|
随着大数据的越来越普及,HBase也变得越来越流行。会用HBase现在已经变的并不困难,然而,怎么把它用的更好却并不简单。那怎么定义‘用的好’呢?很简单,在保证系统稳定性、可用性的基础上能够用最少的系统资源(CPU,IO等)获得最好的性能(吞吐量,读写延迟)就是’用的好’。HBase是一个庞大的体系,涉及到很多方面,很多因素都会影响到系统性能和系统资源使用率,根据场景对这些配置进行优化会很大程度上提升系统的性能。笔者总结至少有如下几个方面:HDFS相关配置优化,HBase服务器端优化(GC优化、Compaction优化、硬件配置优化),列族设计优化,客户端优化等,其中客户端优化在前面已经通过超时机制、重试机制讲过,后面笔者会继续分别介绍其他三个优化重点。
本节重点介绍列族设计优化,HBase中基本属性都是以列族为单位进行设置的,如下示例,用户创建了一张称为‘ NewsClickFeedback’的表,表中只有一个列族’Toutiao’,紧接着的属性都是对此列族进行的设置。这些属性基本都会或多或少地影响该表的读写性能,但有些属性用户只需要理解其意义就知道如何设置,而有些属性却需要根据场景、根据业务来设置,比如BLOCKSIZE属性在不同场景下应该如何设置?还有COMPRESSION属性和DATA_BLOCK_ENCODING属性,两者都可以提供压缩功能,那到底应该选择哪个,还是两个都需要进行设置?本文就重点介绍这三个属性的设计原则。

BlockSize设置
块大小是HBase的一个重要配置选项,默认块大小为64M。对于不同的业务数据,块大小的合理设置对读写性能有很大的影响。而对块大小的调整,主要取决于两点:
1. 用户平均读取数据的大小。理论上讲,如果用户平均读取数据的大小较小,建议将块大小设置较小,这样可以使得内存可以缓存更多block,读性能自然会更好。相反,建议将块大小设置较大。
为了更好说明上述原理,笔者使用YCSB做了一个测试,分别在Get、Scan两种场景下测试不同BlockSize大小(16K,64K,128K)对性能的影响。测试结果分别如下面两图:
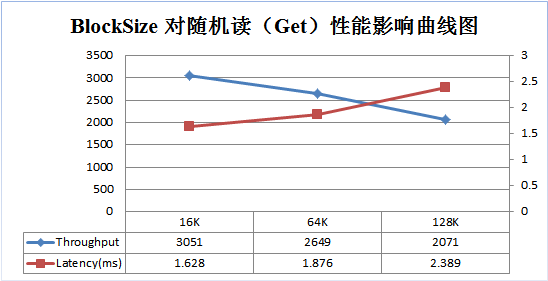
随着BlockSize的增大,系统随机读的吞吐量不断降低,延迟不断增大。64K大小比16K大小的吞吐量大约降低13%,延迟增大13%。同样的,128K大小比64K大小的吞吐量降低约22%,延迟增大27%。因此,对于以随机读为主的业务,可以适当调低BlockSize的大小,以获得更好的读性能。
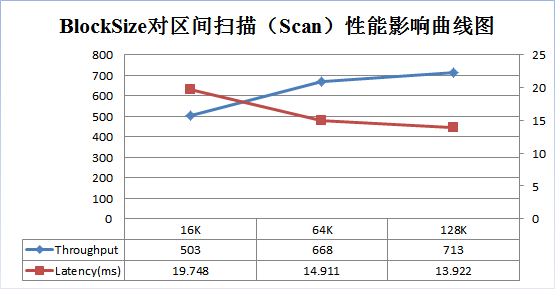
随着BlockSize增大,scan的吞吐量逐渐增大,延迟不断降低。64K大小BlockSize比16K大小的吞吐量增加了33%,延迟降低了24%;128K大小比64K大小吞吐量增加了7%,延迟降低了7%;因此,对于以scan为主的业务,可以适当增大BlockSize的大小,以获得更好的读性能。
可见,如果业务请求以Get请求为主,可以考虑将块大小设置较小;如果以Scan请求为主,可以将块大小调大;默认的64M块大小是在Scan和Get之间取得的一个平衡。
2. 数据平均键值对规模。可以使用HFile命令查看平均键值对规模,如下:
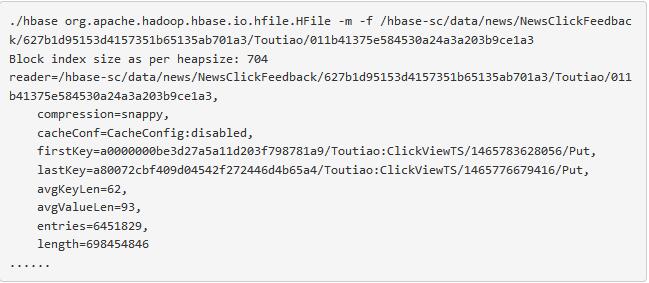
从上面输出的信息可以看出,该HFile的平均键值对规模为62B + 93B = 155B,相对较小,在这种情况下可以适当将块大小调小(例如32KB)。这样可以使得一个block内不会有太多kv,kv太多会增大块内寻址的延迟时间,因为HBase在读数据时,一个block内部的查找是顺序查找。
注意: 默认块大小适用于多种数据使用模式,调整块大小是比较高级的操作。配置错误将对性能产生负面影响。因此建议在调整之后进行测试,根据测试结果决定是否可以线上使用。
数据编码/压缩
Compress/DeCompress
