如何提高代码质量,相信不仅是在座所有人苦恼的事情,也是所有软件项目苦恼的事情。如何提高代码质量呢,我认为我们首先要理解什么是高质量的代码。
高质量代码的三要素
我们评价高质量代码有三要素:可读性、可维护性、可变更性。我们的代码要一个都不能少地达到了这三要素的要求才能算高质量的代码。
1.可读性强
一提到可读性似乎有一些老生常谈的味道,但令人沮丧的是,虽然大家一而再,再而三地强调可读性,但我们的代码在可读性方面依然做得非常糟糕。由于工作的需要,我常常需要去阅读他人的代码,维护他人设计的模块。每当我看到大段大段、密密麻麻的代码,而且还没有任何的注释时常常感慨不已,深深体会到了这项工作的重要。由于分工的需要,我们写的代码难免需要别人去阅读和维护的。而对于许多程序员来说,他们很少去阅读和维护别人的代码。正因为如此,他们很少关注代码的可读性,也对如何提高代码的可读性缺乏切身体会。有时即使为代码编写了注释,也常常是注释语言晦涩难懂形同天书,令阅读者反复斟酌依然不明其意。针对以上问题,我给大家以下建议:
1)不要编写大段的代码
如果你有阅读他人代码的经验,当你看到别人写的大段大段的代码,而且还不怎么带注释,你是怎样的感觉,是不是“嗡”地一声头大。各种各样的功能纠缠在一个方法中,各种变量来回调用,相信任何人多不会认为它是高质量的代码,但却频繁地出现在我们编写的程序了。如果现在你再回顾自己写过的代码,你会发现,稍微编写一个复杂的功能,几百行的代码就出去了。一些比较好的办法就是分段。将大段的代码经过整理,分为功能相对独立的一段又一段,并且在每段的前端编写一段注释。这样的编写,比前面那些杂乱无章的大段代码确实进步了不少,但它们在功能独立性、可复用性、可维护性方面依然不尽人意。从另一个比较专业的评价标准来说,它没有实现低耦合、高内聚。我给大家的建议是,将这些相对独立的段落另外封装成一个又一个的函数。
许多大师在自己的经典书籍中,都鼓励我们在编写代码的过程中应当养成不断重构的习惯。我们在编写代码的过程中常常要编写一些复杂的功能,起初是写在一个类的一个函数中。随着功能的逐渐展开,我们开始对复杂功能进行归纳整理,整理出了一个又一个的独立功能。这些独立功能有它与其它功能相互交流的输入输出数据。当我们分析到此处时,我们会非常自然地要将这些功能从原函数中分离出来,形成一个又一个独立的函数,供原函数调用。在编写这些函数时,我们应当仔细思考一下,为它们取一个释义名称,并为它们编写注释(后面还将详细讨论这个问题)。另一个需要思考的问题是,这些函数应当放到什么地方。这些函数可能放在原类中,也可能放到其它相应职责的类中,其遵循的原则应当是“职责驱动设计”(后面也将详细描述)。
下面是我编写的一个从XML文件中读取数据,将其生成工厂的一个类。这个类最主要的一段程序就是初始化工厂,该功能归纳起来就是三部分功能:用各种方式尝试读取文件、以DOM的方式解析XML数据流、生成工厂。而这些功能被我归纳整理后封装在一个不同的函数中,并且为其取了释义名称和编写了注释:
?Java代码
/**
* 初始化工厂。根据路径读取XML文件,将XML文件中的数据装载到工厂中
* @param path XML的路径
*/
public void initFactory(String path){
if(findOnlyOneFileByClassPath(path)){return;}
if(findResourcesByUrl(path)){return;}
if(findResourcesByFile(path)){return;}
this.paths = new String[]{path};
}
/**
* 初始化工厂。根据路径列表依次读取XML文件,将XML文件中的数据装载到工厂中
* @param paths 路径列表
*/
public void initFactory(String[] paths){
for(int i=0; i<paths.length; i++){
initFactory(paths[i]);
}
this.paths = paths;
}
/**
* 重新初始化工厂,初始化所需的参数,为上一次初始化工厂所用的参数。
*/
public void reloadFactory(){
initFactory(this.paths);
}
/**
* 采用ClassLoader的方式试图查找一个文件,并调用<code>readXmlStream()</code>进行解析
* @param path XML文件的路径
* @return 是否成功
*/
protected boolean findOnlyOneFileByClassPath(String
path){
boolean success = false;
try {
Resource resource = new ClassPathResource(path, this.getClass());
resource.setFilter(this.getFilter());
InputStream is = resource.getInputStream();
if(is==null){return false;}
readXmlStream(is);
success = true;
} catch (SAXException e) {
log.debug("Error when findOnlyOneFileByClassPath:"+path,e);
} catch (IOException e) {
log.debug("Error when findOnlyOneFileByClassPath:"+path,e);
