| БрМЭЦМі: |
БОЮФДгЕзВуПЊЪМНщЩмаГЬ,ШчКЮНЈСЂдкАВШЋгааЇЕиЖд
RESTful ЗўЮёНјааЖрДЮЕїгУЕФЙцЗЖадЃЌЯЃЭћФмЖдФњгаЫљАяжњЁЃ
БОЮФРДздгкInfoQЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
БОЮФвЊЕу
JVM ВЂУЛгаЬсЙЉЖдаГЬЕФдЩњжЇГж
Kotlin дкБрвыЦїжаЪЕЯжаГЬЪЧЭЈЙ§НЋЦфзЊЛЛЮЊвЛИізДЬЌЛњЪЕЯжЕФ
Kotlin ЮЊЪЕЯжЪЙгУСЫвЛИіЙиМќзжЃЌЦфгрЖМЪЧЭЈЙ§ПтРДЭъГЩЕФ
Kotlin ЪЙгУСЌајДЋЕнЗчИёЃЈContinuation Passing StyleЃЌCPSЃЉРДЪЕЯжаГЬ
аГЬЛсЪЙгУЕН DispatcherЃЌЫљвддк JavaFXЁЂAndroidЁЂSwing ЕШГЁОАЯТЃЌгУЗЈТдгаВювьЁЃ
ОЁЙмаГЬВЂВЛЪЧвЛИіаТЕФЛАЬтЃЌЕЋЫќЪЧвЛИіКмЮќв§ШЫЕФЛАЬтЁЃе§ШчЦфЫћЕиЗНЕФЮФЕЕЫљЪіЃЌаГЬдкетаЉФъРяБЛжиаТЗЂЯжСЫКмЖрДЮЃЌЬиБ№ЪЧЕБашвЊФГжжаЮЪНЕФЧсСПМЖЯпГЬКЭ
/ ЛђбАевЁАЛиЕїЕигќЁБЕФНтОіЗНАИЪБЁЃ
зюНќЃЌаГЬвбОГЩЮЊ JVM ЩЯЗДгІЪНБрГЬЕФвЛИіСїааЕФЬцДњЗНАИЁЃЯё RxJava Лђ Reactor
ЯюФПетбљЕФПђМмЮЊПЭЛЇЖЫЬсЙЉСЫвЛжжНЅНјЪНДІРэДЋШыаХЯЂЕФЗНЪНЃЌВЂЖдНкСїКЭВЂааЬсЙЉСЫЙуЗКЕФжЇГжЁЃЕЋЪЧЃЌЮвУЧБиаыЮЇШЦЗДгІСїЕФКЏЪ§ЪНВйзїРДжиЙЙДњТыЃЌдкаэЖрЧщПіЯТЃЌетУДзіЕФГЩБОДѓгкЪевцЁЃ
ОйР§РДНВЃЌетЪЧ Android ЩчЧјашвЊИќМђЕЅЬцДњЗНАИЕФдвђЁЃKotlin гябдв§ШыаГЬзїЮЊЪЕбщадЕФЬиадвдТњзуИУашЧѓЃЌдквЛаЉИФНјжЎКѓЃЌЫќУЧГЩЮЊИУгябд
1.3 АцБОЕФЙйЗНЬиадЁЃKotlin аГЬЕФгІгУвбОДг UI ПЊЗЂРЉеЙЕНЗўЮёЦїЖЫПђМм (Шч Spring
5 жаЬэМгЕФжЇГж)ЃЌЩѕжСАќРЈЯё Arrow(ЭЈЙ§ Arrow Fx ) етбљЕФКЏЪ§ЪНПђМмЁЃ
РэНтаГЬЕФЬєеН
СюШЫвХКЖЕФЪЧЃЌРэНтаГЬВЂВЛЪЧвЛМўШнвзЕФШЮЮёЁЃОЁЙмгааэЖр Kotlin зЈМвЫљзіЕФЙигкаГЬЕФбнНВЃЌЦфжаКмЖрЖМЪЧЦєЗЂадЕФВЂЧвАќКЌЗЧГЃЖрЕФаХЯЂЃЌЕЋЪЧЯывЊМђЕЅЕижЊЕРаГЬЪЧЪВУДЃЈЛђепЫќИУдѕбљЪЙгУЃЉВЂВЛШнвзЁЃФуПЩФмЛсЫЕаГЬОЭЪЧВЂааБрГЬЕФЕШМлЦЗЁЃ
ЕМжТИУЮЪЬтЕФВПЗждвђдкгкЕзВуЪЕЯжЁЃдк Kotlin аГЬжаЃЌБрвыЦїжЛЪЕЯжСЫвЛИіsuspendЙиМќзжЃЌЦфЫћЕФЪТЧщЖМЪЧгЩаГЬПтДІРэЕФЁЃвђДЫЃЌKotlin
аГЬЗЧГЃЧПДѓКЭСщЛюЃЌЕЋдкНсЙЙЩЯШДВЛФЧУДЙЬЖЈЁЃЖдгкГѕбЇепРДЫЕЃЌетЪЧвЛИібЇЯАЕФеЯАЃЌвђЮЊЫћУЧбЇЯАЕФзюКУЗНЗЈЪЧзёбМсЪЕЕФжИЕМЗНеыКЭбЯИёЕФддђЁЃБОЮФЛсДгЕзВуПЊЪМНщЩмаГЬЃЌЯЃЭћФмЙЛЮЊЖСепЬсЙЉетбљЕФЛљДЁжЊЪЖЁЃ
ЮвУЧЕФЪОР§гІгУЃЈЗўЮёЦїЖЫЃЉ
ЮвУЧЕФгІгУГЬађНЋНЈСЂдкАВШЋгааЇЕиЖд RESTful ЗўЮёНјааЖрДЮЕїгУЕФЙцЗЖадЃЈcanonicalЃЉЮЪЬтжЎЩЯЁЃЮвУЧНЋВЅЗХ
WhereЁЏs Waldo ЕФвЛИіЮФБОАцБОЁЊЁЊдкетИіАцБОжаЃЌгУЛЇзёбвЛЯЕСаЕФУћГЦЃЌжБЕНЫћУЧевЕНЁАWaldoЁБЁЃ
ЯТУцЪЧЭъећЕФ RESTful ЗўЮёЃЌЫќЪЧЪЙгУ Http4k БраДЕФЁЃHttp4k ЪЧгЩ Marius
Eriksen зЋаДЕФжјУћТлЮФжаУшЪіЕФКЏЪ§ЪНЗўЮёЦїМмЙЙЕФKotlin АцБОЁЃИУЪЕЯжДцдкаэЖрЦфЫћгябдЕФАцБОЃЌАќРЈScalaЃЈ
Http4s ЃЉКЭ Java 8 ЛђИќИпАцБОЃЈ Http4j ЃЉЁЃ
етРяжЛгавЛИіЖЫЕуЃЌЫќЭЈЙ§ Map ЪЕЯжСЫвЛИіУћзжЕФСДЁЃИјЖЈвЛИіУћзжЃЌЮвУЧвЊУДвд
