| 由于从各光伏电站采集的数据量较大,必须解决海量数据的查询、分析的问题。目前主要考虑两种方式:
1. Hadoop大数据技术;
2. Oracle(数据仓库)+BI;
本文仅介绍hadoop的技术要应用特征。
Hadoop 基本介绍
hadoop是一个平台,是一个适合大数据的分布式存储和计算的平台。什么是分布式存储?这就是后边我们要讲的hadoop核心之一HDFS(Hadoop
Distributed File System);什么是分布式计算?这是我们后边要讲的hadoop另外一个重要的核心MapReduce。
hadoop的优点一:低成本
hadoop本身是运行在普通PC服务器组成的集群中进行大数据的分发及处理工作的,这些服务器集群是可以支持数千个节点的。
hadoop优点二:高效性
这也是hadoop的核心竞争优势所在,接受到客户的数据请求后,hadoop可以在数据所在的集群节点上并发处理。
hadoop优点三:可靠性
通过分布式存储,hadoop可以自动存储多份副本,当数据处理请求失败后,会自动重新部署计算任务。
hadoop优点四:扩展性
hadoop的分布式存储和分布式计算是在集群节点完成的,这也决定了hadoop可以扩展至更多的集群节点。
hadoop安装方式|hadoop部署方式
hadoop安装方式只有三种:本地安装;伪分布安装;集群安装。
Hadoop 适应的场景
1:超大文件
可以是几百M,几百T这个级别的文件。
2:流式数据访问
Hadoop适用于一次写入,多次读取的场景,也就是数据复制进去之后,长时间在这些数据上进行分析。
3:商业硬件
也就是说大街上到处都能买到的那种硬件,这样的硬件故障率较高,所以要有很好的容错机制。
Hadoop 不适用的场景
1:低延迟数据访问
Hadoop设计的目的是大吞吐量,所以并没有针对低延迟数据访问做一些优化,如果要求低延迟, 可以看看Hbase。
2:大量的小文件
由于NameNode把文件的MetaData存储在内存中,所以大量的小文件会产生大量的MetaData。这样的话百万级别的文件数目还是可行的,再多的话就有问题了。
3:多用户写入,任意修改
Hadoop现在还不支持多人写入,任意修改的功能。也就是说每次写入都会添加在文件末尾。
Hadoop 业务场景 1
在大数据背景下,Apache Hadoop已经逐渐成为一种标签性,业界对于这一开源分布式技术的了解也在不断加深。但谁才是Hadoop的最大用户呢?首先想到的当然是它的“发源
地”,像Google这样的大型互联网搜索引擎,以及Yahoo专门的广告分析系统。也许你会认为,Hadoop平台发挥作用的领域是互联网行业,用来改
善分析性能并提高扩展性。其实Hadoop的应用场景远不止这一点,深入挖掘的话你会发现Hadoop能够在许多地方发挥巨大的作用。
美国着名科技博客GigaOM的专栏作家Derrick Harris跟踪云计算和Hadoop技术已有多年时间,他也在最近的一篇文章中总结了10个Hadoop的应用场景,下面分享给大家:
在线旅游:目前全球范围内80%的在线旅游网站都是在使用Cloudera公司提供的Hadoop发行版,其中SearchBI网站曾经报道过的Expedia也在其中。
移动数据:Cloudera运营总监称,美国有70%的智能手机数据服务背后都是由Hadoop来支撑的,也就是说,包括数据的存储以及无线运营商的数据处理等,都是在利用Hadoop技术。
电子商务:这一场景应该是非常确定的,eBay就是最大的实践者之一。国内的电商在Hadoop技术上也是储备颇为雄厚的。
能源开采:美国Chevron公司是全美第二大石油公司,他们的IT部门主管介绍了Chevron使用Hadoop的经验,他们利用Hadoop进行数据的收集和处理,其中这些数据是海洋的地震数据,以便于他们找到油矿的位置。
节能:另外一家能源服务商Opower也在使用Hadoop,为消费者提供节约电费的服务,其中对用户电费单进行了预测分析。
基础架构管理:这是一个非常基础的应用场景,用户可以用Hadoop从服务器、交换机以及其他的设备中收集并分析数据。
图像处理:创业公司Skybox Imaging 使用Hadoop来存储并处理图片数据,从卫星中拍摄的高清图像中探测地理变化。
诈骗检测:这个场景用户接触的比较少,一般金融服务或者政府机构会用到。利用Hadoop来存储所有的客户交易数据,包括一些非结构化的数据,能够帮助机构发现客户的异常活动,预防欺诈行为。
IT安全:除企业IT基础机构的管理之外,Hadoop还可以用来处理机器生成数据以便甄别来自恶意软件或者网络中的攻击。
医疗保健:医疗行业也会用到Hadoop,像IBM的Watson就会使用Hadoop集群作为其服务的基础,包括语义分析等高级分析技术等。医疗机构可以利用语义分析为患者提供医护人员,并协助医生更好地为患者进行诊断。
Hadoop 业务场景 2
其实我们要知道大数据的实质特性:针对增量中海量的结构化,非结构化,半结构数据,在这种情况下,如何快速反复计算挖掘出高效益的市场数据?
