| БрМЭЦМі: |
| БОЮФРДздгкdaniellaah.github.ioЃЌЮФжаУшЪіСЫЛњЦїбЇЯАСІЕФМрЖНбЇЯАКЭЮоМрЖНбЇЕФЕФЗжРрЁЂвдМАЭЈЙ§АИР§ЕФНВЪіЁЃ |
|
МрЖНбЇЯА(Supervised Learning)
дкМрЖНбЇЯАжаЃЌИјЖЈвЛзщЪ§ОнЃЌЮвУЧжЊЕРе§ШЗЕФЪфГіНсЙћгІИУЪЧЪВУДбљзгЃЌВЂЧвжЊЕРдкЪфШыКЭЪфГіжЎМфгазХвЛИіЬиЖЈЕФЙиЯЕЁЃетУДЫЕПЩФмРэНтЦ№РДВЛЪЧКмЧхЮњЃЌУЛЙиЯЕЃЌКѓУцгаОпЬхЕФР§згЁЃ
МрЖНбЇЯАЕФЗжРр
МрЖНбЇЯАПЩЗжЮЊЁАЛиЙщЁБКЭЁАЗжРрЁБЮЪЬтЁЃМрЖНбЇЯАЗжРр

дкЛиЙщЮЪЬтжаЃЌЮвУЧЛсдЄВтвЛИіСЌајжЕЁЃвВОЭЪЧЫЕЮвУЧЪдЭМНЋЪфШыБфСПКЭЪфГігУвЛИіСЌајКЏЪ§ЖдгІЦ№РДЃЛЖјдкЗжРрЮЪЬтжаЃЌЮвУЧЛсдЄВтвЛИіРыЩЂжЕЃЌЮвУЧЪдЭМНЋЪфШыБфСПгыРыЩЂЕФРрБ№ЖдгІЦ№РДЁЃ
ЯТУцОйСНИіР§згЃЌОЭЛсЗЧГЃЧхГўетМИИіИХФюСЫЁЃ
МрЖНбЇЯАОйР§
ЛиЙщ
ЭЈЙ§ЗПЕиВњЪаГЁЕФЪ§ОнЃЌдЄВтвЛИіИјЖЈУцЛ§ЕФЗПЮнЕФМлИёОЭЪЧвЛИіЛиЙщЮЪЬтЁЃетРяЮвУЧПЩвдАбМлИёПДГЩЪЧУцЛ§ЕФКЏЪ§ЃЌЫќЪЧвЛИіСЌајЕФЪфГіжЕЁЃ
