| БрМЭЦМі: |
| БОЮФРДздгкdaniellaah.github.ioЃЌНщЩмСЫЛњЦїбЇЯАЕФЕЅБфСПЯпадЛиЙщЕФФЃаЭеЙЪОжаЕФКЏЪ§КЭЬнЖШЃЌЮФжаВЩгУЖрЪ§ЭМЦЌЕФаЮЪНЯъЯИУшЪіЁЃ |
|
БОЮФЕФЕквЛЦЊЮвЕФЛњЦїбЇЯАБЪМЧ(вЛ)-МрЖНбЇЯАvs
ЮоМрЖНбЇЯА
ФЃаЭеЙЪО
бЕСЗМЏ
ЪВУДЪЧбЕСЗМЏ(Training Set)ЃПгабЕСЗбљР§(training example)зщГЩЕФМЏКЯОЭЪЧбЕСЗМЏЁЃШчЯТЭМЫљЪОЃЌгвБпЕФСНСаЪ§ОнОЭЪЧБОР§згжаЕФбЕСЗМЏЃЌ
Цфжа\((x, y)\)ЪЧвЛИібЕСЗбљР§ЃЌ\((x^{(i)}, y^{(i)})\)ЪЧЕк\(i\)ИібЕСЗбљР§ЁЃ
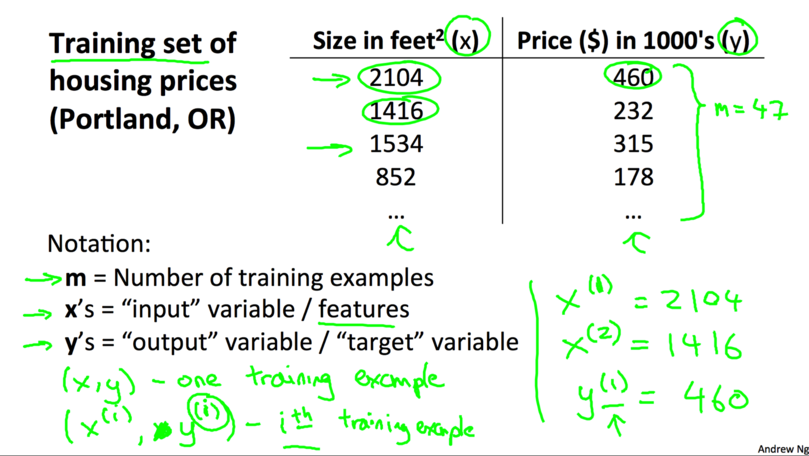
МйЩшКЏЪ§
ЭЈЙ§бЕСЗМЏКЭбЇЯАЫуЗЈЮвУЧОЭПЩвдЕУЕНМйЩшКЏЪ§(Hypothesis
Function)ЃЌМйЩшКЏЪ§МЧЮЊhЁЃдкЗПЮнЕФР§згжаЃЌЮвУЧЕФМйЩшКЏЪ§ОЭЯрЕБгквЛИігЩЗПЮнУцЛ§ЕНЗПЮнМлИёЕФНќЫЦКЏЪ§ЃЌЭЈЙ§етИіМйЩшОЭПЩвдЕУГіЯргІУцЛ§ЗПЮнЕФЙРМлСЫЁЃШчЯТЭМЫљЪОЃК
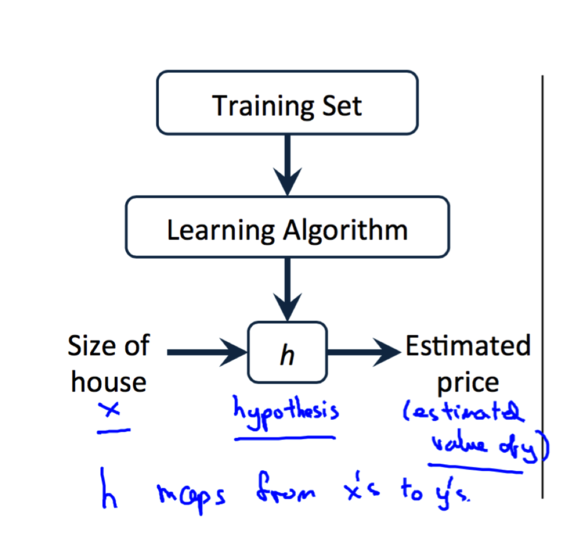
ФЧУДЮвУЧИУШчКЮБэЪОМйЩшКЏЪ§ФиЃПдкБОР§жаЃЌжЛгавЛИіБфСПx(ЗПЮнЕФУцЛ§)ЃЌЮвУЧПЩвдНЋМйЩшКЏЪ§hвдШчЯТЕФаЮЪНБэЪОЃК<font