200 зДЬЌТыЗЕЛиЦЅХфЕФжЕЃЌвЊУДвд 404 зДЬЌТыЗЕЛивЛЬѕДэЮѓаХЯЂЁЃ
fun main() {
val names = mapOf(
"Jane" to "Dave",
"Dave" to "Mary",
"Mary"
to "Pete",
"Pete" to "Lucy",
"Lucy" to "Waldo"
)
val lookupName = { request: Request ->
val name = request.path("name")
val headers = listOf("Content-Type"
to "text/plain")
val result = names[name]
if (result != null) {
Response(OK)
.headers(headers)
.body(result)
} else {
Response(NOT_FOUND)
.headers(headers)
.body("No match for $name")
}
}
routes(
"/wheresWaldo" bind routes(
"/{name:.*}" bind Method.GET to lookupName
)
).asServer(Netty(8080))
.start()
} |
ЪЕМЪЩЯЃЌЮвУЧЯЃЭћПЭЛЇЖЫЗЂЫЭШчЯТЕФЧыЧѓСД:

ЮвУЧЕФЪОР§гІгУЃЈПЭЛЇЖЫЃЉ
ЮвУЧЕФПЭЛЇЖЫгІгУНЋЛсЛљгк JavaFX ПтРДДДНЈгУЛЇНчУцЁЃЕЋЪЧЃЌЮЊСЫМђЛЏЮвУЧЕФШЮЮёВЂБмУтВЛБивЊЕФЯИНкЃЌЮвУЧНЋЛсЪЙгУ
TornadoFX ЃЌЫќдк JavaFX жЎЩЯЬсЙЉСЫвЛИі Kotlin DSLЁЃ
ШчЯТЪЧПЭЛЇЖЫЪгНЧЕФЭъећЖЈвхЃК
class HelloWorldView:
View("Coroutines Client UI") {
private val finder: HttpWaldoFinder by inject()
private val inputText = SimpleStringProperty("Jane")
private val resultText = SimpleStringProperty("")
override val root = form {
fieldset("Lets Find Waldo") {
field("First Name:") {
textfield().bind(inputText)
button("Search") {
action {
println("Running event handler".addThreadId())
searchForWaldo()
}
}
}
field("Result:") {
label(resultText)
}
}
}
private fun searchForWaldo() {
GlobalScope.launch(Dispatchers.Main) {
println("Doing Coroutines".addThreadId())
val input = inputText.value
val output = finder.wheresWaldo(input)
resultText.value = output
}
}
}class HelloWorldView: View("Coroutines Client
UI") { private val finder: HttpWaldoFinder
by inject() private val inputText = SimpleStringProperty("Jane")
private val resultText = SimpleStringProperty("")
override val root = form { fieldset("Lets
Find Waldo") { field("First Name:")
{ textfield().bind(inputText) button("Search")
{ action { println("Running event handler".addThreadId())
searchForWaldo() } } } field("Result:")
{ label(resultText) } } } private fun searchForWaldo()
{ GlobalScope.launch(Dispatchers.Main) { println("Doing
Coroutines".addThreadId()) val input = inputText.value
val output = finder.wheresWaldo(input) resultText.value
= output } } |
ЮвУЧЛЙЛсЪЙгУШчЯТЕФИЈжњКЏЪ§зїЮЊ String РраЭЕФРЉеЙЃК
| fun String.addThreadId()
