| БрМЭЦМі: |
| БОЮФРДздгкжЊКѕЃЌНщЩмСЫ
Simulink КЭ StateflowЕФНЧЩЋЃЌ ФЃаЭНсЙЙЗжВуЃЌAUTOSAR
ИХФюЃЌЕЅШЮЮёКЭЖрШЮЮёЕШЁЃ |
|
1. Simulink КЭ StateflowЕФНЧЩЋ
ЫљгаЕФЯЕЭГЖМПЩвдЪЙгУSimulinkЛђStateflowНјааНЈФЃЁЃ
ШчЙћЪЙгУStateflowНјааНЈФЃЃЌSimulinkНіНізїЮЊаХКХЕФЪфШыЪфГіКЭЗТецЃЌдкStateflowжаПЩвдЪЙгУЖржжЙЋЪНКЭЗНЗЈРДЬцДњsimulinkНјааДІРэЁЃШчЙћжЛгУSimulinkЃЌПЩвдЭЈЙ§ЪЙгУSwitch-CaseПщЕФЗНЗЈРДЬцДњStateflowЪЕЯжИДдгЕФзДЬЌБфСПЁЃ
вђДЫЃЌЪЙгУSimulinkЛђStateflowЖдгкЬиЖЈВПЗжЕФНЈФЃЃЌЪЧжїЙлвРОнПЊЗЂШЫдБЖдгкФФжжБэДяЗНЗЈИќЮЊРэНтЁЃгІИУИљОнећЬхЕФЭХЖгЫЎЦНРДЪЕЯжШчЩЯбЁдёКЭНЈФЃЁЃ
дкДѓЖрЪ§ЧщПіЯТЃЌStateflowЕФRAMаЇТЪвЊБШSimulinkВюЁЃвђДЫЃЌSimulinkдкЪЙгУМђЕЅЙЋЪНЕФМЦЫужаОпгагХЪЦЁЃГ§ДЫжЎЭтЃЌSimulinkдкЪЙгУМђЕЅЕФДЅЗЂКЭЧаЛЛЯЕЭГжаЃЌЖдгкзДЬЌБфСПЕФЪЙгУвВИќОпгагХЪЦЁЃЕБЪЙгУStateflowЫљНЈЕФФЃаЭПЩвдгУSimulinkНјааЬцДњНЈФЃЪБЃЌашвЊПМТЧШчЯТвђЫиНјЖјзіГіОіЖЈЃК
ШЗБЃОВЬЌRAMзуЙЛДѓЃЌвдБЃжЄStateflow ЕФЪфШыЪфГівдМАФкВПБфСПЕФе§ШЗдЫааЁЃЕБЪЙгУФкВПЭЈгУМЦЫуЙЋЪНЪБЃЌвЊЩшМЦЗРвчГіЕФБЃЛЄЁЃЕБЭтВПМЦЫуЭъГЩЪБЃЌашвЊЖдећЬхНјааЗжПщЃЌвдНЕЕЭетИіФЃПщЕФРэНтФбЖШЁЃ
дквЛаЉЧщПіЯТЃЌStateflowФмЙЛБШSimulinkНјааИќНгНќгкCгябдЕФБэДяЗНЗЈЃЌЕЋЪЧетбљЕФФЃаЭУЛгаКмКУЕФЭтЙлзДЬЌЃЌВЂВЛЪЧКмШнвзРэНтЁЃдкетаЉЧщПіЯТЃЌЪЙгУS-FunctionЛсИќгаРћЁЃ
Stateflow ПЩвдМЦЫуЬиЖЈЕФзДЬЌАВХХЃЌЛђНјааfor-loopЕФМЦЫуЃЌдкетаЉВуУцЩЯвЊБШSimulinkИќгааЇТЪЃЌЕЋЪЧНќаЉФъРДЃЌЪЙгУMatlabгябдНјааШчЩЯМЦЫуЃЌвВБфЕУИќгааЇТЪвЛаЉЁЃ
ЕБЪЙгУSimulinkНјааНЈФЃЪБЃЌШчЙћДІРэШчЯТЫљЪіЕФзДЬЌЃЌдђПЩЭЈЙ§ЪЙгУStateflowРДИФЩЦПЩЖСадЁЃ
1.ЭЌвЛИіЪфШыгаВЛЭЌЕФЪфГіжЕ
2.ЖрИізДЬЌДцдк (Р§Шч3ИіМАИќЖр)
3.ЖдгкЖЈвхЕФвЛИізДЬЌЕФвтвхЃЌВЛЪЧЮоЯоЕФжЕЖјЪЧвЛИіРыЩЂЕФЪ§жЕЁЃ
4.дкзДЬЌФкВПЃЌвЊЧѓГѕЪМЛЏЃЈЪзДЮжДааЃЉКЭКѓУцЕФ жДаазДЬЌЦкМфгаЫљВЛЭЌЁЃ
5.Г§СЫзДЬЌБфСПЃЌЪфШыКЭЪфГіБфСПЪЧПЩвдБЛПЩЪгЛЏЕФаХКХ.