size='4'>$$ {h_\theta(x) =\theta_0+\theta_1x} $$</font>ЮЊСЫЗНБу$h_\theta(x)$вВПЩвдМЧзї$h(x)$ЁЃетИіОЭНазіЕЅБфСПЕФЯпадЛиЙщ(Linear
Regression with One Variable)ЁЃ(Linear regression with
one variable = Univariate linear regressionЃЌ univariateЪЧone
variableЕФзАБЦаДЗЈЁЃ) ШчЯТЭМЫљЪОЁЃ

ДњМлКЏЪ§
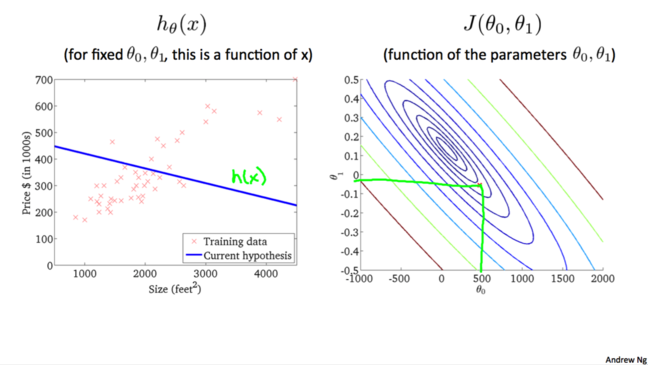
дкИеВХЕФМйЩшКЏЪ§жагаСНИіЮДжЊЕФВЮЪ§$\theta_0$КЭ$\theta_1$ЃЌЕБбЁдёВЛЭЌЕФ$\theta_0$КЭ$\theta_1$ЪБЃЌЮвУЧФЃаЭЕФаЇЙћПЯЖЈЪЧВЛвЛбљЕФЁЃШчЯТЭМЫљЪОЃЌСаОйСЫШ§жжЧщПіЯТЕФМйЩшКЏЪ§ЁЃ

ФЧУДЮвУЧИУШчКЮбЁдёетСНИіВЮЪ§ФиЃПЮвУЧЕФЯыЗЈЪЧбЁдё$\theta_0$КЭ$\theta_1$ЃЌЪЙЕУЖдгкбЕСЗбљР§$(x,y)$ЃЌ$h_\theta(x)$зюНгНќ$y$ЁЃМДЃЌЪЙУПИібљР§ЕФЙРМЦжЕгыецЪЕжЕжЎМфЕФВюЕФЦНЗНЕФОљжЕзюаЁЁЃгУЙЋЪНБэДяЮЊ:
<font size='4'>$${\mathop{minimize}\limits_{\theta_0,\theta_1}
\frac{1}{2m}\sum_{i=0}^m\left(h_\theta(x^{(i)}) -y^{(i)}\right)^2}$$</font>
НЋЩЯУцЕФЙЋЪНminimizeгвБпВПЗжМЧЮЊ$J(\theta_0,\theta_1)$ЃК
<font size='4'>$$ {J(\theta_0,\theta_1)