= "$this on thread ${Thread.currentThread().id}" |
дкдЫааЕФЪБКђЃЌUI ШчЯТЫљЪОЃК
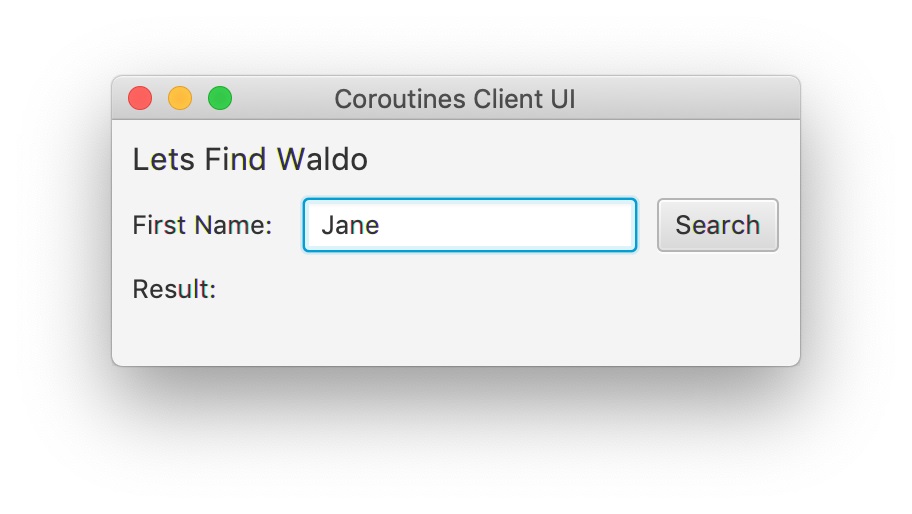
ЕБгУЛЇЕуЛїАДХЅЕФЪБКђЃЌЮвУЧЛсДДНЈвЛИіаТЕФаГЬЃЌВЂЭЈЙ§ЁАHttpWaldoFinderЁБРраЭЕФЗўЮёЖдЯѓЗУЮЪ
RESTful ЖЫЕуЁЃ
Kotlin аГЬДцдкгквЛИіЁАCoroutineScopeЁБжаЃЌЖјКѓепгжЛсЗДЙ§РДКЭФГжж Dispatcher
ЙиСЊЃЌDispatcher ДњБэСЫЕзВуЕФВЂЗЂФЃаЭЁЃВЂЗЂФЃаЭЭЈГЃЪЧвЛИіЯпГЬГиЃЌЕЋЪЧЛсгаЫљВювьЁЃ
ОпЬхФФаЉ Dispatcher ПЩгУШЁОігк Kotlin ДњТыдЫааЕФЛЗОГЁЃMain Dispatcher
БэЪО UI ПтЕФЪТМўДІРэЯпГЬЃЌвђДЫ (дк JVM ЩЯ) жЛФмдк AndroidЁЂJavaFX КЭ Swing
жаЪЙгУЁЃзюГѕЃЌKotlin Native ИљБОВЛжЇГжаГЬЕФЖрЯпГЬДІРэЃЌЕЋетжжЧщПіе§дкИФБфЁЃдкЗўЮёЦїЖЫЃЌЮвУЧПЩвдздМКв§ШыаГЬЃЌЕЋЪЧдкдНРДдНЖрЕФЧщПіжаЃЌаГЬФЌШЯОЭЪЧПЩгУЕФЃЌБШШчдк
Spring 5 жаЁЃ
дкЕїгУЙвЦ№ЃЈsuspendingЃЉЗНЗЈжЎЧАЃЌЮвУЧБиаыНЋаГЬЁЂЁАCoroutineScopeЁБКЭЁАDispatcheЁБзМБИОЭаїЁЃШчЙћетЪЧГѕЪМЕїгУЕФЛАЃЈШчЩЯУцЕФДњТыЫљЪОЃЉЃЌЮвУЧПЩвдЭЈЙ§ЁАаГЬЙЙдьепЁБКЏЪ§ЃЌШчЁАlaunchЁБКЭЁАasyncЁБЃЌЦєЖЏИУЙ§ГЬЁЃ
ВЛЙмЪЧЕїгУаГЬЙЙНЈепКЏЪ§ЃЌЛЙЪЧЯёЁАwithContextЁБетбљЕФзїгУгђКЏЪ§ЃЌЖМЛсДДНЈвЛИіаТЕФЁАCoroutineScopeЁБЁЃдкИУзїгУгђжаЃЌШЮЮёЬхЯжЮЊЁАJobЁБЪЕР§ЕФВуМЖНсЙЙЁЃ
ЫќУЧгавЛаЉКмгавтЫМЕФЪєадЃЌМДЃК
Job ЛсЕШД§ЦфПщФкЫљгааГЬЭъГЩКѓВХФмЭъГЩздМКЁЃ
ШЁЯћвЛИі Job ЛсЕМжТЦфЫљгаЕФзг Job ЖМБЛШЁЯћЁЃ
зг Job ЕФЪЇАмЛђШЁЯћЛсДЋВЅжСИИ JobЁЃ
етбљЩшМЦЕФФПЕФЪЧБмУтВЂЗЂБрГЬжаЕФГЃМћЮЪЬтЃЌБШШчЩБЫРИИ Job ЕФЪБКђУЛгажеНсЦфзг JobЁЃ
ЗУЮЪ REST ЖЫЕуЕФЗўЮё
ШчЯТЪЧ HttpWaldoFinder ЗўЮёЕФЭъећДњТыЃК
class HttpWaldoFinder
: Controller(), WaldoFinder {
override suspend fun wheresWaldo(starterName:
String): String {
val firstName = fetchNewName(starterName)
println("Found $firstName name".addThreadId())
val secondName = fetchNewName(firstName)
println("Found $secondName name".addThreadId())
val thirdName = fetchNewName(secondName)
println("Found $thirdName name".addThreadId())
val fourthName = fetchNewName(thirdName)
println("Found $fourthName name".addThreadId())
return fetchNewName(fourthName)
}
private suspend fun fetchNewName(inputName: String):
String {
val url = URI("http://localhost:8080/wheresWaldo/$inputName")
val client = HttpClient.newBuilder().build()
val handler = HttpResponse.BodyHandlers.ofString()
val request = HttpRequest.newBuilder().uri(url).build()
return withContext<String>(Dispatchers.IO)
{
println("Sending HTTP Request for $inputName".addThreadId())
client
