|
我们基于Hadoop 1.2.1源码分析MapReduce V1的处理流程。
TaskTracker周期性地向JobTracker发送心跳报告,在RPC调用返回结果后,解析结果得到JobTracker下发的运行Task的指令,即LaunchTaskAction,就会在TaskTracker节点上准备运行这个Task。Task的运行是在一个与TaskTracker进程隔离的JVM实例中执行,该JVM实例是通过org.apache.hadoop.mapred.Child来创建的,所以在创建Child VM实例之前,需要做大量的准备工作来启动Task运行。一个Task的启动过程,如下序列图所示:
通过上图,结合源码,我们将一个Task启动的过程,分为下面3个主要的步骤:
1.初始化跟踪Task运行的相关数据结构
2. 准备Task运行所共享的Job资源
3. 启动Task
下面,我们详细分析上面3个步骤的流程:
初始化跟踪Task运行的相关数据结构
如果是LaunchTaskAction,则TaskTracker会将该指令加入到一个启动Task的队列中,进行一步加载处理,如下所示:
``````````````
根据Task的类型,分别加入到对应类型的TaskLauncher的队列中。这里需要了解一下TaskLauncher线程类,在TaskTracker中创建了2个TaskLauncher线程,一个是为启动MapTask,另一个是为启动ReduceTask。下面是TaskLauncher类的构造方法:

构造方法中,参数taskType表示Task类型,分为MapTask和ReduceTask,参数numSlots表示对每一种类型的Task每个TaskTracker上最多可以启动的Task的实例数,默认都是2个。在TaskTracker初始化时,会读取mapred-site.xml配置文件,读取mapred.tasktracker.map.tasks.maximum和mapred.tasktracker.reduce.tasks.maximum配置的参数值,分别赋值给maxMapSlots和maxReduceSlots这2个属性,如下TaskTracker构造方法中初始化这2个属性:

然后,在TaskTracker创建时,会根据上述maxMapSlots和maxReduceSlots的值来创建并启动2个TaskLauncher线程:

将LaunchTaskAction加入到TaskLauncher的队列中,这个是调用TaskLauncher的addToTaskQueue()方法:

上面方法中,最关键的就是registerTask()方法,调用该方法来初始化TaskTracker端Task对应TaskInProgress结构,代码如下所示:
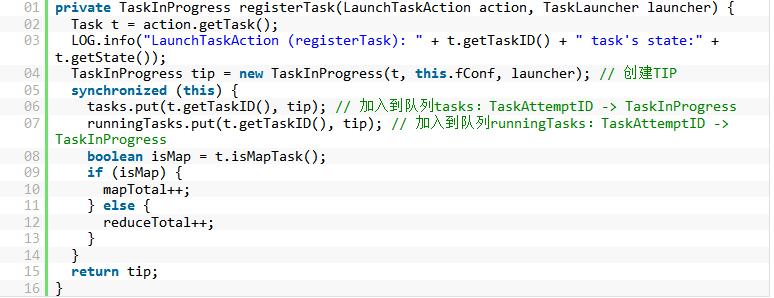
