| Platform
Symphony 简介
简单来说,Platform Symphony 是一个提供数据分发、任务调度以及资源管理的企业级分布式计算框架,并且支持异构化的
IT 环境。Symphony 由两层架构组成,一层是负责资源管理的 EGO,另一层是任务管理的 SOAM。在
Symphony 的集群中,用户需要根据 Symphony 提供的 API 实现 Client 和 Service
程序。Symphony 涉及的基础模块如下图。
图 1. Platform Symphony 基础模块
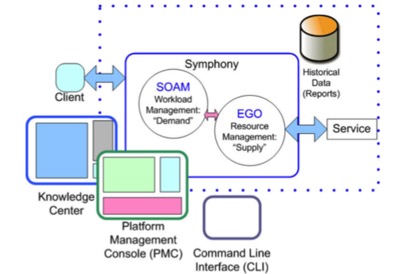
如图所示,Client 程序用于提交任务到 Symphony 集群,Symphony 会在 EGO 层为该类应用申请计算资源,接着在对应的机器上启动用户的
Service。Service 接收任务数据并进行计算,最终会通过 Symphony 将任务结果返回 Client
程序。
PMC 是 Symphony 提供的一个专业 WEB 操作界面,其可以定制 Symphony 集群的配置,以及管理任务等。
CLI 是 Symphony 提供了一些命令行工具的集合,对于习惯使用命令操作的用户来说,更加方便和高效。Knowledge
Center 是 Symphony 产品文档的 WEB 接口,用户可以在其中找到 Symphony 各个功能的介绍和使用方法。
分布式大数据框架的分类 在详细介绍 Platform Symphony 与大数据生态圈的关系之前,让我们先了解一下整个大数据生态系统。我个人理解是:目前这个行业可以简单的分为三大块,分别是数据源、数据处理以及数据分析。数据分析是直接将大数据转换为商业价值的领域,在数据分析的领域会提出各种业务需求。数据处理领域则是负责实现数据分析提出的需求,这一领域也就是我们经常说的基础设施架构层(Infrastructure)。数据源指的就是数据产生的地方。在这三块之间也有一些衔接的软件领域,不过往往也都归在了数据处理领域(基础架构层),例如衔接数据源与数据处理层的数据导入工具(如
sqoop 等),以及衔接数据分析和数据处理的应用接口(如:SQL 接口的 Hive,以及流的接口等)。在大数据的这三大领域中有很多开源以及非开源的产品,熟知的开源的
Hadoop、Spark 等,都属于数据处理领域,也就是基础架构这块。IBM Platform Symphony
无疑也属于这一块。综上所述,如果宏观的抽象出整个大数据生态涉及的相关领域,大致如下图所示: 图 2.
大数据行业相关的领域 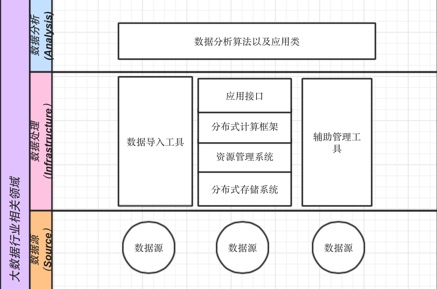
基于对大数据相关领域的宏观描述,下来我们就再来谈下基础架构这一块。目前大多开源相关的大数据框架基本可以归属到基础设施架构这块。为了更好的理解各个框架之间的关系,我们又将基础设施架构这块分为四层,分别是数据存储层、集群资源管理层、计算引擎层、以及应用接口层。除了一些提供易用性、可维护性以及健壮性的框架之外(一般也可以统称为管理类),其他大部分都可以归在这四类。例如
HDFS 属于数据存储层,Mesos 和 Yarn 则属于集群资源管理层,Hadoop MapReduce、Storm、Spark
等则归属于计算引擎层,Hive、Pig 则为数据查询提供接口。Ambari 则是一个提升易用性和可维护性的工具,Zookeeper
提供了健壮性(HA)。这些系统之间具体的关系,请参见下面的简图: 图 3. 分布式大数据基础架构关系图
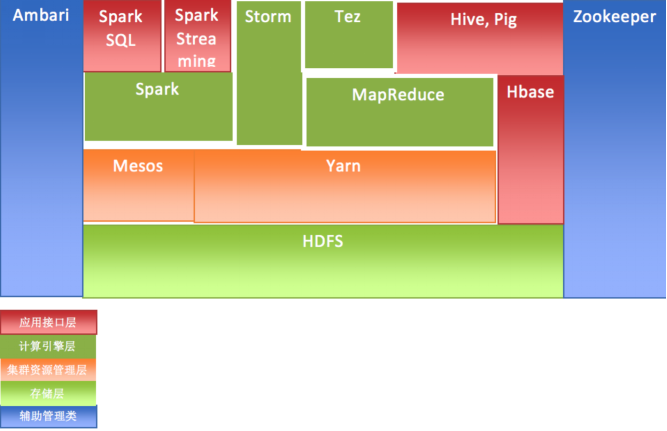
那么 Platform Symphony 又具体处在哪个层,又可以替代哪些开源的框架呢?带着问题,我们来理解下图。