.send(request, handler)
.body()
}
}
} |
ЁАfetchNewNameЁБКЏЪ§ЛсНгЪевЛИівбжЊЕФУћзжЃЌВЂВщбЏЖЫЕуЛёШЁЙиСЊЕФУћзжЁЃетЪЧЭЈЙ§ЪЙгУЁАHttpClientЁБРраЭРДЪЕЯжЕФЃЌИУРраЭЪЧДг
Java 11 ПЊЪМзїЮЊБъзМЕФЁЃЪЕМЪЕФ HTTP GET ЛсдквЛИіаТЕФзгаГЬжадЫааЃЌИУзгаГЬЛсЪЙгУ
IO DispatcherЁЃЫќЕФБэЯжаЮЪНЪЧвЛИіЮЊГЄЪБМфдЫааЕФЛюЖЏЃЈШчЭјТчЕїгУЃЉгХЛЏЕФЯпГЬГиЁЃ
ЁАwheresWaldoЁБКЏЪ§ЛсИљОнУћзжСДжДааЮхДЮЃЌвдБугкЃЈОЁСІЃЉевЕН WaldoЁЃЮвУЧЫцКѓНЋЛсЗжНтЩњГЩЕФзжНкТыЃЌЫљвдЮвУЧШУЪЕЯжОЁПЩФмЕиМђЕЅЁЃЮвУЧИааЫШЄЕФЪЧЃЌУПДЮЕїгУЁАfetchNewNameЁБЖМЛсЕМжТЕБЧАаГЬдкзгаГЬдЫааЪББЛЙвЦ№ЁЃдкетИіЬиЪтГЁОАЯТЃЌИИ
Job дЫаадк Main Dispatcher ЩЯЃЌЖјзг Job дЫаадк IO Dispatcher
ЩЯЁЃвђДЫЃЌЕБзг Job жДаа HTTP ЧыЧѓЪБЃЌUI ЪТМўДІРэЯпГЬЛсБЛЪЭЗХГіРДДІРэгыЪгЭМЕФгУЛЇНЛЛЅЁЃШчЯТЭМЫљЪОЁЃ

IntelliJ ЛсЮЊЮвУЧеЙЪОКЮЪБЗЂЦ№ЙвЦ№ЕїгУЃЌвђДЫЛсдкаГЬМфзЊЛЛПижЦЁЃашвЊзЂвтЃЌШчЙћЮвУЧУЛгаЧаЛЛ
Dispatcher ЕФЛАЃЌФЧЗЂЦ№ЕїгУВЛвЛЖЈЛсДДНЈаТЕФаГЬЁЃЕБвЛИіЙвЦ№КЏЪ§ЕїгУСэвЛИіЙвЦ№КЏЪ§ЪБЃЌПЩФмЛсдкЯрЭЌЕФаГЬжаМЬајЃЌШчЙћЮвУЧецЕФЯЃЭћБЃГждкЭЌвЛИіЯпГЬЩЯЃЌФЧУДетЕФШЗОЭЪЧЮвУЧЯывЊЕФааЮЊЁЃ

ЕБЮвУЧжДааПЭЛЇЖЫЕФЪБКђЃЌШчЯТОЭЪЧПижЦЬЈЕФЪфГіЃК
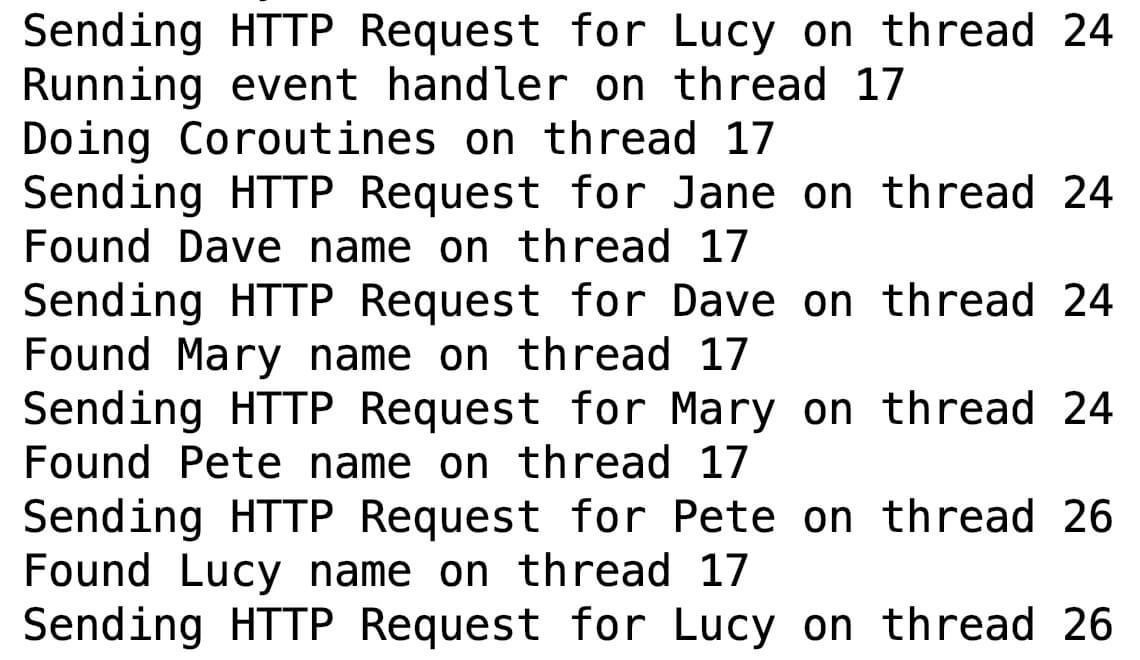
ЮвУЧПЩвдПДЕНЃЌдкетИіЬиЪтЕФГЁОАЯТЃЌMain Dispatcher/UI ЪТМўДІРэЦїдЫаадк 17 КХЯпГЬЩЯЃЌЖј
IO Dispatcher дЫаадкЯпГЬГиЩЯЃЌАќРЈ 24 КХКЭ 26 КХЯпГЬЁЃ
ПЊЪМЮвУЧЕФЕїВщ
Ншжњ IntelliJ здДјЕФзжНкТыЗжНтЙЄОпЃЌЮвУЧПЩвдПДГіЕНЕзЗЂЩњСЫЪВУДЁЃСэЭтЃЌЮвУЧвВПЩвдЪЙгУ JDK
ЬсЙЉЕФБъзМЁАjavapЁБЙЄОпЁЃ
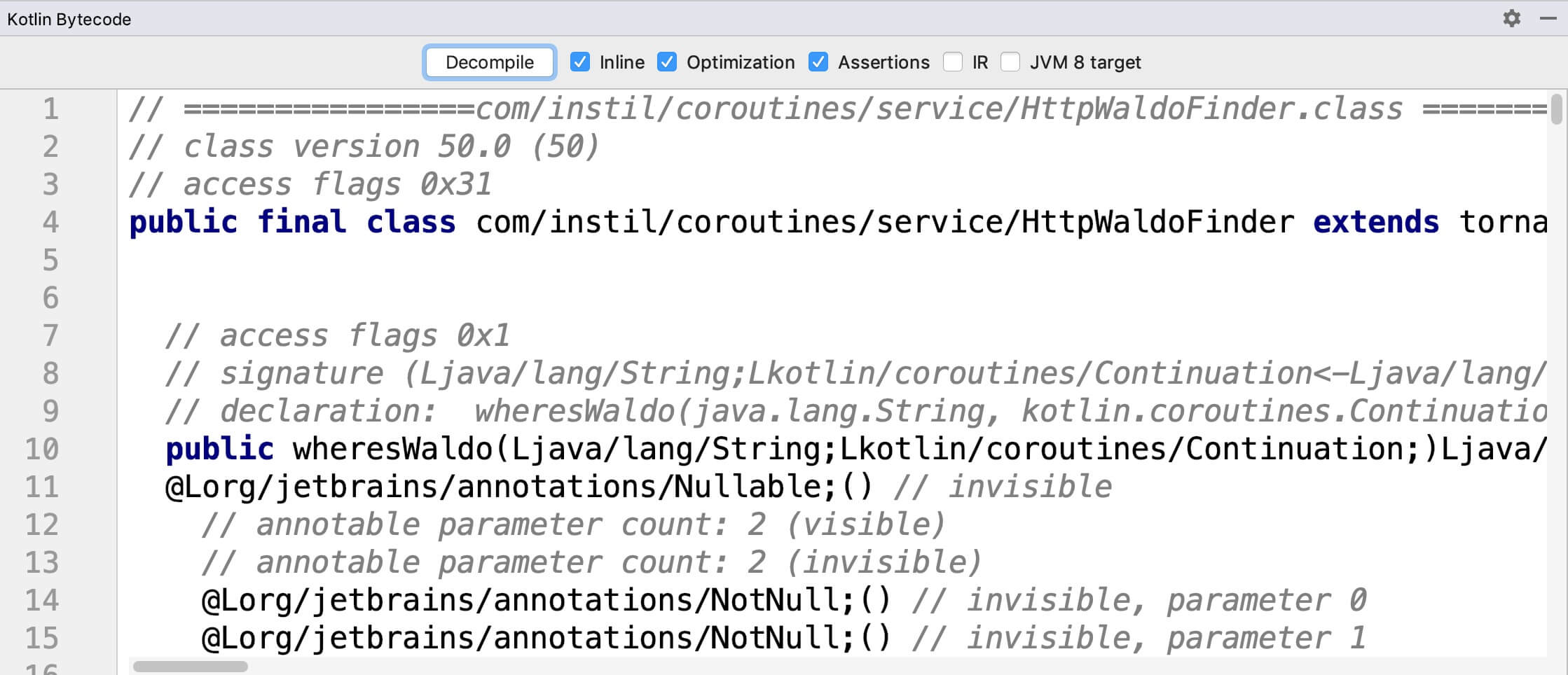
ЮвУЧПЩвдПДЕНЁАHttpWaldoFinderЁБЕФЗНЗЈИФБфСЫЦфЧЉУћЃЌЫљвдЫќУЧПЩвдНгЪмвЛИі
Continuation ЖдЯѓзїЮЊЦфЖюЭтЕФВЮЪ§ЃЌВЂЧвЗЕЛиФГжжЭЈгУЕФЖдЯѓЁЃ
public final
class HttpWaldoFinder extends Controller implements
WaldoFinder {
public Object wheresWaldo(String a, Continuation
b)
final synthetic Object fetchNewName(String a,
Continuation b)
} |
ЯждкЃЌЮвУЧЩюШыДњТыПДвЛЯТетаЉЗНЗЈЖМЬэМгСЫаЉЪВУДЃЌВЂВћЪіЁАContinuationЁБЪЧЪВУДвдМАЯждкЗЕЛиЕФЪЧЪВУДЁЃ
СЌајДЋЕнЗчИёЃЈConinuation Passing StyleЃЌCPSЃЉ
АДее Kotlin БъзМЛЏЙ§ГЬЖдаГЬЬсвщЕФЮФЕЕУшЪіЃЌаГЬЕФЪЕЯжЪЧЛљгкСЌајДЋЕнЗчИё (Continuation
Passing StyleЃЌCPS) ЕФЁЃЛсгавЛИі continuation ЖдЯѓРДДцДЂКЏЪ§дкЙвЦ№НзЖЮЫљашЕФзДЬЌЁЃ
дкБОжЪЩЯЃЌЙвЦ№КЏЪ§ЕФУПИіОжВПБфСПЖМЛсГЩЮЊ continuation ЕФвЛИізжЖЮЁЃСэЭтЃЌЛЙашвЊДДНЈзжЖЮРДДцДЂЫљгаЕФВЮЪ§КЭЕБЧАЖдЯѓЃЈШчЙћКЏЪ§ЪЧЗНЗЈЕФЛАЃЉЁЃЫљвдЃЌвЛИіЙвЦ№ЗНЗЈШчЙћгаЫФИіВЮЪ§КЭЮхИіОжВПБфСПЕФЛАЃЌcontinuation
жСЩйвЊга 10 ИізжЖЮЁЃ
