| 1、MapReduce理论简介
1.1 MapReduce编程模型
MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
1.2 MapReduce处理过程
在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map函数和reduce函数。map函数接收一个<key,value>形式的输入,然后同样产生一个<key,value>形式的中间输出,Hadoop函数接收一个如<key,(list
of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key,value>形式的。
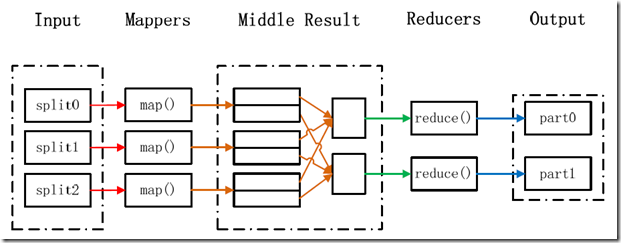
MapReduce处理大数据集的过程
2、运行WordCount程序
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello
World",该程序的完整代码可以在Hadoop安装包的"src/examples"目录下找到。单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。
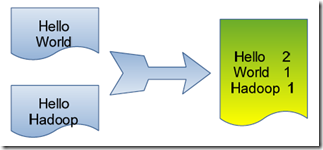
2.1 准备工作
现在以"hadoop"普通用户登录"Master.Hadoop"服务器。
1)创建本地示例文件
首先在"/home/hadoop"目录下创建文件夹"file"。
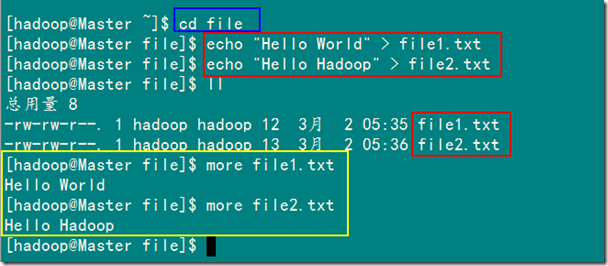
接着创建两个文本文件file1.txt和file2.txt,使file1.txt内容为"Hello
World",而file2.txt的内容为"Hello Hadoop"。
2)在HDFS上创建输入文件夹

3)上传本地file中文件到集群的input目录下

2.2 运行例子
1)在集群上运行WordCount程序
备注:以input作为输入目录,output目录作为输出目录。
已经编译好的WordCount的Jar在"/usr/hadoop"下面,就是"hadoop-examples-1.0.0.jar",所以在下面执行命令时记得把路径写全了,不然会提示找不到该Jar包。

2)MapReduce执行过程显示信息
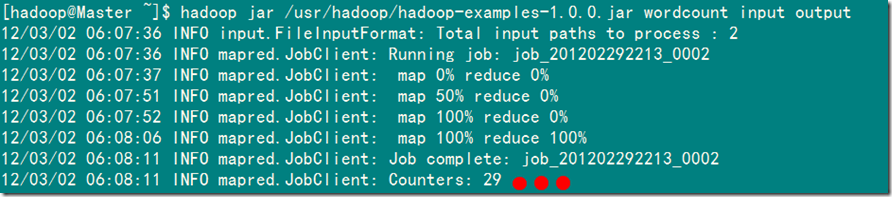
Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop
Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_201202292213_0002,而且得知输入文件有两个(Total
input paths to process : 2),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。比如说,在本例中,map的task数量是2个,reduce的task数量是一个。map的输入record数是2个,输出record数是4个等信息。
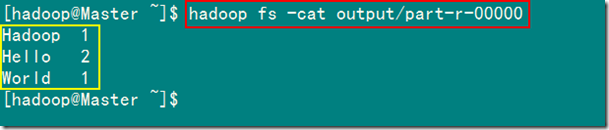
2.3 查看结果
1)查看HDFS上output目录内容

从上图中知道生成了三个文件,我们的结果在"part-r-00000"中。
2)查看结果输出文件内容
3、WordCount源码分析
3.1 特别数据类型介绍
Hadoop提供了如下内容的数据类型,这些数据类型都实现了WritableComparable接口,以便用这些类型定义的数据可以被序列化进行网络传输和文件存储,以及进行大小比较。
BooleanWritable:标准布尔型数值
ByteWritable:单字节数值
DoubleWritable:双字节数
FloatWritable:浮点数
IntWritable:整型数
LongWritable:长整型数
Text:使用UTF8格式存储的文本
NullWritable:当<key,value>中的key或value为空时使用
3.2 旧的WordCount分析
1)源代码程序
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class Map extends MapReduceBase
implements
Mapper<LongWritable, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase
implements
Reducer<Text, IntWritable, Text, IntWritable>
{
public void reduce(Text key, Iterator<IntWritable>
values,
OutputCollector<Text, IntWritable> output,
Reporter reporter)
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws
Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
} |
3)主方法Main分析
public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
} |
首先讲解一下Job的初始化过程。main函数调用Jobconf类来对MapReduce Job进行初始化,然后调用setJobName()方法命名这个Job。对Job进行合理的命名有助于更快地找到Job,以便在JobTracker和Tasktracker的页面中对其进行监视。
JobConf conf = new JobConf(WordCount. class ); conf.setJobName("wordcount" ); |
接着设置Job输出结果<key,value>的中key和value数据类型,因为结果是<单词,个数>,所以key设置为"Text"类型,相当于Java中String类型。Value设置为"IntWritable",相当于Java中的int类型。
conf.setOutputKeyClass(Text.class );
conf.setOutputValueClass(IntWritable.class ); |
然后设置Job处理的Map(拆分)、Combiner(中间结果合并)以及Reduce(合并)的相关处理类。这里用Reduce类来进行Map产生的中间结果合并,避免给网络数据传输产生压力。
conf.setMapperClass(Map.class );
conf.setCombinerClass(Reduce.class );
conf.setReducerClass(Reduce.class ); |
接着就是调用setInputPath()和setOutputPath()设置输入输出路径。
conf.setInputFormat(TextInputFormat.class );
conf.setOutputFormat(TextOutputFormat.class
); |
