| 编辑推荐: |
本文主要介绍DDD设计中,如何从领域视角深入仓储(Repository)的设计和实现。希望对您的学习有所帮助。
本文来自于微信公众号阿里开发者 ,由火龙果软件Linda编辑、推荐。 |
|
一、前言
“ DDD设计的目标是关注领域模型而并非技术来创建更好的软件,假设开发人员构建了一个SQL,并将它传递给基础设施层中的某个查询服务然后根据表数据的结构集取出所需信息,最后将这些信息提供给构造函数或者Factory,开发人员在做这一切的时候早已不把模型看做重点了,这个整个过程就变成了数据处理的风格
”——摘 Eric Evans《领域驱动设计》
《领域驱动设计》中的Repository(下面将用仓储表示)层实际上是极具有挑战性的,对于它的理解,也十分重要。本文大部分内容都在众多前辈理论基础上,从一个崭新的领域视觉开始探索,并结合自己的实践感悟进行细致的解析。同时本文不仅仅是DDD前辈的搬运工,也创新提出了仓储实体转移的概念,可以提供给读者思考是否在自己场景中可以用到这种模式。即使读者也对仓储有很深的了解,我也觉得本文会对你有新的阅读体验。
导读:
本文首先从聚合根的生命周期和生存环境出发,引出了Repository概念,并说明其本质是管理中间过程的集合容器(2.1节);
根据集合容器的概念,在领域角度去挖掘出Repository的职责,并提出了仓储实体转移模式用作对不同仓储实现的对比标准(2.2节);
然后从实现例子出发,介绍了一种纯内存实现的仓储,用作体现仓储最佳实现(3.1节);
继续从实现例子出发,介绍了关系型数据库下的仓储特点,并描述面向持久化的仓储的特点(3.4节);
二、概念剖析
DDD作者在介绍仓储模式的时候,谈到了大部分技术的过程会入侵领域模型,让开发人员迷失,本文反其道行之,读者可以先假设内存是无限大的,便于我们先关注模型再讨论技术实现,然后我们先从DDD中的重要概念
聚合实体 的领域模型使用出发,挖掘出仓储的本质特征和与之相关领域概念,然后再从本质特征,指导如何实现仓储。
2.1 聚合实体
服务于实体的集合容器:说到仓储我们必须要先讨论聚合(聚合是由实体和值对象组成,其中有一个实体为聚合根,后面提到聚合实体即聚合根),仓储必然是为聚合实体服务的,值对象则不必要。那我们的实体为何需要仓储呢?这得从实体的整个生命周期说起,我们先总结一下DDD中聚合实体的特点:
标识:实体具有唯一标识,这个唯一标识使得实体和值对象区分开来;
状态:实体是具有可以被改变的状态,因此聚合实体无法被静态描述;
生命周期:实体拥有生命周期,从实体的创建,到实体的状态的终态;
生存环境:实体的活动存在于各个上下文中的领域服务或者应用服务中,其中分用例过程和中间过程;
用例过程:只要在执行用例过程的时候才需要实体的存在,其他时候,实体生命周期并没有结束,而是处于中间状态;
中间过程:当没有任何用例在处理一个实体的时候,实体消失了吗?没有,它仍然存在生命周期内,这个时候我们认为实体正处在一种中间过程。
其中最重要的就是实体会存在于各个上下文中的用例运行过程中,之外的都会存在于一个中间过程中,我们用图示来进行中间过程的描述。
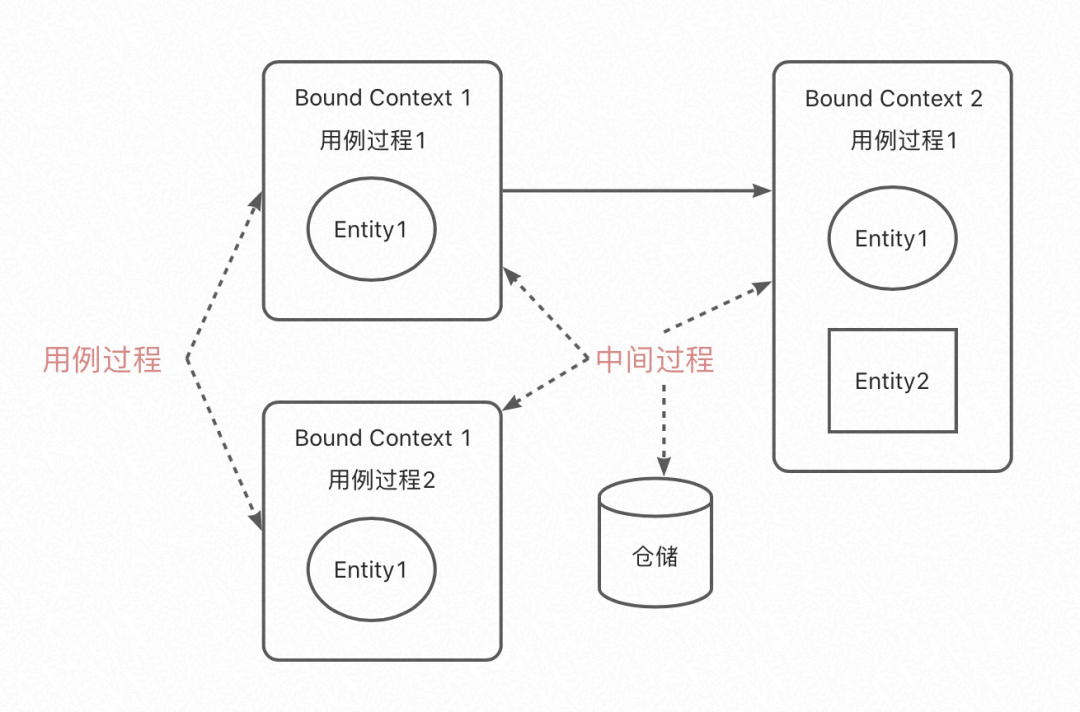
检索聚合根:在解决空间的运行态中,用例调度者(执行者、线程)要么新建聚合实体,要么获取中间过程的聚合实体,创建新实体好说,但是中间过程的实体是如何获取到的呢?其实中间过程的实体,只能是经过查找到得到的,这是一个检索的过程。其中检索包括全体遍历(包括索引)和关联遍历,不管何种检索渠道,我们都要让Domain感觉到,检索回来的实体还是原来那个实体。
统一语言:中间过程、用例过程,这些词领域专家、业务人员是听不懂的,中间过程也不在模型关注点上,但又是与模型有关联。所以我们在领域角度、统一语言角度,封装角度,这个中间过程都应该提出一个统一的领域概念抽象,屏蔽掉中间过程的细节,让领域专家能明白我们的意思。仓储(仓库,贮藏室,Repository),这个词就很适合,它类似一个帮你暂存物品的仓库,然后你可以在仓库中找回你要的物品。
但这个词本身不重要,重要的是领域专家能听懂仓储这个词的语义,并和技术人员统一,搭建一个沟通的桥梁。有关仓储的统一语言应该有以下几点:
放置:建立一个新的聚合实体,这是一个聚合实体生命的开始,在用例过程结束后,把聚合实体放到仓储中;
查找:把已经存在的聚合实体找出来,这是一个聚合实体的中间过程到用例过程的行为;
管理:它负责聚合实体的中间过程管理,并屏蔽掉中间过程的细节,向领域层提供统一的能力抽象,一些数据统计类的也可以在该范畴内;
集合容器:为了方便的把处于中间过程的实体找出来,我们的仓储需要解决两个问题,第一个是如何放置实体,第二个问题是如何检索实体。
如何放置实体:为了方便管理,我们通常会采用分治把同一种类型的实体放在一起成为一个集合。相同类型和集合给了我们一个指导就是:仓储的设计应该是一个聚合实体类型对应一个仓储实体,具有一一对应关系,所以仓储实体应该是一个保存相同类型元素的集合容器;
如何查找实体:我们知道实体具有唯一标识别,也具有其他特征属性,所以为了查找实体,我们应该通过实体的唯一标识或者特征属性去遍历查找,仓储应当提供这种功能,所以仓储应该针对聚合实体字段具有索引查找功能;
如何查找仓储:既然我们提到了需要用仓储来查找实体,那么我们又是如何查到仓储的呢?其实这个很简单,如果一个聚合实体类型只具有一个仓储类型,那么我们把仓储设计为单例的就可以了。
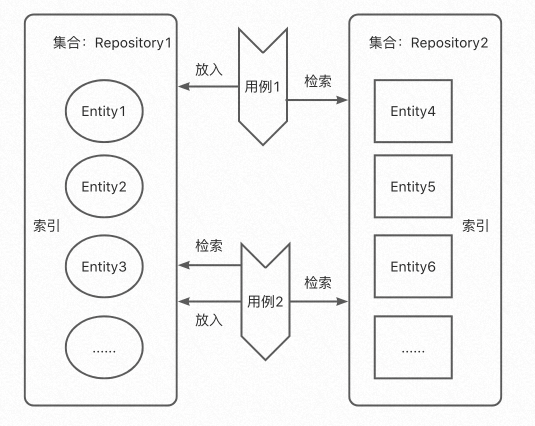
我们从领域模型的生存环境角度,引申出了仓储的必要性,并在统一语言的原则上,从它的必要性行为中挖掘出了仓储的特征,关注领域模型的仓储,应当让客户感觉模型就一直在内存中一样,最后我们总结一下仓储的本质:
一个聚合类型(也就是一个聚合根),最好对应一个仓储(这个不是绝对的);
一个仓储应该是单例的,便于先查到到仓储,再查找到聚合实体(当然也不是绝对的);
仓储应该是一个集合的抽象概念,并且负责屏蔽中间过程,包括其中的实现细节,如持久化和重建,它最好能让客户感觉它似乎就一直在内存中一样;
仓储作为聚合实体的集合,应该具有检索实体的功能,如果从技术角度看,那么将一直持有聚合实体引用;
2.2 仓储职责
仓储与统计:在我们关注领域服务的时候,会有部分统计的领域逻辑可以归纳到中间过程管理中,例如我要根据某个聚合根的个数进行更新另一个聚合,仓储也应当封装这部分逻辑,主要是考虑到以下几点:
我们的一个用例服务中很可能不需要使用聚合实体本身,而仅使用到符合某种条件的聚合的数量,因此我们没必要查出聚合实体进行统计;
具体的基础设施数据库实现,对统计性能有着显著的性能优化,为了使用这些中间技术的优点,把统计这种细节的操作委托给仓储是一个很好的选择。
统计和查询有很多时候的应用场景是不修改聚合根状态的,所以这种情况你可能没必要使用仓储完成这件事,CQRS的思想要求我们去分离查询,建立查询模型,所以建立一套查询模型去做这件事是一个好的解耦实践。
仓储与规格:上面提到仓储应当具有检索功能,检索必然需要一些聚合实体的状态字段作为入参,最好的直接检索是通过实体的唯一标识别进行,但如果我们有大量不同的字段检索需求,为每一个需求在仓储建立一个这样的方法接口,必然让仓储变得臃肿。规格这个概念可以消除这种臃肿变得可能。我们抽象一个规格实体,然后把规格作为一个参数传给仓储,让仓储根据规格获取聚合实体,便可统一检索功能。对该模式敢兴趣的可以参考Eric
Evans的《领域驱动设计》第9章:
规格是一个谓词,封装了业务规则,可以明确表达一个特定实体是否满足该规格标准;
规则是值对象,可以组合使用,其组合实现与SQL的拼凑非常契合,使得其十分适合应用在仓储;
规格的概念引入,使得我们对实体多种检索的需求过程做到了通用化;
好的规格实现,链式 API 调用,可以使得编程变得灵活,表达能力强流畅;
仓储与唯一标识:上面提到,聚合实体具有唯一标识,其中唯一标识的生产方法也有很多种(如用户输入生成、分布式ID生成、数据库持久化时候生成),生成时机也可以在执行用例步骤之初,也可以在事务持久化的时候。在用例执行之初的情况下,我们其实可以让仓储封装这种生成唯一标识,或者直接让仓储提供新聚合的工厂方法,这种表达会更自然。
仓储生成唯一标识别:在利用数据库能力生成唯一ID的时候(例如TDDL的Sequence),因为仓储本身封装数据库细节,所以仓储可以单独提供这种功能,例如
DomainRepository.getInstance().newEntityId() 方法,返回一个由数据库管理的唯一ID。
仓储提供工厂方法:聚合实体的创建,不一定是由领域服务完成的,如果我们的聚合实体具有创建模板,那么我们可以假设仓储本身具有大量的新对象池待使用。所以可以这样创建实体:DomainRepository.getInstance().newXXEntity()
返回聚合实体(该方式Evric不推荐);
仓储与Resource:Repository通常被翻译为资源库,个人认为对比仓储,资源库的描述可能会让我们更多的把聚合实体看作为一种网络中可以唯一定位的资源(Resource)抽象。我们通常在网络术语中看到资源的概念,如URL中的R即资源,如REST架构风格(表现层状态转移)也会把对象当初是资源。如果从资源角度看仓储,就是实实在在的资源库:
作为Resource,我们通常会给它定一个URI(统一资源识别),用作全网唯一识别,但很少资源库会定义URI,因为实体唯一标识已经足够;
作为Resource,仓储一但持有了资源,那么就一直持有并跟踪资源,直到资源被删除;
作为Resource,仓储有时会被当作是对远程服务进程封装的机制,这个时候仓储有点像防腐层,但我不建议这样做(国内部分书籍有这种介绍);
介绍这种角度,只是想让读者了解各种一些方案背后的设计理念。后面介绍面向集合的仓储的时候,或者需要结合DDD和REST架构风格的时候,读者可以自行体会聚合实体作为Resource的意义。
仓储实体转移(创新):现在我们讨论一个问题,当我们从仓储中获取到聚合实体之后,仓储是否还应该拥有该聚合实体?如果我们抛开计算机和技术概念,完全从问题空间出发,那么仓储是不再拥有聚合实体的:想象一下,一个仓库管理人员需要处理一个商品,当他从仓库获取到该商品后后,另一个人在仓库中还能找到这个商品吗?按照这种思维对仓储进行建模,仓储和聚合的关系可以明确为:
聚合实体一个时刻只能存在于一个用例过程或者一个仓储实例中;
聚合实体无法同时存在在仓储中和用例过程中;
聚合实体也无法同时存在于两个用例过程中;
如果我们在解空间中对这个过程进行建模,可以描述为下图:

有人或者会觉得我对这个仓储的建模太较真了,因为我完全从问题空间角度看这个问题,但我提出这个的目的,只是想为后面的实践方案提供一个以问题空间为主的参考标准,突出在仓储选择不同实现的时候不得不屈服于技术的特性从而使得仓储的特性产生的差异。我会在每个实现中提出如果要抹平差异要怎么做,并给出可以应用的场景,读者理解这些差异后会对仓储有更深的了解,其中《实现领域驱动设计》中Vaughn
Vernon提出的一种实现为面向持久化的资源库和这种问题空间角度其实是相通的,而Vaughn Vernon提出的另一种实现为面向集合的资源库和解空间看的角度是想通的。我暂且将仓储实体转移描述为一种模式(后面统一为仓储实体转移模式),在该模式下,仓储领域本质上,应该只有两种操作:
放置(put或save):把聚合实体从用例过程,放置到仓储中,状态变为中间过程,用例过程中不再拥有实体;
获取(Take):用例过程运行中,需要把实体从中间过程,转移到用例过程,完成这个操作后,仓储将不再拥有实体,我特别用take而不是find表达了这种思想。
大家可以对比数据库的操作更新和删除。这两个操作是带着数据建模的思想,我将会在下面关系型数据仓储中提及,让大家衡量要不要仓储增加这两种行为。同时也会介绍在关系型数据仓储实现和内存仓储实现如何改进为仓储实体转移模式,达到对比的目的。
作为开发人员,我们在应用DDD,关注模型的时候隔离了中间过程,确实得到了以模型为关注点的概念设计,但我们还需要兼顾技术的实现难度以及可行性,其实整个仓储的解决方案在细节中并没有那么简单,下面我们开始沿着领域模型分析的结论,开始看技术实现的鸿沟。
三、实现剖析
如果有无限大的内存,或者无需持久化的业务,DAO层必然不存在,但仓储(集合容器+检索的数据结构)是仍然存在的。这就是为什么我认为,理解仓储的本质,不应该从技术角度思考,而是从领域角度思。即使我们对仓储在领域上有几乎固定的职责和功能,具体实现的仓储都很难满足其领域模型角度的功能。在《实现领域驱动设计》一书中,Vaughn
Vernon提出2种仓储的实现模式:
面向集合的资源库:面向集合的仓储提出的是完全按照集合的理念去设计仓储,就似乎它就是Set数据结构一样。所以他能自动去跟踪聚合实体的变化
面向持久化的资源库:面向持久化的仓储,核心点是合并了插入和更新这两种操作,统一用 save() 操作完全取代仓储旧实体使得仓储的功能更统一。这种数据存储(如MongoDB等文档数据库)通常称之为:面向聚合的数据库(Aggregation-Oriented
DataBase)或聚合存储(Aggregation Store)。
以上两种模式对仓储来说都没有统一,他们各有不同特点,面向集合模式强调仓储一直保持跟踪(引用),而面向持久化则强调采用
save()或者 put() 操作全量覆盖。本文的实现介绍角度不同,但效果差异不大,本文只对内存实现和关系型数据库实现做区分,并希望在统一的角度做了一些解读给读者参考。但我认为读者可以根据自己理解去侧重选择自己的实现。
3.1 内存仓储
在《实现领域驱动设计》一书中,作者Vaughn Vernon提出一种面向集合的仓储,我认为这其实就是一种完全面向内存实现的仓储方式,在这种方式中,我们利用仓储管理聚合实体的生命周期中间过程其实和使用框架集合(Collection)是一样的。我把书中的例子稍改动展现如下:
public class CalendarRepository extends HashMap{
private Map<CalendarId,Calendar> calendars;
public CalendarRepository(){
this.calendars = new HashMap<CalendarId,Calendars>();
}
public void add(Calendar aCalendar){
this.calendars.put(aCalendar.getId,aCalendar);
}
public Calendar findCalendars(CalendarId calendarId){
return this.calendars.get(calendarId);
}
} |
熟悉编程的人员很简单就知道这是怎么一回事了。这个实现也很能表达从领域模型的角度看仓储应该是怎么样子的。我总结了该实现特点如下:
仓储应该是一个集合实例,而且无法对仓储进行重复的放置;
从仓储获取的聚合实例,应当和放置仓储的实例具有完全一样的状态,在这里是原对象;
如果在仓储之外对聚合实例进行了修改,无需“重新保存”聚合实例;
这种仓储下的聚合实体,看起来更加像资源Resource;
抹去引用的创新改进:Vaughn Vernon的这个例子完全解析了仓储应有的样子,但即使纯内存实现也不得不融入了实现的特性——仓储完全持有集合。这种持有引用特性几乎对领域无影响,但我还想试图把这种实现特性抹掉。对比
2.2中间过程的仓储实体转移一小节中,当取出资源后,集合不应该再拥有聚合实体。所以按照这种思路进行,findCalendars方法还应该加上逻辑移除Calendar聚合的实现,如下面代码所示。但这样完全模拟有什么好处呢?这是一个好问题,因为我们的选择必须要权衡其中得失。继续往下看一下不这样做引起的并发冲突问题......
public class CalendarRepository extends HashMap{
//存聚合实体
private Map<CalendarId,Calendar> calendars;
//标记实体被逻辑移除
private Map<CalendarId,Thread> calendarsTakenAway;
public CalendarRepository(){
this.calendars = new HashMap<CalendarId,Calendars>();
}
public synchronized void add(Calendar aCalendar){
this.calendars.put(aCalendar.getId,aCalendar);
//移除逻辑删除
calendarsTakenAway.remove(aCalendar.getId)
}
//注意我们改了命名方法,变为了take,获取,体现仓储不再拥有实体
public synchronized Calendar takeCalendars(CalendarId