=\frac{1}{2m}\sum_{i=0} ^m\left(h_\theta(x^{(i)})-y^{(i)}\right)^2}$$</font>
етбљОЭЕУЕНСЫЮвУЧЕФДњМлКЏЪ§(Cost Function)$J (\theta_0,\theta_1)$ЃЌЮвУЧЕФФПБъОЭЪЧ<font
size='4'>$$\mathop{minimize} \limits_{\theta_0,\theta_1}
J(\theta_0,\theta_1)$$</font>

ДњМлКЏЪ§IIЁЁ
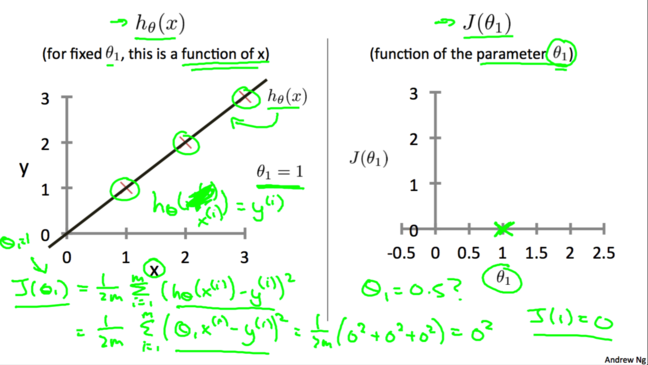
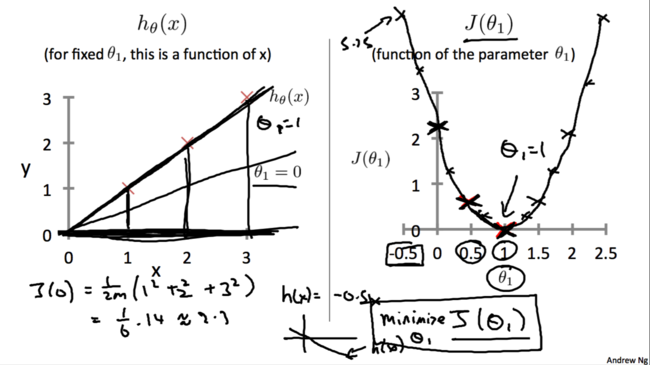
ЯждкЮЊСЫИќЗНБуЕиЬНОП$h_\theta(x)$гы$ J(\theta_0,\theta_1)$ЕФЙиЯЕЃЌЮвУЧЯШСю$\theta_0$ЕШгк0ЁЃетбљЮвУЧОЭЕУЕНСЫМђЛЏКѓЕФМйЩшКЏЪ§ЃЌЯргІЕивВПЩвдЕУЕНМђЛЏЕФДњМлКЏЪ§ЁЃШчЭМЫљЪО:

МђЛЏжЎКѓЃЌЮвУЧдйСю$\theta_1=1$ЃЌОЭЕУЕН$h_\theta(x)=x$ШчЯТЭМзѓЫљЪОЁЃЭМжаШ§ИіКьВцБэЪОбЕСЗбљР§ЃЌЭЈЙ§ДњМлКЏЪ§ЕФЖЈвхЮвУЧМЦЫуЕУГі$J(1)=0$ЃЌЖдгІЯТЭМгвжаЕФ$(1,0)$зјБъЁЃ
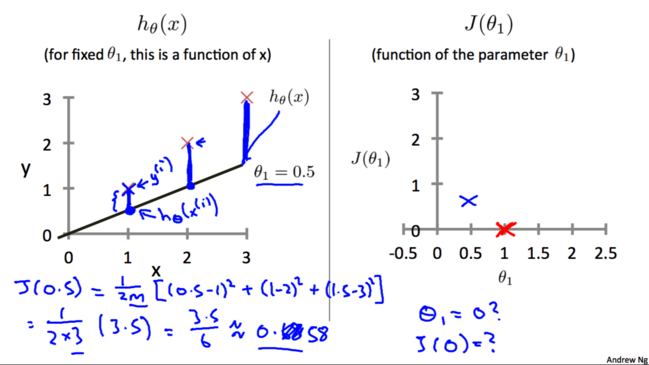
жиИДЩЯУцЕФВНжшЃЌдйСю$\theta_1=0.5$ЃЌЕУЕН$h_\theta(x)$ШчЯТЭМзѓЫљЪОЁЃЭЈЙ§МЦЫуЕУГі$J(0.5)=0.58$ЃЌЖдгІЯТЭМгвжаЕФ$(0.5,0.58)$зјБъЁЃ
