| 在2016
Hadoop技术峰会的主题演讲上,星环科技创始人孙元浩深入浅出的阐述了Hadoop是如何推动数据仓库技术进行深刻变革。
一、数据库技术进入战略转折点
今年大会的主题是Hadoop十年。2006年雅虎等团队开始研发Hadoop技术至今已整整十年。在此之间技术发展迅速,Hadoop上的生态系统逐渐扩大。各个行业的用户逐渐开始基于这一新的技术来开发全新的应用,甚至将原先的应用向Hadoop之上进行迁移。未来,Hadoop会成为企业数据中心的核心。经过这10年的发展,今年开始进入一个战略转折点(strategic
inflection point)。这意味着新的技术开始逐渐取代和超越老的技术,并在各个行业迅速发展。未来的若干年之内,取代过程会不断加速。星环近3年的发展,经过持续的研发、投入以及大量的案例积累,达到新的高度。去年12月份Gartner分析师把星环科技(Transwarp)列为了国际主流的Hadoop发行版厂商之一,其他几家包括Cloudera、Hortonworks、MapR。另外还有两家公司分别是IBM和Pivotal,他们采用Open
data Platform。全球共有6家公司上榜,星环也很荣幸能成为其中一家。

今年2月份Gartner发布的数据仓库魔力象限当中,星环科技也被放入了远见者(Visionaries)象限当中。这个象限里基本上都是采用
Hadoop技术的创业公司。这些公司采用全新的技术,逐渐替代传统数据库来构造新的数据平台。另外虽然目前领导者象限(Leaders)仍是大厂商,如
Oracle、Teradata等,但是经过这10年的经验技术的积累,逐渐达到战略转折点,技术的取代过程明显加速。如果关注这些领导者公司股票在过去一年的价格变化,就会发现市场预期在2016至2017年技术会发生非常大的变化。在企业客户中,使用新技术的步伐会明显加速。
二、中美Hadoop应用统计对比
今天我演讲的题目是介绍Hadoop是如何推动数据仓库技术进行深刻变革的。这里有一组统计数据:
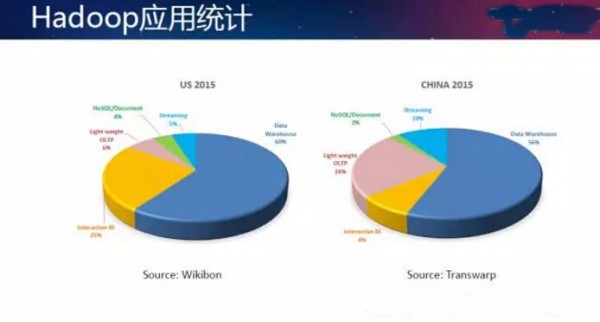
左边的数据是Wikibon的分析师做的美国市场中Hadoop新技术的应用场景统计。他采访了上千名Hadoop的用户,这其中有60%的用户使用
Hadoop技术来做数据仓库,有25%的用户是按照交互式BI的,在 Hadoop之上用报表工具、可视化工具来做交互式分析数据报表。同时有6%的用户是在用HBase、Cassandra来做OLAP的简单轻量级
Key-Value查询。有4%用户使用MongoDB、Couchbase文档式数据库进行文档存储,还有5%的用户使用流处理来做实时数据研判,由此构成一个完整的100%的应用分类。当然还有可能有一些其他的应用漏掉了,但这几个是主要的应用产品。
在中国市场,根据我们的样本中几百名企业用户进行统计,结果跟美国稍微有点差异。分析结果显示,有56%的客户是做数据仓库的,包括ODS、
ETL、数据清洗等,如在我们的客户中,用于取代关系型数据库提供完整的数据仓库支持,来建构各种主题模型。这个比例是比较接近美国用户的。但是我们只有
8%的用户在做交互式BI。自主BI这一块在国内也开始兴起。注意到和美国市场相比,显著不一样的地方在于我们有24%的客户是用来做轻量级查询的,这个百分比指的是客户数量占比而不是客户集群规模(构成的集群节点数量)。这个比较有趣的现象说明,实际上在中国,应用比较简单,因为客户的数据量非常巨大,才会使用新技术解决问题。实际上中国客户的数据量,跟美国同类型客户的数据量相比是要大一个数量级(10倍)的,简单的查询对中国的客户来说是有巨大的困难的。所以我们可以看到有24%的客户在用Hyperbase(HBase)组件进行简单查询。还有2%的客户是用我们的产品来进行文档的搜索和图检索。另外还有个很大的不同是有10%的用户是用流处理的。从图中就可以发现,我们国家的工业4.0制造业传感器的网络建设速度是快于美国的。我们的用户群中比例明显就超过了美国的市场比例。
