平台PADDLE(Parallel
Asynchronous Distributed Deep Learning),很好地满足了许多业务需求。但由于PADDLE是独立的深度学习平台,不能很好地跟其他业务逻辑结合,导致PADDLE与其他业务逻辑间的数据通路成为了性能的瓶颈。为了让更多的业务使用上深度学习技术,我们开发了Spark
on PADDLE平台,让PADDLE变成百度Spark生态系统的一个功能模块。在第一版完成之后,我们发现CPU计算能力已经满足不了百度巨大的数据量需求,于是我们在Spark
on PADDLE的基础上增加了对异构的支持,充分利用了GPU和FPGA等资源去加速PADDLE上的作业。
深度学习系统PADDLE的设计
PADDLE是一个成熟的分布式深度学习平台,广泛应用于百度的图像识别、自然语言理解、语音、无人车等领域,其主要的特点是训练算法高度优化,支持多GPU/CPU训练,训练效率高,对稀疏特征有独特的优化。
现有的深度学习平台,一般都是通过单机方式进行训练,如开源的Caffe平台也是通过单机多卡的方式进行训练。但当数据或者模型规模上去以后,要提高训练效率,必然要进行分布式训练,主要有数据并行和模型并行两种方法。
数据并行是分布式深度学习用得最多的并行方法。所谓数据并行,就是因为训练数据规模非常大,需要把数据拆分,把模型分布到N个机器训练。但是因为最终训练的是一个模型,同时每个机器只能分配到一部分数据,训练的同步和收敛性必须得到保证。最经典的做法是在《Parameter
Server for Distributed Machine Learning》中提到的用参数服务器(Parameter
Server)的方法。具体的想法是用模型参数服务的方法来同步参数的更新,每个参数服务器只负责同步公共参数的一部分。举个例子来说,如果模型M,被分布到N个机器上面训练,每个机器拿到一部分数据.
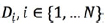
假设训练的参数集合是W,每个机器首先进行本地训练,假设他们初始化参数都是
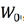
根据
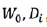
每台机器都能算出相应的代价函数的梯度,一般按照单机神经网络反向传播的方式,每个层都可以梯度来得到参数的修正值,这样参数就变成

因为是多机,每个节点对参数的修正量不同,就会多了一个步骤把各自参数的修正量push给参数服务器,由它统一决策下个训练循环的修正量,这样大家的训练模型就会被统一起来。
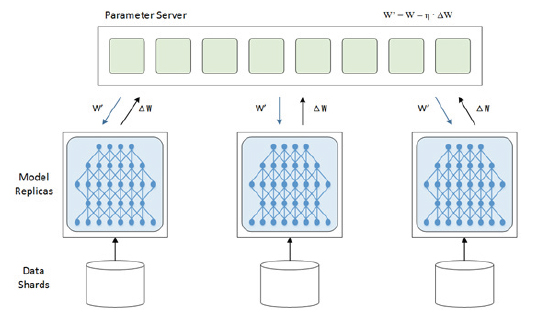
图1 数据并行
图1展示了深度学习数据并行的部署架构。一般分为以下步骤;
1.训练数据预处理,把数据切分为data shards;
2. 每个机器得到同样的模型定义,并且统一初始化参数;
3. 对于每个训练循环,每个机器算各自的梯度,并且把梯度修正量push给参数服务器,参数服务器统一计算,并且把下一轮迭代的参数push给本地训练机器;
4.不断循环,直到模型收敛
