������Twitter Storm�ٷ�WikiΪ��������ϸ������ο��ٴһ��Storm��Ⱥ�����У���Ŀʵ�������������⼰�����ܽᣬ����Ӧ�½��ԡ�ע���������ʽ������
1. Storm��Ⱥ���
Storm��Ⱥ�а�������ڵ㣺���ؽڵ㣨Master Node�������ڵ㣨Work Node������ֱ��Ӧ�Ľ�ɫ���£�
���ؽڵ㣨Master Node��������һ������ΪNimbus�ĺ�̨������������Storm��Ⱥ�ڷַ����룬����������������������Ҹ����ؼ�Ⱥ����״̬��Nimbus������������Hadoop��JobTracker�Ľ�ɫ��
ÿ�������ڵ㣨Work Node��������һ������ΪSupervisor�ĺ�̨����Supervisor���������Nimbus�������ִ�е����ݴ�������ִֹͣ������Ĺ������̡�ÿһ����������ִ��һ��Topology���Ӽ���һ�������е�Topology�ɷֲ��ڲ�ͬ�����ڵ��ϵĶ������������ɡ�
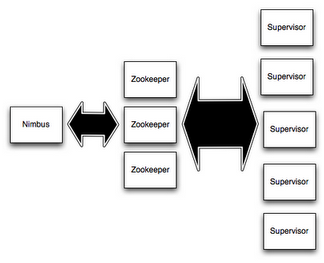
Storm��Ⱥ���
Nimbus��Supervisor�ڵ�֮�����е�Э��������ͨ��Zookeeper��Ⱥ��ʵ�ֵġ����⣬Nimbus��Supervisor���̶��ǿ���ʧ�ܣ�fail-fast)����״̬��stateless���ģ�Storm��Ⱥ���е�״̬Ҫô��Zookeeper��Ⱥ�У�Ҫô�洢�ڱ��ش����ϡ�����ζ���������kill -9��ɱ��Nimbus��Supervisor���̣���������������Լ���������������ʹ��Storm��Ⱥӵ�в���˼����ȶ��ԡ�
2. ��װStorm��Ⱥ
��һ�½ڽ���ϸ������δһ��Storm��Ⱥ�������ǽ�������Ҫ������ɵİ�װ���裺
�Zookeeper��Ⱥ��
��װStorm�����⣻
���ز���ѹStorm�����汾��
��storm.yaml�����ļ���
����Storm������̨���̡�
2.1 �Zookeeper��Ⱥ Stormʹ��ZookeeperЭ����Ⱥ������Zookeeper����������Ϣ���ݣ�����Storm��Zookeeper������ѹ���൱�͡����������£������ڵ��Zookeeper��Ⱥ�㹻ʤ�Σ�����Ϊ��ȷ�����ϻָ����߲�����ģStorm��Ⱥ��������Ҫ�����ģ�ڵ��Zookeeper��Ⱥ������Zookeeper��Ⱥ�Ļ����ٷ��Ƽ�����С�ڵ���Ϊ3��������Zookeeper��Ⱥ��ÿ̨������������°�װ�����裺
1�����ذ�װJava JDK���ٷ���������Ϊhttp://java.sun.com/javase/downloads/index.jsp��JDK�汾ΪJDK 6�����ϡ�
2������Zookeeper��Ⱥ�ĸ����������������Java�Ѵ�С�������ܱ��ⷢ��swap������Zookeeper�����½��������ڼ䣬4GB�ڴ�Ļ�������ΪZookeeper����3GB���ѿռ䡣 3�����غ��ѹ��װZookeeper�����ٷ���������Ϊhttp://hadoop.apache.org/zookeeper/releases.html��
4������Zookeeper��Ⱥ�ڵ�������������¸�ʽ��Zookeeper�����ļ�zoo.cfg��
tickTime=2000
dataDir=/var/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888 |
���У�dataDirָ��Zookeeper�������ļ�Ŀ¼������server.id=host:port:port��id��Ϊÿ��Zookeeper�ڵ�ı�ţ�������dataDirĿ¼�µ�myid�ļ��У�zoo1~zoo3��ʾ����Zookeeper�ڵ��hostname����һ��port����������leader�Ķ˿ڣ��ڶ���port������leaderѡ�ٵĶ˿ڡ�
5����dataDirĿ¼�´���myid�ļ����ļ���ֻ����һ�У�������Ϊ�ýڵ��Ӧ��server.id�е�id��š� 6������Zookeeper����
java -cp zookeeper.jar:lib/log4j-1.2.15.jar:conf \ org.apache.zookeeper.server.quorum.QuorumPeerMain zoo.cfg |
Ҳ����ͨ��bin/zkServer.sh�ű�����Zookeeper����
7��ͨ��Zookeeper�ͻ��˲��Է����Ƿ���ã�
Java�ͻ����£�ִ���������
java -cp zookeeper.jar:src/java/lib/log4j-1.2.15.jar:conf:src/java/lib/jline-0.9.94.jar
\ org.apache.zookeeper.ZooKeeperMain -server 127.0.0.1:2181 |
Ҳ����ͨ��bin/zkCli.sh�ű�����Zookeeper Java�ͻ��ˡ�
C�ͻ����£�����src/cĿ¼�£����뵥�̻߳���߳̿ͻ��ˣ�
/configure
make cli_st
make cli_mt |
���н���C�ͻ��ˣ�
���ˣ������Zookeeper��Ⱥ�IJ�����������
ע�����
����Zookeeper�ǿ���ʧ�ܣ�fail-fast)�ģ��������κδ�����������̾����˳�����ˣ������ͨ����س���Zookeeper������������֤Zookeeper�˳����ܱ��Զ�����������ο����
Zookeeper���й����л���dataDirĿ¼�����ɺܶ���־�Ϳ����ļ�����Zookeeper���н��̲��������������ϲ���Щ�ļ�������ռ�ô������̿ռ䣬��ˣ���Ҫͨ��cron�ȷ�ʽ�������û�õ���־�Ϳ����ļ�������ο�������������ʽ���£�java -cp zookeeper.jar:log4j.jar:conf org.apache.zookeeper.server.PurgeTxnLog <dataDir> <snapDir> -n <count>
2.2 ��װStorm������
����������Ҫ��Nimbus��Supervisor�����ϰ�װStorm�������⣬�������£�
ZeroMQ 2.1.7 �C ����ʹ��2.1.10�汾����Ϊ�ð汾��һЩ����bug�ᵼ��Storm��Ⱥ����ʱ������ֵ����⡣�����û���2.1.7�汾������"IllegalArgumentException"���쳣����ʱ��Ϊ2.1.4�汾������һ���⡣
JZMQ
Java 6
Python 2.6.6
unzip
����������İ汾�Ǿ���Storm���Եģ�Storm�����ܱ�֤�������汾��Java��Python���¿����С�
2.2.1 ��װZMQ 2.1.7
���غ���밲װZMQ��
wget http://download.zeromq.org/zeromq-2.1.7.tar.gz
tar -xzf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
./configure
make
sudo make install |
ע�����
1. �����װ���̱���uuid�Ҳ�������ͨ�����µİ���װuuid�⣺
sudo yum install e2fsprogsl -b current
sudo yum install e2fsprogs-devel -b current |
2.2.2 ��װJZMQ
���غ���밲װJZMQ��
git clone https://github.com/nathanmarz/jzmq.git
cd jzmq
./autogen.sh
./configure
make
sudo make install
|
Ϊ�˱�֤JZMQ����������������Ҫ����������ã�
��ȷ���� JAVA_HOME��������
��װJava������
����autoconf
�������Mac OSX�������
ע�����
1. �������./configure����������⣬�ο����
2.2.3 ��װJava 6
1. ���ز���װJDK 6���ο����
2. ����JAVA_HOME����������
3. ����java��javac�������java������װ��
2.2.4 ��װPython2.6.6
1. ����Python2.6.6��
wget http://www.python.org/ftp/python/2.6.6/Python-2.6.6.tar.bz2
|
2. ���밲װPython2.6.6��
tar �Cjxvf Python-2.6.6.tar.bz2
cd Python-2.6.6
./configure
make
make install
|
3. ����Python2.6.6��
2.2.5 ��װunzip
1. ���ʹ��RedHatϵ��Linuxϵͳ��ִ���������װunzip��
2. ���ʹ��Debianϵ��Linuxϵͳ��ִ���������װunzip��
2.3 ���ز���ѹStorm�����汾
��һ������Ҫ��Nimbus��Supervisor�����ϰ�װStorm���а汾��
1. ����Storm���а汾���Ƽ�ʹ��Storm0.8.1��
wget https://github.com/downloads/nathanmarz/storm/storm-0.8.1.zip
|
2. ��ѹ����װĿ¼�£�
2.4 ��storm.yaml�����ļ�
Storm���а汾��ѹĿ¼����һ��conf/storm.yaml�ļ�����������Storm��Ĭ��������������Բ鿴��conf/storm.yaml�е�����ѡ�����defaults.yaml�е�Ĭ�����á���������ѡ���DZ�����conf/storm.yaml�н������õģ�
1) storm.zookeeper.servers: Storm��Ⱥʹ�õ�Zookeeper��Ⱥ��ַ�����ʽ���£�
storm.zookeeper.servers:
- "111.222.333.444"
- "555.666.777.888"
|
���Zookeeper��Ⱥʹ�õIJ���Ĭ�϶˿ڣ���ô����Ҫstorm.zookeeper.portѡ�
2) storm.local.dir: Nimbus��Supervisor�������ڴ洢����״̬����jars��confs�ȵı��ش���Ŀ¼����Ҫ��ǰ������Ŀ¼�������㹻�ķ���Ȩ�ޡ�Ȼ����storm.yaml�����ø�Ŀ¼���磺
storm.local.dir: "/home/admin/storm/workdir"
|
3) java.library.path: Stormʹ�õı��ؿ⣨ZMQ��JZMQ������·����Ĭ��Ϊ"/usr/local/lib:/opt/local/lib:/usr/lib"��һ����˵ZMQ��JZMQĬ�ϰ�װ��/usr/local/lib �£���˲���Ҫ���ü��ɡ�
4) nimbus.host: Storm��ȺNimbus������ַ������Supervisor�����ڵ���Ҫ֪���ĸ�������Nimbus���Ա�����Topologies��jars��confs���ļ����磺
nimbus.host: "111.222.333.444"
|
5) supervisor.slots.ports: ����ÿ��Supervisor�����ڵ㣬��Ҫ���øù����ڵ�������е�worker������ÿ��workerռ��һ�������Ķ˿����ڽ�����Ϣ��������ѡ����ڶ�����Щ�˿��ǿɱ�workerʹ�õġ�Ĭ������£�ÿ���ڵ��Ͽ�����4��workers���ֱ���6700��6701��6702��6703�˿ڣ��磺
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
|
2.5 ����Storm������̨����
���һ��������Storm�����к�̨���̡���Zookeeperһ����StormҲ�ǿ���ʧ�ܣ�fail-fast)��ϵͳ������Storm����������ʱ�̱�ֹͣ�����ҵ�������������ȷ�ػָ�ִ�С���Ҳ��ΪʲôStorm���ڽ����ڱ���״̬��ԭ��ʹNimbus��Supervisors�������������е�Topologies�����ܵ�Ӱ�졣
����������Storm������̨���̵ķ�ʽ��
Nimbus: ��Storm���ؽڵ�������"bin/storm nimbus >/dev/null 2>&1 &"����Nimbus��̨�����ŵ���ִ̨�У�
Supervisor: ��Storm���������ڵ�������"bin/storm supervisor >/dev/null 2>&1 &"����Supervisor��̨�����ŵ���ִ̨�У�
UI: ��Storm���ؽڵ�������"bin/storm ui >/dev/null 2>&1 &"����UI��̨�����ŵ���ִ̨�У����������ͨ��http://{nimbus host}:8080�۲켯Ⱥ��worker��Դʹ�������Topologies������״̬����Ϣ�� ע����� Storm��̨���̱���������Storm��װ����Ŀ¼�µ�logs/��Ŀ¼�����ɸ������̵���־�ļ���
�����ԣ�Storm UI�����Storm Nimbus������ͬһ̨�����ϣ�����UI��������������ΪUI���̻��鱾���Ƿ����Nimbus���ӡ�
Ϊ�˷���ʹ�ã����Խ�bin/storm���뵽ϵͳ���������С� ���ˣ�Storm��Ⱥ�Ѿ�����������ϣ�������Ⱥ�ύ���������ˡ�
3. ��Ⱥ�ύ����
1������Storm Topology��
storm jar allmycode.jar org.me.MyTopology arg1 arg2 arg3
|
���У�allmycode.jar�ǰ���Topologyʵ�ִ����jar����org.me.MyTopology��main������Topology����ڣ�arg1��arg2��arg3Ϊorg.me.MyTopologyִ��ʱ��Ҫ����IJ�����
2��ֹͣStorm Topology��
���У�{toponame}ΪTopology�ύ��Storm��Ⱥʱָ����Topology�������ơ�
|






