|
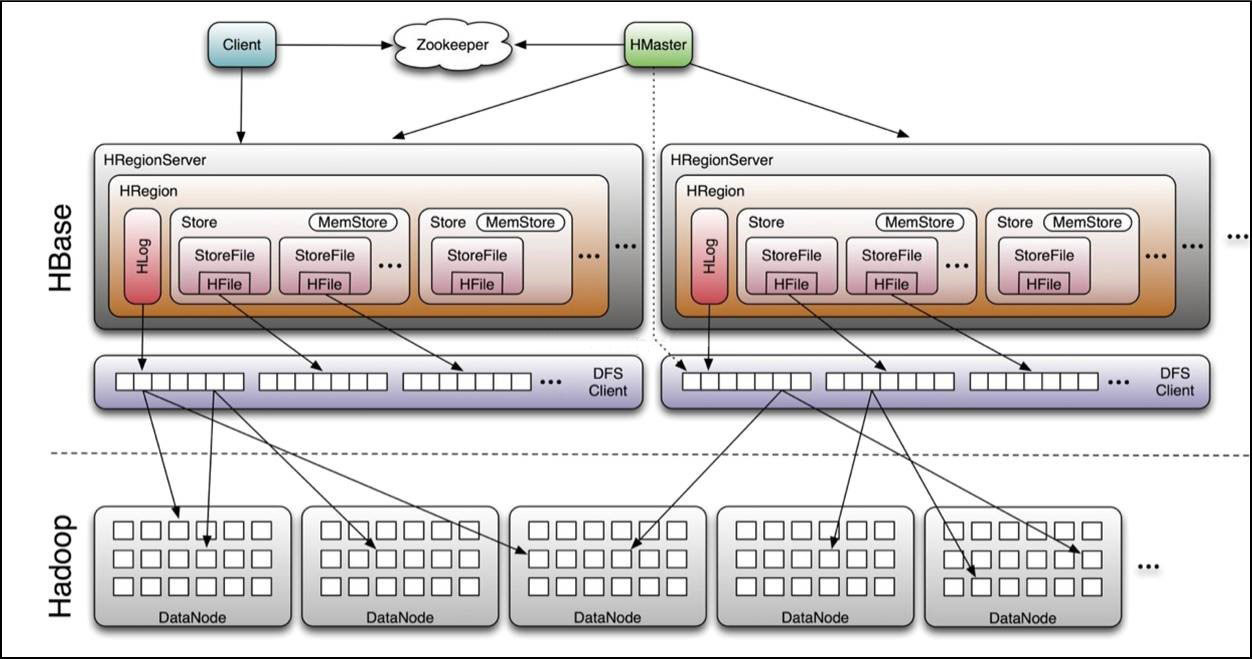
Hbase����ģ�ͼܹ���ϵ
hbase��������
HRegionServer�����region��������HRegionʵ��������Ϊÿ������HColumnFamily���û�������ʱ����ģ�����һ��
Storeʵ����ÿ��Storeʵ������һ������StoreFileʵ������ʵ�����ݴ洢�ļ�HFile����������װ��ÿ��Store���Ӧһ��
MemStore��д������ʱ���ݻ���д��Hlog�гɹ�����д��MemStore�С�Memstore�е�������Ϊ�ռ����ޣ�������Ҫ����flush���ļ�StoreFile�У�ÿ��flush���������µ�StoreFile��HRegionServer�ڴ���Flush����ʱ��������д��HFile�ļ����ô洢��HDFS�ϣ����Ҵ洢���д����������кš�
Client
(1)����HBase��Ⱥ�����
(1)ʹ��HBase RPC������HMaster��HRegionserverͨ��
(1)��HMasterͨ�Ž��й�����IJ���
(1)��HRegionserverͨ�Ž��ж�д�����
(1)��������hbase �Ľӿڣ�client ά����һЩcache ���ӿ��hbase
�ķ��ʣ�����regione ��λ����Ϣ
Zookeeper
��֤�κ�ʱ��Ⱥ��ֻ��һ��running master��Master��RegionServers����ʱ����ZooKeeperע��Ĭ������£�HBase
����ZooKeeper ʵ�������磬��������ֹͣZooKeeperZookeeper������ʹ��Master�����ǵ������
��������Region ��Ѱַ���
ʵʱ���RegionServer ��״̬����Regionserver �����ߺ�������Ϣ��ʵʱ֪ͨ��Master
�洢Hbase��schema��tableԪ����
Master
�����û���Table����ɾ�IJ����
��RegionSplit������region�ķ���
����regionserver�ĸ��ؾ��⣬����region�ֲ�
��RegionServerͣ������ʧЧRegionserver��region�����·���
HMasterʧЧ���ᵼ������Ԫ�������ģ��������ݶ�д���ǿ�����������
Region Server
Regionserverά��region����������Щregion��IO����
Regionserver�����з������й����б�ù����region