ЕЋЪЧЃЌЕБАбЩЯУцЕФЮЪЬтИФЮЊЁАдЄВтвЛИіИјЖЈУцЛ§ЕФЗПЮнЕФМлИёЪЧЗёБШвЛИіЬиЖЈЕФМлИёИпЛђепЕЭЁБЕФЪБКђЃЌетОЭБфГЩСЫвЛИіЗжРрЮЪЬт,
вђЮЊДЫЪБЕФЪфГіЪЧЁЎИпЁЏЛђепЁЎЕЭЁЏСНИіРыЩЂЕФжЕЁЃ
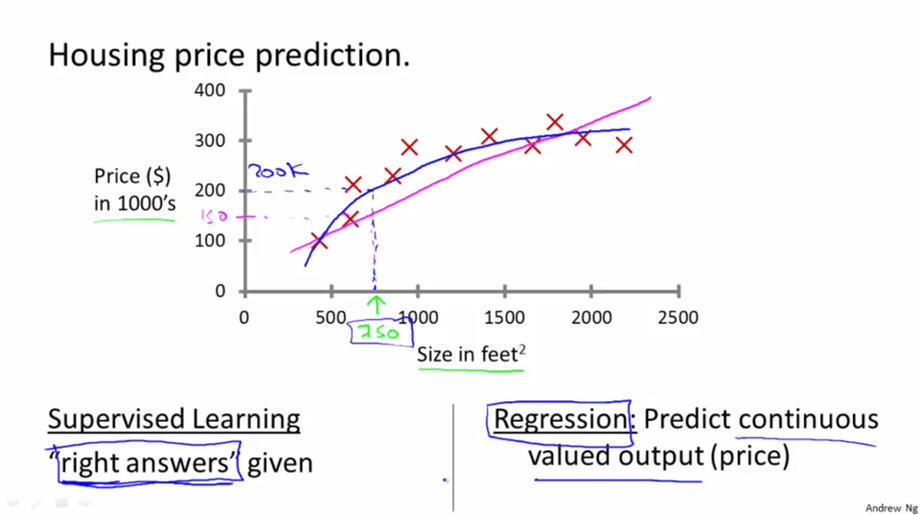
ЗжРр
ИјЖЈвНбЇЪ§ОнЃЌЭЈЙ§жзСіЕФДѓаЁРДдЄВтИУжзСіЪЧЖёадСіЛЙЪЧСМадСі(ПЮГЬжаИјЕФЪЧШщЯйАЉЕФР§зг)ЃЌетОЭЪЧвЛИіЗжРрЮЪЬтЃЌЫќЕФЪфГіЪЧ0Лђеп1СНИіРыЩЂЕФжЕЁЃ(0ДњБэСМадЃЌ1ДњБэЖёад)ЁЃ
ЗжРрЮЪЬтЕФЪфГіПЩвдЖргкСНИіЃЌБШШчдкИУР§згжаПЩвдга{0,1,2,3}ЫФжжЪфГіЃЌЗжБ№ЖдгІ{СМад, ЕквЛРржзСі,
ЕкЖўРржзСі, ЕкШ§РржзСі}ЁЃ
ЯТЭМжаЩЯЯТСНИіЭМжЛЪЧСНжжЛЗЈЁЃЕквЛИіЪЧгаСНИіжсЃЌYжсБэЪОЪЧЗёЪЧЖёадСіЃЌXжсБэЪОСіЕФДѓаЁ;
ЕкЖўИіЪЧжЛгУвЛИіжсЃЌЕЋЪЧгУСЫВЛЭЌЕФБъМЧЃЌгУOБэЪОСМадСіЃЌXБэЪОЖёадСіЁЃ

