| БрМЭЦМі: |
| БОЮФРДздгкЭјТчЃЌЮФеТНщЩмСЫApp
ТЗгЩФмНтОіФФаЉЮЪЬтЁЂApp жЎМфЬјзЊЪЕЯжвдМАApp ФкзщМўМфТЗгЩЩшМЦ ЁЃ |
|
ЧАбд
ЫцзХгУЛЇЕФашЧѓдНРДдНЖрЃЌЖд App ЕФгУЛЇЬхбщвВБфЕФвЊЧѓдНРДдНИпЁЃЮЊСЫИќКУЕФгІЖдИїжжашЧѓЃЌПЊЗЂШЫдБДгШэМўЙЄГЬЕФНЧЖШЃЌНЋ
App МмЙЙгЩдРДМђЕЅЕФ MVC БфГЩ MVVMЃЌVIPER ЕШИДдгМмЙЙЁЃИќЛЛЪЪКЯвЕЮёЕФМмЙЙЃЌЪЧЮЊСЫКѓЦкФмИќКУЕФЮЌЛЄЯюФПЁЃ
ЕЋЪЧгУЛЇвРОЩВЛТњвтЃЌМЬајЖдПЊЗЂШЫдБЬсГіСЫИќЖрИќИпЕФвЊЧѓЃЌВЛНіашвЊИпжЪСПЕФгУЛЇЬхбщЃЌЛЙвЊЧѓПьЫйЕќДњЃЌзюКУвЛЬьГівЛИіаТЙІФмЃЌЖјЧвгУЛЇЛЙвЊЧѓВЛИќаТОЭФмЬхбщЕНаТЙІФмЁЃЮЊСЫТњзугУЛЇашЧѓЃЌгкЪЧПЊЗЂШЫдБОЭгУH5ЃЌReactNativeЃЌWeex
ЕШММЪѕЖдвбгаЕФЯюФПНјааИФдьЁЃЯюФПМмЙЙвВБфЕУИќМгЕФИДдгЃЌзнЯђЕФЛсНјааЗжВуЃЌЭјТчВуЃЌUI ВуЃЌЪ§ОнГжОУВуЁЃУПвЛВуКсЯђЕФвВЛсИљОнвЕЮёНјаазщМўЛЏЁЃОЁЙметбљзіСЫвдКѓЛсШУПЊЗЂИќМггааЇТЪЃЌИќМгКУЮЌЛЄЃЌЕЋЪЧШчКЮНтёюИїВуЃЌНтёюИїИіНчУцКЭИїИізщМўЃЌНЕЕЭИїИізщМўжЎМфЕФёюКЯЖШЃЌШчКЮФмШУећИіЯЕЭГВЛЙмЖрУДИДдгЕФЧщПіЯТЖМФмБЃГжЁАИпФкОлЃЌЕЭёюКЯЁБЕФЬиЕуЃПетвЛЯЕСаЕФЮЪЬтЖМАкдкПЊЗЂШЫдБУцЧАЃЌиНД§НтОіЁЃНёЬьОЭРДЬИЬИНтОіетИіЮЪЬтЕФвЛаЉЫМТЗЁЃ
ФПТМ
1ЁЂв§зг
2ЁЂApp ТЗгЩФмНтОіФФаЉЮЪЬт
3ЁЂApp жЎМфЬјзЊЪЕЯж
4ЁЂApp ФкзщМўМфТЗгЩЩшМЦ
5ЁЂИїИіЗНАИгХШБЕу
6ЁЂзюКУЕФЗНАИ
вЛЁЂв§зг
ДѓЧАЖЫЗЂеЙетУДЖрФъСЫЃЌЯраХвВвЛЖЈЛсгіЕНЯрЫЦЕФЮЪЬтЁЃНќСНФъSPAЗЂеЙМЋЦфбИУЭЃЌReact КЭ VueвЛжБДІгкЗчПкРЫМтЃЌФЧЮвУЧОЭПДПДЫћУЧЪЧШчКЮДІРэКУетвЛЮЪЬтЕФЁЃ

дк SPA ЕЅвГУцгІгУЃЌТЗгЩЦ№ЕНСЫКмЙиМќЕФзїгУЁЃТЗгЩЕФзїгУжївЊЪЧБЃжЄЪгЭМКЭ URL ЕФЭЌВНЁЃдкЧАЖЫЕФблРяПДРДЃЌЪгЭМЪЧБЛПДГЩЪЧзЪдДЕФвЛжжБэЯжЁЃЕБгУЛЇдквГУцжаНјааВйзїЪБЃЌгІгУЛсдкШєИЩИіНЛЛЅзДЬЌжаЧаЛЛЃЌТЗгЩдђПЩвдМЧТМЯТФГаЉживЊЕФзДЬЌЃЌБШШчгУЛЇВщПДвЛИіЭјеОЃЌгУЛЇЪЧЗёЕЧТМЁЂдкЗУЮЪЭјеОЕФФФвЛИівГУцЁЃЖјетаЉБфЛЏЭЌбљЛсБЛМЧТМдкфЏРРЦїЕФРњЪЗжаЃЌгУЛЇПЩвдЭЈЙ§фЏРРЦїЕФЧАНјЁЂКѓЭЫАДХЅЧаЛЛзДЬЌЁЃзмЕФРДЫЕЃЌгУЛЇПЩвдЭЈЙ§ЪжЖЏЪфШыЛђепгывГУцНјааНЛЛЅРДИФБф
URLЃЌШЛКѓЭЈЙ§ЭЌВНЛђепвьВНЕФЗНЪНЯђЗўЮёЖЫЗЂЫЭЧыЧѓЛёШЁзЪдДЃЌГЩЙІКѓжиаТЛцжЦ UIЃЌдРэШчЯТЭМЫљЪОЃК
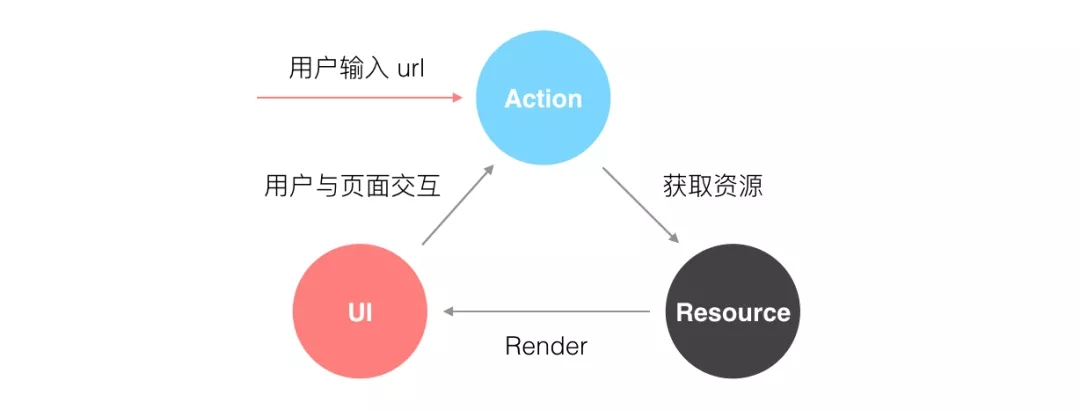
react-router ЭЈЙ§ДЋШыЕФ location ЕНзюжефжШОаТЕФUIЃЌСїГЬШчЯТЃК
location ЕФРДдДга 2 жжЃЌвЛжжЪЧфЏРРЦїЕФЛиЭЫКЭЧАНјЃЌСэЭтвЛжжЪЧжБНгЕуСЫвЛИіСДНгЁЃаТЕФ location
ЖдЯѓКѓЃЌТЗгЩФкВПЕФ matchRoutes ЗНЗЈЛсЦЅХфГі Route зщМўЪїжагыЕБЧА location
ЖдЯѓЦЅХфЕФвЛИізгМЏЃЌВЂЧвЕУЕНСЫ nextStateЃЌдкthis.setState(nextState)
ЪБОЭПЩвдЪЕЯжжиаТфжШО Router зщМўЁЃ
ДѓЧАЖЫЕФзіЗЈДѓИХЪЧетбљЕФЃЌЮвУЧПЩвдАбетаЉЫМЯыНшМјЕН iOS етБпРДЁЃЩЯЭМжаЕФ Back / Forward
дк iOS етБпКмЖрЧщПіЯТЖМПЩвдБЛ UINavgation ЫљЙмРэЁЃЫљвд iOS ЕФ Router
жївЊДІРэТЬЩЋЕФФЧвЛПщЁЃ
ЖўЁЂAppТЗгЩФмНтОіФФаЉЮЪЬт

МШШЛЧАЖЫФмдк SPA ЩЯНтОі URL КЭUIЕФЭЌВНЮЪЬтЃЌФЧетжжЫМЯыПЩвддк App ЩЯНтОіФФаЉЮЪЬтФиЃП
ЫМПМШчЯТЕФЮЪЬтЃЌЦНЪБЮвУЧПЊЗЂжаЪЧШчКЮгХбХЕФНтОіЕФЃК
1ЁЂ3D-Touch ЙІФмЛђепЕуЛїЭЦЫЭЯћЯЂЃЌвЊЧѓЭтВПЬјзЊЕН App ФкВПвЛИіКмЩюВуДЮЕФвЛИіНчУцЁЃ
БШШчЮЂаХЕФ 3D-Touch ПЩвджБНгЬјзЊЕНЁАЮвЕФЖўЮЌТыЁБЁЃЁАЮвЕФЖўЮЌТыЁБНчУцдкЮвЕФРяУцЕФЕкШ§МЖНчУцЁЃЛђепдйМЋЖЫвЛЕуЃЌВњЦЗашЧѓИјСЫИќМгБфЬЌЕФашЧѓЃЌвЊЧѓЬјзЊЕН
App ФкВПЕкЪЎВуЕФНчУцЃЌдѕУДДІРэЃП
2ЁЂздМвЕФвЛЯЕСа App жЎМфШчКЮЯрЛЅЬјзЊЃП
ШчЙћздМК App гаМИИіЃЌЯрЛЅжЎМфЛЙЯыЯрЛЅЬјзЊЃЌдѕУДДІРэЃП
3ЁЂШчКЮНтГ§ App зщМўжЎМфКЭ App вГУцжЎМфЕФёюКЯадЃП
ЫцзХЯюФПдНРДдНИДдгЃЌИїИізщМўЃЌИїИівГУцжЎМфЕФЬјзЊТпМЙиСЊаддНРДдНЖрЃЌШчКЮФмгХбХЕФНтГ§ИїИізщМўКЭвГУцжЎМфЕФёюКЯадЃП
4ЁЂШчКЮФмЭГвЛ iOS КЭ Android СНЖЫЕФвГУцЬјзЊТпМЃПЩѕжСШчКЮФмЭГвЛШ§ЖЫЕФЧыЧѓзЪдДЕФЗНЪНЃП
ЯюФПРяУцФГаЉФЃПщЛсЛьКЯ ReactNativeЃЌWeexЃЌH5НчУцЃЌетаЉНчУцЛЙЛсЕїгУ Native
ЕФНчУцЃЌвдМА Native ЕФзщМўЁЃФЧУДЃЌШчКЮФмЭГвЛ Web ЖЫКЭ Native ЖЫЧыЧѓзЪдДЕФЗНЪНЃП
5ЁЂШчЙћЪЙгУСЫЖЏЬЌЯТЗЂХфжУЮФМўРДХфжУ App ЕФЬјзЊТпМЃЌФЧУДШчЙћзіЕН iOS КЭ Android
СНБпжЛвЊЙВгУвЛЬзХфжУЮФМўЃП
6ЁЂШчЙћ App ГіЯж bug СЫЃЌШчКЮВЛгУ JSPatchЃЌОЭФмзіЕНМђЕЅЕФШШаоИДЙІФмЃП
БШШч App ЩЯЯпЭЛШЛгіЕНСЫНєМБ bugЃЌФмЗёАбвГУцЖЏЬЌНЕМЖГЩ H5ЃЌReactNativeЃЌWeexЃПЛђепЪЧжБНгЛЛГЩвЛИіБОЕиЕФДэЮѓНчУцЃП
7ЁЂШчКЮдкУПИізщМўМфЕїгУКЭвГУцЬјзЊЪБЖМНјааТёЕуЭГМЦЃПУПИіЬјзЊЕФЕиЗНЖМЪжаДДњТыТёЕуЃПРћгУ Runtime
AOP ЃП
8ЁЂШчКЮдкУПИізщМўМфЕїгУЕФЙ§ГЬжаЃЌМгШыЕїгУЕФТпММьВщЃЌСюХЦЛњжЦЃЌХфКЯЛвЖШНјааЗчПиТпМЃП
9ЁЂШчКЮдк App ШЮКЮНчУцЖМПЩвдЕїгУЭЌвЛИіНчУцЛђепЭЌвЛИізщМўЃПжЛФмдк AppDelegate РяУцзЂВсЕЅР§РДЪЕЯжЃП
БШШч App ГіЯжЮЪЬтСЫЃЌгУЛЇПЩФмдкШЮКЮНчУцЃЌШчКЮЫцЪБЫцЕиЕФШУгУЛЇЧПжЦЕЧГіЃПЛђепЧПжЦЖМЬјзЊЕНЭЌвЛИіБОЕиЕФ
error НчУцЃПЛђепЬјзЊЕНЯргІЕФH5ЃЌReactNativeЃЌWeex НчУцЃПШчКЮШУгУЛЇдкШЮКЮНчУцЃЌЫцЪБЫцЕиЕФЕЏГівЛИі
View ЃП
вдЩЯетаЉЮЪЬтЦфЪЕЖМПЩвдЭЈЙ§дк App ЖЫЩшМЦвЛИіТЗгЩРДНтОіЁЃФЧУДЮвУЧдѕУДЩшМЦвЛИіТЗгЩФиЃП
Ш§ЁЂAppжЎМфЬјзЊЪЕЯж
дкЬИ App ФкВПЕФТЗгЩжЎЧАЃЌЯШРДЬИЬИдк iOS ЯЕЭГМфЃЌВЛЭЌ App жЎМфЪЧдѕУДЪЕЯжЬјзЊЕФЁЃ
1ЁЂURL SchemeЗНЪН
iOS ЯЕЭГЪЧФЌШЯжЇГж URL Scheme ЕФЃЌОпЬхМћЙйЗНЮФЕЕЁЃ
БШШчЫЕЃЌдк iPhone ЕФ Safari фЏРРЦїЩЯУцЪфШыШчЯТЕФУќСюЃЌЛсздЖЏДђПЊвЛаЉ AppЃК
// ДђПЊгЪЯф
mailto://
// Иј110ВІДђЕчЛА
tel://110 |
дк iOS 9 жЎЧАжЛвЊдк App ЕФ info.plist РяУцЬэМг URL types - URL
SchemesЃЌШчЯТЭМЃК
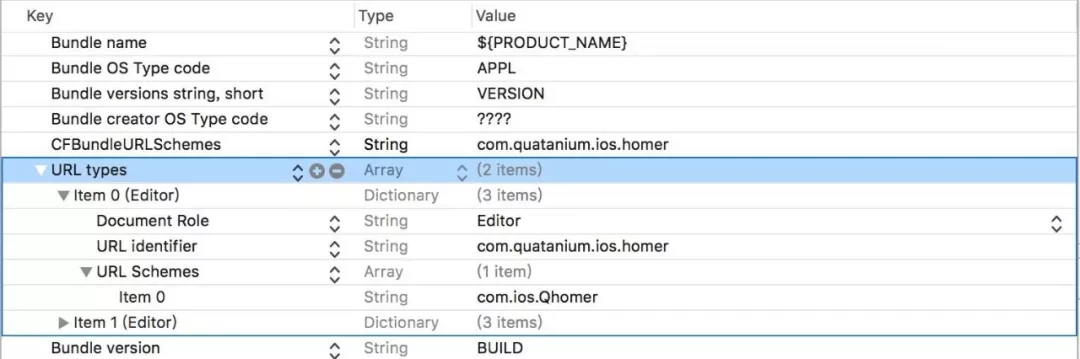
етРяОЭЬэМгСЫвЛИі com.ios.Qhomer ЕФ SchemeЁЃетбљОЭПЩвддк
iPhone ЕФ Safari фЏРРЦїЩЯУцЪфШыЃК
ОЭПЩвджБНгДђПЊетИі App СЫЁЃ
ЙигкЦфЫћвЛаЉГЃМћЕФ AppЃЌПЩвдДг iTunes РяУцЯТдиЕНЫќЕФ ipa
ЮФМўЃЌНтбЙЃЌЯдЪОАќФкШнРяУцПЩвдевЕН info.plist ЮФМўЃЌДђПЊЫќЃЌдкРяУцОЭПЩвдЯргІЕФ URL
SchemeЁЃ
// ЪжЛњQQ
mqq://
// ЮЂаХ
weixin://
// аТРЫЮЂВЉ
sinaweibo://
// ЖіСЫУД
eleme:// |