ОйИіР§згЃЌдкДЅЗЂЦїЕчТЗжаЃЌВЛЭЌЕФЪфГіЖдгІгкЭЌвЛИіЪфШыЁЃЖјЧвЃЌзДЬЌБфСПЕФжЕБЛЯоЖЈдк0КЭ1ЁЃ
ШЛЖјЃЌдкЪфШыЪфГіЖМЮЊ0Лђ1ЕФЧщПіЯТЃЌШдПЩвдгаЮоЯоЖрЕФзДЬЌЗжРрЁЃДЫЭтЃЌдкзДЬЌНјШыКЭжДааСНИіЖЏзїМфУЛгаЧјБ№ЁЃЛЛОфЛАЫЕЃЌЩЯЫпМИЬѕжаНіНіЗћКЯЕквЛЬѕЃЌЫљвдетЪБКђгІИУЪЙгУSimulinkНјааНЈФЃЁЃ
ЙигкВЩгУSimulinkЛЙЪЧStateflowНјааНЈФЃПЩвдКЭМИИіШЫНјааЙЕЭЈаЩЬЃЌВЂзюжеШЁОігкашвЊНтОіЕФЪЕМЪЮЪЬтЁЃ
StateflowжаЪЧВЩгУзДЬЌзЊЛЛЛЙЪЧ СїГЬЭМКЏЪ§вВашвЊНјааПМТЧКЭОіЖЈЃЌР§ШчашвЊ ЖЈЖс ЪЙгУ зДЬЌЕФзЊЛЛКЭЬѕМўЗжжЇРД
ЬцДњ ЪЙгУзДЬЌЕФСїГЬЭМКЏЪ§ЁЃецжЕБэвВБЛЗжРрЮЊЪЙгУЬѕМўЗжжЇЕБжаЕФЗНЗЈЁЃ
ДЫЭтЃЌЕБЪЙгУStateflowНјааШчЩЯЩшМЦЪБЃЌашвЊвРОнОЕфЕФФЃаЭбљЪННјааЩшМЦЃЌвдБугкФмЙЛИќКУЕФЩњГЩЧЖШыЪНДњТыЁЃ
StateflowжЇГжЩњГЩHDLДњТыЁЃдкЪЕЯжHDLБрТыЦїЪБЃЌгІЪЙгУMealyКЭMooreФЃЪНЁЃДЫЭтЃЌЕБашвЊЖдФкВПаЙТЉНјааБЃЛЄЪБЃЌ
Moore ФЃЪНИќЪЪКЯЁЃ
ашвЊзЂвтЃЌБОжИФЯВЛЪЧеыЖдHDLДњТыЩњГЩЁЃ
2. ФЃаЭНсЙЙЗжВу
ШчЯТЪОР§СЫФЃаЭЗжВужаЗжИюКЭВМОжЕФЙлФюЃЌПЩзїЮЊПЊЗЂжаЕФВЮПМЁЃетВЂВЛЪЧвЛИіУїШЗЕФЙцдђЃЌЕЋетЪЧвЛИіНЈФЃЕФЛљДЁЗНЗЈЁЃ
2.1 ВуЕФРраЭ
ДюНЈВуЕФЗНЗЈ
ШчЙћжївЊФПЕФЮЊЕїећвЛВуЕФПеМфХХВМЃЌдђгІОЁСПБмУтДђАќЕНзгЯЕЭГШчЯТЮЊВуДЮЕФИХФюЃЌзгЯЕЭГашвЊвРОнДЫУшЪіНјааЗжВуВЛвЊЪЙгУЖргрЕФВувЛВуФЃаЭжаЃЌдЪаэИДКЯВуЕФНЈФЃИХФю
ВуИХФю
УћГЦ |ВуИХФю | ВуФПЕФ
-------|-----------|------------
ЖЅВу |ЙІФмВу |ДѓПщЙІФмВПЗж
|ЕїЖШВу |жДааЪБМфЕФБэДяЃЈВЩбљЁЂЫГађЃЉ
ЕзВу |згЙІФмВу |ЙІФмЕФЯИНкБэДяВПЗж
|ПижЦСїВу |ИљОнДІРэКЭжДааЫГађЛЎЗжЃЈinput Ёњ judgment Ёњ output,ЕШЃЉ
|бЁдёВу | (select output with Merge block) ЧаЛЛЯргІБЛМЄЛюЕФзгЯЕЭГВЂЧвжДаа
|Ъ§ОнСїВу |гУгкВЛПЩЗжРыМЦЫуЕФВу
2.2 ЖЅВуЛЎЗжЗНЗЈ
ЖдгкЖЅВуЛЎЗжЃЌжївЊгаШчЯТШ§ИіЗНЗЈ
МђЕЅПижЦФЃаЭ
БэЯжЮЊЙІФмВуКЭЕїЖШВудкЭЌвЛВужаЃЌдкетбљЕФФЃаЭРяЃЌЙІФм = жДааЕЅдЊЁЃ
Р§згЃК ПижЦФЃаЭжЛгавЛИіВЩбљжмЦкЃЌВЂЧвИїЙІФмФЃПщЖМАДеежДааЫГађНјааХХСаЁЃ
ИДдгПижЦФЃаЭ ІС
ЕїЖШВуЗХдкзюЖЅВу
етбљЛсЪЙЪжаДДњТыИќШнвзМЏГЩЃЌЕЋЪЧЙІФмФЃПщБЛЗжИюЃЌЕМжТФЃаЭПЩЖСадНЕЕЭЁЃ
