为了提高Web交互设计模式抽取的准确性,增加现有方法对中文站点的分析能力,提出了一种基于HTML词法分析的改进方法。利用设计的HTML词法分析器将Web页面表示成语法树,抽取Web交互设计模式的特征,并对特征的词条内容进行语义扩展,细化了特征抽取的粒度。实验结果表明,改进的方法在召回率和准确率等方面明显优于现有的方法,并在中文站点交互模式抽取方面取得了很好的效果。
0.引言
在软件工程中,使用设计模式是为了产生灵活的可复用的软件系统。在人机交互的应用系统中,交互设计模式可被用来设计用户接口,解决用户与软件系统的交互问题。在Web应用中,与用户接口相关的设计模式就是Web交互设计模式,例如在Web应用中典型的交互设计模式包括允许用户通过互联网搜索信息,参加所感兴趣话题的讨论,可以在一个网站上进行注册等等。从大量现有的Web应用中抽取Web交互设计模式不仅有利于软件工程人员开发新的Web应用,而且有利于维护人员对现有Web应用的理解、维护和进化工作。
在面向对象分析领域,一些研究者提出了通过分析源代码抽取可复用的设计模式的方法。在Web应用领域,DiLucca等人提出一种通过分析源代码提取交互设计模式的典型特征,以模式的典型特征为线索恢复Web交互设计模式的方法。但该方法在实际应用中存在以下问题:只能分析英语和意大利语的Web站点,不适用于中文站点的分析;在Web页面中包含相似特征的模式时,模式识别的准确性下降;模式的特征提取粒度比较粗,还需要进一步细化等。
为了解决现有方法所存在的问题,帮助Web开发人员和维护人员提高工作效率,本文提出了一种基于HTML词法分析的Web交互设计模式抽取的改进方法。利用设计的HTML词法分析器将Web客户端页面表示成语法树,抽取Web交互设计模式的典型特征。改进的方法增加了标签属性和属性值的分析,扩展了特征描述性词条的中文语义信息,细化了特征提取的粒度。实验表明改进的方法有效解决了现有方法存在的问题,提高了Web交互设计模式抽取的准确性。
1.现有的交互设计模式的抽取方法
一般认为Web交互设计模式的特征是由用户界面部分的图形内容和词条内容体现的,其中图形内容包括表格、文本输入框、复选框、单选按钮、窗体等:词条内容指描述交互模式功能的文本信息,如留言板、搜索、注册、用户名、密码等文字说明。例如Google搜索网站的用户界面部分如图1所示,该用户界面的搜索功能模式由一个文本输入框和一个显示“Google搜索”的类似按钮的部件组成。经过对大量具有搜索功能网站的用户界面进行分析,一个搜索模式一般至少包括两个特征;一个文本输入框和一个语义为“搜索”的词条。那么Web搜索模式的抽取就可通过检测Web页面中的文本输入框和与关键字“搜索”语义相关的词条等进行识别和抽取。

图1 Google搜索网站的用户界面部分
基于以上思想,Web交互设计模式的抽取就可通过分析源代码,提取可能存在的交互设计模式的特征,然后以这些特征为线索抽取Web页面中所存在的交互设计模式。如图2给出了现有的Web交互设计模式的抽取过程,整个过程分成3个阶段:训练阶段、候选模式识别阶段和验证阶段。
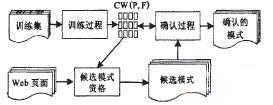
图2 Web交互设计模式的抽取过程
1.1训练阶段
训练阶段需要分析某一交互设计模式的所有可能包含的特征,然后计算这些特征对该模式的刻画程度。
首先在客户端页面中选择一组只包含一种交互模式的页面,并且每个页面中只包含一个被分析模式P的实例,把这个页面集称为训练集TrainingSet(P)。然后提取可表示模式P的所有特征,用Freq(P,f)表示特征,在训练集TrainingSet(P)中出现的频率,Freq(P,f)的计算公式如下
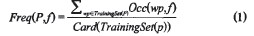
其中,Occ(wp,f)=l时表示Web页面wp包含特f,否则Occ(wp,f)=o;Card(TrainingSet(P))表示训练集TrainingSet(P)的基数。Freq(P,f)的取值范围为【0,l】,当Freq(e,f)=0时表示特征/从未在模式P中出现;Freq(P,f)=1意味着每个模式P都包含特征f。