calendarId){
//如果已经被取过,无法再取
if(calendarsTakenAway.containsKey(calendarId)){
return null;
}
Calendar calendar = this.calendars.get(calendarId);
//逻辑删除
calendarsTakenAway.put(calendarId,Thread.currentThread());
return calendar;
}
} |
考虑并发:在领域角度,在同一个时刻没有有两个人可以同时在一个仓库中获取到同一件商品,但在计算机解空间中可以,所以计算机解空间会出现并发问题。为了解决并发问题,我们可以使用以下方式
悲观锁:在一个调度者(线程)使用该聚合实体前,先对聚合实体进行加锁,其他调度者则无法获取实体进行操作
阻塞悲观锁:如果调度者发现聚合实体被锁了之后,则停止调度直到等待得到实体锁后继续;
非阻塞悲观锁:如果调度者发现聚合实体被锁了之后,不等待锁,立即返回做其他用例;
乐观锁:一个调度者认为冲突可能性不大,所以可以先获取聚合实体进行事务操作,但是当它想把聚合持久化的时候,发现有人操作过这个聚合,则回滚自己所有的操作。
采用哪一种操作完全取决于软件开发人员,这个时候要求我们对程序架构设计和运作方式有着充分的了解,但是我们可以看到,其实用到了仓储实体转移这种完全模拟真实的领域问题空间的实现,刚刚好就是非阻塞悲观锁。只要是findCalendars方法删除找到的Calendar实体是原子性的操作,其他线程则无法获取到实体,那么我们便不需要考虑重新设计一个新的锁方案。如果你不是为了性能等其他因素非要领域模型妥协或者你刚好选择的就是非阻塞性悲观锁,那么这种实现将会大大简化你的程序代码重量,也能让客户了解你的模型运作机制,使得该过程也做到了统一语言。
即使是我们常用的乐观锁,在数据库仓储下仓储实体转移也非常适用。最后明确一下,做到统一语言,回归领域本质的意义非常大。它是领域驱动设计应付软件复杂之道的核心理论基础。它要求我们抓住问题的本质复杂度,尽量排除因计算机技术方案引入的偶然复杂度,从而实现软件的架构价值,获取长远的软件效益。
3.2 关系型数据库仓储
DAO和仓储思维差异:正如本文开篇中的第一段话所引用,我们程序员通常会在实现技术的过程中,把关注模型的想法早早抛之脑后,这是可以理解的,我们在入门该科学所接受的基础学习让我们的思维很大程度上固化为面向计算机技术的开发,却往往没注意到,软件工程的设计建模更应该关注的是模型,DAO和仓储正是这两种差异的产物。本文不会解析DAO和DO之类的概念,因为读到这里的读者,对他们的了解应当是非常专业的。
DAO和仓储实现差异:先引出一个例子:我们有一个主任务TaskA和两个子任务subTaskB,subTaskC,这三个实体都有一个叫state的状态字段,我们有一个业务规则是:所有子任务实体的状态都是FINISHED,那么就把TaskA实体的state设置为FINISHED。但是外部事件是一个一个子任务回传回来的,我们接下来看不同思维的实现。
面向数据的开发思维,使用关系型数据库实现仓储的时候,我们对数据表有插入、更新、删除、查询四种主要操作,而且在面向数据模型开发的时候,服务类本身明确知道自己是在做哪一步操作。所以面向数据模型的开发经常会写这样的代码:
public class BusinessService {
@Resource
private TaskDao taskDao;
@Resource
private SubTaskDao subTaskDao;
@Transactional
public void onFinished(String subTaskId,String
taskId){
//查出所有子任务
List<SubTask> subTasks = subTaskDao.getAllSubTask(taskId);
//找出回传的子任务
SubTask callBackTask = subTasks.stream()
.filter(e->subTaskId.equals(e.getSubTaskId)).findAny();
//更新子任务状态
callBackTask.setFinished(true);
//如果所有子任务完成,更新主任务状态
if(allFinished(subTasks)){
taskDao.updateStateById(taskId,TaskStatusEnum.FINISHED);
}
//更新一个字段
subTaskDao.updateStateById(subTaskId,TaskStatusEnum.FINISHED);
}
} |
上面的代码,用例服务知道自己要更新什么字段,并自行去做了更新,但当我们关注模型思维用到仓储的之后,针对以上的功能实现用例服务就不应该关注到更新哪一个字段这个和持久化相关的操作,而是让仓储需要自行去对比,哪些字段变化了,然后更新到数据库中去,用例服务会是下面所示的样子:
public class
BusinessDomainService {
public void onFinished(String subTaskId,String
taskId){
//获取实体的时候记录快照
Task task = DomainRepository.getInstance().taskOf(taskId);
//聚合实体负责业务逻辑
task.subTaskFinished(subTaskId);
//仓储自己识别到底哪个字段变化了,然后更新该字段(简称diff)