ИДдгПижЦФЃаЭ ІТ
ЙІФмВуЗХдкзюЖЅВуЃЌВЂЧвЕїЖШВудкИїЙІФмФЃПщЯТНјааЙЙНЈЁЃ
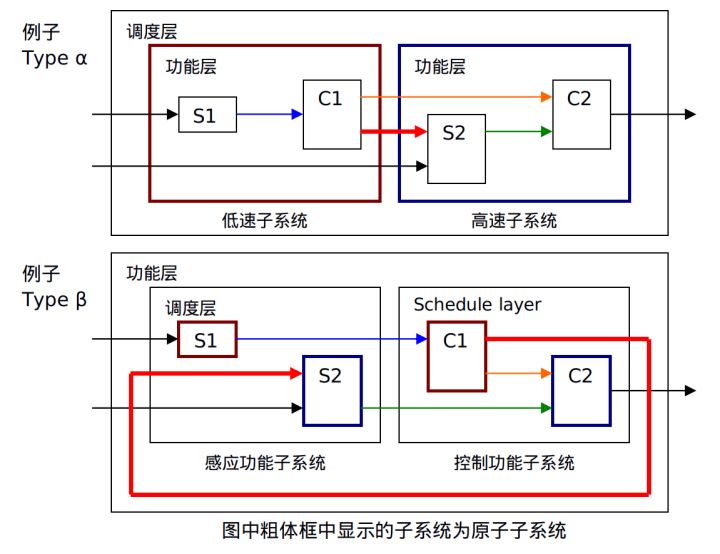
2.3 ЙІФмВуКЭзгЙІФмВуНЈФЃЗНЗЈ
ИљОнЙІФмЛЎЗжзгЯЕЭГЃЌУПИізгЯЕЭГДњБэЁАвЛИіЖРСЂЙІФмЁБЖдгкжДааЕЅдЊЃЌЁАвЛИіЖРСЂЙІФмЁБЕФзгЯЕЭГЪЧВЛБивЊЕФЁЃвђДЫЃЌИїзгЯЕЭГВЛвЛЖЈШЋЖМЩшЮЊдзгзгЯЕЭГЁЃ
(ЖдгкШчЩЯСаГіЕФ type ІТ, НЋЙІФмВузгЯЕЭГЩшЮЊащФтзгЯЕЭГИќКЯЪЪвЛаЉЁЃШчЙћНЋЫћУЧЩшЮЊдзгзгЯЕЭГЃЌдђПЩФмЛсГіЯжДњЪ§ЛЗЁЃ)ЪЙгУзЂЪЭЃЌЙІФмИХЪіБиаыдкЭМВуЩЯУшЪіЛђАќКЌдкзгЯЕЭГИХЪіжаЃЌВЂЯдЪОЮЊзЂЪЭЁЃШчЙћФЃаЭРягаМИИіДѓЕФЙІФмФЃПщЃЌдђашвЊПМТЧЪЙгУФЃаЭв§гУЁЃ
2.4 ЕїЖШВуНЈФЃЗНЗЈ
ашвЊЩшжУжмЦкМфИєКЭгХЯШМЖМАЫГађЁЃ
ЩшжУЖрИіжмЦкМфИєашвЊзЂвт
дкВЛЭЌжмЦкЕФСЌНгЯЕЭГжаЃЌгаПЩФмЗЂЩњаХКХБфСПЛсдкПьжмЦкШЮЮёжаБЛЕїгУЃЌДЫЪБдкТ§жмЦкжаИУаХКХЛЙУЛгаБЛМЦЫуГіРДЁЃЕБВЛЭЌжмЦкНјааСЌНгЪБЃЌашвЊвЛПщЙЬЖЈЕФRAMЧјЁЃвђДЫЃЌашвЊдкЖЅВуЮЊУПИіВЛЭЌжмЦкЕФШЮЮёНјааНјааЪБМфЗжИюЃЌБЃжЄЕзВужаУЛгаВЛЭЌжмЦкЕФФЃПщНјааСЌНгЁЃ
ЩшжУгХЯШМЖ
дкЩшМЦЖрИіВЛЭЌЙІФмЕФЯЕЭГЪБЃЌгХЯШМЖЩшЖЈЪЎЗжживЊЁЃНЈвщОЁСПИљОнСЌНгЕФЫГађРДЪЙЯЕЭГздЖЏШЗЖЈдЫааЫГађЁЃ
ЖдгкЫГађгХЯШМЖЃЌШчЯТЯюашвЊНјааЩшЖЈЃКВЛЭЌжмЦкЕФгХЯШМЖЃЌКЭЭЌжмЦкЕФгХЯШМЖЁЃ
жмЦкМфИєКЭгХЯШМЖЕФЩшЖЈЗНЗЈЃК
ШчЯТУшЪіЕФЗНЗЈПЩДѓЬхЩЯЗжЮЊ2жжРраЭЁЃ
згЯЕЭГЛђФЃПщЕФжДаажмЦкЪБМфКЭгХЯШМЖЩшжУЁЃЪЙгУЬѕМўзгЯЕЭГЃЌгУЛЇЩшжУЖРСЂЕФХХСаЫГађРДЦЅХфШЮЮёЕїЖШЁЃ
МИИіЬѕМўЯТДцдкЕФФЃЪНЃЌР§ШчХфжУЕЅЫйТЪЛђЖрЫйТЪЃЌдзгзгЯЕЭГЩшжУЃЌЪЧЗёЪЙгУФЃаЭв§гУЕШЁЃетЦфжаЦєгУФФИіЙІФмЖМЛсжБНггАЯьЕНЩњГЩЕФCДњТыЃЌЫљвдашвЊИљОнЯюФПЕФВЛЭЌЧщПіНјаазлКЯПМСПЁЃ
ЪмгАЯьЕФЕфаЭвђЫиШчЯТЃК
ФЃаЭЗНУцЩЯЪЧЗёДцдкВЛЭЌЕФВЩбљЪБМфЃПФЃаЭЪЧЗёашвЊЪЕЯжМИИіЖРСЂЕФЙІФмЃПЪЙгУФЃаЭв§гУФЃаЭЪ§СП (SimulinkЪЧЗёЛсЩњГЩЖрИідДДњТы)дДДњТыЗНУцЩЯЪЧЗёЪЙгУЪЕЪБВйзїЯЕЭГЪЕМЪВЩбљжмЦкКЭРэТлМЦЫужмЦкЕФвЛжТадЪЪгУЗЖЮЇ
(гІгУВуЛђЛљДЁШэМў)дДДњТыРраЭЃКЪЧЗёЗћКЯ/жЇГж AUTOSAR .RAM, ROM ЬиБ№ЪЧRAMЪЃгрАйЗжБШ
НјааШчЩЯПМСПКѓЃЌНЋЛсЖдЪЙгУЕФбљЪННјааЕїећЁЃ