дкЁАHttpWaldoFinderЁБЕФЁАwheresWaldoЁБЗНЗЈжаЃЌгавЛИіВЮЪ§КЭЫФИіБОЕиБфСПЃЌЫљвдЮвУЧдЄЦк
continuation ЪЕЯжРраЭЛсгаСљИізжЖЮЁЃШчЙћЮвУЧНЋ Kotlin БрвыЦїЩњГЩЕФзжНкТыЗжНтГЩ
Java дДТыЕФЛАЃЌОЭЛсЗЂЯжЪТЪЕШЗЪЕШчДЫЃК
$continuation
= new ContinuationImpl($completion) {
Object result;
int label;
Object L$0;
Object L$1;
Object L$2;
Object L$3;
Object L$4;
Object L$5;
@Nullable
public final Object invokeSuspend(@NotNull Object
$result) {
this.result = $result;
this.label |= Integer.MIN_VALUE;
return HttpWaldoFinder.this.wheresWaldo((String)null,
this);
}
}; |
МјгкЫљгаЕФзжЖЮЖМЪЧ Object РраЭЕФЃЌЫљвдЫќУЧИУШчКЮЪЙгУВЂВЛУїЯдЁЃЫцзХНјвЛВНЬНЫїЃЌЮвУЧНЋЛсПДЕНЃК
ЁАL$0ЁБГжгаЖдЁАHttpWaldoFinderЁБЪЕР§ЕФв§гУЁЃЫќЪМжеЖМЛсДцдкЁЃ
ЁАL$1ЁБГжгаЁАstarterNameЁБВЮЪ§ЕФжЕЁЃЫќЪМжеЖМЛсДцдкЁЃ
ЁАL2ЁБЕНЁАL5ЁБГжгаБОЕиБфСПЕФжЕЁЃЫцзХДњТыЕФжДааЃЌЫќУЧНЋЛсНЅНјЪНЕиЬюГфНјРДЁЃЁАL$2ЁБЛсГжгаЁАfirstNameЁБЕФжЕЃЌвдДЫРрЭЦЁЃ
ЮвУЧЛЙгаЖюЭтЕФзжЖЮДцДЂзюжеНсЙћЃЌгавЛИіУћЮЊЁАlabelЁБЕФгаШЄЕФећаЭзжЖЮЁЃ
ЙвЦ№ЛЙЪЧВЛЙвЦ№ЁЊЁЊетЪЧвЛИіЮЪЬт
ЕБЮвУЧМьВщЩњГЩЕФДњТыЪБЃЌашвЊМЧзЁЫќвЊДІРэСНИіГЁОАЁЃУПЕБвЛИіЙвЦ№ЕФКЏЪ§ЕїгУСэвЛИіКЏЪ§ЪБЃЌЫќПЩФмЛсЙвЦ№ЕБЧАЕФаГЬЃЈетбљСэЭтвЛИіКЏЪ§ПЩвддкЯрЭЌЕФЯпГЬЩЯдЫааЃЉЃЌвВПЩФмдкЕБЧАаГЬЛсМЬајжДааЁЃ
ЮвУЧПМТЧвЛИіДгЪ§ОнДцДЂжаЖСШЁжЕЕФЙвЦ№КЏЪ§ЁЃЕБ I/O ЗЂЩњЕФЪБКђЃЌЫќКмПЩФмЛсБЛЙвЦ№ЃЌЕЋЪЧЫќвВПЩФмЛсЛКДцНсЙћЁЃКѓајЕїгУПЩвдЭЌВНЗЕЛиЛКДцЕФжЕЃЌВЛашвЊШЮКЮЕФЙвЦ№ЁЃKotlin
БрвыЦїЫљЩњГЩЕФДњТыБиаывЊЭЌЪБжЇГжетСНжжТЗОЖЁЃ
Kotlin ЛсЕїећУПИіЙвЦ№КЏЪ§ЕФЗЕЛиРраЭЃЌетбљЕФЛАЃЌЫќвЊУДЗЕЛиеце§ЕФНсЙћЃЌвЊУДЗЕЛиЬиЪтЕФжЕ COROUTINE_SUSPENDEDЁЃШчЙћЪЧКѓепЕФЛАЃЌЕБЧАЕФаГЬЛсБЛЙвЦ№ЁЃетвВЪЧЮЊЪВУДЙвЦ№КЏЪ§ЕФЗЕЛиРраЭДгНсЙћРраЭБфГЩСЫЁАObjectЁБЁЃ
дкЮвУЧЕФбљР§гІгУжаЃЌЁАwheresWaldoЁБЛсжиИДЕїгУЁАfetchNewNameЁБЁЃдкРэТлЩЯЃЌУПДЮетбљЕФЕїгУЖМПЩФмЙвЦ№ЛђВЛЙвЦ№ЕБЧАЕФаГЬЁЃАДееЮвУЧБраДЁАfetchNewNameЁБЕФЗНЪНЃЌПЩвджЊЕРЃЌЙвЦ№ЪМжеЖМЛсЗЂЩњЁЃЕЋЪЧЃЌЮЊСЫРэНтЩњГЩЕФДњТыЃЌЮвУЧБиаыМЧзЁЫќашвЊДІРэЫљгаЕФПЩФмадЁЃ
ДѓЕФ Switch гяОфКЭ Label
ШчЙћЮвУЧНјвЛВНВщПДЗжНтКѓЕФДњТыЃЌЛсЗЂЯжвЛИівўВидкЖрИіЧЖЬз label
жаЕФ switch гяОфЁЃетЪЧвЛИізДЬЌЛњЕФЪЕЯжЃЌгУРДдк wheresWaldo() ЗНЗЈжаПижЦВЛЭЌЕФЙвЦ№ЕуЁЃЯТУцЪЧећЬхЕФНсЙЙЃК
// ГЬађЧхЕЅ 1ЃКЩњГЩЕФ
switch гяОфКЭ label
String firstName;
String secondName;
String thirdName;
String fourthName;
Object var11;
Object var10000;
label48: {
label47: {
label46: {
Object $result = $continuation.result;
var11 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch($continuation.label) {
