|
项目起源
在日常的开发过程中,功能总是先于性能被考虑。只有当用户抱怨系统性能时,我们才开始头痛医头,脚痛医脚地来解决这些性能问题。
公司的CRM和ERP系统叫作Olite,完全是我们组开发的。从无到有,功能不断扩展,原先只有CRM模块,后来加入了ERP模块,Accounting功能和Report功能。近来出现的情况是当某些用户跑一个大Report时,正在进行业务操作的用户感觉系统响应非常慢。通过对系统的性能监视发现,在这些时刻,数据库中产生了大量的锁,同时服务器上出现了CPU和内存资源消耗的尖峰。
系统结构
性能问题源于系统的整体结构和发展过程。Olite系统的Application是基于.NET平台的Web
Form程序,数据库为SQL Server 2005。其主体结构如下图所示:
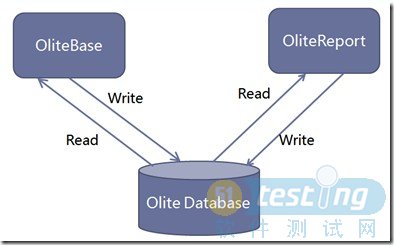
其Application端包括两个网站:OliteBase和OliteReport,但连接的都是同一个数据库。
Olite的Application端其实很薄,而把大量的业务逻辑包装在存储过程中,放在数据库端来运行。
这种结构在起初性能很好,而且提供给用户的Report是实时的业务数据。但随着提供的业务模块,特别是Report的增多(Report对应的存储过程连接的表多,计算量大,输出的结果集大),数据库就成为了瓶颈。
首先,我们做了存储过程的优化,通过创建Trace捕获性能差的存储过程,并对其进行优化。我们这么做了一段时间,但获得的收效并不大。我们在优化以往存储过程的同时,随着系统新功能的上线,又有新的存储过程进入需要优化的列表中。
其次,修改数据库设计,其中包括修改表结构和优化索引。在系统局部重构表结构与关系对于性能的提升还是比较明显的,但这样的修改会造成Application端的大量修改,工作量大,风险大,所以不能大规模实施。对于索引优化又存在矛盾,业务模块(OliteBase)要求数据库中的索引不要太多,以支持高效的插入、修改和删除,而报表模块(OliteReport)则希望在数据库中有更多的索引,以支持高效读。
最后,我们还试图提供晚一天的Report服务,来分流主数据库的压力。每天通过把前一天的备份数据库恢复在另一台服务器上,并在此服务器上提供OliteReport2站点,给用户提供Report服务。但用户并不喜欢使用OliteReport2,原因分析下来有3个方面:其一,有时用户确实需要实时的Report。其二,OliteReport能存储用户的Report条件,而OliteReport2由于每天都会被刷新,无法保留这些条件。其三,用户更习惯打开原来的Report链接。
项目需求
上述的各种优化方案都没有根本性的解决系统的性能问题。在这种的背景下我们有了把报表数据库与业务数据库分离的想法。
此项目的需求:
- 1. 提高用户对整个系统性能的感受,Report模块不要影响到业务模块的运行。
- 2. 用户可以和原先一样使用Report模块,即不增加新的Report站点。
- 3. 用户可以和原先一样存储填写的Report条件,以供重复使用。
- 4. 尽可能提供最小延时的Report。
需求1是这个项目的主要目标,需求2、3、4是尽可能保证项目所带来的改变对用户是透明的。
方案选择
对于原来的系统结构,其Application端已经是两个独立的站点OliteBase和OliteReport。所以只要把OliteBase和OliteReport的数据库进行分离,在分离后的两数据库间进行数据的同步就行了。这里的关键在于如何进行数据库间的同步。
微软提供了很多种数据同步的选择:1.集群;2.Log Shipping;3.Replication;4.Mirror;5.Integration
Service。
微软提供的这些方案中大部分都是用于做数据库的高可用性的,而我们的项目是以高性能为目标的。为了满足我们自己的需求,应选择那种方案,并做哪些修改呢?