2.5 ПижЦВуНЈФЃЗНЗЈ
ПижЦВуЪЧгУгкБэЪОЫљгаЪфШыДІРэЁЂжаМфДІРэЁЂКЭЪфГіДІРэЕФВуЁЃФЃПщКЭзгЯЕЭГЕФХХСаЪЎЗжживЊЁЃНЋЖрИіЛьКЯЕФаЁЙІФмЗжзщЃЌзюКѓХХСаГЩ3ИіДѓзщЃЌАќРЈЃКЪфШыДІРэЃЌжаМфЙ§ГЬДІРэЃЌЪфГіДІРэЁЃетШ§ИіДѓзщЙЙГЩСЫПижЦВуЕФИХФюЛљДЁЁЃгыЪ§ОнСїВуЯрЫЦЕФХХСаЗНЗЈЪЧЃЌЖМЪЙгУЫЎЦНЯпДњБэФЃПщдЫааЫГађКЭЗНЯђЃЌгыЦфВЛЭЌЕФЪЧПижЦСїВуДѓЖрЪЧгЩИДКЯФЃПщКЭзгЯЕЭГЙЙГЩЕФЁЃ
дкПижЦСїГЬЃЌЭЌвЛЫЎЦНЯпЩЯЕФИљОнМ§ЭЗЫљжИЗНЯђНјааЫГађДІРэЃЌЭЌвЛДЙжБЗНЯђЕФДњБэгаЯрЭЌЕФгХЯШМЖЁЃ
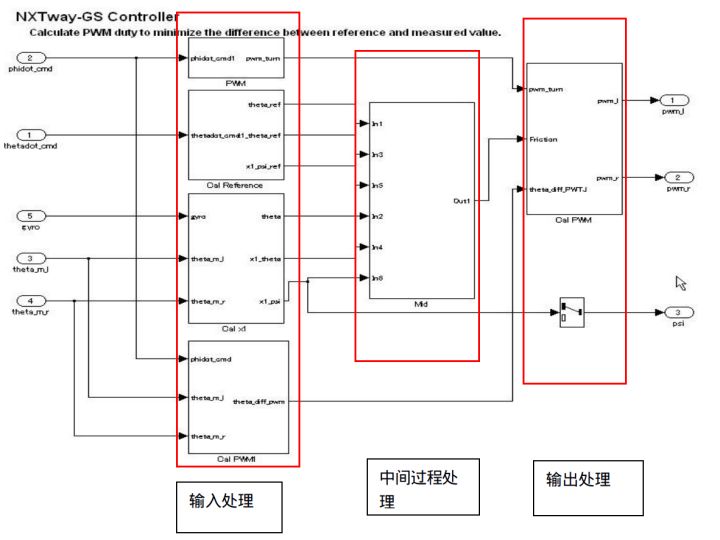
ПЩвдЪЙгУAreaЙЄОпНјааПђбЁВЂБъзЂМИИіФЃПщЕФВПЗж
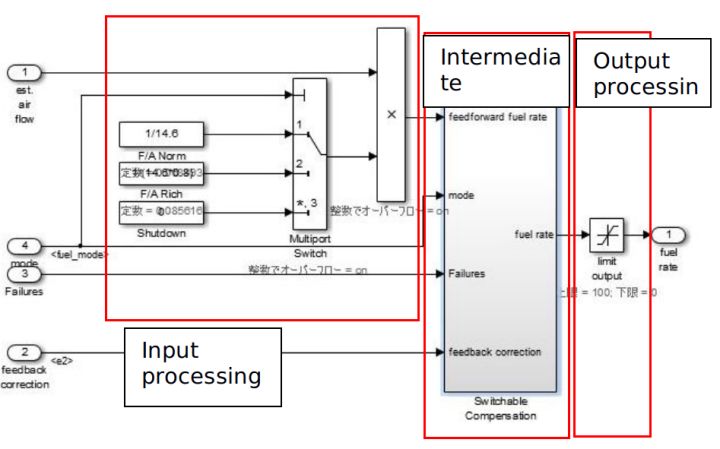
ПижЦВуПЩвдКЭОпгаЙІФмЕФФЃПщЙВДцЁЃ
етаЉФЃПщЗХжУдкзгЙІФмВуКЭЪ§ОнСїВужЎМфЕФЧјгђЁЃ
ЕБФЃПщЕФЪ§СПЬиБ№ЖрЃЌЧвЖМдкЪ§ОнСїВуНјааЪЙгУЃЌетЪБПЩвдЪЙгУЙІФмЕЅдЊДђАќЕФЗНЪННјааПижЦВуЕФећКЯЁЃетбљЛсЪЙФЃаЭИќШнвзРэНтЃЌЭЌЪБЬсИпСЫФЃаЭЕФПЩЮЌЛЄадЁЃ
МДЪЙНігЩФЃПщЙЙГЩЃЌВЛДцдкзгЯЕЭГКЭФЃПщЕФЛьКЯЬхЃЌШчЙћФЃаЭЕФЫЎЦНЗНЯђНсЙЙФмЙЛЛЎЗжГЩ ЪфШы/жаМфЙ§ГЬ/ЪфГі
ДІРэЃЌетбљвВПЩвдГЦзїЮЊПижЦВуЁЃ
2.6 бЁдёВуНЈФЃЗНЗЈ
бЁдёВуПЩвдДЙжБЛђЫЎЦНЗНЯђЙЙНЈЁЃ(There is no significance to which
orientation is chosen)
бЁдёВуЪЧКЭПижЦВуНјааЛьКЯЖјГЩЁЃ
ЯТЭМКьЩЋПђФкЃЌИљОнЬѕМўжЛгавЛИізгЯЕЭГФмЙЛдЫааЃЌЫљвдетБЛГЦзїЮЊбЁдёВуЁЃетВуФЃаЭЫфШЛФмЙЛБЛЛЎЗжГЩ initial
processing/intermediate processing (conditional control
flow)/output processingетШ§ИіДІРэФЃПщзщЃЌЕЋЪЧГЦЮЊПижЦВуВЂВЛЧЁЕБЃЌвђЮЊдкПижЦВуЃЌЫЎЦНЗНЯђДњБэВЛЭЌЕФДІРэЃЌВЂЧвОпгаЯрЭЌгХЯШМЖЕФВЂааДІРэдкДЙжБЗНЯђЩЯНјааХХСаЁЃЖјдкбЁдёВуЃЌДЙжБЗНЯђЩЯЕФВЂВЛвЛЖЈЪЧВЂааДІРэЃЌЖјЪЧУПДЮНібЁдёЦфжавЛИіНјаадЫааЁЃ
Р§згЃК
Switching of coupled functions between running upwards
or downwards, changing in chronological order.Switching
to setting where the computation switches after the
first time (immediately after reset) and second time.Switching
between destination A and destination B.