} catch (ParserConfigurationException e) {
log.debug("Error when findOnlyOneFileByClassPath:"+path,e);
}
return success;
}
/**
* 采用URL的方式试图查找一个目录中的所有XML文件,并调用<code>readXmlStream()</code>进行解析
* @param path XML文件的路径
* @return 是否成功
*/
protected boolean findResourcesByUrl(String path){
boolean success = false;
try {
ResourcePath resourcePath = new PathMatchResource(path,
this.getClass());
resourcePath.setFilter(this.getFilter());
Resource[] loaders = resourcePath.getResources();
for(int i=0; i<loaders.length; i++){
InputStream is = loaders[i].getInputStream();
if(is!=null){
readXmlStream(is);
success = true;
}
}
} catch (SAXException e) {
log.debug("Error when findResourcesByUrl:"+path,e);
} catch (IOException e) {
log.debug("Error when findResourcesByUrl:"+path,e);
} catch (ParserConfigurationException e) {
log.debug("Error when findResourcesByUrl:"+path,e);
}
return success;
}
/**
* 用File的方式试图查找文件,并调用<code>readXmlStream()</code>解析
* @param path XML文件的路径
* @return 是否成功
*/
protected boolean findResourcesByFile(String path){
boolean success = false;
FileResource loader = new FileResource(new File(path));
loader.setFilter(this.getFilter());
try {
Resource[] loaders = loader.getResources();
if(loaders==null){return false;}
for(int i=0; i<loaders.length; i++){
InputStream is = loaders[i].getInputStream();
if(is!=null){
readXmlStream(is);
success = true;
}
}
} catch (IOException e) {
log.debug("Error when findResourcesByFile:"+path,e);
} catch (SAXException e) {
log.debug("Error when findResourcesByFile:"+path,e);
} catch (ParserConfigurationException e) {
log.debug("Error when findResourcesByFile:"+path,e);
}
return success;
}
/**
* 读取并解析一个XML的文件输入流,以Element的形式获取XML的根,
* 然后调用<code>buildFactory(Element)</code>构建工厂
* @param inputStream 文件输入流
* @throws SAXException
* @throws IOException
* @throws ParserConfigurationException
*/
protected void readXmlStream(InputStream inputStream)
throws SAXException, IOException, ParserConfigurationException{
if(inputStream==null){
throw new ParserConfigurationException("Cann't
parse source because of InputStream is null!");
}
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setValidating(this.isValidating());
factory.setNamespaceAware(this.isNamespaceAware());
DocumentBuilder build = factory.newDocumentBuilder();
Document doc = build.parse(new InputSource(inputStream));
Element root = doc.getDocumentElement();
buildFactory(root);
}
/**
* 用从一个XML的文件中读取的数据构建工厂