图 4. Platform Symphony 与大数据生态圈的关系 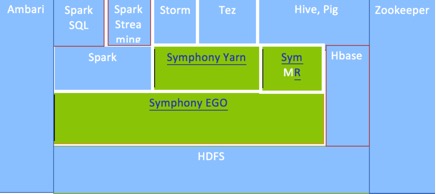
从图 3 中我们可以看出,在大数据应用场景中,Platform Symphony
既处在资源管理层,也涵盖了计算引擎层。因此很多原有的大数据应用,都可以很平滑的迁移到 Symphony 的集群中运行,例如
Hive、Pig 等。并且用户以前在 Hadoop MapReduce 上开发的应用也可以很平滑的运行在 Symphony
之上。 类比开源的框架,Platform Symphony 中的 EGO 相似与 Yarn 和 Mesos
处于集群资源管理层,SOAM 处于计算引擎层,负责任务管理和调度。Symphony MapReduce 只是
Symphony 内置的一种应用(Hadoop MapReduce 也是内置于 Yarn 的一种应用)。用户其实可以根据
Symphony 的 API 实现各种不同的 Symphony 应用。目前 Symphony 已经与开源 Yarn
和 Spark 集成,也就是说用户之前在 Yarn 和 Spark 上面的应用,可以直接通过 Symphony
管理和调度集群资源。 Platform Symphony 的模块和基础知识
在文章的开始我们就已经谈到了 Platform Symphony 的基础架构,这里我们就来看看 Platform
Symphony 两层架构中都有哪些详细的模块。 EGO 简介 用一句说,EGO(全称为 Enterprise
Grid Orchestrator)就是一个管理集群资源的模块。首先它会将物理资源,进行虚拟抽象并管理,然后在多个应用之间进行协调和分配。这也是其设计的初衷。类似于开源的
Yarn,可是要知道 EGO 这个设计及实现都是十几年前就已经有了,而 Yarn 则是这几年才发展起来的(企业级的分布式系统,通常都会积累沉淀很久才会趋于稳定)。EGO
会将集群节点分为管理节点和计算节点,并定义一套资源分配的策略。我们也可以说 EGO 就是由这三部分组成,如下图所示。
图 5. EGO 的组成 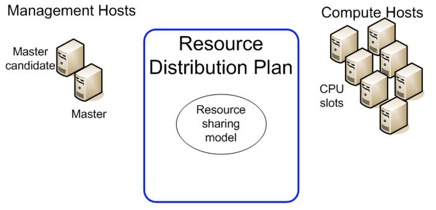
管理节点,一般会运行一些特殊化的服务,例如管理
Symphony 任务的服务(Session Manager 和 WEB 的服务进程,后面会介绍)。计算节点则是承载用户计算任务的节点。图中的
Master candidate 属于一个 Standby 的 Master 节点。对于 Symphony
的 Master 节点来说,这就是它的 HA。Master 和 Master Candidate 都属于管理节点,它们会共享一个目录(NFS)来记录运行时的一些媒体信息。当
Master 宕机或长时间不响应的时候,Master Candidate 会接管集群成为新的 Master,并从
NFS 的媒体信息中恢复正在执行的任务信息。CPU slot 是一个用来衡量计算资源的基本单位。一个 Slot
可以用来启动一个用户的 Service 实例(在计算节点),也可以用来启动一个 Session Manager
这样的管理服务实例(在管理节点)。其实管理节点和计算节点只是 EGO 内置的两种资源分组,我们也叫 Resource
Group。用户也可以自定义其特有的 Resource Group 来隔离不同的应用。Resource Group
之间也可以有优先级,也可以定制化共享资源。这也是 EGO 提供给上层的功能。 这里也介绍下 EGO
中几个重要的服务进程,VEMKD、EGOSC、PEM。VEMKD 相当于 Yarn 中的 RM,它启动在 Master