case 0:
// ЪЁТдДњТы
case 1:
// ЪЁТдДњТы
case 2:
// ЪЁТдДњТы
case 3:
// ЪЁТдДњТы
case 4:
// ЪЁТдДњТы
case 5:
// ЪЁТдДњТы
default:
throw new IllegalStateException(
"call
to 'resume' before 'invoke' with coroutine");
} // НсЪј switch
// ЪЁТдДњТы
} // НсЪј label 46
// ЪЁТдДњТы
} // НсЪј label 47
// ЪЁТдДњТы
} // НсЪј label 48
// ЪЁТдДњТы |
ЮвУЧЯждкПЩвдПДЕН continuation жаЁАlabelЁБзжЖЮЕФФПЕФСЫЁЃЕБЭъГЩЁАwheresWaldoЁБЕФВЛЭЌНзЖЮЪБЃЌЮвУЧНЋЛсБфИќЁАlabelЁБжаЕФжЕЁЃЧЖЬзЕФ
label ДњТыПщжаАќКЌСЫдЪМ Kotlin ДњТыРяУцЙвЦ№ЕужЎМфЕФДњТыПщЁЃетИіЁАlabelЁБжЕдЪаэжиаТНјШыИУДњТыЃЌЬјЕНзюКѓЙвЦ№ЕФЕиЗНЃЈЪЪЕБЕФ
case гяОфЃЉЃЌвдБугкДг continuation жаГщШЁЪ§ОнЃЌШЛКѓЬјзЊЕНе§ШЗЕФ label ДњТыПщЁЃ
ЕЋЪЧЃЌШчЙћЫљгаЕФЙвЦ№ЕуЖМУЛгаеце§ЙвЦ№ЕФЛАЃЌећИіДњТыПщПЩвдЭЌВНжДааЁЃдкЩњГЩЕФДњТыжаЃЌЮвУЧОГЃЛсПДЕНетбљЕФЦЌЖЮЃК
// ГЬађЧхЕЅ 2ЃКШЗЖЈЕБЧАЕФаГЬЪЧЗёгІИУЙвЦ№
if (var10000 == var11) {
return var11;
} |
ДгЩЯУцЮвУЧПЩвдПДЕНЃЌЁАvar11ЁББЛЩшжУГЩСЫCONTINUATION_SUSPENDEDЕФжЕЃЌЖјЁАvar10000ЁББЃДцСЫЖдСэвЛИіЙвЦ№КЏЪ§ЕФЕїгУЕФЗЕЛижЕЁЃвђДЫЃЌЕБЙвЦ№ЗЂЩњЪБЃЌДњТыНЋЗЕЛи
(ЩдКѓЛсжиаТНјШы)ЃЌШчЙћУЛгаЗЂЩњЙвЦ№ЃЌдђДњТыНЋЭЈЙ§ЧаЛЛЕНЪЪЕБЕФ label ПщМЬајжДааКЏЪ§ЕФЯТвЛВПЗжЁЃ
дйДЮЧПЕїЃЌЧыМЧзЁЃЌЩњГЩЕФДњТыВЛФмМйЩшЫљгаЕїгУЖМНЋЙвЦ№ЃЌЛђепЫљгаЕїгУЖМНЋМЬајЪЙгУЕБЧАЕФаГЬЁЃЫќБиаыФмЙЛДІРэШЮКЮПЩФмЕФзщКЯЁЃ
ИњзйжДаа
ЕБЮвУЧПЊЪМжДааЪБЃЌcontinuation жаЁАlabelЁБЕФжЕНЋЛсБЛжУЮЊСуЁЃШчЯТЪЧЖдгІЕФ
switch гяОфЗжжЇЃК
// ГЬађЧхЕЅ 3ЃКswitch
ЕФЕквЛИіЗжжЇ
case 0:
ResultKt.throwOnFailure($result);
$continuation.L$0 = this;
$continuation.L$1 = starterName;
$continuation.label = 1;
var10000 = this.fetchNewName(starterName, $continuation);
if (var10000 == var11) {
return var11;
}
break; |
ЮвУЧНЋЪЕР§КЭВЮЪ§ДцДЂЕНСЫ continuation ЖдЯѓжаЃЌШЛКѓНЋ continuation ЖдЯѓДЋЕнИјЁАfetchNewNameЁБЁЃШчЧАЮФЫљЪіЃЌБрвыЦїЫљЩњГЩЕФЁАfetchNewNameЁБАцБОвЊУДЗЕЛиЪЕМЪЕФНсЙћЃЌвЊУДЗЕЛиCOROUTINE_SUSPENDEDжЕЁЃ
ШчЙћаГЬЙвЦ№ЕФЛАЃЌФЧУДЮвУЧЛсДгКЏЪ§жаЗЕЛиЃЌВЂЧвЕБЮвУЧЛжИДЕФЪБКђЃЌЛсЬјШыЁАcase
1ЁБЗжжЇЁЃШчЙћЮвУЧМЬајЪЙгУЕБЧАЕФаГЬЃЌФЧУДЛсЬјГі switch ЕНФГвЛИі label ДњТыПщЃЌНјШыШчЯТЕФДњТыЃК
// ГЬађЧхЕЅ 4ЃКЕкЖўДЮЕїгУЁАfetchNewNameЁБ
firstName = (String)var10000;
secondName = UtilsKt.addThreadId("Found "
+ firstName + " name");
boolean var13 = false;
System.out.println(secondName);
$continuation.L$0 = this;
$continuation.L$1 = starterName;
$continuation.L$2 = firstName;