ЖдгкВЛЭЌЕФ$\theta_1$ЃЌПЩвдЕУЕНВЛЭЌЕФМйЩшКЏЪ§$h_\theta(x)$ЃЌгкЪЧОЭгаСЫВЛЭЌЕФ$J(\theta_1)$ЕФжЕЁЃНЋетаЉЕуСЌНгЦ№РДОЭПЩвдЕУЕН$J(\theta_1)$ЕФЧњЯпЃЌШчЯТЭМЫљЪОЃК
ДњМлКЏЪ§IIIЁЁЁЁЁЁ
дкЩЯвЛНкжаЃЌЮвУЧСю$\theta_0$ЕШгк0ЃЌЕУЕН$J(\theta_1)$ЕФЧњЯпЁЃШчЙћ$\theta_0$ВЛЕШгк0ЃЌР§Шч$\theta_0=50$,
$\theta_0=0.06$ЃЌДЫЪБОЭгаСНИіБфСПЃЌКмШнвзЯыЕН$J(\theta_1)$гІИУЪЧвЛИіЧњУцЁЃ
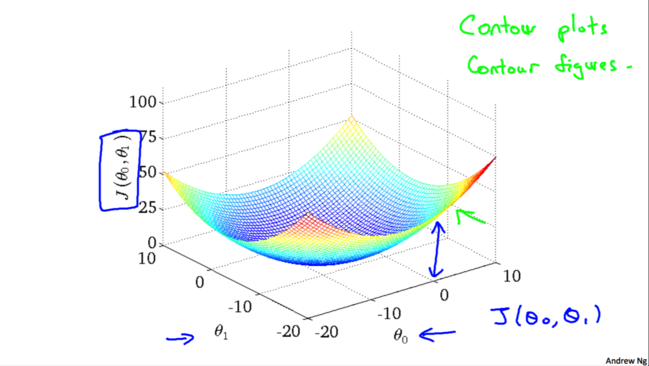
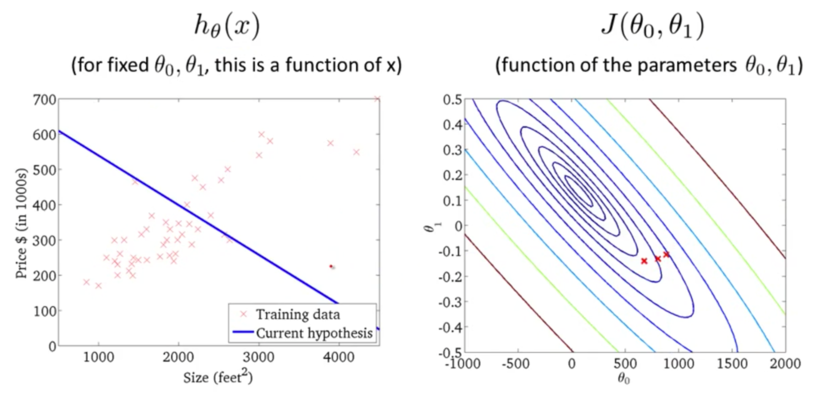
етИіЭМЪЧНЬЪкгУmatlabЛцжЦЕФЃЌгЩгк3DЭМаЮВЛЬЋЗНБуЮвУЧбаОПЃЌЮвУЧОЭЪЙгУЖўЮЌЕФЕШИпЯп(ЩЯЭМгвЩЯНЧНЬЪкаДЕФcontour
plots/figures)ЃЌетбљПДЩЯШЅБШНЯЧхГўвЛаЉЁЃШчЯТЭМгвЃЌдНЭљРяБэЪО$J(\theta_0,\theta_1)$ЕФжЕдНаЁ(ЖдгІ3DЭМжадНППНќзюЕЭЕуЕФЮЛжУ)ЁЃЯТЭМзѓБэЪОЕБ$\theta_0=800$,
$\theta_1=0.15$ЕФЪБКђЖдгІЕФ$h_\theta(x)$ЃЌЭЈЙ§$\theta_0$, $\theta_1$ЕФжЕПЩвдевЕНЯТЭМгвжа$J(\theta_0,\theta_1)$ЕФжЕЁЃ
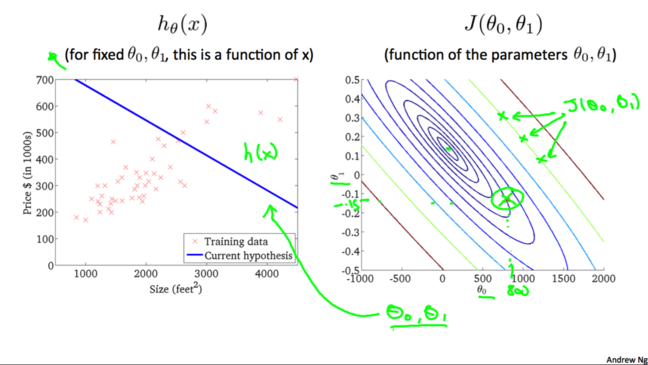
РрЫЦЕиЃК
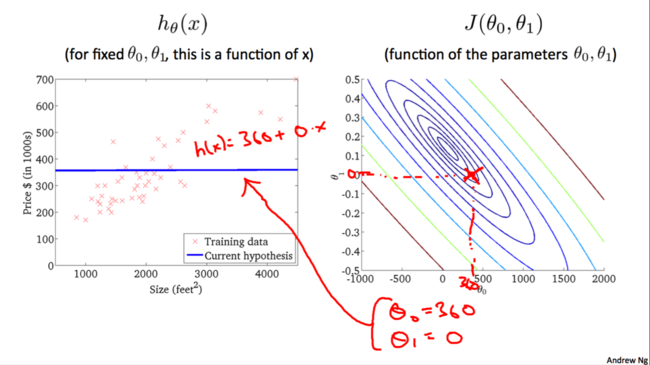
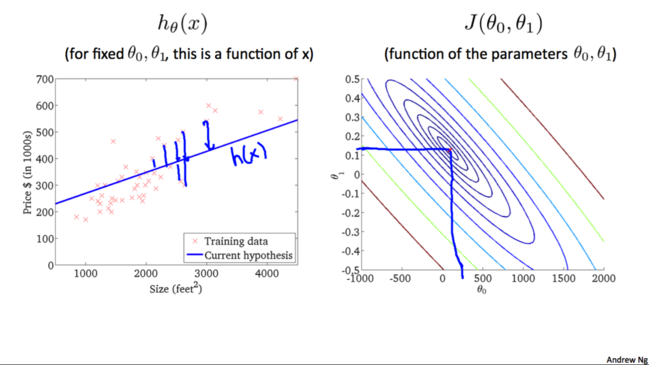