ЕБШЛСЫЃЌФГаЉ App ЖдгкЕїгУ URL Scheme БШНЯУєИаЃЌЫќУЧВЛЯЃЭћЦфЫћЕФ App ЫцвтЕФОЭЕїгУздМКЁЃ
ШчЙћД§ЕїгУЕФ App вбОдЫааСЫЃЌФЧУДЫќЕФЩњУќжмЦкШчЯТЃК
ШчЙћД§ЕїгУЕФ App дкКѓЬЈЃЌФЧУДЫќЕФЩњУќжмЦкШчЯТЃК
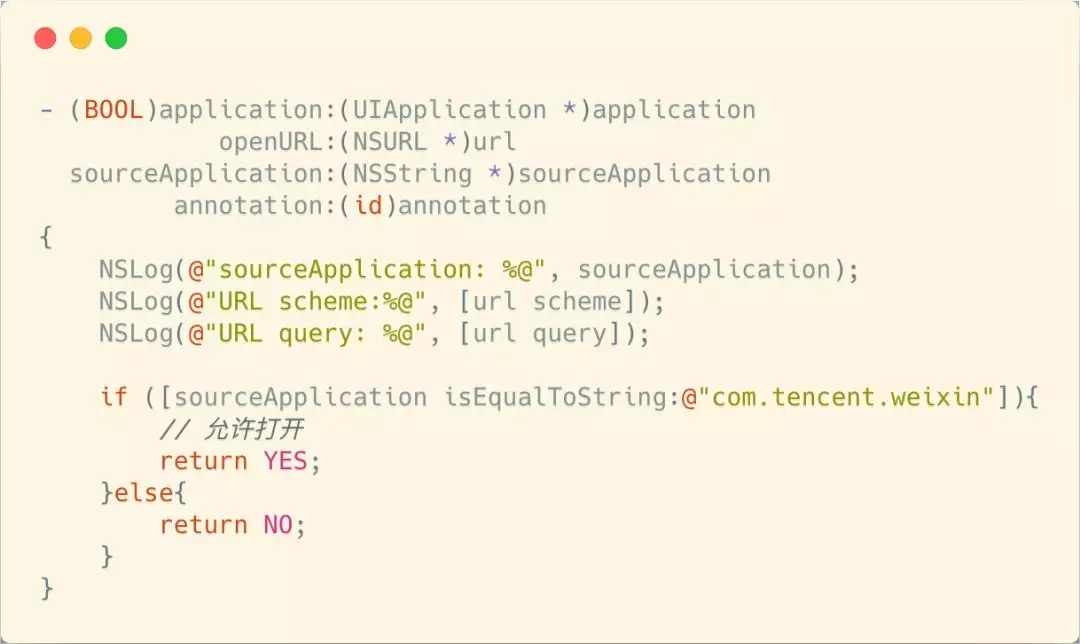
УїАзСЫЩЯУцЕФЩњУќжмЦкжЎКѓЃЌЮвУЧОЭПЩвдЭЈЙ§ЕїгУ application:openURL:sourceApplication:annotation:
етИіЗНЗЈЃЌРДзшжЙвЛаЉ App ЕФЫцвтЕїгУЁЃ
ШчЩЯЭМЃЌЖіСЫУД App дЪаэЭЈЙ§ URL Scheme ЕїгУЃЌФЧУДЮвУЧПЩвддк Safari РяУцЕїгУЕНЖіСЫУД
AppЁЃЪжЛњ QQ ВЛдЪаэЕїгУЃЌЮвУЧдк Safari РяУцвВОЭУЛЗЈЬјзЊЙ§ШЅЁЃ
Йигк App МфЕФЬјзЊЮЪЬтЃЌИааЫШЄЕФПЩвдВщПДЙйЗНЮФЕЕ Inter-App CommunicationЁЃ
AppвВЪЧПЩвджБНгЬјзЊЕНЯЕЭГЩшжУЕФЁЃБШШчгааЉашЧѓвЊЧѓМьВтгУЛЇгаУЛгаПЊЦєФГаЉЯЕЭГШЈЯоЃЌШчЙћУЛгаПЊЦєОЭЕЏПђЬсЪОЃЌЕуЛїЕЏПђЕФАДХЅжБНгЬјзЊЕНЯЕЭГЩшжУРяУцЖдгІЕФЩшжУНчУцЁЃ
2/Universal LinksЗНЪН
ЫфШЛдкЮЂаХФкВППЊЭјвГЛсНћжЙЫљгаЕФ SchemeЃЌЕЋЪЧ iOS 9.0 аТдіМгСЫвЛЯюЙІФмЪЧ Universal
LinksЃЌЪЙгУетИіЙІФмПЩвдЪЙЮвУЧЕФ App ЭЈЙ§ HTTP СДНгРДЦєЖЏ AppЁЃ
1ЁЂШчЙћАВзАЙ§ AppЃЌВЛЙмдкЮЂаХРяУц http СДНгЛЙЪЧдк Safari фЏРРЦїЃЌЛЙЪЧЦфЫћЕкШ§ЗНфЏРРЦїЃЌЖМПЩвдДђПЊ
AppЁЃ
2ЁЂШчЙћУЛгаАВзАЙ§ AppЃЌОЭЛсДђПЊЭјвГЁЃ
ОпЬхЩшжУашвЊ3ВНЃК
AppашвЊПЊЦє Associated Domains ЗўЮёЃЌВЂЩшжУ DomainsЃЌзЂвтБиаывЊ applinks:ПЊЭЗЁЃ
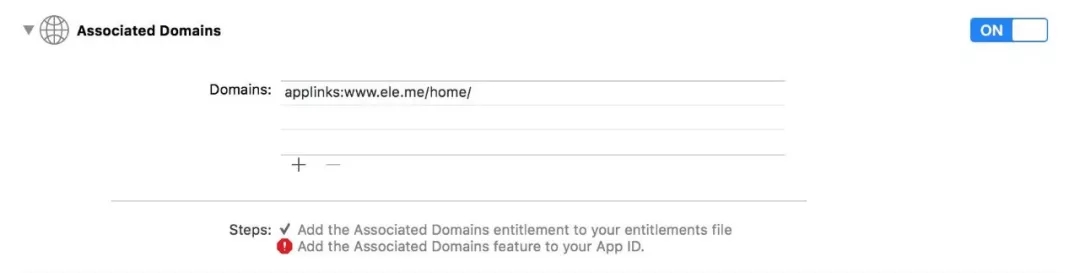
гђУћБиаывЊжЇГж HTTPSЁЃ
ЩЯДЋФкШнЪЧ Json ИёЪНЕФЮФМўЃЌЮФМўУћЮЊ apple-app-site-association
ЕНздМКгђУћЕФИљФПТМЯТЃЌЛђеп .well-known ФПТМЯТЁЃiOS здЖЏЛсШЅЖСШЁетИіЮФМўЁЃОпЬхЕФЮФМўФкШнЧыВщПДЙйЗНЮФЕЕЁЃ
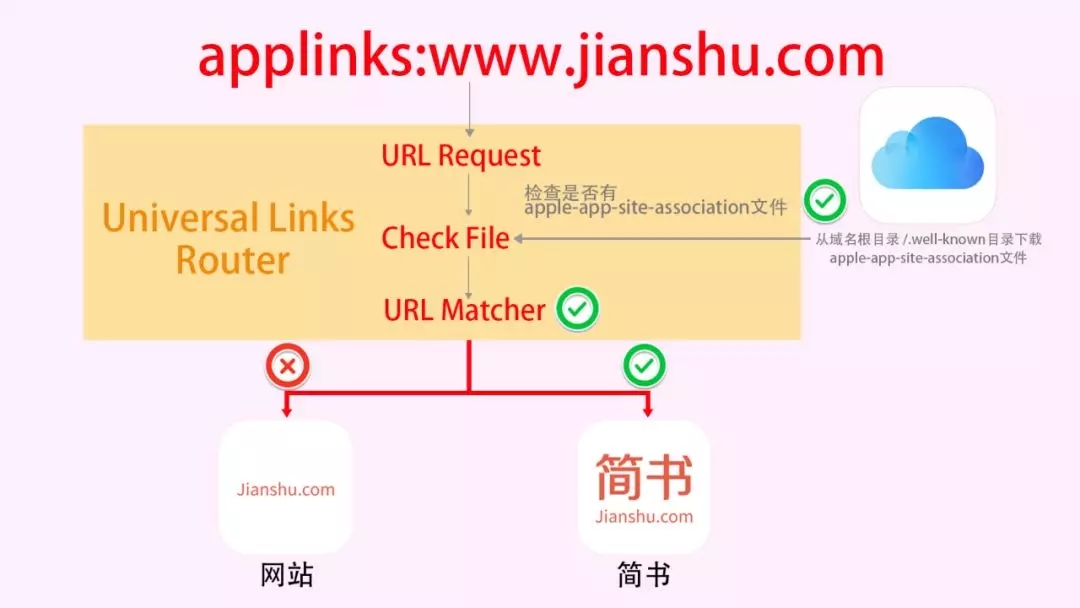
ШчЙћ App жЇГжСЫ Universal Links ЗНЪНЃЌФЧУДПЩвддкЦфЫћ App РяУцжБНгЬјзЊЕНЮвУЧздМКЕФ
App РяУцЁЃШчЯТЭМЃЌЕуЛїСДНгЃЌгЩгкИУСДНгЛс Matcher ЕНЮвУЧЩшжУЕФСДНгЃЌЫљвдВЫЕЅРяУцЛсЯдЪОгУЮвУЧЕФ
App ДђПЊЁЃ

дкфЏРРЦїРяУцвВЪЧвЛбљЕФаЇЙћЃЌШчЙћЪЧжЇГжСЫ Universal Links ЗНЪНЃЌЗУЮЪЯргІЕФ URLЃЌЛсгаВЛЭЌЕФаЇЙћЁЃШчЯТЭМЃК
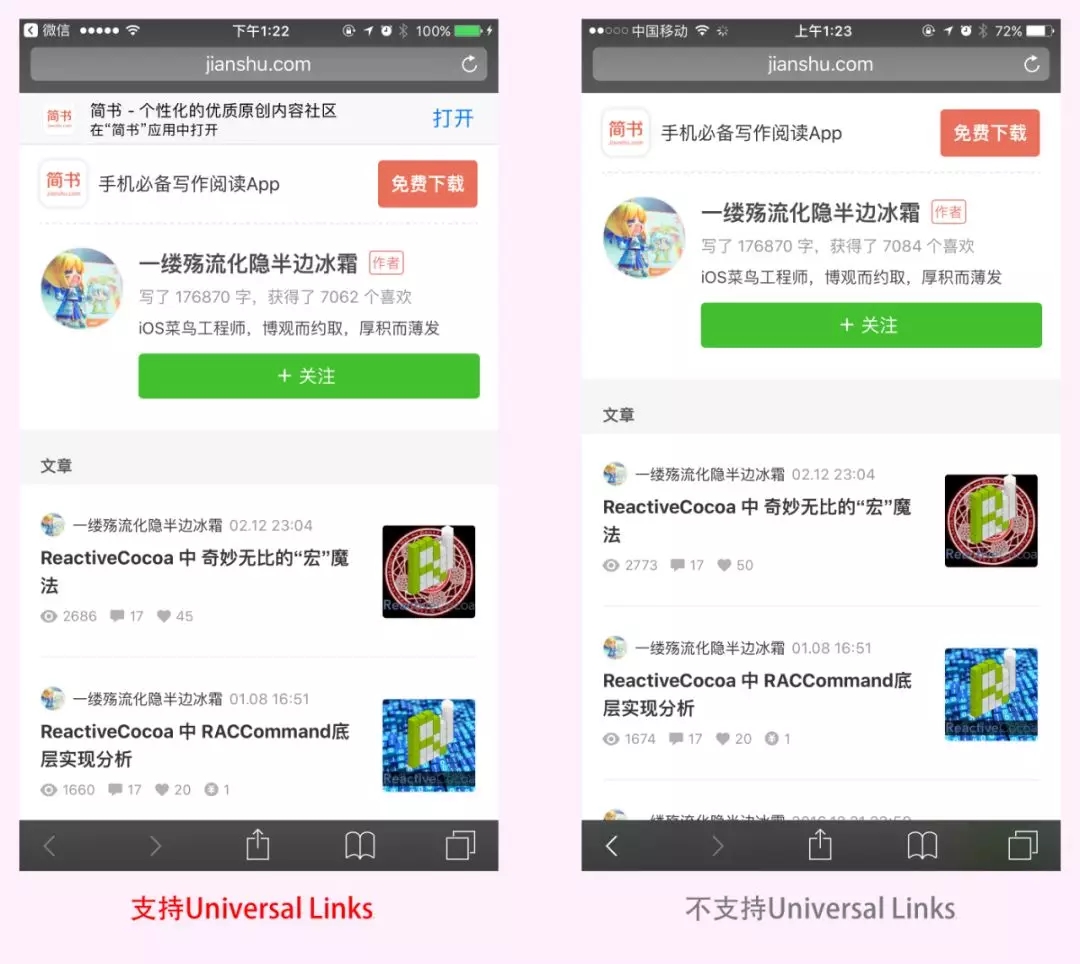
вдЩЯОЭЪЧ iOS ЯЕЭГжа App МфЬјзЊЕФЖўжжЗНЪНЁЃ
Дг iOS ЯЕЭГРяУцжЇГжЕФ URL Scheme ЗНЪНЃЌЮвУЧПЩвдПДГіЃЌЖдгквЛИізЪдДЕФЗУЮЪЃЌЦЛЙћвВЪЧгУ
URI ЕФЗНЪНРДЗУЮЪЕФЁЃ
ЭГвЛзЪдДБъЪЖЗћЃЈгЂгяЃКUniform Resource IdentifierЃЌЛђURI)ЪЧвЛИігУгкБъЪЖФГвЛЛЅСЊЭјзЪдДУћГЦЕФзжЗћДЎЁЃ
ИУжжБъЪЖдЪаэгУЛЇЖдЭјТчжаЃЈвЛАужИЭђЮЌЭјЃЉЕФзЪдДЭЈЙ§ЬиЖЈЕФавщНјааНЛЛЅВйзїЁЃURIЕФзюГЃМћЕФаЮЪНЪЧЭГвЛзЪдДЖЈЮЛЗћЃЈURLЃЉЁЃ
ОйИіР§згЃК