带着这个问题渗透到业务中去分析,就知道hadoop需要应用到什么业务场景了!!!如果关系型数据库都能应付的工作还需要hadoop吗?
比如:
1.银行的信用卡业务,当你正在刷卡完一笔消费的那一瞬间,假如在你当天消费基础上再消费满某个额度,你就可以免费获得某种令你非常满意的利益等
等,你可能就会心动再去消费,这样就可能提高银行信用卡业务,那么这个消费额度是如何从海量的业务数据中以秒级的速度计算出该客户的消费记录,并及时反馈
这个营销信息到客户手中呢?这时候关系型数据库计算出这个额度或许就需要几分钟甚至更多时间,就需要hadoop了,这就是所谓的“秒级营销”.
针对真正的海量数据,一般不主张多表关联。
2. 在淘宝,当你浏览某个商品的时候,它会及时提示出你感兴趣的同类商品的产品信息和实时销售情况,这或许也需要用到hadoop。
3. 就是报表用到的年度报告或者年度环比数据报告的时候也会用到hadoop去计算。
4.搜索引擎分析的时候应该也会用到。一个网友说过,其实还是看big data能否带来多大的效益!比如银行在躺着都赚钱的情况下,big
data不一定是银行的项目. 况且hadoop是新兴技术,银行业对新技术还是相对保守的。
hadoop 主要用于大数据的并行计算,并行计算按计算特征分为:
数据密集型并行计算:数据量极大,但是计算相对简单的并行处理。如:大规模Web信息搜索;
计算密集型并行计算:数据量相对不是很大,但是计算较为复杂的并行计算。如:3-D建模与渲染,气象预报,科学计算;
数据密集与计算密集混合型的并行计算。如:3-D电影的渲染;
hadoop比较擅长的是数据密集的并行计算,它主要是对不同的数据做相同的事情,最后再整合。
我知道以及曾经实验过的hadoop的例子有:
wordCount (相当于hadoop的HelloWorld的程序);
文档倒排索引;
PageRank;
K-Means 算法;
这些程序都可以从网上找到相应的解决方案。
hadoop的是根据Google MapReduce 提出的开源版本。但是它的性能不是很好。
hadoop主要应用于数据量大的离线场景。特征为:
1、数据量大。一般真正线上用Hadoop的,集群规模都在上百台到几千台的机器。这种情况下,T级别的数据也是很小的。Coursera上一门课了有句话觉得很不错:Don’t
use hadoop, your data isn’t that big.
2、离线。Mapreduce框架下,很难处理实时计算,作业都以日志分析这样的线下作业为主。另外,集群中一般都会有大量作业等待被调度,保证资源充分利用。
3、数据块大。由于HDFS设计的特点,Hadoop适合处理文件块大的文件。大量的小文件使用Hadoop来处理效率会很低。举个例子,百度每天都会有用户对侧边栏广告进行点击。这些点击都会被记入日志。然后在离线场景下,将大量的日志使用Hadoop进行处理,分析用户习惯等信息。
MapReduce 的经典案例
MapReduce的一个经典实例是Hadoop。用于处理大型分布式数据库。由于Hadoop关联到云以及云部署,大多数人忽略了一点,Hadoop有些属性不适合一般企业的需求,特别是移动应用程序。下面是其中的一些特点:
Hadoop的最大价值在于数据库,而Hadoop所用的数据库是移动应用程序所用数据库的10到1000倍。对于许多人来说,使用Hadoop就是杀鸡用牛刀。
Hadoop有显著的设置和处理开销。 Hadoop工作可能会需要几分钟的时间,即使相关数据量不是很大。
Hadoop在支持具有多维上下文数据结构方面不是很擅长。例如,一个定义给定地理变量值的记录,然后使用垂直连接,来连续定义一个比hadoop使用的键值对定义更复杂的数据结构关系。
Hadoop必须使用迭代方法处理的问题方面用处不大,尤其是几个连续有依赖性步骤的问题。
MapReduce (EMR),这是一项Hadoop服务。Hadoop旨在同期文件系统工作,以HDFS著称。