参数服务器的更新算法还分为同步和异步的区别。因为严格同步的方法会让本地训练机在每一个训练迭代都会进行参数的同步更新,这样在有慢节点的情况下,整个训练都会被拖慢。异步参数更新的想法是让参数同步的频率变长,这样可以让本地训练机迭代好几个回合以后再进行参数同步,这样的做法有利有弊,好处是慢节点对这个训练的影响变小,坏处是每个模型训练可能会浪费训练周期,因为同步以后的修正量可能跟本地训练机做的修正量有很大的不同。这其中对于同步频率的把握和异步收敛性的问题都是研究的方向。
模型并行方法如图2所示,针对参数规模达到单机无法载入的量级或者模型间存在很少连接的区块的场景,可以考虑做模型并行,但是模型并行通信开销和同步消耗超过数据并行,效率可能没有数据并行高。
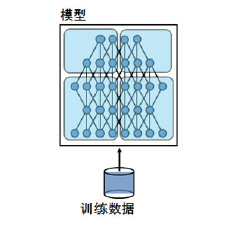
图2 模型并行
PADDLE的设计主要采用了单机做到模型并行、多机做到数据并行的方式,从而达到亿级模型规模以上,大规模数据量的分布式训练。
PADDLE与业务逻辑结合的痛点
PADDLE是一个独立的深度学习平台,不能很好地支持把数据从其他平台接入的需求。研发人员通常要等上一阶段的工作完成产生PADDLE的输入数据后,把数据先存入HDFS,再读到PADDLE集群的本地内存与硬盘,等数据准备好以后再用PADDLE去训练模型。等模型训练好后,再把模型存在HDFS里,让下一个业务逻辑去读取。这个过程不仅耗时长,成为整个计算流程的瓶颈,并且都是重复性的枯燥工作,影响了PADDLE平台的推广,让很多有需要的团队没法用上深度学习技术。
为了解决这个问题,我们设计了Spark on PADDLE架构,把Spark与PADDLE耦合起来,让PADDLE成为Spark的一个模块。如图3所示,模型训练可以与前端的功能整合,比如特征提取通过RDD的形式进行数据传递,无需通过HDFS进行数据导流。这样一来,PADDLE与业务逻辑间的数据通路不再是性能瓶颈。

图3 基于百度Spark的通用业务逻辑
Spark on PADDLE架构1.0版
Spark是近几年快速兴起的大数据处理平台,不仅仅在于它的计算模型比传统的Hadoop
MapReduce要高效很多,同时在于它所带来的生态系统非常强大。基于Spark计算引擎构建的上层应用如Spark
SQL、Spark Streaming、Spark MLlib等,都是很优秀的应用,比传统应用性能好几倍,并且更加稳定。同时与Yarn/Mesos的结合让Spark对计算资源的管理和分配更加灵活。
Spark在百度内部已经广泛应用,主要用于数据处理和数据分析。但是传统的数据处理平台必定会有根据数据训练模型的机制,广告系统的CTR预测就是一个例子,对于用户产生大量的点击和浏览日志,Spark可以进行处理和清洗。但是对于大规模模型的训练,Spark
MLlib的支持还是有限,特别是对于深度学习的支持,所以需要解决在Spark上支持PADDLE的问题。
对于用户的应用程序,Spark叫驱动节点(Driver),可以视为Spark用户分布式程序调度和程序流控制的主节点。Spark程序的具体运算都分布在Worker
Node上面的Executor跑。Spark还有一个非常重要的概念叫RDD,这是一个分布式的分区(partitioned)数据抽象集。Spark所有输入和输出数据都是以RDD为导向的,它不仅描述了数据集的依赖关系,同时还对数据进行了逻辑上的切分,对一个RDD操作一般都是partition来并行的。
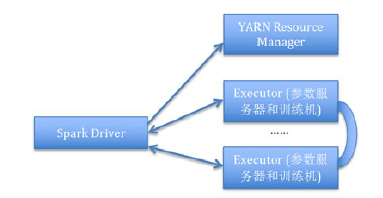
图4 Spark DNN训练运行构架