$continuation.label = 2;
var10000 = this.fetchNewName(firstName, $continuation);
if (var10000 == var11) {
return var11;
} |
вђЮЊЮвУЧжЊЕРЁАvar10000ЁБАќКЌСЫЮвУЧЦкЭћЕФЗЕЛижЕЃЌЫљвдЮвУЧПЩвдНЋЦфзЊЛЛГЩе§ШЗЕФРраЭВЂДцДЂЕНОжВПБфСПЁАfirstNameЁБжаЁЃЫцКѓЃЌЩњГЩЕФДњТыЛсЪЙгУЁАsecondNameЁБРДДцДЂЯпГЬ
id СЌНгЕФНсЙћЃЌВЂЧвНЋЦфДђгЁСЫГіРДЁЃ
ЮвУЧИќаТСЫ continuation жаЕФзжЖЮЃЌЬэМгСЫЗўЮёЦїМьЫїЕНЕФжЕЁЃзЂвтЃЌЁАlabelЁБЕФжЕЯждквбОЪЧ
2 СЫЁЃЫцКѓЃЌЮвУЧЕкШ§ДЮЕїгУЁАfetchNewNameЁБЁЃ
ЕкШ§ДЮЕїгУЁАfetchNewNameЁБЁЊЁЊЮоЙвЦ№
ЮвУЧашвЊдйДЮЛљгкЁАfetchNewNameЁБЗЕЛиЕФжЕзіГібЁдёЃЌШчЙћЗЕЛиЕФжЕЪЧCOROUTINE_SUSPENDEDЕФЛАЃЌЮвУЧЛсДгЕБЧАКЏЪ§ЗЕЛиЁЃЕБЯТвЛДЮЕїгУЪБЃЌЮвУЧвЊзёб
switch ЕФЁАcase 2ЁБЗжжЇЁЃ
ШчЙћЮвУЧМЬајЪЙгУЕБЧАаГЬЕФЛАЃЌФЧУДНЋЛсжДааШчЯТЕФДњТыПщЁЃЮвУЧПЩвдПДЕНЫќгыЩЯУцЕФДњТыЪЧЯрЭЌЕФЃЌжЛВЛЙ§ЮвУЧЯждквЊгаИќЖрЕФЪ§ОнДцДЂЕН
continuation жаЁЃ
// ГЬађЧхЕЅ 4ЃКЕкШ§ДЮЕїгУЁАfetchNewNameЁБ
secondName = (String)var10000;
thirdName = UtilsKt.addThreadId("Found "
+ secondName + " name");
boolean var14 = false;
System.out.println(thirdName);
$continuation.L$0 = this;
$continuation.L$1 = starterName;
$continuation.L$2 = firstName;
$continuation.L$3 = secondName;
$continuation.label = 3;
var10000 = this.fetchNewName(secondName, (Continuation)$continuation);
if (var10000 == var11) {
return var11;
} |
етжжФЃЪНдкКѓајЕФЕїгУжаЛсжиИДЃЈМйЖЈЪМжеУЛгаЗЕЛиCOROUTINE_SUSPENDEDЃЉЃЌжБЕНЕНДяжеЕуЮЊжЙЁЃ
ЕкШ§ДЮЕїгУЁАfetchNewNameЁБЁЊЁЊДјгаЙвЦ№
ЛђепЃЌШчЙћаГЬвбОБЛЙвЦ№ЕФЛАЃЌФЧУДНЋЛсдЫааШчЯТЕФДњТыПщЃК
// ГЬађЧхЕЅ 5ЃКswitch
ЕФЕкШ§ИіЗжжЇ
case 2:
firstName = (String)$continuation.L$2;
starterName = (String)$continuation.L$1;
this = (HttpWaldoFinder)$continuation.L$0;
ResultKt.throwOnFailure($result);
var10000 = $result;
break label46; |
ЮвУЧНЋ continuation жаЕФжЕГщШЁЕНКЏЪ§ЕФОжВПБфСПжаЁЃЫцКѓЪЙгУвЛИі label аЮЪНЕФ break
ЪЙжДааЬјзЊжСЧАЪіЕФГЬађЧхЕЅ 4 жаЁЃЫљвдзюжеЃЌЮвУЧЛсдкЯрЭЌЕФЕиЗННсЪјЁЃ
змНсжДааЙ§ГЬ
ЯждкЃЌЮвУЧПЩвджиаТПДвЛЯТГЬађЧхЕЅЕФДњТыНсЙЙЃЌВЂдкећЬхЩЯУшЪівЛЯТУПИіЧјгђжаЖМЗЂЩњСЫЪВУДЃК
// ГЬађЧхЕЅ 6ЃКЩюЖШНтЮіЩњГЩЕФ
switch гяОфКЭ label
String firstName;
String secondName;
String thirdName;
String fourthName;
Object var11;
Object var10000;
label48: {
label47: {
label46: {
Object $result = $continuation.result;
var11 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch($continuation.label) {
case 0:
// НЋ label ЩшжУЮЊ 1ЃЌШчЙћЗЕЛиЙвЦ№ЕФЛАЃЌЕквЛДЮЕїгУЁАfetchNewNameЁБ
// ЗёдђЃЌДг switch жа break ЭЫГі
case 1:
// Дг continuation жаГщШЁВЮЪ§
// Дг switch жа break ЭЫГі
case 2:
// Дг continuation жаГщШЁВЮЪ§КЭЕквЛИіНсЙћ
// ЬјзЊЕНЭтБпЕФЁАlabel46ЁБ
case 3:
// Дг continuation жаГщШЁВЮЪ§ЃЌЕквЛИіКЭЕкЖўИіНсЙћ
// ЬјзЊЕНЭтБпЕФЁАlabel47ЁБ
case 4:
// Дг continuation жаГщШЁВЮЪ§ЃЌЕквЛИіЁЂЕкЖўИіКЭЕкШ§ИіНсЙћ
// ЬјзЊЕНЭтБпЕФЁАlabel48ЁБ
case 5:
// Дг continuation жаГщШЁВЮЪ§ЃЌЕквЛИіЁЂЕкЖўИіЁЂЕкШ§ИіКЭЕкЫФИіНсЙћ
// ЗЕЛизюКѓЕФНсЙћ
default:
throw new IllegalStateException(
"call
to 'resume' before 'invoke' with coroutine");
} // НсЪј switch
// ДцДЂВЮЪ§КЭЕквЛИіНсЙћЕН continuation жа
// ШчЙћЗЕЛиЙвЦ№ЕФЛАЃЌНЋ label ЩшжУЮЊ 2 ВЂЖдЁАfetchNewNameЁБНјааЕкЖўДЮЕїгУ
// ЗёдђЕФЛАМЬајНјаа
} // НсЪј label 46
// ДцДЂВЮЪ§ЁЂЕквЛИіНсЙћКЭЕкЖўИіНсЙћЕН continuation жа
// ШчЙћЗЕЛиЙвЦ№ЕФЛАЃЌНЋ label ЩшжУЮЊ 3 ВЂЖдЁАfetchNewNameЁБНјааЕкШ§ДЮЕїгУ
// ЗёдђЕФЛАМЬајНјаа
} // НсЪј label 47
// ДцДЂВЮЪ§ЁЂЕквЛИіНсЙћЁЂЕкЖўИіНсЙћКЭЕкШ§ИіНсЙћЕН continuation жа
// ШчЙћЗЕЛиЙвЦ№ЕФЛАЃЌНЋ label ЩшжУЮЊ 4 ВЂЖдЁАfetchNewNameЁБНјааЕкЫФДЮЕїгУ
// ЗёдђЕФЛАМЬајНјаа
} // НсЪј label 48
// ДцДЂВЮЪ§ЁЂЕквЛИіНсЙћЁЂЕкЖўИіНсЙћЁЂЕкШ§ИіНсЙћКЭЕкЫФИіНсЙћЕН continuation
жа
// НЋ label ЩшжУЮЊ 5 ВЂЖдЁАfetchNewNameЁБНјааЕкЮхДЮЕїгУ
// ЗЕЛизюжеНсЙћЛђ COROUTINE_SUSPENDED |
НсЙћ
етИіДњТыПтРэНтЦ№РДВЂВЛМђЕЅЁЃЮвУЧЗжЮіСЫзжНкТыЗжНтЕУЕНЕФ Java ДњТыЃЌетаЉзжНкТыЪЧгЩ Kotlin
БрвыЦїжаЕФДњТыЩњГЩЦїЫљВњЩњЕФЁЃетИіДњТыЩњГЩЦїЕФЪфГідкЩшМЦЪБПМТЧЕФЪЧаЇТЪКЭзюаЁЛЏЃЌЖјВЛЪЧПЩРэНтадЁЃ
ЕЋЪЧЃЌЮвУЧПЩвдЕУГівЛаЉгагУЕФНсТлЃК
ВЂУЛгаЪВУДФЇЗЈЁЃЕБПЊЗЂШЫдБЕквЛДЮПЊЪМбЇЯАаГЬЪБЃЌКмШнвзЛсШЯЮЊгааЉЬиЪтЕФЁАФЇЗЈЁБНЋЫљгаЕФетаЉЪТЧщСЌНгдкСЫвЛЦ№ЁЃЮвУЧПЩвдПДЕНЃЌЩњГЩЕФДњТыжЛЪЙгУСЫвЛаЉЙ§ГЬЪНБрГЬЕФЛљБОЙЙНЈПщЃЌБШШчЬѕМўгяОфКЭДјга
label ЕФ breakЁЃ
ЪЕЯжЪЧЛљгк continuation ЕФЁЃдкзюГѕЕФ KEEP ЬсвщжаЃЌКЏЪ§ЙвЦ№КЭЛжИДЕФЗНЗЈЪЧНЋКЏЪ§ЕФзДЬЌЛКДцдквЛИіЖдЯѓжаЁЃвђДЫЃЌЖдгкУПИіЙвЦ№КЏЪ§ЃЌБрвыЦїНЋДДНЈвЛИіАќКЌ
N ИізжЖЮЕФ continuation РраЭЃЌЦфжа N ЪЧВЮЪ§ЕФЪ§СПМгЩЯзжЖЮЪ§дйМгЩЯ 3ЁЃзюКѓЕФШ§ИізжЖЮБЃДцЕБЧАЖдЯѓЁЂзюжеНсЙћКЭЫїв§ЁЃ
жДааЪМжезёбвЛИіБъзМЕФФЃЪНЁЃШчЙћДгЙвЦ№жаЛжИДЃЌФЧУДЮвУЧвЊЪЙгУ continuation ЕФЁАlabelЁБзжЖЮЬјзЊЕН
switch гяОфЕФЪЪЕБЗжжЇЁЃдкетИіЗжжЇжаЃЌЮвУЧДг continuation ЖдЯѓМьЫїЕНФПЧАЮЊжЙвбОевЕНЕФЪ§ОнЃЌШЛКѓЪЙгУвЛИіДјга
label ЕФ break ЬјзЊЕНУЛгаЗЂЩњЙвЦ№ЕФДњТыЃЌетаЉДњТыБОРДЪЧвЊжБНгжДааЕФЁЃ
|