DomainRepository.getInstance().put(task);
}
}
public class Task {
private List<SubTask> subTasks;
private TaskStatusEnum status;
public void subTaskFinished(subTaskId){
//找出回传的子任务
SubTask callBackTask = subTasks.stream()
.filter(e->subTaskId.equals(e.getSubTaskId)).findAny();
//更新子任务状态
callBackTask.setFinished(true);
//如果所有子任务完成,更新主任务状态
if(allFinished(subTasks)){
status = TaskStatusEnum.FINISHED;
}
}
} |
以上就是面向数据开发和面向领域模型的仓储开发的差别。那么这样的例子应该选择哪一种实现最好呢?这个问题不好回答,既然是DDD那只能选择仓储,这基本涉及的是系统如何设计的问题。简单的系统选择面向数据开发是简单直接的。你应该在什么时候使用「领域驱动设计」这种仓储设计思想,别忘记了它的作用:复杂性软件应对之道。
复杂的聚合根实体:如果你的数据字段是有限的,但是实体变化的规则是多种多样的,那么实现自动更新模式将得到好处。假设我们一个实体有20个字段,那么我们
diff 20个字段的代码必然比写不知道多少个由这20个字段组成的组合接口要强。另一方面,比较可怕的是,有可能用例过程本身根本不知道一个要更新的实体哪些字段发生了变化,为了说明这些情况,我们不得不提一下聚合根的另外一些特点。
聚合内部一致性:聚合根的存在,最主要是的封装和管理聚合内部各种实体的关联和耦合,包括代码耦合和数据耦合,所以上面的task本身持有所有subTask的引用,而且负责subTask和task的state状态业务规则一致。此时,这个事务处理过程,就无法感知Task封装的一致性逻辑是否由subTask引起了Task实体自身的状态变化成为FINISHED,所以diff的实现就很有必要。

领域服务的纯粹性:如上图所示,因为设置Task的状态规则是由聚合根负责,所以领域服务是不感知的,必须要靠diff,但是如果把diff这个逻辑写在领域服务中,不如把逻辑写在仓储中,因为我们也不应该让领域服务去关注一些技术上的逻辑,增加领域服务逻辑的复杂性。其实这样做,刚好就是仓储本身的职责,封装diff后的仓储让领域服务感觉到聚合实体一直在内存中一样。
聚合根的重建工序:在DAO中,我们可以直接方便从ORM框架中返回数据对象,但是聚合根却不能,因为聚合根是由多个DO组成的,我们的持久化中间件(不管是MySQL关系型还是MongoDB文档型)无法给我们返回一个聚合根实体。所以仓储还得老老实实的把ORM中获取到的DO组装为Entity和Value
Object,且要保证查找到的实体是要和原来的实体一摸一样的。这意味着需要“重建”实体的操作;
拆建规则(Convertor):仓储应当知道怎么拆,就应该怎么复原,所以它应该有一套拆解和重建规则,并根据此规则进行复原,Convertor是维护这种规则的一种工具,我建议采用这种命名类封装拆建规则
事件溯源(Event Sourcing):还有一种重建工厂的实现是利用实体的快照+实体的领域事件集合回放来恢复聚合实体,有兴趣的同学可以了解一下事件溯源;
聚合根与关联单例:关联单例是一种特殊的重建工序。我用一个领域事件监听器来说明,例如我们的聚合根实体实现了观察者模式,聚合根为主题,内部持有一些单例监听器对象列表,其中一个监听器用作监听聚合根的状态变化发送领域事件,那么这个监听器也应该让仓储负责拆解和恢复。
以上的几种特性,都意味着关系型数据库仓储的实现都会比较复杂。但这种复杂换来的是我们领域模型的干净,当软件系统的复杂度提升,面向数据的开发所带来的偶然复杂度是指数级别的,所以这个时候我们就能感受到仓储的复杂性付出是值得的。最后我们列举一下对比DAO,仓储的缺点:
实现复杂:因为聚合的复杂性所以我们其实现起来也非常困难,其中最好模型能配合实现这种复杂性。
犯错成本:正如DAO的某个接口只对一个属性更新,那么无论代码有何种bug,最多只会写错一个字段,但仓储全量化更新后,我们在未知情况下手一抖,那么将可能覆盖其他本应安全字段,所以这也提高了我们的犯错成本。断言是解决的一种较好方案
关系型仓储实现方案:仓储必须要让客户感觉它似乎就一直在内存中一样;但上面提到的 Diff 逻辑让仓储的使用和实现变得困难,设计者需要在整个上下文角度了解仓储的原理细节,因为要追求性能和安全的实现,还要只针对已经变化的字段更新,忽略无变化字段。其中Vaughn
Vernon在《实现领域驱动设计》里面提到了两个方法,来解决这个问题:
隐式读时复制:在查找聚合实体的时候,记录下聚合实体的所有状态,然后在更新的时候,用新状态diff旧的状态,只对特定字段进行更新;
隐式写时复制:在查找到集合实体的时候,仓储把聚合实体的更新操作隐式委派给仓储的某种机制进行,所以每次更新状态实体状态仓储都能跟踪到,并在这个时候对该值标记为脏数据,最后仓储在事务结束的时候把脏数据给刷盘。
public interface TaskRepository{
//相当于findTask,获取到的Task会被隐式追踪复制
public Task taskOf(String taskId);
public void addTask(Task task);
public void removeTask(String taskId);
//其他/统计/集合操作等
//......