三、传统数据仓库面临的四大挑战
实际上大家可以看到,Hadoop技术在过去一段时间之内,至少在2015年逐渐开始往数据仓库方向转变。当然,Hadoop在早年刚开始创建的时候,主要也是作为数据仓库的,所以现在越来越多的行业也开始用Hadoop技术做数据仓库。那么什么是数据仓库?Gartner的解释是:数据仓库不仅是一个单一的数据库,它是一整套的数据管理系统,包含很多的辅助工具、一些设计理念和管理方法。传统的数据仓库技术,经过快20年或者更长时间的发展,已经面临了一些瓶颈。
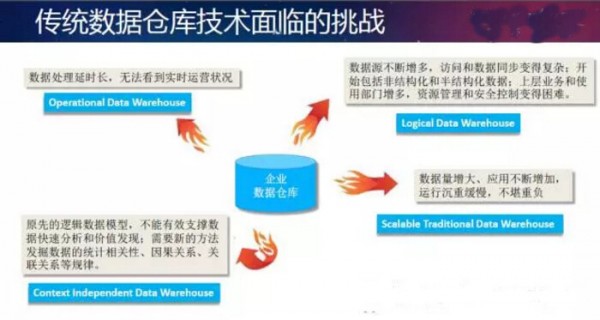
第一个问题,我们看到随着数据量增大,包括复杂程序应用的增多,传统数据仓库越来越不堪重负。我们有一个客户在数据仓库建立了5000个统计报表应用。我们也有客户使用着数据量近20个PB的商业系统。对于大部分的企业用户,数据量一般在几十个TB
或者几百个TB左右。这么大的数据量对传统的仓库系统来说是非常大的负担。单一的数据仓库无法处理这么大量的数据,所以在这一块需要新的技术,特别是利用分布式计算来取代原本单一的计算方式来进行横向扩展。我们认为Hadoop技术能成功的最根本的原因是它是从单机的集中式运算变成了分布式计算,这是它最大的计算模式的演变。把集中计算变成分布计算是一个必然趋势,这是碰到的第一个困难,一是需要一些新型的分布式数据库技术进行性能的加速,来处理这种几百
TB或者上PB的数据量。二是随着数据源的不断增多,访问数据的方式变得非常复杂。我们很多客户有几百个库表,有几千上万张表,这样复杂的数据模型通常很难把所有数据存储到一个数据库当中,只能分摊到很多个库当中。对数据的使用者带来了很大的困难,因为他们需要把多种数据全部存储起来。这个是第一个大的困难。
第二个问题是数据的类型发生变化,过去是以结构化数据为主,80%是结构化数据。现在非结构化数据逐渐增多,这个值开始反过来,80%是非结构化数据和半结构化数据。但是从价值度来讲,
80%的价值密度仍然是来自于结构化数据。而对于企业来讲,需要这些非结构化数据,进行存储分析。另外在数据源变多以后,用户和业务部门也变多。这些部门之间如何进行资源有效管理和隔离,变成一个非常严重的问题。例如过去有些银行客户是采用行政处罚措施,如果有人写一条SQL,把数据仓库资源耗尽,导致其他人不能使用,那么这个人今年的奖励就没有了。采用这种方式是没有效果的,因为用户根本就不知道他写的这个SQL,会不会把数据仓库跑挂掉。另外做访问控制也是很痛苦的,为了使不同的分支机构只能访问自己的数据,需要创建视图。如果用户有1000张表,同时还有几十个分支机构,那么久需要创建上万个视图,这对数据的视图管理会带来巨大的挑战。所以在几年前,分析机构就提出要建逻辑数据仓库。逻辑数据仓库就是在过去几年当中一直被数据仓库领导者反复强调,我们需要去建一个逻辑上大的数据仓库,他底下可以包括多个数据源―-通过database
federation(数据联邦)功能,同时它可以跨多种数据源,可以把结构化数据和非结构化数据统一处理。Michael
Stonebraker在前段时间讲过,未来不管是传统数据库技术还是大数据技术,大家都会统一到使用SQL接口,包括结构化数据与非机构化数据,非结构化数据也会被结构化后进行处理。所以逻辑数据仓库适应于这种变化,通过统一接口统一方式访问数据源,完成跨各种数据源的访问,同时也会建造一个有多租户管理、资源管控的环境,能够被很多部门、用户进行使用。这从理论上来讲是区别于传统数据仓库的应用场景。
第三个挑战是数据处理的延时太长。过去整个数据架构前面是OLTP系统,中间是ODS,后面是数据仓库层,再往后是数据集市。那么在数据仓库这一层,数据是T+1的,意味着第二天才访问前一天的数据。但是很多行业需要更实时的数据,为了了解当前的生产运营状况,它们需要基于T+0、准实时的,甚至是实时的几分钟几秒钟之内的数据。这种需求就演变成第三种数据仓库运营模式――Operational