����ͼ���Կ�����client ����hbase�����ݵĹ��̲�����Ҫmaster ���룬Ѱַ������zookeeper��regionserver�����ݶ�д����regioneserver��
HRegionServer��Ҫ������Ӧ�û�I/O������HDFS�ļ�ϵͳ�ж�д���ݣ���HBase������ĵ�ģ�顣
�����洢
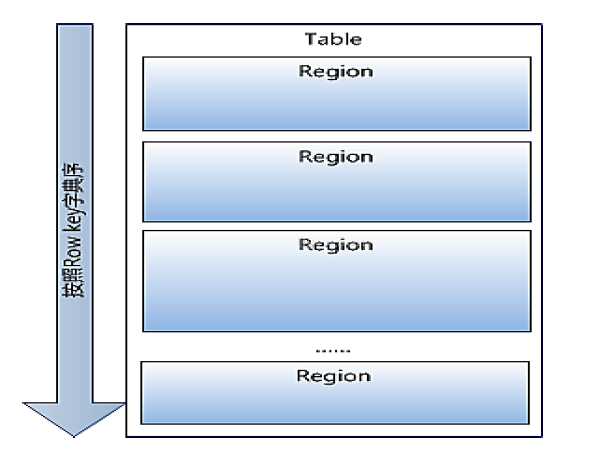
1.table�е������ж��ǰ���rowkey���ֵ�����
2.table���еķ����Ϸָ�Ϊ���Region
3.Region����С�ָÿ������ʼֻ��һ��region�������������࣬region��������������ֵʱ��region�ͻ�ָ�������µ�region�����region��Խ��Խ�ࡣ
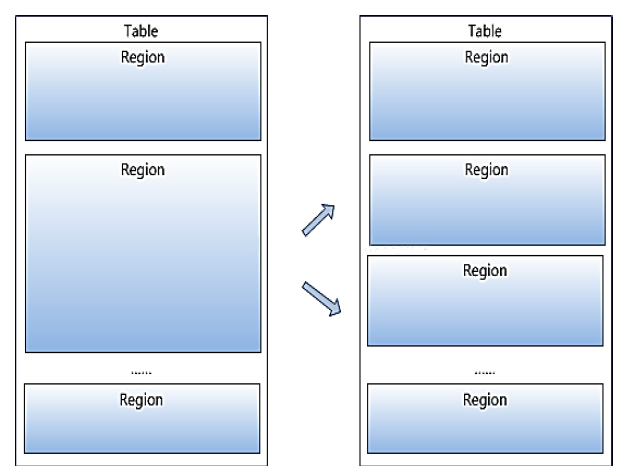
4.region��hbase�зֲ�ʽ�洢���ؾ������С��Ԫ����ͬ��regioon�ֲ�����ͬ��regionserver�ϣ���Region�����ֵ���ͬ��Region
Server�ϡ�
Table ���еķ����Ϸָ�Ϊ���HRegion��һ��region��[startkey,endkey)��ʾ
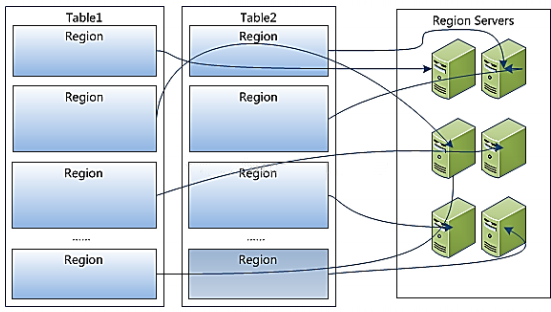
Region�Ƿֲ�ʽ�洢����С��Ԫ�������Ǵ洢����С�ĵ�Ԫ��
1. region��һ������Store��ɣ�ÿ��Store����һ��columnfamily
2. ÿ��Store����һ��memStore��0������StoreFile���
3. memStore�洢���ڴ��У�StoreFile�洢��HDFS��
Table��Region�ڲ��ṹ
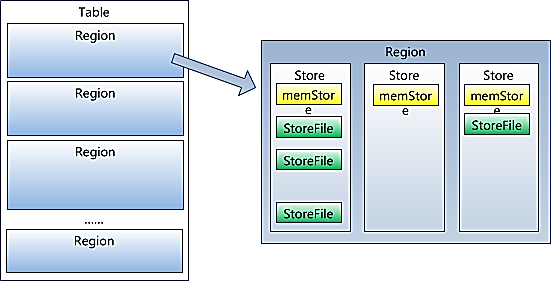
1.һ�����ᰴ���У���������������Ϊ���ɸ�regionÿһ��region�����һ̨�ض���regionserver����
2.ÿһ��region�ڲ���Ҫ�������廮��Ϊ���ɸ�HStore
3.ÿ��HStore�е����ݻ���ص����ɸ�HFILE�ļ���
4.region������������ݲ����������������һ����ֵ������
5.����region�ķ��ѣ�һ̨regionserver�Ϲ�����region��Խ��Խ��
6.HMASTER�����regionserver�Ϲ�����region�������ؾ���
7.region�е�����ӵ��һ���ڴ滺�棺memstore�����ݵķ���������memstore�н���
8.memstore�е�������Ϊ�ռ����ޣ�������Ҫ����flush���ļ�storefile�У�ÿ��flush���������µ�storefile
9.storefile����������ʱ��Ҳ������ӣ�regionserver�ᶨ�ڽ�����storefile���кϲ���merge��
StoreFile
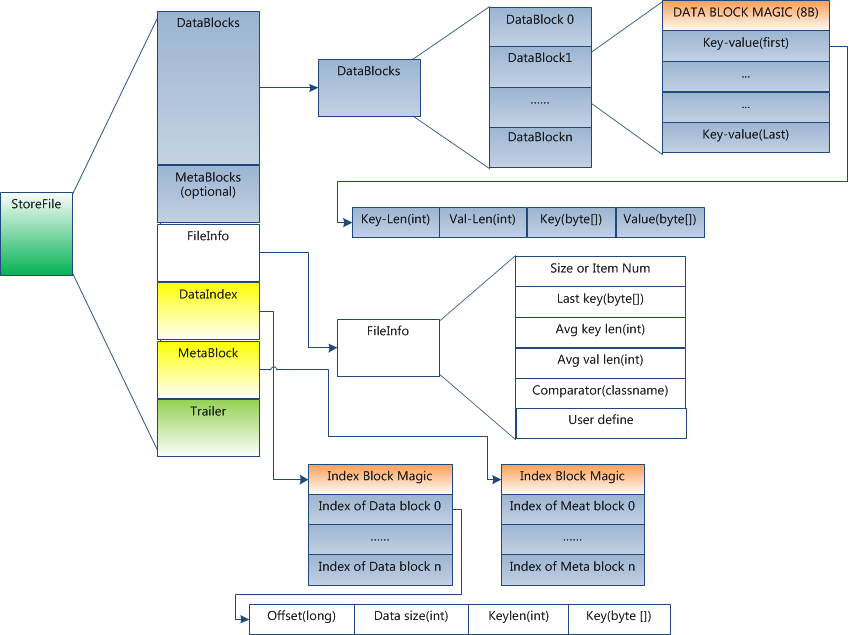
Data Block �ΨC������е����ݣ��ⲿ�ֿ��Ա�ѹ��
Meta Block �� (��ѡ��)�C�����û��Զ����kv�ԣ����Ա�ѹ����
File Info �ΨCHfile��Ԫ��Ϣ������ѹ�����û�Ҳ��������һ���������Լ���Ԫ��Ϣ��
Data Block Index �ΨCData Block��������ÿ��������key�DZ�������block�ĵ�һ����¼��key��
Meta Block Index�� (��ѡ��)�CMeta Block��������
Trailer�C��һ���Ƕ����ġ�������ÿһ�ε�ƫ��������ȡһ��HFileʱ�������ȶ�ȡTrailer��Trailer������ÿ���ε���ʼλ��(�ε�Magic
Number��������ȫcheck)��Ȼ��DataBlock Index�ᱻ��ȡ���ڴ��У�������������ij��keyʱ������Ҫɨ������HFile����ֻ����ڴ����ҵ�key���ڵ�block��ͨ��һ�δ���io������
block��ȡ���ڴ��У����ҵ���Ҫ��key��DataBlock Index����LRU������̭��
HFile��Data Block��Meta Blockͨ������ѹ����ʽ�洢��ѹ��֮����Դ���������IO�ʹ���IO����֮�����Ŀ�����Ȼ����Ҫ����cpu����ѹ���ͽ�ѹ����Ŀ��Hfile��ѹ��֧�����ַ�ʽ��Gzip��Lzo��
HFile��ʽ
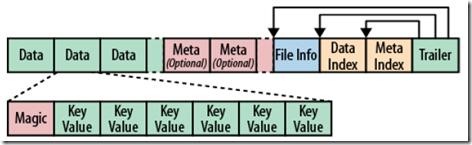
HFile�ļ����Ȳ��̶������ȹ̶��Ŀ�ֻ��������Trailer��FileInfo
Trailer��ָ��ָ���������ݿ����ʼ�㣬�����ڳ־û����ݵ��ļ�����ʱд��ģ���ȷ��Ϊ���ɱ�Ĵ洢�ļ���
File Info�м�¼���ļ���һЩMeta��Ϣ�����磺AVG_KEY_LEN,AVG_VALUE_LEN,
LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY��
Data Index��Meta Index���¼��ÿ��Data���Meta�����ʼ��
Data Block��HBase I/O�Ļ�����Ԫ��Ϊ�����Ч�ʣ�HRegionServer���л���LRU��Block
Cache���ơ�
ÿ��Data��Ĵ�С�����ڴ���һ��Table��ʱ��ͨ������ָ������ŵ�Block������˳��Scan��С��Block���������ѯ.
ÿ��Data����˿�ͷ��Magic�������һ����KeyValue��ƴ�Ӷ���, Magic���ݾ���һЩ������֣�Ŀ���Ƿ�ֹ������
HFile�����ÿ��KeyValue�Ծ���һ����byte���顣���byte������������˺ܶ�������й̶��Ľṹ��
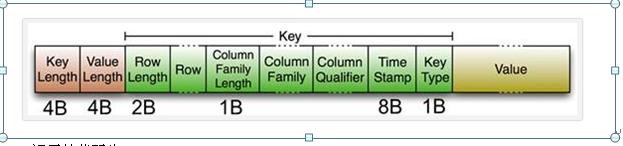
KeyValue��ʽ
KeyLength��ValueLength�������̶��ij��ȣ��ֱ����Key���Ⱥ�Value�ij��ȣ���˿��Ժ��Լ�ֱ�ӷ��ʣ��û�����ʵ������������Ծ��
Key���֣�Row Length�ǹ̶����ȵ���ֵ����ʾRowKey�ij��ȣ�Row ����RowKey��Column
Family Length�ǹ̶����ȵ���ֵ����ʾFamily�ij��Ƚ��ž���Column Family���ٽ�����Qualifier��Ȼ���������̶����ȵ���ֵ����ʾTime
Stamp��Key Type��Put/Delete��
Value����û����ô���ӵĽṹ�����Ǵ���Ķ���������
Zookeeper������
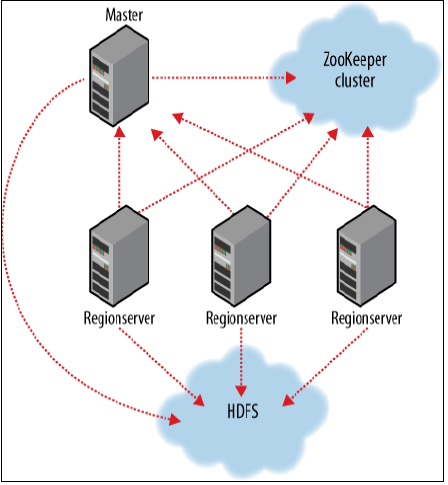
.HBase����ZooKeeper��Ĭ������£�HBase����ZooKeeper�������رգ�
2.Master��RegionServer����ʱ����Zookeeperע�ᡣ
3.Zookeeper������ʹ��Master�����ǵ�����ϡ�
Redion��λ
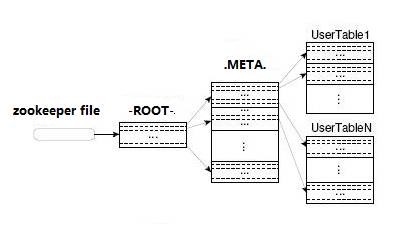
Ѱ��RegionServer
1.ZooKeeper�������ҵ�ROOT����λ�ã�
2. -ROOT-��ֻ��洢��һ��region�ϣ���ROOT�����ҵ�.META����λ�ã�
3..META���洢���û���ʵ�ʴ洢��λ�ã����û�����
4.�û���
-ROOT-
1.������.META.�����ڵ�region�б����ñ�ֻ��洢��һ������
2.ZooKeeper�м�¼��-ROOT-����location
.META���������������û��ռ�region�б����Լ�RegionServer�ķ�������ַ