(1)InputFormat和InputSplit
InputSplit是Hadoop定义的用来传送给每个单独的map的数据,InputSplit存储的并非数据本身,而是一个分片长度和一个记录数据位置的数组。生成InputSplit的方法可以通过InputFormat()来设置。
当数据传送给map时,map会将输入分片传送到InputFormat,InputFormat则调用方法getRecordReader()生成RecordReader,RecordReader再通过creatKey()、creatValue()方法创建可供map处理的<key,value>对。简而言之,InputFormat()方法是用来生成可供map处理的<key,value>对的。
Hadoop预定义了多种方法将不同类型的输入数据转化为map能够处理的<key,value>对,它们都继承自InputFormat,分别是:
InputFormat
|
|---BaileyBorweinPlouffe.BbpInputFormat
|---ComposableInputFormat
|---CompositeInputFormat
|---DBInputFormat
|---DistSum.Machine.AbstractInputFormat
|---FileInputFormat
|---CombineFileInputFormat
|---KeyValueTextInputFormat
|---NLineInputFormat
|---SequenceFileInputFormat
|---TeraInputFormat
|---TextInputFormat |
其中TextInputFormat是Hadoop默认的输入方法,在TextInputFormat中,每个文件(或其一部分)都会单独地作为map的输入,而这个是继承自FileInputFormat的。之后,每行数据都会生成一条记录,每条记录则表示成<key,value>形式:
key值是每个数据的记录在数据分片中字节偏移量,数据类型是LongWritable;
value值是每行的内容,数据类型是Text。
(2)OutputFormat
每一种输入格式都有一种输出格式与其对应。默认的输出格式是TextOutputFormat,这种输出方式与输入类似,会将每条记录以一行的形式存入文本文件。不过,它的键和值可以是任意形式的,因为程序内容会调用toString()方法将键和值转换为String类型再输出。
3)Map类中map方法分析
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
} |
Map类继承自MapReduceBase,并且它实现了Mapper接口,此接口是一个规范类型,它有4种形式的参数,分别用来指定map的输入key值类型、输入value值类型、输出key值类型和输出value值类型。在本例中,因为使用的是TextInputFormat,它的输出key值是LongWritable类型,输出value值是Text类型,所以map的输入类型为<LongWritable,Text>。在本例中需要输出<word,1>这样的形式,因此输出的key值类型是Text,输出的value值类型是IntWritable。
实现此接口类还需要实现map方法,map方法会具体负责对输入进行操作,在本例中,map方法对输入的行以空格为单位进行切分,然后使用OutputCollect收集输出的<word,1>。
4)Reduce类中reduce方法分析
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } |
Reduce类也是继承自MapReduceBase的,需要实现Reducer接口。Reduce类以map的输出作为输入,因此Reduce的输入类型是<Text,Intwritable>。而Reduce的输出是单词和它的数目,因此,它的输出类型是<Text,IntWritable>。Reduce类也要实现reduce方法,在此方法中,reduce函数将输入的key值作为输出的key值,然后将获得多个value值加起来,作为输出的值。
3.3 新的WordCount分析
1)源代码程序
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text,
IntWritable>{
private final static IntWritable one =
new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value,
Context context)
throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable>
values,Context context)
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws
Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,
args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount
<in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new
Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)
? 0 : 1);
}
} |
1)Map过程
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new
IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context
context)
throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
} |
Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量。然后StringTokenizer类将每一行拆分成为一个个的单词,并将<word,1>作为map方法的结果输出,其余的工作都交有MapReduce框架处理。
2)Reduce过程
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable>
values,Context context)
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} |
Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
3)执行MapReduce任务
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,
args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount
<in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ?