Data Warehouse。这种业务模式的设计初衷是希望把数据实时或准实时的导入到数据仓库当中,能够对实时数据进行快速的分析和挖掘。传统的数据仓库是每天晚上数据导入,花7-8个小时进行批处理计算,第二天才能看到报表。所以传统技术面临一个普遍的问题:不能实现实时处理。
第四个挑战是原先的逻辑数据模型不能有效支撑数据快速分析和价值发现。过去大家做统计是对数据做一些常见的聚合以及连接关联操作。遵循关系数据库的模式,有很多模型和各种范式,像很多厂商在相关行业设计了十大主题模型、八大主题模型,中间数据的关联程度是非常高的。一个有几千个数据源表的业务系统,中间层需要用上万张数据表来满足它的模型。这样一个复杂的模型所带来的弊端就是数据结构一旦发生变化或者增加时,模型就不堪重负。预先设定的模型没法适应业务的快速变化,所以我们经常能看到银行花几年时间建立一个数据仓库,反复投入,每年在改造它。近期了解到一家银行科技部门,前后10年投入十几亿来建数据仓库。而今天一方面大量数据在产生,同时新的数据也在增加,有些来自内部的数据,有些来自新的外部数据。数据处理方法的确到了应该变革的时候。通过利用新的机器学习的统计方法,不仅做传统SQL的统计,还希望能够从数据关联上面发现规律、关联模式、时序上的特征。通过对它进行一些预测分析,能够发现统计学意义上的因果关系。这就变得对企业更加重要。这一块是第四种数据仓库新的设计模式,叫context
independent data warehouse,也就是说抛弃这些逻辑关联模型,在不知道这些模型的情况下,也能通过机器学习的方法找到数据之间的关联关系,能够找到他们之间统计学的因果关系。
四、全新的数据仓库设计模式
这四个应用模式,这四个困境引出了新的数据仓库的设计模式。意味着这四种应用模式需要全新的技术支撑,这也是我们看到新的技术,特别是Hadoop产生以后,衍生出来新的技术演进逐步在满足这些需求。
现在讲第一个,传统数据仓库为了应对数据量的增加,需要采用新的方式。我们看到计算模式在过去的十几年里发生了非常明显的变化,从单机开始,首先是第一步计算并行化。计算并行化就是我们称为并行数据库――数据库引擎并行化,但是对存储无法有效扩展,所以就演变出了第二代计算和存储的分布式化,产生了第二代分布式技术,大规模并行数据库就是MPP数据库,这个数据库解决了一部分问题――几个TB级别的数据的高速处理问题。但是在数量增加的时候,又遇到一个瓶颈,它需要一个新一代的技术。新一代的计算模式发生了变化,这个是Google在2003、2004年中发布的两篇论文中,解释了
MapReduce的计算模式。大家发现,经过这么多年发展,MapReduce计算模式仍然是最佳的分布式计算模式,它把计算和存储有效地结合了起来,它仍然是现在最具有扩展性、最具容错性,现在随着我们星环新的技术实现,它甚至是性能最好的计算模式。这样一个演变使得新的数据仓库技术能够处理从几个
TB到几十个PB的数据量,能够线性扩展,而且在每个数量级上都可以比传统的数据处理技术快若干倍甚至一个数量级(10倍)。这里有一组数据,是我们在春节前测试的数据结果,今天的演讲也是为了介绍我们在TPC-DS标准测试集上的最新进展。去年的时候我们已经做到了基于TPC-DS
benchmark从1TB到100TB都能有效地处理,而且处理的性能是,我们用29台机器,能够在40个小时内完成100TB总共99个报表处理。我们测试使用的是普通的两路的服务器,CPU还是比较弱的,今天能够在TPC-DS
benchmark上跑过100TB的数据仓库,应该是屈指可数的。大家可以发现新的技术,在处理100TB上是没有压力的。
第一个问题我们可以通过分布式计算来解决,第二个是通过数据联邦技术处理多数据源以及解决多租户的问题,这个是