��˷�������ΪClient�����û�����֮ǰ��Ҫ���ȷ���zookeeper��Ȼ�����-ROOT-����������.META.�����������ҵ��û����ݵ�λ��ȥ���ʡ�
HBase�ݴ���
Master�ݴ���Zookeeper����ѡ��һ���µ�Master
1.��Master�����У����ݶ�ȡ���ճ����У�
2.��master�����У�region�з֡����ؾ���������У�
RegionServer�ݴ�����ʱ��Zookeeper�㱨���������һ��ʱ����δ����������
1.Master����RegionServer�ϵ�Region���·��䵽����RegionServer�ϣ�
2.ʧЧ�������ϡ�Ԥд����־�������������зָ�����µ�RegionServer
Zookeeper�ݴ���Zookeeper��һ���ɿ��ط���һ������3��5��Zookeeperʵ��
Write-Ahead-Log
Write-Ahead-Log �û����������ݵ��ݴ��ͻָ���
ÿ��HRegionServer�ж���һ��HLog����HLog��һ��ʵ��Write Ahead Log���࣬��ÿ���û�����д��MemStore��ͬʱ��Ҳ��дһ�����ݵ�HLog�ļ��У�HLog�ļ���ʽ����������HLog�ļ����ڻ�������µģ���
ɾ���ɵ��ļ����ѳ־û���StoreFile�е����ݣ���
��HRegionServer������ֹ��HMaster��ͨ��Zookeeper��֪����HMaster���Ȼᴦ��������
HLog�ļ����� ���в�ͬRegion��Log���ݽ��в�֣��ֱ�ŵ���Ӧregion��Ŀ¼�£�Ȼ���ٽ�ʧЧ��region���·��䣬��ȡ����Щregion��
HRegionServer��Load Region�Ĺ����У��ᷢ������ʷHLog��Ҫ��������˻�Replay
HLog�е����ݵ�MemStore�У�Ȼ��flush��StoreFiles��������ݻָ�
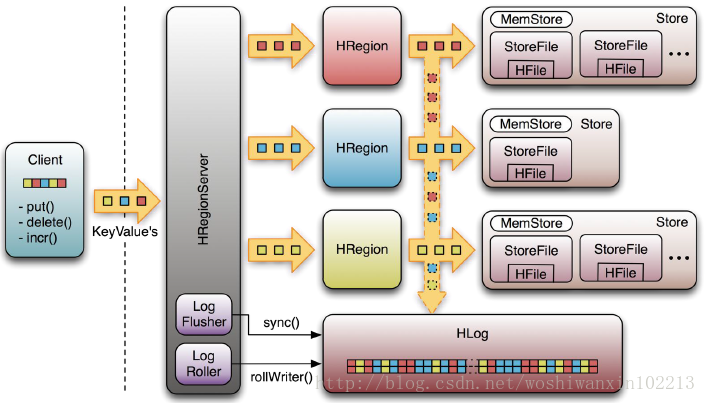
Write-Ahead-Log(WAL)Ԥд��־
1.Client��RegionServer���ύ���ݵ�ʱ������дWAL��־(WAL)����WAL��־д��ɹ���Client�Żᱻ��֪�ύ���ݳɹ������д��WALʧ�ܣ�����߿ͻ����ύʧ�ܡ�����ͨ��WAL��־�ָ�ʧ�ܵ����ݡ�
2.һ��Regionserver�����е�Region������һ��HLog,һ���ύ��дWAL����дmemStore��
|