节点上面,用于监测集群的资源的状态以及管理集群资源。上层的应用最终都会向 VEMKD 来申请资源(Slot)。EGOSC
全名就是 EGO service controller,它会向 VEMKD 申请资源启动一些系统管理的服务。PEM
全名是 Process Manager,用于启动进程实例,和监测进程实例的状态。 SOAM 的组成
SOAM 是一个面向服务的中间件,其由 Session Director(SD)、Session Manager(SSM)、Service
Instance Manager (SIM) 和 Service Instance(SI)组成。具体的关系如下图。
图 6. SOAM 的架构设计 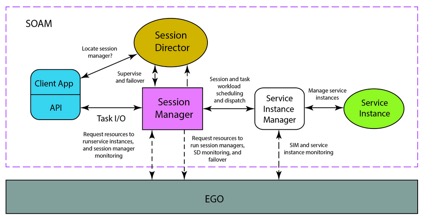
简单介绍下各个模块之间的关系,Client
就是用户根据 Symphony SDK 开发的客户端程序,用户从 Client 提交计算任务。Client
会先和 SD 建立连接,SD 会找到该类型应用的 SSM。如果该类型 SSM 不存在,SD 会向 EGO 层申请管理节点的资源,并启动
SSM(这里的 SD 和 SSM 都是管理节点的系统服务实例,不占用计算节点的资源)。SSM 会根据用户提交的任务向
EGO 层申请一定的计算资源。拿到计算资源后 SOAM 层会在计算节点启动 SIM 和 SI(一般一个 Slot
启动一个 SI 实例)。然后 SSM 会发送任务和数据到 SIM,进而到 SI 完成计算。SIM 会管理用户的
Service 进程,如果用户的 Service 遇到一些错误,SIM 会根据用户配置产生对应的行为,我们称之为
Error Handing。 Symphony 的应用以及其运行时涉及的概念 在 Symphony
中运行的应用,主要包含三部分,分别是 Client、Service 程序以及该应用的定义文件 App Profile。其中
Client、Service 都需要用户根据 Symphony SDK 开发。运行时涉及的概念见下图。
图 7. Symphony App 运行时的相关概念 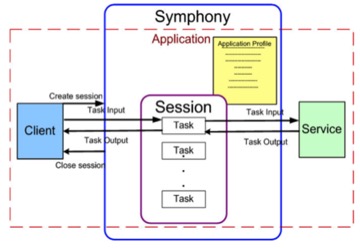
从图中,可以看见 Client 会创建 Session(跟 Job 是一个意思),Session 会包含很多个
Task。Client 每提交一次作业都会创建一个 Session,并生成多个 Task。Session 的
ID 是全局唯一的,而 Task 的 ID 只是在该 Session 中唯一。每一个应用都会有一个 App
Profile,它会定义跟该应用相关的属性,以及 Symphony 对该应用在某个场景的行为。对运行时的数据流向,我们可以参见下图。
图 8. Symphony 应用的数据流向 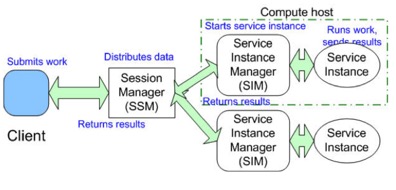
Symphony
的 Package 管理 无论是开源的 Hadoop 还是 Platform Symphony,用户都需要开发自己的程序。因此,会涉及到如何管理用户应用的部署包。对于
Hadoop 来说,需要上传 Package(Jar 包)到 HDFS。同样的 Symphony 需要用户将
Package 发送给 RS 服务。不过 Symphony 提供了很友好的命令行工具和 WEB 操作入口。用户上传完成后,Symphony
会在运行该用户应用时,自动下载 Package 到计算节点。如下图所示。 图 9. Symphony
的 Package 的管理 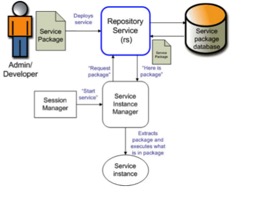