* @param root 从一个XML的文件中读取的数据的根
*/
protected abstract void buildFactory(Element root);
完整代码在附件中。在编写代码的过程中,通常有两种不同的方式。一种是从下往上编写,也就是按照顺序,每分出去一个函数,都要将这个函数编写完,才回到主程序,继续往下编写。而一些更有经验的程序员会采用另外一种从上往下的编写方式。当他们在编写程序的时候,每个被分出去的程序,可以暂时只写一个空程序而不去具体实现功能。当主程序完成以后,再一个个实现它的所有子程序。采用这样的编写方式,可以使复杂程序有更好的规划,避免只见树木不见森林的弊病。
有多少代码就算大段代码,每个人有自己的理解。我编写代码,每当达到15~20行的时候,我就开始考虑是否需要重构代码。同理,一个类也不应当有太多的函数,当函数达到一定程度的时候就应该考虑分为多个类了;一个包也不应当有太多的类。。。。。。
2)释义名称与注释
我们在命名变量、函数、属性、类以及包的时候,应当仔细想想,使名称更加符合相应的功能。我们常常在说,设计一个系统时应当有一个或多个系统分析师对整个系统的包、类以及相关的函数和属性进行规划,但在通常的项目中这都非常难于做到。对它们的命名更多的还是程序员来完成。但是,在一个项目开始的时候,应当对项目的命名出台一个规范。譬如,在我的项目中规定,新增记录用new或add开头,更新记录用edit或mod开头,删除用del开头,查询用find或query开头。使用最乱的就是get,因此我规定,get开头的函数仅仅用于获取类属性。
注释是每个项目组都在不断强调的,可是依然有许多的代码没有任何的注释。为什么呢?因为每个项目在开发过程中往往时间都是非常紧的。在紧张的代码开发过程中,注释往往就渐渐地被忽略了。利用开发工具的代码编写模板也许可以解决这个问题。
用我们常用的MyEclipse为例,在菜单“window>>Preferences>>Java>>Code
Style>>Code Templates>>Comments”中,可以简单的修改一下。
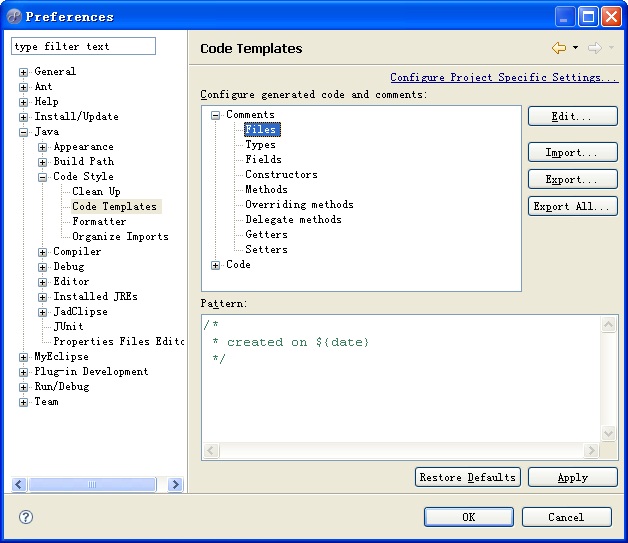
“Files”代表的是我们每新建一个文件(可能是类也可能是接口)时编写的注释,我通常设定为:
/*
* created on ${date}
*/
“Types”代表的是我们新建的接口或类前的注释,我通常设定为:
/**
*
* @author ${user}
*/
第一行为一个空行,是用于你写该类的注释。如果你采用“职责驱动设计”,这里首先应当描述的是该类的职责。如果需要,你可以写该类一些重要的方法及其用法、该类的属性及其中文含义等。
${user}代表的是你在windows中登陆的用户名。如果这个用户名不是你的名称,你可以直接写死为你自己的名称。
其它我通常都保持为默认值。通过以上设定,你在创建类或接口的时候,系统将自动为你编写好注释,然后你可以在这个基础上进行修改,大大提高注释编写的效率。
同时,如果你在代码中新增了一个函数时,通过Alt+Shift+J快捷键,可以按照模板快速添加注释。
在编写代码时如果你编写的是一个接口或抽象类,我还建议你在@author后面增加@see注释,将该接口或抽象类的所有实现类列出来,因为阅读者在阅读的时候,寻找接口或抽象类的实现类比较困难。
/**
* 抽象的单表数组查询实现类,仅用于单表查询
* @author 范钢
* @see com.htxx.support.query.DefaultArrayQuery
* @see com.htxx.support.query.DwrQuery
*/
public abstract class ArrayQuery implements ISingleQuery
{
...
2.可维护性
软件的可维护性有几层意思,首先的意思就是能够适应软件在部署和使用中的各种情况。从这个角度上来说,它对我们的软件提出的要求就是不能将代码写死。
1)代码不能写死
我曾经见我的同事将系统要读取的一个日志文件指定在C盘的一个固定目录下,如果系统部署时没有这个目录以及这个文件就会出错。如果他将这个决定路径下的目录改为相对路径,或者通过一个属性文件可以修改,代码岂不就写活了。一般来说,我在设计中需要使用日志文件、属性文件、配置文件,通常都是以下几个方式:将文件放到与类相同的目录,使用ClassLoader.getResource()来读取;将文件放到classpath目录下,用File的相对路径来读取;使用web.xml或另一个属性文件来制定读取路径。
我也曾见另一家公司的软件要求,在部署的时候必须在C:/bea目录下,如果换成其它目录则不能正常运行。这样的设定常常为软件部署时带来许多的麻烦。如果服务器在该目录下已经没有多余空间,或者已经有其它软件,将是很挠头的事情。
2)预测可能发生的变化
除此之外,在设计的时候,如果将一些关键参数放到配置文件中,可以为软件部署和使用带来更多的灵活性。要做到这一点,要求我们在软件设计时,应当更多地有更多的意识,考虑到软件应用中可能发生的变化。比如,有一次我在设计财务软件的时候,考虑到一些单据在制作时的前置条件,在不同企业使用的时候,可能要求不一样,有些企业可能要求严格些而有些要求松散些。考虑到这种可能的变化,我将前置条件设计为可配置的,就可能方便部署人员在实际部署中进行灵活变化。然而这样的配置,必要的注释说明是非常必要的。
软件的可维护性的另一层意思就是软件的设计便于日后的变更。这一层意思与软件的可变更性是重合的。所有的软件设计理论的发展,都是从软件的可变更性这一要求逐渐展开的,它成为了软件设计理论的核心。 | 