етЪЧвЛЖЮ URIЃЌУПвЛЖЮЖМДњБэСЫЖдгІЕФКЌвхЁЃЖдЗННгЪеЕНСЫетбљвЛДЎзжЗћДЎЃЌАДееЙцдђНтЮіГіРДЃЌОЭФмЛёШЁЕНЫљгаЕФгагУаХЯЂЁЃ
етИіФмИјЮвУЧЩшМЦ App зщМўМфЕФТЗгЩДјРДвЛаЉЫМТЗУДЃПШчЙћЮвУЧЯывЊЖЈвхвЛИіШ§ЖЫЃЈiOSЃЌAndroidЃЌH5ЃЉЕФЭГвЛЗУЮЪзЪдДЕФЗНЪНЃЌФмгУURIЕФетжжЗНЪНЪЕЯжУДЃП
ЫФЁЂAppФкзщМўМфТЗгЩЩшМЦ
ЩЯвЛеТНкжаЮвУЧНщЩмСЫ iOS ЯЕЭГжаЃЌЯЕЭГЪЧШчКЮАяЮвУЧДІРэ App МфЬјзЊТпМЕФЁЃетвЛеТНкЮвУЧзХжиЬжТлвЛЯТЃЌApp
ФкВПЃЌИїИізщМўжЎМфЕФТЗгЩгІИУдѕУДЩшМЦЁЃЙигк App ФкВПЕФТЗгЩЩшМЦЃЌжївЊашвЊНтОі2ИіЮЪЬтЃК
1ЁЂИїИівГУцКЭзщМўжЎМфЕФЬјзЊЮЪЬтЁЃ
2ЁЂИїИізщМўжЎМфЯрЛЅЕїгУЁЃ
ЯШРДЗжЮівЛЯТетСНИіЮЪЬтЁЃ
1ЁЂЙигквГУцЬјзЊ
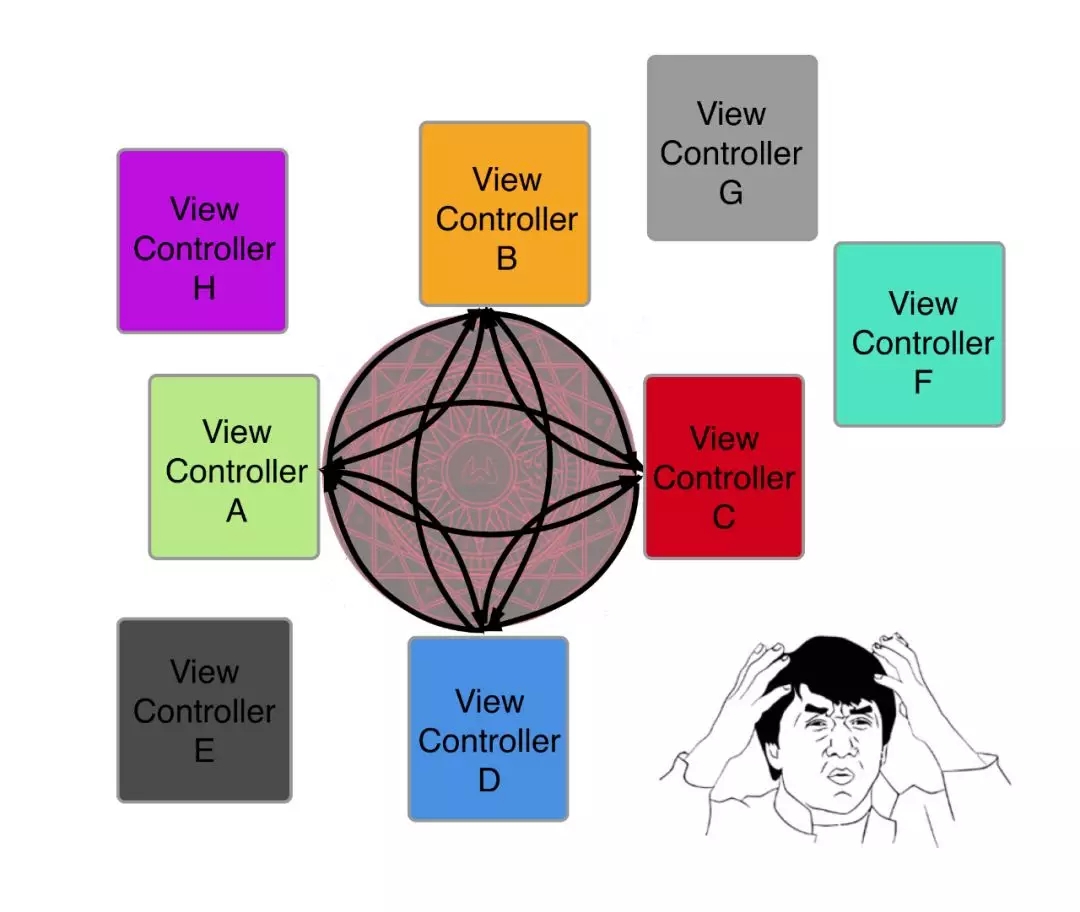
дк iOS ПЊЗЂЕФЙ§ГЬжаЃЌОГЃЛсгіЕНвдЯТЕФГЁОАЃЌЕуЛїАДХЅЬјзЊ Push ЕНСэЭтвЛИіНчУцЃЌЛђепЕуЛївЛИі
cell Present вЛИіаТЕФ ViewControllerЁЃдкMVCФЃЪНжаЃЌвЛАуЖМЪЧаТНЈвЛИі
VCЃЌШЛКѓ Push / Present ЕНЯТвЛИі VCЁЃЕЋЪЧдк MVVM жаЃЌЛсгавЛаЉВЛКЯЪЪЕФЧщПіЁЃ
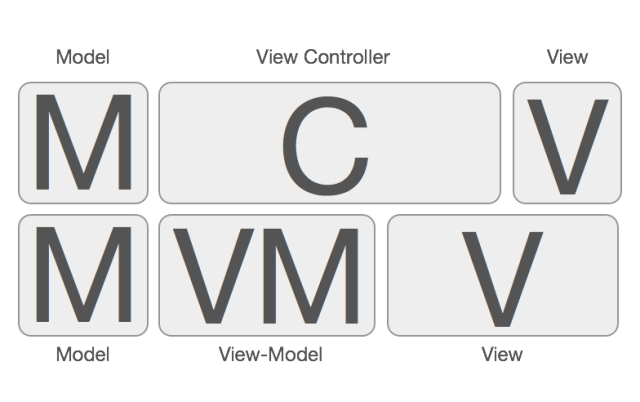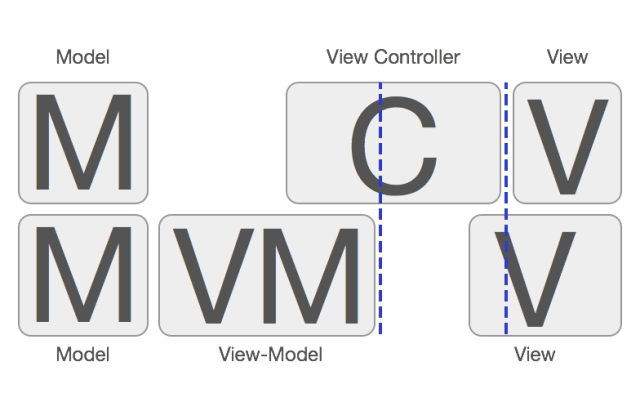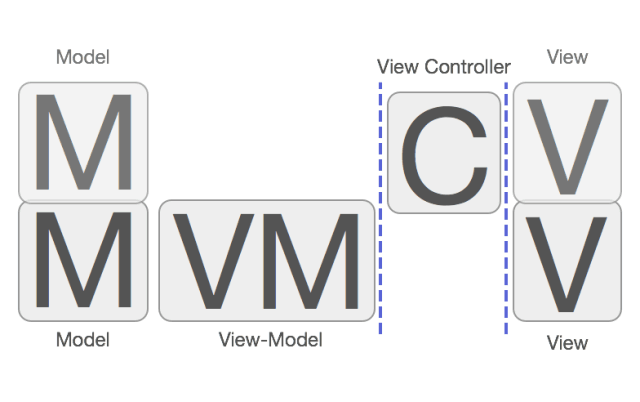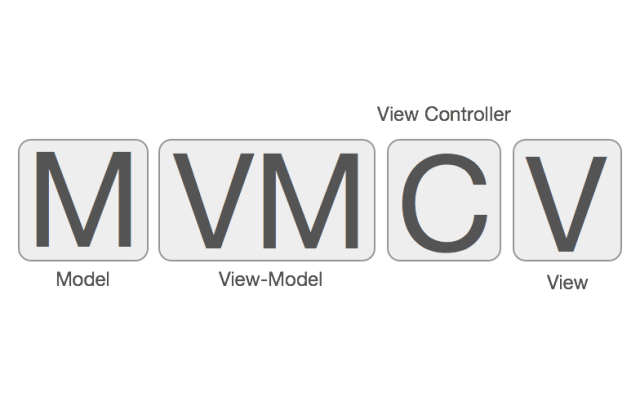
жкЫљжмжЊЃЌMVVM Аб MVC В№ГЩСЫЩЯЭМбнЪОЕФбљзгЃЌдРД View ЖдгІЕФгыЪ§ОнЯрЙиЕФДњТыЖМвЦЕН
ViewModel жаЃЌЯргІЕФ C вВБфЪнСЫЃЌбнБфГЩСЫ M-VM-C-V ЕФНсЙЙЁЃетРяЕФ C РяУцЕФДњТыПЩвджЛЪЃЯТвГУцЬјзЊЯрЙиЕФТпМЁЃШчЙћгУДњТыБэЪООЭЪЧЯТУцетбљзгЃК
МйЩшвЛИіАДХЅЕФжДааТпМЖМЗтзАГЩСЫ commandЁЃ
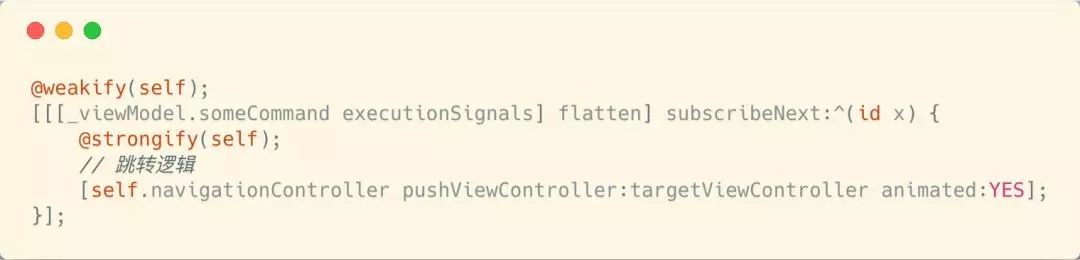
ЩЯЪіЕФДњТыБОЩэУЛЩЖЮЪЬтЃЌЕЋЪЧПЩФмЛсШѕЛЏ MVVM ПђМмЕФвЛИіживЊзїгУЁЃ
MVVM ПђМмЕФФПЕФГ§ШЅНтёювдЭтЃЌЛЙга 2 ИіКмживЊЕФФПЕФЃК
1ЁЂДњТыИпИДгУТЪ
2ЁЂЗНБуНјааЕЅдЊВтЪд
ШчЙћашвЊВтЪдвЛИівЕЮёЪЧЗёе§ШЗЃЌЮвУЧжЛвЊЖд ViewModel НјааЕЅдЊВтЪдМДПЩЁЃЧАЬсЪЧМйЖЈЮвУЧЪЙгУ
ReactiveCocoa Нјаа UI АѓЖЈЕФЙ§ГЬЪЧзМШЗЮоЮѓЕФЁЃФПЧААѓЖЈЪЧе§ШЗЕФЁЃЫљвдЮвУЧжЛашвЊЕЅдЊВтЪдЕН
ViewModel МДПЩЭъГЩвЕЮёТпМЕФВтЪдЁЃ
вГУцЬјзЊвВЪєгквЕЮёТпМЃЌЫљвдгІИУЗХдк ViewModel жавЛЦ№ЕЅдЊВтЪдЃЌБЃжЄвЕЮёТпМВтЪдЕФИВИЧТЪЁЃ
АбвГУцЬјзЊЗХЕН ViewModel жаЃЌга 2 жжзіЗЈЃЌЕквЛжжОЭЪЧгУТЗгЩРДЪЕЯжЃЌЕкЖўжжгЩгкКЭТЗгЩУЛгаЙиЯЕЃЌЫљвдетРяОЭВЛЖрВћЪіЃЌгааЫШЄЕФПЩвдПД
lpd-mvvm-kit етИіПтЙигквГУцЬјзЊЕФОпЬхЪЕЯжЁЃ
вГУцЬјзЊЯрЛЅЕФёюКЯадвВОЭЬхЯжГіРДСЫЃК
1ЁЂгЩгк pushViewController Лђеп presentViewControllerЃЌКѓУцЖМашвЊДјвЛИіД§ВйзїЕФ
ViewControllerЃЌФЧУДОЭБиаывЊв§ШыИУРрЃЌ import ЭЗЮФМўвВОЭв§ШыСЫёюКЯадЁЃ
2ЁЂгЩгкЬјзЊетРяаДЫРСЫЬјзЊВйзїЃЌШчЙћЯпЩЯвЛЕЉГіЯжСЫ bugЃЌетРяЪЧВЛЪмЮвУЧПижЦЕФЁЃ
3ЁЂЭЦЫЭЯћЯЂЛђепЪЧ 3D-Touch ашЧѓЃЌвЊЧѓжБНгЬјзЊЕНФкВПЕк 10 МЖНчУцЃЌФЧУДОЭашвЊаДвЛИіШыПкЬјзЊЕНжИЖЈНчУцЁЃ
2ЁЂЙигкзщМўМфЕїгУ
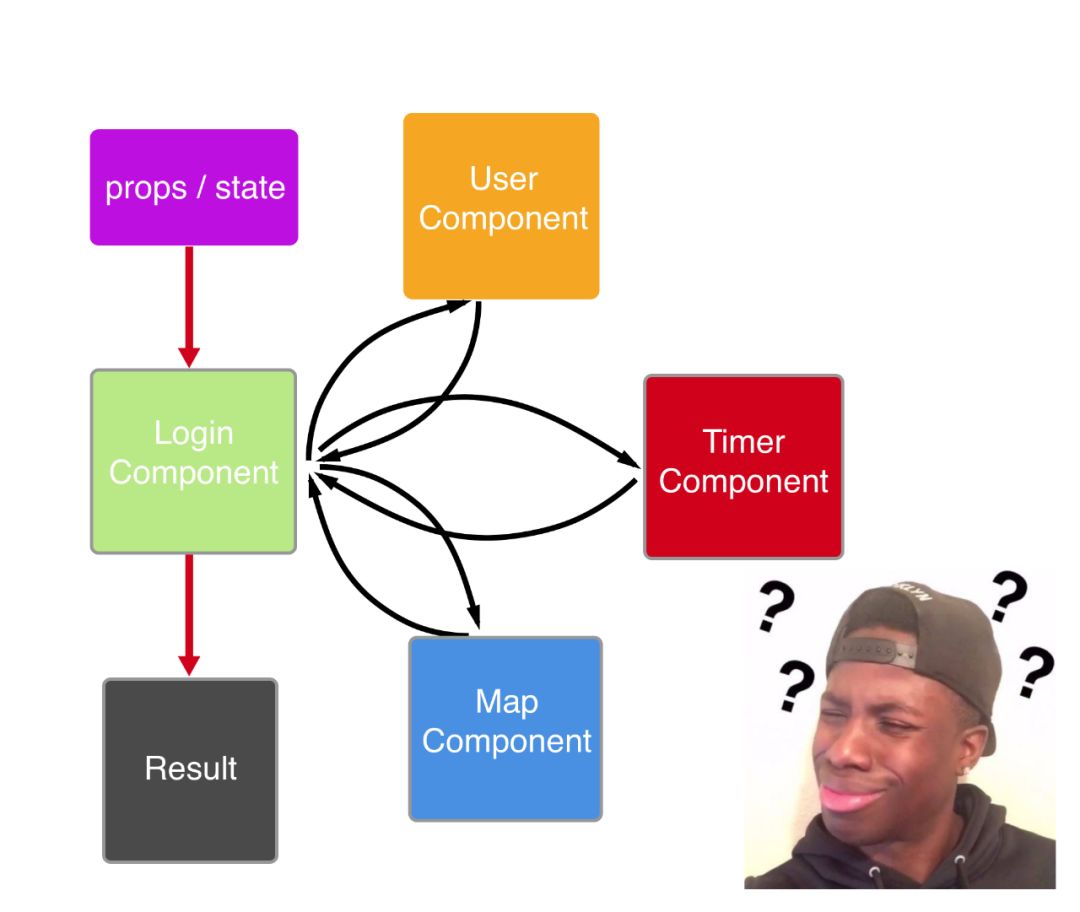
ЙигкзщМўМфЕФЕїгУЃЌвВашвЊНтёюЁЃЫцзХвЕЮёдНРДдНИДдгЃЌЮвУЧЗтзАЕФзщМўдНРДдНЖрЃЌвЊЪЧЗтзАЕФСЃЖШФУФѓВЛзМЃЌОЭЛсГіЯжДѓСПзщМўжЎМфёюКЯЖШИпЕФЮЪЬтЁЃзщМўЕФСЃЖШПЩвдЫцзХвЕЮёЕФЕїећЃЌВЛЖЯЕФЕїећзщМўжАд№ЕФЛЎЗжЁЃЕЋЪЧзщМўжЎМфЕФЕїгУвРОЩВЛПЩБмУтЃЌЯрЛЅЕїгУЖдЗНзщМўБЉТЖЕФНгПкЁЃШчКЮМѕЩйИїИізщМўжЎМфЕФёюКЯЖШЃЌЪЧвЛИіЩшМЦгХауЕФТЗгЩЕФжАд№ЫљдкЁЃ
3ЁЂШчКЮЩшМЦвЛИіТЗгЩ
ШчКЮЩшМЦвЛИіФмЭъУРНтОіЩЯЪі 2 ИіЮЪЬтЕФТЗгЩЃЌШУЮвУЧЯШРДПДПД GitHub ЩЯгХауПЊдДПтЕФЩшМЦЫМТЗЁЃвдЯТЪЧЮвДг
Github ЩЯУцевЕФвЛаЉТЗгЩЗНАИЃЌАДее Star ДгИпЕНЕЭХХСаЁЃвРДЮРДЗжЮівЛЯТЫќУЧИїздЕФЩшМЦЫМТЗЁЃ
ЃЈ1ЃЉJLRoutes Star 3189
JLRoutes дкећИі Github ЩЯУц Star зюЖрЃЌФЧОЭРДДгЫќРДЗжЮіЗжЮіЫќЕФОпЬхЩшМЦЫМТЗЁЃ
ЪзЯШ JLRoutes ЪЧЪм URL Scheme ЫМТЗЕФгАЯьЁЃЫќАбЫљгаЖдзЪдДЕФЧыЧѓПДГЩЪЧвЛИі URIЁЃ
ЪзЯШРДЪьЯЄвЛЯТ NSURLComponent ЕФИїИізжЖЮЃК

Note
The URLs employed by the NSURL class are described
in RFC 1808, RFC 1738, and RFC 2732.
JLRoutes ЛсДЋШыУПИізжЗћДЎЃЌЖМАДееЩЯУцЕФбљзгНјааЧаЗжДІРэЃЌЗжБ№ИљОн RFC ЕФБъзМЖЈвхЃЌШЁЕНИїИі
NSURLComponentЁЃ
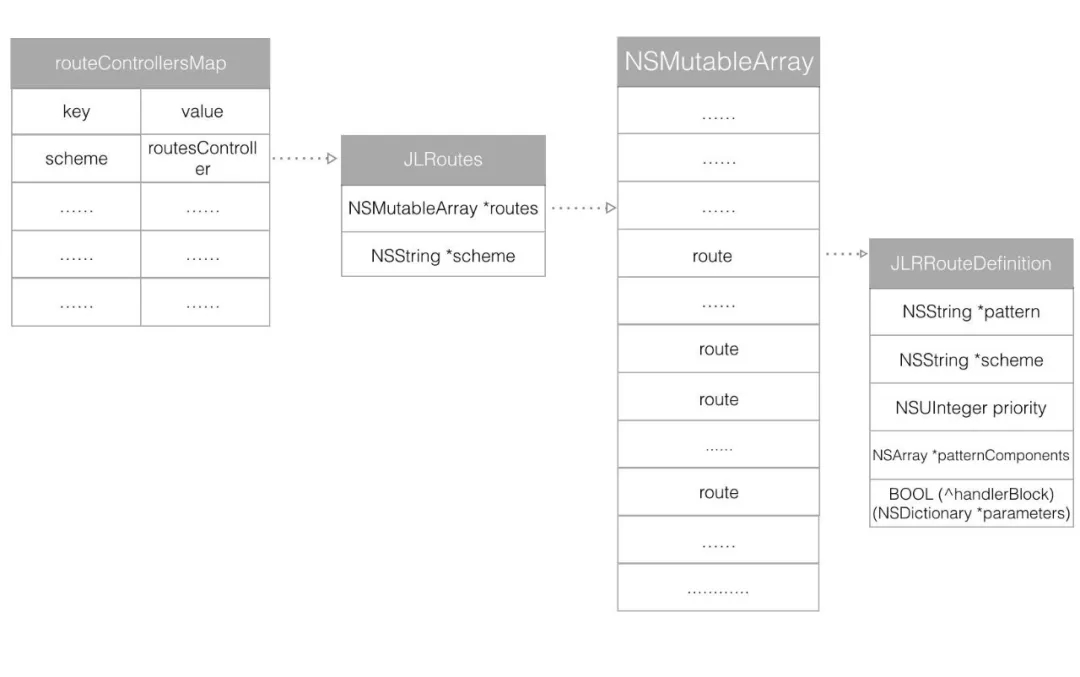
JLRoutes ШЋОжЛсБЃДцвЛИі MapЃЌетИі Map Лсвд scheme ЮЊ KeyЃЌJLRoutes
ЮЊ ValueЁЃЫљвддк routeControllerMap РяУцУПИі scheme ЖМЪЧЮЈвЛЕФЁЃ
жСгкЮЊКЮгаетУДЖрЬѕТЗгЩЃЌБЪепШЯЮЊЃЌШчЙћТЗгЩАДеевЕЮёЯпНјааЛЎЗжЕФЛАЃЌУПИівЕЮёЯпПЩФмЛсгаВЛЯрЭЌЕФТпМЃЌМДЪЙУПИівЕЮёРяУцЕФзщМўУћзжПЩФмЯрЭЌЃЌЕЋЪЧгЩгквЕЮёЯпВЛЭЌЃЌЛсгаВЛЭЌЕФТЗгЩЙцдђЁЃ
ОйИіР§згЃКШчЙћЕЮЕЮАДееУПИіГЧЪаЕФДђГЕвЕЮёНјаазщМўЛЏВ№ЗжЃЌФЧУДУПИіГЧЪаОЭЖдгІзХетРяЕФУПИі schemeЁЃУПИіГЧЪаЕФДђГЕвЕЮёЖМгаНаГЕЃЌИЖПюЁЁЕШвЕЮёЃЌЕЋЪЧгЩгкУПИіГЧЪаЕФЕиЗНЗЈЙцВЛЯрЭЌЃЌЫљвдетаЉзщМўМДЪЙУћзжЯрЭЌЃЌЕЋЪЧРяУцЕФЙІФмвВаэЧЇВюЭђБ№ЁЃЫљвдетРяЛЎЗжГіСЫЖрИі
routeЃЌвВПЩвдРэНтЮЊВЛЭЌЕФУќУћПеМфЁЃ
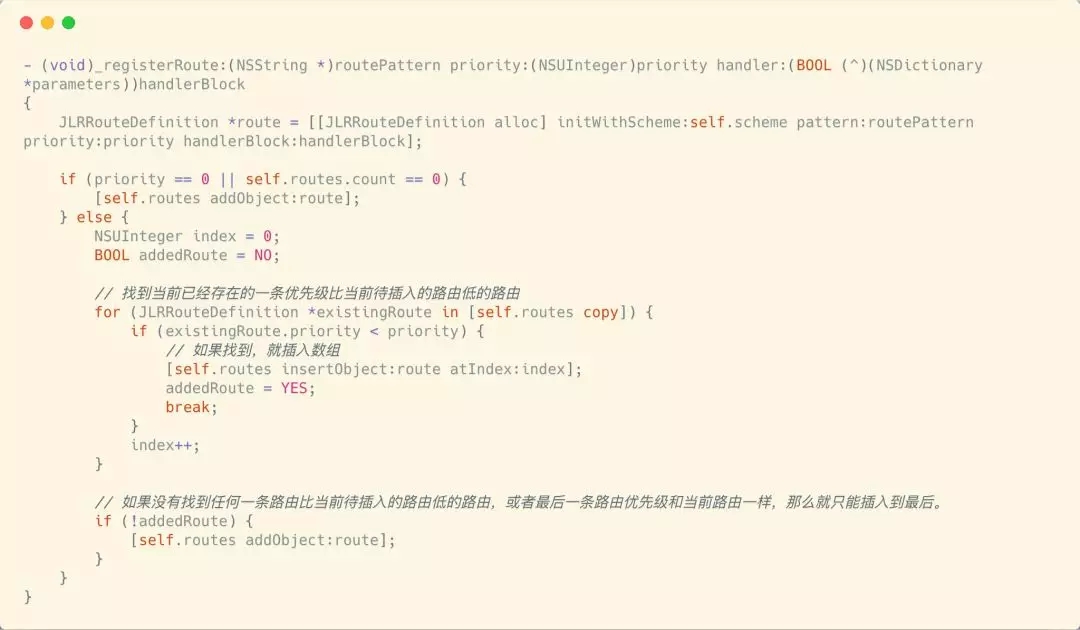
дкУПИі JLRoutes РяУцЖМБЃДцСЫвЛИіЪ§зщЃЌетИіЪ§зщРяУцБЃДцСЫУПИіТЗгЩЙцдђ JLRRouteDefinition
РяУцЛсБЃДцЭтВПДЋНјРДЕФ block БеАќЃЌ patternЃЌКЭВ№ЗжжЎКѓЕФ patternЁЃ
дкУПИі JLRoutes ЕФЪ§зщРяУцЃЌЛсАДееТЗгЩЕФгХЯШМЖНјааХХСаЃЌгХЯШМЖИпЕФХХСадкЧАУцЁЃ
гЩгкетИіЪ§зщРяУцЕФТЗгЩЪЧвЛИіЕЅЕїЖгСаЃЌЫљвдВщевгХЯШМЖЕФЪБКђжЛгУДгИпЭљЕЭБщРњМДПЩЁЃ
ОпЬхВщевТЗгЩЕФЙ§ГЬШчЯТЃК
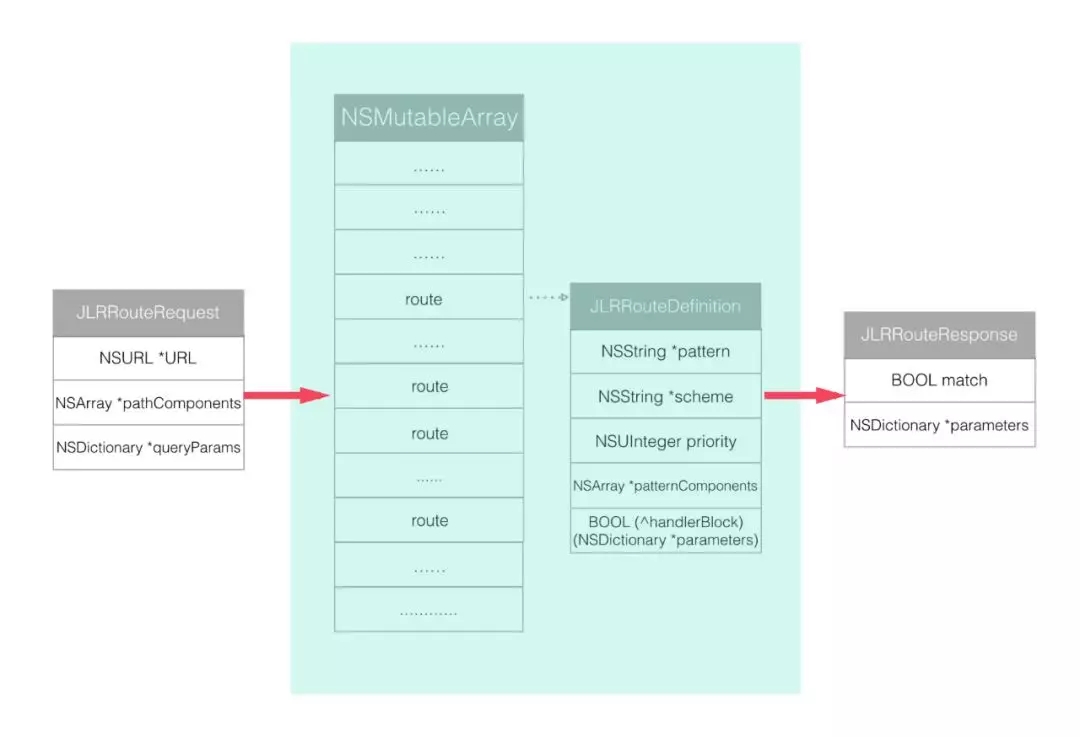
ЪзЯШИљОнЭтВПДЋНјРДЕФ URL ГѕЪМЛЏвЛИі JLRRouteRequestЃЌШЛКѓгУетИі JLRRouteRequest
дкЕБЧАЕФТЗгЩЪ§зщРяУцвРДЮ requestЃЌУПИіЙцдђЖМЛсЩњГЩвЛИі responseЃЌЕЋЪЧжЛгаЗћКЯЬѕМўЕФ
response ВХЛс matchЃЌзюКѓШЁГіЦЅХфЕФ JLRRouteResponse ФУГіЦфзжЕф parameters
РяУцЖдгІЕФВЮЪ§ОЭПЩвдСЫЁЃВщевКЭЦЅХфЙ§ГЬжаживЊЕФДњТыШчЯТЃК