Platform Symphony 应用间的资源管理和和共享 Platform Symphony 通过
Consumer 来管理应用之间的资源。我们可以简单理解 Consumer 就相当于每个应用的银行账户,申请到的资源就会存放在
Consumer,然后与其关联的应用就可以使用该 Consumer 获得的资源。下图是 Consumer 和
App 以及 Resource Group 的关系。 图 10. Consumer、App、RG 的关系
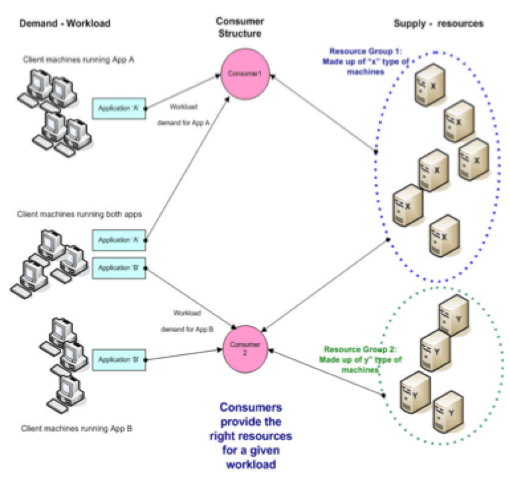
从图中我们可以看到 App 会以 Consumer
为账户在 Resource Group 中取得资源,一个 Consumer 可以配置从一个或多个 RG 中申请资源。为了最大化的利用资源,Symphony
允许 Consumer 之间的资源共享。在 Symphony 的集群中,会有 Resource Distribution
Plan 的定义,也就是全局资源分配的策略。它会包含三种资源共享的模型、分别是 Siloed 模型、Directed
Shared 模型以及 Brokered share 模型(也可以称为 utility 模型)如下图。
图 11. Symphony 资源共享模型 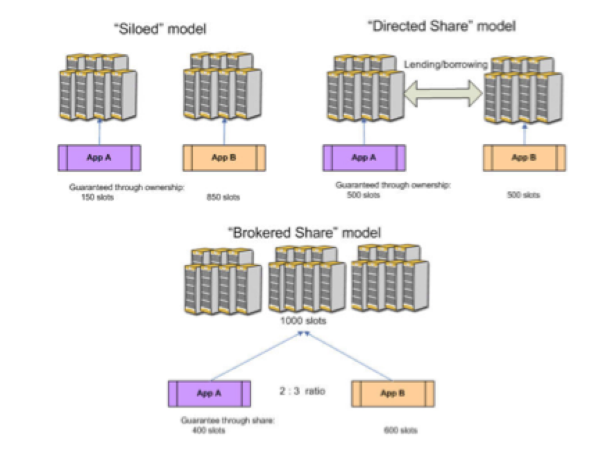
简单来说,用户可以对一个(或多个)应用配置独占一部分资源,将剩下的分配给其他应用。在独占的资源中,又可以配置借入和借出规则。在应用与应用之间(也就是
Consumer 之间)也可以配置一个比例,这样应用之间可以按比例获取集群中国的资源。以上只是很简单的概括描述,资源如何分配是
Symphony 的一个核心的内容,感兴趣的读者可以在 IBM Knowledge Center 中获得更多内容。
Platform Symphony 与 Yarn 的对比 前面介绍了 Symphony
中 EGO 和 SOAM 里的一些模块和概念,可能有的人觉得和大数据并没有什么关系。其实是很多人已经先入为主了,提到大数据可能想到的更多的是
Hadoop MapReduce 和 Spark 之类,而这些都只是计算框架而已。Symphony 的用户完全可以根据自己的业务计算逻辑,实现自己的
Symphony 应用。拿 MapReduce 而言,它也只是 Symphony 的一个应用。这也间接说明了
Symphony 的另一个优势,多租户的概念。Symphony 中可以同时运行多种类型的应用。用过 Yarn
的读者,可能觉得 Symphony 有些类似于 Yarn。这里就将 Symphony 的各个模块与 YARN
做个简单的对照。下图是 Yarn 的架构设计,我们对比下 Yarn 与 Symphony 的相似之处。
图 12. Yarn 的架构设计 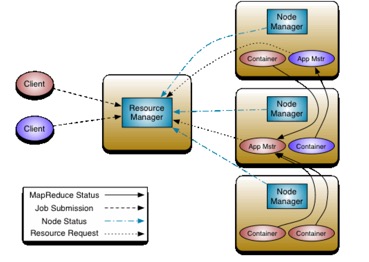
Client 都是用来提交任务的,在
Yarn 中 RM 会申请资源启动 App Master。这一步类似于 SOAM 中 SD 申请资源启动(或找到)SSM。Yarn
中 App Master 会向 RM 申请资源启动 container 运行 MR 任务,并收集任务状态。这里类似于
SSM 向 EGO 申请资源启动 SIM 和 SI,并发送任务和收集任务结果的过程。SSM 和 App Master
一样,是管理和调度任务的模块,在一个集群中可以存在多个(多种不同类型的应用)。很多人都很赞叹 Yarn 架构的前沿性,尤其与
Hadoop 一代比较,Yarn 将资源管理层单独抽象出来,这样使得 Hadoop 的架构更加清晰。而 Symphony