Gartner分析师在几年之前提出来的,叫逻辑数据仓库。逻辑data warehouse能够比较有效地解决这个问题。分析师认为,逻辑数仓应该有三个部分。第一个部分是中心的Repository,所有数据全部集中放在这个上面。第二个是需要有一个数据库虚拟化,或者叫数据库联邦技术,能够把多种数据源融合起来,从应用角度来看使用更加方便。第三个是在逻辑数仓之上,最核心的就是分布式计算。同时其中有两个特性是需要满足的,一个就是能不能按需对数据仓库进行扩张、能不能实现多个用户共享一个平台。这个是逻辑数据仓库必须要解决的问题。第二个是对于元数据的管理、对数据质量管理的有效方法、对数据访问要有审计,这也是逻辑数据库核心设计的原则。当然我们这里介绍的两个技术,是星环用来支撑逻辑数据库建设的。
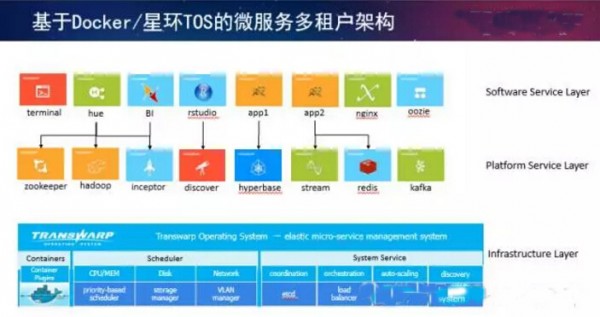
我们在SQL层也支持传统数据库的数据联邦的概念,可以支持DBlink的语法。我们把这个计算分散开,划到多个数据源上面。这里有两种实现方式,一种是传统关系型数据库的方式,把Hadoop作为另外备用的计算引擎。另外一种,星环是建造SQL翻译层,把源数据放到Hadoop上的执行计划里,但是如果数据在关系型数据库上,我们会把SQL给到关系型数据库执行,执行的时候实际上计算仍然是分布式的,仍然在Hadoop上进行运算,只不过数据源在关系型数据库里。这里面有两个优化技术,一个优化是把数据抽取到多个节点上进行分布式计算,同时把SQL中的一些过滤条件下推(pushdown)到关系型数据库。这种方式的变化就是关系型数据库以及传统上现在处于领导者象限的厂商实际上希望是以他们的数据库为主,而我们是希望以Hadoop为主,来构造这样一个数据联邦的实现方案。今天看来,这种技术是最佳的,因为我们的计算是全部分布式化的,所以我们的性能比他们更有优势。第二个,为了构造逻辑数仓引入了微服务的概念,那微服务的实现是用容器来实现的。我们有个产品,也有相应的演讲是介绍新的产品TOS(Transwarp
Operating System),这个产品是基于Docker和kubernetes来构造弹性的基于容器化的计算环境。在这之上我们把传统的数据仓库的应用,即刚才我们讲的上千个应用,全部容器化,放在我们的应用商店当中。应用商店里面的每一项应用都是标准的服务,这些服务在实例化的时候可能会由几百个上千个容器组成。那么我们会把这个应用打包成一个服务,作为整体进行调度。通过这种方式,我们可以有效地实现把数据库本身的服务当成平台服务,能够一件一件部署,能够进行灵活地扩张,同时我们也可以把上层应用像苹果的apple
store安装应用一样,在我们的应用商店中快速地部署。同时,不同应用之间可以通过容器技术进行有效的隔离。
第三种就是实现实时数据仓库。我们需要有一种新的方法把数据实时导入到数仓当中,一种方法是把传统的OLTP数据库通过ETL抽入到一个operational
database当中。过去,这就是 关系型数据库,现在,很多人是用HBase或Cassandra来实现。但是有一个普遍的问题就是数据进入这个operational
database以后,大家需要对数据进行复杂的分析,因为数据仓库是用来做分析的。数据分析的复杂程度可能是在上面跑几十万行SQL统计。同时,它的一个复杂分析可能就有上万行,需要快速地完成。这样的一个要求实际上是很难满足的,因为它的特点是要对数据进行实时的写入,同时也要对它进行复杂的分析,目前没有一项数据库技术能够同时满足这两个需求。当然有的厂商号称既能支持OLTP又能支持OLAP。有一个新的类别叫Hybrid
Transactional &AnalyticalDatabase,这种数据库也有相关分析报告,但目前好像没有技术能比较成熟地来解决这个问题。那我们在实现该设计模式的时候,底层采用的技术其实就是基于Hadoop,我们是在HDFS上构造自己的分布数据库,存储格式改进了ORC的存储格式,可以支持增删查改,也可以支持分布式事务处理。我们前面开发了一个ETL的工具,可以把数据库的日志进行重放,直接插入到ORC事务表里面去。这是一个准实时的操作,通常是几分钟内能完成从交易型数据库实时同步到Hadoop当中,然后在这个上面的做复杂关系,这个分析是非常高效的。这是一种实现方式,但是他的延时还不够快,因为它是分钟级别的,比如是业务数据库,如DB2借助IBM