ОйИіР§згЃК
ЮвУЧЯШзЂВсвЛИі RouterЃЌЙцдђШчЯТЃК

ЮвУЧДЋШывЛИі URLЃЌШУ Router НјааДІРэЁЃ

ЦЅХфГЩЙІжЎКѓЃЌЮвУЧЛсЕУЕНЯТУцетбљвЛИізжЕфЃК
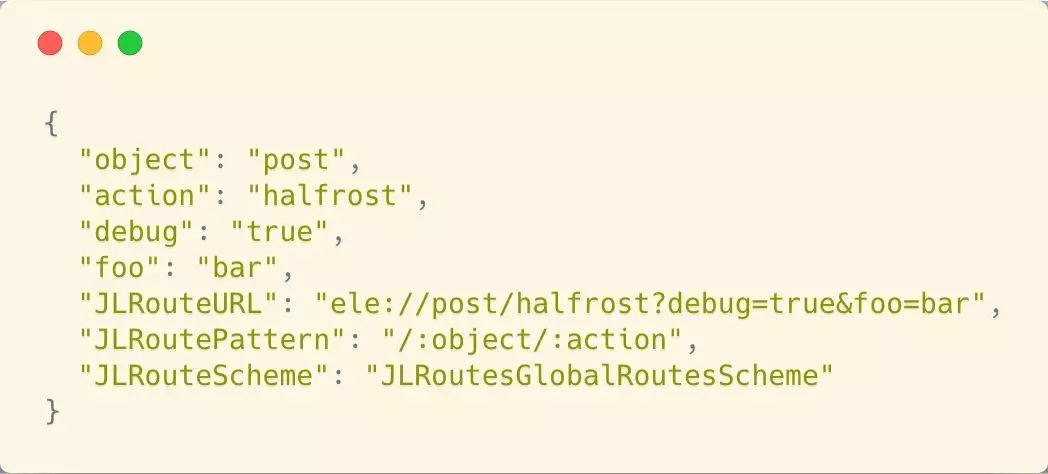
АбЩЯЪіЙ§ГЬЭМНтГіРДЃЌМћЯТЭМЃК
JLRoutes ЛЙПЩвджЇГж Optional ЕФТЗгЩЙцдђЃЌМйШчЖЈвхвЛЬѕТЗгЩЙцдђЃК
JLRoutes ЛсАяЮвУЧФЌШЯзЂВсШчЯТ 4 ЬѕТЗгЩЙцдђЃК
/the/foo/:a/bar/:b
/the/foo/:a
/the/bar/:b
/the |
ЃЈ2ЃЉroutable-ios Star 1415
Routable ТЗгЩЪЧгУдк in-app native ЖЫЕФ URL router, ЫќПЩвдгУдк
iOS ЩЯвВПЩвдгУдк Android ЩЯЁЃ
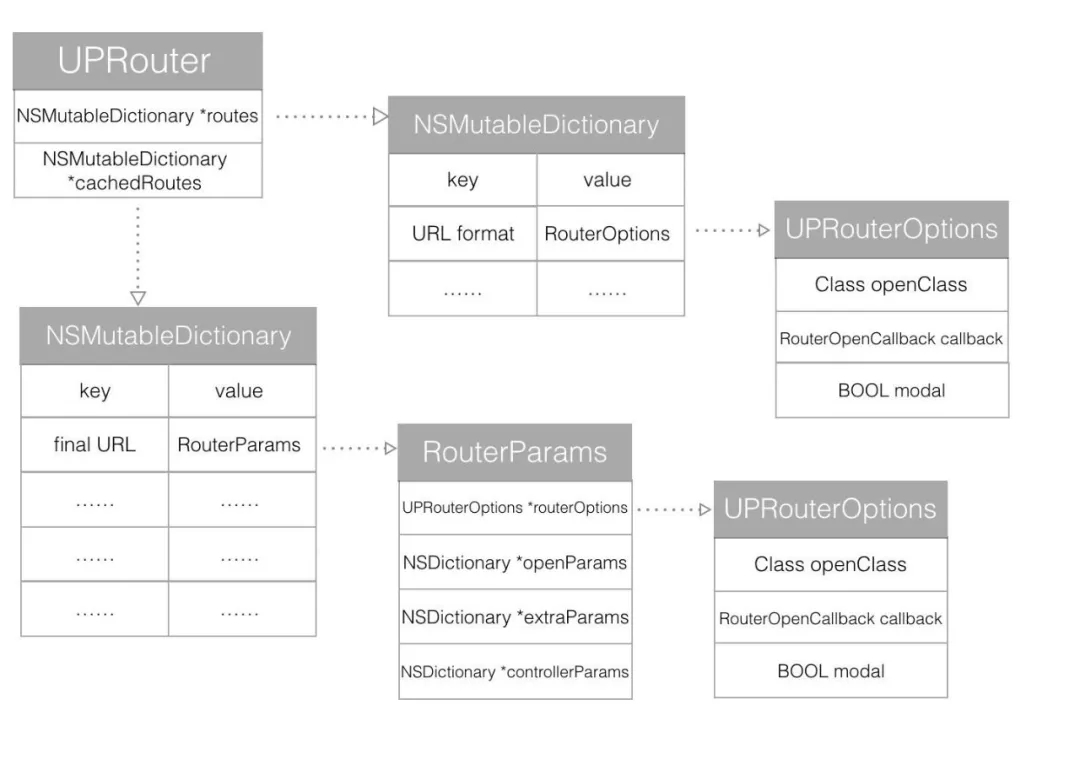
UPRouter РяУцБЃДцСЫ 2 ИізжЕфЁЃroutes зжЕфРяУцДцДЂЕФ Key ЪЧТЗгЩЙцдђЃЌValue
ДцДЂЕФЪЧ UPRouterOptionsЁЃcachedRoutes РяУцДцДЂЕФ Key ЪЧзюжеЕФ URLЃЌДјДЋВЮЕФЃЌValue
ДцДЂЕФЪЧ RouterParamsЁЃRouterParams РяУцЛсАќКЌдк routes ЦЅХфЕФЕНЕФ
UPRouterOptionsЃЌЛЙгаЖюЭтЕФДђПЊВЮЪ§ openParams КЭвЛаЉЖюЭтВЮЪ§ extraParamsЁЃ

етвЛЖЮДњТыРяУцжиЕудкИЩвЛМўЪТЧщЃЌБщРњ routes зжЕфЃЌШЛКѓевЕНВЮЪ§ЦЅХфЕФзжЗћДЎЃЌЗтзАГЩ RouterParams
ЗЕЛиЁЃ
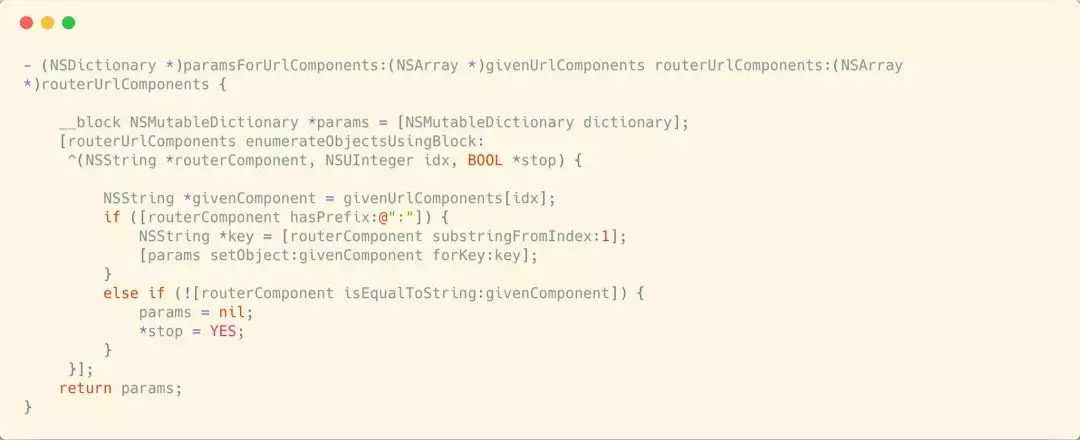
ЩЯУцетЖЮКЏЪ§ЃЌЕквЛИіВЮЪ§ЪЧЭтВПДЋНјРДURLДјгаИїИіШыВЮЕФЗжИюЪ§зщЁЃЕкЖўИіВЮЪ§ЪЧТЗгЩЙцдђЗжИюПЊЕФЪ§зщЁЃrouterComponentгЩгкЙцЖЈЃККХКѓУцВХЪЧВЮЪ§ЃЌЫљвдrouterComponentЕФЕк1ИіЮЛжУОЭЪЧЖдгІЕФВЮЪ§УћЁЃparamsзжЕфРяУцвдВЮЪ§УћЮЊKeyЃЌВЮЪ§ЮЊValueЁЃ

зюКѓЭЈЙ§RouterParamsЕФГѕЪМЛЏЗНЗЈЃЌАбТЗгЩЙцдђЖдгІЕФUPRouterOptionsЃЌЩЯвЛВНЗтзАКУЕФВЮЪ§зжЕфgivenParamsЃЌЛЙга
routerParamsForUrl: extraParams:
ЗНЗЈЕФЕкЖўИіШыВЮЃЌет3ИіВЮЪ§зїЮЊГѕЪМЛЏВЮЪ§ЃЌЩњГЩСЫвЛИіRouterParamsЁЃ
| [self.cachedRoutes
setObject:openParams forKey:url]; |
зюКѓвЛВНself.cachedRoutesЕФзжЕфРяУцKeyЮЊДјВЮЪ§ЕФURLЃЌValueЪЧRouterParamsЁЃ
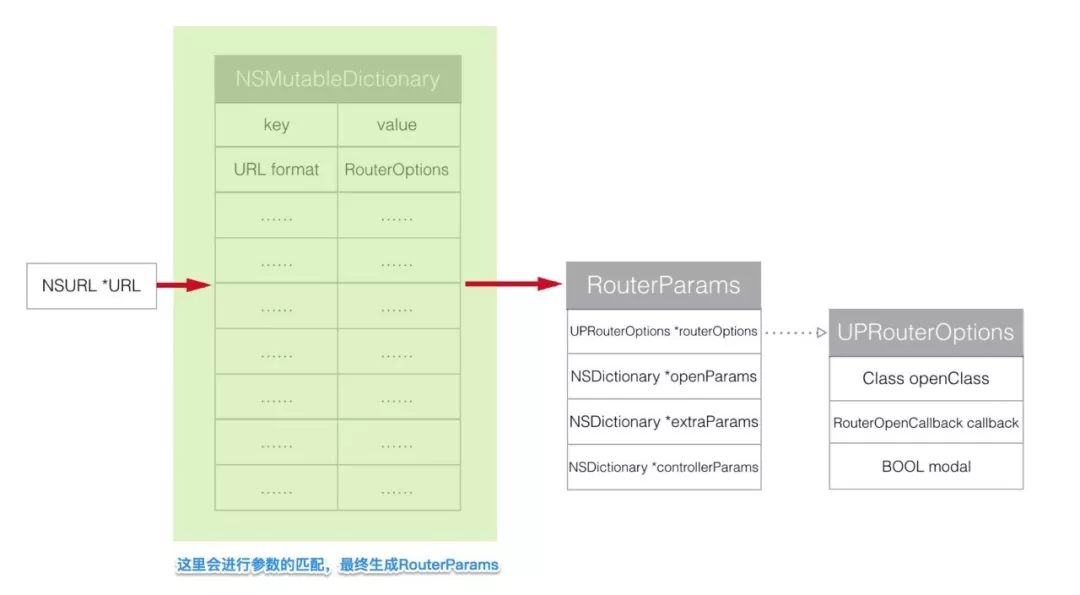
зюКѓНЋЦЅХфЗтзАГіРДЕФRouterParamsзЊЛЛГЩЖдгІЕФControllerЁЃ
ШчЙћControllerЪЧвЛИіРрЃЌФЧУДОЭЕїгУallocWithRouterParams:ЗНЗЈШЅГѕЪМЛЏЁЃШчЙћControllerвбОЪЧвЛИіЪЕР§СЫЃЌФЧУДОЭЕїгУinitWithRouterParams:ЗНЗЈШЅГѕЪМЛЏЁЃ
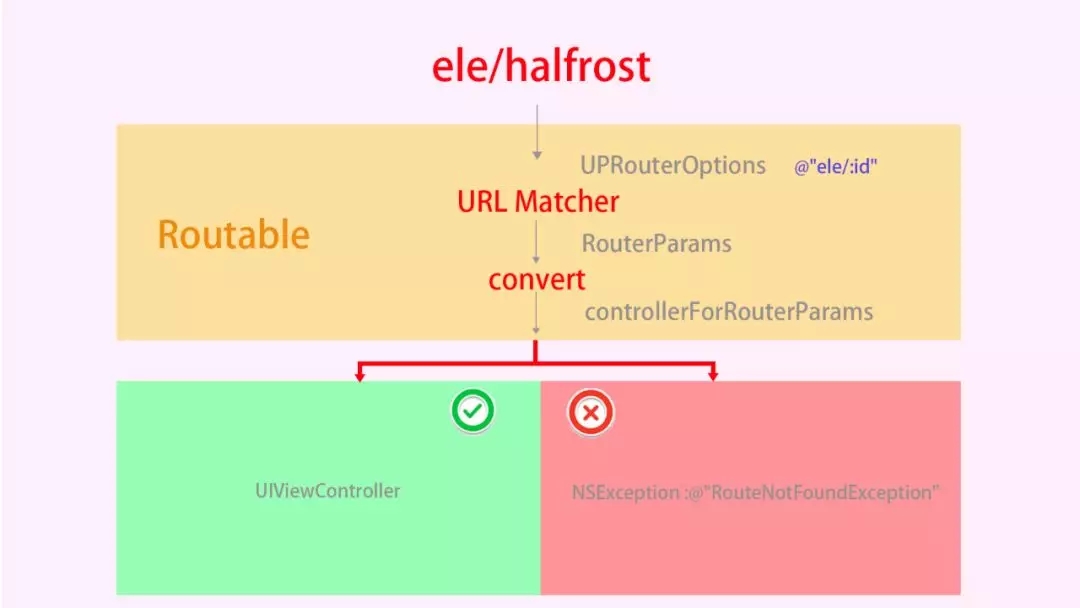
НЋRoutableЕФДѓжТСїГЬЭМНтШчЯТЃК
ЃЈ3ЃЉHHRouter Star 1277
етЪЧВМЖЁЖЏЛЕФвЛИіRouterЃЌСщИаРДздгк ABRouter КЭ Routable iOSЁЃ
ЯШРДПДПДHHRouterЕФApiЁЃЫќЬсЙЉЕФЗНЗЈЗЧГЃЧхЮњЁЃ
ViewControllerЬсЙЉСЫ2ИіЗНЗЈЁЃmapЪЧгУРДЩшжУТЗгЩЙцдђЃЌmatchControllerЪЧгУРДЦЅХфТЗгЩЙцдђЕФЃЌЦЅХфељШЁжЎКѓЗЕЛиЖдгІЕФUIViewControllerЁЃ