0 : 1);
} |
在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。此处设置了使用TokenizerMapper完成Map过程中的处理和使用IntSumReducer完成Combine和Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务。
4、WordCount处理过程
本节将对WordCount进行更详细的讲解。详细执行步骤如下:
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如图4-1所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。
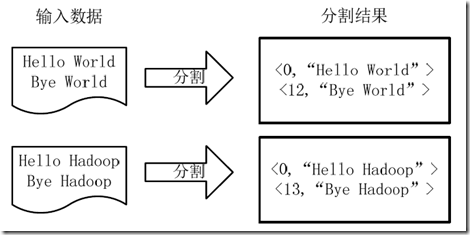
图4-1 分割过程
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如图4-2所示。
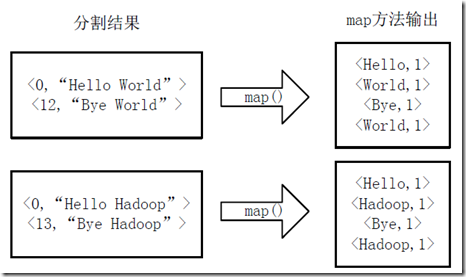
图4-2 执行map方法
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如图4-3所示。
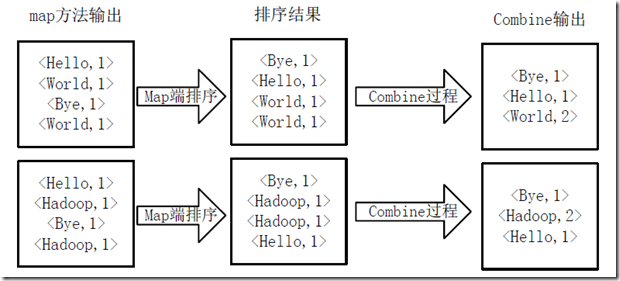
图4-3 Map端排序及Combine过程
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如图4-4所示。
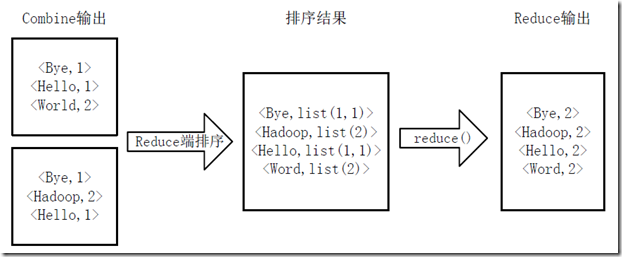
图4-4 Reduce端排序及输出结果
5、MapReduce新旧改变
Hadoop最新版本的MapReduce Release 0.20.0的API包括了一个全新的Mapreduce
JAVA API,有时候也称为上下文对象。
新的API类型上不兼容以前的API,所以,以前的应用程序需要重写才能使新的API发挥其作用
。
新的API和旧的API之间有下面几个明显的区别。
新的API倾向于使用抽象类,而不是接口,因为这更容易扩展。例如,你可以添加一个方法(用默认的实现)到一个抽象类而不需修改类之前的实现方法。在新的API中,Mapper和Reducer是抽象类。
新的API是在org.apache.hadoop.mapreduce包(和子包)中的。之前版本的API则是放在org.apache.hadoop.mapred中的。
新的API广泛使用context object(上下文对象),并允许用户代码与MapReduce系统进行通信。例如,MapContext基本上充当着JobConf的OutputCollector和Reporter的角色。
新的API同时支持"推"和"拉"式的迭代。在这两个新老API中,键/值记录对被推mapper中,但除此之外,新的API允许把记录从map()方法中拉出,这也适用于reducer。"拉"式的一个有用的例子是分批处理记录,而不是一个接一个。
新的API统一了配置。旧的API有一个特殊的JobConf对象用于作业配置,这是一个对于Hadoop通常的Configuration对象的扩展。在新的API中,这种区别没有了,所以作业配置通过Configuration来完成。作业控制的执行由Job类来负责,而不是JobClient,它在新的API中已经荡然无存。
|