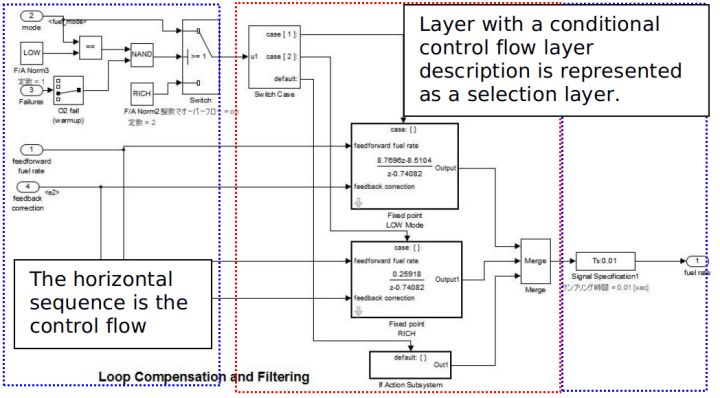
2.7 Ъ§ОнСїВуНЈФЃЗНЗЈ
Ъ§ОнСїВуЪЧдкбЁдёВу/ПижЦВужЎЯТЕФвЛВуЁЃ
ЕБНіБэЯжЮЊвЛИіЙІФмЃЌВЂзїЮЊЪфШы/жаМфЙ§ГЬ/ЪфГіДІРэЕФОпЬхЪЕЯжЃЌЧвВЛФмдйНјааЛЎЗжЃЌдђетбљЕФвЛВуБЛГЦзїЮЊЪ§ОнСїВуЁЃОйИіР§згЃЌвЛИіГжајМЦЫуВЛФмБЛЗжИюЕФЯЕЭГЁЃГ§вЛаЉЬиЪтЧщПіЯТЃЌЪ§ОнСїВуВЛдЪаэГіЯжзгЯЕЭГЁЃ
ЬиЪтЧщПіЃКШчЯТЧщПідЪаэдкЪ§ОнСїВуГіЯжзгЯЕЭГЁЃ
згЯЕЭГБЛЩшЮЊжигУзгЯЕЭГЁЃSimulink БъзМПтРяДцдкЕФзгЯЕЭГЁЃгУЛЇздЖЈвхПтжаДцдкЕФзгЯЕЭГЁЃ
МђЕЅЪ§ОнСїВу Р§зг
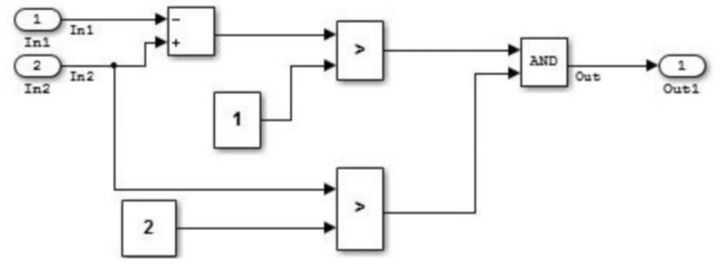
ИДдгЪ§ОнСїВу Р§зг
ЕБгіЕНЪфШыДІРэКЭжаМфЙ§ГЬДІРэВЛФмЙЛЧхЮњНјааЛЎЗжЕФЪБКђЃЌОЭШчЩЯУцЕФР§згЫљЪОЃЌеЙПЊЮЊЪ§ОнСїВуЁЃ
ЕБЭЌЪБМЦЫувЛИіаХКХЕФЧАЖЫЗДРЁКЭКѓЖЫЗДРЁЪБЃЌЪ§ОнСїВуЛсБфЕУИДдгЁЃЩѕжСДЫжжЧщПіЛсгаКмЖрФЃПщдкЭЌвЛВуЃЌ
ЕЋЪЧЮЊСЫЧхЮњЕФБэДяМЦЫуЃЌШдОЩВЛФмдкЪ§ОнСїВуНјаазгЯЕЭГЕФДДНЈЁЃЕБФмЙЛЭЈЙ§ЛЎЗжФЃаЭНјааећКЯЕФЪБКђЃЌгІИУБЛДђАќГЩПижЦВуЖјВЛЪЧЪ§ОнСїВуЁЃ
2.8 Simulink ФЃаЭКЭЧЖШыЪНЪЕЯжЕФЙиЯЕ
дкецЪЕЕФЧЖШыЪНЯЕЭГжадЫааЃЌашвЊSimulinkФЃаЭЩњГЩЧЖШыЪНCДњТыЁЃетгаКмДѓвЛВПЗжЪмЕНSimulinkХфжУЯюЕФгАЯьЃЌИљОнSimulinkеыЖдЯрЙиЙІФмНјааКЮжжГЬЖШЕФНЈФЃЃЌвдМАШчКЮЧЖШыКЭецЪЕЯЕЭГЕФЪБМфЩшЖЈЁЃ
ШчЙћЧЖШыЪНЯЕЭГРяЪЙгУЕФШЮЮёгыSimulinkФЃаЭРяЕїЖШЕФШЮЮёВЛЭЌЃЌетНЋВњЩњКмбЯжиЕФгАЯьЁЃ
3. AUTOSAR ИХФю
БОЮФжаЃЌВЂВЛЖдAUTOSARБъзМНјааНтЪЭЃЌЖјЛсЫЕУїAUTOSARЕФИХФюЁЃгУЛЇВЛБиЭъШЋЗћКЯAUTOSARБъзМЃЌЕЋБиаыСЫНтЫќЃЌВЂзїЮЊНЈФЃжаЕФВЮПМЁЃ
3.1 AUTOSAR ШэМўЦНЬЈИХФю
ЕБЩшМЦвЛИіПижЦФЃаЭЕФЪБКђЃЌБиаывЊзёбAUTOSAR ШэМўЦНЬЈЕФИХФюЃЌВЂвЊЩѓВщЫљЩшМЦЕФФЃаЭЪЧЙщРрЕНгІгУШэМўЛЙЪЧЛљДЁШэМўЁЃ
ШчЙћФЃаЭЛьКЯСЫгІгУКЭЛљДЁШэМўЃЌашвЊдкЩшМЦНзЖЮОЭНјааЛЎЗжЁЃ
AUTOSAR ШэМўЦНЬЈИХФю
ИпШнСПЃЌЕЭЫйЃЌГЃЙцЕФДІРэдкгІгУШэМўВуИпЫйЃЌЗЧГЃЙцЧ§ЖЏЕФДІРэдкЛљДЁШэМўВу
AUTOSARШэМўЦНЬЈШчЯТЭМЫљЪО