blockБеАќЬсЙЉСЫШ§ИіЗНЗЈЃЌmapвВЪЧЩшжУТЗгЩЙцдђЃЌmatchBlockЃКЪЧгУРДЦЅХфТЗгЩЃЌевЕНжИЖЈЕФblockЃЌЕЋЪЧВЛЛсЕїгУИУblockЁЃcallBlock:ЪЧевЕНжИЖЈЕФblockЃЌевЕНвдКѓОЭСЂМДЕїгУЁЃ

matchBlock:КЭcallBlock:ЕФЧјБ№ОЭдкгкЧАепВЛЛсздЖЏЕїгУБеАќЁЃЫљвдmatchBlock:ЗНЗЈевЕНЖдгІЕФblockжЎКѓЃЌШчЙћЯыЕїгУЃЌашвЊЪжЖЏЕїгУвЛДЮЁЃ
Г§ШЅЩЯУцетаЉЗНЗЈЃЌHHRouterЛЙЮЊЮвУЧЬсЙЉСЫвЛИіЬиЪтЕФЗНЗЈЁЃ
| - (HHRouteType)canRoute:(NSString
*)route; |
етИіЗНЗЈОЭЪЧгУРДевЕНжДааТЗгЩЙцдђЖдгІЕФRouteTypeЃЌRouteTypeзмЙВОЭ3жж:
typedef NS_ENUM
(NSInteger, HHRouteType) {
HHRouteTypeNone = 0,
HHRouteTypeViewController = 1,
HHRouteTypeBlock = 2
}; |
дйРДПДПДHHRouterЪЧШчКЮЙмРэТЗгЩЙцдђЕФЁЃећИіHHRouterОЭЪЧгЩвЛИіNSMutableDictionary
*routesПижЦЕФЁЃ

Б№ПДжЛгаетвЛИіПДЫЦЁАМђЕЅЁБЕФзжЕфЪ§ОнНсЙЙЃЌЕЋЪЧHHRouterТЗгЩЩшМЦЕФЛЙЪЧКмОЋУюЕФЁЃ
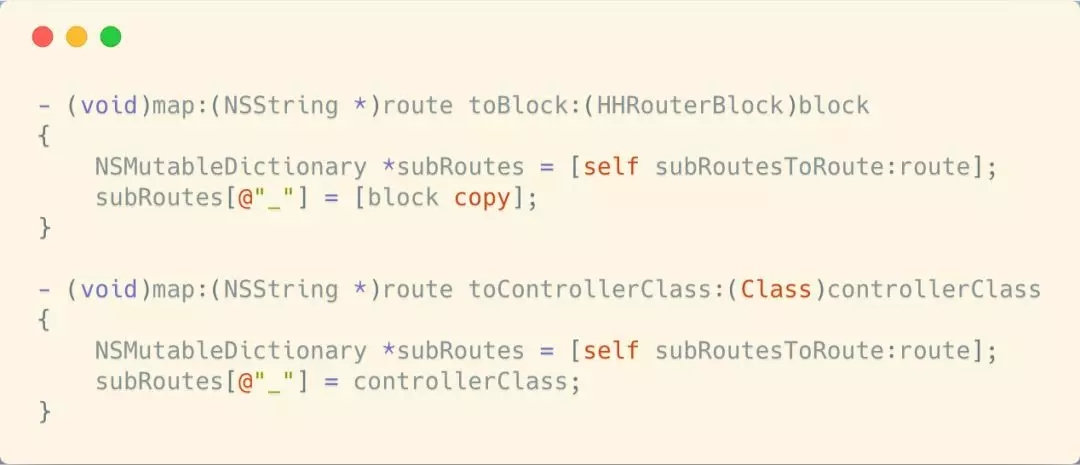
ЩЯУцСНИіЗНЗЈЗжБ№ЪЧblockБеАќКЭViewControllerЩшжУТЗгЩЙцдђЕїгУЕФЗНЗЈЪЕЬхЁЃВЛЙмЪЧViewControllerЛЙЪЧblockБеАќЃЌЩшжУЙцдђЕФЪБКђЖМЛсЕїгУsubRoutesToRoute:ЗНЗЈЁЃ

ЩЯУцетЖЮКЏЪ§ОЭЪЧРДЙЙдьТЗгЩЦЅХфЙцдђЕФзжЕфЁЃ
ОйИіР§згЃК

ЩшжУ3ЬѕЙцдђвдКѓЃЌАДееЩЯУцЙЙдьТЗгЩЦЅХфЙцдђЕФзжЕфЕФЗНЗЈЃЌИУТЗгЩЙцдђзжЕфОЭЛсБфГЩетИібљзгЃК

ТЗгЩЙцдђзжЕфЩњГЩжЎКѓЃЌЕШЕНЦЅХфЕФЪБКђОЭЛсБщРњетИізжЕфЁЃ
МйЩшетЪБКђгавЛЬѕТЗгЩЙ§РДЃК
| [[[HHRouter
shared] matchController:@"hhrouter20://user/1/"]
class], |
HHRouterЖдетЬѕТЗгЩЕФДІРэЗНЪНЪЧЯШЦЅХфЧАУцЕФschemeЃЌШчЙћСЌschemeЖМВЛе§ШЗЕФЛАЃЌЛсжБНгЕМжТКѓУцЦЅХфЪЇАмЁЃ
ШЛКѓдйНјааТЗгЩЦЅХфЃЌзюКѓЩњГЩЕФВЮЪ§зжЕфШчЯТЃК
{
"controller_class"
= UserViewController;
route = "/user/1/";
userId = 1;
} |
ОпЬхЕФТЗгЩВЮЪ§ЦЅХфЕФКЏЪ§дк
| - (NSDictionary
*)paramsInRoute:(NSString *)r |
етИіЗНЗЈРяУцЪЕЯжЕФЁЃетИіЗНЗЈОЭЪЧАДееТЗгЩЦЅХфЙцдђЃЌАбДЋНјРДЕФURLЕФВЮЪ§ЖМвЛвЛНтЮіГіРДЃЌДјЃПКХЕФвВЖМЛсНтЮіГЩзжЕфЁЃетИіЗНЗЈУЛЪВУДФбЖШЃЌОЭВЛдкзИЪіСЫЁЃ
ViewController ЕФзжЕфРяУцФЌШЯЛЙЛсМгЩЯ2ЯюЃК
"controller_class"
=
route = |
routeРяУцЖМЛсБЃДцДЋЙ§РДЕФЭъећЕФURLЁЃ
ШчЙћДЋНјРДЕФТЗгЩКѓУцДјЗУЮЪзжЗћДЎФиЃПФЧЮвУЧдйРДПДПДЃК
| [[HHRouter shared]
matchController:@"/user/1/?a=b&c=d"] |
ФЧУДНтЮіГіЫљгаЕФВЮЪ§зжЕфЛсЪЧЯТУцЕФбљзгЃК
{
a = b;
c = d;
"controller_class" = UserViewController;
route = "/user/1/?a=b&c=d";
userId = 1;
} |
ЭЌРэЃЌШчЙћЪЧвЛИіblockБеАќЕФЧщПіФиЃП
ЛЙЪЧЯШЬэМгвЛЬѕblockБеАќЕФТЗгЩЙцдђЃК
[[HHRouter shared]
map:@"/user/add/"
toBlock:^id(NSDictionary* params) {
}]; |
етЬѕЙцдђЖдгІЕФЛсЩњГЩвЛИіТЗгЩЙцдђЕФзжЕфЁЃ
{
story = {
":storyId" = {
"_"
= StoryViewController;
};
};
user = {
":userId" = {
"_"
= UserViewController;
story = {
"_" = StoryListViewController;
};
};
add = {
"_" = "<__NSMallocBlock__:
0x600000240480>";
};
};
} |
зЂвтЁБ_ЁБКѓУцИњзХЪЧвЛИіblockЁЃ
ЦЅХфblockБеАќЕФЗНЪНгаСНжжЁЃ

ЦЅХфГіРДЕФВЮЪ§зжЕфЪЧШчЯТЃК
{
a = 1;
b = 2;
block = "<__NSMallocBlock__: 0x600000056b90>";
route = "/user/add/?a=1&b=2";
} |
blockЕФзжЕфРяУцЛсФЌШЯМгЩЯЯТУцет2ЯюЃК
routeРяУцЖМЛсБЃДцДЋЙ§РДЕФЭъећЕФURLЁЃ
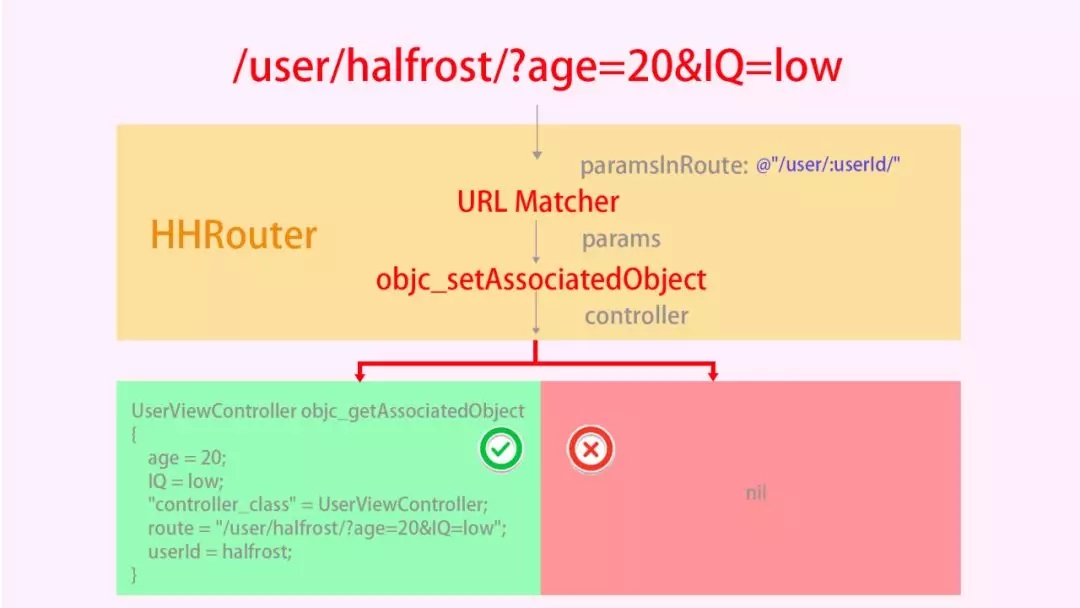
ЩњГЩЕФВЮЪ§зжЕфзюжеЛсБЛАѓЖЈЕНViewControllerЕФAssociated ObjectЙиСЊЖдЯѓЩЯЁЃ

етИіАѓЖЈЕФЙ§ГЬЪЧдкmatchЦЅХфЭъГЩЕФЪБКђНјааЕФЁЃ

зюжеЕУЕНЕФViewControllerвВЪЧЮвУЧЯывЊЕФЁЃЯргІЕФВЮЪ§ЖМдкЫќАѓЖЈЕФparamsЪєадЕФзжЕфРяУцЁЃ
НЋЩЯЪіЙ§ГЬЭМНтГіРДЃЌШчЯТЃК
ЃЈ4ЃЉMGJRouter Star 633
етЪЧФЂЙННжЕФвЛИіТЗгЩЕФЗНЗЈЁЃ
етИіПтЕФгЩРДЃК
JLRoutes ЕФЮЪЬтжївЊдкгкВщев URL ЕФЪЕЯжВЛЙЛИпаЇЃЌЭЈЙ§БщРњЖјВЛЪЧЦЅХфЁЃЛЙгаОЭЪЧЙІФмЦЋЖрЁЃ
HHRouter ЕФ URL ВщевЪЧЛљгкЦЅХфЃЌЫљвдЛсИќИпаЇЃЌMGJRouter вВЪЧВЩгУЕФетжжЗНЗЈЃЌЕЋЫќИњ
ViewController АѓЖЈЕиЙ§гкНєУмЃЌвЛЖЈГЬЖШЩЯНЕЕЭСЫСщЛюадЁЃ
гкЪЧОЭгаСЫ MGJRouterЁЃ
ДгЪ§ОнНсЙЙРДПДЃЌMGJRouterЛЙЪЧКЭHHRouterвЛФЃвЛбљЕФЁЃ
@interface MGJRouter
()
@property (nonatomic) NSMutableDictionary *routes;
@end |

ФЧУДЮвУЧОЭРДПДПДЫќЖдHHRouterзіСЫФФаЉгХЛЏИФНјЁЃ
1ЁЂMGJRouterжЇГжopenURLЪБЃЌПЩвдДЋвЛаЉ userinfo
Й§ШЅ
[MGJRouter openURL:@"mgj://category/travel"
withUserInfo:@{@"user_id": @1900}
completion:nil]; |
етИіЖдБШHHRouterЃЌНіНіжЛЪЧаДЗЈЩЯЕФвЛИігяЗЈЬЧЃЌдкHHRouterжаЫфШЛВЛжЇГжДјзжЕфЕФВЮЪ§ЃЌЕЋЪЧдкURLКѓУцПЩвдгУURL
Query ParameterРДУжВЙЁЃ

MGJRouterЖдuserInfoЕФДІРэЪЧжБНгАбЫќЗтзАЕНKey = MGJRouterParameterUserInfoЖдгІЕФValueРяУцЁЃ
2ЁЂжЇГжжаЮФЕФURLЁЃ

етРяОЭЪЧашвЊзЂвтвЛЯТБрТыЁЃ
3ЁЂЖЈвхвЛИіШЋОжЕФ URL Pattern зїЮЊ FallbackЁЃ
етвЛЕуЪЧФЃЗТЕФJLRoutesЕФЦЅХфВЛЕНЛсздЖЏНЕМЖЕНglobalЕФЫМЯыЁЃ
if (parameters)
{
MGJRouterHandler handler = parameters[@"block"];
if (handler) {
[parameters removeObjectForKey:@"block"];
handler(parameters);
}
} |
parametersзжЕфРяУцЛсЯШДцДЂЯТвЛИіТЗгЩЙцдђЃЌДцдкblockБеАќжаЃЌдкЦЅХфЕФЪБКђЛсШЁГіетИіhandlerЃЌНЕМЖЦЅХфЕНетИіБеАќжаЃЌНјаазюжеЕФДІРэЁЃ
4ЁЂЕБ OpenURL НсЪјЪБЃЌПЩвджДаа Completion BlockЁЃ
дкMGJRouterРяУцЃЌзїепЖддРДЕФHHRouterзжЕфРяУцДцДЂЕФТЗгЩЙцдђЕФНсЙЙНјааСЫИФдьЁЃ

ет3ИіkeyЛсЗжБ№БЃДцвЛаЉаХЯЂЃК
MGJRouterParameterURLБЃДцЕФДЋНјРДЕФЭъећЕФURLаХЯЂЁЃ
MGJRouterParameterCompletionБЃДцЕФЪЧcompletionБеАќЁЃ
MGJRouterParameterUserInfoБЃДцЕФЪЧUserInfoзжЕфЁЃ
ОйИіР§згЃК
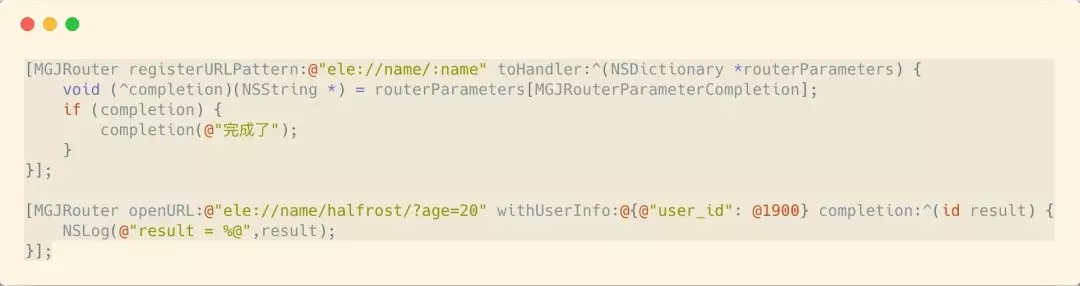
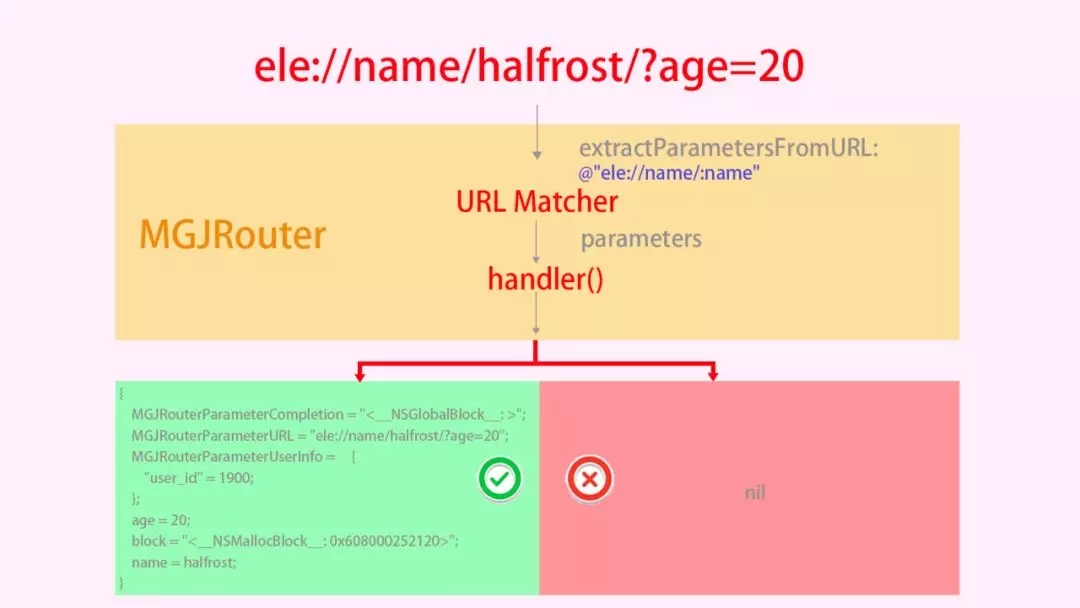
ЩЯУцЕФURLЛсЦЅХфГЩЙІЃЌФЧУДЩњГЩЕФВЮЪ§зжЕфНсЙЙШчЯТЃК