} |
看上面代码,在获取方法 taskOf() 中,仓储负责开始对实体进行跟踪,因为外界调用方不感知仓储在跟踪实体,所以称之为隐式,我们可以根据聚合的不同构成自行实现以上提供的两种隐式跟踪的方案的一种,如果是追求性能那么写时复制比较好,如果是采用读时复制,那么Javers开源框架会是一个比较好的选择,但记得一定要做好单测。
以上两种方案其实都是对实体进行状态跟踪,但要注意的是在介绍这两种方案的时候,Vaughn是打算让仓储往面向集合仓储的思路走的(该方法被他归到面向集合一章)。虽然以上两种隐式方案是非常好的实践,但我认为还是可以像在面向内存仓储一节提到的一样,继续引入创新改进为仓储实体转移模型,现在我们看一下关系型数据库仓储该如何应对这种模型。
抹去跟踪的创新改进:我们上面提到了,仓储实体转移模式下,仓储实则只有两种主要操作,一个是放置聚合实体,一个是获取(Take)聚合实体。获取到实体后,仓储将不再拥有实体管理权限。在面向内存的仓储实现中,我们只需在take方法中remove掉实体即可。但是持久化下的这种仓储模式该如何实现、又有什么特点呢?
很简单,只要我们在原来的基础上,让仓储把插入和更新(即上面的跟踪)操作封装为一个操作put(也可以用save),然后让find操作不变,直接命名为take,让领域服务认为仓储实际上已经没有实体即可完成仓储实体转移模式,解析如下:
领域服务视觉:在获取(take)到聚合实体后,领域服务可以认为仓储中的聚合实体是不存在的(即使仓储没有删除聚合实体);
合并插入和更新(全覆盖):仓储没有所谓的更新操作,只有直接放置聚合实体到仓储中,可以让仓储判断该插入还是全量更新(其实和用隐式跟踪实现部分更新差别不大,隐式跟踪更安全但多一个复制操作),或者我们直接一点,完全删除实体后再次插入或者全覆盖实体;
删除:不管是否改进模型,当聚合实体生命周期结束都需要去真正的删除实体,这一点确实不好统一;
乐观锁:我们可以在实现的时候在关系型仓储中采用乐观锁保证一个聚合实体不会存在于不同的领域事务中。因为乐观锁只会让其中一个成功;
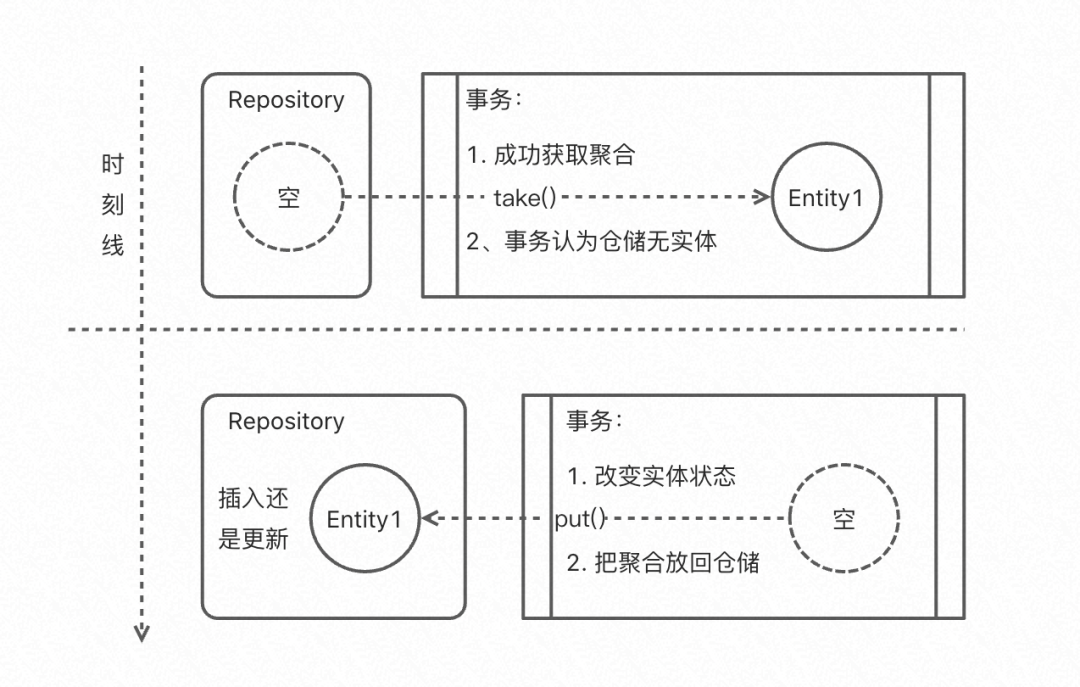