1.集群
这是第一个被我们否决的方案。配置SQL Server数据库集群,对硬件有较多限制,而且配置相对其他方案复杂。我们的项目总共的服务器资源就两台,除原先主数据库服务器外,另一台是虚拟机。
2.Log Shipping
Log Shipping把主数据库的日志传送到从数据库,并在从数据库上进行回放来保证主、从数据库间数据的一致,从数据库为只读。Log
Shipping而且还有配置简单的特点,开始时是我们的一个候选方案,但在进一步的实验过程中发现了两个问题。第一、Log
Shipping可设置的时间间隔最小单位为分钟。第二、当从数据库进行日志回放时,连接此数据库的连接需要被断开。其中第二个问题是难以容忍的,这个方案也被淘汰了。
3.Replication
Replication的原理和Log Shipping有些相似,但其提供了更多的灵活性。Replication可以只多主数据库的一些表、函数或存储过程进行,甚至可以对某些符合条件的记录进行。除此之外,其复制出来的数据库可写,而且复制的最小时间间隔可配置为concurrent(测试下来的时间延迟为秒级别),而且其配置也较为简单。经过一些实验,我们最后选择了它。后面会对其原理和配置进一步讨论。
4.Mirror
Mirror是SQL Server 2005提供的强大的高可用性方案。其镜像数据库不能直接读取,这和我们的需求场景不符合,所以被否了。
5.Integration Service
Integration Service具有最大的灵活性,其可以为数据仓库进行数据抽取,转换和装载。但使用Integration
Service需要有大量的开发与测试工作,所以我们也没选用。
Replication方案细分
Replication方案又可以分为Snapshot Replication, Transactional
Replication, Peer-2-Peer Replication, Merge Replication。
Snapshot Replication:一般用于对于数据库的一次性的完全复制。
Transactional Replication:用于主数据库向从数据库的单向复制。
Peer-2-Peer Replication:能进行二个或多个数据库之间的互相复制,即从数据库也能向主数据库复制,这个功能很强大,但可能会引起冲突,需要特别关注保证各库的数据完整性。
Merge Replication:可以把多个数据库中的数据进行合并后,复制到目标数据库。
对于我们的需求,我们选用了最单纯的Transactional Replication。
Transactional Replication原理
在Transactional Replication中有3个角色:Publisher(发布者),
Distributor(分发者), Subscriber(订阅者)。其逻辑图如下:
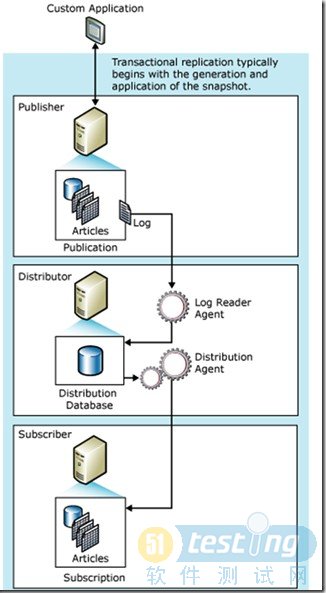
在进行增量的Transactional Replication之前,Subscriber需要进行初始化,使其包含和Publisher一样的表结构和初始数据。
Transactional Replication启动之后,Distributor上的Log
Reader Agent会将读取Publisher的Log信息,并分拣出被标识为replication的INSERT,
UPDATE, DELETE语句。此后复制这些Transaction到Distributor,并写入distribution数据库。最后Distribution
Agent把Distributor上的Transaction运送到Subscriber进行重放。
注意:在图中Distribution Agent运行在Distributor上,这是在push(推)模式下的情况。可以配置为pull(拉)模式,Distribution
Agent将运行在Subscriber上。
项目中的配置与考量
在前文的系统结构小节,给出了原先的系统结构。我们希望通过这次的项目得到如下所示的系统结构:
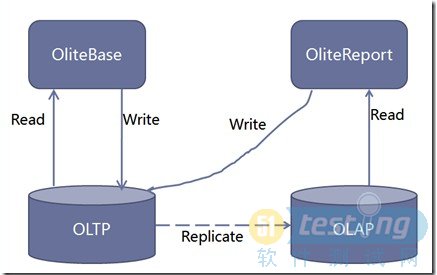
OliteReport能连接到一个由主数据库复制出的单独数据库上,这样这两个库之间的锁就被隔离了。同时主数据库与从数据库安排在两台服务器上(项目中我们把复制出的数据库放在了一台虚拟机上),那么CPU资源与内存资源的消耗也被隔离了。需要注意的是图中OliteReport除了主要的读操作外,还有少量的写操作(这是因为用户可以存储Report条件)。我们把这些写指回主数据库,从数据库在下一时刻的复制中得到这些数据。
在Transactional Replication中有三个逻辑角色,而项目中只有两台服务器。我们如何来安排这三个逻辑角色呢?
● 候选的方案有两种:1.主数据库上配置Publisher和Distributor,从数据库上配置Subscriber;2.主数据库上只配置Publisher,从数据库上配置Distributor和Subscriber。矛盾的焦点是Distributor放哪里?需要指出的是Distributor对于Replication非常重要,这个角色承担着从主数据库抓取Transaction的工作,在Push模式下,它还需要负责把Transaction推送到个Subscriber。这些工作都会消耗所在服务器的CPU和内存资源。我们的项目希望尽可能保证业务模块的性能,所以我们选用了方案2,把Distributor配置在从数据库上。
我们是选用Push模式还是Pull模式呢?
● Push和Pull其实是针对Distributor传送Transaction到Subscriber的方式而言的(这点我是很后面才认识到的,开始一直认为Push或Pull会影响Distributor抓取Publisher上的信息,其实不然)。对于Distributor和Subscriber在一台服务器上,这两种模式的效果基本一样。我们选择了Pull模式,即Distribution
Agent运行在Subscriber端从Distributor拉Transaction数据。这是为了将来扩展考虑,如果以后再加一台服务器来作为Subscriber时,Distributor不会增加太多的性能压力。
另一个需要考虑的问题是复制些什么?