Spark DNN训练运行构架如图4所示,训练一般分为以下5个步骤:
1.DNN 数据预处理和训练特征准备
一般这是Spark的强项,不管是流式数据还是已经落盘的数据都通过Spark来进行数据处理,其中包括数据清洗、特征准备,然后把得到的训练数据用RDD输出。
2.资源申请
Spark训练任务提交的时候先从Yarn那里拿到对于DNN训练任务的节点资源,比如说一个训练任务需要4个有4
GPU机器的节点。Yarn会对资源做Container式的管理,不管CPU还是GPU对于Yarn来说都是一个虚拟的资源。后文会做具体介绍。
3.训练初始化
Driver会根据Yarn分配的资源相应分发模型配置。模型训练资源库,并且启动训练机和参数服务器,同时初始化模型的初始参数。
4.模型训练
训练的数据会以RDD的方式输入到训练机接口,以数据并行的方式进行训练,并且启动的训练机会跟参数服务器通信,完成梯度交换和参数同步,当训练最大迭代达到或者模型收敛,则训练终止。
5.模型预测
模型可以传入某一个服务器集群或者以Spark Streaming的方式进行载入并且预测。
在Spark on PADDLE 1.0开发的过程中,我们验证了Spark确实可以把ETL、训练数据预处理和深度学习训练结合起来,同时发现百度内部有很多深度学习需求,需要在1.0的基础上考虑把Spark
on PADDLE平台化,做到Multi-Tenancy的资源管理、训练监控、训练容错等等。
Spark on PADDLE 架构2.0版
平台化是Spark on PADDLE 2.0的主要目标。它引入了更多的功能,主要包括在训练过程中引入了监控机制、容错机制,加入了ML决策模块做超参数选择等。下面是对Spark
on PADDLE 2.0设计的分析。
如图5、图6所示,客户可以直接与Spark DNN Driver通信启动DNN训练,Spark
DNN Driver启动一个训练实例(Training Instance),并且透传训练数据、训练网络配置等信息。一个训练实例包括了训练所需的整体服务,包括一组训练器以及对应的参数服务器。然后有一个训练Master(Training
Master)来管理整个的训练进程。同时训练Master管理训练器和超参数服务器的生存周期和失败重启。参数服务器和训练器会定期给训练Master发送heartbeat,确保其正常运行。
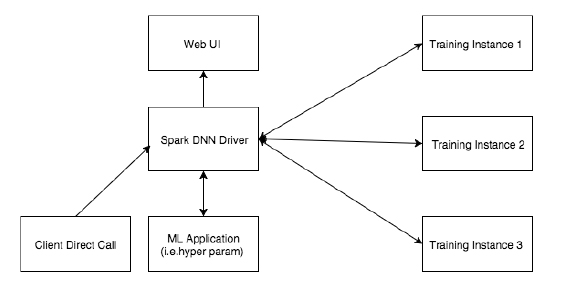
图5 Spark on PADDLE 2.0 总体架构
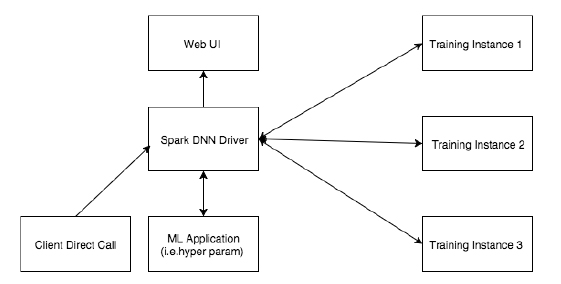
图6 Spark on PADDLE 2.0 Training Instance架构
训练过程中的监控机制
当训练开始以后,用户会对训练过程中的一些数据进行监控,包括训练的每个迭代的loss值、错误率、所用的时间以及训练机和参数服务器的日志进行监控,我们在实现的过程中会在Worker端用消息传递的方式(AKKA)向Driver端汇报训练的数据。对于整个Spark
Job的性能数据会依赖Spark本身提供的监控功能,所有信息都反馈在监控页面中(Web UI)。
训练过程中的容错机制
因为DNN在训练过程中,训练机和参数服务器都是有可能失败的地方。最简单的容错方式是定期对模型的参数和训练信息做备份,当模型训练失败以后,从备份点开始重启模型训练就可以。训练Master会把这些信息收集起来,并且汇报给Spark