在Vaughn的书中介绍,隐式读时/写时跟踪是做成面向集合的Repository,而另外用面向聚合的数据库(Aggregation-Oriented
DataBase)来表达他的面向持久化Repository,不知道读者是否能Get到其实关系型数据库实现的仓储实体转移模式,正是关系型数据库下的面向持久化的Repository。
优点:所以它最大的优点就是无需跟踪实体,而是以转移的聚合实体为主;
缺点:因为仓储实现要全量覆盖整个聚合状态,所以只适合用在类文档数据库,对于关系型数据库则需要复杂的隐式读/写跟踪了;
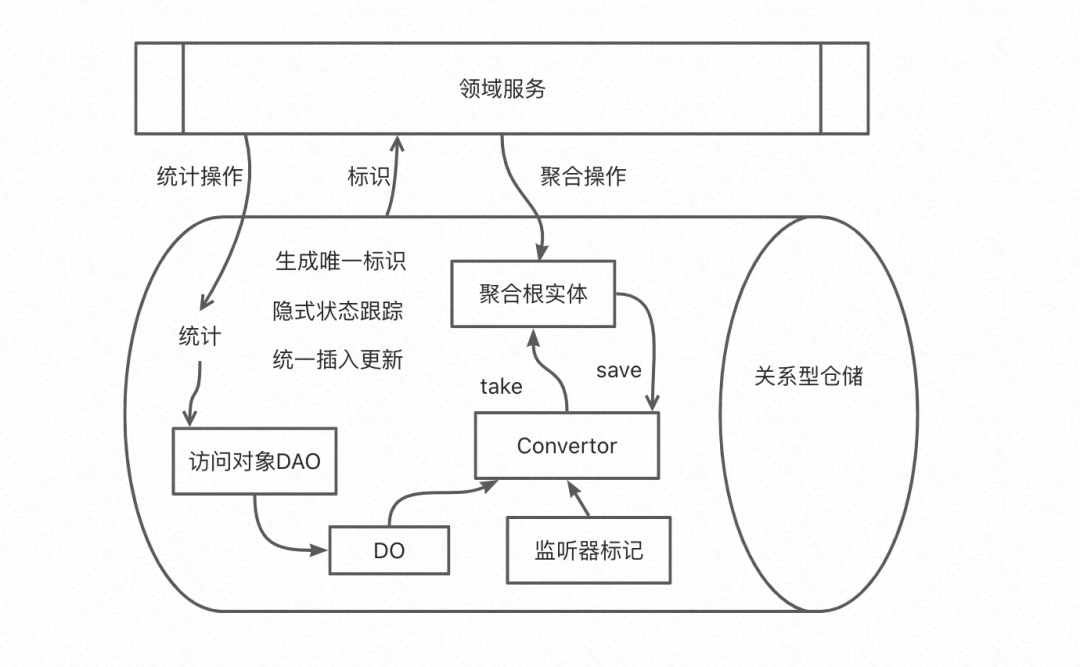
关系型仓储总结:但确实不同的实现仓储表现出了不同的特点,所以不管用何种实现,我们都需要了解仓储的使用方法,不然是无法正确使用仓储的。下面给一个图大概描述一下关系型数据库持久化仓储的功能和内部结构:
访问对象DAO:可以封装一层Mapper,或者其他ORM框架,提供DO以及其他统计数据;
Convertor:维护拆解规则和重建规则,同时复制聚合根监听器的一些组装;
DO:数据对象,一般和关系型数据表一一对应;
隐式状态跟踪:实现一套隐式读时复制和隐式写时复制状态跟踪的逻辑;
当性能不是很重要而且代码比较重视质量的时候,我比较推荐推荐在领域服务结束之前,都要把聚合实体回归仓储,然后用乐观锁把整个聚合实体替换掉仓储实现中的聚合实体。在开发规范约束、统一语言闭环的情况下,我们有了这条默契的规则,就不用担心这种漏掉持久化实现的问题,也无需考虑我们到底是插入还是更新。
3.3 仓储的架构
仓储层(资源层):我们提到,中间过程是不归领域模型关注的,我们屏蔽了中间过程提供了仓储的领域概念,那么显然仓储是领域模型关注的,这就涉及一个耦合以及依赖的问题。其中最自然的依赖就是我们的领域服务,要依赖仓储,而仓储要依赖数据库、内存等具体的实现工具去做真正的中间过程状态维护(持久化),如下图所示(图中连线代表依赖关系):
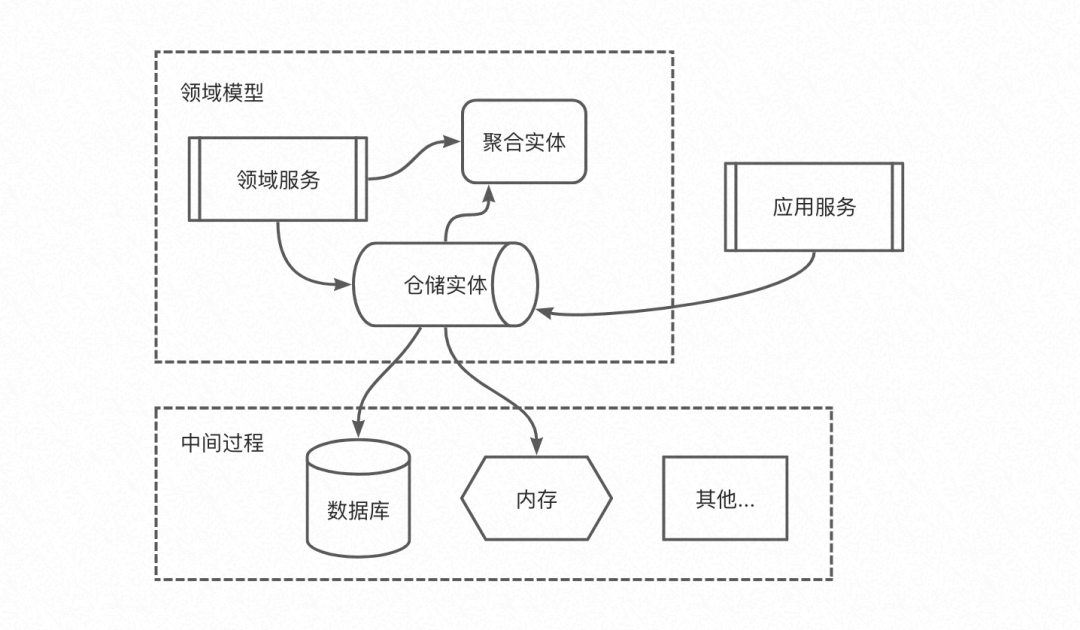