当用户用EMR创建了一个Hadoop集群,他们可以从AWS S3(亚马逊简单储存服务)或者一些其他的数据存储复制数据到集群上的HDFS,或者也可以直接从S3访问数据。HDFS使用本地存储,而且通常提供了比从S3恢复更好的性能,但是在运行Hadoop工作之前,也需要时间从S3复制数据到HDFS。如果EMR集群要运行一段时间,且针对多项工作使用相同的数据,可能值得额外的启动时间来从S3复制数据到HDFS。
为什么hadoop不适合处理实时数据
1. 概述
Hadoop已 被公认为大数据分析领域无可争辩的王者,它专注与批处理。这种模型对许多情形(比如:为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自
高度动态的来源的实时信息。为了解决这个问题,就得借助Twitter推出得Storm。Storm不处理静态数据,但它处理预计会连续的流数据。考虑到
Twitter用户每天生成1.4亿条推文,那么就很容易看到此技术的巨大用途。
但Storm不只是一个传统的大数据分析系统:它是复杂事件处理(CEP)系统的一个示例。CEP系统通常分类为计算和面向检测,其中每个系统都是通过用户定义的算法在Storm中实现。举例而言,CEP可用于识别事件洪流中有意义的事件,然后实时的处理这些事件。
2. 为什么Hadoop不适合实时计算
这里说的不适合,是一个相对的概念。如果业务对时延要求较低,那么这个 问题就不存在了;但事实上企业中的有些业务要求是对时延有高要求的。下面我
就来说说:
2.1时延
Storm 的网络直传与内存计算,其时延必然比 Hadoop 的 HDFS 传输低得多;当计算模型比较适合流式时,Storm
的流试处理,省去了批处理的收集数据的时 间;因为 Storm 是服务型的作业,也省去了作业调度的时延。所以从时延的角
度来看,Storm 要快于 Hadoop,因而 Storm 更适合做实时流水数据处理。下面用一个业务场景来描述这个时延问题。
2.1.1业务场景
几千个日志生产方产生日志文件,需要对这些日志文件进行一些 ETL 操作存
入数据库。
我分别用 Hadoop 和 Storm 来分析下这个业务场景。假设我们用 Hadoop 来 处理这个业务流程,则需要先存入
HDFS,按每一分钟(达不到秒级别,分钟是最小纬度)切一个文件的粒度来计算。这个粒度已经极端的细了,再小的话
HDFS 上会一堆小文件。接着 Hadoop 开始计算时,一分钟已经过去了,然后再开始 调度任务又花了一分钟,然后作业运行起来,假设集群比较大,几秒钟就计算完
成了,然后写数据库假设也花了很少时间(理想状况下);这样,从数据产生到 最后可以使用已经过去了至少两分多钟。
而我们来看看流式计算则是数据产生时,则有一个程序一直监控日志的产生, 产生一行就通过一个传输系统发给流式计算系统,然后流式计算系统直接处理,
处理完之后直接写入数据库,每条数据从产生到写入数据库,在资源充足(集群 较大)时可以在毫秒级别完成。
2.1.2吞吐
在吞吐量方面,Hadoop 却是比 Storm 有优势;由于 Hadoop 是一个批处理计算,相比
Storm 的流式处理计算,Hadoop 的吞吐量高于 Storm。
2.2应用领域
Hadoop 是基于 MapReduce 模型的,处理海量数据的离线分析工具,而 Storm是分布式的,实时数据流分析工具,数据是源源不断产生的,比如:Twitter
的 Timeline。另外,M/R 模型在实时领域很难有所发挥,它自身的设计特点决定了 数据源必须是静态的。
2.3硬件
Hadoop 是磁盘级计算,进行计算时,数据在磁盘上,需要读写磁盘;Storm是内存级计算,数据直接通过网络导入内存。读写内存比读写磁盘速度快
N 个 数量级。根据行业结论,磁盘访问延迟约为内存访问延迟的 7.5w 倍,所以从这 个方面也可以看出,Storm
从速度上更快。