DNN Driver。对于参数服务器的容错,可以采取增加冗余的方法,如果一个参数服务器挂掉,训练Master会负责重启相应服务,但是会有一个备份的参数服务器去负责挂掉的参数服务器的参数更新。
超参数选择

图7 超参数选择训练
超参数是确立模型训练的基础,Spark在MLlib中引入了超参数选择模块,主要的做法就是通过一定的超参数选择算法对模型进行并行训练,最终选择的超参数将会被用做最终的模型训练。超参数的选择对于深度学习很有意义,包括网络拓扑、参数的衰减率、触发函数的选择都是影响深度学习的超参数。图7显示了一个大概的超参数选择流程,模型的特征选择到归化系数(Regulation
Parameter)一起配对来训练一个模型,最终评估模块选择最终超参数。在Spark的场景中,DNN Driver端会跟评估端通过RPC通信来决策需要尝试什么超参数。评估端逻辑是在Spark
DNN Driver依赖的MLApplication服务。如果用户需要对DNN训练模型进行超参数选择,则Spark
DNN Driver会根据不同参数配对启动多个训练实例,然后根据训练来是否需要进一步搜索。
Spark异构分布式计算平台架构
如上所述,我们已经看到Spark on PADDLE能够使得传统的深度学习可以在更大规模的分布式系统上运行。但是,百度面临非常现实的问题就是巨量的数据。在百度内部,每天处理的数据量都远远超出了传统平台的能力,会使用到巨量的模型参数、特征以及训练数据。这些巨量数据对分布式系统的性能和扩展性都提出了更高的要求。一方面,我们希望提供可以比拟传统MapReduce集群规模的深度学习计算集群,可以并行运行大量的深度学习任务;另一方面,每个深度学习模型不可能无限制地切分成更小的单元,因此每个节点的模型处理能力也是至关重要的。
目前以CPU为主的计算节点受到本身计算能力的限制,远远不能满足计算的需求,因此,我们需要通过更强大的异构计算来加速现在的计算平台。目前我们的项目主要涉及到两种计算资源:GPU和FPGA。GPU可以提供强大的计算能力,适用于高密度的计算类型;FPGA有低功耗、高度可定制的特点,适合加速很多特定的动态任务(本项目使用的FPGA硬件加速由百度美国研发中心的计算团队提供)。
我们的项目正是基于Spark on PADDLE,探索了如何有效地把异构资源整合到现在的大规模分布式系统,以提供高应用性能和易用性为目标。在满足前述要求的基础上,系统需要动态地对GPU/FPGA资源进行管理,进行无缝的调度,正如CPU和Memory等资源的调度一样。这一功能是通过把资源调度整合到开源的Yarn系统来实现的,而资源隔离方案基于业界流行的Container技术。
同时,我们还需要提供简单易用的编程接口,以便现有的应用程序可以更快地迁移到我们的系统上来。因为Spark所有的数据都是基于RDD的,我们创建了一类新的RDD,通过这个RDD,程序可以直接使用到底层的GPU/FPGA来加速相应的计算。我们知道,真正在GPU/FPGA上完成程序的功能,还需要提供Kernels,这里我们采用了业界最为流行的标准OpenCL接口,以便于将程序移植到不同的GPU/FPGA。可以看到,一个特定的功能实现需要3个部分:一个Scala