上面方法中,tasks队列用来记录该TaskTracker上所有的Task,包括正在运行和已经完成的Task,而队列runningTasks则表示当前TaskTracker上正在运行的Task。同时,通过mapTotal和reduceTotal来分别记录当前TaskTracker上运行的总的MapTask和ReduceTask的数量。
根据LaunchTaskAction创建的TaskInProgress结构被加入到队列tasksToLaunch中,然后通知TaskLauncher线程,在方法run中检测并取出队列中TaskInProgress对象,并判断当前TaskTracker的资源状态能否启动一个Task,如果可以则调用startNewTask()方法启动Task,代码如下所示:

这样,当前TaskTracker所在节点的资源状态,和Task对应的TIP状态都已经满足启动Task的要求,可以启动一个Task去运行。
准备Task运行所共享的Job资源
调用startNewTask()方法,异步地启动了一个单独的线程去启动Task,该方法如下所示:
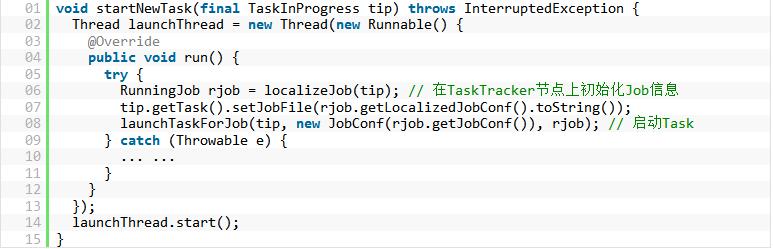
如果在一个TaskTracker节点上运行的多个Task都属于同一个Job(一个TaskTracker上运行的Task按照Job来分组,每一组Task都属于同一个Job),那么第一次初始化时,还没有建立一个Task到Job的映射关系,也就是说,在TaskTracker端也要维护Job的状态,以及属于该Job的所有Task的状态信息。比如,如果用户提交了一个kill掉Job的请求,那么正在运行的属于该Job的所有Task都应该被kill掉。
上面代码中调用localizeJob()方法,执行了如下处理:
1.创建一个RunningJob对象,并加入到TaskTracker维护的runningJobs队列(包含了JobID到RunningJob的映射关系)中,同时将Task对应的TIP对象加入到RunningJob所维护的tasks队列中。
2. 一个Job完成初始化,还需要将Job相关的信息,如Job配置信息从HDFS上下载到TaskTracker所在节点本地,供该Job的一组Task运行共享。我们知道,在JobClient提交Job时,会将相关资源拷贝到HDFS上的指定目录中,例如,在HDFS上的/tmp/hadoop/mapred/staging/shirdrn/.staging/job_200912121733_0002/目录下存储Job相关的资源文件,拷贝到TaskTracker本地目录下,例如/tmp/mapred/local/ttprivate/taskTracker/shirdrn/jobcache/job_200912121733_0002/目录。
3.调用TaskController的initializeJob()方法初始化Job所包含的相关资源信息,为属于该Job的一组Task所共享。
这里,TaskController使用的LinuxTaskController实现类,通过调用该方法,实际上构造了一个Shell命令行,用来在TaskTracker节点上初始化目录和拷贝相关资源,该命令行示例如下所示:

通过工具ShellCommandExecutor来执行上述命令行,启动一个单独的JVM实例,完成Job资源初始化,完成即退出。通过上述命令行可以看到,主要的初始化工作都在JobLocalizer中完成的,需要传入2个参数:用户、jobid,在JobLocalizer中创建了一个Job所包含的各种资源,供Task在TaskTracker节点上运行共享,这些相关的目录或资源文件包括:

这样,在一个TaskTracker节点上运行的一组Task所共享的对应唯一Job相关的资源已经满足,接下来就可以启动Task了。
启动Task
启动Task的流程相对复杂一些,我们分几个阶段/要点来进行说明:
启动Task准备
在startNewTask()方法中调用localizeJob()方法,完成了Job资源在TaskTracker节点上的初始化,接着就可以调用launchTaskForJob()方法进入启动Task的处理流程,代码如下所示:

通过调用TaskInProgress tip的launchTask()方法来启动Task,我们看一下该方法实现代码:
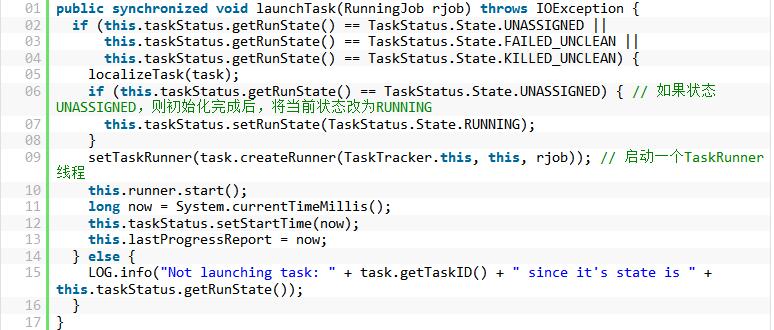
TaskInProgress里面taskStatus维护了一个TIP的状态,通过上述代码可以看出,一个Task只有具备下面3个状态之一:UNASSIGNED、FAILED_UNCLEAN、KILLED_UNCLEAN,才能够被启动。
首先要进行Task的初始化,调用localizeTask()方法,如下所示:

在这里,Task可能是MapTask,也可能是ReduceTask,所以调用task.localizeConfiguration()的初始化逻辑稍微有些不同,具体可以查看MapTask和ReduceTask类实现。另外,对于不同类型的Task,也会创建不同类型的TaskRunner线程,分别对应于MapTaskRunner和ReduceTaskRunner,实际所有Task启动的相关逻辑都是在这2个TaskRunner中实现的。
在TaskRunner中,主要逻辑是在run()方法中实现的,其中在调用launchJvmAndWait(setupCmds, vargs, stdout, stderr, logSize, workDir)之前,做了一些准备工作:
1.构建setupCmds:读取系统环境变量,或者hadoop设置的环境变量,LD_LIBRARY_PATH、LD_LIBRARY_PATH、USER、SHELL、LOGNAME、HOME、HADOOP_TOKEN_FILE_LOCATION、HADOOP_ROOT_LOGGER、HADOOP_CLIENT_OPTS、HADOOP_CLIENT_OPTS,这些变量都是键值对的形式,最后会通过export在当前环境下导出这些变量配置