Datastage把操作日志放出来之后,再解读这个日志,写到仓库中去。但是还有一些客户希望是更实时的,他希望在几秒钟之内能够完成计算,这个时候我们采用第二种方法是把数据与复杂计算前推到流处理框架中去。前置的交易系统通常是采用这种方式,今天有很多金融机构的应用,特别是网银,像互联网金融,全部的交易订单都在消息队列中,如RabbitMQ、Kafka,这个时候我们天生的优势,就是可以直接从交易队列中把数据取出来,在流上进行运算。流上的计算实际上也是在数据仓库中的一个复杂的运算,也有大量存储过程和SQL,这方面星环做了大量的工作,我们能够在流上进行复杂的SQL运算,支持标准
SQL2003和存储过程,包括DB2和Oracle存储过程,也就意味着你可以把原来在后端的复杂的SQL运算前置到流上面来做,例如时间窗口中的数据构成一张表,这张表跟普通表不一样的地方是,它是一直处于变化流动当中。这种方式适合对计算延时要求很高的,我们有一个客户要在一秒钟之内对市场行情进行运算,他有160个复杂模型,有些复杂模型其实是用存储过程来写得偏微分方程的构成。这就意味着我们需要在流上面做复杂计算,然后延时要在几秒钟内完成,新型的高频交易的场合就非常需要这种模式。
第四种数据仓库设计模式指的是,叫context independent
Data warehouse,一种上下文无关的数据仓库设计架构。这个架构通常需要完成几项重要的工作。首先就是说,这个数据仓库应该能够支持关联分析,对于数据和表,能够通过相关性找到它们之间的关联关系,同时也能发现一些统计学上的因果关系。这一块我们是借助R语言来实现的。只不过我们把R语言的很多算法分布式化了,但是对用户来讲,体验是跟R语言一模一样的。如果用户有熟悉R语言的专家,可以很快上手,能够用R语言来做复杂的关联分析和机器学习。其实这一块,也就意味着是不需要复杂模型模式,对数据特征抽取以后就可以进行机器学习,也不需要太多的专家来帮你设计规则,它是通过机器学习方法自动帮你补充的。这是第一大功能,第二是网络分析、图分析的能力。现在特别是社交网络分析、通讯网络分析,又比如银行资金转账链、担保关系、企业投资关系,都要用图的技术来实现。图技术就广泛地运用到金融机构的反欺诈当中。在这样一个数据仓库中,图的分析能力也是一个重要的关键能力。第三块是需要文本的分析挖掘能力,也需要文本制作能力。第四个就是我们希望能摒弃过去设计复杂的逻辑模型,有几万张中间表,这种模型代价非常高,而且固定下来就很难变化。我们希望能自由地进行探索,我们希望能有一个自主的工具对它进行数据挖掘分析,这一块也需要工具上的支撑。所以我们今天在实现这种数据仓库架构的时候,综合使用了我们的绝大部分组件,我们使用了Inceptor分析型数据库,对数据特征进行清洗,甚至SQL能直接用图的算法进行分析。同时,我们在Hyperbase上还能支持文档搜索、文本搜索,也支持大规模图的并发查询,我们对外提供
DataFrame的抽象,就是R语言的DataFrame的抽象,和R语言的原始DataFrame是一样的,可以用R的算法去访问这些
DataFrame,同时我们也提供几十种分布式机器学习算法,让用户来做大规模的机器学习。中间演变出几种应用模式,有风险分析、有精准营销的,也有反欺诈、文本分析。当然我们也综合了传统的R的单机算法包,也提供传统的R的体验。
这些技术组件构建出一个完整的数据仓库。如果把这些数据仓库全部放在一张纸上的话,那我们就能看到整个架构的底层其实是用TOS实现资源管理多租户的能力,用容器来隔离,中间层是一个逻辑数据仓库,把结构化以及非结构化数据全部放到这个逻辑层当中,同时上层是借助TOS创建逻辑集群来构建如自由探索的应用,也可以用来构建传统数据仓库、构造数据集市、构造实时数据仓库。整体来说就是可以用全新的技术来打造一个新的企业数据平台,这也是为什么我们被
Gartner选为数据仓库中在远见象限中是最右边的厂商,是因为我们的技术在支持这四类新的数据仓库中是最领先的而且是最完备的厂商。
|