Driver,一个C++的Worker以及一个OpenCL Kernel(on GPU/FPGA)。如果常用的功能已经集成在MLlib中,那么用户只需要创建自己的Scala
Driver,通过新的RDD调用库里面已经支持的函数,就可以无缝享受到GPU/FPGA资源的加速。
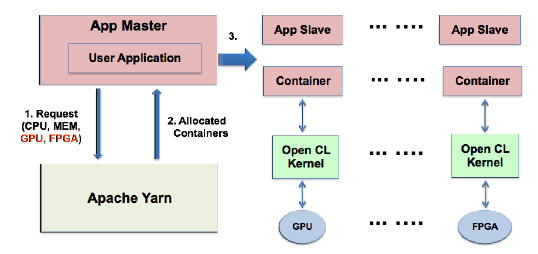
图8 Spark异构计算平台架构
异构系统架构如图8所示。系统的运行过程如下:
1.首先用户应用程序(Scala Driver)会由App Master启动;
2.然后用户应用程序会向Yarn请求其所需的资源,其中GPU、FPGA作为不同的资源类别,与请求CPU资源方式完全一致;
3.用户应用程序取得所有资源,由App Master在相应的App Slave上启动Container运行用户程序的一个Scala
Worker;
4.这时,按照程序Scala Worker的需求,如果使用到了新的RDD,便会调用相应的C++的OpenCL程序,如果函数功能是MLlib内嵌的,那么这部分对用户也是完全透明的。
5.OpenCL程序启动后,会把所分配的数据传输到GPU或FPGA上,然后在GPU或者FPGA上动态启动特定的OpenCL
Kernel,处理这些已经传输过来的数据。
6.OpenCL Kernel计算完成后,数据会自动被拉回到主存,这时OpenCL的程序就可以把结果返回给Scala
Worker;
7.最后所有Scala Worker把结果提交给在App Master上运行的用户程序Scala
Driver。
可以看到,整个流程支持加入了新的GPU/FPGA计算资源,还有需要用户使用新的RDD。其他方面对用户程序来说没有任何额外的改动。
Spark异构平台性能评估
在异构平台架构搭建好后,我们首先测试了机器学习底层矩阵运算库的CPU与GPU性能对比。结果显示,在执行同一个计算方程时,GPU的加速效果很好,对CPU的加速比大约是30倍。与此同时,百度美国研发中心计算团队也对Kmeans算法用FPGA进行加速,取得了15到20倍的加速化,而且FPGA能耗只是CPU的20%。在第二个实验中,我们对比了Spark
on PADDLE在训练ImageNet时的GPU与 CPU加速比,发现使用GPU可以加速30倍,也就是说,在使用异构平台后我们只用3%的机器资源就可以完成同样的计算。
在很好地了解了异构平台加速比后,我们也研究了异构平台的可扩展性。测试结果如图9所示,基本上随着GPU资源的增加,计算时间也在线性地降低,表现出很强的可扩展性,可以承受很大的数据量与计算量。
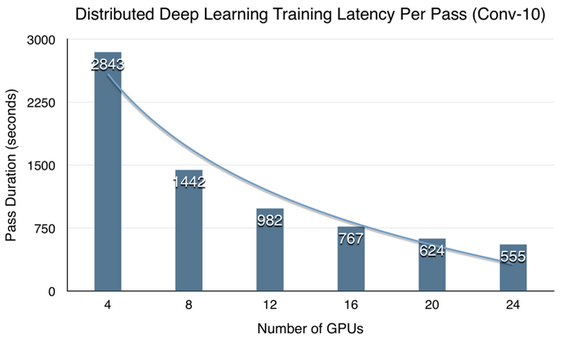
图9 Spark异构计算平台性能数据
总结
本文介绍了百度基于Spark的异构分布式深度学习系统。把Spark与深度学习平台PADDLE结合起来解决了PADDLE与业务逻辑间的数据通路问题,使业务方可以很容易地使用深度学习技术。在此基础上,我们使用GPU与FPGA的异构平台极大地提升了每台机器的数据处理能力。在异构平台上,我们使用YARN对异构资源做分配,以支持Multi-Tenancy,让资源的使用更有效。下一步工作我们打算把平台推广到百度不同的业务平台,比如语音、百度秘书、百度图搜、百度无人车等,让平台在不同业务上锤炼。在平台更成熟后,我们打算把Spark
on PADDLE以及异构计算平台开源,回馈社区。
|