дкетИіР§згжаЬиеїжЛгавЛИіЃЌФЧОЭЪЧСіЕФДѓаЁЁЃ гаЪБКђвВгаСНИіЛђепЖрИіЬиеї, Р§ШчЯТЭМЃЌ гаЁАФъСфЁБКЭЁАжзСіДѓаЁЁБСНИіЬиеїЁЃ(ЛЙПЩвдгаЦфЫћаэЖрЬиеїЃЌШчЯТЭМгвВрЫљЪО)
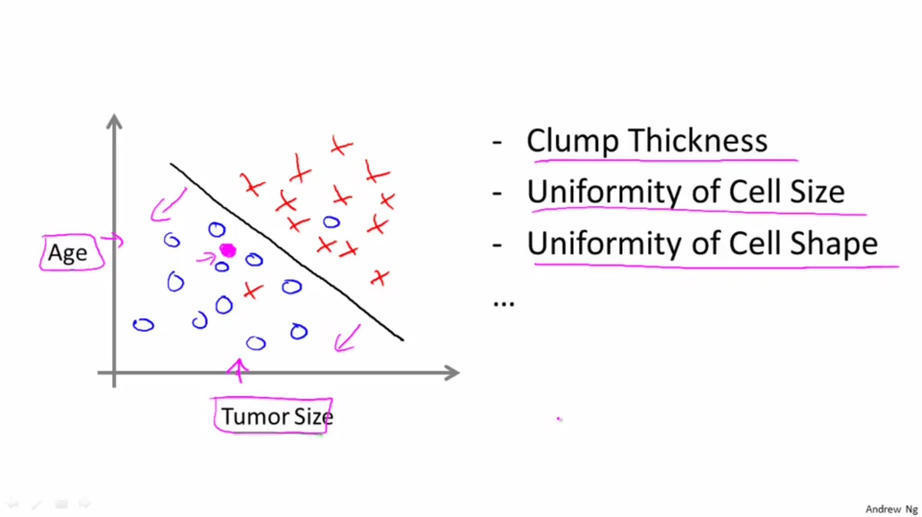
ЮоМрЖНбЇЯА
дкЮоМрЖНбЇЯАжаЃЌЮвУЧЛљБОЩЯВЛжЊЕРНсЙћЛсЪЧЪВУДбљзгЃЌЕЋЮвУЧПЩвдЭЈЙ§ОлРрЕФЗНЪНДгЪ§ОнжаЬсШЁвЛИіЬиЪтЕФНсЙЙЁЃдкЮоМрЖНбЇЯАжаИјЖЈЕФЪ§ОнЪЧКЭМрЖНбЇЯАжаИјЖЈЕФЪ§ОнЪЧВЛвЛбљЕФЁЃдкЮоМрЖНбЇЯАжаИјЖЈЕФЪ§ОнУЛгаШЮКЮБъЧЉЛђепЫЕжЛгаЭЌвЛжжБъЧЉЁЃШчЯТЭМЫљЪОЃК
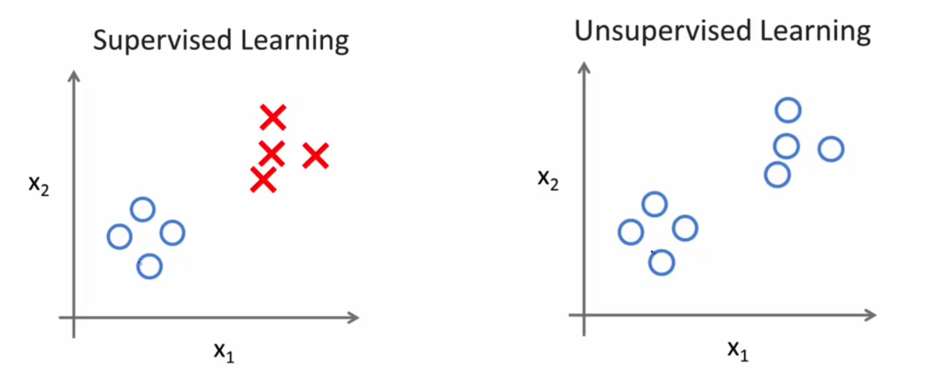
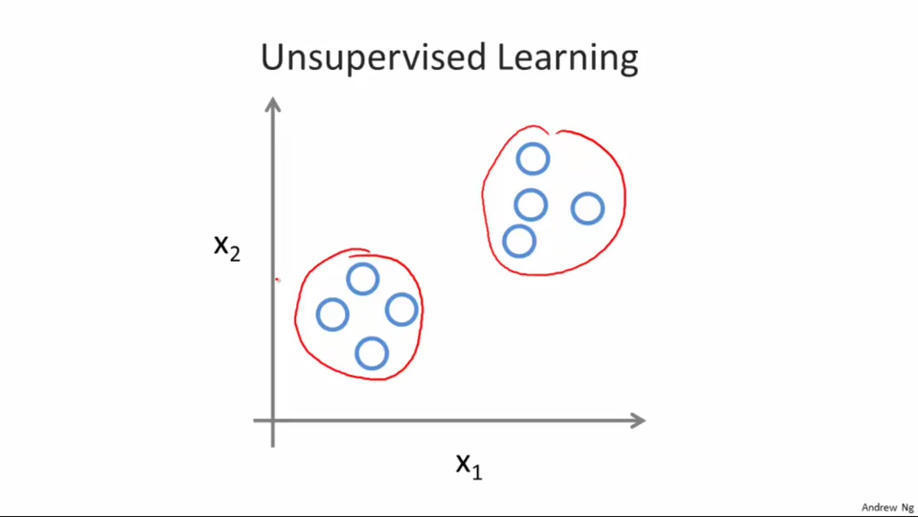
ШчЯТЭМЫљЪОЃЌдкЮоМрЖНбЇЯАжаЃЌЮвУЧжЛЪЧИјЖЈСЫвЛзщЪ§ОнЃЌЮвУЧЕФФПБъЪЧЗЂЯжетзщЪ§ОнжаЕФЬиЪтНсЙЙЁЃР§ШчЮвУЧЪЙгУЮоМрЖНбЇЯАЫуЗЈЛсНЋетзщЪ§ОнЗжГЩСНИіВЛЭЌЕФДи,ЃЌетбљЕФЫуЗЈОЭНаОлРрЫуЗЈЁЃ
ЮоМрЖНбЇЯАОйР§
аТЮХЗжРр