十几年前就已经这样设计,可见 Symphony 已经领先开源很多年。 当然 Symphony 与 Yarn
也有一些差异,例如默认情况下(Yarn 可以配置),Yarn 的 App Master 是启动在 Yarn
的 Container 中,与真正的计算实例的 Container 并无特殊对待。也就是说启动 App Master
的机器,有随机性。而 Symphony 一般只能启动 SSM 在 Symphony 的管理节点。一般情况下,管理节点的性能会远高于计算节点的,而
SSM 等管理进程对性能的消耗一般也会比较大,所以在管理节点启动 SSM 这样的重量级进程是有技术背景的。再例如
Yarn 没有 Resource Group 的概念,如果需要将某些特殊的任务调度到某一群特定机器时,Yarn
显得有些沉重,因为 Yarn 目前只能通过标签调度(Tag Policy)去做。Symphony 可能只需要设定几个
Resource Group,并设计不同优先级即可(Symphony 很早前也支持了 Tag 的调度策略)。与所有的开源框架相比,Symphony
支持更多的 OS 平台以及硬件平台。例如 Hadoop 目前还没支持 Windows,而 Symphony
很早就支持了。更多的差异化,可以在 IBM 的 Knowledge Center 找到。
Platform Symphony 的 SDK 接口介绍 在介绍 SDK 层之前,先简单介绍一下 Symphony
本身的实现语言。Symphony 的主要模块 EGO 和 SOAM 是由 C/C++语言实现的,这也是 Symphony
追求性能极致的一种体现。因此 Symphony 也不会受限于 JVM(如 GC 的影响)。不过对于用户来说,更关心的是
SDK 层支持的语言。 目前,Symphony 支持 2 种接口: - 原生的 SDK
支持 Java、C++、C# 以及 Python。因此,用户可以根据自己擅长的语言,开发对应的 Symphony
应用程序。 ― Symphony MapReduce 的接口 Symphony 提供和开源
Hadoop 一致的 API,并确保兼容性,这里就再不多做介绍。 下面主要介绍下 Symphony
原生 SDK 的接口。 Client 端的 API 在 Client 端涉及的最重要的几个
API 有: connect(),用于在 Client 端连接 Symphony 集群中该类应用的
SSM。 createSession(),用于为该次任务创建 Session(Job)。 sendTaskInput(),用于发送任务需要的输入。
fetchTaskOutput(),用于获取计算任务的结果。 Client 工作流程图如下:
图 13. Client 端 API 的流程图 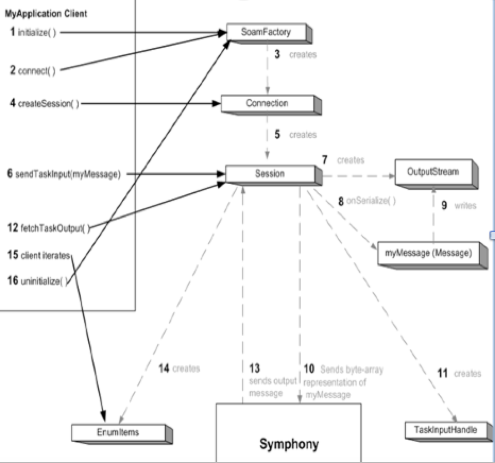
Service 端 API 在 Service 端主要的 API 会有: onCreateService(),提供用户
Service 端初始化的时机。 onSessionEnter(),用户 Service 端 Common
Data 等数据的读取。 onInvoke(),用户计算逻辑的实现接口,也就是说在这里并行执行用户的计算逻辑。
onSessionLeave(),用于 Common Data 数据的清理。 onDestoryService(),用户可以在这里清理掉初始化时候的数据。
图 14. Service 端 API 的流程图 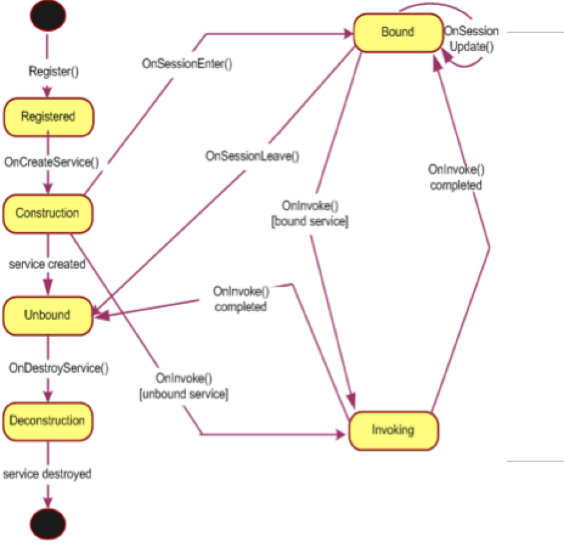
更多 API 的细节,可以参见 Knowledge Center 中的介绍。 |