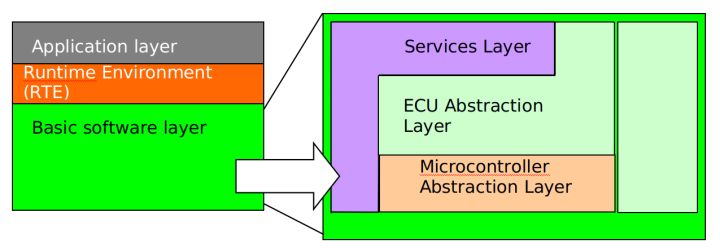
ОйИіР§згЃЌЩшМЦв§ЧцПижЦФЃаЭЕФЪБКђЃЌВЛНЈСЂвджаЖЯжДааШЮЮёЗНЪНЕФФЃаЭЃЌЖјЪЧдкгІгУШэМўВуМЦЫуЫљгаЦјИзЙВЯэЕФБфСПЁЃР§ШчЃЌМЦЫуЕБЧАХХЗХзДЬЌЛђФПБъСІОиЁЃЕБВЛЙцдђжаЖЯДгЛљДЁШэМўЧјЗЂЩњЃЌЭЈЙ§RTEДЋЕнЕНгІгУВуЪБЃЌМЦЫуНсЙћФмЙЛБЛЕїгУЃЌЪЕМЪЕФЧ§ЖЏЦївВФмЙЛБЛМЄЛюЁЃAUTOSTARЕФИХФюЪЙЕУЛљДЁШэМўЧјЕФЭЈгУМЦЫуФмЙЛОЁПЩФмМђЕЅЕФЗХЕНгІгУВуЁЃ
ЕБSimulinkФЃаЭШЋВПЙЙНЈКУжЎКѓЃЌ НЈвщдкжаЖЯЗўЮёЧјЬэМгОЁСПМђЕЅЕФМЦЫуЁЃжаЖЯЗўЮёГЬађЕФМђЕЅПЩвдМѕЩйЦфЫљеМЪБМфЃЌетбљФмБЃжЄЯЕЭГЕїгУШЮЮёЪБМфМфИєЕФзМШЗадЁЃШчЙћПЩвдЃЌжаЖЯжаВЛвЊАќКЌБъзМЕФPIDМЦЫуЃЌЭЦМіЗХжУНіжДааЩшЖЈЖЏзїЕФКЏЪ§ЁЃЕБШЛЃЌВЛФмШБЩйБивЊЕФМЦЫуЁЃОйИіР§згЃЌЖдгкДэЮѓеяЖЯЃЌМДЪЙЪЧИДдгМЦЫуЃЌдкИУжДааЕФЪБПЬЛЙЪЧБиаывЊеяЖЯГіНсЙћЕФЁЃ
ЖдгкФЧаЉБШжаЖЯЗўЮёГЬађТ§ЕФВПЗжЃЌКЭНгЪежИСювЊБШжДааЫйЖШПьЕФВПЗжЃЌВЛгІИУИјГіжБНгжДааЕФДњТыЃЌЖјЪЧвЊШУФПБъжЕЛђНзЖЮжЕдкЯТвЛИіУќСюЕНРДжЎЧАЃЌЭЈЙ§ЯпадВхжЕЕФЗНЗЈДЋЕнГіШЅЁЃ
3.2 RCP КЭ AUTOSAR ШэМўЦНЬЈ
ЪЙгУRCPЕШЩшБИНЈФЃРрЫЦгкAUTOSARжаШэМўИќаТЕФИХФюЁЃЕБШЛЃЌЩњГЩЕФДњТыВЛЗћКЯAUTOSARЙцЗЖЁЃР§ШчЃЌRCPЕФI/OШэМўдЪаэЙЉгІЩЬЬсЙЉЕФSКЏЪ§НјааСДНгЃЌВЂЧвдЪаэгУЛЇЩшжУгІгУГЬађЧјгђЁЃгІгУГЬађжагУЛЇздЖЈвхКЏЪ§КЭSКЏЪ§ФмЙЛдкSimulinkжажБНгСЌНгЃЌВЛашвЊПМТЧЖдRAMЕШвђЫиЕФгАЯьЁЃ
ЩњГЩЕФCДњТыдкЪЕЪБВйзїЯЕЭГЩЯдЫааЃЌSimulink РяI/OЯрЙиЛсЩњГЩдкВЛЭЌЕФдДДњТыЮФМўжаЃЌЪЕЪБВйзїВПЗжКЭзїЮЊжаЖЯДІРэЕФВПЗжЛсздШЛЗжРыЁЃгУЛЇВЛБиПМТЧФЧаЉЦНЬЈЃЛГЇЩЬДДНЈЕФ
I/O S-functionЛсдкашвЊЕФЪБКђдЫааЃЌВЂЧвЖдгк гІгУГЬађНЈФЃЃЌВЛгУПМТЧI/OДІРэЕФФкШнКЭЪБМфЁЃ
ОпгаетжжШэМўНсЙЙЕФецЪЕЕФПижЦФЃаЭ/ШэМўЃЌЛсгаИќЖрЕФгХЪЦЁЃгЩгкRCPФмЙЛМЏжаОЋСІПЊЗЂгІгУГЬађЃЌЖјВЛБиПМТЧШэМўНсЙЙЃЌЫћУЧЛсздШЛЕФбЁдёAUTOSAR
ЦНЬЈЁЃЛЛбджЎЃЌШчЙћФуЕФВњЦЗВЛТњзуAUTOSAR БъзМЃЌВЂЧвдкRCPЩЯЪЙгУAUTOSARЕФИХФюНјааПЊЗЂЃЌФуБиаыздЖЈвхЩњГЩЕФДњТыЃЌВЂЧвДгMBDПЊЗЂГЩЙћЕФЙВЯэжаЗжРыГіРДЁЃ