5ЁЂПЩвдЭГвЛЙмРэURL
етИіЙІФмЗЧГЃгагУЁЃ
URL ЕФДІРэвЛВЛаЁаФЃЌОЭШнвзЩЂТфдкЯюФПЕФИїИіНЧТфЃЌВЛШнвзЙмРэЁЃБШШчзЂВсЪБЕФ pattern ЪЧ
mgj://beauty/:idЃЌШЛКѓ open ЪБОЭЪЧ mgj://beauty/123ЃЌетбљЕНЪБКђ
url гаИФЖЏЃЌДІРэЦ№РДОЭЛсКмТщЗГЃЌВЛКУЭГвЛЙмРэЁЃ
Ыљвд MGJRouter ЬсЙЉСЫвЛИіРрЗНЗЈРДДІРэетИіЮЪЬтЁЃ

generateURLWithPattern:КЏЪ§ЛсЖдЮвУЧЖЈвхЕФКъРяУцЕФЫљгаЕФ:НјааЬцЛЛЃЌЬцЛЛГЩКѓУцЕФзжЗћДЎЪ§зщЃЌвРДЮИГжЕЁЃ
НЋЩЯЪіЙ§ГЬЭМНтГіРДЃЌШчЯТЃК
ФЂЙННжЮЊСЫЧјЗжПЊвГУцМфЕїгУКЭзщМўМфЕїгУЃЌгкЪЧЯыГіСЫвЛжжаТЕФЗНЗЈЁЃгУProtocolЕФЗНЗЈРДНјаазщМўМфЕФЕїгУЁЃ
УПИізщМўжЎМфЖМгавЛИі EntryЃЌетИі EntryЃЌжївЊзіСЫШ§МўЪТЃК
1ЁЂзЂВсетИізщМўЙиаФЕФ URL
2ЁЂзЂВсетИізщМўФмЙЛБЛЕїгУЕФЗНЗЈ/Ъєад
3ЁЂдк App ЩњУќжмЦкЕФВЛЭЌНзЖЮзіВЛЭЌЕФЯьгІ
вГУцМфЕФopenURLЕїгУОЭЪЧШчЯТЕФбљзгЃК
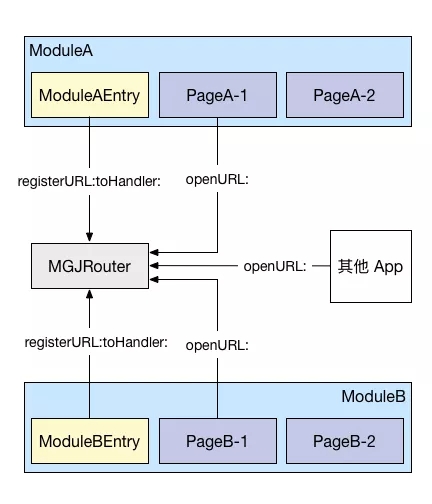
УПИізщМўМфЖМЛсЯђMGJRouterзЂВсЃЌзщМўМфЯрЛЅЕїгУЛђепЪЧЦфЫћЕФAppЖМПЩвдЭЈЙ§openURL:ЗНЗЈДђПЊвЛИіНчУцЛђепЕїгУвЛИізщМўЁЃ
дкзщМўМфЕФЕїгУЃЌФЂЙННжВЩгУСЫProtocolЕФЗНЪНЁЃ
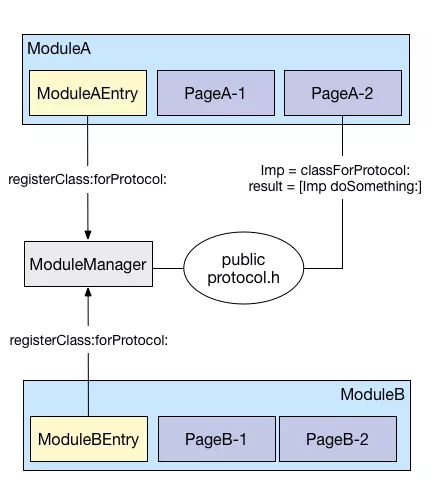
[ModuleManager registerClass:ClassA forProtocol:ProtocolA]
ЕФНсЙћОЭЪЧдк MM ФкВПЮЌЛЄЕФ dict РяаТМгСЫвЛИігГЩфЙиЯЕЁЃ
[ModuleManager classForProtocol:ProtocolA] ЕФЗЕЛиНсЙћОЭЪЧжЎЧАдк
MM ФкВП dict Ря protocol ЖдгІЕФ classЃЌЪЙгУЗНВЛашвЊЙиаФетИі class ЪЧИіЪВУДЖЋЖЋЃЌЗДе§ЪЕЯжСЫ
ProtocolA авщЃЌФУРДгУОЭааЁЃ
етРяашвЊгавЛИіЙЋЙВЕФЕиЗНРДШнФЩетаЉ public protoclЃЌвВОЭЪЧЭМжаЕФ PublicProtocl.hЁЃ
ЮвВТВтЃЌДѓИХЪЕЯжПЩФмЪЧЯТУцЕФбљзгЃК
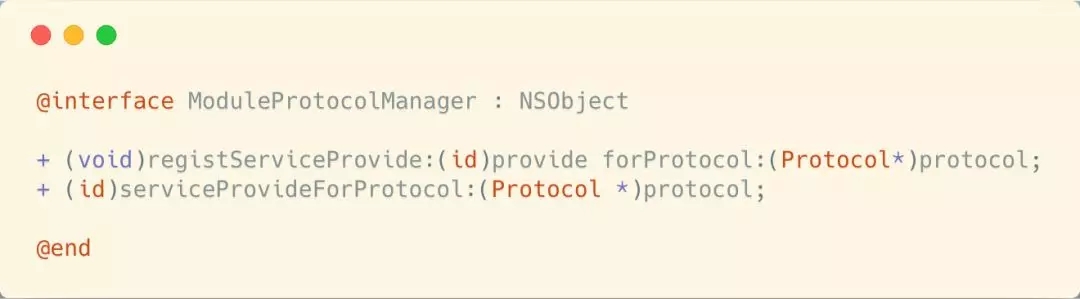
ШЛКѓетИіЪЧвЛИіЕЅР§ЃЌдкРяУцзЂВсИїИіавщЃК

дкModuleProtocolManagerжагУвЛИізжЕфБЃДцУПИізЂВсЕФprotocolЁЃЯждкдйРДВТВТModuleEntryЕФЪЕЯжЁЃ

ШЛКѓУПИіФЃПщФкЖМгавЛИіКЭБЉТЖЕНЭтУцЕФавщЯрСЌНгЕФЁАНгЭЗЁБЁЃ
#import <Foundation/Foundation.h>
@interface DetailModuleEntry : NSObject
@end |
дкЫќЕФЪЕЯжжаЃЌашвЊв§Шы3ИіЭтВПЮФМўЃЌвЛИіЪЧModuleProtocolManagerЃЌвЛИіЪЧDetailModuleEntryProtocolЃЌзюКѓвЛИіЪЧЫљдкФЃПщашвЊЬјзЊЛђепЕїгУЕФзщМўЛђепвГУцЁЃ
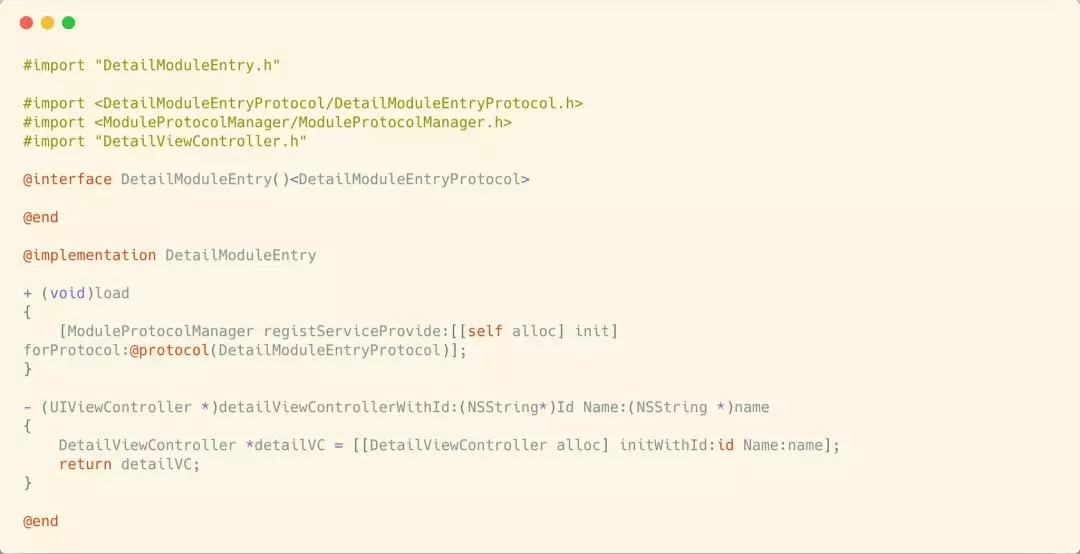
жСДЫЛљгкProtocolЕФЗНАИОЭЭъГЩСЫЁЃШчЙћашвЊЕїгУФГИізщМўЛђепЬјзЊФГИівГУцЃЌжЛвЊЯШДгModuleProtocolManagerЕФзжЕфРяУцИљОнЖдгІЕФModuleEntryProtocolевЕНЖдгІЕФDetailModuleEntryЃЌевЕНСЫDetailModuleEntryОЭЪЧевЕНСЫзщМўЛђепвГУцЕФЁАШыПкЁБСЫЁЃдйАбВЮЪ§ДЋНјШЅМДПЩЁЃ

етбљОЭПЩвдЕїгУЕНзщМўЛђепНчУцСЫЁЃ
ШчЙћзщМўжЎМфгаЯрЭЌЕФНгПкЃЌФЧУДЛЙПЩвдНјвЛВНЕФАбетаЉНгПкЖМГщРыГіРДЁЃетаЉГщРыГіРДЕФНгПкБфГЩЁАдЊНгПкЁБЃЌЫќУЧЪЧПЩвдзуЙЛжЇГХЦ№ећИізщМўвЛВуЕФЁЃ
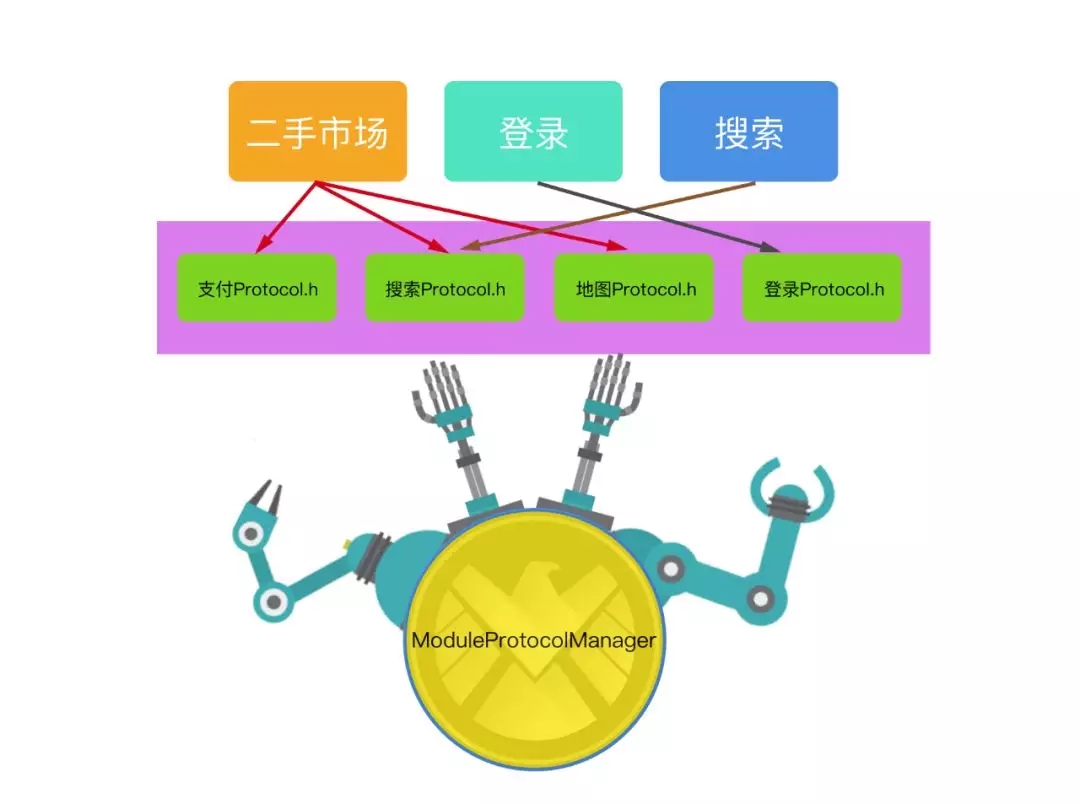
ЃЈ5ЃЉCTMediator Star 803
дйРДЫЕЫЕ@casatwyЕФЗНАИЃЌетЗНАИЪЧЛљгкMediatorЕФЁЃ
ДЋЭГЕФжаМфШЫMediatorЕФФЃЪНЪЧетбљЕФЃК
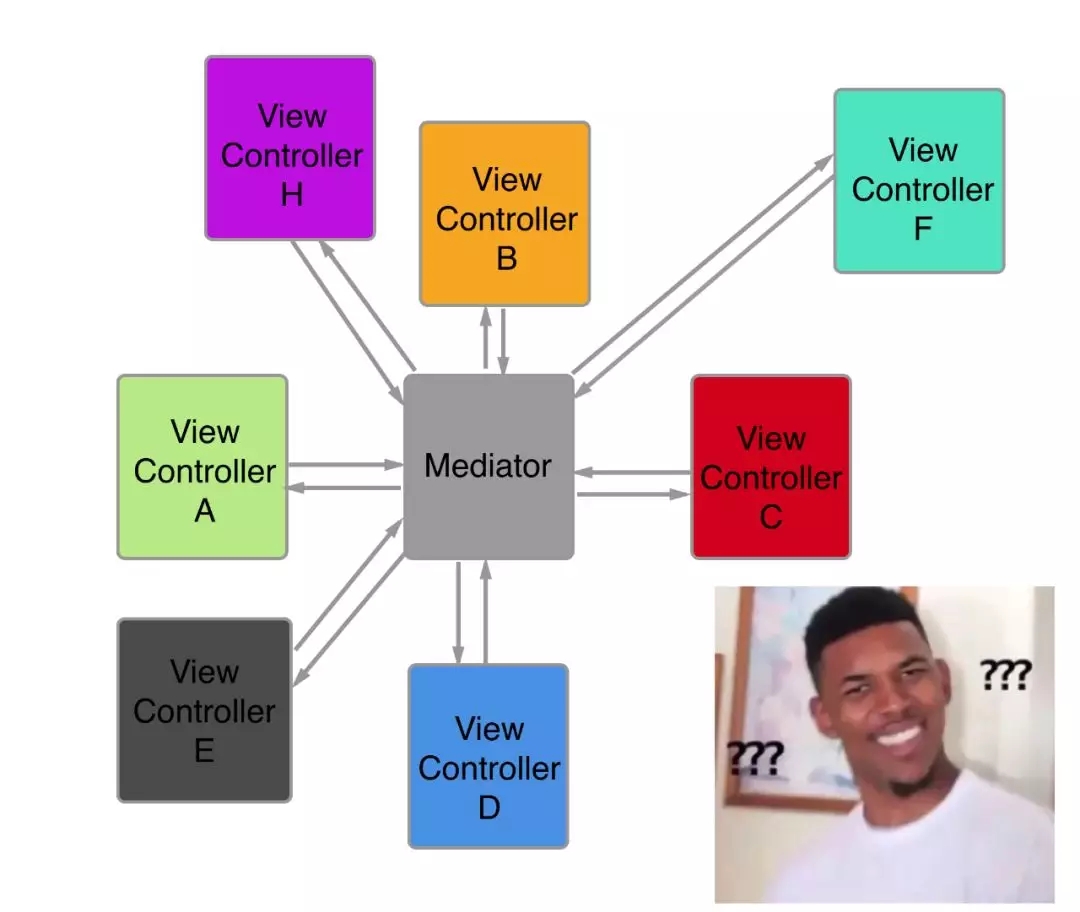
етжжФЃЪНУПИівГУцЛђепзщМўЖМЛсвРРЕжаМфепЃЌИїИізщМўжЎМфЛЅЯрВЛдйвРРЕЃЌзщМўМфЕїгУжЛвРРЕжаМфепMediatorЃЌMediatorЛЙЪЧЛсвРРЕЦфЫћзщМўЁЃФЧУДетЪЧзюжеЗНАИСЫУДЃП
ПДПД@casatwyЪЧдѕУДМЬајгХЛЏЕФЁЃ
жївЊЫМЯыЪЧРћгУСЫTarget-ActionМђЕЅДжБЉЕФЫМЯыЃЌРћгУRuntimeНтОіНтёюЕФЮЪЬтЁЃ