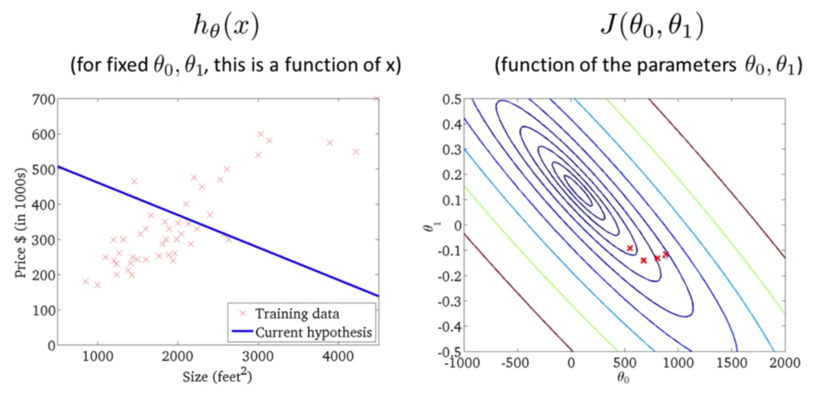
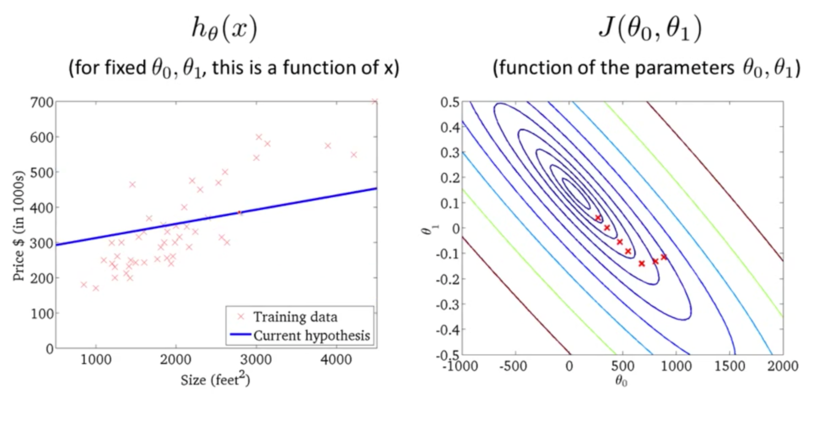
ЮвУЧВЛЖЯГЂЪджБЕНевЕНвЛИізюМбЕФ$h_\theta(x)$ЃЌЪЙЕУ$J(\theta_0,\theta_1)$зюаЁЁЃЕБШЛЮвУЧВЛПЩФмЫцЛњВТВтЛђепЪжЙЄГЂЪдВЛЭЌВЮЪ§ЕФжЕЁЃЮвУЧФмЯыЕНЕФгІИУОЭЪЧЭЈЙ§ЩшМЦГЬађЃЌевЕНзюМбЕФ$h_\theta(x)$ЃЌвВОЭЪЧзюКЯЪЪЕФ$\theta_0$КЭ$\theta_1$ЁЃ
ЬнЖШЯТНЕI
ЮвУЧЯШжБЙлЕФИаЪмвЛЯТЪВУДЪЧЬнЖШЯТНЕ(Gradient Descent)ЁЃЯывЊевЕНзюКЯЪЪЕФ$\theta_0$КЭ$\theta_1$ЃЌЮвУЧПЩвдЯШвдФГвЛ$\theta_0$КЭ$\theta_1$ПЊЪМЃЌШЛКѓВЛЖЯИФБф$\theta_0$КЭ$\theta_1$ЕФжЕЪЙЕУ$J(\theta_0,\theta_1)$жЕВЛЖЯМѕаЁЃЌжБЕНевЕНвЛИізюаЁжЕЁЃ

ШчЯТЭМЫљЪОЃЌДгФГвЛЕуПЊЪМЃЌУПДЮбизХвЛЖЈЕФЬнЖШЯТНЕжБЕНЕНДявЛИіМЋаЁжЕЮЊжЙЁЃ

ЕБДгВЛЭЌЕФЕуПЊЪМЪБ(МДВЛЭЌЕФ$\theta_0$КЭ$\theta_1$)ЃЌПЩФмЕНДяВЛЭЌЕФзюаЁжЕ(МЋаЁжЕ)ЃЌШчЯТЭМЃК
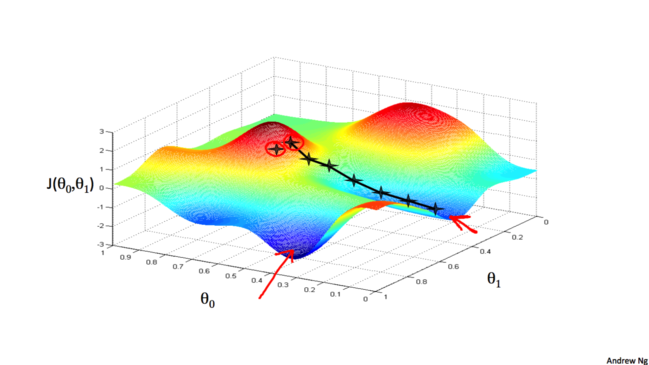
ЯждкЮвУЧДѓИХжЊЕРЪВУДЪЧЬнЖШЯТНЕСЫЃЌОЭКУБШЯТЩНвЛбљЃЌВЛЭЌЕФЩНТЗгаВЛЭЌЕФЦТЖШЃЌгаЕФЩНТЗзпЕУПьгаЕФзпЕУТ§ЁЃвЛжБЭљЕиДІзпгаПЩФмзпЕНВЛЭЌЕФзюЕЭЕуЁЃФЧУДЮвУЧУПДЮИУШчКЮгІИУШчКЮИФБф$\theta_0$КЭ$\theta_1$ЕФжЕФиЃПШчЯТЭМЫљЪОЃЌетРяЬсЕНСЫЬнЖШЯТНЕЫуЗЈ(Gradient