此外,需考虑每个特征对于给定模式所表现出的特殊属性值spec(P,f)它可以通过计算特征f在每个被分析模式P中出现的频率进行描述。在训练阶段,将所有被分析的交互设计模式的集合称为PattemSet,特征f在模式集PattemSet中出现频率的平均值用AV(F)表示,计算公式如下
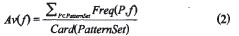
其中,Card(PattemSet)是模式集PattemSet的基数。那么特殊属性值就可以通过以下公式得到
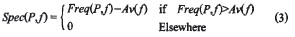
其中,spec(P,f)的取值范围为【0,l】,当Freq(P,f)≤AV(F)时,spec(P,f)=0表示特征f在模式P中出现的频率低于特征f在整个模式集中式集中出现的频率,说明该特征f是模式P的一个可能特征,但不是模式P的典型特征。
一般认为特征,在模式P中出现的频度越高,而在其它模式中出现的频率越低,该特征,就是模式P的典型特征。因此一个特征对给定模式所表现出的典型特征值CW(P,f)为
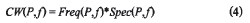
其中CW(P,f)的取值范围为【0,l】,对于模式P,特征f的特殊属性值越大,计算得到的CW(P,f)值最高。
1.2候选模式识别阶段
候选模式识别阶段是利用计算得到的特征刻画值CW(P,f),检测被分析Web页面集中可能存在的模式,主要包括两个步骤:
(1)对每个被分析Web页面和模式集中的模式求似然值为
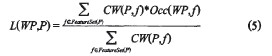
其中,FeatureSet(P)表示满足CW(P,f)>0的特征f的集合;Occ(wp,f)表示特征f是否包含在Web页面WP中,如果包含在WP中,则值为l,否则为0。
(2)识别候选模式;先给定一个阈值,然后将所计算的似然值与给定的阈值进行比较,如果似然值大于阈值则说明Web页面WP中包含模式P,否则不包含模式P。
1.3验证阶段
验证阶段是对所检测到的候选模式进行确认的过程,此过程需要有经验的软件工程人员参与完成。
2.现有方法存在的问题
现有方法通过训练得到模式的典型特征,以这些特征为线索检测Web页面中可能包含的交互设计模式,并在实验中取得了一定成果,但是在实际应用中现有方法存在以下问题:
(1)在特征提取过程中,现有方法利用扩展的WAE(webapplieation reverse engineering)工具,对源代码进行词法和语法分析,抽取Web应用的实体信息及实体之间的关系信息,并未构建抽象语法树。这种方法可能会漏识特征信息或丢失特征之间的关联,存在一定的局限性。当Web页面中包含相似特征的交互设计模式时,模式识别的准确率就会下降,例如在训练阶段,使用现有方法得到的搜索功能模式的特征中CW>0.2的有:

而登录模式的特征中CW>0.2的也有:

如图3所示网页中只包含登录模式,但在模式描述性词条内容中又多次出现关键字“search”,在识别模式时就可能错误地认为该Web页面包含登录模式和搜索模式。
图3 Web页面中交互模式误识的举例
(2)现有方法是针对英语和意大利语网站进行训练和实验分析,并不适用于中文站点,存在一些语义方面的问题,例如具有搜索功能模式的关键字不仅是“search”,可能是“搜索”,也可能是“查询”,还有可能是“百度”或“谷歌”等,在中文站点的搜索模式中,这些关键字都表达了“search”的意思。
(3)现有方法还有一个不足之处是特征的提取粒度不够,这也是造成识别过程中出现错误的原因之一,例如前面提到的搜索功能模式只粗略地提取了4个典型的特征,经过详细地分析可以发现搜索功能模式的典型特征还可以更加细化。
3.现有交互设计模式抽取方法的改进
为了使现有的方法能够抽取中文站点的交互设计模式。提高模式识别的准确性,本文设计了一个HTML词法分析器提取Web交互设计模式的特征,并对特征的词条内容进行了语义扩展,细化了模式的特征抽取粒度。
3.1 HTML词法分析器的实现