2.构建vargs:设置启动Child VM的配置,读取mapred-site.xml配置文件中mapred.map.child.java.opts和mapred.reduce.child.java.opts的配置内容,最终会使用org.apache.hadoop.mapred.Child创建一个JVM实例来启动Task
3. 目录文件设置:包括2个日志文件stdout和stderr,以及当前启动JVM所在的目录workDir
使用JvmManager管理启动Task相关数据
完成上述准备工作以后,调用launchJvmAndWait()方法,创建Child VM实例,如下所示:

最终是通过JvmManager来实现JVM实例的创建,下面是JvmManager保存的一些数据结构,用来维护JVM相关数据的数据结构,如下图所示:
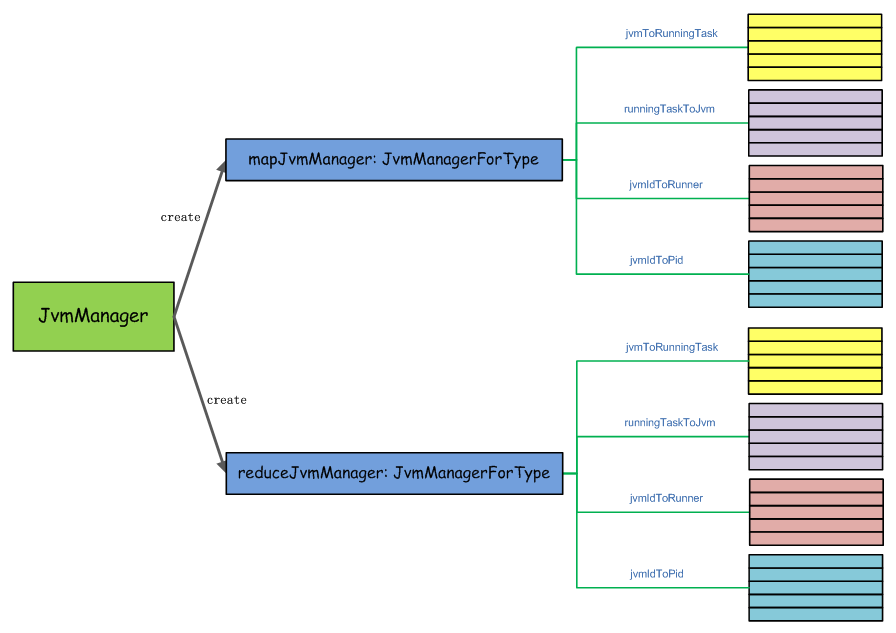
可以看到,一个JvmManager对应2个JvmManagerForType,分别负责管理MapTask和ReduceTask启动对应的Child VM等数据,JvmManager的构造方法,如下所示:

上面调用了jvmManager.launchJvm()方法,其中内部根据Task类型,选择调用mapJvmManager或reduceJvmManager的reapJvm()方法,如下所示:

上面代码中,调用setRunningTaskForJvm()很关键,实际上把需要启动的Task与JvmRunner建立映射关系,更新相应的内存数据结构(队列),如下所示:

该方法,在spawnNewJvm()方法也调用了,spawnNewJvm()方法创建了一个新的JVM,代码如下所示:

接下来,我们看一下JvmRunner线程类,该线程体run()方法中直接调用了runChild()方法,该方法实现代码,如下所示:

在JvmRunner线程类中,其中委托TaskController来控制Task的实际启动。
使用TaskController控制启动Child VM
下面,我们看TaskController启动Task的实现方法launchTask(),代码如下所示:
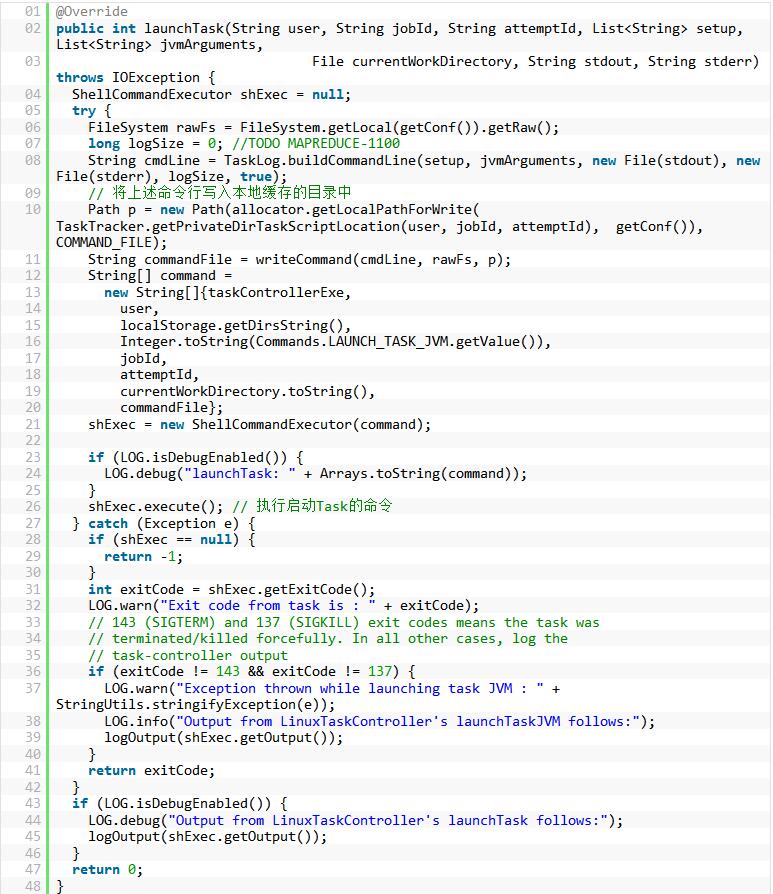
将构造好的启动Child的命令行写入到本地目录下的文件中,该脚本文件的绝对路径,示例如下所示:
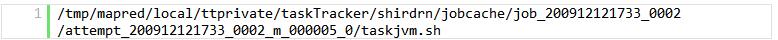
在TaskController(实际上是LinuxTaskController)的launchTask()方法中,使用ShellCommandExecutor工具执行的命令行,类似如下这样:

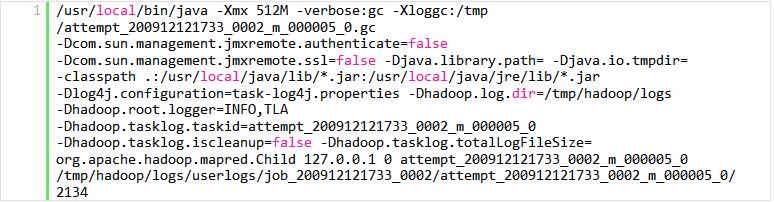
在taskjvm.sh脚本中的内容,才是真正启动Child VM的命令行,示例如下所示:
至此,一个Task通过Child VM的加载已经启动,就可以运行一个Task了,我们后续再详细介绍。
|