Descent Algorithm)ЃЌЦфжа$:=$БэЪОИГжЕЃЌ$\alpha$НазібЇЯАТЪЃЌ$\frac{\partial
}{\partial\theta_j}J(\theta_0, \theta_1)$НазіЬнЖШЁЃетРявЛЖЈвЊзЂвтЕФЪЧЃЌЫуЗЈУПДЮЪЧЭЌЪБ(simultaneous)ИФБф$\theta_0$КЭ$\theta_1$ЕФжЕЃЌШчЭМЯТЭМЫљЪОЁЃ

ЬнЖШЯТНЕII
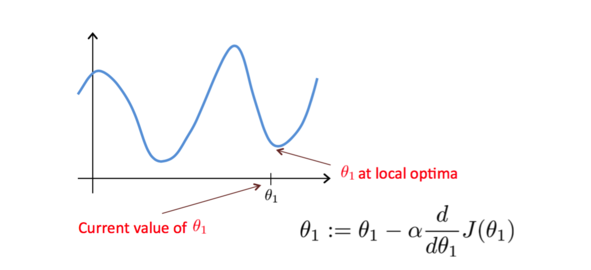
ЯжСю$\theta_0$ЕШгк0ЃЌМйЩшвЛПЊЪМбЁШЁЕФ$\theta_1$дкзюЕЭЕуЕФгвВрЃЌДЫЪБЕФЬнЖШЪЧвЛИіе§Ъ§ЁЃИљОнЩЯУцЕФЫуЗЈИќаТ$\theta_1$ЕФЪБКђЃЌЫќЕФжЕЛсМѕаЁЃЌМДППНќзюЕЭЕуЁЃ
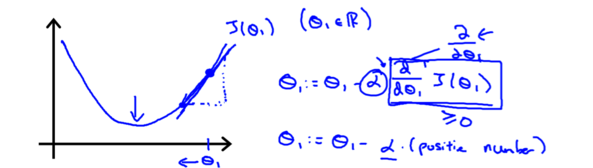
РрЫЦЕиМйЩшвЛПЊЪМбЁШЁЕФ$\theta_1$дкзюЕЭЕуЕФзѓВрЃЌДЫЪБЕФЬнЖШЪЧвЛИіИКЪ§ЃЌИљОнЩЯУцЕФЫуЗЈИќаТ$\theta_1$ЕФЪБКђЃЌЫќЕФжЕЛсдіДѓЃЌвВЛсППНќзюЕЭЕуЁЃ
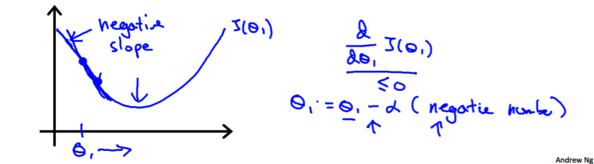
ШчЙћвЛПЊЪМбЁШЁЕФ$\theta_1$ЧЁКУдкзюЪЪЮЛжУЃЌФЧУДИќаТ$\theta_1$ЪБЃЌЫќЕФжЕВЛЛсЗЂЩњБфЛЏЁЃ
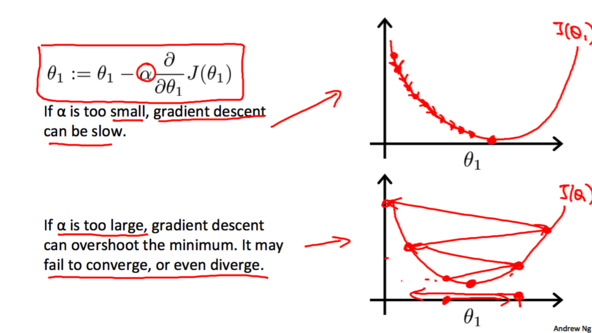