● Transactional Replication可以选择复制哪些表、存储过程或函数等内容。最简单的是把整个数据库中的所以元素都进行复制,但这会造成Replication服务所要监视的对象很多,同时网络上传输的信息量也很大。项目中我们最后决定只复制所有的表,这样做是出去性能的考虑。这样做会对将来的release产生影响,需要注意,下文会进行讨论。
还有一个需要考虑的是如何进行从数据库的初始化?
● 在Transactional Replication开始之前,首先要对从数据库进行初始化,使其获得与主数据库一致的表结构和初始数据。在配置Transactional
Replication中会有一个选项来进行初始化(由Snapshot Agent完成)。但在我们的实验中初始化耗费了几个小时,所以我们没有使用Transactional
Replication默认的初始化方式,而是通过数据库备份还原来完成初始化,要这样做就需要改变配置的一些选项,下文还会涉及。
Transactional Replication有些什么前提条件?
● 数据库的Compatibility level(兼容性等级)需要达到SQL Server
2005(90)(我们使用的是SQL Server 2005,当兼容性级别为80时,配置过程中会出现异常)。
● 数据库的Recovery model(恢复模式)需要是Full(完整)。
● 所有需要Replicate的表必须具有主键。(这应该是理所当然的,但在这次配置中竟然发现一些非常“可耻”的东西)
● 存储过程或其他脚本中,不能对进行Replicate的表进行truncate,需把相应存储过程中的语句改为delete。这是因为Replication是基于对Log的抓取与解析,但truncate不产生Log。
● 如果Replicate的元素还包括存储过程或函数,还会有其他一些前提条件,我们不在这里展开,可以查看msdn。
如何来配置Transactional Replication?
● 微软提供了非常易用的图形化界面可以进行Replication的配置。但图形化配置的灵活性是有限的,有些配置选项在图形化界面下无法完成。我的建议是先用图形化配置Replication,并生成相应的script。此后根据需求修改script,并用script进行配置。在我们的项目中也是这么做的。
● 默认的情况下,Distributor服务器的D:\Program Files\Microsoft
SQL Server\MSSQL.1\MSSQL\repldata会存放replicate数据。由于我们要支持Pull模式,需要共享这一文件夹,并给此文件夹设置一个具有Full
Control权限的域账户。并把此域账户设置为Subscriber服务器上SQL Server Agent服务的运行账户,此服务同时需要被设为Automatic启动方式。在sp_adddistpublisher的@working_directory参数设为此共享目录的网络路径。
● 配置Publisher时,sp_addpublication的参数@sync_method
= N'concurrent', @repl_freq = N'continuous'保证了Replicate能尽可能实时;@allow_initialize_from_backup
= N’true’表示通过备份还原来进行从数据库的初始化。
● 配置Subscriber时,sp_addsubscription的参数@sync_type
= N'replication support only'表示从数据库的初始化完全由外部来完成;@subscription_type
= N'pull'表示使用拉模式。
后期维护
如何监视Replication的性能与异常?
● 微软提供了Replication Monitor。这个工具还是比较好用的,可以查看到Publication和Subscription的状态,还能查看到当前有多少Transaction等待传送。
● Transactional Replication设置好后,Distributor上将自动生成相关的多个Alerts,如:Replication
Warning: Subscription expiration (Threshold: expiration),Replication
Warning: Transactional replication latency (Threshold:
latency)等。可以将这些Alerts与Database Mail进行绑定。当出现警告时,自动发出邮件。(此功能虽然在项目中配置了,但从未正常发出警告邮件,一直不知道为什么,如果有人知道的话可以联系我)。
如何进行以后的Release?
● 原先数据库的Release一般会分为三部分:1.表结构的变化(包括加/删表,加/删列);2.配置数据的装载(如添加新功能的配置数据);3.刷函数与存储过程脚本。
● 对于本项目中的Replication数据库,在Release过程中需注意以下几点:1.若新加的表需要进行Replication,除了在主数据库创建表之外,还需配置此表进行Replicate,并进行初始化。2.若要删除某处于Replication的表,需先取消此表的Replication,再在主、从库中drop此表。3.若需要加/删Replication表的列(此列不能为主键列)时,可以直接在主数据库上执行脚本,变化会自动Replicate到从数据库。4.配置数据的装载也只需要在主数据库完成。5.函数与存储过程需要在主、从库上都进行刷新。
总结与设想
此项目已经上线,基本达到了需求所提出的目标,但这只是开始,优化后的结构给将来系统的扩展提供了一个基础。
● 通过实验发现,在主/从数据库上可以创建不同的索引而不互相干扰(这和Replication的配置相关)。这就可以根据主、从数据库不同的使用模式,创建更优化的索引。我曾在国外某Blog上看到,利用SQL
Server 2005的动态视图,自动根据数据库的使用模式来创建索引,就像自适应索引机一样。这也是我将在OliteReport数据库上做的事。
● 将来如果有了多个Subscriber数据库,还能做OliteReport的数据库Load
Balance。当有Report请求时,系统首先查看各个Subscriber的CPU和Memory的Load,选择Load较轻的Subscriber接受Report请求。
● 我们还能利用Replicate出的数据库进行BI(商业智能)分析与挖掘,而不会影响到主数据库的运行。 | 