4. ЕЅШЮЮёКЭЖрШЮЮё
ЧЖШыЪНШэМўЕїЖШЦїЩшМЦжаЃЌгаЕЅШЮЮёКЭЖрШЮЮёЕФИХФюЁЃ
4.1 ЕЅШЮЮё
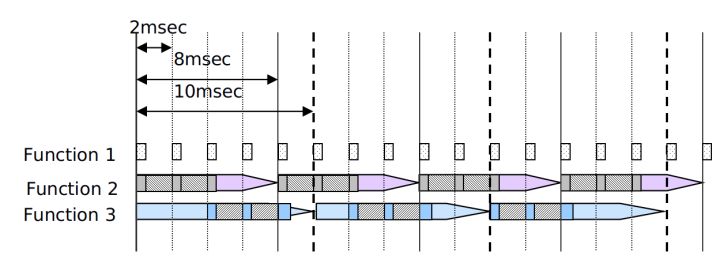
ЖдгкЕЅШЮЮёЃЌМйЖЈЛљДЁжмЦкЮЊ2msЃЌЕБ2msЁЂ8msЁЂ10msдкЯЕЭГжаДцдкЪБЃЌетаЉЪБМфЦЌЖМЪЧЛљгк2msЕФМЦЪБЦїНјааДДНЈЕФЁЃУП2msЕФжДааЫГађЮЊЃК8msЕФШЮЮёЯТУП4Иі2msШЮЮёКѓжДаавЛДЮЃЌ10msОЭЪЧУП5Иі2msЁЃашвЊзЂвтЕФЪЧЃЌвЊЪЙгУЕЭЦЕТЪЕФШЮЮёЦЌРДДІРэИДдгЕФдЫЫуЃЌВЂЧв2msЁЂ8msЁЂ10msЖМЪЧгЩЯрЭЌЕФ2msНјаажмЦкМЦЫуЁЃвђЮЊЫљгаЕФдЫЫуЖМвЊдк2msФкЭъГЩЃЌвдБуБЃжЄЧЖШыЪНШэМўЕФЪЕЪБадЃЌдкетжжЧщПіЯТ8msКЭ10msЕФШЮЮёБЛЗжИюГЩСЫМИЖЮЃЌвдБЃжЄЫљга2msЕФМЦЫуСПЛљБОГжЦНЁЃдкетжжЗНЗЈЯТЃЌПЩвдЭЈЙ§ЗжЧјРДМѕЩйУПИіжмЦкЕФМЦЫуСПЃЌВЂЧвЪЙЕУCPUИКдиЦНОљЗжХфЁЃ
ЛљгкШчЩЯдвђЃЌ10msЕФШЮЮёЦЌБЛЗжГЩШчЯТМИИіВПЗжЁЃ
|Fundamental frequency |Offset |
|---------------------- |-------|
|10ms |0ms |
|10ms |2ms |
|10ms |4ms |
|10ms |6ms |
|10ms |8ms |
ЭЌРэПЩжЊЃЌ8msЕФШЮЮёЦЌБЛЗжИюГЩСЫ4ВПЗжЁЃ
ЕБШЛЃЌОјЖдЕФЦНОљЗжХфЪЧВЛЯжЪЕЕФЃЌФГаЉдЫЫуЙІФмВЛФмЙЛБЛЗжХфЕНЫљгажмЦкЃЌЕЋживЊЕФЪЧБЈБЃжЄCPUЕФЦНОљвЛжТЕФИКдиТЪ
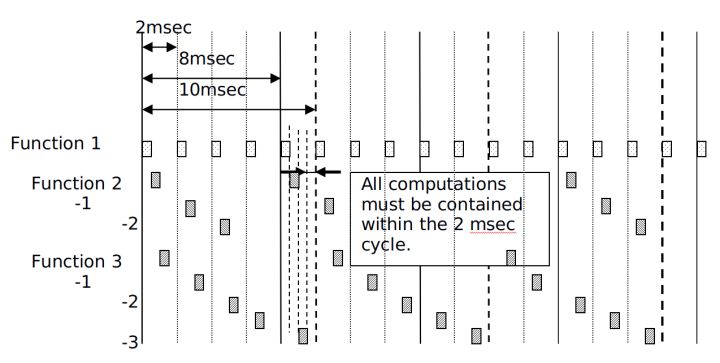
ШчКЮЩшжУШЮЮёЕФдЫааЦЕТЪ
ЩшжУTasking mode for periodic sample times ЮЊ Single
Tasking
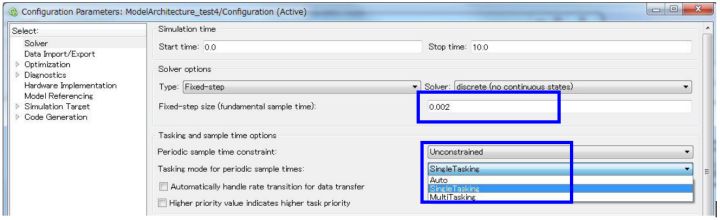
ШЛКѓдкзгЯЕЭГЕФЁАSample TimeЁБжаЪфШы ЁАsampling period, offsetЁБ
ЕФжЕЁЃПЩвджИЖЈдЫаажмЦкЕФзгЯЕЭГЮЊ дзгзгЯЕЭГЁЃ
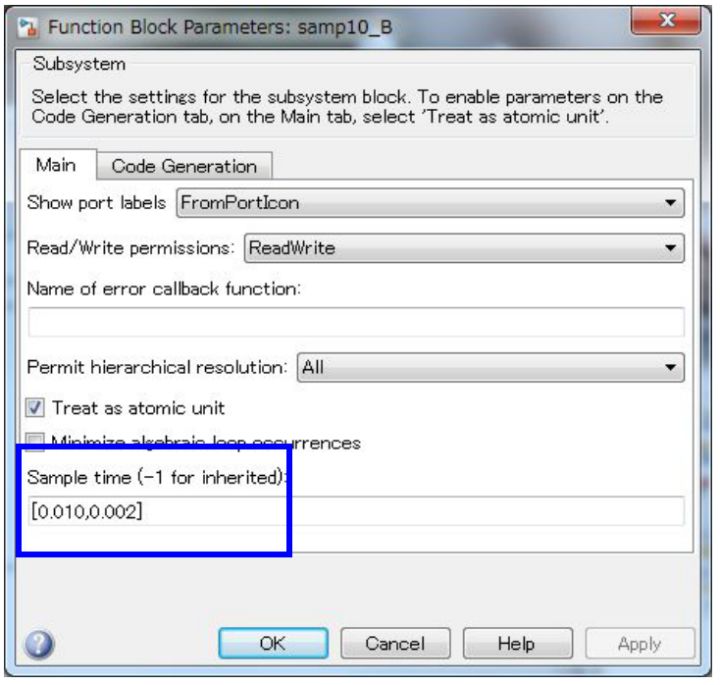
4.2 ЖрШЮЮё
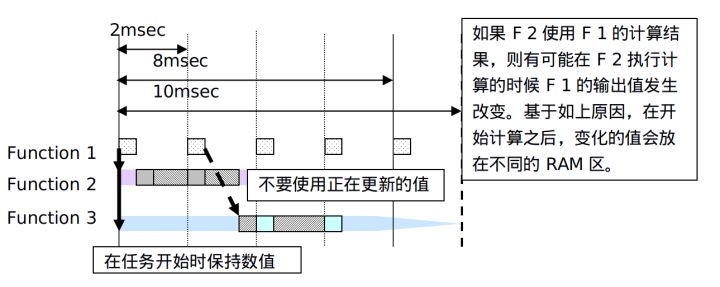
ЖрШЮЮёЮЊЪЙгУЪЕЪБВйзїЯЕЭГЕФЧщПіЯТЃЌЯЕЭГжЇГжЖрШЮЮёжмЦкЩшЖЈЁЃШчжЎЧАНщЩмЕЅШЮЮёжаЫљЪіЃЌдкЕЅШЮЮёЯЕЭГжаЃЌЦНКтCPUИКдиТЪВЛЪЧздЖЏЕФЃЌашвЊНјааЧЩУюЕФЩшЖЈЁЃЖјдкЖрШЮЮёЯЕЭГжаЃЌCPUЛсИљОнЕБЧАзДЬЌНјааздЖЏМЦЫуЃЌВЂЧвВЛашвЊНјааЬиЪтЕФШЮЮёЗжХфКЭЩшЖЈЁЃЯЕЭГЛсДггХЯШМЖИпЕФШЮЮёПЊЪММЦЫуВЂИјГіНсЙћЃЌШЮЮёЕФгХЯШМЖгЩПЊЗЂШЫдБНјааЩшЖЈЁЃДѓЖрЪ§ЧщПіЯТЃЌашвЊПьЫйжДааЕФШЮЮёБЛЗжХфИпЕФгХЯШМЖЁЃ