бЇЯАТЪ$\alpha$ЛсгАЯьЬнЖШЯТНЕЕФГЬЖШЁЃШчЙћ$\alpha$ЬЋаЁЃЌИљОнЫуЗЈЃЌ$\theta$ЕФжЕУПДЮЛсБфЛЏЕФКмаЁЃЌФЧУДЬнЖШЯТНЕОЭЛсЗЧГЃТ§ЃЛЯрЗДЕиЃЌШчЙћ$\alpha$Й§ДѓЃЌ$\theta$ЕФжЕУПДЮЛсБфЛЏЛсКмДѓЃЌгаПЩФмжБНгдНЙ§зюЕЭЕуЃЌПЩФмЕМжТгРдЖУЛЗЈЕНДязюЕЭЕуЁЃ
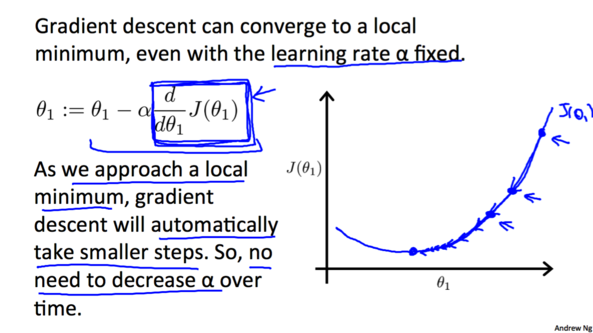
ЫцзХдНРДдННгНќзюЕЭЕуаБТЪ(ОјЖджЕ)Лсж№НЅМѕаЁЃЌУПДЮЯТНЕГЬЖШОЭЛсдНРДдНаЁЁЃЫљвдВЂВЛашвЊМѕаЁ$\alpha$ЕФжЕРДМѕаЁЯТНЕГЬЖШЁЃ
ЬнЖШЯТНЕIII
ЯждкЮвУЧЫљвЊзіЕФОЭЪЧНЋЬнЖШЯТНЕЫуЗЈгІгУЕНЯпадЛиЙщФЃаЭжаШЅЃЌЖјЦфжазюЙиМќЕФОЭЪЧМЦЫуЦфжаЕФЦЋЕМЪ§ЯюЃЌШчЯТЭМЫљЪОЁЃ

ЮвУЧНЋ$h_\theta(x^{(i)})=\theta_0+\theta_1x^{(i)}$ДјШыЕН$J(\theta_0,\theta_1)$жаЃЌВЂЧвЗжБ№Жд$\theta_0$КЭ$\theta_1$ЧѓЕМЕУ:
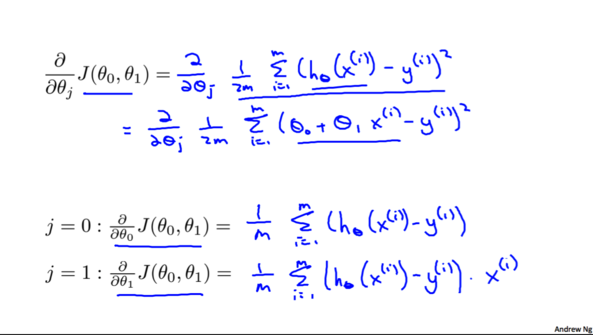
гЩДЫПЩЕУЕНЮвУЧЕФЕквЛИіЛњЦїбЇЯАЫуЗЈЃЌЬнЖШЯТНЕЫуЗЈ:

дкЮвУЧжЎЧАНВЕНЬнЖШЯТНЕЕФЪБКђЃЌЮвУЧгУЕНЕФЪЧетИіЭМЃК
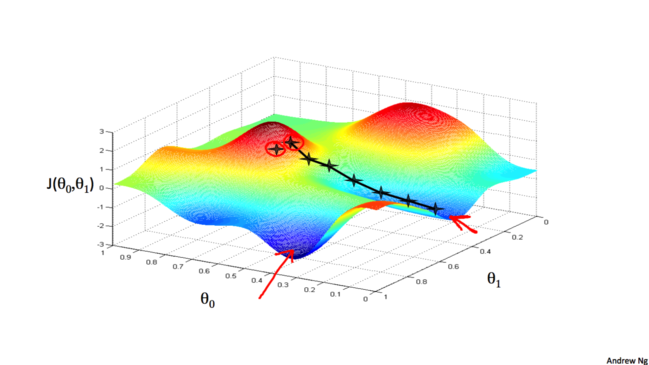
Ц№ЪМЕуВЛЭЌЃЌЛсЕУЕНВЛЭЌЕФОжВПзюгХНтЁЃЕЋЪТЪЕЩЯЃЌгУгкЯпадЛиЙщЕФДњМлКЏЪ§змЪЧвЛИіЭЙКЏЪ§(Convex