3.详细分析
在分析之前,我们先看看两种计算框架的模型,首先我们看下MapReduce的模型,以WordCount为例,如下图所示:
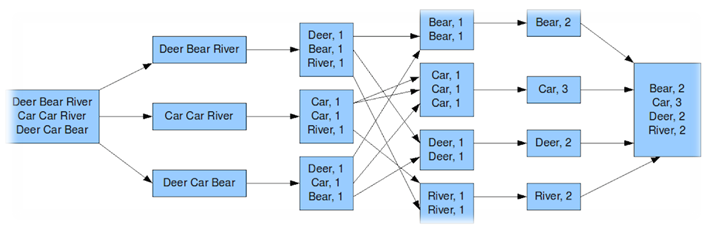
阅读过Hadoop源码下的hadoop-mapreduce-project工程中的代码应该对这个流程会熟悉,我这里就不赘述这个流程了。
接着我们在来看下Storm的模型,如下图所示:
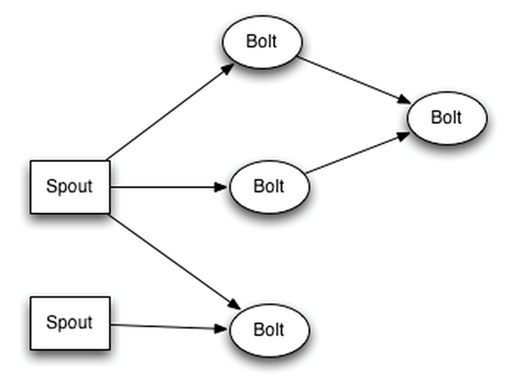
然后下面我们就会涉及到2个指标问题:延时和吞吐。
延时:指数据从产生到运算产生结果的时间。与“速度”息息相关。
吞吐:指系统单位时间处理的数据量。
另外,在资源相同的情况下;一般 Storm 的延时要低于 MapReduce,但是
吞吐吞吐也要低于 MapReduce,下面我描述下流计算和批处理计算的流程。 整个数据处理流程来说大致可以分为三个阶段:
1. 数据采集阶段
2. 数据计算(涉及计算中的中间存储)
3. 数据结果展现(反馈)
3.1.1数据采集阶段
目前典型的处理策略:数据的产生系统一般出自 Web 日志和解析 DB 的 Log,流计算数据采集是获取的消息队列(如:Kafka,RabbitMQ)等。批处理系统一
般将数据采集到分布式文件系统(如:HDFS),当然也有使用消息队列的。我们 暂且把消息队列和文件系统称为预处理存储。二者在这个阶段的延时和吞吐上没
太大的区别,接下来从这个预处理存储到数据计算阶段有很大的区别。流计算一 般在实时的读取消息队列进入流计算系统(Storm)的数据进行运算,批处理系
统一般回累计大批数据后,批量导入到计算系统(Hadoop),这里就有了延时的 区别。
3.1.2数据计算阶段
流计算系统(Storm)的延时主要有以下几个方面:
・Storm 进程是常驻的,有数据就可以进行实时的处理。MapReduce
数据累 计一批后由作业管理系统启动任务,Jobtracker 计算任务分配,Tasktacker 启动相关的运算进程。
・Storm 每个计算单元之间数据通过网络(ZeroMQ)直接传输。MapReduce
Map 任务运算的结果要写入到 HDFS,在 Reduce 任务通过网络拖过去运算。 相对来说多了磁盘读写,比较慢。
・对于复杂运算,Storm的运算模型直接支持DAG(有向无环图,多个应用程
序存在依赖关系,后一个应用程序的 输入为前一个的输出),MapReduce 需要多个 MR 过程组成,而且有些
Map 操作没有意义。
3.1.3数据展现
流计算一般运算结果直接反馈到最终结果集中(展示页面,数据库,搜索引擎的索引)。而 MapReduce
一般需要整个运算结束后将结果批量导入到结果集中。
4.总结
Storm 可以方便的在一个计算机集群中编写与扩展复杂的实时计算,Storm 之于实时,就好比 Hadoop
之于批处理。Storm 保证每个消息都会得到处理,而 且速度很快,在一个小集群中,每秒可以处理数以百万计的消息。
Storm 的主要特点如下:
・ 简单的编程模型。类似于MR降低了并行批处理的复杂行,Storm降低了实时处理的复杂行。
・ 可以使用各种编程语言。只要遵守实现Storm的通信协议即可。
・ 容错性。Storm会管理工作进程和节点故障。
・ 水平扩展。计算是在多个线程,进程和服务器之间并行进行的。
・ 可靠的消息处理。Storm保证每个消息至少能得到处理一次完整的处理,使用 MQ 作为其底层消息队列。
・ 本地模式。Storm 有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
最后总结:Hadoop 的 MR 基于 HDFS,需要切分输入数据,产生中间数据文件,排序,数据压缩,多分复制等,效率地下。而
Storm 基于 ZeroMQ 这个高性能的消息通讯库,不能持久化数据。
|