дкжмЦкФкЭъГЩМЦЫуЪЧЪЎЗжживЊЕФЃЌАќРЈТ§ШЮЮёЃЌКЭЕБИпгХЯШМЖШЮЮёжДааМЦЫуЧвCPU ЪЭЗХЪБЃЌжДааЯТвЛИігХЯШМЖШЮЮёЕФМЦЫуЁЃИпгХЯШМЖШЮЮёЛсДђЖЯЕЭгХЯШМЖШЮЮёЃЌВЂЛсЯШжДааЭъИпгХЯШМЖЕФМЦЫуЁЃ
4.3 ВЛЭЌдЫаажмЦкЕФзгЯЕЭГСЌНгКѓЕФгАЯь
ШчЙћзгЯЕЭГBга20msЕФдЫаажмЦкЃЌЪЙгУСЫ10msдЫаажмЦкЕФзгЯЕЭГAЕФЪфГіЃЌЕБBЛЙдкНјааМЦЫуЕФЪБКђAПЩФмЛсгаВЛЭЌЕФЪфГіЁЃШчЙћдкдЫЫуЙ§ГЬжаЗЂЩњСЫжЕЕУИФБфЃЌзгЯЕЭГBПЩФмЛсдЫЫуГівЛИіДэЮѓЕФНсЙћЁЃОйИіР§згЃЌдкBжаШчЙћДцдкЪзДЮМЦЫужЕгыAЕФЪфГіБШНЯЕФдЫЫуЃЌЧвзюжеЪфГівРОнБШНЯЕФНсЙћЃЌДЫЪБгаПЩФмЗЂЩњдкBМЦЫуЙ§ГЬжаAЕФжЕЗЂЩњИФБфЃЌЕМжТзюжеЪфГіВЛе§ШЗЕФЧщПіЁЃЮЊСЫБмУтДЫжжЧщПіЗЂЩњЃЌШчЙћШЮЮёжїЬхЗЂЩњИФБфЃЌДгAЕУЕНЕФЪфГіжЕашвЊдкБЛBЪЙгУжЎЧАНјааЙЬЖЈЁЃЛЛбджЎЃЌМДБудкBдЫЫуЙ§ГЬжаAЕФЪфГіжЕЗЂЩњИФБфЃЌвђЮЊЕїгУСЫВЛЭЌЕФRAMЧјЃЌзюжеЕФМЦЫуНсЙћвВВЛЪмгАЯьЁЃ
ЕБдкSimulinkжаДДНЈФЃаЭВЂЧвдкSimulinkжаСЌНгСЫОпгаВЛЭЌдЫаажмЦкЕФзгЯЕЭГЪБЃЌSimulinkЛсздЖЏБЃСєЫљашЕФRAMЁЃ
ЕБШЛЃЌШчЙћВЛЭЌдЫаажмЦкЕФЪфШыжЕЛёЕУЪЧЭЈЙ§ ЪжаДДњТыМЏГЩЕФЗНЪНЃЌдђЯргІЧЖШыЪНШэМўЙЄГЬЪІашвЊНјааЯргІRAMЧјБЃСєЕФЩшжУЁЃдкAUTOSARжаЕФRTWВуЃЌОЭЪЧдкНгЪеКЭЗЂЫЭГіПкЗНУцЖМЖЈвхСЫСЫВЛЭЌЕФRAMЁЃ
ЕЅШЮЮё
2msбЛЗФкаХКХжЕЯрЭЌЃЌЕЋЪЧашвЊзЂвтВЛЭЌЕФ2msдЫЫужЕКЭЩЯвЛИі2msЕФжЕПЩФмВЛЭЌЁЃШчЙћ2-1 ЁЂ
2-2 ЪЙгУСЫF 1жаЕФаХКХAЃЌдђ 2-1 ЁЂ 2-2 ЛсЪЙгУВЛЭЌ2msШЮЮёМЦЫуГіЕФжЕЃЌДЫДІвЊНјаагАЯьЪЖБ№ЁЃ
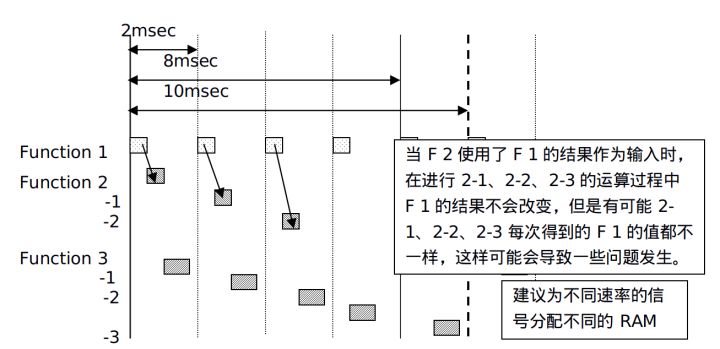
ЖрШЮЮё
ЖдгкЖрШЮЮёЃЌВЛФмЙЛжИЖЈЪЙгУМЦЫуНсЙћЕФЪБМфЕуЁЃдкЖрШЮЮёЯЕЭГжаЃЌЮоТлЪЧЗёЮЊВЛЭЌдЫаажмЦкЃЌзмЪЧашвЊИјаХКХБфСПКЭДЋЕнБфСПЗжХфВЛЭЌЕФRAMЁЃ
дкжДааШЮЮёЕФаТМЦЫужЎЧАЃЌЫљгаЕФжЕЖМЛсвЛДЮадИДжЦвЛБщЁЃ
|