Function)ЁЃетбљЕФКЏЪ§УЛгаОжВПзюгХНтЃЌжЛгавЛИіШЋОжзюгХНтЁЃЫљвдЮвУЧдкЪЙгУЬнЖШЯТНЕЕФЪБКђЃЌзмЛсЕУЕНвЛИіШЋОжзюгХНтЁЃ
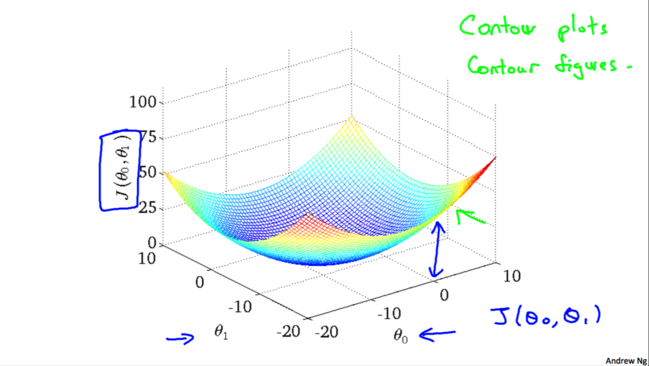
ЯТУцЮвУЧРДПДвЛЯТЬнЖШЯТНЕЕФдЫааЙ§ГЬЃК

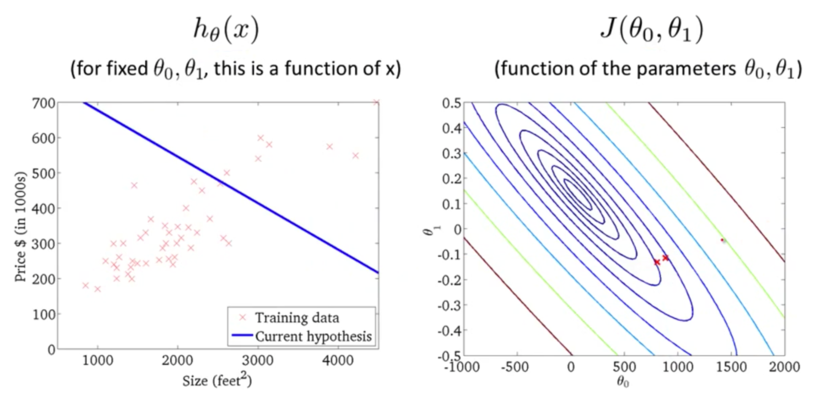
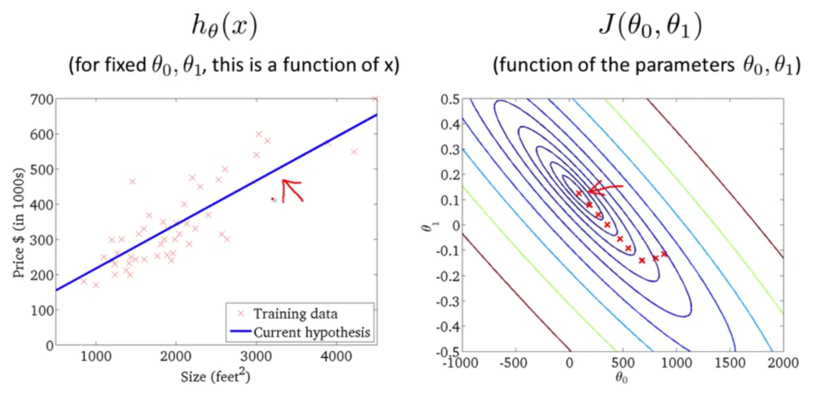
ЕќДњЖрДЮКѓЃЌЮвУЧЕУЕНСЫзюгХНтЁЃЯждкЮвУЧПЩвдгУзюгХНтЖдгІЕФМйЩшКЏЪ§РДЖдЗПМлНјаадЄВтСЫЁЃР§ШчвЛИі1,250ЦНЗНгЂГпЕФЗПзгДѓИХФмТєЕН250k$ЃЌШчЯТЭМЫљЪОЃК
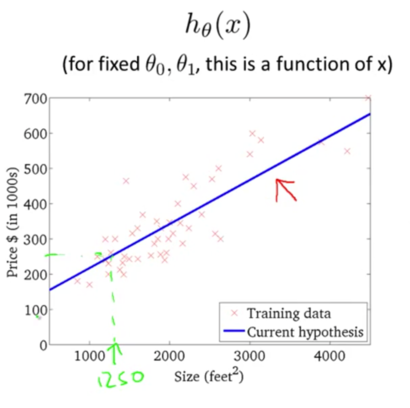
зюКѓЮвУЧдкНщЩмМИИіЯрЙиЕФИХФюЁЃИеВХЮвУЧгУЕНЕФЬнЖШЯТНЕвВНазїХњЬнЖШЯТНЕ(Batch Gradient
Descent)ЁЃетРяЕФЁЎХњЁЏЕФвтЫМЪЧЫЕЃЌЮвУЧУПДЮИќаТ$\theta$ЕФЪБКђЃЌЖМЪЧгУСЫЫљгаЕФбЕСЗбљР§(training
example)ЁЃЕБШЛвВгавЛаЉЦфЫћЕФЬнЖШЯТНЕЃЌдкКѓУцЕФПЮГЬжаЛсНщЩмЕНЁЃ

дкКѓУцЕФПЮГЬжаЮвУЧЛЙЛсбЇЯАЕНСэвЛжжВЛашвЊЯёЬнЖШЯТНЕвЛбљЖрДЮЕќДњвВФмЧѓГізюгХНтЕФЗНЗЈЃЌФЧОЭЪЧе§ЙцЗНГЬ(Normal
Equation)ЁЃЕЋЪЧдкЪ§ОнСПКмДѓЕФЧщПіЯТЃЌЬнЖШЯТНЕБШНЯЪЪгУЁЃ
|