在特征提取的实现上,Di Lucca等人使用的是Web逆向工程工具WARE,虽然他们对此工具也做了扩展,但是该工具并不是针对Web交互设计模式特征的抽取而设计的,不能充分挖掘模式中存在的典型特征,存在一定的局限性。本文针对现有交互设计模式在特征抽取方面出现的问题,设计了一个专用于Web交互设计模式特征提取的HTML词法分析器。
在模式训练时,可以发现用户界面中Web交互设计模式的典型特征一般比较聚集,其源代码一般是在一个区段、表格或表单中。如果能定位这个区域的代码,并进行分析,就可以有效提高捕捉特征信息的能力和准确性。
基于此思想,本文设计的HTML词法分析器在对Web页面源代码进行分析时,首先根据HTML标签之间的嵌套关系构建~棵带有元素、属性和文本的语法树。由于标签的属性可以细化模式特征提取的粒度,所以在构建语法树时,如果标签包含属性设置,将其最左孩子结点值设为1,并将标签的属性和属性值作为该结点韵孩子结点,如果没有属性,将最左子树接入一个空节点。然后使用深度优先遍历算法遍历语法树进行特征提取,记录从根结点到叶子结点的路径,按照一定的规则将祖先结点与子孙结点形成一种偏序关系,去除冗余信息后构成候选模式特征集。最后计算候选模式特征集中各元素的CW(p,f)值,提取被分析交互设计模式的典型特征FeatureSet(P
3.2词条语义扩展的实现
汉语是一门语义丰富的语言,一个词语在不同的上下文中所表达的含义也会不同。在Web交互设计模式的抽取过程中,词条内容的准确捕捉和正确理解直接影响着候选模式的判定结果。在训练阶段,本文首先使用HTML词法分析器将出现在被分析模式中的词条内容提取出来,然后根据Word.Net、《同义词词林》和人工参与,将含有不同语义的词条划分到不同的集合中,例如通过词典的辅助可以将“搜索”和“查询”归到一个集合中,而“百度”和“谷歌”与“搜索”不具有同义或近义性,但这两个词在中文站点中也表示了“搜索”的含义,所以需要人工参与将这些特殊语义的词条正确划分。
3.3特征提取的细化
为了提高Web交互设计模式抽取的准确性,本文在现有方法利用HTML词法分析器将Web页面构建成语法树后,使用深度优先遍历算法遍历标签的子树,记录遍历路径,将祖先结点与子孙结点建立偏序关系,计算CW值,将提取的模式特征存储起来。例如经训练得到的搜索功能模式的特征如表1所示。
表1 搜索功能模式特征中CW>0.2的典型特征

3.4实现原型
本文在现有方法的基础上进行了改进,增加了词条内容的语义扩展,用HTML词法分析器取代了工具WARE。图4为改进后的系统框架图,该系统对Web交互设计模式的分析更有针对性,并能有效识剐中文站点中的交互设计模式。
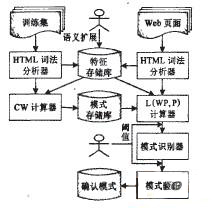
图4 Web交互设计模式抽取系统框架
4.实验结果及分析
为了与现有方法进行对比,本文选取了文献【3】实验中的6种交互设计模式作为被分析模式,被分析模式有登录模式、民意投票模式、注册模式、搜索模式和网站地图模式。每个模式选取15个客户端页面作为训练集;又从不同类型和领域的站点上选取了200个客户端页面作为被分析页面。实验结果是被分析的200个Web页面中包括8个留言板模式、12个登录模式、5个民意投票模式、9个注册模式、9个搜索模式和4个网站地图模式,有一些页面中不包含一个交互设计模式,而有一些页面中同时包含多种交互设计模式。图5给出了现有方法的召回率(原R)和准确率(原P)与改进方法的召回率(改R)和准确率(改P)的对比图表。通过对比图表可以看出改进的方法明显优于原方法。
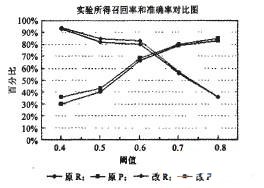
图5 实验测试得到的召回率和准确率
5.结束语
为了帮助Web应用的开发人员和维护人员对Web交互设计模式的更好应用和理解,提高工作效率,本文针对Di
Licca等人提出的Web交互设计模式的抽取方法中存在的问题,提出了一种改进方法,设计了一个HTML词法分析器,将Web客户端页面表示成语法树,通过对语法树的遍历抽取交互设计模式的特征,细化了特征抽取的粒度,扩展了特征描述性词条的语义。通过实验分析表明该方法能有效识别中文站点包含的交互设计模式,提高了识别的准确性,且明显优于现有方法。
| 