targetNameОЭЪЧЕїгУНгПкЕФObjectЃЌactionNameОЭЪЧЕїгУЗНЗЈЕФSELЃЌparamsЪЧВЮЪ§ЃЌshouldCacheTargetДњБэЪЧЗёашвЊЛКДцЃЌШчЙћашвЊЛКДцОЭАбtargetДцЦ№РДЃЌKeyЪЧtargetClassStringЃЌValueЪЧtargetЁЃ
ЭЈЙ§етжжЗНЪННјааИФдьЕФЃЌЭтУцЕїгУЕФЗНЗЈЖМКмЭГвЛЃЌЖМЪЧЕїгУperformTarget: action:
params: shouldCacheTarget:ЁЃЕкШ§ИіВЮЪ§ЪЧвЛИізжЕфЃЌетИізжЕфРяУцПЩвдДЋКмЖрВЮЪ§ЃЌжЛвЊKey-ValueаДКУОЭПЩвдСЫЁЃДІРэДэЮѓЕФЗНЪНвВЭГвЛдквЛИіЕиЗНСЫЃЌtargetУЛгаЃЌЛђепЪЧtargetЮоЗЈЯьгІЯргІЕФЗНЗЈЃЌЖМПЩвддкMediatorетРяНјааЭГвЛГіДэДІРэЁЃ
ЕЋЪЧдкЪЕМЪПЊЗЂЙ§ГЬжаЃЌВЛЙмЪЧНчУцЕїгУЃЌзщМўМфЕїгУЃЌдкMediatorжаашвЊЖЈвхКмЖрЗНЗЈЁЃгкЪЧзїепгжЯыГіСЫНЈвщЮвУЧгУCategoryЕФЗНЗЈЃЌЖдMediatorЕФЫљгаЗНЗЈНјааВ№ЗжЃЌетбљОЭОЭПЩвдВЛЛсЕМжТMediatorетИіРрЙ§гкХгДѓСЫЁЃ
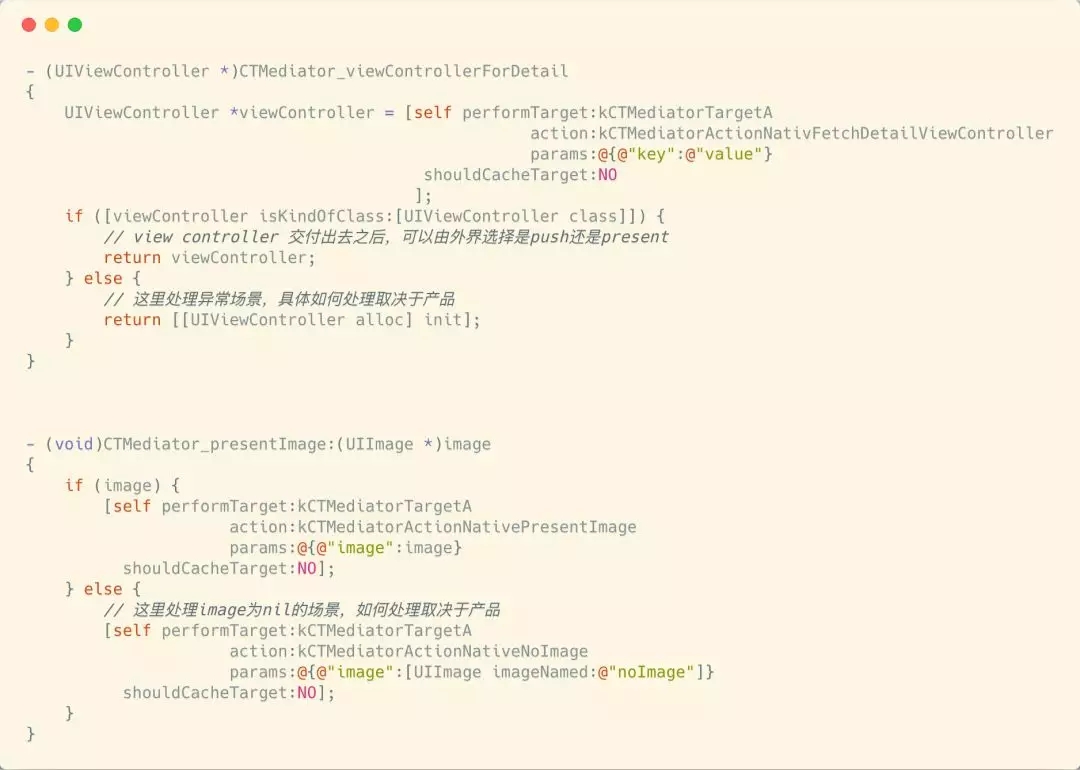
АбетаЉОпЬхЕФЗНЗЈвЛИіИіЕФЖМаДдкCategoryРяУцОЭКУСЫЃЌЕїгУЕФЗНЪНЖМЗЧГЃЕФвЛжТЃЌЖМЪЧЕїгУperformTarget:
action: params: shouldCacheTarget:ЗНЗЈЁЃ
зюжеШЅЕєСЫжаМфепMediatorЖдзщМўЕФвРРЕЃЌИїИізщМўжЎМфЛЅЯрВЛдйвРРЕЃЌзщМўМфЕїгУжЛвРРЕжаМфепMediatorЃЌMediatorВЛвРРЕЦфЫћШЮКЮзщМўЁЃ
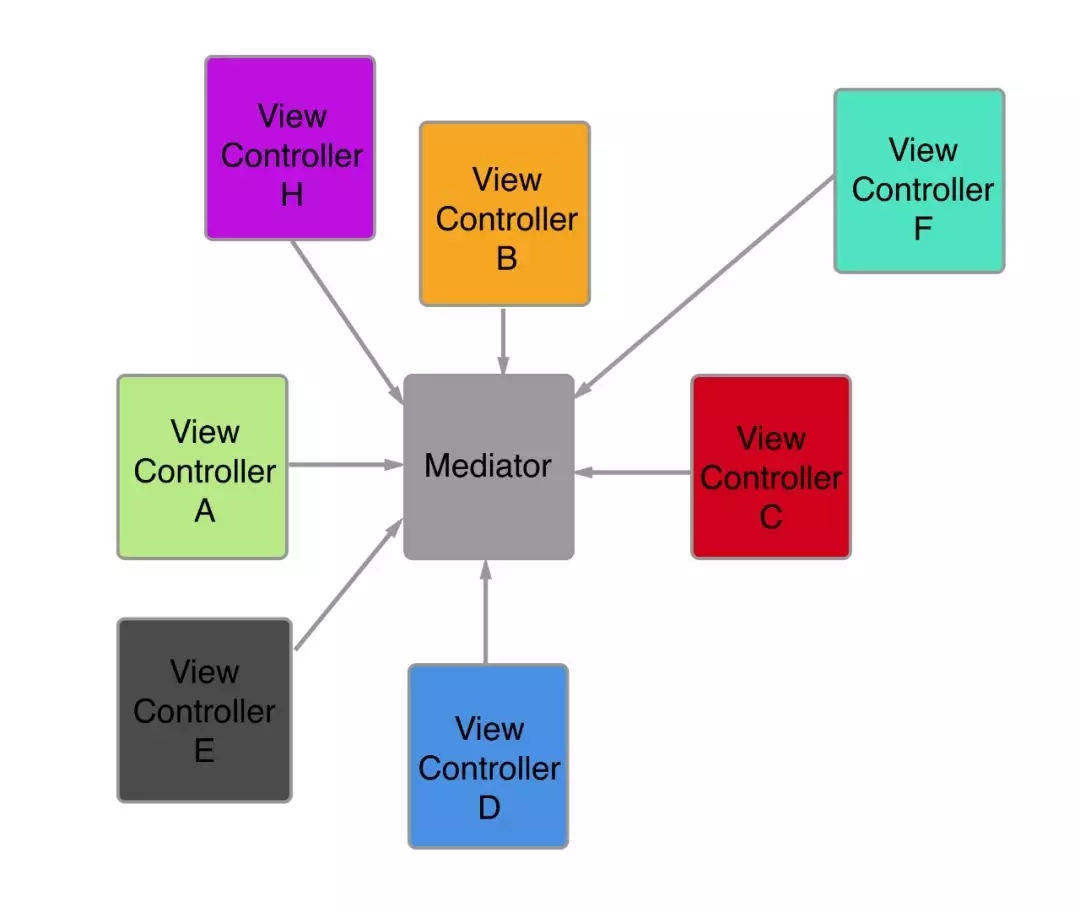
ЃЈ6ЃЉвЛаЉВЂУЛгаПЊдДЕФЗНАИ
Г§СЫЩЯУцПЊдДЕФТЗгЩЗНАИЃЌЛЙгавЛаЉВЂУЛгаПЊдДЕФЩшМЦОЋУРЕФЗНАИЁЃетРяПЩвдКЭДѓМввЛЦ№ЗжЮіНЛСївЛЯТЁЃ
етИіЗНАИЪЧUber ЦяЪжAppЕФвЛИіЗНАИЁЃ
UberдкЗЂЯжMVCЕФвЛаЉБзЖЫжЎКѓЃКБШШчЖЏщќЩЯЭђааОоХжЮоБШЕФVCЃЌЮоЗЈНјааЕЅдЊВтЪдЕШШБЕуКѓЃЌгкЪЧПМТЧАбМмЙЙЛЛГЩVIPERЁЃЕЋЪЧVIPERвВгавЛЖЈЕФБзЖЫЁЃвђЮЊЫќЕФiOSЬиЖЈЕФНсЙЙЃЌвтЮЖзХiOSБиаыЮЊAndroidзіГівЛаЉЭзаЕФШЈКтЁЃвдЪгЭМЮЊЧ§ЖЏЕФгІгУГЬађТпМЃЌДњБэгІгУГЬађзДЬЌгЩЪгЭМЧ§ЖЏЃЌећИігІгУГЬађЖМЫјЖЈдкЪгЭМЪїЩЯЁЃгЩВйзїгІгУГЬађзДЬЌЫљЙиСЊЕФвЕЮёТпМЕФИФБфЃЌОЭБиаыОЙ§PresenterЁЃвђДЫЛсБЉТЖвЕЮёТпМЁЃзюжеЕМжТСЫЪгЭМЪїКЭвЕЮёЪїНјааСЫНєНєЕФёюКЯЁЃетбљЯыЪЕЯжвЛИіНєНєжЛгавЕЮёТпМЕФNodeНкЕуЛђепНєНєжЛгаЪгЭМТпМЕФNodeНкЕуОЭЗЧГЃЕФРЇФбСЫЁЃ
ЭЈЙ§ИФНјVIPERМмЙЙЃЌЮќЪеЦфгХауЕФЬиЕуЃЌИФНјЦфШБЕуЃЌОЭаЮГЩСЫUber ЦяЪжAppЕФШЋаТМмЙЙЁЊЁЊRiblets(РпЙЧ)ЁЃ
дкетИіаТЕФМмЙЙжаЃЌМДЪЙЪЧЯрЫЦЕФТпМвВЛсБЛЧјЗжГЩКмаЁКмаЁЃЌЯрЛЅЖРСЂЃЌПЩвдЕЅЖРНјааВтЪдЕФзщМўЁЃУПИізщМўЖМгаЗЧГЃУїШЗЕФгУЭОЁЃЪЙгУетаЉвЛаЁПщвЛаЁПщЕФRiblets(РпЙЧ)ЃЌзюжеАбећИіAppЦДНгГЩвЛПХRiblets(РпЙЧ)ЪїЁЃ
ЭЈЙ§ГщЯѓЃЌвЛИіRiblets(РпЙЧ)БЛЖЈвхГЩвЛЯТ6ИіИќаЁЕФзщМўЃЌетаЉзщМўИїздгаИїздЕФжАд№ЁЃЭЈЙ§вЛИіRiblets(РпЙЧ)НјвЛВНЕФГщЯѓвЕЮёТпМКЭЪгЭМТпМЁЃ
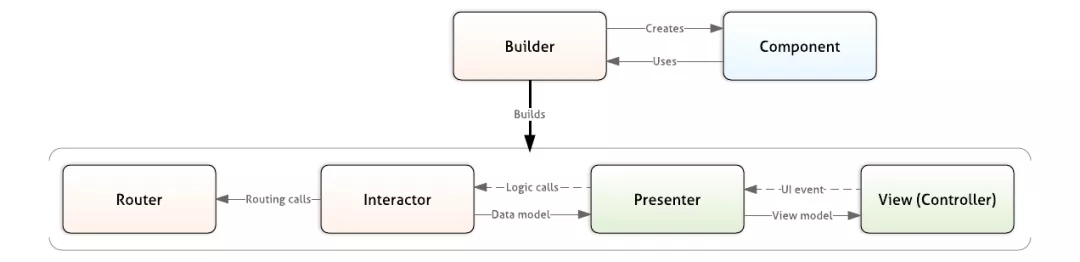
вЛИіRiblets(РпЙЧ)БЛЩшМЦГЩетбљЃЌФЧКЭжЎЧАЕФVIPERКЭMVCгаЪВУДЧјБ№ФиЃПзюДѓЕФЧјБ№дкТЗгЩЩЯУцЁЃ
Riblets(РпЙЧ)ФкЕФRouterВЛдйЪЧЪгЭМТпМЧ§ЖЏЕФЃЌЯждкБфГЩСЫвЕЮёТпМЧ§ЖЏЁЃетвЛжиДѓИФБфОЭЕМжТСЫећИіAppВЛдйЪЧгЩБэЯжаЮЪНЧ§ЖЏЃЌЯждкБфГЩСЫгЩЪ§ОнСїЧ§ЖЏЁЃ
УПвЛИіRibletЖМЪЧгЩвЛИіТЗгЩRouterЃЌвЛИіЙиСЊЦїInteractorЃЌвЛИіЙЙдьЦїBuilderКЭЫќУЧЯрЙиЕФзщМўЙЙГЩЕФЁЃЫљвдЫќЕФУќУћЃЈRouter
- Interactor - BuilderЃЌRibЃЉвВгЩДЫЕУРДЁЃЕБШЛЛЙПЩвдгаПЩбЁЕФеЙЪОЦїPresenterКЭЪгЭМViewЁЃТЗгЩRouterКЭЙиСЊЦїInteractorДІРэвЕЮёТпМЃЌеЙЪОЦїPresenterКЭЪгЭМViewДІРэЪгЭМТпМЁЃ
жиЕуЗжЮівЛЯТRibletРяУцТЗгЩЕФжАд№ЁЃ
1.ТЗгЩЕФжАд№
дкећИіAppЕФНсЙЙЪїжаЃЌТЗгЩЕФжАд№ЪЧгУРДЙиСЊКЭШЁЯћЙиСЊЦфЫћзгRibletЕФЁЃжСгкОіЖЈЪЧгЩЙиСЊЦїInteractorДЋЕнЙ§РДЕФЁЃдкзДЬЌзЊЛЛЙ§ГЬжаЃЌЙиСЊКЭШЁЯћЙиСЊзгRibletЕФЪБКђЃЌТЗгЩвВЛсгАЯьЕНЙиСЊЦїInteractorЕФЩњУќжмЦкЁЃТЗгЩжЛАќКЌ2ИівЕЮёТпМЃК
1ЁЂЬсЙЉЙиСЊКЭШЁЯћЙиСЊЦфЫћТЗгЩЕФЗНЗЈЁЃ
2ЁЂдкЖрИіКЂзгжЎМфОіЖЈзюжезДЬЌЕФзДЬЌзЊЛЛТпМЁЃ
2ЁЂЦДзА
УПвЛИіRibletsжЛгавЛЖдRouterТЗгЩКЭInteractorЙиСЊЦїЁЃЕЋЪЧЫќУЧПЩвдгаЖрЖдЪгЭМЁЃRibletsжЛДІРэвЕЮёТпМЃЌВЛДІРэЪгЭМЯрЙиЕФВПЗжЁЃRibletsПЩвдгЕгаЕЅвЛЕФЪгЭМЃЈвЛИіPresenterеЙЪОЦїКЭвЛИіViewЪгЭМЃЉЃЌвВПЩвдгЕгаЖрИіЪгЭМЃЈвЛИіPresenterеЙЪОЦїКЭЖрИіViewЪгЭМЃЌЛђепЖрИіPresenterеЙЪОЦїКЭЖрИіViewЪгЭМЃЉЃЌЩѕжСвВПЩвдФмУЛгаЪгЭМЃЈУЛгаPresenterеЙЪОЦївВУЛгаViewЪгЭМЃЉЁЃетжжЩшМЦПЩвдгажњгквЕЮёТпМЪїЕФЙЙНЈЃЌвВПЩвдКЭЪгЭМЪїзіЕНКмКУЕФЗжРыЁЃ
ОйИіР§згЃЌЦяЪжЕФRibletЪЧвЛИіУЛгаЪгЭМЕФRibletЃЌЫќгУРДМьВщЕБЧАгУЛЇЪЧЗёгавЛИіМЄЛюЕФТЗЯпЁЃШчЙћЦяЪжШЗЖЈСЫТЗЯпЃЌФЧУДетИіRibletОЭЛсЙиСЊЕНТЗЯпЕФRibletЩЯУцЁЃТЗЯпЕФRibletЛсдкЕиЭМЩЯЯдЪОГіТЗЯпЭМЁЃШчЙћУЛгаШЗЖЈТЗЯпЃЌЦяЪжЕФRibletОЭЛсБЛЙиСЊЕНЧыЧѓЕФRibletЩЯЁЃЧыЧѓЕФRibletЛсдкЦСФЛЩЯЯдЪОЕШД§БЛКєНаЁЃЯёЦяЪжЕФRibletетбљУЛгаШЮКЮЪгЭМТпМЕФRibletЃЌЫќЗжПЊСЫвЕЮёТпМЃЌдкЧ§ЖЏAppКЭжЇГХФЃПщЛЏМмЙЙЦ№СЫжиДѓзїгУЁЃ
3ЁЂRibletsЪЧШчКЮЙЄзїЕФ
RibletжаЕФЪ§ОнСї
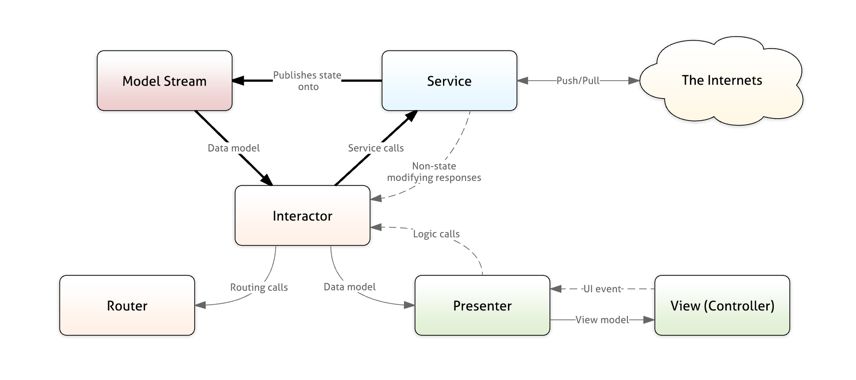
дкетИіаТЕФМмЙЙжаЃЌЪ§ОнСїЖЏЪЧЕЅЯђЕФЁЃDataЪ§ОнСїДгserviceЗўЮёСїЕНModel StreamЩњГЩModelСїЁЃModelСїдйДгModel
StreamСїЖЏЕНInteractorЙиСЊЦїЁЃInteractorЙиСЊЦїЃЌschedulerЕїЖШЦїЃЌдЖГЬЭЦЫЭЖМПЩвдЯыServiceДЅЗЂБфЛЏРДв§Ц№Model
StreamЕФИФЖЏЁЃModel StreamЩњГЩВЛПЩИФЖЏЕФmodelsЁЃетИіЧПжЦЕФвЊЧѓОЭЕМжТЙиСЊЦїжЛФмЭЈЙ§ServiceВуИФБфAppЕФзДЬЌЁЃ
ОйСНИіР§згЃК
1ЁЂЪ§ОнДгКѓЬЈЕНЪгЭМViewЩЯ
вЛИізДЬЌЕФИФБфЃЌв§Ц№ЗўЮёЦїКѓЬЈДЅЗЂЭЦЫЭЕНAppЁЃЪ§ОнОЭБЛPushЕНAppЃЌШЛКѓЩњГЩВЛПЩБфЕФЪ§ОнСїЁЃЙиСЊЦїЪеЕНmodelжЎКѓЃЌАбЫќДЋЕнИјеЙЪОЦїPresenterЁЃеЙЪОЦїPresenterАбmodelзЊЛЛГЩview
modelДЋЕнИјЪгЭМViewЁЃ
2ЁЂЪ§ОнДгЪгЭМЕНЗўЮёЦїКѓЬЈ
ЕБгУЛЇЕуЛїСЫвЛИіАДХЅЃЌБШШчЕЧТМАДХЅЁЃЪгЭМViewОЭЛсДЅЗЂUIЪТМўДЋЕнИјеЙЪОЦїPresenterЁЃеЙЪОЦїPresenterЕїгУЙиСЊЦїInteractorЕЧТМЗНЗЈЁЃЙиСЊЦїInteractorгжЛсЕїгУService
callЕФЪЕМЪЕЧТМЗНЗЈЁЃЧыЧѓЭјТчжЎКѓЛсАбЪ§ОнpullЕНКѓЬЈЗўЮёЦїЁЃ
RibletМфЕФЪ§ОнСї
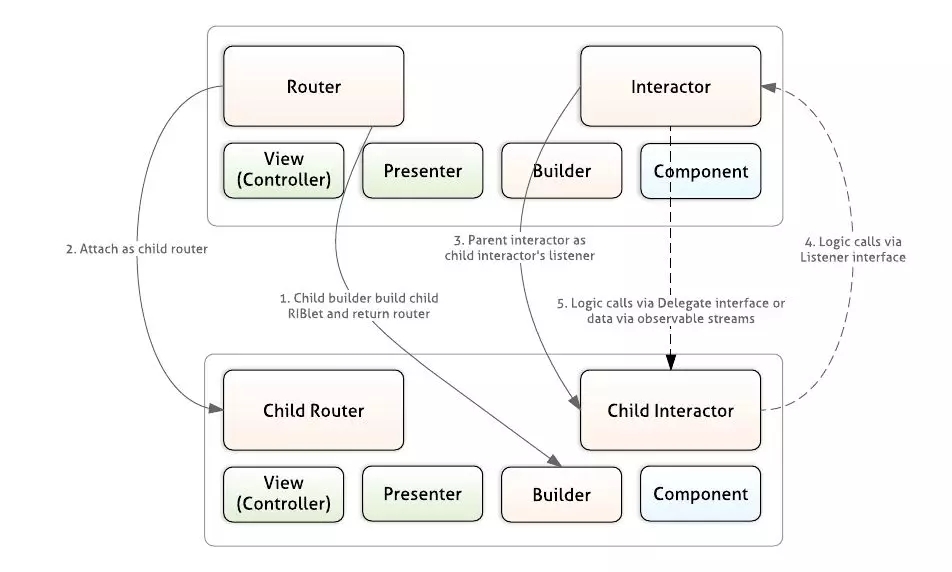
ЕБвЛИіЙиСЊЦїInteractorдкДІРэвЕЮёТпМЕФЙЄГЬжаЃЌашвЊЕїгУЦфЫћRibletЕФЪТМўЕФЪБКђЃЌЙиСЊЦїInteractorашвЊКЭзгЙиСЊЦїInteractorНјааЙиСЊЁЃМћЩЯЭМ5ИіВНжшЁЃ
ШчЙћЕїгУЗНЗЈЪЧДгзгЕїгУИИРрЃЌИИРрЕФInteractorЕФНгПкЭЈГЃБЛЖЈвхГЩМрЬ§епlistenerЁЃШчЙћЕїгУЗНЗЈЪЧДгИИРрЕїгУЕНзгРрЃЌФЧУДзгРрЕФНгПкЭЈГЃЪЧвЛИіdelegateЃЌЪЕЯжИИРрЕФвЛаЉProtocolЁЃ
дкRibletЕФЗНАИжаЃЌТЗгЩRouterНіНіжЛЪЧгУРДЮЌЛЄвЛИіЪїаЭЙиЯЕЃЌЖјЙиСЊЦїInteractorВХЕЃЕБЕФЪЧгУРДОіЖЈДЅЗЂзщМўМфЕФТпМЬјзЊЕФНЧЩЋЁЃ
ЮхЁЂИїИіЗНАИгХШБЕу