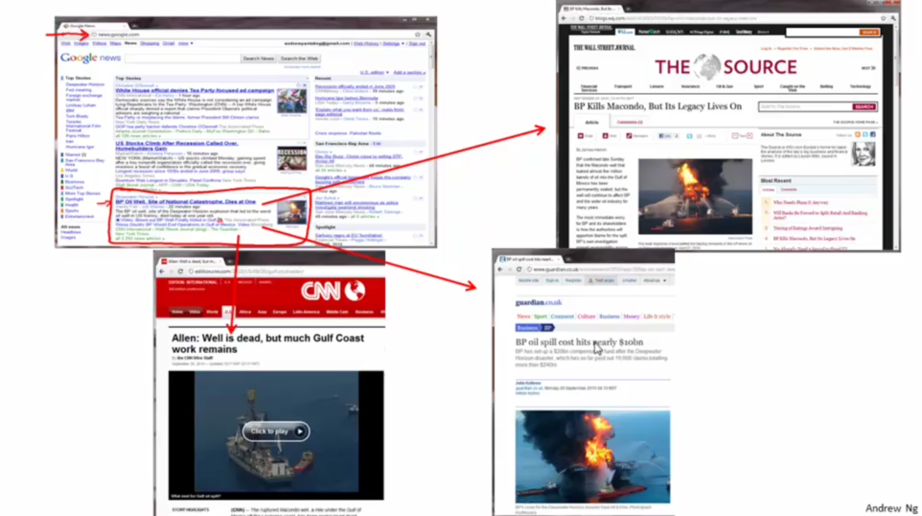
ЕквЛИіР§згОйЕФЪЧGoogle NewsЕФР§згЁЃGoogle NewsЫбМЏЭјЩЯЕФаТЮХЃЌВЂЧвИљОнаТЮХЕФжїЬтНЋаТЮХЗжГЩаэЖрДи,
ШЛКѓНЋдкЭЌвЛИіДиЕФаТЮХЗХдквЛЦ№ЁЃШчЭМжаКьШІВПЗжЖМЪЧЙигкBP Oil WellИїжжаТЮХЕФСДНгЃЌЕБДђПЊИїИіаТЮХСДНгЕФЪБКђЃЌеЙЯжЕФЖМЪЧЙигкBP
Oil WellЕФаТЮХЁЃ
ИљОнИјЖЈЛљвђНЋШЫШКЗжРр
ШчЭМЪЧDNAЪ§ОнЃЌЖдгквЛзщВЛЭЌЕФШЫЮвУЧВтСПЫћУЧDNAжаЖдгквЛИіЬиЖЈЛљвђЕФБэДяГЬЖШЁЃШЛКѓИљОнВтСПНсЙћПЩвдгУОлРрЫуЗЈНЋЫћУЧЗжГЩВЛЭЌЕФРраЭЁЃетОЭЪЧвЛжжЮоМрЖНбЇЯА,
вђЮЊЮвУЧжЛЪЧИјЖЈСЫвЛаЉЪ§ОнЃЌЖјВЂВЛжЊЕРФФаЉЪЧЕквЛжжРраЭЕФШЫЃЌФФаЉЪЧЕкЖўжжРраЭЕФШЫЕШЕШЁЃ

МІЮВОЦХЩЖдаЇгІ
ЯъМћПЮГЬ: Unsupervised Learning
ЦфЫћ
етРягжОйСЫЦфЫћМИИіР§згЃЌгазщжЏМЦЫуЛњМЏШКЃЌЩчНЛЭјТчЗжЮіЃЌЪаГЁЛЎЗжЃЌЬьЮФЪ§ОнЗжЮіЕШЁЃОпЬхПЩвдПДвЛЯТЪгЦЕЃКUnsupervised
Learning
|