如此,在代码实现上,必然很容易让领域模型对数据库、内存等这里基础设施的代码产生依赖,从而让基础设施的概念入侵到领域模型变得容易。我们习惯于面向数据和过程的开发,当这类代码和领域模型的代码界限变得没那么明显的时候,聚焦于模型也容易被破坏,倒置依赖和整洁架构分层给了我们解决这个问题很好的实践。我们可以把仓储的行为抽象为基本的接口,然后利用控制反转,把实现该节点的仓储注入领域模型的运行态中。实现了倒置依赖的依赖图如下:
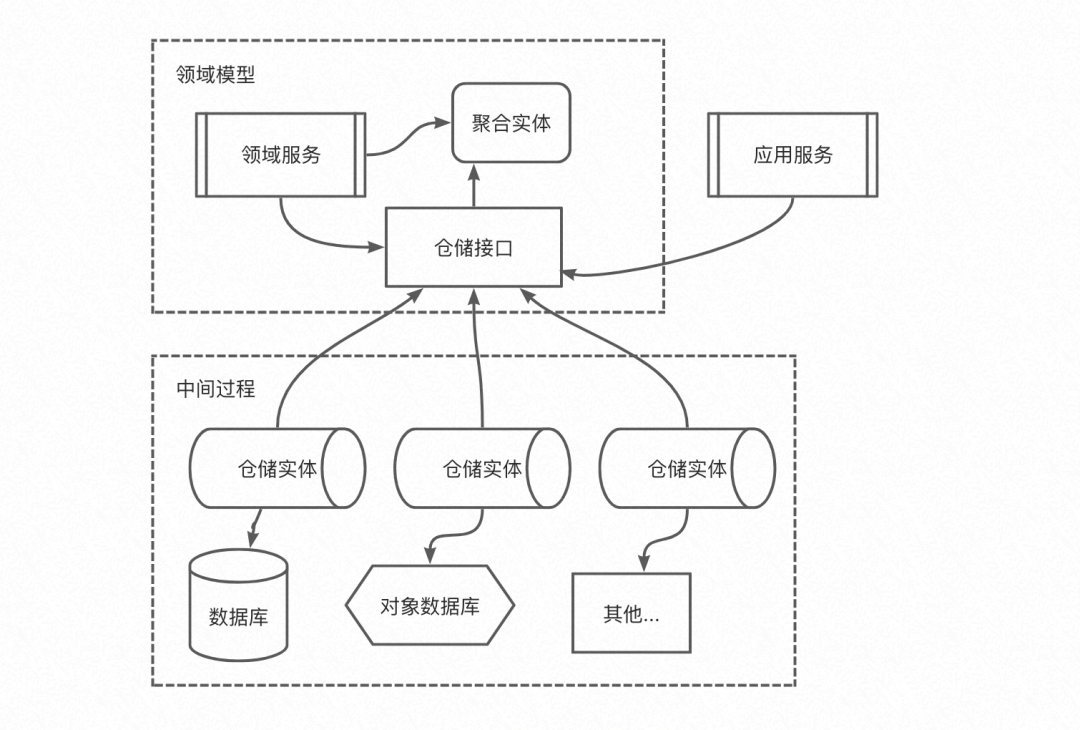
应用了依赖倒置,把所有的仓储都在一个命名空间(模块)中管理,就形成了我们熟知的仓储层(也叫资源层)。
四、结束语
对Repository的认知其实和对DDD思维的认识是统一的,他们都是从领域专家角度去对解决方案进行建模。仓储为聚合根在领域知识和工程知识之间做了隔离,并为技术实现提供了统一的概念抽象。这样的模式和例子在DDD中是经常有的,例如:防腐层也是其中的一种,他们都是为了保持领域模型的纯粹性作出了自己的努力。最后由于篇幅问题简要提一下仓储的一些我还能想到的关注点:
仓储与事务:聚合根是事务修改的基本单元;所以仓储其实也是隐藏着一个事务原子化的能力。我们通常数据库事务的实现要控制在应用层,但有时候会遇到大事务问题或者两阶段提交的问题,所以有极端情况下把事务用一个领域概念进入领域层,从而让仓储层的实现来反转控制事务也不失为一个好选择。这种打破原则的事情也要求我们理解原则。
仓储与值对象:值对象可以很简单,就一个数字,也可以很复杂,如一个完备的Domain Primitive概念。我们的实体拥有值对象,所以Repository也是要负责值对象的持久化,这点的处理也是非常值得大家去注意的点。读者在实战中处理的值对象的时候更需要丰富的经验去取舍设计方案。
仓储的设计和实现十分的复杂,我们很难在节奏比较快的开发迭代中去完成业务不关注的这种设计方式,这或许要求我们在每一次不同的迭代中去慢慢完成一个仓储。这个时候代码实现的仓储有多丑陋不重要,或者重要的是你心中有一个成型的仓储,它始终会跟着你的每一次改进被沉淀、演进。这就是为什么我们要去理解仓储存在的意义和本质,开发者如何去看待一个系统的各个构件,最终系统就会被开发成什么样子。 |







 订阅
订阅