数据压缩是HBase提供的另一个特性,HBase在写入数据块到HDFS之前会首先对数据块进行压缩,再落盘,从而可以减少磁盘空间使用量。而在读数据的时候首先从HDFS中加载出block块之后进行解压缩,然后再缓存到BlockCache,最后返回给用户。写路径和读路径分别如下:
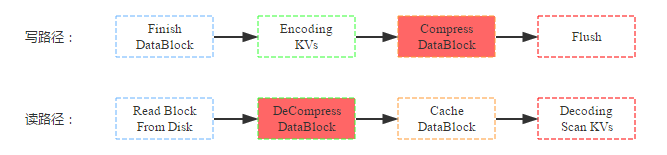
结合上图,来看看数据压缩对资源使用情况以及读写性能的影响:
(1) 资源使用情况:压缩最直接、最重要的作用即是减少数据硬盘容量,理论上snappy压缩率可以达到5:1,但是根据测试数据不同,压缩率可能并没有理论上理想;压缩/解压缩无疑需要大量计算,需要大量CPU资源;根据读路径来看,数据读取到缓存之前block块会先被解压,缓存到内存中的block是解压后的,因此和不压缩情况相比,内存前后基本没有任何影响。
(2) 读写性能:因为数据写入是先将kv数据值写到缓存,最后再统一flush的硬盘,而压缩是在flush这个阶段执行的,因此会影响flush的操作,对写性能本身并不会有太大影响;而数据读取如果是从HDFS中读取的话,首先需要解压缩,因此理论上读性能会有所下降;如果数据是从缓存中读取,因为缓存中的block块已经是解压后的,因此性能不会有任何影响;一般情况下大多数读都是热点读,缓存读占大部分比例,压缩并不会对读有太大影响。
可见,压缩特性就是使用CPU资源换取磁盘空间资源,对读写性能并不会有太大影响。HBase目前提供了三种常用的压缩方式:GZip | LZO | Snappy,下面表格是官方分别从压缩率,编解码速率三个方面对其进行对比:

综合来看,Snappy的压缩率最低,但是编解码速率最高,对CPU的消耗也最小,目前一般建议使用Snappy。
Encode/Decode
除了数据压缩之外,HBase还提供了数据编码功能。和压缩一样,数据在落盘之前首先会对KV数据进行编码;但又和压缩不同,数据块在缓存前并没有执行解码,因此即使后续命中缓存的查询也是编码的数据块,需要解码后才能获取到具体的KV数据。写路径和读路径分别如下:
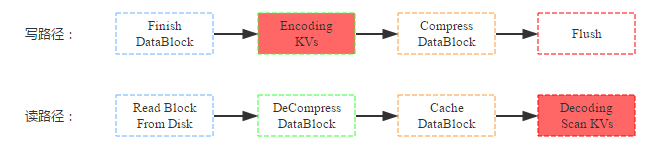
同样,来看看数据编码对资源使用情况以及读写性能的影响:
(1) 资源使用情况:和压缩一样,编码最直接、最重要的作用也是减少数据硬盘容量,但是数据编码压缩率一般没有数据压缩的压缩率高,理论上只有5:2;编码/解码一般也需要大量计算,需要大量CPU资源;根据读路径来看,数据读取到缓存之前block块并没有被解码,缓存到内存中的block是编码后的,因此和不编码情况相比,相同数据block快占用内存更少,即内存利用率更高。
(2) 读写性能:和数据压缩相同,数据编码也是在数据flush到hdfs阶段执行的,因此并不会直接影响写入过程;前面讲到,数据块是以编码形式缓存到blockcache中的,因此同样大小的blockcache可以缓存更多的数据块,这有利于读性能。另一方面,用户从缓存中加载出来数据块之后并不能直接获取KV,而需要先解码,这却不利于读性能。可见,数据编码在内存充足的情况下会降低读性能,而在内存不足的情况下需要经过测试才能得出具体结论。
HBase目前提供了四种常用的编码方式:Prefix | Diff | Fast_Diff | Prefix_Tree。下图是Prefix_Tree编码算法作者做的一个测试结果:
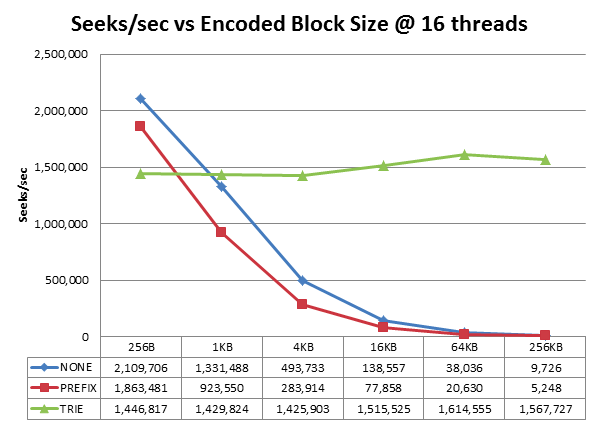
可见,prefix_tree压缩算法在不同的block size下性能都比较稳定,而另外两种压缩算法的查找性能会随着blocksize直线下降。对于我们默认的64K的block大小,性能相差40+倍。另外,阿里天梧大牛之前在一篇博文里面做过测试证明了PREFIX_TREE算法的优越性,见《HBase-0.96中新BlockEncoding算法-PREFIX_TREE压缩的初步探究及测试》,因此一般建议使用PREFIX_TREE编码压缩。
选择哪一个?Why?