ОЙ§ЩЯУцЕФЗжЮіЃЌПЩвдЗЂЯжЃЌТЗгЩЕФЩшМЦЫМТЗЪЧДгURLRoute ->Protocol-class
->Target-ActionвЛВНВНЕФЩюШыЕФЙ§ГЬЁЃетвВЪЧж№НЅЩюШыБОжЪЕФЙ§ГЬЁЃ
1ЁЂURLRouteзЂВсЗНАИЕФгХШБЕу
ЪзЯШURLRouteвВаэЪЧНшМјЧАЖЫRouterКЭЯЕЭГAppФкЬјзЊЕФЗНЪНЯыГіРДЕФЗНЗЈЁЃЫќЭЈЙ§URLРДЧыЧѓзЪдДЁЃВЛЙмЪЧH5ЃЌRNЃЌWeexЃЌiOSНчУцЛђепзщМўЧыЧѓзЪдДЕФЗНЪНОЭЖМЭГвЛСЫЁЃURLРяУцвВЛсДјЩЯВЮЪ§ЃЌетбљЕїгУЪВУДНчУцЛђепзщМўЖМПЩвдЁЃЫљвдетжжЗНЪНЪЧзюШнвзЃЌвВЪЧзюЯШПЩвдЯыЕНЕФЁЃ
URLRouteЕФгХЕуКмЖрЃЌзюДѓЕФгХЕуОЭЪЧЗўЮёЦїПЩвдЖЏЬЌЕФПижЦвГУцЬјзЊЃЌПЩвдЭГвЛДІРэвГУцГіЮЪЬтжЎКѓЕФДэЮѓДІРэЃЌПЩвдЭГвЛШ§ЖЫЃЌiOSЃЌAndroidЃЌH5
/ RN / Weex ЕФЧыЧѓЗНЪНЁЃ
ЕЋЪЧетжжЗНЪНвВашвЊПДВЛЭЌЙЋЫОЕФашЧѓЁЃШчЙћЙЋЫОРяУцвбОЭъГЩСЫЗўЮёЦїЖЫЖЏЬЌЯТЗЂЕФНХЪжМмЙЄОпЃЌЧАЖЫвВЭъГЩСЫNativeЖЫШчЙћГіЯжДэЮѓСЫЃЌПЩвдЫцЪБЬцЛЛЯрЭЌвЕЮёНчУцЕФашЧѓЃЌФЧУДетИіЪБКђПЩФмбЁдёURLRouteЕФМИТЪЛсИќДѓЁЃ
ЕЋЪЧШчЙћЙЋЫОРяУцH5УЛгазіЯрЙиГіЯжЮЪЬтКѓФмЬцЛЛЕФНчУцЃЌH5ПЊЗЂШЫдБОѕЕУетЪЧИјЫћУЧдіЬэИКЕЃЁЃШчЙћЙЋЫОвВУЛгаЭъГЩЗўЮёЦїЖЏЬЌЯТЗЂТЗгЩЙцдђЕФФЧЬзЯЕЭГЃЌФЧУДЙЋЫОПЩФмОЭВЛЛсВЩгУURLRouteЕФЗНЪНЁЃвђЮЊURLRouteДјРДЕФЩйСПЖЏЬЌадЃЌЙЋЫОЪЧПЩвдгУJSPatchРДзіЕНЁЃЯпЩЯГіЯжbugСЫЃЌПЩвдСЂМДгУJSPatchаоЕєЃЌЖјВЛВЩгУURLRouteШЅзіЁЃ
ЫљвдбЁдёURLRouteетжжЗНАИЃЌвВвЊПДЙЋЫОЕФЗЂеЙЧщПіКЭШЫдБЗжХфЃЌММЪѕбЁаЭЗНУцЁЃ
URLRouteЗНАИвВЪЧДцдквЛаЉШБЕуЕФЃЌЪзЯШURLЕФmapЙцдђЪЧашвЊзЂВсЕФЃЌЫќУЧЛсдкloadЗНЗЈРяУцаДЁЃаДдкloadЗНЗЈРяУцЪЧЛсгАЯьAppЦєЖЏЫйЖШЕФЁЃ
ЦфДЮЪЧДѓСПЕФгВБрТыЁЃURLСДНгРяУцЙигкзщМўКЭвГУцЕФУћзжЖМЪЧгВБрТыЃЌВЮЪ§вВЖМЪЧгВБрТыЁЃЖјЧвУПИіURLВЮЪ§зжЖЮЖМБиаывЊвЛИіЮФЕЕНјааЮЌЛЄЃЌетИіЖдгквЕЮёПЊЗЂШЫдБвВЪЧвЛИіИКЕЃЁЃЖјЧвURLЖЬСЌНгЩЂТфдкећИіAppЫФДІЃЌЮЌЛЄЦ№РДЪЕдкгаЕуТщЗГЃЌЫфШЛФЂЙННжЯыЕНСЫгУКъЭГвЛЙмРэетаЉСДНгЃЌЕЋЪЧЛЙЪЧНтОіВЛСЫгВБрТыЕФЮЪЬтЁЃ
еце§вЛИіКУЕФТЗгЩЪЧдкЮоаЮЕБжаЗўЮёећИіAppЕФЃЌЪЧвЛИіЮоИажЊЕФЙ§ГЬЃЌДгетвЛЕуРДЫЕЃЌТдгаЕуШБЪЇЁЃ
зюКѓвЛИіШБЕуЪЧЃЌЖдгкДЋЕнNSObjectЕФВЮЪ§ЃЌURLЪЧВЛЙЛгбКУЕФЃЌЫќзюЖрЪЧДЋЕнвЛИізжЕфЁЃ
2ЁЂProtocol-ClassзЂВсЗНАИЕФгХШБЕу
Protocol-ClassЗНАИЕФгХЕуЃЌетИіЗНАИУЛгагВБрТыЁЃ
Protocol-ClassЗНАИвВЪЧДцдквЛаЉШБЕуЕФЃЌУПИіProtocolЖМвЊЯђModuleManagerНјаазЂВсЁЃ
етжжЗНАИModuleEntryЪЧЭЌЪБашвЊвРРЕModuleManagerКЭзщМўРяУцЕФвГУцЛђепзщМўСНепЕФЁЃЕБШЛModuleEntryвВЪЧЛсвРРЕModuleEntryProtocolЕФЃЌЕЋЪЧетИівРРЕЪЧПЩвдШЅЕєЕФЃЌБШШчгУRuntimeЕФЗНЗЈNSProtocolFromStringЃЌМгЩЯгВБрТыЪЧПЩвдШЅЕєЖдProtocolЕФвРРЕЕФЁЃЕЋЪЧПМТЧЕНгВБрТыЕФЗНЪНЖдГіЯжbugЃЌКѓЦкЮЌЛЄЖМЪЧВЛгбКУЕФЃЌЫљвдЖдProtocolЕФвРРЕЛЙЪЧВЛвЊШЅГ§ЁЃ
зюКѓвЛИіШБЕуЪЧзщМўЗНЗЈЕФЕїгУЪЧЗжЩЂдкИїДІЕФЃЌУЛгаЭГвЛЕФШыПкЃЌвВОЭУЛЗЈзізщМўВЛДцдкЪБЛђепГіЯжДэЮѓЪБЕФЭГвЛДІРэЁЃ
3ЁЂTarget-ActionЗНАИЕФгХШБЕу
Target-ActionЗНАИЕФгХЕуЃЌГфЗжЕФРћгУRuntimeЕФЬиадЃЌЮоашзЂВсетвЛВНЁЃTarget-ActionЗНАИжЛгаДцдкзщМўвРРЕMediatorетвЛВувРРЕЙиЯЕЁЃдкMediatorжаЮЌЛЄеыЖдMediatorЕФCategoryЃЌУПИіcategoryЖдгІвЛИіTargetЃЌCategroyжаЕФЗНЗЈЖдгІActionГЁОАЁЃTarget-ActionЗНАИвВЭГвЛСЫЫљгазщМўМфЕїгУШыПкЁЃ
Target-ActionЗНАИвВФмгавЛЖЈЕФАВШЋБЃжЄЃЌЫќЖдurlжаНјааNativeЧАзКНјаабщжЄЁЃ
Target-ActionЗНАИЕФШБЕуЃЌTarget_ActionдкCategoryжаНЋГЃЙцВЮЪ§ДђАќГЩзжЕфЃЌдкTargetДІдйАбзжЕфВ№АќГЩГЃЙцВЮЪ§ЃЌетОЭдьГЩСЫвЛВПЗжЕФгВБрТыЁЃ
4ЁЂзщМўШчКЮВ№ЗжЃП
етИіЮЪЬтЦфЪЕгІИУЪЧдкДђЫуЪЕЪЉзщМўЛЏжЎЧАОЭгІИУПМТЧЕФЮЪЬтЁЃЮЊКЮЛЙвЊЗХдкетРяЫЕФиЃПвђЮЊзщМўЕФВ№ЗжУПИіЙЋЫОЖМгаЪєгкздМКЕФВ№ЗжЗНАИЃЌАДеевЕЮёЯпВ№ЃПАДеезюЯИаЁЕФвЕЮёЙІФмФЃПщВ№ЃПЛЙЪЧАДеевЛИіЭъГЩЕФЙІФмНјааВ№ЗжЃПетИіОЭЧЃГЖЕНСЫВ№ЗжДжЯИЖШЕФЮЪЬтСЫЁЃзщМўВ№ЗжЕФДжЯИЖШОЭЛсжБНгЙиЯЕЕНЮДРДТЗгЩашвЊНтёюЕФГЬЖШЁЃ
МйЩшЃЌАбЕЧТМЕФЫљгаСїГЬЗтзАГЩвЛИізщМўЃЌгЩгкЕЧТМРяУцЛсЩцМАЕНЖрИівГУцЃЌФЧУДетаЉвГУцЖМЛсДђАќдквЛИізщМўРяУцЁЃФЧУДЦфЫћФЃПщашвЊЕїгУЕЧТМзДЬЌЕФЪБКђЃЌетЪБКђОЭашвЊгУЕНЕЧТМзщМўБЉТЖдкЭтУцПЩвдЛёШЁЕЧТМзДЬЌЕФНгПкЁЃФЧУДетИіЪБКђОЭПЩвдПМТЧАбетаЉНгПкаДЕНProtocolРяУцЃЌБЉТЖИјЭтУцЪЙгУЁЃЛђепгУTarget-ActionЕФЗНЗЈЁЃетжжАбвЛИіЙІФмШЋВПЖМЛЎЗжГЩЕЧТМзщМўЕФЛАЃЌЛЎЗжСЃЖШОЭЩдЮЂДжвЛЕуЁЃ
ШчЙћНіНіАбЕЧТМзДЬЌЕФЯИаЁЙІФмЛЎЗжГЩвЛИідЊзщМўЃЌФЧУДЭтУцЯыЛёШЁЕЧТМзДЬЌОЭжБНгЕїгУетИізщМўОЭКУЁЃетжжЛЎЗжЕФСЃЖШОЭЗЧГЃЯИСЫЁЃетбљОЭЛсЕМжТзщМўИіЪ§ОоЖрЁЃ
ЫљвддкНјааВ№ЗжзщМўЕФЪБКђЃЌвВаэЕБЪБвЕЮёВЂВЛИДдгЕФЪБКђЃЌВ№ЗжГЩзщМўЃЌЯрЛЅёюКЯвВВЛДѓЁЃЕЋЪЧЫцзХвЕЮёВЛЙмБфЛЏЃЌжЎЧАЛЎЗжЕФзщМўМфёюКЯаддНРДдНДѓЃЌгкЪЧОЭЛсПМТЧМЬајАбжЎЧАЕФзщМўдйНјааВ№ЗжЁЃвВаэгааЉвЕЮёПГЕєСЫЃЌжЎЧАвЛаЉаЁЕФзщМўвВаэЛЙЛсБЛзщКЯЕНвЛЦ№ЁЃзмжЎЃЌдквЕЮёУЛгаЭъШЋЙЬЖЈЯТРДжЎЧАЃЌзщМўЕФЛЎЗжПЩФмвЛжБНјааЪБЁЃ
СљЁЂзюКУЕФЗНАИ
ЙигкМмЙЙЃЌЮвОѕЕУХзПЊвЕЮёЬИМмЙЙЪЧУЛгавтвхЕФЁЃвђЮЊМмЙЙЪЧЮЊСЫвЕЮёЗўЮёЕФЃЌПеЬИМмЙЙжЛЪЧвЛжжРэЯыЕФзДЬЌЁЃЫљвдУЛгазюКУЕФЗНАИЃЌжЛгазюЪЪКЯЕФЗНАИЁЃ
зюЪЪКЯздМКЙЋЫОвЕЮёЕФЗНАИВХЪЧзюКУЕФЗНАИЁЃЗжЖјжЮжЎЃЌеыЖдВЛЭЌвЕЮёбЁдёВЛЭЌЕФЗНАИВХЪЧзюгХЕФНтОіЗНАИЁЃШчЙћЗЧвЊС§ЭГЕФВЩгУвЛжжЗНАИЃЌВЛЭЌвЕЮёжЎМфашвЊЭЌвЛжжЗНАИЃЌашвЊЭзаЮўЩќЕФЖЋЮїЬЋЖрОЭВЛКУСЫЁЃ
ЯЃЭћБОЮФФмХззЉв§гёЃЌАяжњДѓМвбЁдёГізюЪЪКЯздМввЕЮёЕФТЗгЩЗНАИЁЃЕБШЛПЯЖЈЛсгаИќМггХауЕФЗНАИЃЌЯЃЭћДѓМвФмЖрЖржИЕуЮвЁЃ |