综上上面分析,数据压缩和数据编码使命基本相同:消耗CPU资源压缩数据大小,可以认为是一种时间换空间的做法。但,同时开启两个功能会不会更好?如果只需要开启一个,优先选择哪一个?
为了更加深刻地认识数据压缩编码,回答上面两个问题,本人在测试环境使用YCSB做了一个简单的测试,分别在四种场景下(无压缩无编码、仅压缩、仅编码、既压缩既编码)对随机读以及扫描读的操作延时、CPU使用率以及对应的压缩率进行了测试。
测试条件:
数据:6000w条记录,一个列族,每个列族10个列,单条记录总共1K大小;
硬件:单RegionServer,3G BlockCache,CPU: 32 Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
测试结果:
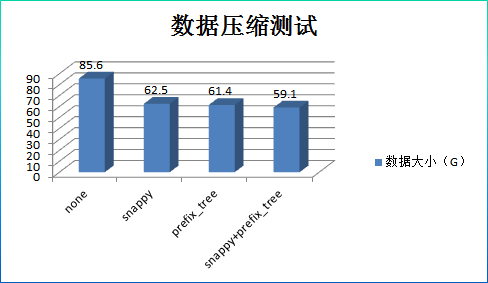
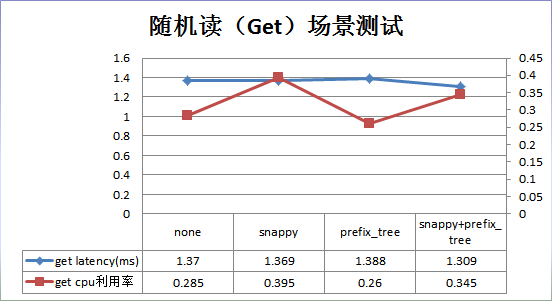
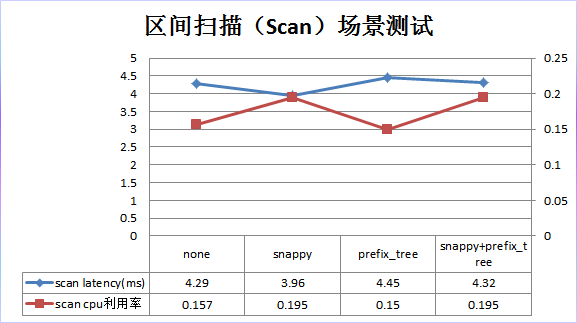
结果分析:
1. 数据压缩率并没有理论上0.2那么高,只有0.7左右,这和数据结构有关系。其中压缩、编码、压缩+编码三种方式的压缩率基本相当。
2. 随机读场景:和默认配置相比,snappy压缩在性能上没有提升,CPU开销却上升了38%;prefix_tree性能上没有提升,CPU利用率也基本相当;snappy+prefix_tree性能没有提升,CPU开销上升了38%。
3. 区间扫描场景:和默认配置相比,snappy压缩在性能上略有10%的提升,但是CPU开销却上升了23%;prefix_tree性能上略有4%左右的下降,但是CPU开销也下降了5%;
snappy+prefix_tree在性能上基本没有提升,CPU开销却上升了23%;
设计原则:
1. 在任何场景下开启prefix_tree编码都是安全的
2. 在任何场景下都不要同时开启snappy压缩和prefix_tree编码
3. 通常情况下snappy压缩并不能比prefix_tree编码获得更好的优化结果,如果需要使用snappy需要针对业务数据进行实际测试
到此为止,本文主要介绍了HBase的一个优化方向:列族设计优化。其中重点介绍了BlockSize在不同场景下对读写性能的影响,以及Compress与Data_Block_Encoding的设计原则。希望看官能够根据上述对HBase的列族优化有一个更好的认识,并且能够更多地通过测试来巩固认知。需要说明的是,这里的设计原则对大多数应用业务都是有效的,也有可能对于某些特殊场景并不适用,因此对于比较敏感的业务,还是以实际测试为准。后期笔者将会继续分析HBase优化这个专题,接着介绍HBase体系中另一个非常非常重要的概念-Compaction,敬请期待~
|






